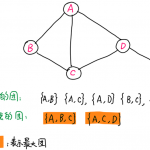
情感分析的定义与核心地位 情感分析(Sentiment Analysis),亦称为意见挖掘或倾向性分析,是人工智能领域中计算语言学的分支,属于自然语言处理(NLP)的核心内容。其核心定义为:通过自动化技术判定文本中观点持…

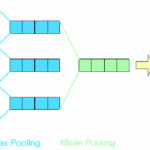
均值池化简介 均值池化(Mean Pooling) 是自然语言处理(NLP)中常用的一种技术,用于将一组词向量(如一个句子中所有词的向量)压缩成一个固定长度的句子向量。它的核心思想是通过简单的数学平均操作,将分散的…
平时在使用LightGMB,需要保存训练好的模型。以下是梳理的几种方式: 使用LightGBM 自带的save_model 方法 import lightgbm as lgb # 假设已经训练好的模型是 model model = lgb.LGBMClassifier() model.fit(X_t…

背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是…
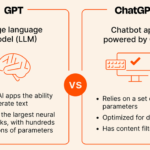
ChatGPT与GPT ChatGPT,全称聊天生成预训练转换器(英语:Chat Generative Pre-trainedTransformer),是OpenAI开发的人工智能聊天机器人程序,于2022年11月推出。该程序使用基于GPT-3.5、GPT-4架构的大型语言模型…
BERT简介 BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google的研究者在2018年提出。它在自然语言处理(NLP)领域取得了革命性的进展,尤其是在理解上下文含义…

Transformer简介 Transformer是一种深度学习架构,由Google的研究者在2017年的论文《Attention Is All You Need》中首次提出。它在自然语言处理(NLP)和其他领域取得了巨大的成功,特别是在处理长序列数据方面。Tr…
在潜在语义分析LSA的文章中对LDA有一些简单的介绍,今天的目标是对LDA进行相对深入的了解,大致搞明白其原理。 LDA简介 在机器学习领域中有2个LDA: 线性判别分析(Linear Discriminant Analysis),主要用于降维和…
什么是潜在语义分析LSA? 潜在语义分析(Latent Semantic Analysis),是语义学的一个新的分支。传统的语义学通常研究字、词的含义以及词与词之间的关系,如同义,近义,反义等等。潜在语义分析探讨的是隐藏在字词…

条件随机场(conditional random field, CRF)是用来标注和划分序列结构数据的概率化结构模型。言下之意,就是对于给定的输出,标识序列Y和观测序列X,条件随机场通过定义条件概率P(Y|X),而不是联合概率分布P(X,Y)来…