时序分析(Time Series Analysis)是一种统计方法,用于分析按时间顺序排列的一系列数据点。其主要目的是识别数据中的模式,如趋势、周期性和季节性变化,以便进行预测和解释。时序分析在金融、经济学、气象学、库存管理等领域有广泛应用,用于预测股票价格、经济指标、天气变化和产品需求等。
Python 自带的时间处理模块
在 Python 中,datetime 和 time 是两个用于处理日期和时间的标准库模块。它们提供了多种方法和类来操作和格式化时间和日期。
datetime 模块
datetime 模块是一个功能强大的模块,用于处理日期和时间。它提供了以下几个主要的类:
- datetime:用于表示日期和时间的组合。它包括年、月、日、小时、分钟、秒、微秒等信息。
- 创建一个 datetime 对象:datetime(year, month, day, hour, minute, second, microsecond)
- 获取当前日期和时间:datetime.now()
- 格式化日期和时间:strftime() 方法
- date:仅表示日期(年、月、日)。
- 创建一个 date 对象:date(year, month, day)
- 获取当前日期:date.today()
- time:仅表示时间(小时、分钟、秒、微秒)。
- 创建一个 time 对象:time(hour, minute, second, microsecond)
- timedelta:表示两个日期或时间之间的时间差。
- 创建一个时间差对象:timedelta(days, seconds, minutes, hours, weeks)
time 模块
time 模块提供了与时间相关的各种函数,主要用于处理时间戳(自 1970 年 1 月 1 日以来的秒数)。
- time():返回当前时间的时间戳。
- sleep(seconds):推迟调用线程的运行,休眠指定的秒数。
- ctime([secs]):将时间戳转换为可读的时间字符串。如果不提供 secs 参数,默认使用当前时间。
- strftime(format[, t]):格式化时间为字符串,根据指定的格式。t 是一个时间元组(类似 struct_time 对象),默认使用当前时间。
- strptime(string, format):将格式化的时间字符串解析为时间元组。
- localtime([secs]):将时间戳转换为当前时区的 struct_time 对象。
- gmtime([secs]):将时间戳转换为 UTC 时区的 struct_time 对象。
总结:
- 使用 datetime 模块时,通常更适合需要处理复杂的日期和时间运算的场景,比如需要支持时区、日期加减等。
- 使用 time 模块时,通常用于简单的时间戳操作和需要与系统时间进行交互的场景。
更多详细内容可以查看:Python 日期与时间处理详解
Pandas 时间序列基础知识
时间戳 (Timestamp)
在 Pandas 中,Timestamp 是一个用于表示单个时间点的对象,类似于 Python 的原生 datetime.datetime 对象,但提供了更丰富的功能和更好的性能。Timestamp 是 Pandas 处理时间序列数据的核心组件之一。
Pandas 中的时间戳和 Unix 时间戳都是用于表示时间点的概念,但它们在表达方式和用途上有一些差异。以下是它们的主要区别:
Pandas 时间戳
- 定义:
- Pandas 时间戳是 Timestamp 对象,用于表示特定的时间点。
- 它是 Pandas 中处理时间序列数据的基础。
- 特性:
- 具有更高的精度,可以表示到纳秒级。
- 支持时区信息,可以进行时区转换。
- 兼容性:Timestamp 对象与 Python 的 datetime 对象和 NumPy 的 datetime64 对象兼容,可以很方便地进行相互转换。
- 提供丰富的方法和属性,例如 year、month、day、hour 等,方便提取日期和时间组件。
使用示例:
import pandas as pd
# 创建 Timestamp
# 从字符串创建:
ts = pd.Timestamp('2023-10-01 12:00:00')
print("Timestamp from string:", ts)
# 从日期时间组件创建:
ts = pd.Timestamp(year=2023, month=10, day=1, hour=12, minute=0, second=0)
print("Timestamp from components:", ts)
# 从时间戳(秒)创建:
ts = pd.Timestamp(1696152000, unit='s')
print("Timestamp from timestamp:", ts)
# 获取日期和时间信息:
print("Year:", ts.year)
print("Month:", ts.month)
print("Day:", ts.day)
print("Hour:", ts.hour)
print("Minute:", ts.minute)
print("Second:", ts.second)
# 时区处理:
# 设置时区
ts_utc = ts.tz_localize('UTC')
print("UTC Timestamp:", ts_utc)
# 转换时区
ts_ny = ts_utc.tz_convert('America/New_York')
print("New York Timestamp:", ts_ny)
# 时间运算:
# 加减时间
new_ts = ts + pd.Timedelta(days=1, hours=2)
print("Time after addition:", new_ts)
# 时间差
delta = new_ts - ts
print("Time difference:", delta)
# 格式化和转换:
# 格式化输出
formatted_str = ts.strftime('%Y-%m-%d %H:%M:%S')
print("Formatted Timestamp:", formatted_str)
# 转换为不同格式
dt_object = ts.to_pydatetime()
print("Converted to datetime:", dt_object)
Unix 时间戳
定义:
- Unix 时间戳是一个整数或浮点数,表示自 1970 年 1 月 1 日(称为 Unix 纪元)以来的秒数。
- 常用于系统级时间表示和计算。
特性:
- 通常以秒或毫秒为单位,不直接支持更高的精度。
- 没有内置的时区信息,仅表示一个绝对时间点。
- 由于其简单的整数或浮点表示,常用于存储和传输。
使用示例:
import time # 获取当前时间的 Unix 时间戳 unix_timestamp = time.time() print(unix_timestamp) # 将 Unix 时间戳转换为 Pandas 时间戳 ts_from_unix = pd.to_datetime(unix_timestamp, unit='s') print(ts_from_unix) # 转换 Pandas 时间戳到 Unix 时间戳 unix_timestamp = ts.timestamp() print(unix_timestamp) # 转换 Unix 时间戳到 Pandas 时间戳 ts_from_unix = pd.to_datetime(unix_timestamp, unit='s') print(ts_from_unix)
总结
-
- Pandas 时间戳提供了更高的精度和丰富的功能,适合数据分析和处理。
- Unix 时间戳更简单,适合存储和跨系统传输。
- 两者可以互相转换,以满足不同的应用需求。
时间间隔(Period)
在 Pandas 中,时间间隔(Period)是一种用于表示固定长度时间段的数据结构。它非常适合用于处理周期性数据,如按年、季度、月、周等频率的时间序列数据。
Period 对象表示一个固定的时间周期,具有以下特性:
- 时间频率:每个 Period 都有一个频率(freq),表示周期的单位,如年度(’A’)、季度(’Q’)、月(’M’)、日(’D’)等。
- 时间段表示:Period 表示一个时间段,而不是一个具体的时间点。例如,Period(‘2023-01′, freq=’M’) 表示整个 2023 年 1 月。
创建 Period
# 创建单个 Period import pandas as pd # 创建一个表示 2023 年 3 月的 Period 对象 period_month = pd.Period('2023-03', freq='M') print(period_month) # 输出: 2023-03 # 创建一个表示 2023 年的 Period 对象 period_year = pd.Period('2023', freq='Y') print(period_year) # 输出: 2023Period 的属性和方法
属性:
- start_time:返回 Period 的开始时间。
- end_time:返回 Period 的结束时间。
- freq:返回 Period 的频率。
print(period_month.start_time) # 输出: 2023-03-01 00:00:00 print(period_month.end_time) # 输出: 2023-03-31 23:59:59.999999999 print(period_month.freq) # 输出: M
方法:
- asfreq():转换 Period 的频率。
- to_timestamp():将 Period 转换为时间戳。
# 将月频率的 Period 转换为日频率 daily_period = period_month.asfreq('D') print(daily_period) # 将 Period 转换为时间戳 timestamp = period_month.to_timestamp() print(timestamp) # 输出: 2023-03-01 00:00:00时间算术运算
Period 对象支持加减运算,可以用于时间段的计算。
# 增加一个月 next_month = period_month + 1 print(next_month) # 输出: 2023-04 # 减少一个月 previous_month = period_month - 1 print(previous_month) # 输出: 2023-02
重采样与聚合
Period 可以用于重采样和聚合操作,例如将数据从日频率聚合到月频率。
# 假设我们有一个日期时间索引的数据 date_rng = pd.date_range('2023-01-01', periods=100, freq='D') ts_data = pd.Series(range(len(date_rng)), index=date_rng) # 将数据重采样为月频率 monthly_data = ts_data.to_period('M').groupby(level=0).sum() print(monthly_data)总结
- Period 是处理周期性数据的强大工具,适合按固定频率分析数据。
- 提供了丰富的属性和方法,支持频率转换和时间算术运算。
- 与 Timestamp 互相转换,以满足不同分析需求。
时间间隔(Timedelta)
在 Pandas 库中,Timedelta 是一个非常有用的数据类型,主要用于表示两个日期或时间之间的差值。它能够处理日期、时间间隔的加减运算,并且提供了多种方法来操作和转换这些间隔。
创建 Timedelta 对象
你可以通过以下几种方式创建 Timedelta 对象:
import pandas as pd # 直接使用 pd.Timedelta 构造函数: td = pd.Timedelta(days=3, hours=4, minutes=5, seconds=6) # 使用字符串: td_str = pd.Timedelta('3 days 4 hours 5 minutes 6 seconds') # 使用其他时间单位: weeks, days, hours, minutes, seconds, milliseconds, microseconds, nanoseconds基本属性
Timedelta 对象有一些基本属性可以访问其组成部分:
- days: 表示天数。
- seconds: 表示秒数。
- microseconds: 表示微秒数。
- nanoseconds: 表示纳秒数。
- components: 返回一个 TimedeltaComponents 对象,其中包含更详细的分量信息。
加减操作
你可以对 Timedelta 对象执行加减操作,包括与日期或时间戳的加减:
import pandas as pd td = pd.Timedelta('3 days 4 hours 5 minutes 6 seconds') date = pd.Timestamp('2023-01-01') # 加法 new_date = date + td print(new_date) # 减法 new_date = date - td print(new_date)与其他 Timedelta 的操作
可以进行加减操作以计算总的时间间隔:
td1 = pd.Timedelta('3 days') td2 = pd.Timedelta('2 days 5 hours') result = td1 + td2 print(result) # 输出: 5 days 05:00:00乘除运算
可以使用整数对 Timedelta 进行乘除运算:
td = pd.Timedelta('3 days') print(td * 2) # 输出: 6 days 00:00:00 print(td / 2) # 输出: 1 days 12:00:00应用示例
假设你有一个包含日期的 DataFrame,并希望计算每个日期与当前日期之间的天数差异:
import pandas as pd data = {'date': ['2023-01-01', '2023-01-02', '2023-01-03']} df = pd.DataFrame(data) df['date'] = pd.to_datetime(df['date']) today = pd.Timestamp('today') df['days_since_today'] = (today - df['date']).dt.days print(df)DatetimeIndex:用于索引时间序列数据。
DatetimeIndex是Pandas中专门用于时间序列数据的索引类型。它是一个特殊的Index对象,专门设计用于存储和操作时间戳数据。DatetimeIndex在时间序列数据的处理、分析和可视化中扮演着重要角色。
特性和优势
- 高效的时间序列操作:DatetimeIndex允许对时间序列数据进行快速高效的切片、索引和聚合操作。
- 丰富的时间属性:提供了一系列属性来提取年、月、日、小时、分钟、秒、星期几、季度等信息。
- 时区支持:内置对时区的支持,能够轻松进行时区转换。
- 频率管理:支持设置频率(如日、月、年、业务日等),方便进行时间序列的重采样和频率转换。
创建DatetimeIndex
DatetimeIndex可以通过多种方式创建:
# 从日期范围创建: import pandas as pd # 创建一个日期范围 date_range = pd.date_range(start='2023-01-01', end='2023-01-10', freq='D') print("DatetimeIndex from date range:", date_range) # 从列表或数组创建: # 从日期列表创建 dates = ['2023-01-01', '2023-01-02', '2023-01-03'] datetime_index = pd.DatetimeIndex(dates) print("DatetimeIndex from list:", datetime_index) # 从时间戳创建: timestamps = [1672531200, 1672617600, 1672704000] # Unix timestamps datetime_index = pd.to_datetime(timestamps, unit='s') print("DatetimeIndex from timestamps:", datetime_index)使用 DatetimeIndex
# 时间序列索引: # 创建一个带有DatetimeIndex的Series ts = pd.Series([1, 2, 3], index=datetime_index) print("Time series with DatetimeIndex:", ts) # 基于时间的切片 print("Slice by date:", ts['2023-01-02':'2023-01-03']) # 提取时间信息: print("Year:", datetime_index.year) print("Month:", datetime_index.month) print("Day:", datetime_index.day) print("Weekday:", datetime_index.weekday)时区处理:
# 设置时区 datetime_index_utc = datetime_index.tz_localize('UTC') print("DatetimeIndex with UTC timezone:", datetime_index_utc) # 转换时区 datetime_index_ny = datetime_index_utc.tz_convert('America/New_York') print("DatetimeIndex converted to New York timezone:", datetime_index_ny)频率和重采样:
# 生成一个带频率的DatetimeIndex date_range = pd.date_range(start='2023-01-01', periods=5, freq='B') # Business day frequency print("DatetimeIndex with frequency:", date_range) # 重采样 ts_resampled = ts.resample('2D').sum() print("Resampled time series:", ts_resampled)PeriodIndex:用于索引周期性数据。
PeriodIndex是Pandas库中专门用于处理周期性时间数据的索引类型。与DatetimeIndex不同,PeriodIndex表示一系列的时间周期(Period),如年、季度、月、日等,而不是具体的时间点。PeriodIndex在处理需要按周期分析的数据时非常有用,例如财务季度报告、年度数据等。
创建 PeriodIndex
PeriodIndex可以通过多种方式创建:
# 从日期范围创建: import pandas as pd # 创建一个从2023年1月到2023年12月的月度周期索引 period_index = pd.period_range(start='2023-01', end='2023-12', freq='M') print("Monthly PeriodIndex:", period_index) # 从列表或数组创建: # 从字符串列表创建 period_index_from_list = pd.PeriodIndex(['2023-01', '2023-02', '2023-03'], freq='M') print("PeriodIndex from list:", period_index_from_list) # 通过to_period方法: # 将DatetimeIndex转换为PeriodIndex datetime_index = pd.date_range(start='2023-01-01', periods=3, freq='D') period_index_from_datetime = datetime_index.to_period('M') print("PeriodIndex from DatetimeIndex:", period_index_from_datetime)使用 PeriodIndex
作为数据索引:PeriodIndex可以用作Pandas数据结构(如Series和DataFrame)的索引,便于周期性数据的存储和检索。
# 创建一个带有PeriodIndex的Series period_series = pd.Series([1, 2, 3], index=period_index_from_list) print("Period Series:", period_series) 时间序列操作:PeriodIndex支持多种时间序列操作,如频率转换、周期移动等。 # 将PeriodIndex转换为季度 quarterly_index = period_index.asfreq('Q') print("Quarterly PeriodIndex:", quarterly_index) # 移动周期 shifted_period = period_index.shift(1) print("Shifted PeriodIndex:", shifted_period)访问周期属性:可以访问周期的开始时间、结束时间、年、月、季度等信息。
print("Start time of periods:", period_index.start_time) print("End time of periods:", period_index.end_time) print("Year of periods:", period_index.year) print("Month of periods:", period_index.month)TimedeltaIndex:用于索引时间差
TimedeltaIndex是Pandas中的一种索引类型,用于处理时间间隔序列。它是基于Timedelta对象的索引,允许你在时间间隔数据上进行复杂的时间序列分析和操作。TimedeltaIndex可以用于创建、操作和管理一系列时间间隔,尤其在时间序列数据处理中非常有用。
创建TimedeltaIndex
你可以通过多种方式创建TimedeltaIndex:
import pandas as pd # 从列表或数组创建: td_index = pd.TimedeltaIndex(['1 days', '2 days', '3 days']) # 使用pd.to_timedelta函数: td_index = pd.to_timedelta(['1 days', '2 days', '3 days']) # 通过算术运算生成: td_index = pd.date_range('2023-01-01', periods=3) - pd.Timestamp('2023-01-01')属性和方法
TimedeltaIndex具有许多有用的属性和方法:
属性:
- days, seconds, microseconds, nanoseconds: 获取时间间隔的各个组成部分。
- components: 返回一个DataFrame,显示时间间隔的各个组成部分。
方法:
- min(), max(): 获取最小和最大的时间间隔。
- sum(): 获取所有时间间隔的总和。
- mean(): 计算时间间隔的平均值。
- total_seconds(): 返回时间间隔的总秒数。
使用 TimedeltaIndex 进行数据索引
假设你有一个DataFrame,其中的索引是时间间隔:
import pandas as pd data = [10, 20, 30] td_index = pd.TimedeltaIndex(['1 days', '2 days', '3 days']) df = pd.DataFrame(data, index=td_index, columns=['value']) print(df)
计算时间间隔的总和
total_duration = df.index.sum() print(total_duration)
过滤数据
你可以使用条件来过滤基于时间间隔的数据:
filtered_df = df[df.index > pd.Timedelta('1 days')] print(filtered_df)时间频率(Freq)
在Pandas中,freq参数用于指定时间序列数据的频率。Pandas提供了一系列频率字符串(frequency strings),用于表示不同的时间间隔。以下是常用的频率字符串及其含义:
基本频率
- B:Business day frequency(工作日频率)
- C:Custom business day frequency(自定义工作日频率)
- D:Calendar day frequency(日历日频率)
- W:Weekly frequency(每周频率),默认从周日开始
月度和年度频率
- M:Month end frequency(月末频率)
- MS:Month start frequency(月初频率)
- Q:Quarter end frequency(季度末频率)
- QS:Quarter start frequency(季度初频率)
- A or Y:Year end frequency(年度末频率)
- AS or YS:Year start frequency(年度初频率)
财务年度频率
- Q-DEC:Quarter end frequency with fiscal year ending in December(财政年度季度末频率,12月结束)
- DEC:Year end frequency with fiscal year ending in December(财政年度末频率,12月结束)
小时和分钟频率
- H:Hourly frequency(每小时频率)
- T or min:Minutely frequency(每分钟频率)
秒和更高精度频率
- S:Secondly frequency(每秒频率)
- L or ms:Millisecond frequency(每毫秒频率)
- U or us:Microsecond frequency(每微秒频率)
- N:Nanosecond frequency(每纳秒频率)
组合频率
可以通过整数与基本频率组合来表示多个时间单位。例如:
- 5D:每五天
- 10T:每十分钟
其他频率
- BM:Business month end frequency(工作月末频率)
- BMS:Business month start frequency(工作月初频率)
- BQ:Business quarter end frequency(工作季度末频率)
- BQS:Business quarter start frequency(工作季度初频率)
- BA or BY:Business year end frequency(工作年度末频率)
- BAS or BYS:Business year start frequency(工作年度初频率)
这些频率字符串可以用于生成时间序列数据、重采样数据、转换数据频率等操作。例如,使用pd.date_range()或pd.period_range()时,可以通过freq参数指定时间序列的频率。选择合适的频率有助于更准确地处理和分析时间序列数据。
时间序列创建与转换
使用 pd.to_datetime() 将字符串转换为 Datetime
pd.to_datetime()是Pandas中一个非常强大的函数,用于将各种格式的日期和时间数据转换为Pandas的Timestamp对象。这是进行时间序列分析和处理的基础步骤之一。该函数能够处理多种输入格式,包括字符串、数值、日期时间对象等,并将其标准化为Pandas的日期时间格式。
主要功能
pd.to_datetime()可以处理以下类型的输入:
import pandas as pd # 字符串格式的日期和时间: date_str = "2023-10-15" date = pd.to_datetime(date_str) # 列表或数组: date_list = ["2023-10-15", "2023-10-16", "2023-10-17"] dates = pd.to_datetime(date_list) # Pandas Series: date_series = pd.Series(["2023-10-15", "2023-10-16", "2023-10-17"]) dates = pd.to_datetime(date_series) # 数值格式的日期: 可以将Unix时间戳(秒或毫秒)转换为日期。 timestamp = 1634160000 date = pd.to_datetime(timestamp, unit='s')
常用参数
- format: 指定日期字符串的格式,以提高解析效率。例如,format=”%Y-%m-%d”。
- errors: 指定错误处理方式。可以是’raise’(默认),’coerce’(将无法解析的值设置为 NaT),或 ‘ignore’(返回原始输入)。
- unit: 当输入是整数或浮点数时,指定其单位,比如’s’(秒),’ms’(毫秒)。
- utc: 如果为True,则返回UTC时区的时间。
- dayfirst: 当日期字符串格式不明确时,如果为True,将优先将第一个数字解析为日。
- yearfirst: 当日期字符串格式不明确时,如果为True,将优先将第一个数字解析为年。
# 解析不同格式的日期 date_str = "15-10-2023" date = pd.to_datetime(date_str, dayfirst=True) print(date) # 处理错误 date_list = ["2023-10-15", "not_a_date", "2023-10-17"] dates = pd.to_datetime(date_list, errors='coerce') print(dates) # 处理Unix时间戳 timestamps = [1634160000, 1634246400, 1634332800] dates = pd.to_datetime(timestamps, unit='s') print(dates)
使用 pd.date_range() 创建时间范围
pandas.date_range是Pandas库中用于生成日期时间序列的函数。它能够创建一个DatetimeIndex对象,包含一个指定频率和范围的时间序列。date_range是处理时间序列数据的基础工具,尤其在需要生成规则的时间序列时非常有用。
date_range 的参数
date_range函数提供了多种参数,允许用户灵活地生成所需的日期时间序列:
- start:序列的开始日期时间,可以是字符串或datetime对象。
- end:序列的结束日期时间,可以是字符串或datetime对象。
- periods:生成的时间点数量。如果指定了此参数,则end参数会被忽略。
- freq:时间序列的频率。默认是’D’(每日)。常用频率包括:
- tz:时区信息,可以是时区名称(如’Asia/Shanghai’)或pytz时区对象。
- normalize:布尔值,如果为True,则将时间序列中的时间部分标准化为午夜。
- name:为生成的DatetimeIndex指定一个名称。
- closed:指定是否包含开始或结束时间点,选项有’left’、’right’或None。
以下是一些常见的date_range用法示例:
import pandas as pd # 生成每日时间序列: # 从2023年1月1日到2023年1月10日的每日时间序列 dates = pd.date_range(start='2023-01-01', end='2023-01-10') print("Daily date range:", dates) # 指定周期数: # 从2023年1月1日开始,生成5个时间点,每个时间点间隔一周 dates = pd.date_range(start='2023-01-01', periods=5, freq='W') print("Weekly date range with 5 periods:", dates) # 使用时区: # 生成带有时区信息的时间序列 dates = pd.date_range(start='2023-01-01', periods=3, freq='D', tz='UTC') print("Date range with timezone:", dates) # 生成每小时的时间序列: # 从2023年1月1日开始,生成一天内每小时的时间序列 dates = pd.date_range(start='2023-01-01', periods=24, freq='H') print("Hourly date range:", dates) # 使用closed参数: # 从2023年1月1日到2023年1月10日的每日时间序列,排除结束日期 dates = pd.date_range(start='2023-01-01', end='2023-01-10', closed='left') print("Closed date range:", dates)使用 pd.period_range() 创建周期范围
pd.period_range()是Pandas中用于创建周期范围(PeriodRange)的函数。它生成一个PeriodIndex对象,该对象表示一系列等间隔的时间周期。与pd.date_range()类似,但pd.period_range()返回的是时间周期而不是时间点。这对于需要处理固定时间间隔的数据分析非常有用,例如月度、季度或年度数据。
基本用法
pd.period_range(start=None, end=None, periods=None, freq=None, name=None)
参数说明
- start: 起始时间点,字符串或Period 对象。定义周期范围的开始。
- end: 结束时间点,字符串或Period 对象。定义周期范围的结束。
- periods: 生成的周期数。如果指定了start 或 end,则需要提供此参数以确定范围的长度。
- freq: 频率字符串,例如’D’(天)、’M’(月)、’Q’(季度)、’A’(年)等。定义周期的间隔。
- name: 为生成的PeriodIndex 指定一个名称。
import pandas as pd # 创建月度周期范围 # 创建从2023年1月到2023年6月的月度周期 period_range = pd.period_range(start='2023-01', end='2023-06', freq='M') print(period_range) # 创建指定数量的周期 # 创建从2023年1月开始的5个季度周期 period_range = pd.period_range(start='2023-01', periods=5, freq='Q') print(period_range) # 使用不同的频率 # 创建从2023年1月1日到2023年1月10日的日度周期 period_range = pd.period_range(start='2023-01-01', end='2023-01-10', freq='D') print(period_range)
注意事项
- period_range()与 pd.date_range() 类似,但它返回的是 PeriodIndex,而不是 DatetimeIndex。
- PeriodIndex可以进行加减运算、频率转换等操作,支持丰富的时间序列功能。
频率字符串(freq)的选择应与数据的实际时间间隔相匹配,以确保分析的准确性。
时间序列索引与切片
在Pandas中,时间序列索引和切片是处理和分析时间序列数据的关键技术。利用时间序列索引和切片,可以方便地按时间维度来管理和访问数据。这种能力对于时间序列数据的探索、分析和可视化都非常重要。下面详细介绍基于时间戳的索引和切片、如何使用loc和iloc进行切片,以及部分字符串匹配的支持。
基于时间戳的索引和切片
时间戳(Timestamp)是Pandas时间序列数据的基本单位。当时间序列数据以时间戳作为索引时,可以通过时间戳来快速索引和切片。
创建一个时间序列DataFrame
import pandas as pd
# 创建一个示例DataFrame
data = {
'value': [10, 20, 30, 40, 50]
}
dates = pd.date_range('2023-01-01', periods=5, freq='D')
df = pd.DataFrame(data, index=dates)
print(df)
基于时间戳的单点索引
# 选择特定日期的数据 print(df.loc['2023-01-02'])
基于时间戳的范围切片
# 选择一个时间范围内的数据 print(df.loc['2023-01-02':'2023-01-04'])
使用 loc 和 iloc 进行切片
- loc: 基于标签(这里是时间戳)进行索引和切片。它可以处理时间戳和部分字符串匹配。
- iloc: 基于整数位置进行索引和切片,适用于不依赖标签的情况。
使用 loc 进行切片
loc允许基于标签的切片,尤其适用于时间序列数据。
# 选择特定日期的数据 print(df.loc['2023-01-02']) # 选择一个时间范围内的数据 print(df.loc['2023-01-02':'2023-01-04'])
使用 iloc 进行切片
iloc适用于按整数位置进行切片。
# 选择前两行数据 print(df.iloc[:2]) # 选择特定位置的数据 print(df.iloc[1])
Pandas提供了强大的部分字符串匹配功能,允许按年、月、日等粒度进行切片。这在处理大型时间序列数据集时非常有用。
按年进行切片
# 选择2023年的数据 print(df.loc['2023'])
按月进行切片
# 选择2023年1月的数据 print(df.loc['2023-01'])
按日进行切片
# 选择特定日期的数据 print(df.loc['2023-01-01'])
注意事项
- 确保你的时间数据已经转换为DatetimeIndex,这对于时间戳索引和切片至关重要。
- 使用to_datetime() 函数将日期列转换为时间戳格式。
- 当进行切片时,Pandas会自动处理时区信息,但需要确保时区一致性。
时间序列运算
时间序列运算在数据分析中扮演着重要角色,尤其是在金融、经济、气象等领域。Pandas提供了丰富的功能来处理时间序列数据的运算,包括算术运算、时间对齐和合并,以及数据移位等操作。
时间序列数据的算术运算
时间序列数据的算术运算与普通的Pandas数据运算类似,但它们会自动对齐时间索引,这使得处理具有不同时间范围的数据更加方便。
import pandas as pd
import numpy as np
# 创建两个时间序列
dates = pd.date_range('2023-01-01', periods=5, freq='D')
ts1 = pd.Series([1, 2, 3, 4, 5], index=dates)
ts2 = pd.Series([5, 4, 3, 2, 1], index=dates)
# 执行算术运算
sum_series = ts1 + ts2
diff_series = ts1 - ts2
product_series = ts1 * ts2
quotient_series = ts1 / ts2
print("Sum:\n", sum_series)
print("Difference:\n", diff_series)
print("Product:\n", product_series)
print("Quotient:\n", quotient_series)
时间对齐和合并
时间对齐是指在执行算术运算时,Pandas会根据时间索引自动对齐数据。对于两个时间序列,如果它们的索引不完全一致,Pandas会自动插入缺失值(NaN)以确保索引对齐。
# 创建两个不完全对齐的时间序列
dates1 = pd.date_range('2023-01-01', periods=3, freq='D')
dates2 = pd.date_range('2023-01-02', periods=3, freq='D')
ts1 = pd.Series([1, 2, 3], index=dates1)
ts2 = pd.Series([4, 5, 6], index=dates2)
# 时间对齐并进行运算
aligned_sum = ts1 + ts2
print("Aligned Sum:\n", aligned_sum)
使用shift()方法进行数据移位
shift()方法用于将数据在时间轴上移动。它可以用于计算变化率、创建滞后变量等。这在时间序列分析中非常有用,例如在金融分析中计算日收益率。
# 创建一个时间序列
dates = pd.date_range('2023-01-01', periods=5, freq='D')
ts = pd.Series([1, 2, 3, 4, 5], index=dates)
# 向前移位
shifted_forward = ts.shift(1)
print("Shifted Forward:\n", shifted_forward)
# 向后移位
shifted_backward = ts.shift(-1)
print("Shifted Backward:\n", shifted_backward)
# 计算变化率
daily_return = ts.pct_change()
print("Daily Return:\n", daily_return)
注意事项
- 在算术运算中,如果两个时间序列的索引不对齐,Pandas会引入NaN值,这可能需要进一步处理。
- 使用shift() 方法时,注意NaN值的引入,因为移位会导致边界上的数据缺失。
- 对于时间对齐,确保你了解数据的频率和时间戳的意义,以避免错误的对齐和分析。
使用offsets对时间进行偏移
Pandas中的offsets模块提供了一系列的时间偏移量类,用于表示和处理时间序列数据中的时间增量。时间偏移量可以理解为时间单位的抽象,用于在时间序列中进行加减操作。这些偏移量支持多种时间单位和复杂的频率规则,使得时间序列数据的处理更加灵活和强大。
常用的 offsets 类
Pandas的offsets模块中包含许多不同的时间偏移类,下面是一些常用的:
- DateOffset:基础类,其他偏移类都继承自它。
- Day(pd.offsets.Day):表示天数的偏移量。
- BusinessDay(pd.offsets.BDay):表示工作日的偏移量。
- Hour(pd.offsets.Hour):表示小时的偏移量。
- Minute(pd.offsets.Minute):表示分钟的偏移量。
- Second(pd.offsets.Second):表示秒的偏移量。
- MonthEnd(pd.offsets.MonthEnd):表示月末的偏移量。
- MonthBegin(pd.offsets.MonthBegin):表示月初的偏移量。
- YearEnd(pd.offsets.YearEnd):表示年末的偏移量。
- YearBegin(pd.offsets.YearBegin):表示年初的偏移量。
- Week(pd.offsets.Week):表示周的偏移量,可以指定起始的星期几。
使用示例
以下是一些使用Pandas offsets模块进行时间操作的示例:
# 简单时间偏移:
import pandas as pd
# 创建一个时间点
ts = pd.Timestamp('2023-01-01')
# 加上3天
new_ts = ts + pd.offsets.Day(3)
print("Original Timestamp:", ts)
print("After adding 3 days:", new_ts)
# 工作日偏移:
# 加上2个工作日
new_ts = ts + pd.offsets.BDay(2)
print("After adding 2 business days:", new_ts)
# 月末偏移:
# 下一个月末
new_ts = ts + pd.offsets.MonthEnd()
print("Next month end:", new_ts)
# 复杂偏移:
# 创建一个复合偏移
composite_offset = pd.offsets.MonthEnd() + pd.offsets.Day(10)
# 使用复合偏移
new_ts = ts + composite_offset
print("After composite offset (MonthEnd + 10 days):", new_ts)
# 频率字符串:
偏移量可以通过频率字符串在date_range等函数中使用:
# 每月的最后一个工作日
date_range = pd.date_range(start='2023-01-01', periods=3, freq='BM')
print("Date range with business month end:", date_range)
重采样与频率转换
重采样与频率转换是时间序列分析中的重要操作,它们允许你将时间序列数据从一个时间频率转换为另一个时间频率。这对于数据聚合、特征工程和时间序列建模都非常有用。Pandas提供了强大的工具来执行这些操作,主要包括resample()和asfreq()方法。
使用resample()方法进行重采样
resample()方法用于对时间序列数据进行重采样,能够将数据聚合到不同的时间频率。它支持多种聚合函数,如求和、平均、最大值、最小值等。
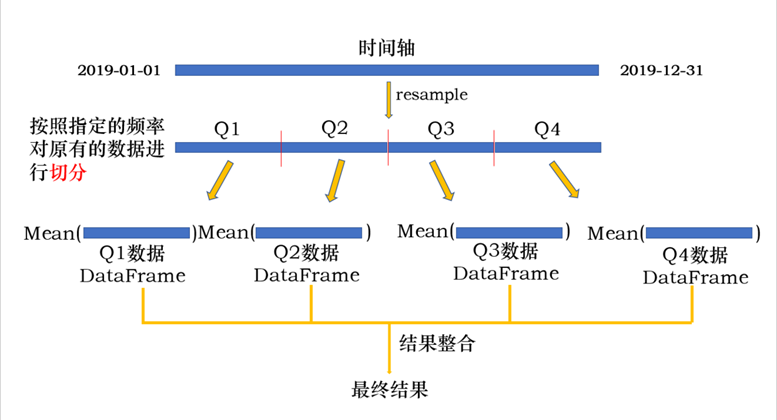
import pandas as pd
import numpy as np
# 创建一个示例时间序列
dates = pd.date_range('2023-01-01', periods=10, freq='D')
ts = pd.Series(np.random.randn(10), index=dates)
# 将数据从每日聚合到每周
weekly_resampled = ts.resample('W').sum()
print("Weekly Resampled:\n", weekly_resampled)
# 将数据从每日聚合到每月,取平均值
monthly_resampled = ts.resample('M').mean()
print("Monthly Resampled:\n", monthly_resampled)
重采样的频率:
- 日度:’D’
- 工作日:’B’
- 小时:’H’
- 分钟:’T’或 ‘min’
- 秒:’S’
- 毫秒:’L’
- 微秒:’U’
- 周:’W’
- 月:’M’
- 季度:’Q’
- 年:’A’
重采样的聚合函数:
- mean:计算平均值。
- sum:计算总和。
- first:取第一个值。
- last:取最后一个值。
- max:计算最大值。
- min:计算最小值。
- median:计算中位数。
- count:计算非空值的数量。
- std:计算标准差。
- var:计算方差。
- quantile:计算分位数。
- cumsum:计算累计和。
- ffill/ pad:前向填充。
- bfill/ backfill:后向填充。
- asfreq:仅调整频率,不进行聚合。
上采样和下采样的区别
- 下采样(Downsampling):将高频数据转换为低频数据。例如,将每日数据转换为每周或每月数据。通常需要聚合操作(如求和、平均)来填充较低频率的值。
- 上采样(Upsampling):将低频数据转换为高频数据。例如,将每月数据转换为每日数据。通常需要填充操作(如前向填充、后向填充)来填补较高频率的值。
# 下采样示例:
# 将数据从每日下采样到每周,求和
weekly_downsampled = ts.resample('W').sum()
print("Weekly Downsampled:\n", weekly_downsampled)
# 上采样示例:
# 创建一个每月的数据
dates = pd.date_range('2023-01-01', periods=3, freq='M')
ts_monthly = pd.Series([1, 2, 3], index=dates)
# 将数据上采样到每日,使用前向填充
daily_upsampled = ts_monthly.resample('D').ffill()
print("Daily Upsampled:\n", daily_upsampled)
使用 asfreq() 方法改变频率
asfreq()方法用于更改时间序列的频率,而不执行聚合或填充。它通常用于查看特定频率下的原始数据。
# 使用 asfreq() 改变频率为每日
daily_asfreq = ts.asfreq('D')
print("Daily As Freq:\n", daily_asfreq)
# 使用 asfreq() 改变频率为每周
weekly_asfreq = ts.asfreq('W')
print("Weekly As Freq:\n", weekly_asfreq)
注意事项
- 在下采样时,选择合适的聚合函数以确保数据的准确性。
- 在上采样时,选择适当的填充方法(如前向填充、后向填充)以避免引入偏差。
- 使用 asfreq() 时,注意它不会对数据进行聚合或填充,仅改变频率。
时间序列的处理与分析
时间序列的处理与分析在数据科学、金融、经济学等领域中非常重要。Pandas提供了丰富的工具来支持时间序列分析,其中包括滚动窗口计算、移动平均和指数加权函数。这些工具帮助我们识别时间序列数据中的趋势、波动和周期性特征。
滚动窗口计算(rolling())
滚动窗口计算是一种用于计算时间序列中某个窗口内统计量的技术。它通过在时间序列上滑动一个固定大小的窗口来计算每个位置上的统计值。
import pandas as pd
import numpy as np
# 创建一个示例时间序列
dates = pd.date_range('2023-01-01', periods=10, freq='D')
ts = pd.Series(np.random.randn(10), index=dates)
# 计算滚动窗口的和,窗口大小为3
rolling_sum = ts.rolling(window=3).sum()
print("Rolling Sum:\n", rolling_sum)
移动平均(rolling().mean())
移动平均是滚动窗口计算的一种特例,用于平滑时间序列数据,减少短期波动,突出长期趋势或周期。它通过计算窗口内数据的平均值来实现。
# 计算滚动窗口的平均值,窗口大小为3
moving_average = ts.rolling(window=3).mean()
print("Moving Average:\n", moving_average)
指数加权函数(ewm())
指数加权函数用于计算加权平均,其中较新的数据点赋予更大的权重。这种方法对于识别时间序列中的趋势和变化特别有用。
# 计算指数加权移动平均,指定衰减因子为0.5
ewm_average = ts.ewm(alpha=0.5).mean()
print("Exponentially Weighted Moving Average:\n", ewm_average)
注意事项
- 窗口大小: 滚动窗口的大小(window参数)会影响计算结果。较大的窗口会产生更平滑的曲线,但可能掩盖短期变化。
- 缺失值处理: 在计算滚动窗口和指数加权时,Pandas会自动处理窗口内的缺失值。
- 加权因子: 指数加权函数的加权因子(alpha)决定了新数据点的权重。较大的 alpha 会使新数据点对平均值的影响更大。
时间序列可视化
时间序列可视化是理解数据趋势、季节性和周期性的关键步骤。Pandas提供了内置的绘图功能,可以方便地绘制时间序列数据,并结合其他可视化库(如Matplotlib和Seaborn)来创建更复杂的图表。此外,通过对时间序列数据进行趋势、季节性和周期性分析,我们可以更深入地理解数据背后的模式。
使用 Pandas 内置的绘图功能(plot())
Pandas的DataFrame和Series类提供了plot()方法,可以直接绘制时间序列数据。这种方法简单快捷,适用于初步的数据探索。
import pandas as pd
import numpy as np
# 创建一个示例时间序列
dates = pd.date_range('2023-01-01', periods=100, freq='D')
ts = pd.Series(np.random.randn(100).cumsum(), index=dates)
# 绘制时间序列数据
ts.plot()
plt.show()
时间序列数据的趋势、季节性和周期性分析
时间序列数据通常包含趋势、季节性和周期性成分。通过分析这些成分,我们可以更好地理解数据的内在结构。
- 趋势(Trend) 趋势指的是时间序列数据随时间的变化方向,通常是长期的上升或下降。趋势分析可以帮助我们预测未来的发展方向。
- 季节性(Seasonality) 季节性是指数据中重复出现的周期性模式。例如,零售业的销售额通常在每年的某些月份会增加。
- 周期性(Cyclical) 周期性指的是数据中非季节性的长期波动。与季节性不同,周期性没有固定的周期长度,且通常与经济周期有关。
分解时间序列数据
使用时间序列分解的方法来分离趋势、季节性和随机成分。Pandas提供了seasonal_decompose函数来进行这一操作。
from statsmodels.tsa.seasonal import seasonal_decompose # 分解时间序列数据 result = seasonal_decompose(ts, model='additive') # 绘制分解后的结果 result.plot() plt.show()
结合其他可视化库
虽然Pandas的plot()方法提供了基本的绘图功能,但在更复杂的可视化需求下,可以结合Matplotlib或Seaborn来创建更复杂的图表。
import matplotlib.pyplot as plt
# 使用 Matplotlib 自定义图表
fig, ax = plt.subplots(figsize=(10, 6))
ts.plot(ax=ax)
ax.set_title('Time Series Data')
ax.set_xlabel('Date')
ax.set_ylabel('Value')
plt.show()
注意事项
- 数据预处理: 在进行趋势、季节性和周期性分析之前,通常需要对数据进行清洗和预处理,例如处理缺失值和异常值。
- 模型选择: 根据数据的特点选择合适的分解模型(如加性模型或乘性模型)。
- 可视化效果: 根据分析目的选择合适的图表类型,如线图、柱状图等。
时间序列填充与插值
在时间序列分析中,缺失数据是一个常见的问题。处理缺失数据是确保数据完整性和分析准确性的关键步骤。Pandas提供了多种方法来填充和插值时间序列中的缺失值,其中fillna()和interpolate()是最常用的方法。
缺失数据可能由于多种原因出现,例如数据采集问题、系统错误或数据传输失败。在时间序列中,缺失数据会影响趋势分析、模型预测和其他统计计算,因此必须加以处理。
使用 fillna() 方法
fillna()方法用于填充缺失值。它提供了多种策略来填充缺失数据,包括使用特定值、前向填充、后向填充等。
import pandas as pd
import numpy as np
# 创建一个示例时间序列,其中包含缺失值
dates = pd.date_range('2023-01-01', periods=10, freq='D')
data = [1, np.nan, 3, np.nan, 5, 6, np.nan, 8, 9, 10]
ts = pd.Series(data, index=dates)
# 使用特定值填充缺失值
filled_ts = ts.fillna(0)
print("Filled with 0:\n", filled_ts)
# 使用前向填充方法填充缺失值
filled_ts_ffill = ts.fillna(method='ffill')
print("Forward Fill:\n", filled_ts_ffill)
# 使用后向填充方法填充缺失值
filled_ts_bfill = ts.fillna(method='bfill')
print("Backward Fill:\n", filled_ts_bfill)
使用 interpolate() 方法
interpolate()方法用于通过插值算法填充缺失值。它提供了多种插值方法,如线性插值、时间插值、多项式插值等。
# 使用线性插值填充缺失值
interpolated_ts_linear = ts.interpolate(method='linear')
print("Linear Interpolation:\n", interpolated_ts_linear)
# 使用时间插值填充缺失值(适用于时间序列)
interpolated_ts_time = ts.interpolate(method='time')
print("Time Interpolation:\n", interpolated_ts_time)
# 使用多项式插值填充缺失值
interpolated_ts_poly = ts.interpolate(method='polynomial', order=2)
print("Polynomial Interpolation:\n", interpolated_ts_poly)
注意事项
- 选择合适的方法:根据数据的特性选择合适的填充或插值方法。例如,前向填充和后向填充适用于缓慢变化的数据,而线性插值适用于线性趋势的数据。
- 插值方法的影响:不同的插值方法可能对结果有不同的影响,尤其是在数据波动较大的情况下。
- 数据验证:在填充和插值后,验证数据的合理性和一致性,以确保处理结果的可靠性。
时间序列分组与聚合
时间序列分组与聚合是分析时间序列数据的重要步骤,特别是在需要根据时间维度(如年、月、日、小时等)进行数据汇总和计算时。Pandas提供了groupby()方法来实现按时间维度分组,并支持多种聚合操作,如求和、平均、计数等。
使用groupby()方法按时间维度分组
groupby()方法用于将数据根据某个或多个键进行分组。对于时间序列数据,可以通过时间维度(如年份、月份、季度等)进行分组,以便进行更详细的分析。
import pandas as pd
import numpy as np
# 创建一个示例时间序列
dates = pd.date_range('2023-01-01', periods=100, freq='D')
data = np.random.randn(100)
ts = pd.Series(data, index=dates)
# 按月份进行分组
grouped_by_month = ts.groupby(ts.index.month)
# 打印每组的内容
for month, group in grouped_by_month:
print(f"Month: {month}\n", group.head())
时间序列数据的聚合操作
在完成分组后,可以对每个组执行聚合操作。Pandas支持多种聚合函数,包括sum(), mean(), count(), min(), max()等。这些操作可以帮助我们从数据中提取有意义的统计信息。
# 计算每个月的平均值
monthly_mean = grouped_by_month.mean()
print("Monthly Mean:\n", monthly_mean)
# 计算每个月的总和
monthly_sum = grouped_by_month.sum()
print("Monthly Sum:\n", monthly_sum)
# 计算每个月的数据点数
monthly_count = grouped_by_month.count()
print("Monthly Count:\n", monthly_count)
注意事项
- 时间频率:在分组之前,确保时间序列的频率与分析目标一致。例如,如果要按月分析数据,确保数据至少是每日频率。
- 数据完整性:确保时间序列数据没有缺失或错误值,以避免影响聚合结果。
- 自定义聚合:除了内置的聚合函数,Pandas还支持自定义聚合函数,以满足特定的分析需求。
高级时间序列处理
高级时间序列处理涉及对数据进行更复杂的操作,以便深入分析和提取有用的信息。Pandas提供了强大的功能,如apply()方法用于自定义函数的应用,以及去趋势和去季节性分析,以帮助我们更好地理解时间序列数据。
使用 apply() 方法进行自定义函数应用
apply()方法允许我们对DataFrame或Series的每个元素、行或列应用自定义函数。这在需要执行复杂或特定计算时特别有用。
import pandas as pd
import numpy as np
# 创建一个示例时间序列
dates = pd.date_range('2023-01-01', periods=10, freq='D')
ts = pd.Series(np.random.randn(10), index=dates)
# 定义一个自定义函数
def custom_function(x):
return x**2 + 3*x + 1
# 使用apply()方法应用自定义函数
result = ts.apply(custom_function)
print("Result of custom function:\n", result)
时间序列的去趋势和去季节性
去趋势和去季节性是时间序列分析中的两个重要步骤,用于消除数据中的趋势和季节性成分,从而更好地分析和建模剩余的部分。
去趋势(Detrending)
去趋势是从时间序列中移除长期趋势的过程。这可以通过多种方法实现,包括差分法和回归法。
# 使用差分法去趋势
detrended_ts = ts.diff().dropna()
print("Detrended Time Series:\n", detrended_ts)
去季节性(Deseasonalization)
去季节性是从时间序列中移除季节性成分的过程。这通常通过时间序列分解来实现。
from statsmodels.tsa.seasonal import seasonal_decompose
# 分解时间序列数据
result = seasonal_decompose(ts, model='additive', period=1)
# 去除季节性成分
deseasonalized_ts = ts - result.seasonal
print("Deseasonalized Time Series:\n", deseasonalized_ts)
注意事项
- 选择合适的方法:去趋势和去季节性的方法选择取决于数据的特性和分析目标。
- 数据预处理:在进行去趋势和去季节性之前,确保数据已被清洗和预处理。
- 验证结果:在去趋势和去季节性后,验证结果的合理性,以确保数据处理的正确性。
时区处理
时区是地球表面的一种区域划分,每个时区内的所有地方都使用相同的标准时间。时区的划分主要是为了协调世界各地的时间,以适应地球的自转和公转。时区通常以协调世界时(UTC)为基准,并通过加减小时来表示。例如,北京时间是UTC+8,表示比UTC早8小时。
处理时区在全球化应用中非常重要,因为不同地区的用户可能在不同的时区。Python提供了多种工具和库来处理时区数据,以下是一些关键的工具和方法:
使用Python的 datetime 模块
datetime模块中的datetime对象可以处理时区信息,但需要借助pytz库来实现完整的时区支持。
创建时区感知的datetime对象
使用pytz库,可以创建一个带有时区信息的datetime对象:
from datetime import datetime
import pytz
# 获取当前时间
naive_now = datetime.now()
# 设置为UTC时区
utc_now = pytz.utc.localize(naive_now)
print("UTC时间:", utc_now)
转换时区
可以将一个datetime对象从一个时区转换到另一个时区:
# 定义目标时区
beijing_tz = pytz.timezone('Asia/Shanghai')
# 转换时区
beijing_time = utc_now.astimezone(beijing_tz)
print("北京时间:", beijing_time)
创建特定时区的datetime对象
可以直接创建一个属于特定时区的datetime对象:
# 创建一个特定时间的datetime对象
naive_time = datetime(2023, 10, 1, 12, 0, 0)
# 将其设置为UTC时区
utc_time = pytz.utc.localize(naive_time)
# 转换为其他时区
ny_tz = pytz.timezone('America/New_York')
ny_time = utc_time.astimezone(ny_tz)
print("纽约时间:", ny_time)
使用 zoneinfo 模块(Python 3.9+)
从Python 3.9开始,标准库中引入了zoneinfo模块,它提供了对IANA时区数据库的访问,可以不依赖pytz。
from datetime import datetime
from zoneinfo import ZoneInfo
# 获取当前时间并设置时区
dt = datetime.now(ZoneInfo('UTC'))
print("当前UTC时间:", dt)
# 转换为其他时区
beijing_time = dt.astimezone(ZoneInfo('Asia/Shanghai'))
print("北京时间:", beijing_time)
Pandas时序数据时区处理
在处理时间序列数据时,时区管理是一个重要的方面,尤其是在全球化的应用场景中。Pandas提供了丰富的功能来处理和转换时间序列数据中的时区,使得处理跨时区的数据变得更加容易。以下是关于Pandas时序数据时区处理的详细介绍。
创建带时区的时间序列
import pandas as pd
import pytz
# 创建一个带有DatetimeIndex的时间序列
dates = pd.date_range(start='2023-01-01', periods=5, freq='D')
ts = pd.Series(range(5), index=dates)
# 设置时区为UTC
ts_utc = ts.tz_localize('UTC')
print("Time Series with UTC TimeZone:")
print(ts_utc)
时区转换
可以使用.tz_convert()方法将时间序列从一个时区转换为另一个时区。
# 将UTC时区转换为美国东部时间
ts_est = ts_utc.tz_convert('US/Eastern')
print("\nTime Series converted to US/Eastern TimeZone:")
print(ts_est)
移除时区
可以使用.tz_localize(None)来移除时区信息。
# 移除时区信息
ts_no_tz = ts_est.tz_localize(None)
print("\nTime Series with TimeZone Removed:")
print(ts_no_tz)
处理包含时区的时间序列
在处理包含时区的时间序列时,务必注意时区转换后的时间是否符合预期,尤其是在跨越夏令时的情况下。
# 创建一个时间序列,设置为美国东部时间
dates_with_tz = pd.date_range(start='2023-01-01', periods=5, freq='D', tz='US/Eastern')
ts_with_tz = pd.Series(range(5), index=dates_with_tz)
print("\nTime Series with US/Eastern TimeZone:")
print(ts_with_tz)
# 转换为UTC
ts_converted_to_utc = ts_with_tz.tz_convert('UTC')
print("\nTime Series converted to UTC:")
print(ts_converted_to_utc)
时区处理示例
以下是一个综合示例,展示了如何在Pandas中进行时区处理:
import pandas as pd
# 创建一个带有DatetimeIndex的时间序列
dates = pd.date_range(start='2023-01-01', periods=5, freq='D')
ts = pd.Series(range(5), index=dates)
print("Original Time Series:")
print(ts)
# 设置时区为UTC
ts_utc = ts.tz_localize('UTC')
print("\nTime Series with UTC TimeZone:")
print(ts_utc)
# 将UTC时区转换为美国东部时间
ts_est = ts_utc.tz_convert('US/Eastern')
print("\nTime Series converted to US/Eastern TimeZone:")
print(ts_est)
# 移除时区信息
ts_no_tz = ts_est.tz_localize(None)
print("\nTime Series with TimeZone Removed:")
print(ts_no_tz)
注意事项
- 时区设置与转换:tz_localize用于设置时区,而tz_convert用于转换时区。前者假设数据没有时区信息,后者则用于已有时区信息的数据。
- 夏令时:在处理跨越夏令时的时间序列时,确保时区转换正确。
- 性能:时区处理可能会增加计算的复杂性,尤其是在处理大规模数据时,需要注意性能影响。


