情感分析的定义与核心地位 情感分析(Sentiment Analysis),亦称为意见挖掘或倾向性分析,是人工智能领域中计算语言学的分支,属于自然语言处理(NLP)的核心内容。其核心定义为:通过自动化技术判定文本中观点持…

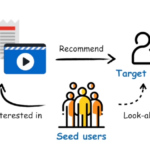
模型概述 RALM(Retrieval-Augmented Look-alike Model)是由腾讯公司于2019年提出并成功应用于微信“看一看”推荐场景的创新模型。该模型的核心目标在于解决传统推荐系统中普遍存在的长尾内容分发难题,即大量缺乏…
推荐系统的优劣需要一套科学、多维度的指标体系来衡量。一套好的评价指标不仅能客观反映系统性能,更能指引产品优化和算法迭代的方向。本文旨在系统性地梳理推荐系统领域常见且重要的评测指标,结合其定义、计算方…
机器学习中的损失函数用于衡量模型预测值与真实值之间的差异,是模型优化的关键。以下按任务类型分类介绍常见损失函数: 回归任务损失函数 均方误差 (Mean Squared Error, MSE / L2 Loss) 公式 $$\text{M…
谱聚类简介 谱聚类(Spectral Clustering)是一种基于图论的聚类算法,它利用数据的相似性矩阵(拉普拉斯矩阵)的特征向量进行降维,然后在低维空间中使用传统聚类方法(如K-means)进行聚类。与K-means等基于距离…

CLIQUE(CLustering In QUEst)是一种经典的子空间聚类算法,由IBM Almaden研究中心在1998年提出。它专门用于从高维数据中发现密度相似的簇,且这些簇可能仅存在于某些子空间(特征的子集)中,而非全维空间。 …

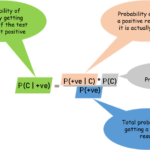
什么是C值? 想象一下你要估计一个网约车司机的完单率(比如接单后成功完成的比例)。你有两种信息: 样本信息:这个司机实际接了多少单,完成了多少单 先验信息:所有司机的平均完单率是多少 C值就是…
BANG算法概述 BANG算法是21世纪初提出的一种用于空间数据聚类的算法,它结合了网格划分和层次聚类的思想,旨在高效地发现数据集中任意形状、不同密度的聚类,并且能够识别嵌套的聚类结构。 BANG算法是一种巧妙…

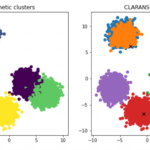
CLARANS简介 CLARANS(Clustering Large Applications based on RANdomized Search,基于随机搜索的大规模应用聚类)是一种经典的聚类算法,由Raymond T. Ng和Jiawei Han于1994年提出。它旨在解决当时主流聚类算法…
X-Means 和 G-Means 都是基于 K-Means 的改进算法,主要目标是自动确定最优的聚类数量k,无需人工预先指定。 X-Means X-Means 是一种能够自动确定最佳聚类数量的改进型K-Means算法,它通过统计指标来评估聚类…






