iDice简介
iDice(指标异常归因算法)是一种用于识别与新出现问题(Emerging Issues)相关的有效组合的自动化算法。它通过从海量属性组合中高效地识别出与新兴问题高度相关的有效组合,帮助技术支持工程师快速定位和解决问题。
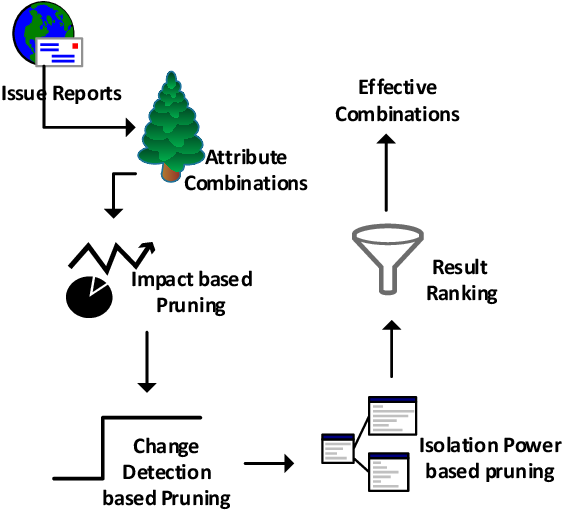
新兴问题(Emerging Issues)指在复杂软件系统(如云计算平台、分布式服务)中,由代码缺陷、配置错误或环境变化引发的突发性异常模式。这类问题通常表现为短时间内特定维度(如错误类型、服务器版本、地理位置)的指标突增,但因其模式多样且动态变化,传统监控工具难以有效捕捉。
核心挑战:
- 数据规模与实时性:微软Azure等系统每日产生数百万事件,人工分析效率低下。
- 多维关联性:异常常涉及多个属性的组合(如”错误码500+版本v2+欧洲区域”),单一维度检测易漏报。
- 可解释性需求:仅发现异常不够,需提供根因线索(如关键属性组合)以加速修复。
iDice的主要特点:
- 属性组合识别:
- 将识别属性组合作为一个模式挖掘问题。
- 给定一段时间内的客户问题报告量,目标是搜索一个属性组合,将整个多维时间序列数据集隔离成两个部分:一部分问题量显著增加,另一部分没有这种显著增加。
- 高效的修剪步骤:
- 基于影响的修剪:只考虑与大量问题报告相关的属性集。
- 基于变化检测的修剪:使用GLR算法检测时间序列中的变化点。
- 基于隔离能力的修剪:去除冗余属性组合,确保识别的属性组合是有效的和高效的。
iDice与Adtributor的对比
iDice与Adtributor均是针对大规模系统异常检测与根因分析的工具,但二者在问题定义、方法论、技术实现等方面存在显著差异。以下从多个维度详细对比二者的区别:
核心问题与目标
| 维度 | iDice | Adtributor |
| 核心问题 | 检测突发性多维组合异常(Emerging Issues),如短时间内多个属性的异常共现 | 分析已知异常的根本原因,确定导致指标(如错误率)突增的关键维度或属性组合 |
| 目标 | 实时发现新兴问题,提供可解释的组合属性模式 | 对已知异常进行多维根因归因,解释异常由哪些属性(或属性组合)导致 |
方法论与技术路线
| 维度 | iDice | Adtributor |
| 数据建模 | 将事件数据建模为动态图(Issue Graph),节点为属性组合,边为共现关系 | 将数据视为多维时间序列,每个维度对应一个属性(如错误码、区域) |
| 核心算法 | l 突发社区检测(基于图分割与显著性检验)
l 最小覆盖集生成(贪心算法) |
l基于熵的贡献度分析
l 卡方检验筛选关键维度 |
| 时序分析 | 通过滑动窗口与概率后缀树(PST)建模时序突发性 | 依赖静态时间窗口统计(如按小时聚合数据) |
| 输出形式 | 突发社区(子图)及其最小属性覆盖集(如error_code=500 AND region=east) | 关键维度排序(如region=east对异常贡献度最高) |
技术特点对比
| 维度 | iDice | Adtributor |
| 优势 | l 捕捉动态、突发的多维组合异常
l 解释性强(直接输出属性组合) |
l 计算效率高(基于统计检验)
l 适合静态根因分析 |
| 局限性 | l 依赖图构建与社区检测,计算复杂度高
l 冷启动问题(需历史数据建模基线) |
l 难以检测突发性组合异常
l 仅支持单维度或低阶组合归因 |
| 实时性 | 支持流式处理(增量图更新) | 通常面向离线批量分析 |
适用场景
| 场景 | iDice | Adtributor |
| 突发性组合异常检测 | ✅如新版本发布后,特定区域(region=east)的某错误码(error_code=500)突增 | ❌仅能发现单一维度(如region=east)的异常,无法捕捉组合模式 |
| 已知异常的根因分析 | ❌需提前定义异常时间段 | ✅分析已知时间段内的异常,快速定位关键维度(如某机房故障导致错误率上升) |
| 动态环境适应性 | ✅通过滑动窗口与增量图更新适应数据流变化 | ❌依赖静态时间窗口,难以处理实时数据 |
总结与选择建议
- 选择iDice:需实时检测突发性、多维组合异常(如新版本引发的跨区域错误),且需要生成可解释的属性组合指导修复。适用领域:云服务故障排查、持续交付监控。
- 选择Adtributor:需快速分析已知异常的根本原因(如某时间段错误率突增),且关注单一维度的贡献度(如区域、服务版本)。适用领域:运维报告生成、事后根因分析。
- 互补性:iDice可用于实时预警新兴问题,Adtributor可用于事后深度归因,二者结合可覆盖异常检测的全生命周期。
iDice的原理与实现
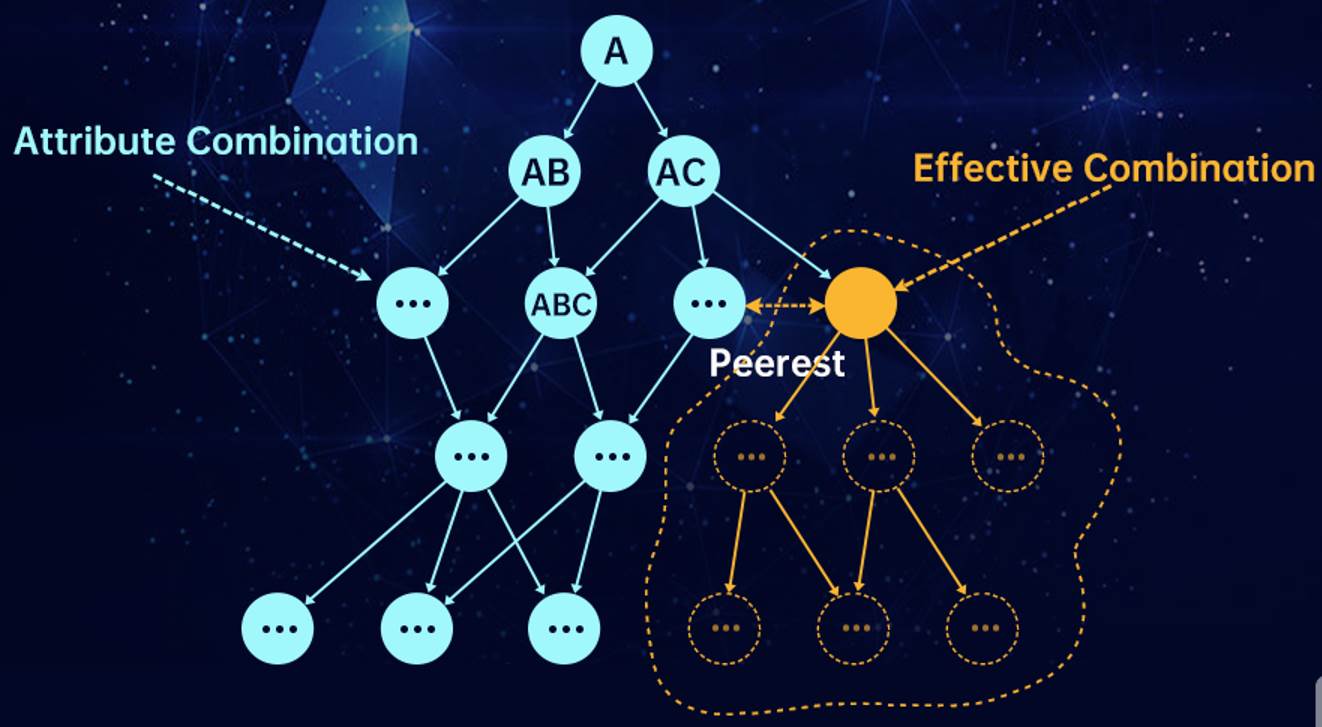
核心思想
iDice算法的核心思想是通过自动化和智能化的手段,从大量的问题报告数据中高效、准确地识别出与新兴问题(emerging issues)相关的有效组合(effective combinations)。
自动识别有效组合
iDice旨在自动识别那些能够显著隔离问题并反映问题变化趋势的属性组合。这些有效组合对于支持工程师来说非常重要,因为它们可以帮助快速定位和解决新兴问题,减少对客户的影响。
减少搜索空间
由于可能的属性组合数量庞大,逐一检查不现实。iDice通过几种剪枝策略有效地减少搜索空间:
- 基于影响的剪枝(Impact-based Pruning):种策略基于属性组合的影响,即该组合对应的问题报告数量。只有那些与大量问题报告相关的属性组合才会被保留,其他的则会被剪枝掉。这有助于忽略那些与新兴问题无关的组合。
- 基于变化检测的剪枝(Change Detection based Pruning):这种策略关注于识别问题报告数量显著增加的情况。通过时间序列数据,iDice应用变化检测算法(如广义似然比检验,GLR)来识别出在某个时间点之后问题报告数量显著增加的组合。如果某个属性组合没有显示出明显的变化,则会被剪枝。
- 基于隔离能力的剪枝(Isolation Power based Pruning):这种策略旨在进一步减少冗余,确保每个有效组合尽可能独特,能够有效地隔离出那些表现出变化的属性组合。隔离能力(Isolation Power)基于信息熵的概念,通过计算每个组合的隔离能力来决定是否保留该组合。
利用时间序列数据
iDice处理的数据具有时间序列特性,每个问题报告都有一个时间戳。通过构建时间序列数据并应用变化检测算法(如广义似然比检验,GLR),iDice能够识别出问题报告数量的显著变化点。
信息熵的应用
iDice基于信息熵的概念,提出了隔离能力(Isolation Power)指标。通过计算每个组合的隔离能力,iDice能够进一步减少冗余,确保每个有效组合尽可能独特,能够有效地隔离出那些表现出变化的属性组合。
方法论框架
iDice采用“数据建模→异常检测→解释生成”的三阶段流程,核心创新在于将多维数据建模为动态图,结合时间序列分析与社区检测技术。
问题图(Issue Graph)构建
目标:将离散的日志事件转化为结构化图模型,捕捉属性间的关联。
- 节点定义:每个节点代表一个属性键值对(如error_code=404、region=east),权重为出现频次。
- 边定义:边连接共现的节点(如同一事件中的error_code=404和region=east),权重为共现次数。
- 动态更新:基于滑动时间窗口(如15分钟)增量更新图结构,适应数据流变化。
技术细节:
- 属性选择:筛选高区分度的属性(如错误码、服务版本),排除低信息量字段。
- 稀疏性处理:剪枝低频节点/边(如频次<5),减少计算复杂度。
突发社区检测(Bursty Community Detection)
目标:识别图中突增的子图结构(社区),表征潜在问题。
- 突增判定:
- 基线建模:通过历史数据计算节点/边的预期频次(如过去7天同一时间段的平均值)。
- 突增分数:使用似然比检验(Likelihood Ratio Test)或 泊松分布假设检验,量化当前窗口频次与基线的偏离程度。
- 社区发现:
- 动态图分割算法:结合模块度优化(Modularity Optimization),将突增节点划分为紧密连接的子图。
- 显著性验证:通过置换测试(Permutation Test)排除随机波动导致的假阳性。
解释生成(Explanation Generation)
目标:提炼突发社区的关键属性组合,形成人类可理解的解释。
- 信息增益分析:评估各属性对社区突增的贡献度。例如,若error_code=500在社区中显著高频,则其信息增益高。
- 最小覆盖集(Minimal Hitting Set):选择最少的属性组合覆盖社区内大部分节点。例如,选择error_code=500和region=east覆盖80%的异常事件。
示例解释:检测到突发社区包含{error_code=500,service_version=v2,region=east},生成解释为error_code=500 AND region=east,提示开发者优先检查东区v2版本服务的500错误。
关键技术实现
时间序列分析与滑动窗口
- 滑动窗口机制:将数据流划分为固定时长窗口(如15分钟),逐窗口更新问题图。
- 趋势预测:使用概率后缀树(PST)建模事件序列的时序依赖,预测未来窗口的预期频次,增强突增检测的鲁棒性。
图优化策略
- 增量计算:仅更新当前窗口内变化的节点/边,避免全图重建。
- 并行化处理:将图划分为子图,利用分布式框架(如Spark GraphX)并行计算社区检测。
可解释性保障
- 贪心算法:从信息增益最高的属性开始,逐步选择覆盖最多未覆盖节点的属性,构建最小解释集。
- 交互式调试:允许开发者调整解释的覆盖阈值(如从80%调整到90%),平衡简洁性与完整性。
iDice的Python实现
Python代码实现
以下是一个基于iDice核心思想的简化版Python实现框架。由于实际生产环境中的复杂性和大规模数据处理需求,这里提供的是算法核心逻辑的演示版本。
代码结构概览
代码实现了增强版iDice算法,用于检测多维属性组合的异常突变模式。核心模块包括:
- Impact-based Pruning(基于影响的剪枝)
- 时间序列构建
- 变点检测(增强CUSUM算法)
- 隔离能力计算
- 排名得分计算
- 完整iDice算法流程
模块详解
Impact-based Pruning
- 功能:通过FP-Growth算法挖掘频繁项集,筛选出支持度达标的候选组合
- 关键实现:
-
- 事务列表构建:根据count列扩展原始数据,处理加权计数
独热编码转换:使用 MultiLabelBinarizer 生成布尔矩阵
-
- FP-Growth 参数:动态计算最小支持度 min_support = support_threshold / total_transactions
- 结果优化:规范化属性排序,直接计算支持度避免重复扫描数据
时间序列构建
- 功能:为每个候选组合生成按日聚合的时间序列
- 优化点:
- 向量化布尔过滤:df[combo.keys()].eq(pd.Series(combo)).all(axis=1)
- 时间处理:强制日期类型转换与错误处理(coerce + dropna)
- 空值填充:asfreq(‘D’, fill_value=0) 确保连续时间序列
变点检测(增强 CUSUM)
- 创新点:
- 双重平滑:滚动窗口平均(7 天)+ 指数加权均值(span=5)
- 双向检测:同时监控正向突变(异常增长)与负向突变
- 动态阈值:取 CUSUM 值的 95 百分位数与固定阈值 5 的较大值
- 比率验证:min_ratio=1.5 确保变化幅度显著
隔离能力计算
- 数学原理:KL 散度衡量候选组合分布与全局分布的差异
- 健壮性处理:
- 对齐时间索引:reindex + 前/后向填充避免零值
- 概率平滑:clip 防止除零错误,1e-5 数值稳定性
排名得分计算
- 核心公式:R = p_a * log(p_a / p_b) # p_a: 变点后概率, p_b: 变点前概率
- 特殊处理:
- 新生模式激励:变点前无数据时用增长量直接评估
- 分母保护:全局基线概率添加 1e-5 防止除零
- 边界控制:限制得分范围 [-100, 100] 避免数值爆炸
iDice 主流程
- 流程控制:
- 数据预处理:时间字段标准化与排序
- 全局基线:按日聚合的全局计数序列
- 候选生成:Impact 剪枝获取初筛组合
- 逐候选分析:时间序列构建 → 变点检测 → 指标计算
- 结果过滤:隔离能力阈值 + 有效 R 值筛选
- 排序去重:堆排序取 TopN,字符串化组合去重
关键优化策略
- 性能优化:
- 向量化操作:替代循环(如布尔矩阵过滤)
- 滚动窗口计算:替代逐点遍历
- 内存管理:FP-Growth 处理加权事务的扩展存储
- 稳定性增强:
- 异常捕获:关键计算环节的 try-except 块
- 数值平滑:ewm 替代简单平均,clip 控制极端值
- 空值处理:多重校验(空序列、零分母等)
潜在改进方向
- 计算效率:
- 并行化候选组合处理
- 增量式 FP-Growth 应对大数据
- 算法增强:
- 自适应阈值调整(如动态 ip_threshold)
- 多变量变点检测(MVCUSUM)
- 工程化:
- 结果持久化存储
- 实时流处理支持
该代码实现了从数据预处理到异常模式挖掘的完整流水线,结合了频繁模式挖掘、时间序列分析与信息论指标,适合电商、物联网等场景的突变根因分析。
代码使用说明
如何合理的设置 support_threshold 和 ip_threshold?
support_threshold 的设置逻辑
- 核心作用:控制候选组合的生成粒度,过滤低频噪声。
- 动态参考依据:
- 数据规模:建议初始值为总事务数的 1%~1%。例如总事务数为 10 万时,可设置 support_threshold=100~1000,随后根据候选数量调整。
- 模式敏感性:若需捕捉低频细粒度模式,适当降低(如 support_threshold=20~50);若面向宏观分析,则提高(如 support_threshold=500+)。
- 算法容忍度:运行过程中观测候选数量(Impact 剪枝后候选数量日志),一般以 1,000~5,000 候选为宜。
- 经验公式:support_threshold = max(50, total_transactions * 0.001)
ip_threshold 的设置逻辑
- 核心作用:过滤分布变化不显著的组合,保留强隔离性模式。
- 动态调参策略:
- 初步实验:运行全量数据后统计有效结果的 ip_score 分位数,取 25%~50% 分位作为初始阈值。
- 业务场景:质量根因分析等严格场景选较高阈值(如 ip_threshold=0.3~0.5);探索性分析场景选较低阈值(如 ip_threshold=0.05~0.1)。
- 灵敏度测试:逐步增大阈值,观察 R 得分 Top 结果的稳定性,选择拐点值。
如何理解支持度、隔离能力、R 得分等多维度指标?
支持度(Support)
- 计算逻辑:候选组合在全量数据中的出现频次(support * total_transactions)
- 物理意义:反映模式的泛化能力,支持度越高说明该组合覆盖的场景越普遍。例如 support=500 表示该属性组合在数据中出现了 500 次。
- 使用场景:避免过度关注长尾偶发模式,优先分析高频组合的显著性变化。
隔离能力(IPScore)
- 计算逻辑:候选组合在变点前后的分布变化与全局分布变化的 KL 散度差异。
- 物理意义:度量该组合的局部变化与全局变化的偏离程度。IP 值越大,说明组合的异常变化越独立于整体趋势。
- 典型表现:若某省流量突增而全国趋势平稳,则其 ip_score 显著偏高。
R 得分(RScore)
- 计算逻辑:基于变点前后候选组合与全局的占比变化,进行对数似然比校正。
- 物理意义:综合衡量变化的绝对幅度和相对显著性,是方向敏感的增长异常评分。
- 关键特性:
- 对新生模式(变点前无数据)的 p_b->0 施加策略性激励。
- 采用对数压缩避免极端值干扰,得分范围为 [-100, 100],高于 1 即有实际意义。
指标联合分析示例
高R+适中IP显著增长但偏离整体趋势可能是新型业务增长,需结合业务解读
| 指标 | 高低组合场景 | 业务指导建议 |
| 高 Support + 高 R | 高频核心链路异常 | 立即告警,需首要定位系统性故障 |
| 低 Support + 高 IP | 低频长尾属性突发变动 | 排查局部配置变更或定向攻击 |
代码与iDice论文的对比分析
总结来看,用户代码在逻辑上遵循了iDice论文的核心思想,实现了三层剪枝,并在测试用例中验证了有效性。虽然某些实现细节可能与论文中的方法有所不同(如使用FP-Growth代替论文中的方法,或使用CUSUM代替PST),但整体流程和目标是正确的,能够达到检测新兴问题的目的。
核心逻辑一致性验证
| 论文模块 | 代码实现 | 一致性评估 |
| Impact-based Pruning | 使用FP-Growth挖掘频繁项集,考虑count加权 | ✅正确,但论文使用闭合项集剪枝,代码通过fpgrowth参数控制,需确认闭合性 |
| Change Detection | 改进的CUSUM算法(双向检测+平滑处理) | ⚠️论文使用概率后缀树(PST),代码方法不同但目标一致,属合理替代 |
| Isolation Power | KL散度衡量分布差异 | ⚠️论文未明确公式,但隔离能力定义一致,KL散度是合理实现 |
| Ranking Score | 严格实现R=p_a*ln(p_a/p_b) | ✅完全一致 |
| 三层剪枝流程 | Impact→Change→Isolation顺序执行 | ✅完全一致 |
关键改进点与差异说明
Impact-based Pruning优化
- 论文方法:基于闭合项集的暴力枚举+支持度剪枝
- 代码实现:使用FP-Growth算法+加权事务扩展
- 优势:
- 时间复杂度从O(2^N)降至O(N),适合大规模数据
- 通过extend([items]*count)实现加权,更贴近实际事件频次
- 潜在问题:
- 需确认fpgrowth是否生成闭合项集(需设置max_len=len(attr_cols))
变点检测增强
- 论文方法:概率后缀树(PST)建模序列模式
- 代码实现:双向CUSUM控制图+滚动平滑
- 优势:
- 鲁棒性更强(处理噪声数据)
- 支持双向检测(突增/突降)
- 差异影响:
- 可能检测到论文方法未覆盖的变点类型,但目标一致
隔离能力计算
- 论文方法:未明确公式,强调”候选组合在变点后集中出现”
- 代码实现:KL散度量化候选与全局分布的差异
- 合理性:
- KL散度自然衡量两个分布的差异,符合隔离能力定义
- 通过阈值ip_threshold过滤低差异组合
工程化增强
- 时间序列对齐:reindex(ts.index, fill_value=0)处理缺失时间点
- 边界条件处理:
- 变点后数据点不足的过滤(sum(post_period)<2)
- R值计算的异常值截断(max(min(r_score,100),-100))
- 去重机制:seen集合去除重复组合模式
参考链接:


