Flink简介
Apache Flink是一个开源的流处理框架,旨在提供高性能、低延迟的实时数据流处理能力,同时支持批处理任务。Flink以其强大的流处理能力、灵活的API和丰富的生态系统而广受欢迎。

Flink核心特性
处理无界和有界数据
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态的计算。Flink被设计为在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
数据可以作为无界流或有界流被处理
- Unbounded streams(无界流)有一个起点,但没有定义的终点。它们不会终止,而且会源源不断的提供数据。无边界的流必须被连续地处理,即事件达到后必须被立即处理。等待所有输入数据到达是不可能的,因为输入是无界的,并且在任何时间点都不会完成。处理无边界的数据通常要求以特定顺序(例如,事件发生的顺序)接收事件,以便能够推断出结果的完整性。
- Bounded streams(有界流)有一个定义的开始和结束。在执行任何计算之前,可以通过摄取(提取)所有数据来处理有界流。处理有界流不需要有序摄取,因为有界数据集总是可以排序的。有界流的处理也称为批处理。
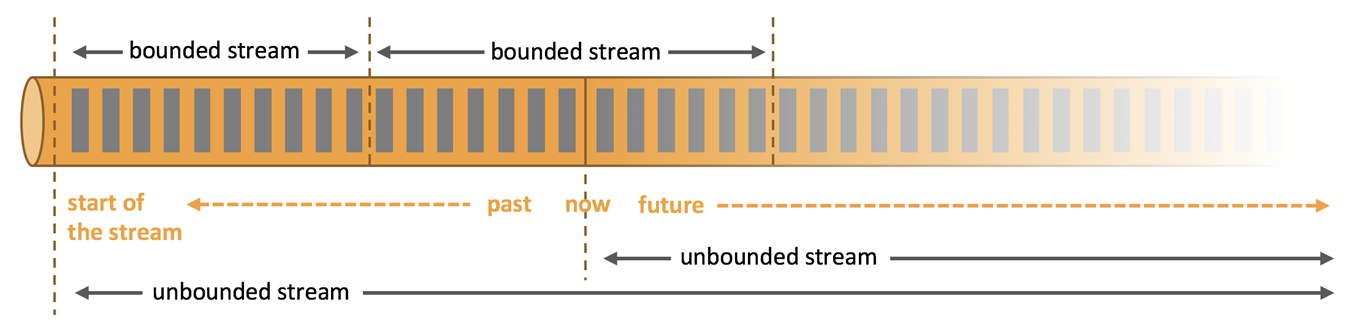
Apache Flink擅长处理无界和有界数据集。对时间和状态的精确控制使Flink的运行时能够在无边界的流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部处理,从而产生出色的性能。
部署应用程序在任何地方
Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink可以与所有常见的群集资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立群集运行。
Flink被设计为能够很好地工作于前面列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,该模式允许Flink以惯用的方式与每个资源管理器进行交互。
部署Flink应用程序时,Flink会根据该应用程序配置自动识别所需的资源,并向资源管理器请求。如果发生故障,Flink会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信均通过REST调用进行。这简化了Flink在许多环境中的集成。
部署应用程序在任何地方
Flink的设计目的是在任何规模上运行有状态流应用程序。应用程序可能被并行化为数千个任务,这些任务分布在集群中并同时执行。因此,一个应用程序可以利用几乎无限数量的cpu、主内存、磁盘和网络IO。而且,Flink很容易维护非常大的应用程序状态。它的异步和增量检查点算法确保对处理延迟的影响最小,同时保证精确一次(exactly-once)状态一致性。
利用内存性能
有状态的Flink应用程序针对本地状态访问进行了优化。任务状态始终在内存中维护,如果状态大小超过可用内存,则在访问高效的磁盘数据结构中维护。因此,任务通过访问本地(通常在内存中)状态来执行所有计算,从而产生非常低的处理延迟。通过定期异步将本地状态检查点指向持久存储,Flink确保了故障发生时的一次状态一致性。
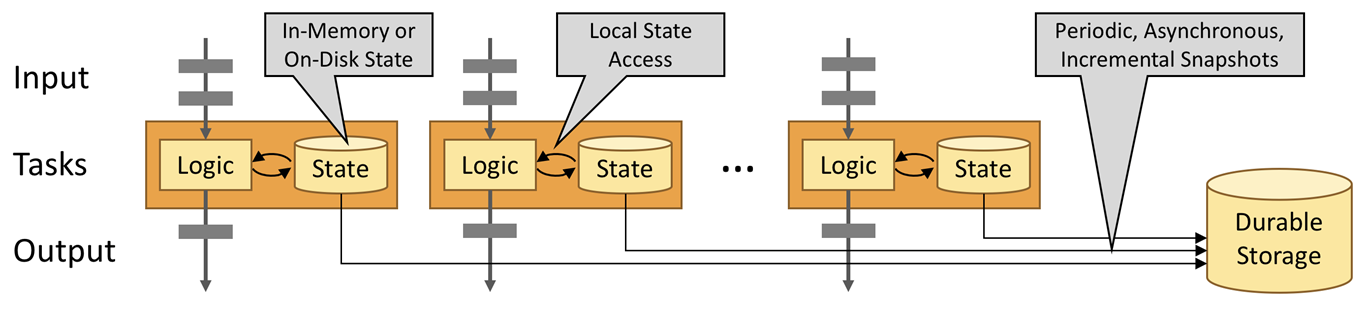
流应用程序的构建块
流应用程序的类型由框架控制流、状态和时间的能力来定义Streams(流)
Flink是一个通用的处理框架,可以处理任何类型的流。
- Bounded and unbounded streams: 流可以是无边界的,也可以是有边界的。Flink具有复杂的特性来处理无界流,但也有专门的操作符来高效地处理有界流。
- Real-time and recorded streams: 所有数据都以流的形式生成。有两种处理数据的方法。在生成流时对其进行实时处理,或将流持久化到存储系统,并在以后进行处理。Flink应用程序可以处理记录的流和实时流。
State(状态)
每个重要的流应用程序都是有状态的,只有在个别事件上应用转换的应用程序才不需要状态。任何运行基本业务逻辑的应用程序都需要记住事件或中间结果,以便在稍后的时间点访问它们,例如在接收下一个事件时或在特定的持续时间之后。

在Flink中,应用程序状态是非常重要的。这一点在很多地方都有体现:
- Multiple State Primitives: Flink为不同的数据结构(例如,原子值、list、map等)提供状态原语
- Pluggable State Backends: 应用程序状态由可插入状态后端管理并进行检查点
- Exactly-once state consistency: Flink的检查点和恢复算法保证了故障情况下应用状态的一致性
- Very Large State: 由于其异步和增量检查点算法,Flink能够维护几个tb大小的应用程序状态
- Scalable Applications: 通过将状态重新分配给更多或更少的worker,Flink支持有状态应用程序的伸缩
Time(时间)
时间是流应用程序的另一个重要组成部分。大多数事件流具有固有的时间语义,因为每个事件都是在特定的时间点产生的。此外,许多常见的流计算都是基于时间的,比如窗口聚合、会话、模式检测和基于时间的连接。流处理的一个重要方面是应用程序如何度量时间,即事件时间和处理时间的差异。
Flink提供了一组丰富的与时间相关的特性:
- Event-time Mode: 使用事event-time语义处理流的应用程序根据事件的时间戳计算结果。因此,无论是处理记录的事件还是实时事件,事件时间处理都可以提供准确一致的结果。
- Watermark Support: Flink在事件时间应用程序中使用水印来推断时间。水印还是权衡结果的延迟和完整性的灵活机制。
- Late Data Handling: 在带有水印的事件时间模式下处理流时,可能会发生所有相关事件到达之前已经完成计算的情况。这种事件称为迟发事件。Flink具有多个选项来处理较晚的事件,例如通过侧面输出重新路由它们并更新先前完成的结果。
- Processing-time Mode: 除了event-time模式外,Flink还支持processing-time语义。处理时间模式可能适合具有严格的低延迟要求的某些应用程序,这些应用程序可以忍受近似结果。
分层API
Flink提供了三层API。每个API在简洁性和表达性之间提供了不同的权衡,并且针对不同的使用场景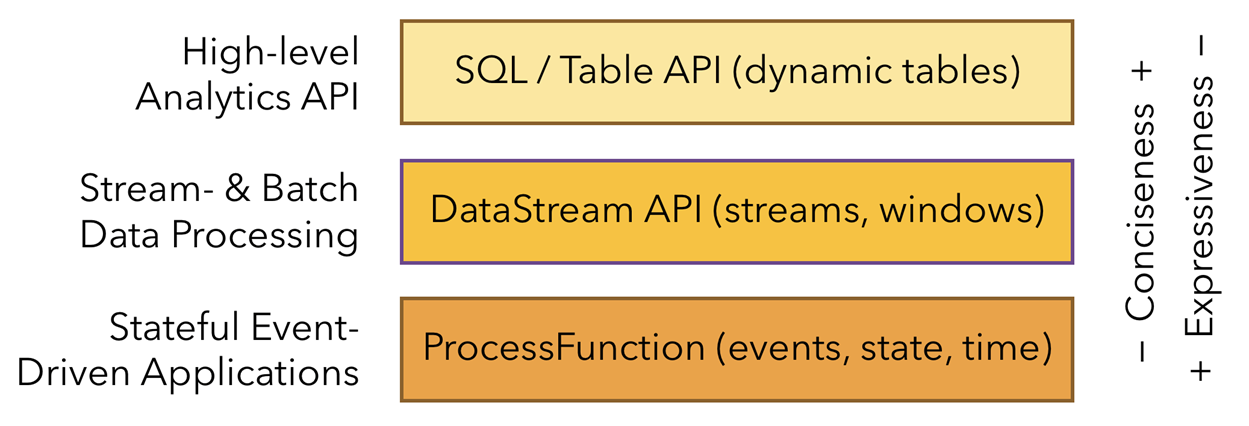
Stateful Functions
Stateful Functions 是一个 API,它简化了分布式有状态应用程序的构建。
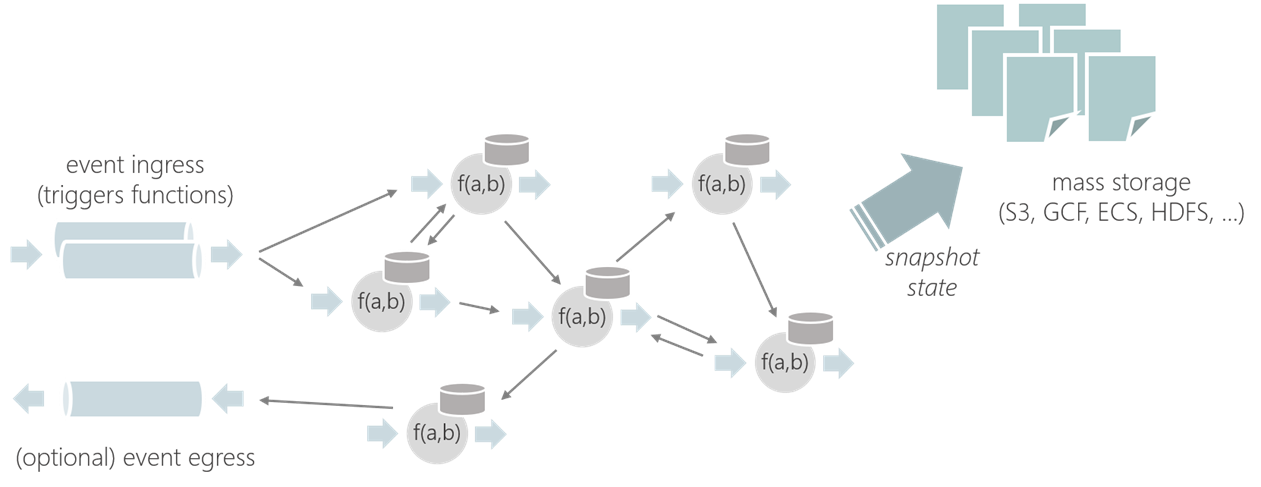
Flink 应用场景
Apache Flink 是开发和运行许多不同类型应用程序的最佳选择,因为它具有丰富的特性。Flink 的特性包括支持流和批处理、复杂的状态管理、事件处理语义以及确保状态的一致性。此外,Flink 可以部署在各种资源提供程序上,例如 YARN、Apache Mesos 和 Kubernetes,也可以作为裸机硬件上的独立集群进行部署。配置为高可用性,Flink 没有单点故障。Flink 已经被证明可以扩展到数千个内核和 TB 级的应用程序状态,提供高吞吐量和低延迟,并支持世界上一些最苛刻的流处理应用程序。
下面是 Flink 支持的最常见的应用程序类型:
- Event-driven Applications(事件驱动的应用程序)
- Data Analytics Applications(数据分析应用程序)
- Data Pipeline Applications(数据管道应用程序)
Event-driven Applications
事件驱动的应用程序是一个有状态的应用程序,它从一个或多个事件流中获取事件,并通过触发计算、状态更新或外部操作对传入的事件作出反应。
事件驱动的应用程序基于有状态的流处理应用程序。在这种设计中,数据和计算被放在一起,从而可以进行本地(内存或磁盘)数据访问。通过定期将检查点写入远程持久存储,可以实现容错。下图描述了传统应用程序体系结构和事件驱动应用程序之间的区别。
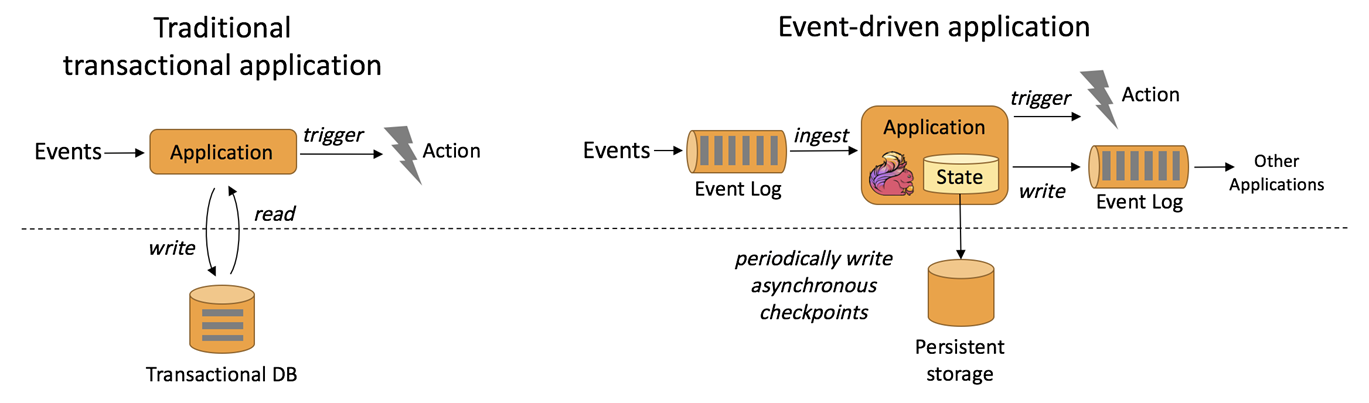
代替查询远程数据库,事件驱动的应用程序在本地访问其数据,从而在吞吐量和延迟方面获得更好的性能。可以定期异步地将检查点同步到远程持久存,而且支持增量同步。不仅如此,在分层架构中,多个应用程序共享同一个数据库是很常见的。因此,数据库的任何更改都需要协调,由于每个事件驱动的应用程序都负责自己的数据,因此更改数据表示或扩展应用程序所需的协调较少。
对于事件驱动的应用程序,Flink 的突出特性是 savepoint。保存点是一个一致的状态镜像,可以用作兼容应用程序的起点。给定一个保存点,就可以更新或调整应用程序的规模,或者可以启动应用程序的多个版本进行 A/B 测试。
典型的事件驱动的应用程序有:
- 欺诈检测
- 异常检测
- 基于规则的提醒
- 业务流程监控
- Web 应用(社交网络)
Data Analytics Applications
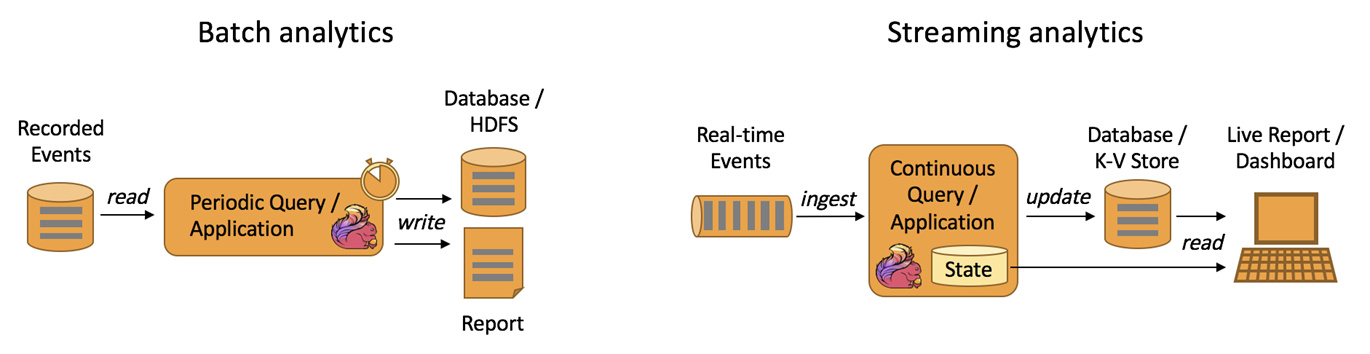
传统上的分析是作为批处理查询或应用程序对已记录事件的有限数据集执行的。为了将最新数据合并到分析结果中,必须将其添加到分析数据集中,然后重新运行查询或应用程序,结果被写入存储系统或作为报告发出。
有了复杂的流处理引擎,分析也可以以实时方式执行。流查询或应用程序不是读取有限的数据集,而是接收实时事件流,并在使用事件时不断地生成和更新结果。结果要么写入外部数据库,要么作为内部状态进行维护。Dashboard 应用程序可以从外部数据库读取最新的结果,也可以直接查询应用程序的内部状态。
Apache Flink 支持流以及批处理分析应用程序,如下图所示:
典型的数据分析应用程序有:
- 电信网络质量监控
- 产品更新分析及移动应用实验评估
- 消费者技术中实时数据的特别分析
- 大规模图分析
Data Pipeline Applications
提取-转换-加载(ETL)是在存储系统之间转换和移动数据的常用方法。通常,会定期触发 ETL 作业,以便将数据从事务性数据库系统复制到分析数据库或数据仓库。
数据管道的作用类似于 ETL 作业。它们转换和丰富数据,并可以将数据从一个存储系统移动到另一个存储系统。但是,它们以连续流模式运行,而不是周期性地触发。因此,它们能够从不断产生数据的源读取记录,并以低延迟将其移动到目的地。例如,数据管道可以监视文件系统目录中的新文件,并将它们的数据写入事件日志。另一个应用程序可能将事件流物化到数据库,或者增量地构建和完善搜索索引。
下图描述了周期性 ETL 作业和连续数据管道之间的差异:
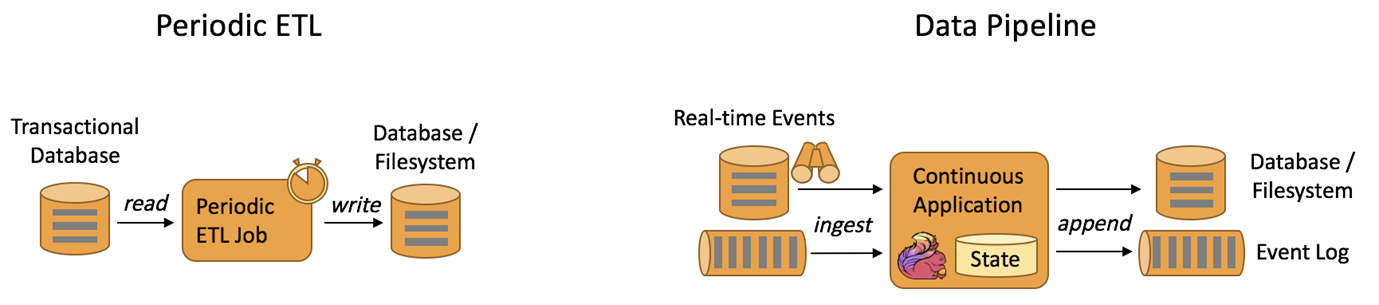
与周期性 ETL 作业相比,连续数据管道的明显优势是减少了将数据移至其目的地的等待时间。此外,数据管道更通用,可用于更多场景,因为它们能够连续消费和产生数据。
典型的数据管道应用程序有:
- 电商中实时搜索索引的建立
- 电商中的持续 ETL
Flink 的架构
基本概念
Stream & Transformation & Operator
用户实现的 Flink 程序是由 Stream 和 Transformation 这两个基本构建块组成,其中 Stream 是一个中间结果数据,而 Transformation 是一个操作,它对一个或多个输入 Stream 进行计算处理,输出一个或多个结果 Stream。
当一个 Flink 程序被执行的时候,它会被映射为 Streaming Dataflow。
一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成,它类似于一个 DAG 图,在启动的时候从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
下面是一个由 Flink 程序映射为 Streaming Dataflow 的示意图,如下所示:
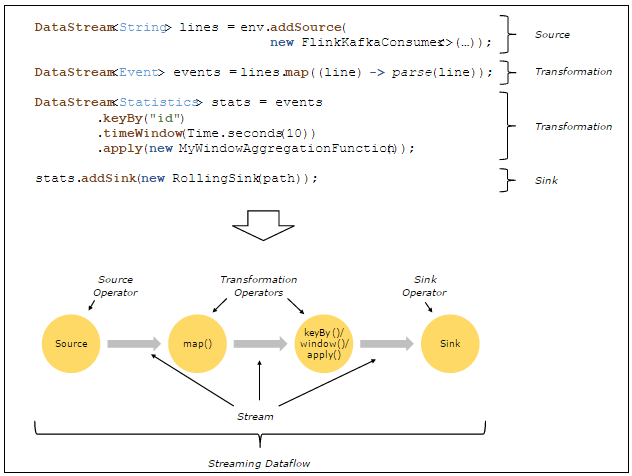
上图中,Flink Kafka Consumer 是一个 Source Operator,map、keyBy、timeWindow、apply 是 Transformation Operator,Rolling Sink 是一个 Sink Operator。
Parallel Dataflow
在 Flink 中,程序天生是并行和分布式的:
- 一个 Stream 可以被分成多个 Stream 分区(Stream Partitions),一个 Operator 可以被分成多个 Operator Subtask,每一个 Operator Subtask 是在不同的线程中独立执行的。
- 一个 Operator 的并行度,等于 Operator Subtask 的个数,一个 Stream 的并行度总是等于生成它的 Operator 的并行度。
有关 Parallel Dataflow 的实例,如下图所示:
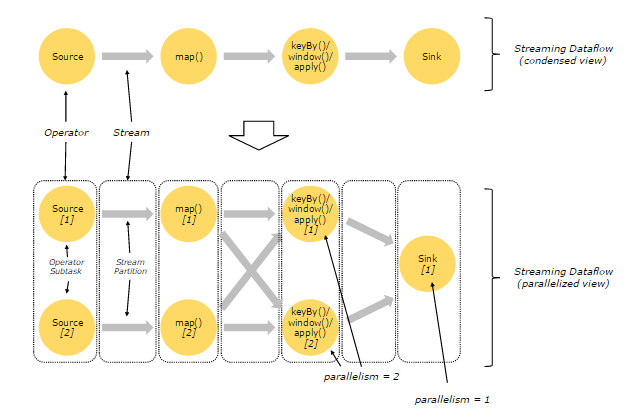
上图 Streaming Dataflow 的并行视图中,展现了在两个 Operator 之间的 Stream 的两种模式:
One-to-one 模式比如从 Source[1] 到 map()[1],它保持了 Source 的分区特性(Partitioning)和分区内元素处理的有序性。
也就是说 map()[1] 的 Subtask 看到数据流中记录的顺序,与 Source[1] 中看到的记录顺序是一致的。
Redistribution 模式
这种模式改变了输入数据流的分区。
比如从 map()[1]、map()[2] 到 keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的 Subtask 向下游的多个不同的 Subtask 发送数据,改变了数据流的分区,这与实际应用所选择的 Operator 有关系。
另外,SourceOperator 对应 2 个 Subtask,所以并行度为 2,而 SinkOperator 的 Subtask 只有 1 个,故而并行度为 1。
Task&OperatorChain
在 Flink 分布式执行环境中,会将多个 OperatorSubtask 串起来组成一个 OperatorChain,实际上就是一个执行链。
每个执行链会在 TaskManager 上一个独立的线程中执行,如下图所示:
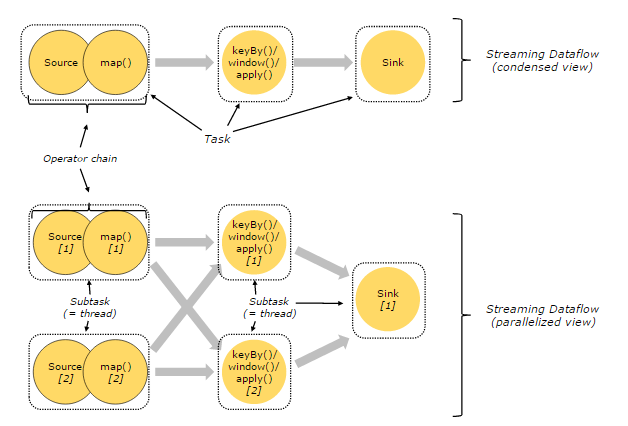
图中上半部分表示的是一个 OperatorChain,多个 Operator 通过 Stream 连接,而每个 Operator 在运行时对应一个 Task。
图中下半部分是上半部分的一个并行版本,也就是对每一个 Task 都并行化为多个 Subtask。
Time&Window
Flink 支持基于时间窗口操作,也支持基于数据的窗口操作,如下图所示:
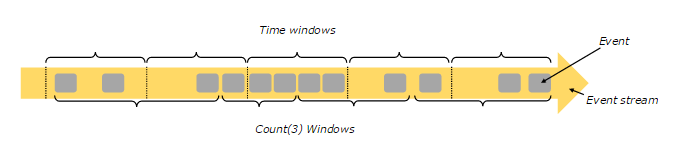
上图中,基于时间的窗口操作,在每个相同的时间间隔对 Stream 中的记录进行处理,通常各个时间间隔内的窗口操作处理的记录数不固定。
而基于数据驱动的窗口操作,可以在 Stream 中选择固定数量的记录作为一个窗口,对该窗口中的记录进行处理。
有关窗口操作的不同类型,可以分为如下几种:
- 倾斜窗口(TumblingWindows,记录没有重叠)
- 滑动窗口(SlideWindows,记录有重叠)
- 会话窗口(SessionWindows)
在处理 Stream 中的记录时,记录中通常会包含各种典型的时间字段,Flink 支持多种时间的处理,如下图所示:
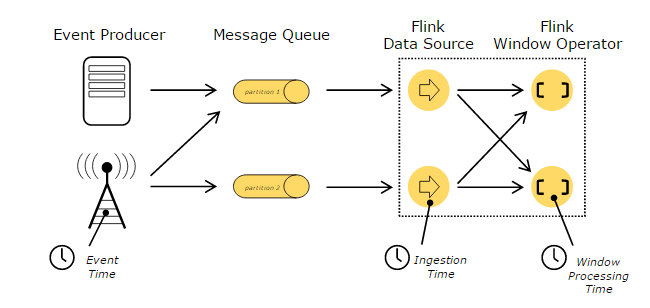
上图描述了在基于 Flink 的流处理系统中,各种不同的时间所处的位置和含义。
其中:
- EventTime 表示事件创建时间
- IngestionTime 表示事件进入到 Flink Dataflow 的时间
- ProcessingTime 表示某个 Operator 对事件进行处理事的本地系统时间(是在 TaskManager 节点上)。
这里,谈一下基于 EventTime 进行处理的问题。
通常根据 EventTime 会给整个 Streaming 应用带来一定的延迟性,因为在一个基于事件的处理系统中,进入系统的事件可能会基于 EventTime 而发生乱序现象。
比如事件来源于外部的多个系统,为了增强事件处理吞吐量会将输入的多个 Stream 进行自然分区,每个 Stream 分区内部有序,但是要保证全局有序必须同时兼顾多个 Stream 分区的处理,设置一定的时间窗口进行暂存数据,当多个 Stream 分区基于 EventTime 排列对齐后才能进行延迟处理。
所以,设置的暂存数据记录的时间窗口越长,处理性能越差,甚至严重影响 Stream 处理的实时性。
有关基于时间的 Streaming 处理,可以参考官方文档,在 Flink 中借鉴了 Google 使用的 WaterMark 实现方式,可以查阅相关资料。
基本架构
Flink 系统的架构与 Spark 类似,是一个基于 Master-Slave 风格的架构,如下图所示:
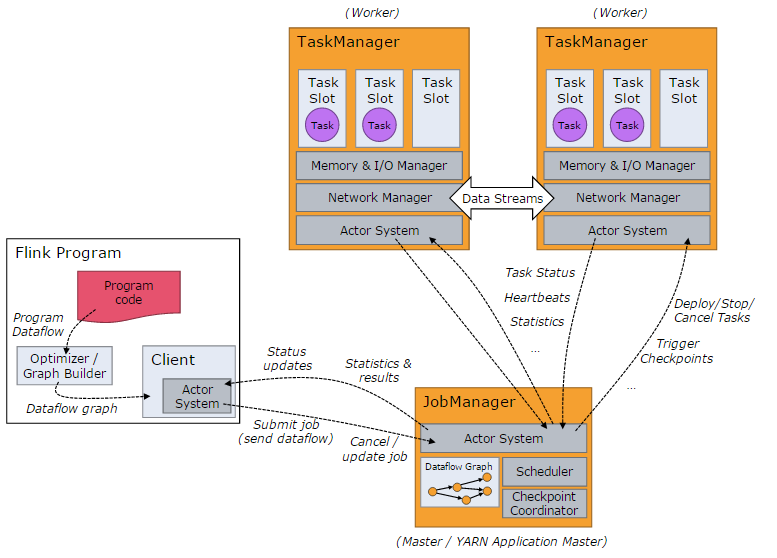
Flink 集群启动时,会启动一个 JobManager 进程、至少一个 TaskManager 进程。
在 Local 模式下,会在同一个 JVM 内部启动一个 JobManager 进程和 TaskManager 进程。
当 Flink 程序提交后,会创建一个 Client 来进行预处理,并转换为一个并行数据流,这是对应着一个 Flink Job,从而可以被 JobManager 和 TaskManager 执行。
在实现上,Flink 基于 Actor 实现了 JobManager 和 TaskManager,所以 JobManager 与 TaskManager 之间的信息交换,都是通过事件的方式来进行处理。
如上图所示,Flink 系统主要包含如下 3 个主要的进程:
JobManager
JobManager 是 Flink 系统的协调者,它负责接收 Flink Job,调度组成 Job 的多个 Task 的执行。
同时,JobManager 还负责收集 Job 的状态信息,并管理 Flink 集群中从节点 TaskManager。
JobManager 所负责的各项管理功能,它接收到并处理的事件主要包括:
- RegisterTaskManager:在 Flink 集群启动的时候,TaskManager 会向 JobManager 注册,如果注册成功,则 JobManager 会向 TaskManager 回复消息 AcknowledgeRegistration。
- SubmitJob:Flink 程序内部通过 Client 向 JobManager 提交 Flink Job,其中在消息 SubmitJob 中以 JobGraph 形式描述了 Job 的基本信息。
- CancelJob:请求取消一个 Flink Job 的执行,CancelJob 消息中包含了 Job 的 ID,如果成功则返回消息 CancellationSuccess,失败则返回消息 CancellationFailure。
- UpdateTaskExecutionState:TaskManager 会向 JobManager 请求更新 ExecutionGraph 中的 ExecutionVertex 的状态信息,更新成功则返回 true。
- RequestNextInputSplit:运行在 TaskManager 上面的 Task,请求获取下一个要处理的输入 Split,成功则返回 NextInputSplit。
- JobStatusChanged:ExecutionGraph 向 JobManager 发送该消息,用来表示 Flink Job 的状态发生的变化,例如:RUNNING、CANCELING、FINISHED 等。
TaskManager
TaskManager 也是一个 Actor,它是实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task。
每个 TaskManager 负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向 JobManager 汇报。
TaskManager 端可以分成两个阶段:
- 注册阶段:TaskManager 会向 JobManager 注册,发送 RegisterTaskManager 消息,等待 JobManager 返回 AcknowledgeRegistration,然后 TaskManager 就可以进行初始化过程。
- 可操作阶段:该阶段 TaskManager 可以接收并处理与 Task 有关的消息,如 SubmitTask、CancelTask、FailTask。
如果 TaskManager 无法连接到 JobManager,这是 TaskManager 就失去了与 JobManager 的联系,会自动进入“注册阶段”,只有完成注册才能继续处理 Task 相关的消息。Client
当用户提交一个Flink程序时,会首先创建一个Client。
该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
Client会将用户提交的Flink程序组装一个JobGraph,并且是以JobGraph的形式提交的。
一个JobGraph是一个Flink Dataflow,它由多个JobVertex组成的DAG。
其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配置信息、一组JobVertex等。
组件栈
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。Flink分层的组件栈如下图所示:
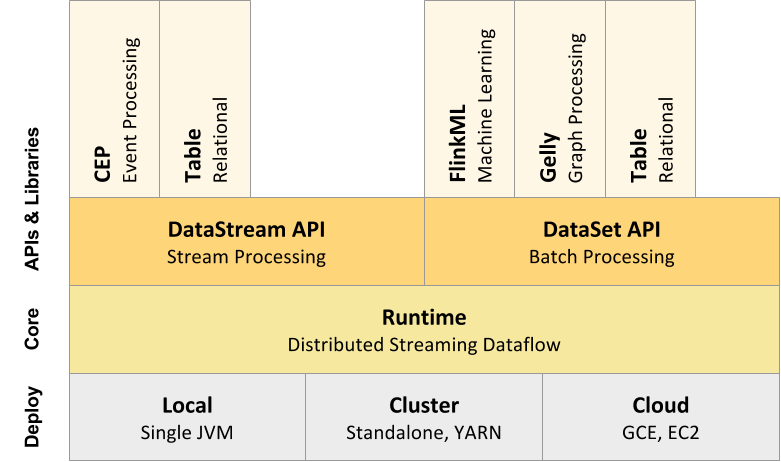
我们自下而上,分别针对每一层进行解释说明。
Deployment层
该层主要涉及了Flink的部署模式,Flink支持多种部署模式:
- 本地、集群(Standalone/YARN)
- 云(GCE/EC2)
- Standalone部署模式与Spark类似。
这里,我们看一下Flink on YARN的部署模式,如下图所示:
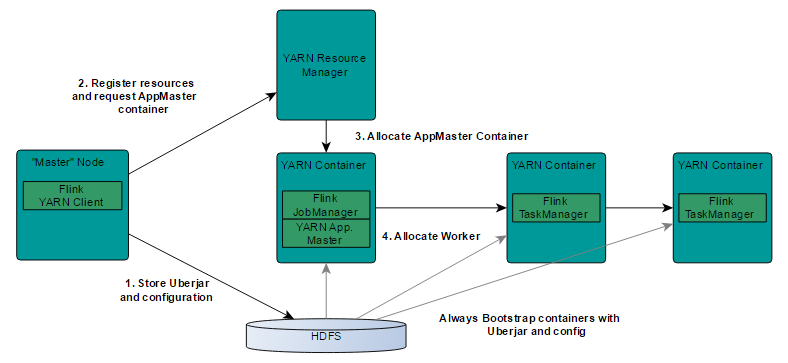
了解YARN的话,对上图的原理非常熟悉,实际Flink也实现了满足在YARN集群上运行的各个组件:
- Flink YARN Client负责与YARN RM通信协商资源请求
- Flink JobManager和Flink TaskManager分别申请到Container去运行各自的进程。
通过上图可以看到,YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。
待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。
Runtime层
Runtime层提供了支持Flink计算的全部核心实现,比如:
- 支持分布式Stream处理
- JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层
API层主要实现了面向无界Stream的流处理和面向Batch的批处理API。
其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层
该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。
- 面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);
- 面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
内部原理
容错机制
Flink基于Checkpoint机制实现容错,它的原理是不断地生成分布式Streaming数据流Snapshot。
在流处理失败时,通过这些Snapshot可以恢复数据流处理。
Barrier
理解Flink的容错机制,首先需要了解一下Barrier这个概念:
- Stream Barrier是Flink分布式Snapshotting中的核心元素,它会作为数据流的记录被同等看待,被插入到数据流中,将数据流中记录的进行分组,并沿着数据流的方向向前推进。
- 每个Barrier会携带一个Snapshot ID,属于该Snapshot的记录会被推向该Barrier的前方。因为Barrier非常轻量,所以并不会中断数据流。带有Barrier的数据流。
如下图所示:
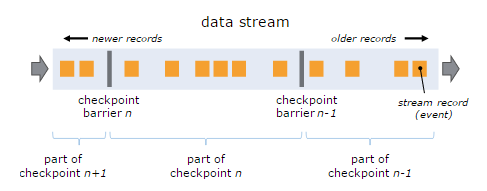
基于上图,我们通过如下要点来说明:
- 出现一个Barrier,在该Barrier之前出现的记录都属于该Barrier对应的Snapshot,在该Barrier之后出现的记录属于下一个Snapshot。
- 来自不同Snapshot多个Barrier可能同时出现在数据流中,也就是说同一个时刻可能并发生成多个Snapshot。
- 当一个中间(Intermediate)Operator接收到一个Barrier后,它会发送Barrier到属于该Barrier的Snapshot的数据流中,等到Sink Operator接收到该Barrier后会向Checkpoint Coordinator确认该Snapshot。
- 直到所有的Sink Operator都确认了该Snapshot,才被认为完成了该Snapshot。
这里还需要强调的是,Snapshot并不仅仅是对数据流做了一个状态的Checkpoint,它也包含了一个Operator内部所持有的状态,这样才能够在保证在流处理系统失败时能够正确地恢复数据流处理。
也就是说,如果一个Operator包含任何形式的状态,这种状态必须是Snapshot的一部分。
Operator State
Operator的状态包含两种:
- 一种是系统状态,一个Operator进行计算处理的时候需要对数据进行缓冲,所以数据缓冲区的状态是与Operator相关联的,以窗口操作的缓冲区为例,Flink系统会收集或聚合记录数据并放到缓冲区中,直到该缓冲区中的数据被处理完成;
- 另一种是用户自定义状态(状态可以通过转换函数进行创建和修改),它可以是函数中的Java对象这样的简单变量,也可以是与函数相关的Key/Value状态。
对于具有轻微状态的Streaming应用,会生成非常轻量的Snapshot而且非常频繁,但并不会影响数据流处理性能。
Streaming应用的状态会被存储到一个可配置的存储系统中,例如HDFS。
在一个Checkpoint执行过程中,存储的状态信息及其交互过程,如下图所示:
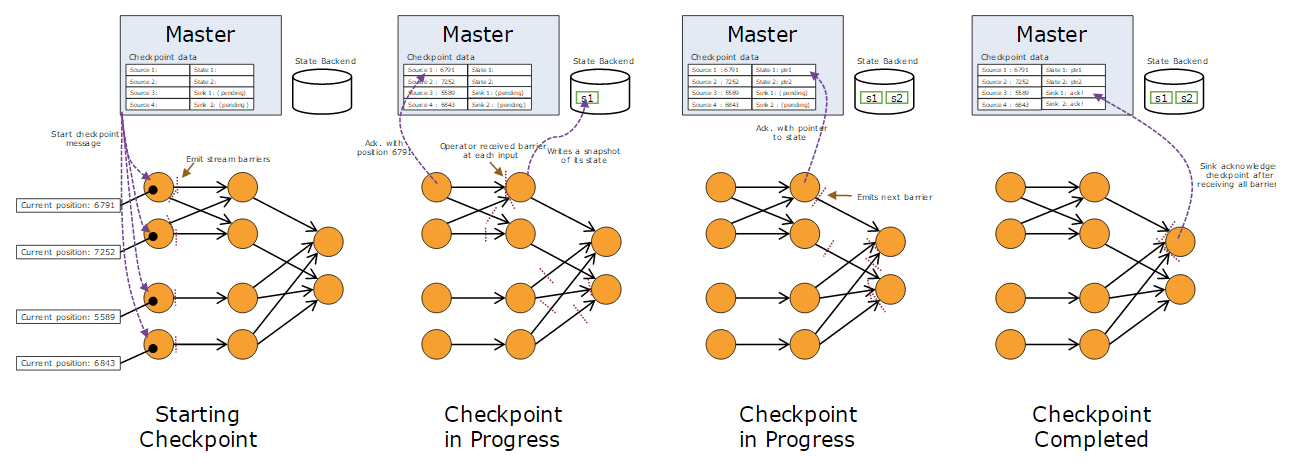
Stream Aligning
在Checkpoint过程中,还有一个比较重要的操作——Stream Aligning。
当Operator接收到多个输入的数据流时,需要在Snapshot Barrier中对数据流进行排列对齐,如下图所示:
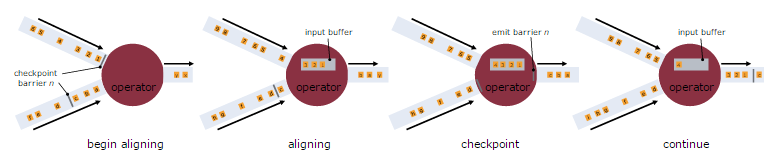
具体排列过程如下:
- Operator从一个incoming Stream接收到Snapshot Barrier n,然后暂停处理,直到其它的incoming Stream的Barrier n(否则属于2个Snapshot的记录就混在一起了)到达该Operator。
- 接收到Barrier n的Stream被临时搁置,来自这些Stream的记录不会被处理,而是被放在一个Buffer中
- 一旦最后一个 Stream 接收到 Barrier n,Operator 会 emit 所有暂存在 Buffer 中的记录,然后向 CheckpointCoordinator 发送 Snapshot n
- 继续处理来自多个 Stream 的记录
基于 StreamAligning 操作能够实现 ExactlyOnce 语义,但是也会给流处理应用带来延迟,因为为了排列对齐 Barrier,会暂时缓存一部分 Stream 的记录到 Buffer 中。
尤其是在数据流并行度很高的场景下可能更加明显,通常以最迟对齐 Barrier 的一个 Stream 为处理 Buffer 中缓存记录的时刻点。
在 Flink 中,提供了一个开关,选择是否使用 StreamAligning,如果关掉则 ExactlyOnce 会变成 Atleastonce。
调度机制
在 JobManager 端,会接收到 Client 提交的 JobGraph 形式的 FlinkJob。
JobManager 会将一个 JobGraph 转换映射为一个 ExecutionGraph,如下图所示:
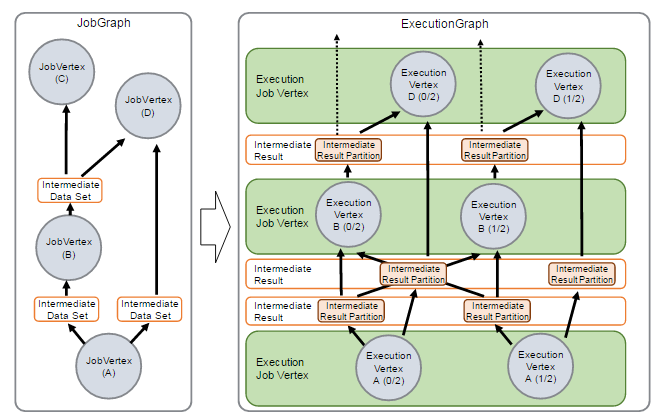
通过上图可以看出:
- JobGraph 是一个 Job 的用户逻辑视图表示,将一个用户要对数据流进行的处理表示为单个 DAG 图(对应于 JobGraph)
- DAG 图由顶点(JobVertex)和中间结果集(IntermediateDataSet)组成,
- 其中 JobVertex 表示了对数据流进行的转换操作,比如 map、flatMap、filter、keyBy 等操作,而 IntermediateDataSet 是由上游的 JobVertex 所生成,同时作为下游的 JobVertex 的输入。
而 ExecutionGraph 是 JobGraph 的并行表示,也就是实际 JobManager 调度一个 Job 在 TaskManager 上运行的逻辑视图。
它也是一个 DAG 图,是由 ExecutionJobVertex、IntermediateResult(或 IntermediateResultPartition)组成
ExecutionJobVertex 实际对应于 JobGraph 图中的 JobVertex,只不过在 ExecutionJobVertex 内部是一种并行表示,由多个并行的 ExecutionVertex 所组成。
另外,这里还有一个重要的概念,就是 Execution,它是一个 ExecutionVertex 的一次运行 Attempt。
也就是说,一个 ExecutionVertex 可能对应多个运行状态的 Execution。
比如,一个 ExecutionVertex 运行产生了一个失败的 Execution,然后还会创建一个新的 Execution 来运行,这时就对应这个 2 次运行 Attempt。
每个 Execution 通过 ExecutionAttemptID 来唯一标识,在 TaskManager 和 JobManager 之间进行 Task 状态的交换都是通过 ExecutionAttemptID 来实现的。
下面看一下,在物理上进行调度,基于资源的分配与使用的一个例子,来自官网,如下图所示:
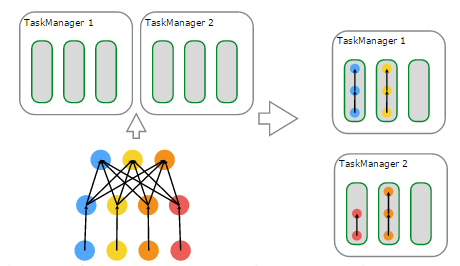
说明如下:
- 左上子图:有 2 个 TaskManager,每个 TaskManager 有 3 个 TaskSlot
- 左下子图:一个 FlinkJob,逻辑上包含了 1 个 datasource、1 个 MapFunction、1 个 ReduceFunction,对应一个 JobGraph
- 左下子图:用户提交的 FlinkJob 对各个 Operator 进行的配置——datasource 的并行度设置为 4,MapFunction 的并行度也为 4,ReduceFunction 的并行度为 3,在 JobManager 端对应于 ExecutionGraph
- 右上子图:TaskManager1 上,有 2 个并行的 ExecutionVertex 组成的 DAG 图,它们各占用一个 TaskSlot
- 右下子图:TaskManager2 上,也有 2 个并行的 ExecutionVertex 组成的 DAG 图,它们也各占用一个 TaskSlot
在 2 个 TaskManager 上运行的 4 个 Execution 是并行执行的
迭代机制
机器学习和图计算应用,都会使用到迭代计算。
Flink 通过在迭代 Operator 中定义 Step 函数来实现迭代算法,这种迭代算法包括 Iterate 和 DeltaIterate 两种类型,在实现上它们反复地在当前迭代状态上调用 Step 函数,直到满足给定的条件才会停止迭代。
下面,对 Iterate 和 DeltaIterate 两种类型的迭代算法原理进行说明:
Iterate
IterateOperator 是一种简单的迭代形式:
- 每一轮迭代,Step 函数的输入或者是输入的整个数据集,或者是上一轮迭代的结果,通过该轮迭代计算出下一轮计算所需要的输入(也称为 NextPartialSolution)
- 满足迭代的终止条件后,会输出最终迭代结果,具体执行流程如下图所示:
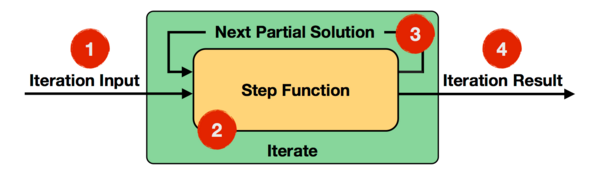
Step 函数在每一轮迭代中都会被执行,它可以是由 map、reduce、join 等 Operator 组成的数据流。
下面通过官网给出的一个例子来说明 IterateOperator,非常简单直观,如下图所示:
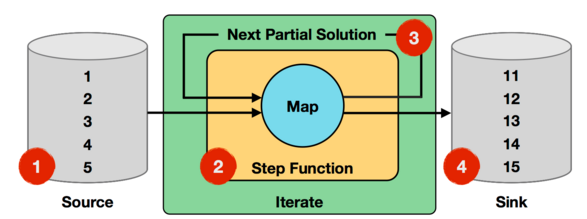
上面迭代过程中,输入数据为 1 到 5 的数字,Step 函数就是一个简单的 map 函数,会对每个输入的数字进行加 1 处理,而 NextPartialSolution 对应于经过 map 函数处理后的结果。
比如第一轮迭代,对输入的数字 1 加 1 后结果为 2,对输入的数字 2 加 1 后结果为 3,直到对输入数字 5 加 1 后结果为变为 6,这些新生成结果数字 2~6 会作为第二轮迭代的输入。
迭代终止条件为进行 10 轮迭代,则最终的结果为 11~15。
DeltaIterate
DeltaIterateOperator 实现了增量迭代,它的实现原理如下图所示:
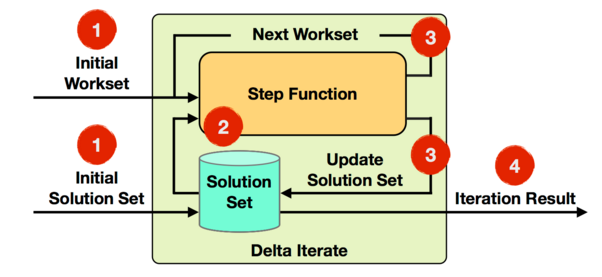
基于 DeltaIterateOperator 实现增量迭代,它有 2 个输入:
- 其中一个是初始 Workset,表示输入待处理的增量 Stream 数据
- 另一个是初始 SolutionSet,它是经过 Stream 方向上 Operator 处理过的结果。
第一轮迭代会将 Step 函数作用在初始 Workset 上,得到的计算结果 Workset 作为下一轮迭代的输入,同时还要增量更新初始 SolutionSet。
如果反复迭代知道满足迭代终止条件,最后会根据 SolutionSet 的结果,输出最终迭代结果。
比如,我们现在已知一个 Solution 集合中保存的是,已有的商品分类大类中购买量最多的商品。
而 Workset 输入的是来自线上实时交易中最新达成购买的商品的人数,经过计算会生成新的商品分类大类中商品购买量最多的结果。
如果某些大类中商品购买量突然增长,它需要更新 SolutionSet 中的结果(原来购买量最多的商品,经过增量迭代计算,可能已经不是最多),最后会输出最终商品分类大类中购买量最多的商品结果集合。
更详细的例子,可以参考官网给出的“PropagateMinimuminGraph”,这里不再累述。
Backpressure 监控机制
Backpressure 在流式计算系统中会比较受到关注。
因为在一个 Stream 上进行处理的多个 Operator 之间,它们处理速度和方式可能非常不同,所以就存在上游 Operator 如果处理速度过快,下游 Operator 处可能机会堆积 Stream 记录,严重会造成处理延迟或下游 Operator 负载过重而崩溃(有些系统可能会丢失数据)。
因此,对下游 Operator 处理速度跟不上的情况,如果下游 Operator 能够将自己处理状态传播给上游 Operator,使得上游 Operator 处理速度慢下来就会缓解上述问题,比如通过告警的方式通知现有流处理系统存在的问题。
Flink Web 界面上提供了对运行 Job 的 Backpressure 行为的监控,它通过使用 Sampling 线程对正在运行的 Task 进行堆栈跟踪采样来实现,具体实现方式如下图所示:
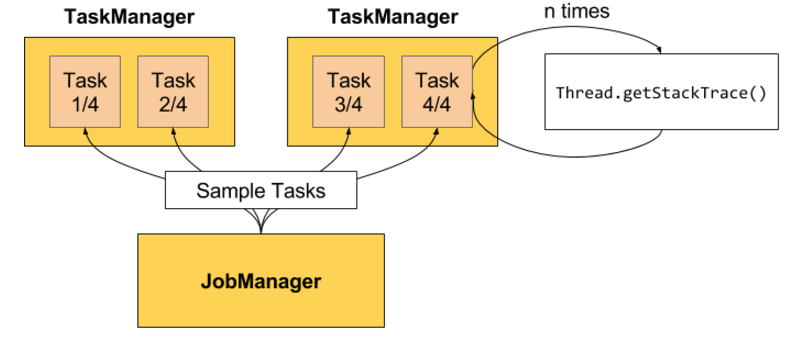
JobManager 会反复调用一个 Job 的 Task 运行所在线程的 Thread.getStackTrace()。
默认情况下,JobManager 会每间隔 50ms 触发对一个 Job 的每个 Task 依次进行 100 次堆栈跟踪调用,根据调用调用结果来确定 Backpressure,Flink 是通过计算得到一个比值(Radio)来确定当前运行 Job 的 Backpressure 状态。
在 Web 界面上可以看到这个 Radio 值,它表示在一个内部方法调用中阻塞(Stuck)的堆栈跟踪次数,例如,radio=0.01,表示 100 次中仅有 1 次方法调用阻塞。
Flink 目前定义了如下 Backpressure 状态:
- OK: 0<=Ratio<=0.10
- LOW: 0.10<Ratio<=0.5
- HIGH: 0.5<Ratio<=1
另外,Flink 还提供了 3 个参数来配置 Backpressure 监控行为:
| 参数名称 | 默认值 | 说明 |
| jobmanager.web.backpressure.refresh-interval | 60000 | 默认 1 分钟,表示采样统计结果刷新时间间隔 |
| jobmanager.web.backpressure.num-samples | 100 | 评估 Backpressure 状态,所使用的堆栈跟踪调用次数 |
| jobmanager.web.backpressure.delay-between-samples | 50 | 默认 50 毫秒,表示对一个 Job 的每个 Task 依次调用的时间间隔 |
通过上面个定义的 Backpressure 状态,以及调整相应的参数,可以确定当前运行的 Job 的状态是否正常,并且保证不影响 JobManager 提供服务。
Flink 的使用
Java 编写 Flink 程序
编写 Apache Flink 程序通常包括以下几个步骤:配置执行环境、定义数据源、编写数据处理逻辑、定义数据输出和执行作业。Flink 支持多种编程语言,其中 Java 和 Scala 是最常用的。以下是如何使用 Java 编写一个简单的 Flink 程序的步骤:
设置开发环境
- 安装 Java:确保安装了 Java 8 或更高版本。
- 安装 Maven:Flink 项目通常使用 Maven 进行管理和构建。
- 创建 Maven 项目:可以使用 Flink 提供的 Maven 原型来快速创建项目。
mvn archetype:generate\ -DarchetypeGroupId=org.apache.flink\ -DarchetypeArtifactId=flink-quickstart-java\ -DarchetypeVersion=1.16.0\ -DgroupId=org.example\ -DartifactId=flink-example\ -Dversion=0.1\ -Dpackage=org.example
编写 Flink 程序
打开生成的项目,在 src/main/java/org/example 目录下找到 StreamingJob.java 文件,并编写以下代码:
package org.example;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamingJob {
public static void main(String[] args) throws Exception {
//创建执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//定义数据源
DataStream<String> text = env.fromElements(
"Flink is a powerful stream processing framework",
"Flink provides high throughput and low latency");
//处理数据
DataStream<Tuple2<String, Integer>> wordCounts = text
.flatMap(new Tokenizer())
.keyBy(value -> value.f0)
.sum(1);
//输出结果
wordCounts.print();
//执行程序
env.execute("WordCount Example");
}
//自定义 FlatMapFunction
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
for (String word : value.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
编译和打包
使用 Maven 编译和打包你的 Flink 应用程序:
mvn clean package
这将生成一个可运行的 JAR 文件,通常位于 target 目录中。
提交和运行 Flink 作业
在本地或集群环境中启动 Flink 集群,然后使用以下命令提交作业:
./bin/flink run -c org.example.StreamingJob target/flink-example-0.1.jar
- -c 参数指定了包含 main 方法的类。
- target/flink-example-0.1.jar 是生成的 JAR 文件路径。
监控和调试
- Flink WebUI:访问 http://localhost:8081 查看 Flink WebUI,监控作业执行情况。
- 日志:在 logs 目录中查看 Flink 的日志文件,以获取有关作业执行的详细信息。
通过上述步骤,你可以使用 Java 编写一个简单的 Flink 流处理程序。Flink 提供了丰富的 API,如 DataStream API 和 Table API,可以用于处理复杂的流处理和批处理任务。根据具体需求,你可以进一步探索 Flink 的高级特性,如窗口操作、状态管理和事件时间处理。
Python 编写 Flink 程序
Apache Flink 支持使用 Python 编写流处理和批处理程序,主要通过 PyFlink 提供的 API 来实现。以下是使用 Python 编写 Flink 程序的基本步骤:
环境准备
- 安装 Java:确保安装了 Java 8 或更高版本,因为 Flink 依赖于 Java 运行环境。
- 安装 Apache Flink:从Apache Flink 官方网站 下载并解压 Flink。
- 安装 PyFlink:可以通过 pip 安装 PyFlink,这个包提供了在 Python 中使用 Flink 的功能。pip install apache-flink
编写 Flink 程序
使用 PyFlink 的 API 可以编写流处理或批处理程序。以下是一个简单的示例,演示如何使用 PyFlink 进行词频统计。
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream import TimeCharacteristic
from pyflink.table import StreamTableEnvironment
from pyflink.table import DataTypes
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
# 创建流执行环境
env = StreamExecutionEnvironment.get_execution_environment()
env.set_stream_time_characteristic(TimeCharacteristic.ProcessingTime)
# 创建表执行环境
table_env = StreamTableEnvironment.create(env)
# 定义数据源
input_path = 'path/to/input'
output_path = 'path/to/output'
table_env.connect(FileSystem().path(input_path))\
.with_format(OldCsv()
.field('word', DataTypes.STRING()))\
.with_schema(Schema()
.field('word', DataTypes.STRING()))\
.create_temporary_table('mySource')
table_env.connect(FileSystem().path(output_path))\
.with_format(OldCsv()
.field_delimiter(',')
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT()))\
.with_schema(Schema()
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT()))\
.create_temporary_table('mySink')
# 编写查询
table = table_env.from_path('mySource')
result = table.group_by(table.word)\
.select(table.word, table.word.count.alias('count'))
# 将结果插入到目标表
result.insert_into('mySink')
# 执行程序
env.execute('word_count')
运行 Flink 程序
- 本地运行:可以直接在本地运行上述 Python 脚本,确保 Flink 集群已启动(如果需要)。
- 集群运行:将 Python 脚本提交到 Flink 集群。可以使用 flink run 命令来运行 PyFlink 作业。./bin/flink run -py path/to/your_script.py
监控和调试
- Flink WebUI:通过 Flink 提供的 WebUI 监控作业执行情况。默认情况下,WebUI 运行在 http://localhost:8081。
- 日志检查:在 logs 目录中检查 Flink 的日志文件,以获取有关作业执行的详细信息。
通过 PyFlink,你可以使用 Python 编写和运行 Flink 程序。PyFlink 提供了与 Java 和 Scala 类似的 API,使得开发者能够在熟悉的编程语言中实现流处理和批处理逻辑。根据具体需求,可以进一步探索 PyFlink 的高级特性,如窗口操作、状态管理和事件时间处理。
参考链接:


