Apache Beam 简介
Apache Beam 是一个统一的编程模型,用于定义和执行大规模的数据处理任务,支持批处理和流处理。它提供了一种抽象层,使开发者可以编写一次数据处理逻辑,然后在不同的分布式处理引擎(如 Apache Flink、Apache Spark、Google Cloud Dataflow 等)上运行。

项目背景
Apache Beam 的项目背景源于谷歌在大规模数据处理领域的经验和技术积累。谷歌在开发和运维其互联网服务的过程中,面临着处理海量数据的挑战。为了解决这些问题,谷歌先后开发了多个内部工具和系统,这些系统奠定了 Apache Beam 的基础。
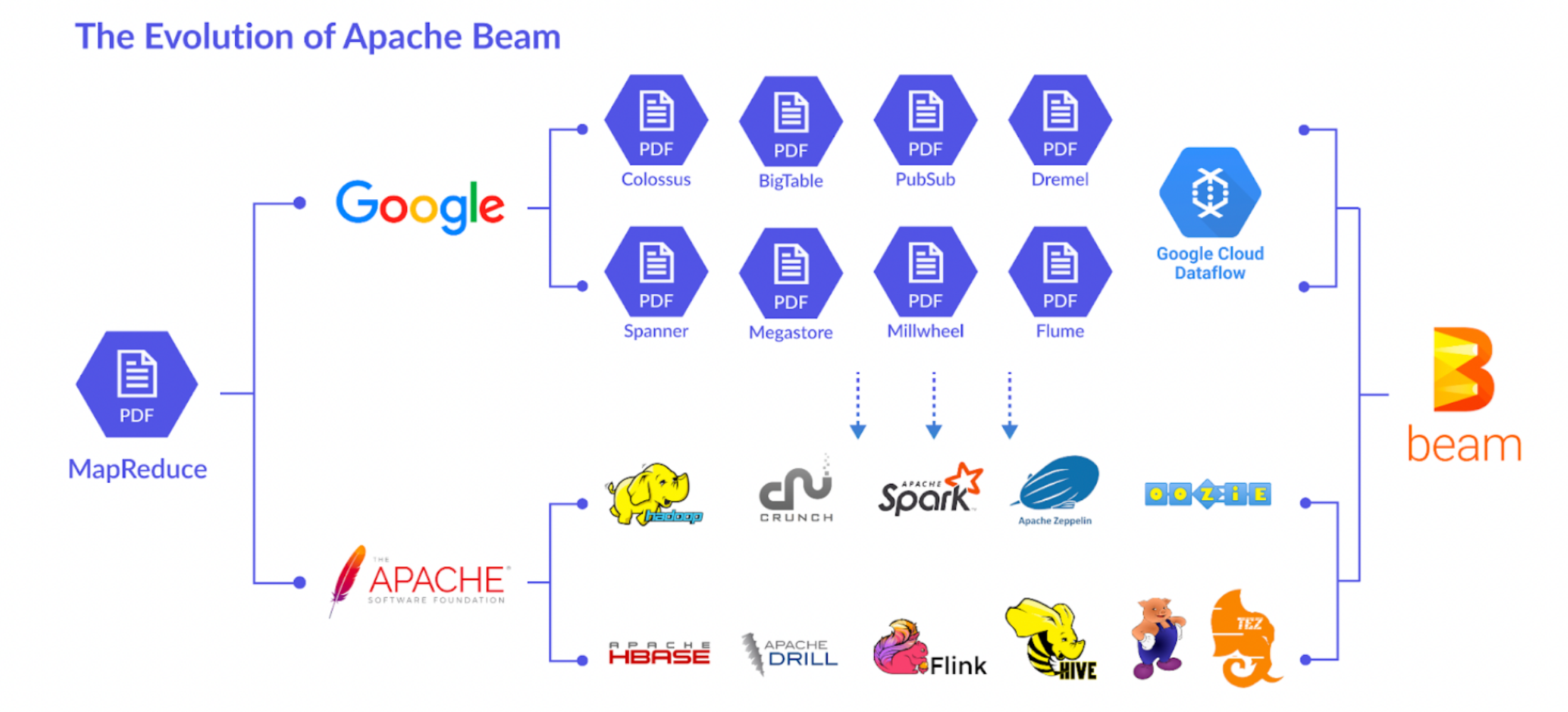
背景与起源
- MapReduce。谷歌最初开发了 MapReduce 作为大规模数据处理的编程模型和执行框架。MapReduce 简化了分布式计算的复杂性,并被广泛应用于批处理任务。
- FlumeJava。FlumeJava 是谷歌内部的一个库,旨在简化大规模数据并行处理的编程。它提供了一种更高层次的抽象,允许开发者以更直观的方式定义数据处理管道。
- MillWheel。为解决实时数据处理需求,谷歌开发了 MillWheel,这是一个低延迟、具备精确一次处理语义的流处理系统。
- Google Cloud Dataflow。谷歌将 FlumeJava 和 MillWheel 的概念结合,推出了 Google Cloud Dataflow。Dataflow 提供了一种统一的模型来处理批处理和流处理任务,并作为谷歌云平台上的一个托管服务。
Apache Beam 的诞生
- 开源化:为了将这些技术优势推广到更广泛的社区,并支持多种执行环境,谷歌于 2016 年将 Dataflow 的 SDK 捐赠给 Apache 软件基金会,形成了 Apache Beam 项目。
- 统一编程模型:Apache Beam 提供了一个统一的编程模型,允许开发者使用同一套 API 来定义批处理和流处理任务。这个模型抽象了底层执行引擎的细节,使用户能够编写一次代码并在多种环境中运行。
- 跨平台支持:Apache Beam 的一个重要特性是支持多种执行引擎(Runners),包括 Apache Flink、Apache Spark、Google Cloud Dataflow 等。这使得用户可以根据具体需求选择合适的执行平台,而不需要重写代码。
目标与愿景
- 简化大规模数据处理:提供一个简单而强大的 API,使开发者能够专注于数据处理逻辑,而不是底层执行细节。
- 灵活的执行选择:通过支持多种 Runners,Beam 允许用户根据性能、成本和基础设施的考虑来选择执行环境。
- 促进社区合作:作为 Apache 软件基金会的项目,Beam 鼓励社区贡献和合作,推动数据处理技术的发展。
Apache Beam 的项目背景体现了从谷歌内部工具到开源社区项目的演变过程,目标是提供一个灵活、统一和高效的数据处理框架,适应现代数据驱动应用的各种需求。
主要特性
- 统一编程模型
- 批处理和流处理:支持批处理和流处理,提供统一的 API 来处理不同类型的数据。
- 可移植性:编写一次代码,可以在多种执行引擎上运行,无需修改。
- 丰富的数据处理功能
- 数据转换:支持多种数据转换操作,如过滤、映射、聚合等。
- 窗口处理:支持时间窗口和会话窗口,适用于流处理中的数据分组和聚合。
- 水印和延迟处理:支持水印(watermark)和延迟处理(lateness handling),确保流处理的准确性和完整性。
- 种执行引擎支持
- Apache Flink:支持 Apache Flink 作为执行引擎,适用于高性能流处理。
- Apache Spark:支持 Apache Spark 作为执行引擎,适用于批处理和流处理。
- Google Dataflow:支持 Google Dataflow 作为执行引擎,适用于云原生数据处理。
- 其他引擎:还支持其他执行引擎,如 Apache Samza、Apache Apex 等。
- 多语言支持
- Java:提供丰富的 Java SDK,适用于大多数大数据处理场景。
- Python:提供 Python SDK,适用于数据科学和机器学习场景。
- Go:提供 Go SDK,适用于高性能和轻量级应用。
- 扩展性和灵活性
- 自定义转换:支持自定义转换函数,用户可以根据需求实现复杂的业务逻辑。
- 连接器:提供多种数据源和目标的连接器,如 Kafka、Pub/Sub、BigQuery 等。
使用场景
Apache Beam 是一个强大的数据处理框架,适用于各种大规模数据处理需求。它的统一编程模型支持批处理和流处理,这使得它能够应对多种使用场景。以下是一些常见的 Apache Beam 使用场景:
- 实时数据流处理:物联网传感器数据处理、实时日志分析、在线欺诈检测。通过流处理能力,Apache Beam 能够实时处理数据流,支持低延迟的事件处理和复杂事件处理。
- 批处理:定期数据报告生成、数据仓库批量加载、历史数据分析。Beam 的批处理模式允许处理有界数据集,适合定期的数据聚合和转换任务。
- ETL(提取、转换、加载):从多个来源提取数据、清洗和转换数据格式、加载到数据仓库或数据湖。Beam 提供丰富的 I/O 连接器和转换操作,支持复杂的 ETL 管道构建。
- 数据集成:跨多个系统的数据同步、数据融合和统一。通过支持多种数据源和接收器,Beam 可以在不同系统之间实现数据集成。
- 机器学习数据预处理:特征工程、数据标准化、训练数据集的生成。Beam 的灵活转换能力使其适合在机器学习管道中执行数据预处理任务。
- 数据清洗和质量检查:数据去重、数据验证、异常值检测。Beam 提供多种数据转换和过滤操作,能够有效地进行数据清洗和质量检查。
- 跨平台数据处理:在不同云服务或分布式计算框架上运行相同的数据处理逻辑。通过 Runners,Beam 支持在 Apache Flink、Apache Spark、Google Cloud Dataflow 等平台上执行相同的管道。
- 日志和事件聚合:收集和分析应用程序日志、用户活动跟踪、事件驱动的分析。Beam 能够处理无界数据流,适合持续的日志和事件聚合任务。
- 实时监控和报警:系统健康监控、实时性能指标分析、自动报警系统。通过流处理和窗口化机制,Beam 可以实时计算和评估关键指标,并触发报警。
这些使用场景展示了 Apache Beam 的灵活性和强大功能,使其成为现代数据驱动应用中不可或缺的工具。无论是批处理还是流处理,Beam 都能提供高效、可扩展的数据处理解决方案。
Apache Beam 的架构
Apache Beam 的架构设计旨在提供一个统一的编程模型,支持在不同执行引擎上进行批处理和流处理。
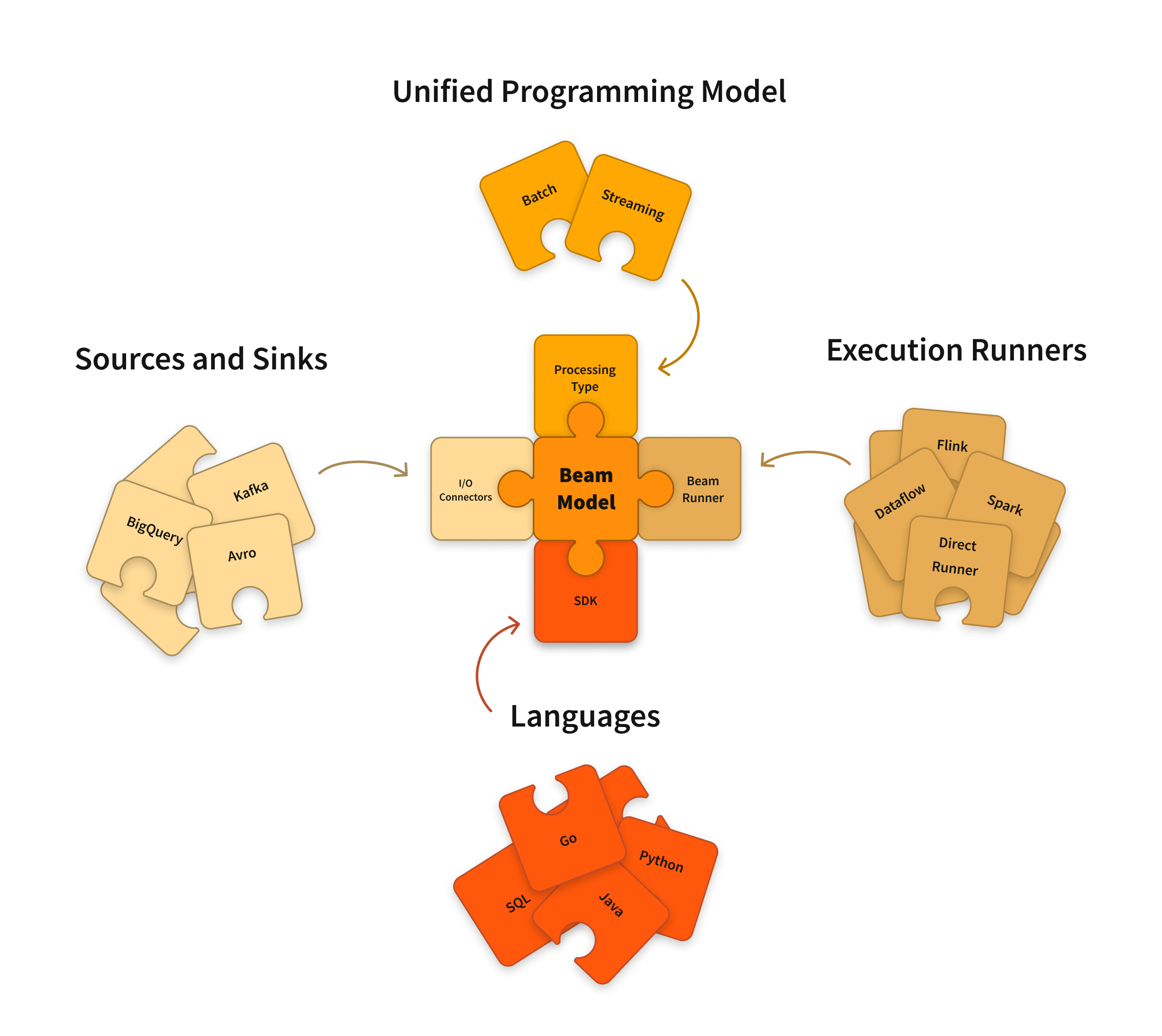
核心组件
- Pipeline(管道):Pipeline 是一个 Beam 应用程序的核心结构,定义了数据的输入、处理和输出。通过一系列的转换(Transforms)和 I/O 操作,将数据从源处理到目标。
- PCollection:PCollection 是管道中的数据集,可以是有界(批处理)或无界(流处理)。类似于分布式集合,支持各种转换操作。
- Transforms(转换):Transforms 是对 PCollection 进行的操作,如 Map、Filter、GroupByKey、Combine 等。负责实现数据的转换和处理逻辑。
- ParDo:ParDo 是一个通用的并行处理操作,用于对每个元素执行任意的用户定义函数。支持复杂的映射和处理逻辑,允许对数据进行细粒度的操作。
- Windowing:Windowing 是将无界数据流分割成有限的窗口以便处理。支持固定窗口、滑动窗口、会话窗口等,帮助在流处理中进行聚合和分析。
- Triggers:Triggers 定义了何时输出窗口结果的策略。支持基于事件时间、处理时间等触发策略,管理窗口结果的输出时机。
- I/O Connectors:I/O Connectors 提供与外部数据源和接收器的接口。支持多种数据源和目标,如文件系统、数据库、消息队列(如 Kafka)、云存储等。
执行引擎(Runners)
Apache Beam 的一个核心优势是其可移植性,允许在多种执行引擎上运行相同的管道。常见的 Runners 包括:
- Apache Flink Runner
- Apache Spark Runner
- Google Cloud Dataflow Runner
- Direct Runner(用于本地测试和调试)
架构流程
- 管道构建:开发者使用 Beam SDK(支持 Java、Python、Go 等)定义数据处理管道,描述从数据输入到输出的整个流程。
- 执行计划生成:Beam 将管道转换为一个可执行的计划,该计划可以在不同的 Runner 上运行。
- 选择 Runner:用户选择合适的 Runner 来执行管道,这可以根据需求选择不同的执行引擎。
- 执行和监控:选定的 Runner 负责在分布式计算环境中执行管道,Beam 提供监控和日志功能以跟踪执行状态。
- 结果输出:数据经过处理后,输出到指定的目标系统或存储。
Apache Beam 的架构设计提供了一个灵活且统一的框架,能够处理多种数据处理需求。通过其模块化的组件和跨平台的执行支持,Beam 成为现代数据处理应用的理想选择,适用于批处理和流处理场景。
Apache Beam 的使用
使用 Apache Beam 涉及几个关键步骤,包括设置开发环境、定义数据处理管道、选择执行引擎(Runner)和运行管道。以下是一个典型的 Apache Beam 使用流程:
设置开发环境
- 选择编程语言:
- Apache Beam 支持多种编程语言,包括 Java、Python 和 Go。根据项目需求选择合适的语言。
- 安装 SDK:
- 根据所选语言,安装相应的 Apache Beam SDK。
- Java:通过 Maven 或 Gradle 引入 Beam SDK 依赖。
- Python:使用 pip 安装,例如 pip install apache-beam。
定义数据处理管道
- 创建 Pipeline:
- 使用 Beam SDK 创建一个 Pipeline 对象,这个对象是所有数据处理的基础。
- 定义 PCollection:
- 通过读取数据源(如文件、数据库、消息队列)来创建 PCollection,这是 Beam 中的数据集表示。
- 应用 Transforms:
- 对 PCollection 应用各种转换(Transforms),如 ParDo、GroupByKey、Combine 等,以实现数据的处理逻辑。
- ParDo:用于执行自定义的并行操作。
- GroupByKey:用于根据键分组数据,常用于聚合操作。
- Combine:用于执行聚合操作,如求和、平均等。
- 定义 Windowing 和 Triggers(可选):
- 对于流处理,定义窗口策略(如固定窗口、滑动窗口)和触发器,以管理数据的分组和结果输出时机。
- 输出结果:
- 将处理后的数据输出到目标系统或存储,如文件系统、数据库、云存储等。
选择执行引擎(Runner)
选择合适的 Runner:
Apache Beam 支持多种 Runners,如 Apache Flink、Apache Spark、Google Cloud Dataflow、Direct Runner 等。选择 Runner 取决于项目需求和可用的基础设施。
- Direct Runner:用于本地测试和调试。
- Google Cloud Dataflow:适合在 Google Cloud 上进行托管的数据处理。
- Apache Flink/Spark Runner:适合已有 Flink 或 Spark 集群的环境。
运行管道
- 本地运行:
- 使用 Direct Runner 进行本地测试,确保管道逻辑正确。
- 分布式运行:
- 配置并提交管道到选定的分布式 Runner 上运行。
监控和调试
- 监控执行:
- 使用 Beam 提供的监控工具或 Runner 提供的监控界面查看管道执行状态。
- 检查日志和指标以确保数据处理正确性。
- 调试:
- 通过日志和错误信息进行调试,必要时调整管道逻辑或配置。
Python 示例代码
安装 Beam SDK:pip install apache-beam编写 Beam 管道:
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
def split_words(line):
return line.split()
def format_result(word_count):
(word, count) = word_count
return f'{word}: {count}'
def run(argv=None):
options = PipelineOptions(argv)
with beam.Pipeline(options=options) as p:
(p | 'ReadLines' >> beam.io.ReadFromText('input.txt')
| 'SplitWords' >> beam.FlatMap(split_words)
| 'PairWithOne' >> beam.Map(lambda word: (word, 1))
| 'GroupAndSum' >> beam.CombinePerKey(sum)
| 'FormatResult' >> beam.Map(format_result)
| 'WriteResults' >> beam.io.WriteToText('output'))
if __name__ == '__main__':
run()
参考链接:


