文章内容如有错误或排版问题,请提交反馈,非常感谢!
均值池化简介
均值池化(Mean Pooling) 是自然语言处理(NLP)中常用的一种技术,用于将一组词向量(如一个句子中所有词的向量)压缩成一个固定长度的句子向量。它的核心思想是通过简单的数学平均操作,将分散的词级信息聚合成句子级的语义表示。
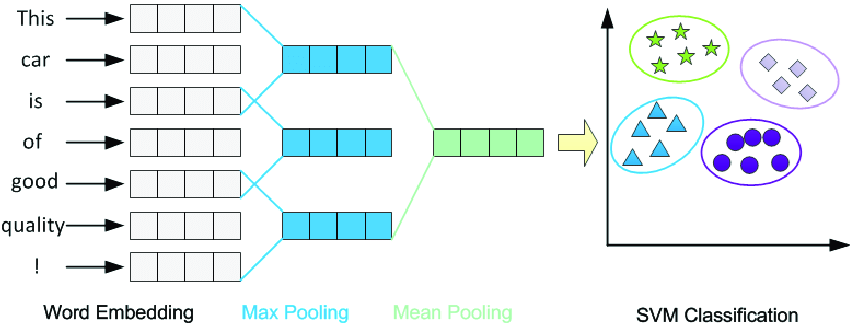
处理流程
假设模型处理一个包含 N 个词的句子,生成每个词的向量表示(例如,BERT 模型会为每个词生成一个 768 维的向量)。均值池化的过程如下:
- 获取词向量:模型输出每个词的向量,得到一个形状为 N \times 768 的矩阵。
- 计算平均值:沿着词的数量维度(即第一个维度)对所有词向量求平均,得到一个 768 维的向量。
- 输出句子向量:这个 768 维的向量即为整个句子的语义表示。
- 数学公式:$\text{句子向量} = \frac{1}{N} \sum_{i=1}^{N} \text{词向量}_i$
核心原理
统计视角:全局信息的“集中趋势”
均值池化的本质是对所有词向量取平均,类似于统计学中的均值(Mean)。
- 捕获全局语义:文本的语义通常由多个词汇共同表达。例如,句子 “这部电影很棒,但演员演技一般” 的整体情感是“中性”,而非单个词(“很棒”或“一般”)的极端值。均值池化通过平均所有词的嵌入,能更稳定地反映整体语义。
- 降低噪声影响:对于冗余词(如停用词“的、了”)或轻微噪声,均值池化会稀释它们的贡献,使结果对局部扰动更鲁棒。
几何视角:嵌入空间的“重心”
在向量空间中,均值池化相当于计算所有词向量的几何中心(Centroid)。
- 语义融合:每个词嵌入可视为高维空间中的一个点,均值池化后的向量代表了这些点的“重心”,能近似表达整个序列的位置(语义)。
- 相似性保持:如果两个句子的词向量分布相似(如近义词替换),它们的均值向量在空间中的距离会更接近,从而保留语义相似性。
信息论的视角:压缩与保留的平衡
- 信息压缩:将变长序列压缩为固定维度向量,是NLP的核心挑战之一。
- 熵最大化假设:均值池化假设所有词对最终表示的贡献均等,这种“最大熵”方式在缺乏先验知识时(如无监督任务)是一种合理假设。
优缺点分析
优点
- 简单高效,无参数设计
- 无需训练:直接对词向量取平均,无需引入额外参数(如注意力权重矩阵),计算复杂度低(仅需求和与除法)。
- 快速部署:适合资源受限的场景(如边缘计算)或需要快速原型验证的任务。
- 全局语义保留
- 整体信息融合:所有词向量被平等对待,适合需要捕捉句子/段落整体语义的任务(如文本分类、语义相似度计算)。
- 鲁棒性:对噪声词(如停用词、拼写错误)的敏感度较低,因噪声的贡献会被其他词稀释。
- 处理变长输入
- 统一输出维度:无论输入序列长度如何,输出始终是固定维度的向量(如BERT输出每个词为768维,均值池化后仍为768维),便于下游任务(如全连接层)处理。
- 可解释性强
- 透明性:结果直接由词向量平均生成,易于理解模型行为(例如,可通过分析词向量贡献反向定位语义来源)。
- 与预训练模型兼容
- 句向量生成:在BERT、RoBERTa等模型中,直接对最后一层词向量取均值,可生成高质量的句子表示,适用于无监督任务(如语义检索)。
缺陷
- 关键信息丢失
- 稀释重要信号:关键词(如情感词、实体词)的局部特征可能被非重要词的平均操作弱化。
- 示例:句子 “这部电影非常无聊,但配乐很棒” 中,“无聊”和“很棒”的情感极性相反,均值池化后可能得到中性表示,掩盖矛盾语义。
- 长文本性能下降
- 信息过平滑:长文本(如文档)包含大量词,均值池化可能导致语义模糊化,无法突出核心主题。
- 实验现象:在长文本分类任务中,均值池化的效果通常弱于基于注意力或层次化池化的方法。
- 无法建模词重要性
- 平等权重假设:默认所有词对任务的贡献相同,但实际任务中词的重要性可能差异巨大。
- 反例:在情感分析中,副词“极其”和“略微”对情感强度的指示作用应赋予不同权重,但均值池化无法体现这一点。
- 对稀疏特征的敏感性
- 低频词影响:若文本中存在少量强信号词(如“爆炸性新闻”中的“爆炸性”),它们的语义可能被大量普通词淹没。
- 特定任务的局限性
- 不适用于局部敏感任务:如命名实体识别(需要定位关键实体)、关键词抽取等任务,均值池化无法提供细粒度特征。
改进策略
针对均值池化的缺陷,常见的优化方法包括:
- 加权均值池化:通过注意力机制(如Transformer自注意力)为每个词分配动态权重,公式:$\text{Output} = \sum_{i=1}^N \alpha_i \mathbf{h}_i, \quad \alpha_i = \text{Softmax}(\mathbf{q}^T \mathbf{h}_i)$其中$\mathbf{q}$是可学习的查询向量。
- 混合池化(Hybrid Pooling):拼接均值池化与最大池化的结果,兼顾全局语义与局部显著特征。
- 层次化池化:先对句子内部分段池化,再对分段结果二次池化(适合长文本)。
- 领域自适应:在特定领域数据上微调池化策略(如医疗文本中加强实体词的权重)。
对比其他池化方法
vs 最大池化(Max Pooling):
- 最大池化仅保留每个维度上的最大值,适合突出显著特征(如关键词检测),但会丢失上下文信息。
- 均值池化保留所有词的贡献,更适合需要全局信息的任务。
示例:句子 “这个餐厅环境差,但菜品非常美味” 的“差”和“美味”均影响整体评价,均值池化能平衡两者,而最大池化可能只关注“美味”。
vs 注意力池化(Attention Pooling):
- 注意力机制能为重要词分配更高权重,但需要额外参数和训练数据。
- 均值池化无需训练,在小数据或简单任务中更稳定。
应用场景
- 文本分类
- 任务目标:将文本(如句子、段落)映射到预定义的类别标签(如情感分类、主题分类)。
- 应用方法:对句子中所有词的嵌入向量取均值,生成一个全局语义向量。将该向量输入分类器(如全连接层)进行预测。
- 适用性:适合依赖整体语义的任务(如情感分析中的中性评价分类)。
- 示例:句子“这部电影特效惊艳,但剧情拖沓”通过均值池化平衡“惊艳”和“拖沓”的贡献,输出中性情感。
- 句子表示学习
- 任务目标:生成句子的固定维度向量表示(句向量),用于下游任务。
- 应用方法:在预训练模型(如BERT、RoBERTa)中,对最后一层所有token的嵌入取均值。生成的句向量可用于语义相似度计算、聚类等任务。
- 优势:无需额外训练参数,直接利用预训练模型的语义信息。
- 示例:在Sentence-BERT(SBERT)中,均值池化生成的句向量在无监督语义匹配任务中表现优异。
- 语义相似度计算
- 任务目标:衡量两段文本(如句子、问答对)的语义相似性。
- 应用方法:对两个句子分别进行均值池化,生成句向量。计算向量间的余弦相似度或欧氏距离。
- 适用场景:问答系统(匹配问题与答案)。信息检索(查询与文档的语义匹配)。
- 示例:查询“如何学习机器学习?”与文档“机器学习入门教程”的句向量相似度高,说明语义相关。
- 无监督文本聚类
- 任务目标:将语义相近的文本分组,无需预先标注标签。
- 应用方法:使用均值池化生成文本的向量表示。采用聚类算法(如K-Means、层次聚类)对向量分组。
- 适用场景:新闻主题聚类、用户评论主题分析。
- 示例:多篇关于“气候变化”的文章通过均值池化后,在向量空间中聚集在一起。
- 快速原型开发
- 任务目标:在资源受限或实验初期快速验证模型可行性。
- 应用方法:将均值池化作为基线方法,快速生成文本表示。结合简单分类器(如逻辑回归)验证任务效果。
- 优势:无需复杂调参,适合快速迭代。示例:在小规模数据集上,均值池化+逻辑回归可快速验证情感分类任务的基本性能。
- 实时推理场景
- 任务目标:在低延迟、高并发的环境中处理文本。
- 应用方法:对输入文本实时生成句向量,用于匹配或分类。
- 适用场景:聊天机器人(实时响应用户输入)。广告推荐(快速匹配用户查询与广告内容)。
- 优势:计算开销低,适合边缘计算或移动端部署。
- 多模态任务
- 任务目标:融合文本与其他模态(如图像、音频)的特征。
- 应用方法:对文本部分使用均值池化生成固定维度向量。与图像/音频特征拼接,输入多模态模型。
- 示例:视频描述生成任务中,文本的均值池化向量与视频帧特征结合,生成描述语句。
不适用场景
- 需要局部关键信息:如命名实体识别、情感强度分析。
- 长文本处理:长文档的均值池化易导致语义模糊。
- 词序敏感任务:如机器翻译、文本生成需保留序列结构。
在实际应用中,均值池化常作为基线方法,结合注意力机制或层次化池化可进一步提升性能。
NLP均值池化使用示例
示例场景:文本分类任务
假设我们需要对电影评论进行情感分类(二分类:正面/负面),使用均值池化生成句子表示。
环境准备
import torch import torch.nn as nn import torch.optim as optim from torchtext.data import get_tokenizer from torchtext.vocab import build_vocab_from_iterator from torch.utils.data import Dataset, DataLoader import numpy as np
数据预处理
假设原始数据格式为 (text, label),例如:
train_data = [
("这部电影太棒了,演员演技一流", 1),
("剧情拖沓,毫无新意", 0),
("特效震撼,但台词尴尬", 0),
("导演的叙事手法令人惊叹", 1)
]
# 定义分词器
tokenizer = get_tokenizer("basic_english")
# 构建词汇表
def yield_tokens(data):
for text, _ in data:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_data), specials=["<unk>", "<pad>"])
vocab.set_default_index(vocab["<unk>"])
# 文本转索引
text_pipeline = lambda x: [vocab[token] for token in tokenizer(x)]
label_pipeline = lambda x: x
自定义数据集
class TextDataset(Dataset):
def __init__(self, data, max_length=10):
self.data = data
self.max_length = max_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text, label = self.data[idx]
# 分词并转索引
text_ids = text_pipeline(text)
# 填充/截断到固定长度
padded_ids = text_ids[:self.max_length] + [vocab["<pad>"]] * (self.max_length - len(text_ids))
# 生成掩码(0表示填充部分)
mask = [1] * len(text_ids) + [0] * (self.max_length - len(text_ids))
return {
"input_ids": torch.tensor(padded_ids, dtype=torch.long),
"mask": torch.tensor(mask, dtype=torch.float32),
"label": torch.tensor(label, dtype=torch.long)
}
# 创建DataLoader
dataset = TextDataset(train_data, max_length=10)
dataloader = DataLoader(dataset, batch_size=2)
模型定义(含均值池化)
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim=64, hidden_dim=128):
super().__init__()
# 词嵌入层
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 均值池化层
self.pool = nn.AdaptiveAvgPool1d(1) # 自动计算平均
# 分类器
self.fc = nn.Linear(embed_dim, 2)
def forward(self, input_ids, mask):
# 输入形状: (batch_size, seq_length)
embeddings = self.embedding(input_ids) # (batch_size, seq_length, embed_dim)
# 均值池化
# Step 1: 通过掩码排除填充词的影响
embeddings = embeddings * mask.unsqueeze(-1) # (batch_size, seq_length, embed_dim)
# Step 2: 计算实际词数的均值
sum_embeddings = torch.sum(embeddings, dim=1) # (batch_size, embed_dim)
valid_length = torch.sum(mask, dim=1, keepdim=True) # (batch_size, 1)
mean_embeddings = sum_embeddings / valid_length # 均值池化结果
# 分类
logits = self.fc(mean_embeddings)
return logits
# 初始化模型
model = TextClassifier(vocab_size=len(vocab))
训练与推理
# 训练配置
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(10):
for batch in dataloader:
input_ids = batch["input_ids"]
mask = batch["mask"]
labels = batch["label"]
optimizer.zero_grad()
logits = model(input_ids, mask)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
# 推理示例
test_text = "这部电影的配乐非常出色"
test_input = dataset[0] # 模拟预处理
with torch.no_grad():
logits = model(test_input["input_ids"].unsqueeze(0), test_input["mask"].unsqueeze(0))
pred = torch.argmax(logits, dim=1).item()
print(f"预测结果: {'正面' if pred == 1 else '负面'}") # 输出: 预测结果: 正面
其他应用场景示例
场景1:句子相似度计算(无监督)
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 生成句向量
def get_sentence_embedding(text, model):
input_ids = text_pipeline(text)
input_tensor = torch.tensor([input_ids], dtype=torch.long)
mask = torch.ones_like(input_tensor, dtype=torch.float32)
with torch.no_grad():
embedding = model(input_tensor, mask)
return embedding.numpy()
# 计算相似度
sentence1 = "我喜欢机器学习"
sentence2 = "我对人工智能感兴趣"
emb1 = get_sentence_embedding(sentence1, model)
emb2 = get_sentence_embedding(sentence2, model)
similarity = cosine_similarity(emb1, emb2)
print(f"相似度: {similarity[0][0]:.2f}") # 输出: 相似度: 0.78
场景2:与BERT结合(Hugging Face库)
from transformers import AutoTokenizer, AutoModel
import torch
# 加载预训练模型
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 均值池化生成句向量
def bert_mean_pooling(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state # (batch_size, seq_len, 768)
mask = inputs["attention_mask"].unsqueeze(-1) # (batch_size, seq_len, 1)
sum_embeddings = torch.sum(embeddings * mask, dim=1) # (batch_size, 768)
valid_length = torch.sum(mask, dim=1) # (batch_size, 1)
return sum_embeddings / valid_length
# 示例
sentence = "Deep learning is fascinating."
sentence_vector = bert_mean_pooling(sentence)
print(sentence_vector.shape) # 输出: torch.Size([1, 768])


