在使用 Pandas 处理数据时,常见的读取数据的方式时从 Excel 或 CSV 文件中获取,另外有时也会需要将处理完的数据输出为 Excel 或 CSV 文件。今天就一起来学习下 Pandas 常见的文件读取与导出的方法。 加载 Excel…

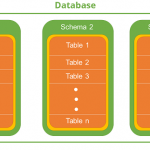
在学习数据库时,会遇到一个让人迷糊的Schema的概念。实际上,schema就是数据库对象的集合,这个集合包含了各种对象如:表、视图、存储过程、索引等。 如果把database看作是一个仓库,仓库很多房间(schema),一…
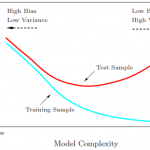
很多参数估计问题均采用似然函数作为目标函数,当训练数据足够多时,可以不断提高模型精度,但是以提高模型复杂度为代价的,同时带来一个机器学习中非常普遍的问题——过拟合。所以,模型选择问题在模型复杂度与模型…
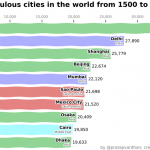
我们经常看到的 Bar Chart Race(柱形竞赛图),可以看到数据的呈现非常的直观。今天就一起来学习下如何生成和上面一样的柱形竞赛图。 1、导入 Python 库 import pandas as pd import matplotlib.pyplot as plt …
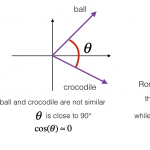
什么是余弦定理 学过向量代数的人都知道,向量实际上是多维空间中有方向的线段。如果两个向量的方向一致,即夹角接近零,那么这两个向量就相近。而要确定两个向量方向是否一致,这就要用到余弦定理计算向量的夹角了…
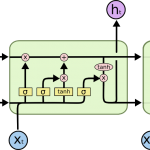
普通RNN存在的问题 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的…
情感分析是一种常见的自然语言处理(NLP)方法的应用,特别是在以提取文本的情感内容为目标的分类方法中。通过这种方式,情感分析可以被视为利用一些情感得分指标来量化定性数据的方法。尽管情绪在很大程度上是主观…
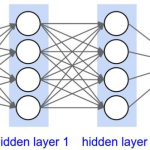
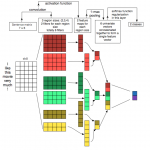
全连接神经网络 全连接神经网络是一种最基本的神经网络结构,英文为 Full Connection,所以一般简称 FC。FC 的准则很简单:神经网络中除输入层之外的每个节点都和上一层的所有节点有连接。 上图是一个双隐层的前…
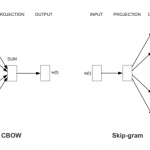
在“卷积神经网络”中我们探究了如何使用二维卷积神经网络来处理二维图像数据。在之前的语言模型和文本分类任务中,我们将文本数据看作是只有一个维度的时间序列,并很自然地使用循环神经网络来表征这样的数据。其实…
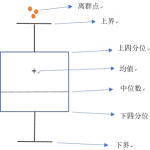
箱形图简介 箱形图(英文:Boxplot),又是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。箱形图于1977年由美国著名统计学家约翰·图基(John Tukey)发明。它能显示出一组数据的最大值、最小值、…