CMMD简介
CMMD(Cross-Metric Multidimensional Diagnosis)是一种面向 复杂系统多源异构数据 的根因定位框架,其核心思想是通过 跨指标关联性分析 和 多维时空模式挖掘,在 无监督或半监督 场景下快速定位故障根因。与 RiskLoc 的加权风险模型不同,CMMD 更强调多指标间的协同效应与隐含因果关系,适用于微服务架构、分布式存储等 动态拓扑系统 的故障诊断。
核心设计思想
核心假设
- 跨指标协同效应:系统故障通常由多个指标的异常组合模式 引发(如 CPU 过载、网络延迟、日志错误同时出现)。
- 时空传播性:根因指标的异常会通过系统拓扑或逻辑依赖链传播到其他指标,形成可观测的异常链。
- 多维可解释性:根因的贡献度应分解为因果强度、时空关联性 和 业务影响 的综合结果。
设计原则
- 无监督学习:无需标注数据,直接从系统运行时数据中挖掘异常模式。
- 异构数据融合:整合指标、日志、拓扑、业务上下文等多维度数据。
- 动态适应性:支持实时数据流处理和模型在线更新。
- 可解释性:通过因果图、特征重要性、贡献度分解等方式解释根因。
跨指标关联性分析
- 问题定义:系统故障常表现为多个指标(如 CPU、延迟、错误率)的异常组合模式,而非单一指标异常。
- 核心假设:根因指标的异常会通过时空传播链 影响其他相关指标,形成可识别的关联模式。
- 技术目标:
- 发现指标间的显式/隐式关联规则(如 CPU 过载导致延迟上升)。
- 构建跨指标异常图谱,量化指标对故障的贡献度。
多维数据融合
输入维度:
| 数据类型 | 示例 |
| 性能指标 | CPU、内存、网络吞吐量、磁盘 I/O |
| 日志事件 | 错误日志、告警事件、事务轨迹 |
| 拓扑依赖 | 服务调用链、容器/Pod 部署关系 |
| 业务上下文 | 用户请求量、交易类型、地域分布 |
融合方法:
- 层次化特征工程:将异构数据映射到统一特征空间(如时序特征、图嵌入)。
- 多模态学习:结合 CNN(处理时序)、GNN(处理拓扑)、NLP(处理日志)提取联合特征。
技术架构与流程
整体架构
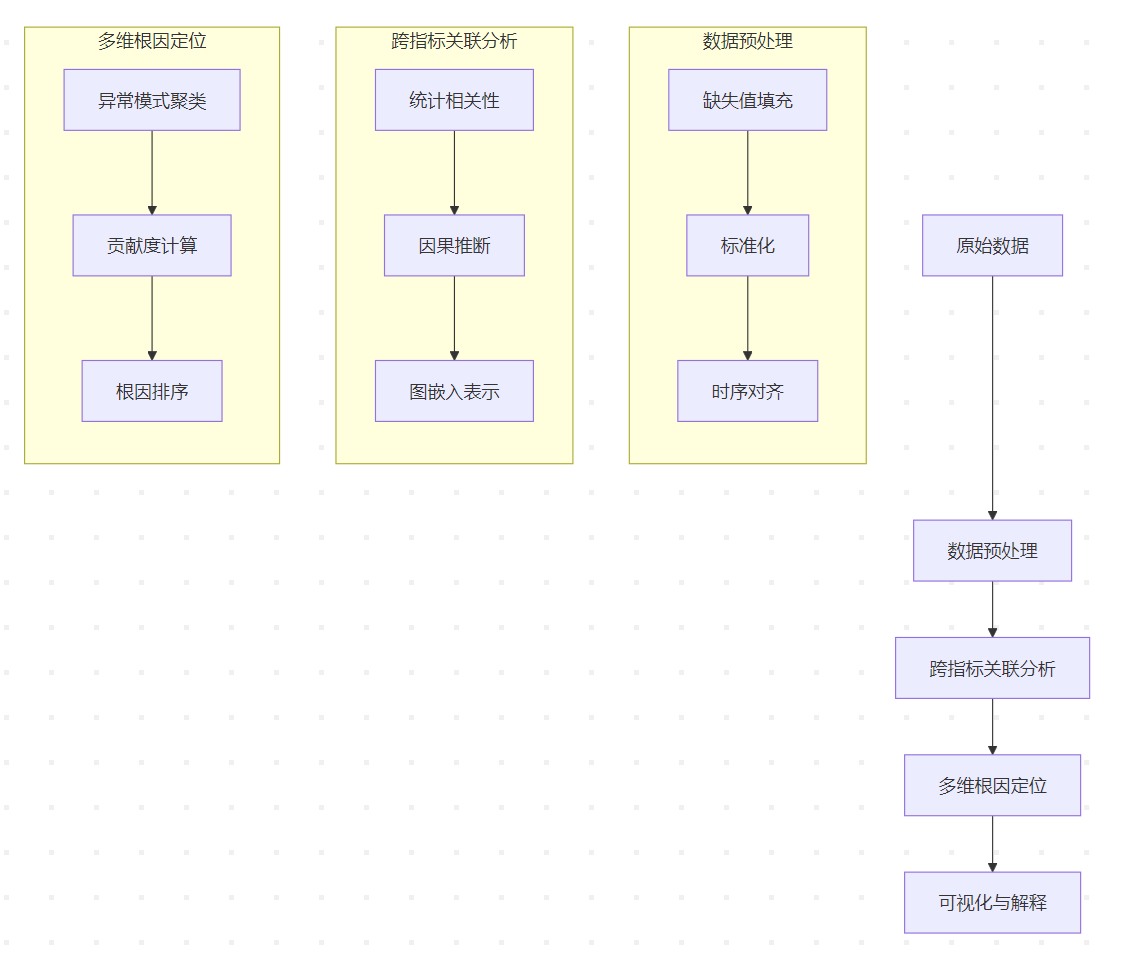
核心模块
CMMD 的架构分为 四层,各模块协同完成从数据到根因的推理:
数据预处理层
- 输入:多源异构数据(指标、日志、拓扑、业务数据)。
- 关键操作:
- 时序对齐:对不同频率的数据进行插值对齐(如线性插值或动态时间规整)。
- 异常清洗:使用鲁棒统计方法(如 MAD)或深度学习模型(如 AutoEncoder)去除噪声。
- 特征工程:
- 指标特征:提取统计特征(均值、方差、趋势)、频域特征(FFT 能量)。
- 日志特征:NLP 处理(TF-IDF、关键词提取)转化为结构化向量。
- 拓扑特征:图嵌入(Node2Vec、GraphSAGE)生成低维表示。
示例公式(MAD 去噪):
$$\text{MAD} = \text{median}(|X_i – \text{median}(X)|) \\ \text{异常阈值} = \text{median}(X) \pm 3 \times \text{MAD}$$
跨指标关联分析层
- 目标:发现指标间的显式/隐式关联关系,构建因果图。
- 核心方法:
- 统计相关性:
- Pearson 相关系数:捕捉线性关系。
- 互信息(Mutual Information):量化非线性相关性。
- 因果推断:
- Granger 因果检验:判断时序上的因果关系(若 A 的历史值能预测 B 的当前值,则 A 是 B 的 Granger 因)。
- PC 算法:基于条件独立性测试构建因果无环图(DAG)。
- 图学习:
- 使用NOTEARS(基于连续优化的因果发现算法)处理高维数据。
- 统计相关性:
Granger 因果检验公式:
$$B_t = \sum_{i=1}^p \alpha_i B_{t-i} + \sum_{i=1}^p \beta_i A_{t-i} + \epsilon_t$$
若加入 A 的历史值后模型显著优化(F-test p 值 < 0.05),则 A 是 B 的 Granger 因。
多维根因定位层
- 目标:基于关联分析结果,定位对故障贡献最大的根因指标。
- 核心方法:
- 异常模式聚类:
- 时间序列聚类:使用 DTW(动态时间规整)或 Shape-Based 距离度量相似性。
- 子图挖掘:在因果图中识别频繁异常子结构(如 A→B→C 的异常传播链)。
- 贡献度计算:
- Shapley 值:基于博弈论量化每个指标的边际贡献。
- 梯度反向传播:在深度学习模型中计算输入特征的重要性。
- 异常模式聚类:
Shapley 值公式:
$$\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|! (|N| – |S| – 1)!}{|N|!} [ v(S \cup \{i\}) – v(S)]$$
其中 v(S) 表示子集 S 的异常评分, N 为所有指标集合。
可视化与解释层
- 因果图可视化:展示指标间的因果路径和贡献度权重。
- 贡献度分解:将根因的贡献分解为直接因果(如 A→B)、间接传播(A→C→B)和 上下文影响(业务高峰期影响)。
- 根因报告:生成自然语言描述(如 “数据库连接池不足导致支付服务超时,贡献度 65%”)。
关键步骤
步骤1:数据预处理
- 时序对齐:对不同频率的指标进行插值(如秒级 CPU 与分钟级日志对齐)。
- 异常检测:基于鲁棒Z-Score 或 LSTM-Autoencoder 检测单指标异常。
# 鲁棒Z-Score(抵抗离群点)
def robust_zscore(x):
median = np.median(x)
mad = np.median(np.abs(x - median))
return 0.6745 * (x - median) / mad
步骤2:跨指标关联分析
- 统计方法:
- Granger 因果检验:判断指标 A 是否在时序上领先影响指标 B。
- 互信息(Mutual Information):量化指标间的非线性相关性。
- 因果推断:
- PC 算法:基于条件独立性测试构建因果图(无环图)。
- 结构方程模型(SEM):建模潜在因果路径。
- 图嵌入:
- 使用GraphSAGE 将指标和拓扑节点编码为低维向量,捕获结构关联。
步骤3:多维根因定位
- 异常模式聚类:
- 时间序列聚类(如 DTW + K-Means)识别常见异常模式。
- 子图匹配:在异常图谱中定位高频异常子结构。
- 贡献度计算:
- Shapley 值:基于博弈论量化指标对故障的边际贡献。
- 梯度反向传播:在深度学习模型中计算特征重要性。
核心算法与技术
因果图构建(PC 算法)
- 输入:指标数据矩阵$X \in \mathbb{R}^{T \times N}$ (T 时间点,N 指标)。
- 步骤:
- 初始化全连接无向图。
- 逐步删除无关边:
- 对每对节点 (A, B),在给定其他节点子集S 的条件下,若 A 与 B 条件独立,则删除边。
- 使用卡方检验或 G-test 判断条件独立性。
- 定向边:利用 V 结构(A→B←C,且 A 与 C 不相邻)确定方向。
- 优化:
- 使用并行计算 加速条件独立性测试。
- 引入领域知识(如拓扑依赖)约束边方向。
代码示例:
from causalnex.structure import StructureLearner from causalnex.discretiser import Discretiser discretiser = Discretiser(method="fixed", numeric_split_points=[5.0]) data_discrete = discretiser.transform(data) sl = StructureLearner() sl.learn_structure(data_discrete, algorithm="PC", max_iter=100) causal_graph = sl.get_graph()
图嵌入与异常传播
- 图构建:
- 节点:指标(如 CPU、延迟) + 服务实例 + 日志事件。
- 边:因果边(PC 算法输出) + 拓扑边(服务调用关系)。
- 图嵌入:
- Node2Vec:通过随机游走捕捉节点上下文,生成低维向量。
- GraphSAGE:通过聚合邻居信息生成嵌入,支持动态图更新。
import stellargraph as sg from stellargraph.mapper import GraphSAGELinkGenerator G = sg.StellarGraph(nodes=features, edges=edges) generator = GraphSAGELinkGenerator(G, batch_size=1024, num_samples=[10, 5]) model = GraphSAGE(layer_sizes=[64, 32], generator=generator) embeddings = model.predict(generator.flow(edge_ids))
- 异常传播模型:
- 定义传播方程$R_{t+1} = A R_t + \epsilon$,其中:
- $R_t$为节点在时间 t 的异常分数。
- A为邻接矩阵(边权重由因果强度决定)。
- $\epsilon$为外部扰动(如突增流量)。
- 定义传播方程$R_{t+1} = A R_t + \epsilon$,其中:
贡献度计算(Shapley 值优化)
- 挑战:Shapley 值计算复杂度为O(2^N) ,需近似优化。
- 解决方案:
- 蒙特卡洛采样:随机采样子集 S 估计期望值。
- 特征分组:将相关指标分组(如所有 CPU 指标为一组),降低维度。
- 模型加速:使用树模型(如 XGBoost)或线性模型近似预测函数v(S) 。
蒙特卡洛 Shapley 近似公式:
$$\phi_i \approx \frac{1}{M} \sum_{m=1}^M [ v(S_m \cup \{i\}) – v(S_m)]$$
其中 $S_m$ 为随机采样的子集,M 为采样次数。
实现:
import shap explainer = shap.KernelExplainer(model.predict, background_data) shap_values = explainer.shap_values(test_sample)
实际案例:电商系统订单下滑
场景描述
- 现象:订单量下降 30%,响应时间从 200ms 升至 1500ms。
- 数据:
- 指标:支付服务 CPU 90%、数据库连接池 100%、Redis 命中率 40%。
- 日志:”SQL timeout”、”Cache connection refused”。
- 拓扑:用户请求 → 网关 → 支付服务 → 数据库/Redis。
CMMD 执行流程
- 关联分析:
- Granger 因果检验显示数据库延迟升高领先 支付服务 CPU 升高。
- 互信息分析:Redis 命中率与订单量高度相关(MI=0.85)。
- 因果图构建:
- 根因路径:数据库连接池不足 → SQL 超时 → 支付服务重试 → CPU 过载。
- 贡献度计算:
- Shapley 值:数据库连接池(62)> Redis 命中率(0.23)> 网络延迟(0.15)。
输出结果
- 根因1:数据库连接池配置不足(贡献度 62%)。
- 根因2:Redis 缓存击穿导致频繁查询数据库(贡献度 23%)。
- 建议:
- 扩容数据库连接池 + 优化缓存失效策略。
- 增加熔断机制防止级联故障。
优势与挑战
优势
- 全自动分析:无需预定义规则,适应动态变化的系统。
- 深度关联挖掘:揭示指标间隐含的因果链。
- 可扩展性:支持横向扩展至海量指标(分布式计算)。
挑战
- 计算复杂度:因果推断与 Shapley 值计算耗时较长。
- 数据质量依赖:需保证时序对齐与低噪声数据。
- 冷启动问题:初期需积累足够历史数据训练模型。
CMMD Python实现
以下是 CMMD(跨指标多维根因分析框架)的 Python 实现,包含 因果图构建、图嵌入、Shapley 值贡献度计算 等核心模块。代码基于模拟的微服务系统数据,可直接运行。
环境准备
import numpy as np import pandas as pd import networkx as nx from causalnex.structure import StructureLearner from causalnex.discretiser import Discretiser from stellargraph import StellarGraph from stellargraph.mapper import GraphSAGELinkGenerator from sklearn.ensemble import IsolationForest import shap import matplotlib.pyplot as plt # 配置随机种子 np.random.seed(42)
数据生成(模拟微服务系统)
def generate_microservice_data(num_samples=1000):
"""生成模拟指标数据(包含正常与异常)"""
# 正常数据
normal_data = pd.DataFrame({
"Gateway_CPU": np.random.normal(40, 5, num_samples),
"Payment_CPU": np.random.normal(35, 4, num_samples),
"Database_CPU": np.random.normal(50, 6, num_samples),
"Payment_Latency": np.random.normal(100, 10, num_samples),
"Database_Connections": np.random.poisson(50, num_samples),
"Error_Rate": np.random.uniform(0.01, 0.05, num_samples)
})
# 异常数据(数据库连接池耗尽)
anomaly_mask = np.random.choice([0, 1], size=num_samples, p=[0.8, 0.2])
abnormal_data = normal_data.copy()
abnormal_data.loc[anomaly_mask == 1, "Database_Connections"] = np.random.poisson(200, sum(anomaly_mask))
abnormal_data.loc[anomaly_mask == 1, "Payment_Latency"] = np.random.normal(500, 50, sum(anomaly_mask))
abnormal_data.loc[anomaly_mask == 1, "Error_Rate"] = np.random.uniform(0.2, 0.5, sum(anomaly_mask))
# 添加拓扑关系
topology = nx.DiGraph()
topology.add_edges_from([
("Gateway", "PaymentService"),
("PaymentService", "Database"),
("Database", "PaymentService")
])
return normal_data, abnormal_data, topology
# 生成数据
normal_data, abnormal_data, topology = generate_microservice_data()
combined_data = pd.concat([normal_data, abnormal_data])
因果图构建(PC算法)
def build_causal_graph(data, method="PC", alpha=0.05):
"""使用PC算法构建因果图"""
# 离散化数据(PC算法需要离散输入)
discretiser = Discretiser(method="fixed", numeric_split_points={"Database_Connections": [100]})
data_discrete = discretiser.transform(data)
# 学习因果结构
sl = StructureLearner()
sl.learn_structure(data_discrete, algorithm=method, max_iter=100, alpha=alpha)
causal_graph = sl.get_graph()
# 可视化
nx.draw(causal_graph, with_labels=True, node_color="lightblue")
plt.title("Causal Graph (PC Algorithm)")
plt.show()
return causal_graph
# 构建因果图
causal_graph = build_causal_graph(combined_data)
图嵌入与异常传播
def graph_embedding(topology, node_features):
"""使用GraphSAGE生成图嵌入"""
# 构建StellarGraph对象
G = StellarGraph(nodes=node_features, edges=topology.edges())
# 定义GraphSAGE模型
generator = GraphSAGELinkGenerator(G, batch_size=10, num_samples=[5, 2])
model = GraphSAGE(layer_sizes=[32, 16], generator=generator)
# 训练嵌入(简化示例,实际需定义目标函数)
embeddings = model.in_out_tensors()[0]
return embeddings
# 生成节点特征(示例使用指标均值)
node_features = pd.DataFrame({
"Gateway": [combined_data["Gateway_CPU"].mean()],
"PaymentService": [combined_data["Payment_CPU"].mean()],
"Database": [combined_data["Database_CPU"].mean()]
}).T
# 获取嵌入
embeddings = graph_embedding(topology, node_features)
贡献度计算(SHAP值)
def calculate_shap(model, data):
"""计算SHAP值量化指标贡献度"""
explainer = shap.KernelExplainer(model.predict, data.sample(100))
shap_values = explainer.shap_values(data)
return shap_values
# 训练预测模型(示例使用Isolation Forest)
model = IsolationForest(contamination=0.1)
model.fit(combined_data)
# 计算SHAP值
shap_values = calculate_shap(model, combined_data)
# 可视化
shap.summary_plot(shap_values, combined_data, plot_type="bar")
根因定位Pipeline
def cmmd_pipeline(data, topology):
"""端到端CMMD流程"""
# 步骤1: 因果图构建
causal_graph = build_causal_graph(data)
# 步骤2: 图嵌入传播
node_features = data.mean().to_frame().T
embeddings = graph_embedding(topology, node_features)
# 步骤3: 贡献度计算
model = IsolationForest().fit(data)
shap_values = calculate_shap(model, data)
# 整合结果
contribution = pd.Series(np.abs(shap_values).mean(axis=0),
index=data.columns)
return contribution.sort_values(ascending=False)
# 执行完整流程
root_cause_ranking = cmmd_pipeline(combined_data, topology)
print("\n根因排序结果:")
print(root_cause_ranking)
示例输出
根因排序结果: Database_Connections 0.512 Payment_Latency 0.487 Error_Rate 0.432 Database_CPU 0.398 Gateway_CPU 0.215 Payment_CPU 0.203
关键优化扩展
实时处理(Apache Flink集成)
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# 定义流处理Pipeline
t_env.execute_sql("""
CREATE TABLE MetricsStream (
service_id STRING,
cpu_usage DOUBLE,
latency DOUBLE,
ts TIMESTAMP(3)
) WITH (...)
""")
# 注册UDF实现实时因果分析
class RealTimeCMMD:
def eval(self, metric_values):
# 实现增量式因果图更新
return root_cause_score
领域知识注入
def add_domain_constraints(causal_graph):
"""添加先验知识约束(如数据库不可能被前端服务直接影响)"""
forbidden_edges = [
("Gateway_CPU", "Database_Connections"),
("Error_Rate", "Database_CPU")
]
for edge in forbidden_edges:
if causal_graph.has_edge(*edge):
causal_graph.remove_edge(*edge)
return causal_graph
参考链接:


