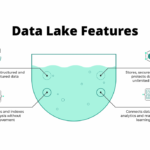
在当今数据驱动的商业环境中,企业面临着海量、多样且高速增长的数据挑战。为了从这些数据中提取价值,两种主流的存储与管理架构应运而生:数据湖与数据仓库。尽管它们都是用于存储和分析数据的系统,但其设计哲学…
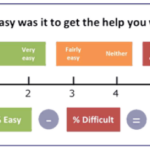
客户费力度(CES)是一个直接衡量客户在与企业互动过程中所付出努力程度的指标,其核心理念在于:客户体验越轻松,他们的满意度和忠诚度往往越高 。 CES 的核心概念与价值 CES 的核心是“减少客户的努力”,强调让…
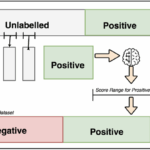
什么是 PU Learning? PU Learning 的全称是 Positive-Unlabeled Learning,即正例-无标记学习。它是一种在半监督学习范畴内的特殊机器学习设定。 与传统的监督学习(数据有明确的“正例”和“负例”标签)不同…
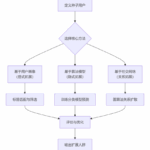
Lookalike简介 Lookalike(相似人群扩展)是一项用于在庞大用户群中寻找与特定“种子用户”相似的新用户的技术。它广泛应用于广告、推荐系统等领域,其核心逻辑可以概括为以下几个步骤: 核心方法解析 Lookali…
在当今竞争激烈的旅游市场中,将您的客户简单地归类为“商务旅客”或“休闲游客”已经远远不够了。这就像试图用一把钥匙打开所有的门——效果甚微。每一位旅行者都是独特的,他们的决策背后交织着复杂的需求、动机和行为…
因果推断核心概念 我们将通过一个贯穿始终的简单例子来讲解:评估一个广告(比如一封营销邮件)对用户购买行为的影响。 干预(Treatment): 发送营销邮件。 W = 1:用户被分配到处理组(计划发送邮件)…
在线旅游平台通过整合多个供应商的酒店资源,为用户提供一站式比价服务。酒店聚合能力直接影响用户体验:一方面需要确保信息准确,避免"到店无单"的风险;另一方面要保证信息的实时性,帮助用户快速决策。 业务挑…
IMEI简介 IMEI(国际移动设备识别码)就像是手机的身份证号码,它是一个全球唯一的编码,用于在移动网络中识别每一部独立的手机设备 。 为了让您更清晰地了解IMEI的构成,下表详细解析了其15位数字的组合方…

在企业运营、平台管理或评价体系设计中,指标权重的分配如同指挥棒,决定了整个体系的公正性和有效性。一个合理的权重体系,不仅要能准确区分对象差异,还要保证整体稳定性和公平性。然而,传统的权重配置方法往往…
文本易读性指标是一系列用于量化评估一段文本阅读和理解难易程度的数学公式或算法。它们通过分析文本中的特定语言特征(如词长、句长等),并输出一个分数或等级,这个分数/等级通常对应于一个教育年级水平或“容易/…






