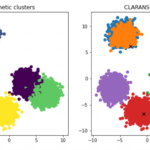
CLARANS简介 CLARANS(Clustering Large Applications based on RANdomized Search,基于随机搜索的大规模应用聚类)是一种经典的聚类算法,由Raymond T. Ng和Jiawei Han于1994年提出。它旨在解决当时主流聚类算法…
X-Means 和 G-Means 都是基于 K-Means 的改进算法,主要目标是自动确定最优的聚类数量k,无需人工预先指定。 X-Means X-Means 是一种能够自动确定最佳聚类数量的改进型K-Means算法,它通过统计指标来评估聚类…

ROCK算法概述 ROCK产生背景 传统聚类算法的局限性 20世纪90年代末,随着电子商务、市场篮子分析和生物信息学等领域的快速发展,分类属性和布尔型数据的聚类需求日益凸显。传统聚类方法面临两大挑战: 距…
K-Medians简介 K-Medians 是 K-Means 聚类算法的一种变体,通过使用中位数而非均值来计算聚类中心,从而提升对异常值的鲁棒性。 核心思想 目标函数:最小化每个数据点到其所属聚类中心的曼哈顿距离之…

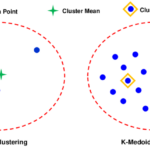
k-medoids算法概述 k-medoids 是一种基于中心的聚类算法,是 k-means 算法的改进版本。与 k-means 使用簇内数据点的均值作为中心点不同,k-medoids 使用实际数据点作为中心点(称为 medoid)。 与 k-means …
香农-范诺编码简介 香农-范诺编码(Shannon-Fano Coding)是一种经典的无损数据压缩算法,由克劳德·香农(Claude Shannon)和罗伯特·范诺(Robert Fano)于1948年左右独立提出。这是第一种基于信息熵理论的压缩算…
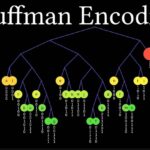
哈夫曼编码简介 哈夫曼编码(Huffman Coding)是一种基于字符出现频率进行编码的无损数据压缩算法,由大卫·哈夫曼于1952年提出。它的核心思想是:赋予高频字符较短的编码,赋予低频字符较长的编码,从而使整个数据…
Apache Beam 简介 Apache Beam 是一个统一的编程模型,用于定义和执行大规模的数据处理任务,支持批处理和流处理。它提供了一种抽象层,使开发者可以编写一次数据处理逻辑,然后在不同的分布式处理引擎(如 Apache…
Kubeflow简介 Kubeflow是一个开源的机器学习平台,旨在简化在Kubernetes上部署、管理和扩展机器学习工作流的过程。它提供了一整套工具和组件,帮助数据科学家和工程师从数据准备、模型训练到部署和监控,构建完整的…

Metaflow简介 Metaflow是由Netflix开发并开源的一个数据科学框架,旨在帮助数据科学家和工程师更容易地构建和管理可扩展的数据科学工作流。Metaflow提供了一个用户友好的API,支持在本地和云端(如AWS)执行工作流…