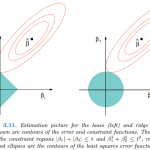
K-Means算法和MeanShift算法都是基于距离的聚类算法,基于距离的聚类算法的聚类结果是球状的簇,当数据集中的聚类结果是非球状结构时,基于距离的聚类算法的聚类效果并不好。 与基于距离的聚类算法不同的是,基…
大部分聚类方法针对的是多维数据,现实场景中还有可能存在以为数据的情况,针对以为数组的聚类和多维的数据有很大的不同,今天就来实战演练下: 需求内容:分析订单的价格分布 常见方案:按照100为梯度,分析不…
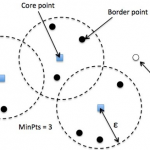
在学习聚类算法得时候并没有涉及到评估指标,主要原因是聚类算法属于非监督学习,并不像分类算法那样可以使用训练集或测试集中得数据计算准确率、召回率等。那么如何评估聚类算法得好坏呢?好的聚类算法,一般要求类…

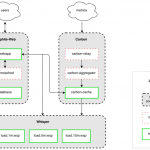
异常监控系统 Skyline的文章中,详细介绍了 Skyline 的架构,今天主要分享的是自己在部署 Skyline 中的一些记录。 项目地址:https://github.com/earthgecko/skyline 参考文档:https://earthgecko-skyline.read…
Graphite 是处理可视化和指标数据的优秀开源工具。它有强大的查询 API 和相当丰富的插件功能设置。事实上,Graphite 指标协议(metrics protocol)是许多指标收集工具的事实标准格式。然而,Graphite 并不总是一个…
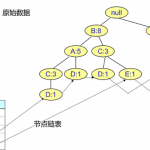
在Apriori算法的学习中,我们了解到Apriori算法需要不断生成候选项目队列和不断得扫描整个数据库进行比对,I/O是很大的瓶颈。为了解决这个问题,FP-Growth利用了巧妙的数据结构,无论多少数据,只需要扫描两次数据…
利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。但人工摘要耗时又耗力,已不能满足日益增长的信息需求,因…
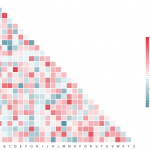
常用相关性分析存在的问题 1、有许多非线性的关系是分数根本无法检测到的,比如下图: 2、计算出来的矩阵是对称的,即a与b的相关性同b与a的相同。更多的时候,关系是不对称的。一个有3个唯一值的…

在分析特征间相关性时,常使用的方法是pandas.DataFrame.corr: DataFrame.corr(self, method=’pearson’, min_periods=1) 其中包含的方法主要为: pearson:Pearson相关系数 kendall:Kendall秩相关系数 Spea…
在处理较为复杂的数据的回归问题时,普通的线性回归算法通常会出现预测精度不够,如果模型中的特征之间有相关关系,就会增加模型的复杂程度。当数据集中的特征之间有较强的线性相关性时,即特征之间出现严重的多重…