PyMC-Marketing简介 PyMC-Marketing是一个基于PyMC(一个用于贝叶斯统计建模的Python库)构建的开源工具包,专门用于解决市场营销领域的数据分析与建模任务。它提供了一套高效、灵活的模型和工具,帮助市场营销从…

关于生存分析,先前已经整理过一篇非常详细的文章:生存分析从概念到实战,里面也涉及到了 lifelines 的使用。本次梳理期望从另外的层面对生存分析的使用进行进一步的梳理。 Lifelines 简介 lifelines 是一个专注于…
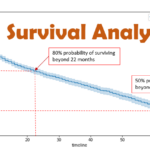
Lifetimes简介 Python的lifetimes包是一个专注于客户生命周期分析(Customer Lifetime Value, CLV)和重复购买行为建模的工具库。它基于概率模型(如Beta-Geometric和Gamma-Gamma模型),帮助预测客户的未来交易频…
什么是媒体组合模型? 媒体组合模型(Marketing Mix Modeling,MMM)是一种统计分析方法,用于量化不同营销渠道和外部因素对销售或业务目标的影响,从而优化营销预算分配和策略。 核心目标 效果评估:量化各营…

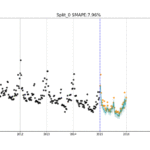
UberOrbit简介 Uber开源的Orbit是一个专为时间序列预测设计的Python库,旨在帮助开发者快速构建、评估和部署预测模型。它结合了统计模型和机器学习技术,特别适合处理具有复杂季节性、趋势性和外部协变量的时间序列…
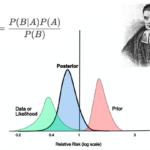
在精细化运营细分维度的PK中,经常会遇到部分场景下数据量较小导致结构存在偏差的问题。于是引入了贝叶斯平均并发现效果不错。 贝叶斯平均简介 贝叶斯平均(Bayesian Average)是一种结合先验信息与观测数据来估…
增量分析(Incremental Analysis)是衡量营销活动或广告投放“真实增量效果”的核心方法,旨在回答一个关键问题:如果没有这次营销活动,用户的行为会发生怎样的变化?它通过量化广告带来的纯新增转化(即用户原本不…
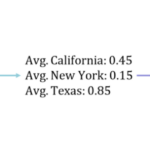
什么是目标编码? 目标编码(Target Encoding),又称均值编码、似然编码,是一种将分类变量转换为数值特征的技术,通过利用目标变量的统计信息来捕捉类别与目标之间的关系。 核心思想 目标编码用目标变量的…
为什么需要后台任务? 场景痛点:同步处理耗时操作(如发送邮件、数据分析)导致请求阻塞,用户体验差。 核心价值:后台任务实现异步非阻塞,提升吞吐量和响应速度。 FastAPI 优势:原生支持异步、多种任务方案…

在数据分析或算法模型搭建时,经常会遇到将连续变量转化为类别分箱的场景。用的分箱方法有等宽分箱、等频分箱、聚类分箱和基于决策树的分箱等。今天要分享的是基于组别间差异的决策树分箱方法。 代码实现 import …






