子曰:学而时习之,不亦说乎!有朋自远方來,不亦乐乎!人不知而不愠,不亦君子乎! 在重读论语之前,我对这句话的理解是:“经常学习,不也喜悦吗?从远方来了朋友,不也快乐吗?别人不了解我也不怨恨,不也是君子吗?” 重读《论语》,总感觉上面的解释有点“跳”…
查看全文情感分析的定义与核心地位 情感分析(Sentiment Analysis),亦称为意见挖掘或倾向性分析,是人工智能领域中计算语言学的分支,属于自然语言处理(NLP)的核心内容。其核心定义为:通过自动化技术判定文本中观点持…

在Python生态中,依赖管理工具的效率和可靠性直接关系到开发体验与项目交付速度。传统的pip虽然作为官方标准,但其在大型项目中的依赖解析速度和环境一致性方面常显不足。而由Astral团队(Ruff工具的创造者)用Rust…

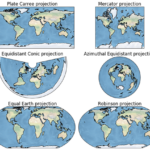
Cartopy是一个基于Matplotlib构建的Python库,专门用于地理空间数据处理和地图绘制。它将Matplotlib强大的绘图功能与专业的地理空间数据处理能力相结合,为科研工作者、数据分析师和开发者提供了一个高效、灵活的地…
Electron框架概述 Electron是一个由GitHub开发的开源框架,它允许开发者使用熟悉的Web技术——JavaScript、HTML和CSS——来构建跨平台的桌面应用程序。其核心理念是将Chromium浏览器内核与Node.js运行时环境相结合,使…

在信息爆炸的时代,如何高效地管理知识、连接想法并构建个人知识体系,已成为现代人尤其是开发者和知识工作者的核心需求。Obsidian,这款基于本地Markdown文件的强大笔记工具,正以其完全免费、双向链接、插件生态…
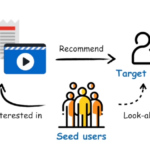
模型概述 RALM(Retrieval-Augmented Look-alike Model)是由腾讯公司于2019年提出并成功应用于微信“看一看”推荐场景的创新模型。该模型的核心目标在于解决传统推荐系统中普遍存在的长尾内容分发难题,即大量缺乏…
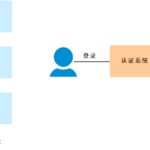
在当今企业数字化和互联网服务高度集成的背景下,用户常常需要在多个独立的应用程序或系统之间切换。如果每个系统都要求用户单独进行身份验证,不仅会严重损害用户体验,还会增加安全管理的复杂性和风险。单点登录…
在信息爆炸的时代,我们每天都会遇到大量有价值的文章、报告或网页,但往往没有时间立即消化。“稍后阅读”软件应运而生,它们不仅是简单的书签工具,更是现代人知识管理、深度学习和信息沉淀的核心枢纽。本文将为您…

在当今数据驱动的商业环境中,企业面临着海量、多样且高速增长的数据挑战。为了从这些数据中提取价值,两种主流的存储与管理架构应运而生:数据湖与数据仓库。尽管它们都是用于存储和分析数据的系统,但其设计哲学…
在信息爆炸的时代,如何高效地梳理思路、激发创意、管理项目?思维导图作为一种强大的图形化思维工具,已成为个人学习、团队协作和商业决策中不可或缺的利器。它通过一个中心主题向外发散,利用色彩、图形和关键词…