Hive内置了很多函数,可以参考Hive Built-In Functions。但是有些情况下,这些内置函数还是不能满足我们的需求,这时候就需要UDF出场了。
UDF全称:User-Defined Functions,即用户自定义函数,在Hive SQL编译成MapReduce任务时,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展。
Hive三种自定义函数:
- UDF(user-defined function)一进一出,给定一个输入,输出一个处理后的数据。许多Hive内置字符串,数学函数,时间函数都是这种类型。大多数情况下编写对应功能的处理函数就能满足需求。如:concat, split, length, rand等。这种UDF主要有两种写法:继承实现UDF类和继承GenericUDF类(通用UDF)。
- UDAF(user-defined aggregate function)多进一出,属于聚合函数,类似于count、sum等函数。一般配合group by使用。主要用于累加操作,常见的函数有max, min, count, sum, collect_set等。这种UDF主要有两种写法:继承实现UDAF类和继承实现AbstractGenericUDAFResolver类。
- UDTF(user-defined table function)一进多出,将输入的一行数据产生多行数据或者将一列打成多列。如explode函数通常配合lateral view使用,实现列转行的功能。parse_url_tuple将一列转为多列。
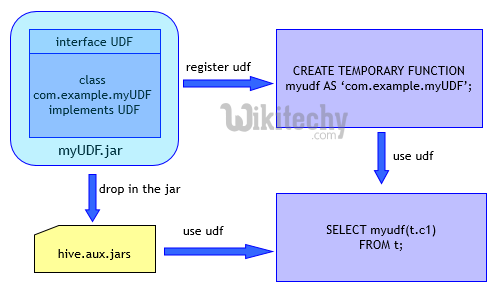
在决定编写自己的函数之前,可以先看看Hive中已经有了哪些函数及其功能:
- show functions; –查看已有函数
- describe function concat; –查看函数用法
- describe function extended concat; –查看函数的用法和示例
UDF(user-defined function)
Hive提供了两个实现UDF的方式:
第一种:继承UDF类
优点:
- 实现简单
- 支持Hive的基本类型、数组和Map
- 支持函数重载
缺点:
- 逻辑较为简单,只适合用于实现简单的函数
这种方式编码少,代码逻辑清晰,可以快速实现简单的UDF
第一种方式的代码实现最为简单,只需新建一个类继承UDF,然后编写evaluate()即可。
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 继承org.apache.hadoop.hive.ql.exec.UDF
*/
public class SimpleUDF extends UDF {
/**
* 编写一个函数,要求如下:
* 1.函数名必须为evaluate
* 2.参数和返回值类型可以为:Java基本类型、Java包装类、org.apache.hadoop.io.Writable等类型、List、Map
* 3.函数一定要有返回值,不能为void
*/
public int evaluate(int a, int b) {
return a + b;
}
/**
* 支持函数重载
*/
public Integer evaluate(Integer a, Integer b, Integer c) {
if(a == null || b == null || c == null)
return 0;
return a + b + c;
}
}
继承UDF类的方式非常简单,但还有一些需要注意的地方:
- evaluate()方法并不是继承自UDF类
- evaluate()的返回值类型不能为void
支持hive基本类型、数组和MapHive基本类型
Java可以使用Java原始类型、Java包装类或对应的Writable类对于基本类型,最好不要使用Java原始类型,当null传给Java原始类型参数时,UDF会报错。Java包装类还可以用于null值判断
| Hive类型 | Java原始类型 | Java包装类 | hadoop.io.Writable |
| tinyint | byte | Byte | ByteWritable |
| smallint | short | Short | ShortWritable |
| int | int | Integer | IntWritable |
| bigint | long | Long | LongWritable |
| string | String | – | Text |
| boolean | boolean | Boolean | BooleanWritable |
| float | float | Float | FloatWritable |
| double | double | Double | DoubleWritable |
数组和Map
| Hive类型 | Java类型 |
| array | List |
| Map<K,V> | Map<K,V> |
第二种:继承GenericUDF类
优点:
- 支持任意长度、任意类型的参数
- 可以根据参数个数和类型实现不同的逻辑
- 可以实现初始化和关闭资源的逻辑(initialize、close)
缺点:
- 实现比继承UDF要复杂一些
与继承UDF相比,GenericUDF更加灵活,可以实现更为复杂的函数
继承GenericUDF后,必须实现其三个方法:
- initialize()
- evaluate()
- getDisplayString()
initialize()
/** * 初始化 GenericUDF,每个 GenericUDF 示例只会调用一次初始化方法 * * @param arguments * 自定义 UDF 参数的 ObjectInspector 实例 * @throws UDFArgumentException * 参数个数或类型错误时,抛出该异常 * @return 函数返回值类型 */ public abstract ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException;
initialize() 在函数在 GenericUDF 初始化时被调用一次,执行一些初始化操作,包括:
- 判断函数参数个数
- 判断函数参数类型
- 确定函数返回值类型
除此之外,用户在这里还可以做一些自定义的初始化操作,比如初始化 HDFS 客户端等1. 判断函数参数个数
可通过 arguments 数组的长度来判断函数参数的个数
判断函数参数个数示例:
// 1. 参数个数检查,只有一个参数
if (arguments.length != 1) // 函数只接受一个参数
throw new UDFArgumentException("函数需要一个参数"); // 当自定义 UDF 参数与预期不符时,抛出异常
2. 判断函数参数类型
ObjectInspector 可用于侦测参数数据类型,其内部有一个枚举类 Category,代表了当前 ObjectInspector 的类型
public interface ObjectInspector extends Cloneable {
public static enum Category {
PRIMITIVE, // Hive 原始类型
LIST, // Hive 数组
MAP, // Hive Map
STRUCT, // 结构体
UNION // 联合体
};
}
Hive 原始类型又细分了多种子类型,PrimitiveObjectInspector 实现了 ObjectInspector,可以更加具体的表示对应的 Hive 原始类型
public interface PrimitiveObjectInspector extends ObjectInspector {
/**
* The primitive types supported by Hive.
*/
public static enum PrimitiveCategory {
VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,
DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,
UNKNOWN
};
}
参数类型判断示例:
// 2. 参数类型检查,参数类型为 String
if (arguments[0].getCategory() != ObjectInspector.Category.PRIMITIVE // 参数是 Hive 原始类型
|| !PrimitiveObjectInspector.PrimitiveCategory.STRING.equals(((PrimitiveObjectInspector)arguments[0]).getPrimitiveCategory())) // 参数是 Hive 的 string 类型
throw new UDFArgumentException("函数第一个参数为字符串"); // 当自定义 UDF 参数与预期不符时,抛出异常
3. 确定函数返回值类型
initialize() 需要 return 一个 ObjectInspector 实例,用于表示自定义 UDF 返回值类型。initialize() 的返回值决定了 evaluate() 的返回值类型
ObjectInspector 的源码中,有这么一段注释,其大意是 ObjectInspector 的实例应该由对应的工厂类获取,以保证实例的单例等属性
/**
* An efficient implementation of ObjectInspector should rely on factory, so
* that we can make sure the same ObjectInspector only has one instance. That
* also makes sure hashCode() and equals() method of java.lang.Object directly
* works for ObjectInspector as well.
*/
public interface ObjectInspector extends Cloneable {}
对于基本类型(byte、short、int、long、float、double、boolean、string),可以通过 PrimitiveObjectInspectorFactory 的静态字段直接获取
| Hive 类型 | writable 类型 | Java 包装类型 |
| tinyint | writableByteObjectInspector | javaByteObjectInspector |
| smallint | writableShortObjectInspector | javaShortObjectInspector |
| int | writableIntObjectInspector | javaIntObjectInspector |
| bigint | writableLongObjectInspector | javaLongObjectInspector |
| string | writableStringObjectInspector | javaStringObjectInspector |
| boolean | writableBooleanObjectInspector | javaBooleanObjectInspector |
| float | writableFloatObjectInspector | javaFloatObjectInspector |
| double | writableDoubleObjectInspector | javaDoubleObjectInspector |
注意:基本类型返回值有两种:Writable 类型和 Java 包装类型:
- 在 initialize 指定的返回值类型为 Writable 类型时,在 evaluate() 中 return 的就应该是对应的 Writable 实例
- 在 initialize 指定的返回值类型为 Java 包装类型时,在 evaluate() 中 return 的就应该是对应的 Java 包装类实例
Array、Map<K,V> 等复杂类型,则可以通过 ObjectInspectorFactory 的静态方法获取
| Hive 类型 | ObjectInspectorFactory 的静态方法 | evaluate() 返回值类型 |
| Array | getStandardListObjectInspector(T t) | List |
| Map<K,V> | Map<K,V> |
返回值类型为Map<String,int>的示例:
// 3. 自定义UDF返回值类型为Map<String,int> return ObjectInspectorFactory.getStandardMapObjectInspector( PrimitiveObjectInspectorFactory.javaStringObjectInspector, // Key是String PrimitiveObjectInspectorFactory.javaIntObjectInspector // Value是int );
完整的initialize()函数如下:
/**
* 初始化GenericUDF,每个GenericUDF示例只会调用一次初始化方法
*
* @param arguments
* 自定义UDF参数的ObjectInspector实例
* @throws UDFArgumentException
* 参数个数或类型错误时,抛出该异常
* @return 函数返回值类型
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 1. 参数个数检查,只有一个参数
if (arguments.length != 1) // 函数只接受一个参数
throw new UDFArgumentException("函数需要一个参数"); // 当自定义UDF参数与预期不符时,抛出异常
// 2. 参数类型检查,参数类型为String
if (arguments[0].getCategory() != ObjectInspector.Category.PRIMITIVE // 参数是Hive原始类型
|| !PrimitiveObjectInspector.PrimitiveCategory.STRING.equals(((PrimitiveObjectInspector)arguments[0]).getPrimitiveCategory())) // 参数是Hive的string类型
throw new UDFArgumentException("函数第一个参数为字符串"); // 当自定义UDF参数与预期不符时,抛出异常
// 3. 自定义UDF返回值类型为Map<String,int>
return ObjectInspectorFactory.getStandardMapObjectInspector(
PrimitiveObjectInspectorFactory.javaStringObjectInspector, // Key是String
PrimitiveObjectInspectorFactory.javaIntObjectInspector // Value是int
);
}
evaluate()
核心方法,自定义UDF的实现逻辑
代码实现步骤可以分为三部分:
- 参数接收
- 自定义UDF核心逻辑
- 返回处理结果
1. 参数接收
evaluate()的参数就是自定义UDF的参数
/** * Evaluate the GenericUDF with the arguments. * * @param arguments * The arguments as DeferedObject, use DeferedObject.get() to get the * actual argument Object. The Objects can be inspected by the * ObjectInspectors passed in the initialize call. * @return The */ public abstract Object evaluate(DeferredObject[] arguments) throws HiveException;
通过源码注释可知,DeferedObject.get()可以获取参数的值:
/**
* A DeferedObject allows us to do lazy-evaluation and short-circuiting.
* GenericUDF use DeferedObject to pass arguments.
*/
public static interface DeferredObject {
void prepare(int version) throws HiveException;
Object get() throws HiveException;
};
再看看DeferredObject的源码,DeferedObject.get()返回的是Object,传入的参数不同,会是不同的Java类型,以下是Hive常用参数类型对应的Java类型
对于Hive基本类型,传入的都是Writable类型
| Hive类型 | Java类型 |
| tinyint | ByteWritable |
| smallint | ShortWritable |
| int | IntWritable |
| bigint | LongWritable |
| string | Text |
| boolean | BooleanWritable |
| float | FloatWritable |
| double | DoubleWritable |
| Array | ArrayList |
| Map<K,V> | HashMap<K,V> |
参数接收示例:
// 只有一个参数:Map<String,int> // 1. 参数为null时的特殊处理 if (arguments[0] == null) return ... // 2. 接收参数 Map<Text, IntWritable> map = (Map<Text, IntWritable>) arguments[0].get();
2. 自定义UDF核心逻辑
获取参数之后,到这里就是自由发挥了~
3. 返回处理结果
这一步和initialize()的返回值一一对应
基本类型返回值有两种:Writable类型和Java包装类型:
- 在initialize指定的返回值类型为Writable类型时,在evaluate()中return的就应该是对应的Writable实例
- 在initialize指定的返回值类型为Java包装类型时,在evaluate()中return的就应该是对应的Java包装类实例
Hive数组和Map的返回值类型如下:
| Hive类型 | Java类型 |
| Array<T> | List<T> |
| Map<K,V> | Map<K,V> |
getDisplayString()getDisplayString()返回的是 explain 时展示的信息
/** * Get the String to be displayed in explain. */ public abstract String getDisplayString(String[] children);
注意:这里不能 return null,否则可能在运行时抛出空指针异常,而且这个出现这个问题还不容易排查~
ERROR [b1c82c24-bfea-4580-9a0c-ff47d7ef4dbe main] ql.Driver: FAILED: NullPointerException null
java.lang.NullPointerException
at java.util.regex.Matcher.getTextLength(Matcher.java:1283)
...
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
close()
资源关闭回调函数
不是抽象方法,可以不实现
/**
* Close GenericUDF.
* This is only called in runtime of MapRedTask.
*/
@Override
public void close() throws IOException {}
自定义 GenericUDF 完整示例
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class SimpleGenericUDF extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
// 1.参数个数检查
if (arguments.length != 1) // 函数只接受一个参数
throw new UDFArgumentException("函数需要一个参数"); // 当自定义 UDF 参数与预期不符时,抛出异常
// 2.参数类型检查
if (arguments[0].getCategory() != ObjectInspector.Category.PRIMITIVE // 参数是 Hive 原始类型
|| !PrimitiveObjectInspector.PrimitiveCategory.STRING.equals(((PrimitiveObjectInspector) arguments[0]).getPrimitiveCategory())) // 参数是 Hive 的 string 类型
throw new UDFArgumentException("函数第一个参数为字符串"); // 当自定义 UDF 参数与预期不符时,抛出异常
// 3.自定义 UDF 返回值类型为 Map<String, int>
return ObjectInspectorFactory.getStandardMapObjectInspector(
PrimitiveObjectInspectorFactory.javaStringObjectInspector, // Key 是 String
PrimitiveObjectInspectorFactory.javaIntObjectInspector // Value 是 int
);
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
// 1.参数接收
if (arguments[0] == null)
return new HashMap<>();
String str = ((Text) arguments[0].get()).toString();
// 2.自定义 UDF 核心逻辑
// 统计字符串中每个字符的出现次数,并将其记录在 Map 中
Map<String, Integer> map = new HashMap<>();
for (char ch : str.toCharArray()) {
String key = String.valueOf(ch);
Integer count = map.getOrDefault(key, 0);
map.put(key, count + 1);
}
// 3.返回处理结果
return map;
}
@Override
public String getDisplayString(String[] children) {
return "这是一个简单的测试自定义 UDF~";
}
}
UDAF(user-defined aggregate function)
实现 UDAF 需要实现两个类
- apache.hadoop.hive.ql.udf.generic.GenericUDAFResolver2:UDAF 入口类,负责参数校验,决定 UDAF 核心逻辑实现类。
- apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator:UDAF 核心逻辑实现类,负责数据聚合。
为了更加直观,本篇文章将以实现计算平均数的案例来讲解
GenericUDAFResolver2
GenericUDAFResolver2 是 UDAF 的入口类,负责参数检验。实现 GenericUDAFResolver2 接口,并实现其方法即可。
public class Avg implements GenericUDAFResolver2 {
/**
* UDAF入口函数
* 负责:
* 1. 参数校验
* 2. 返回 UDAF 核心逻辑实现类
*/
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {
ObjectInspector[] parameters = info.getParameterObjectInspectors();
// 1. 参数个数校验
if (parameters.length != 1)
throw new UDFArgumentException("只接受一个参数");
// 2. 参数类型校验
else if (parameters[0].getCategory() != ObjectInspector.Category.PRIMITIVE ||
((PrimitiveObjectInspector)parameters[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.INT)
throw new UDFArgumentException("第一个参数是int");
// 3. 可以获取参数的其他信息
if (info.isAllColumns()) // 函数参数是否为*
System.out.println("FUNCTION(*)");
if (info.isDistinct()) // 函数参数是否被DISTINCT修饰
System.out.println("FUNCTION(DISTINCT xxx)");
if (info.isWindowing()) // 是否是窗口函数
System.out.println("FUNCTION() OVER(xxx)");
// 3. UDAF核心逻辑实现类
return new AvgEvaluator();
}
/**
* 该方法是用于兼容老的UDAF接口,不用实现
* 如果通过AbstractGenericUDAFResolver实现Resolver,则该方法作为UDAF的入口
*/
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters) throws SemanticException {
throw new UDFArgumentException("方法未实现");
}
}
GenericUDAFEvaluator
GenericUDAFEvaluator是UDAF的核心逻辑实现,需要实现的方法较多,而且不同的模式下会调用不同的方法
在实现GenericUDAFEvaluator之前,首先需要理解它的四个模式Mode
GenericUDAFEvaluator内部有一个Mode枚举类,并且有一个对应的成员变量
Mode对应了MapReduce中的一些阶段,其详细信息请见下方代码
/**
* UDAF入口函数类
*/
public abstract class GenericUDAFEvaluator implements Closeable {
/**
* Mode.
*
*/
public static enum Mode {
/**
* 读取原始数据,聚合部分数据,获得部分聚合结果
* 调用:iterate()、terminatePartial()
* 对应Map阶段(不包括Combiner)
*/
PARTIAL1,
/**
* 读取部分聚合结果,再做部分聚合,获得新的部分聚合结果
* 调用:merge()、terminatePartial()
* 对应Map的Combiner阶段
*/
PARTIAL2,
/**
* 读取部分聚合结果,进行全局聚合,获得全局聚合结果
* 调用:merge()、terminate()
* 对应Reduce阶段
*/
FINAL,
/**
* 读取原始数据,直接进行全局聚合,获得全局聚合结果 and
* 调用:iterate()、terminate()
* 对应MapOnly任务,只有Map阶段
*/
COMPLETE
};
Mode mode;
}
各个Mode调用的方法如下:
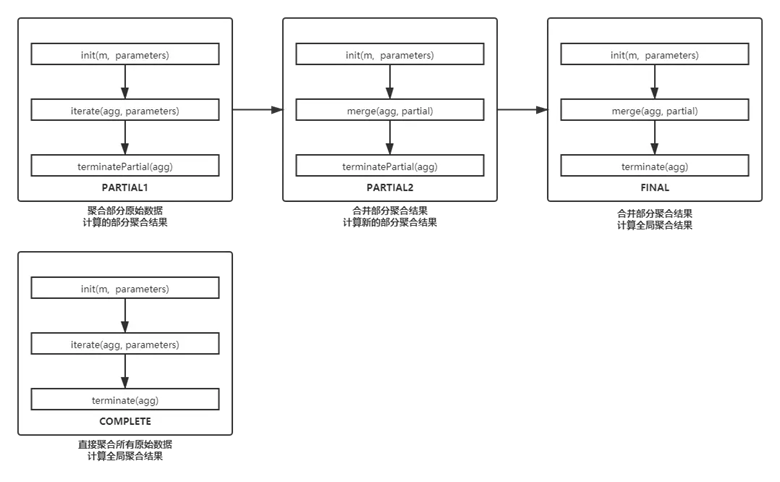
AggregationBuffer
聚合过程中,用于保存中间结果的Buffer
核心函数
| 函数 | 描述 |
| getNewAggregationBuffer() | 获取一个新的Buffer,用于保存中间计算结果 |
| reset(agg) | 重置Buffer,在Hive程序执行时,可能会复用Buffer实例 |
| init(m, parameters) | 各个模式下,都会调用该方法进行初始化。校验上一阶段的参数,并且决定该阶段的输出 |
| iterate(agg, parameters) | 读取原始数据,计算部分聚合结果 |
| terminatePartial(agg) | 输出部分聚合结果 |
| merge(agg, partial) | 合并部分聚合结果 |
| terminate(agg) | 输出全局聚合结果 |
核心函数的调用过程如下:
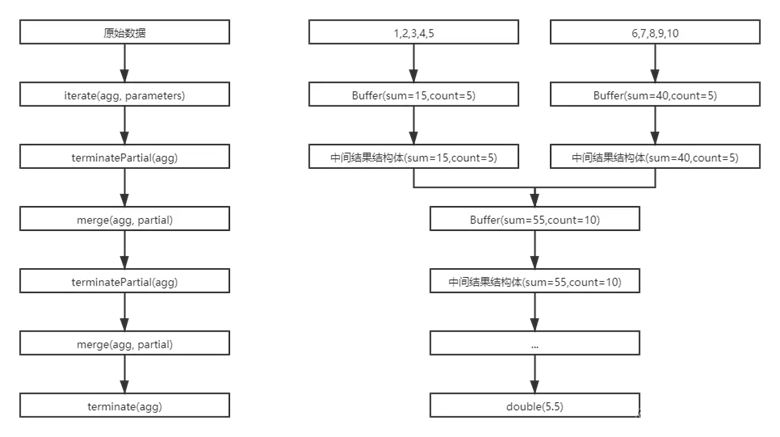
实现代码:
/**
* UDAF核心逻辑类
*/
public class AvgEvaluator extends GenericUDAFEvaluator {
/**
* 聚合过程中,用于保存中间结果的Buffer
* 继承AbstractAggregationBuffer
* <p>
* 对于计算平均数,我们首先要计算总和(sum)和总数(count)
* 最后用总和/总数就可以得到平均数
*/
private static class AvgBuffer extends AbstractAggregationBuffer {
// 总和
private Integer sum = 0;
// 总数
private Integer count = 0;
}
/**
* 初始化
*
* @param m 聚合模式
* @param parameters 上一个阶段传过来的参数,可以在这里校验参数:
* 在PARTIAL1和COMPLETE模式,代表原始数据
* 在PARTIAL2和FINAL模式,代表部分聚合结果
* @return 该阶段最终的返回值类型
* 在PARTIAL1和PARTIAL2模式,代表terminatePartial()的返回值类型
* 在FINAL和COMPLETE模式,代表terminate()的返回值类型
*/
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
super.init(m, parameters);
if (m == Mode.PARTIAL1 || m == Mode.PARTIAL2) {
// 在PARTIAL1和PARTIAL2模式,代表terminatePartial()的返回值类型
// terminatePartial()返回的是部分聚合结果,这时候需要传递sum和count,所以返回类型是结构体
List<ObjectInspector> structFieldObjectInspectors = new LinkedList<ObjectInspector>();
structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.writableIntObjectInspector);
structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.writableIntObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(
Arrays.asList("sum", "count"),
structFieldObjectInspectors
);
} else {
// 在FINAL和COMPLETE模式,代表terminate()的返回值类型
// 该函数最终返回一个double类型的数据,所以这里的返回类型是double
return PrimitiveObjectInspectorFactory.writableDoubleObjectInspector;
}
}
/**
* 获取一个新的Buffer,用于保存中间计算结果
*/
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
// 直接实例化一个AvgBuffer
return new AvgBuffer();
}
/**
* 重置Buffer,在Hive程序执行时,可能会复用Buffer实例
*
* @param agg 被重置的Buffer
*/
public void reset(AggregationBuffer agg) throws HiveException {
// 重置AvgBuffer实例的状态
((AvgBuffer)agg).sum = 0;
((AvgBuffer)agg).count = 0;
}
/**
* 读取原始数据,计算部分聚合结果
*
* @param agg 用于保存中间结果
* @param parameters 原始数据
*/
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
if (parameters == null || parameters[0] == null)
return;
if (parameters[0] instanceof IntWritable) {
// 计算总和
((AvgBuffer)agg).sum += ((IntWritable)parameters[0]).get();
// 计算总数
((AvgBuffer)agg).count += 1;
}
}
/**
* 输出部分聚合结果
*
* @param agg 保存的中间结果
* @return 部分聚合结果,不一定是一个简单的值,可能是一个复杂的结构体
*/
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
// 传递中间结果时,必须传递总和、总数
// 这里需要返回一个数组,表示结构体
return new Object[]{
new IntWritable(((AvgBuffer)agg).sum),
new IntWritable(((AvgBuffer)agg).count)
};
}
/**
* 合并部分聚合结果
* 输入:部分聚合结果
* 输出:部分聚合结果
*
* @param agg 当前聚合中间结果类
* @param partial 其他部分聚合结果值
*/
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
if (partial != null) {
// 传递过来的结构体为LazyBinaryStruct类型,需要从中提取数据
((AvgBuffer)agg).sum += ((IntWritable)((LazyBinaryStruct)partial).getField(0)).get();
((AvgBuffer)agg).count += ((IntWritable)((LazyBinaryStruct)partial).getField(1)).get();
}
}
/**
* 输出全局聚合结果
*
* @param agg 保存的中间结果
*/
public Object terminate(AggregationBuffer agg) throws HiveException {
// 总和/总数
return new DoubleWritable(1.0 * ((AvgBuffer)agg).sum / ((AvgBuffer)agg).count);
}
}
UDTF(user-defined table function)
实现自定义UDTF需要继承GenericUDTF,并且实现其三个方法:
- initialize()
- process()
- close()
其中process()、close()为GenericUDTF中的抽象方法,必须实现。initialize()虽然不是抽象方法,但必须手动覆盖实现该方法,因为GenericUDTF的initialize()最终会抛出一个异常:
throw new IllegalStateException("Should not be called directly");
initialize()
需要覆盖实现的方法如下:
public StructObjectInspector initialize(StructObjectInspector argOIs)
throws UDFArgumentException {}
initialize()在函数在GenericUDTF初始化时被调用一次,执行一些初始化操作,包括:
- 判断函数参数个数
- 判断函数参数类型
- 确定函数返回值类型
除此之外,用户在这里还可以做一些自定义的初始化操作,比如初始化HDFS客户端等1.判断函数参数个数
initialize()的参数为StructObjectInspector argOIs
可以通过如下方式获取自定义UDTF的所有参数
List<? extends StructField> inputFieldRef = argOIs.getAllStructFieldRefs();
判断参数个数的方式很简单,只要判断inputFieldRef的元素个数即可。
示例:
List<? extends StructField> inputFieldRef = argOIs.getAllStructFieldRefs();
//参数个数为1
if(inputFieldRef.size() != 1)
throw new UDFArgumentException("需要一个参数");
2.判断函数参数类型
inputFieldRef的元素类型是StructField,可以通过StructField获取参数类型ObjectInspector
判断参数个数和类型的示例:
//1.判断参数个数,只有一个参数
List<? extends StructField> inputFieldRef = argOIs.getAllStructFieldRefs();
if(inputFieldRef.size() != 1)
throw new UDFArgumentException("需要一个参数");
//2.判断参数类型,参数类型为string
ObjectInspector objectInspector = inputFieldRef.get(0).getFieldObjectInspector();
if(objectInspector.getCategory() != ObjectInspector.Category.PRIMITIVE //参数是Hive原始类型
||!PrimitiveObjectInspector.PrimitiveCategory.STRING.equals(((PrimitiveObjectInspector)objectInspector).getPrimitiveCategory()))//参数是Hive的string类型
throw new UDFArgumentException("函数第一个参数为字符串");//当自定义UDF参数与预期不符时,抛出异常
3.确定函数返回值类型
UDTF函数可以对于一行输入,可以产生多行输出,并且每行结果可以有多列。自定义UDTF的返回值类型会稍微复杂些,需要明确输出结果的所有列名和列类型
initialize()方法的返回值类型为StructObjectInspector
StructObjectInspector表示了一行记录的结构,可以包括多个列。每个列有列名、列类型和列注释(可选)
可以通过ObjectInspectorFactory来获取StructObjectInspector实例:
/**
*structFieldNames:列
*/
ObjectInspectorFactory.getStandardStructObjectInspector(
List<String> structFieldNames,
List<ObjectInspector> structFieldObjectInspectors)
structFieldNames的第n个元素,代表了第n列的名称;structFieldObjectInspectors的第n个元素,代表了第n列的类型。
structFieldNames和structFieldObjectInspectors应该保持长度一致
//只有一列,列的类型为Map<String,int>
return ObjectInspectorFactory.getStandardStructObjectInspector(
Collections.singletonList("result_column_name"),
Collections.singletonList(
ObjectInspectorFactory.getStandardMapObjectInspector(
PrimitiveObjectInspectorFactory.javaStringObjectInspector,//Key是String
PrimitiveObjectInspectorFactory.javaIntObjectInspector//Value是int
)
)
);
process()
核心方法,自定义UDTF的实现逻辑
代码实现步骤可以分为三部分:
- 参数接收
- 自定义UDTF核心逻辑
- 输出结果
/** *Give a set of arguments for the UDTF to process. * *@param args *object array of arguments */ public abstract void process(Object[] args) throws HiveException;
1.参数接收
args即是自定义UDTF的参数,传入的参数不同,会是不同的Java类型,以下是Hive常用参数类型对应的Java类型
| Hive类型 | Java类型 |
| tinyint | ByteWritable |
| smallint | ShortWritable |
| int | IntWritable |
| bigint | LongWritable |
| string | Text |
| boolean | BooleanWritable |
| float | FloatWritable |
| double | DoubleWritable |
| Array | ArrayList |
| Map<K,V> | HashMap<K,V> |
参数接收示例:
//参数null值的特殊处理 if(args[0] == null) return; //接收参数 String str = ((Text)args[0]).toString();
2.自定义UDTF核心逻辑
获取参数之后,到这里就是自由发挥了~
3.输出结果
process()方法本身没有返回值,通过GenericUDTF中的forward()输出一行结果。forward()可以反复调用,可以输出任意行结果
/**
*Passes an output row to the collector.
*
*@param o
*@throws HiveException
*/
protected final void forward(Object o) throws HiveException {
collector.collect(o);
}
forward()可以接收List或Java数组,第n个元素代表第n列的值
List<Object> list = new LinkedList<>();
//第一列是int
list.add(1);
//第二列是string
list.add("hello");
//第三列是boolean
list.add(true);
//输出一行结果
forward(list);
close()
没有其他输入行时,调用该函数
可以进行一些资源关闭处理等最终处理
UDF相关语法
UDF使用需要将编写的UDF类编译为jar包添加到Hive中,根据需要创建临时函数或永久函数。
resources操作
Hive支持向会话中添加资源,支持文件、jar、存档,添加后即可在sql中直接引用,仅当前会话有效,默认读取本地路径,支持hdfs等,路径不加引号。例:add jar /opt/ht/AddUDF.jar;
#添加资源
ADD {FILE[S]|JAR[S]|ARCHIVE[S]} <filepath1> [<filepath2>]*
#查看资源
LIST {FILE[S]|JAR[S]|ARCHIVE[S]} [<filepath1> <filepath2>..]
#删除资源
DELETE {FILE[S]|JAR[S]|ARCHIVE[S]} [<filepath1> <filepath2>..]
临时函数
仅当前会话有效,不支持指定数据库,USING路径需加引号。
CREATE TEMPORARY FUNCTION function_name AS class_name [USING JAR|FILE|ARCHIVE 'file_uri' [, JAR|FILE|ARCHIVE 'file_uri']]; DROP TEMPORARY FUNCTION [IF EXISTS] function_name;
永久函数
函数信息入库,永久有效,USING路径需加引号。临时函数与永久函数均可使用USING语句,Hive会自动添加指定文件到当前环境中,效果与add语句相同,执行后即可list查看已添加的文件或jar包。
CREATE FUNCTION [db_name.]function_name AS class_name [USING JAR|FILE|ARCHIVE 'file_uri' [, JAR|FILE|ARCHIVE 'file_uri']]; DROP FUNCTION [IF EXISTS] function_name; RELOAD (FUNCTIONS|FUNCTION);
查看函数
#查看所有函数,不区分临时函数与永久函数 show functions; #函数模糊查询,此处为查询x开头的函数 show functions like 'x*'; #查看函数描述 desc function function_name; #查看函数详细描述 desc function extended function_name;
escription注解
Hive已定义注解类型org.apache.hadoop.hive.ql.exec.Description,用于执行descfunction[extended]function_name时介绍函数功能,内置函数与自定义函数用法相同。
若Description注解名称与创建UDF时指定名称不同,以创建UDF时指定名称为准。
public @interface Description {
//函数简单介绍
String value() default "_FUNC_is undocumented";
//函数详细使用说明
String extended() default "";
//函数名称
String name() default "";
}
Hive UDF实战—经纬度编码
在Idea中,新建一个Maven项目,命名为: GeoUtilsUdf。
pom.xml文件的修改
修改调整后的pom.xml:
4.0.0 com.ly GeoUtilsUdf 1.0-SNAPSHOT org.apache.hive hive-exec 1.1.0 provided org.apache.hadoop hadoop-common 2.6.0 jdk.tools jdk.tools com.github.davidmoten geo 0.8.0 com.uber h3 4.1.1 org.apache.maven.plugins maven-assembly-plugin jar-with-dependencies make-jar-with-dependencies package single org.apache.maven.plugins maven-compiler-plugin 8 8
pom.xml节点说明:
1.引入hive及hadoop依赖
org.apache.hive hive-exec 1.1.0 provided org.apache.hadoop hadoop-common 2.6.0 jdk.tools jdk.tools
注意,版本必须与线上的Hive和Hadoop版本一致。另外hive-exec的scope设为provided。因为Hive的lib目录下已经包括了hive-exec的jar,Hive会自动将其加载。所以这里就不需要再打包进入jar。
2.添加外部依赖,不重复造轮子。
使用外部已有的java包,一个是Geohash,另外一个是uberh3。
com.github.davidmoten geo 0.8.0 com.uber h3 4.1.1
3.打包设置,将外部依赖打包进入jar。
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-jar-with-dependencies</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> </plugins> </build>
编写Java代码
在src/main/java目录下新建两个Package,并在分别为:
- hive.udf.geohash
- hive.udf.h3
在com.hive.udf.geohash下先建2个JavaClass:
- UDFGeohashEncode(将经纬度转化为geohash)
- UDFGeohashDecode(将geohash转化为经纬度)
代码如下:
# UDFGeohashEncode.java
package com.hive.udf.geohash;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import com.github.davidmoten.geo.GeoHash;
public class UDFGeohashEncode extends UDF {
public Text evaluate(DoubleWritable longitude, DoubleWritable latitude, IntWritable precision){
if(latitude == null || longitude == null || precision == null){
return null;
}
return new Text(GeoHash.encodeHash(latitude.get(), longitude.get(), precision.get()));
}
}
# UDFGeohashDecode.java
package com.hive.udf.geohash;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import com.github.davidmoten.geo.GeoHash;
import com.github.davidmoten.geo.LatLong;
public class UDFGeohashDecode extends UDF {
public Text evaluate(Text geohash){
if(geohash == null){
return null;
}
LatLong location = GeoHash.decodeHash(geohash.toString());
return new Text(location.getLon() + "," + location.getLat());
}
}
在com.hive.udf.h3下先建3个JavaClass:
- UDFH3Encode(将经纬度转化为H3)
- UDFH3ToGeo(将H3转化为经纬度)
- UDFH3ToGeoBoundary(将H3转化为6个顶点的经纬度)
代码示例:
#UDFH3Encode.java
package com.hive.udf.h3;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import com.uber.h3core.H3Core;
import java.io.IOException;
public class UDFH3Encode extends UDF {
public Text evaluate(DoubleWritable longitude, DoubleWritable latitude, IntWritable precision){
H3Core h3 = null;
try{
h3 = H3Core.newInstance();
}catch(IOException e){
e.printStackTrace();
}
if(latitude == null || longitude == null || precision == null){
return null;
}
return new Text(h3.latLngToCellAddress(latitude.get(), longitude.get(), precision.get()));
}
}
#UDFH3ToGeo.java
package com.hive.udf.h3;
import com.uber.h3core.H3Core;
import com.uber.h3core.util.LatLng;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorConverters;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import java.util.HashMap;
public class UDFH3ToGeo extends GenericUDF {
private ObjectInspectorConverters.Converter[] converters;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 1) {
throw new UDFArgumentLengthException(
“The function UDFH3ToGeo(s) takes exactly 1 arguments.”);
}
converters = new ObjectInspectorConverters.Converter[arguments.length];
converters[0] = ObjectInspectorConverters.getConverter(arguments[0],
PrimitiveObjectInspectorFactory.writableStringObjectInspector);
return ObjectInspectorFactory.getStandardMapObjectInspector(
PrimitiveObjectInspectorFactory.javaStringObjectInspector,
PrimitiveObjectInspectorFactory.javaDoubleObjectInspector);
}
@Override
public HashMap
assert (arguments.length == 1);
H3Core h3 = null;
Text hexAddr = (Text) converters[0].convert(arguments[0].get());
if (hexAddr == null) {
return null;
}
try {
h3 = H3Core.newInstance();
} catch (IOException e) {
e.printStackTrace();
}
LatLng coords = h3.cellToLatLng(String.valueOf(hexAddr));
HashMap
try {
map_double.put(“lng”, coords.lng);
map_double.put(“lat”, coords.lat);
} catch (Exception ex) {
ex.printStackTrace();
}
return map_double;
}
@Override
public String getDisplayString(String[] strings) {
return null;
}
}
#UDFH3ToGeoBoundary.java
package com.hive.udf.h3;
import com.uber.h3core.H3Core;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDFUtils;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorConverters;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class UDFH3ToGeoBoundary extends GenericUDF {
private ObjectInspectorConverters.Converter[] converters;
private GenericUDFUtils.ReturnObjectInspectorResolver returnOIResolver;
private transient ArrayList<Object> ret = new ArrayList<Object>();
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
returnOIResolver = new GenericUDFUtils.ReturnObjectInspectorResolver(true);
if (arguments.length != 1) {
throw new UDFArgumentLengthException(
"The function UDFH3ToGeoBoundary(s) takes exactly 1 arguments.");
}
converters = new ObjectInspectorConverters.Converter[arguments.length];
converters[0] = ObjectInspectorConverters.getConverter(arguments[0],
PrimitiveObjectInspectorFactory.javaStringObjectInspector);
ObjectInspector returnOI =
returnOIResolver.get(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardListObjectInspector(returnOI);
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
assert (arguments.length == 1);
H3Core h3 = null;
String hexAddr = (String) converters[0].convert(arguments[0].get());
if (hexAddr == null) {
return null;
}
try {
h3 = H3Core.newInstance();
} catch (IOException e) {
e.printStackTrace();
}
List<com.uber.h3core.util.LatLng> geoCoords = h3.cellToBoundary(hexAddr);
ret.clear();
for (com.uber.h3core.util.LatLng str : geoCoords) {
StringBuilder sb = new StringBuilder();
sb.append(str.lng);
sb.append(",");
sb.append(str.lat);
ret.add(sb);
}
return ret;
}
public String getDisplayString(String[] strings) {
return null;
}
}
编译生成Jar包
命令行执行:mvn clean install
执行完成后会在 target 目录下生成 GeoUtilsUdf-1.0-SNAPSHOT-jar-with-dependencies.jar 文件,此文件就是最终我们要使用的 jar 包。
完成后上传到线上的目录。使用示例:
CREATE TEMPORARY FUNCTION geotoh3address AS 'com.hive.udf.h3.UDFH3Encode' USING JAR 'viewfs://dcfs/ns-common/car/dev/udf_jar/GeoUtilsUdf-1.0-SNAPSHOT-jar-with-dependencies.jar'; SELECT geotoh3address(CAST(lng AS DOUBLE), CAST(lat AS DOUBLE), 7) AS h3hex FROM testdb.test_table LIMIT 10
不重复造轮子,以下一些开源的 Hive UDF 可以复制编译后使用:
- https://github.com/brndnmtthws/facebook-hive-udfs
- https://github.com/klout/brickhouse
- https://github.com/nexr/hive-udf
- https://github.com/aaronshan/hive-third-functions
- https://github.com/yahoo/hive-funnel-udf
- https://github.com/dataiku/dataiku-hive-udf
- https://github.com/petrabarus/HiveUDFs
- https://github.com/Spuul/hive-udfs
- https://github.com/jet2007/jet-hive-udf
- https://github.com/rweald/hive-udfs
- https://github.com/rueedlinger/hive-udf
- https://github.com/ychantit/fuzzymatch_hiveUDF
- https://github.com/Spuul/hive-udfs
参考链接:


