国内OJ平台 经典高校OJ POJ(北京大学在线评测系统) POJ由北京大学建立于2003年,是国内历史最悠久的在线评测系统之一。平台题目以英文为主,难度梯度设计科学,涵盖从基础到高阶的各类算法问题。POJ定期举…

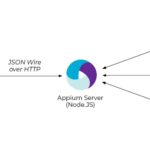
在移动互联网时代,Android和iOS应用的测试变得越来越重要。为了保证应用的质量和用户体验,自动化测试成为了必不可少的一环。Appium作为一个开源的移动端自动化测试框架,为开发者和测试工程师提供了强大的工具来…
App Store 应用内购买(In-App Purchase,简称 IAP)是苹果为 iOS、macOS、tvOS 等平台上的应用提供的一套标准化的虚拟商品与数字服务交易系统。它允许开发者在其应用中安全地销售数字内容、订阅服务、高级功能等,…

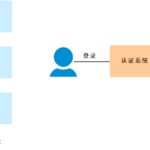
在当今企业数字化和互联网服务高度集成的背景下,用户常常需要在多个独立的应用程序或系统之间切换。如果每个系统都要求用户单独进行身份验证,不仅会严重损害用户体验,还会增加安全管理的复杂性和风险。单点登录…
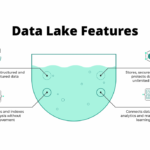
在当今数据驱动的商业环境中,企业面临着海量、多样且高速增长的数据挑战。为了从这些数据中提取价值,两种主流的存储与管理架构应运而生:数据湖与数据仓库。尽管它们都是用于存储和分析数据的系统,但其设计哲学…
编程不仅仅是学习语法和算法,理解计算机如何工作同样至关重要。掌握计算机基础知识能帮助你写出更高效、更可靠的代码,并深入理解程序运行的底层原理。本文系统梳理了学习编程需要了解的计算机核心知识。 计…

在当今动辄数十GB的游戏时代,回顾《超级马力欧兄弟》初代(SMB1)在仅40KB(常被概称为64KB级别)的容量内,构建出32个丰富多彩关卡的设计,堪称工程与艺术的奇迹。这不仅是技术限制下的产物,更是一套历经时间考…

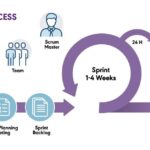
Scrum是一个广泛应用于敏捷项目管理的轻量级框架,旨在通过协作、迭代和增量交付来应对复杂问题并高效创造价值。其核心结构围绕三种角色、三类工件和五个事件展开。 三种角色包括: 产品负责人,定义产…
在当今信息爆炸的时代,搜索引擎已成为我们获取知识、解决问题的主要工具。作为全球第二大搜索引擎,Bing不仅提供了强大的搜索能力,其搜索URL参数体系更是一个精密设计的指令系统。理解这些参数,意味着你能超越普…

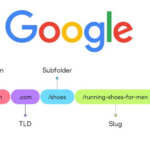
为什么需要了解Google搜索URL参数 在浏览器地址栏里,一个不起眼的Google搜索链接蕴藏着远超表面浏览的精密控制力。当你输入关键词并按下回车,生成的URL并非一串单纯的字符,而是一份由多个参数精确编码的“搜索指…