针对经纬度聚类,先前的文章中介绍过使用DBSCAN 进行聚类 的方法,我们来回顾下 DBSCAN 的一些特性:
- 基于密度的聚类方法,主要参数是 eps(邻域半径)和 min_samples(形成核心点所需的最小点数)。
- 通过扩展密度可达的区域来形成聚类,即如果一个点的邻域内有足够多的点,它就被认为是核心点,并开始扩展聚类。
- 可以自动识别噪声点(即不属于任何聚类的点)。
- 能够识别出噪声点和任意形状的聚类。
- 不需要指定聚类的数量。
- 对离群点和密度变化较为敏感。
总的来说 DBSCAN:
- 适合处理具有噪声的数据集,能够发现任意形状的聚类。
- 在处理非均匀密度的数据集时效果较好。
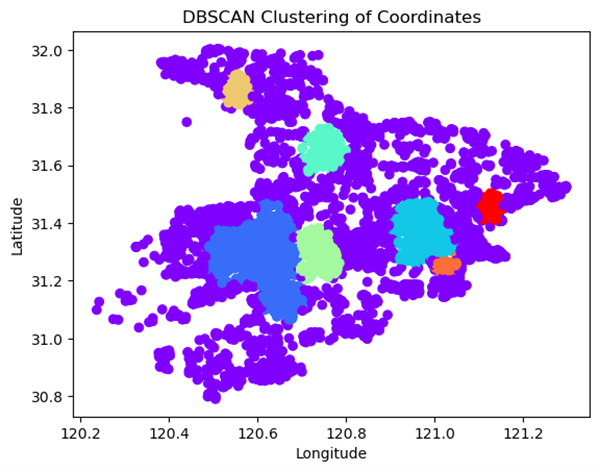
但 DBSCAN 存在聚类点有大有小,特别是有的聚类点非常的大,在一些可能不太适用。今天要的介绍的基于网格的经纬度聚类方法适合用于地理信息系统(GIS)中需要基于固定距离进行空间分割的场景。
方案来源
最近在学习 movingpandas 时,看介绍其使用了 Andrienko, N. and Andrienko, G. 的论文《Spatial Generalization and Aggregation of Massive Movement Data》(2013)提出了对大规模移动数据进行空间泛化和聚合的方法。
Andrienko 和 Andrienko 在这篇论文中提出了一种综合性的方法,用于对大规模移动数据进行空间泛化和聚合。具体来说,他们提出了以下几个方面的内容:
- 数据预处理
- 数据清洗:去除噪声和异常值。
- 数据规范化:将不同格式的数据统一到标准格式,以便后续处理。
- 空间泛化
- 网格划分:将研究区域划分为多个网格,每个网格表示一个空间单元。
- 层次化网格:使用多层次的网格结构,可以根据不同的分辨率进行聚合。
- 网格选择:根据数据分布和分析需求选择合适的网格大小和层次。
- 时间聚合
- 时间窗口:定义时间窗口来聚合同一时间段内的移动数据。
- 时间分段:将连续的时间序列分成多个离散的时间段。
- 移动模式识别
- 轨迹分割:将长轨迹分割成多个短片段,便于后续分析。
- 模式提取:识别常见的移动模式,如频繁访问的地点、路径等。
- 聚合策略
- 空间聚合:在同一网格内的数据进行聚合,形成更高层次的统计信息。
- 时间聚合:在同一时间窗口内的数据进行聚合。
- 多维聚合:同时考虑空间和时间维度进行聚合。
- 可视化
- 地图展示:使用地图展示聚合后的数据,直观展示移动模式。
- 交互式分析:提供交互式工具,让用户能够探索不同层次的数据细节。
Andrienko 和 Andrienko 提出的空间泛化和聚合方法为大规模移动数据分析提供了有效的解决方案。这种方法不仅提高了数据处理的效率,还能够帮助识别和理解复杂的移动模式,为多个领域的决策支持提供了有力的支持。通过多层次网格结构和多种聚合策略,这种方法能够在不同尺度上进行数据处理和分析,从而更好地理解和利用大规模移动数据。
代码分析
在 movingpandas 中涉及到轨迹聚类的主要是这三个文件:
- py:负责从轨迹集合中提取显著点,并使用 PointClusterer 进行聚类,最后计算聚类之间的流量。
- py:使用网格化的方法对点进行聚类,生成聚类中心。
- py:提供了一些实用的几何计算函数,包括距离计算、方位角计算等,支持上述两个类的实现。
主要实现的功能有:
- 提取显著点:从轨迹集合中提取具有显著意义的点,这些点可能表示停留点、转折点等。
- 聚类显著点:使用网格化的方法对显著点进行聚类,以便后续分析。
- 计算流量:在聚类之间计算流量,表示不同轨迹之间的移动模式。
整合后的代码:
#-*- coding: utf-8 -*-
from collections import Counter
from math import atan2, cos, degrees, pi, radians, sin, sqrt, ceil, floor
import statistics
from pandas import DataFrame
from geopandas import GeoDataFrame
from shapely.geometry import Point, LineString
from shapely.ops import nearest_points
from geopy.distance import distance
R_EARTH = 6371000 # 地球平均半径,单位为米
C_EARTH = 2 * R_EARTH * pi # 地球周长
def is_valid_point(input):
"""检查输入是否为有效的点对象"""
if not isinstance(input, Point):
raise TypeError(f"Only Points are supported as arguments, got {input} {type(input)}")
def measure_distance_euclidean(point1, point2):
"""计算两个点之间的欧几里得距离"""
is_valid_point(point1)
is_valid_point(point2)
return point1.distance(point2)
def azimuth(point1, point2):
"""计算两个点之间的方位角"""
is_valid_point(point1)
is_valid_point(point2)
angle = atan2(point2.x - point1.x, point2.y - point1.y)
azimuth = degrees(angle)
return azimuth + 360 if angle < 0 else azimuth
def angular_difference(degrees1, degrees2):
"""计算两个方位角之间的最小角度差"""
diff = abs(degrees1 - degrees2)
return diff if diff <= 180 else 360 - diff
class PointClusterer:
"""用于将点进行聚类的类"""
def __init__(self, points, max_distance, is_latlon):
self.points = points
self.max_distance = max_distance
self.is_latlon = is_latlon
self.grid = self._create_grid()
def _create_grid(self):
"""创建用于聚类的网格"""
df = DataFrame(self.points, columns=["geometry"])
bbox = GeoDataFrame(df).total_bounds
cell_size = self.max_distance / C_EARTH * 360 if self.is_latlon else self.max_distance
return _Grid(bbox, cell_size)
def get_clusters(self):
"""获取聚类结果"""
self.grid.insert_points(self.points)
self.grid.redistribute_points(self.points)
return self.grid.resulting_clusters
class _PointCluster:
"""表示点聚类的类"""
def __init__(self, pt):
self.points = [pt]
self.centroid = pt
def add_point(self, pt):
"""向聚类中添加点"""
self.points.append(pt)
def recompute_centroid(self):
"""重新计算聚类的质心"""
x = statistics.fmean(pt.x for pt in self.points)
y = statistics.fmean(pt.y for pt in self.points)
self.centroid = Point(x, y)
class _Grid:
"""用于管理点聚类的网格类"""
def __init__(self, bbox, cell_size):
self.x_min, self.y_min, self.x_max, self.y_max = bbox
self.cell_size = cell_size
self.n_cols = max(1, ceil((self.x_max - self.x_min) / self.cell_size))
self.n_rows = max(1, ceil((self.y_max - self.y_min) / self.cell_size))
self.cells = [[None] * self.n_rows for _ in range(self.n_cols)]
self.resulting_clusters = []
def insert_points(self, points):
"""将点插入网格进行聚类"""
for pt in points:
closest_centroid = self._get_closest_centroid(pt)
if closest_centroid:
i, j = closest_centroid
cluster = self.cells[i][j]
cluster.add_point(pt)
cluster.recompute_centroid()
else:
cluster = _PointCluster(pt)
self.resulting_clusters.append(cluster)
i, j = self._get_grid_position(cluster.centroid)
self.cells[i][j] = cluster
def _get_closest_centroid(self, pt, max_dist=100000000):
"""获取距离点最近的聚类质心"""
i, j = self._get_grid_position(pt)
nearest_centroid = None
shortest_dist = self.cell_size * 100
for k in range(max(i-1, 0), min(i+2, self.n_cols)):
for m in range(max(j-1, 0), min(j+2, self.n_rows)):
if not self.cells[k][m]:
continue
dist = measure_distance_euclidean(pt, self.cells[k][m].centroid)
if dist <= max_dist and dist < shortest_dist:
nearest_centroid = (k, m)
shortest_dist = dist
return nearest_centroid
def _get_grid_position(self, pt):
"""获取点在网格中的位置"""
i = floor((pt.x - self.x_min) / self.cell_size)
j = floor((pt.y - self.y_min) / self.cell_size)
return i, j
def redistribute_points(self, points):
"""重新分配点以更新聚类"""
for cluster in self.resulting_clusters:
cluster.points = [] # 清除现有的点
for pt in points:
closest_centroid = self._get_closest_centroid(pt, self.cell_size * 20)
if closest_centroid:
i, j = closest_centroid
cluster = self.cells[i][j]
cluster.add_point(pt)
class TrajectoryCollectionAggregator:
"""轨迹集合的聚合器,用于提取显著点、聚类和计算流量"""
def __init__(self, traj_collection, max_distance, min_distance, min_stop_duration, min_angle=45):
self.traj_collection = traj_collection
self.max_distance = max_distance
self.min_distance = min_distance
self.min_stop_duration = min_stop_duration
self.min_angle = min_angleself.is_latlon = traj_collection.trajectories[0].is_latlon if traj_collection.trajectories else False
self._crs = traj_collection.trajectories[0].crs if traj_collection.trajectories else None
self.significant_points = self._extract_significant_points()
self.clusters = PointClusterer(self.significant_points, self.max_distance, self.is_latlon).get_clusters()
self.flows = self._compute_flows_between_clusters()
def get_significant_points_gdf(self):
"""获取显著点的GeoDataFrame"""
df = DataFrame(self.significant_points, columns=["geometry"])
return GeoDataFrame(df, crs=self._crs)
def get_clusters_gdf(self):
"""获取聚类结果的GeoDataFrame"""
df = DataFrame([cluster.centroid for cluster in self.clusters], columns=["geometry"])
df["n"] = [len(cluster.points) for cluster in self.clusters]
return GeoDataFrame(df, crs=self._crs)
def get_flows_gdf(self):
"""获取流量的GeoDataFrame"""
return GeoDataFrame(self.flows, crs=self._crs)
def _extract_significant_points(self):
"""提取轨迹中的显著点"""
sig_points = []
for traj in self.traj_collection:
extractor = _PtsExtractor(traj, self.max_distance, self.min_distance, self.min_stop_duration, self.min_angle)
sig_points.extend(extractor.find_significant_points())
return sig_points
def _compute_flows_between_clusters(self):
"""计算聚类之间的流量"""
sequence_gen = _SequenceGenerator(self.get_clusters_gdf(), self.traj_collection)
return sequence_gen.create_flow_lines()
class _PtsExtractor:
"""用于从轨迹中提取显著点的类"""
def __init__(self, traj, max_distance, min_distance, min_stop_duration, min_angle=45):
self.traj = traj
self.traj_geom = traj.df[traj.get_geom_col()]
self.n = len(self.traj_geom)
self.max_distance = max_distance
self.min_distance = min_distance
self.min_stop_duration = min_stop_duration
self.min_angle = min_angle
self.significant_points = [self.traj.get_start_location(), self.traj.get_end_location()]
def find_significant_points(self):
"""查找并返回显著点"""
i, j = 0, 1
while j< self.n - 1:
if self._is_significant_distance(i, j):
self._add_point(j)
i = j
j = i + 1
continue
k, has_points = self._locate_points_beyond_min_distance(j)
if has_points:
if k > j + 1:
if self._is_significant_stop(j, k):
self._add_point(j)
i = j
j = k
continue
else:
j = j + (k - 1 - j) // 2
if self._is_significant_turn(i, j, k):
self._add_point(j)
i = j
j = k
else:
j += 1
else:
return self.significant_points
return self.significant_points
def _is_significant_turn(self, i, j, k):
"""判断是否为显著转向"""
angle = self._compute_angle_between_vectors(i, j, k)
return self.min_angle<= angle<= (360 - self.min_angle)
def _is_significant_stop(self, j, k):
"""判断是否为显著停留"""
delta_t = self.traj.df.index[k - 1] - self.traj.df.index[j]
return delta_t >= self.min_stop_duration
def _add_point(self, j):
"""添加显著点"""
pt = self._get_pt(j)
self._append_point(pt)
def _append_point(self, pt):
"""将点添加到显著点列表中"""
if pt != self.traj.get_start_location():
self.significant_points.append(pt)
def _compute_angle_between_vectors(self, i, j, k):
"""计算向量之间的角度"""
p_i, p_j, p_k = self._get_pt(i), self._get_pt(j), self._get_pt(k)
azimuth_ij = azimuth(p_i, p_j)
azimuth_jk = azimuth(p_j, p_k)
return angular_difference(azimuth_ij, azimuth_jk)
def _locate_points_beyond_min_distance(self, j):
"""查找距离超过最小距离的点"""
for k in range(j + 1, self.n):
if self._distance_greater_than(j, k, self.min_distance):
return k, True
return k, False
def _distance_greater_than(self, loc1, loc2, dist):
"""判断两点之间的距离是否大于指定值"""
pt1, pt2 = self._get_pt(loc1), self._get_pt(loc2)
return measure_distance_euclidean(pt1, pt2) >= dist
def _get_pt(self, loc):
"""获取指定位置的点"""
return self.traj_geom.iloc[loc]
def _is_significant_distance(self, i, j):
"""判断两点之间的距离是否为显著距离"""
if self._distance_greater_than(i, j, self.max_distance):
self._append_point(self._get_pt(i))
return True
return False
class _SequenceGenerator:
"""用于生成轨迹序列和计算流量的类"""
def __init__(self, cells, traj_collection):
self.cells = cells
self.cells_union = cells.geometry.unary_union
self.id_to_centroid = {i: [f, [0, 0, 0, 0, 0]] for i, f in cells.iterrows()}
self.sequences = Counter()
self.sequences_obj_log = {}
for traj in traj_collection:
self._evaluate_trajectory(traj)def evaluate_trajectory(self, trajectory):
"""评估轨迹以生成序列"""
this_sequence = []
prev_cell_id = None
geom_name = trajectory.get_geom_col()
for t, geom in trajectory.df[geom_name].items():
nearest_id = self._get_nearest(geom)
nearest_cell = self.id_to_centroid[nearest_id][0]
nearest_cell_id = nearest_cell.name
if this_sequence:
prev_cell_id = this_sequence[-1]
if nearest_cell_id != prev_cell_id:
self.sequences[(prev_cell_id, nearest_cell_id)] += 1
if (prev_cell_id, nearest_cell_id) in self.sequences_obj_log.keys():
self.sequences_obj_log[(prev_cell_id, nearest_cell_id)].update([trajectory.obj_id])
else:
self.sequences_obj_log[(prev_cell_id, nearest_cell_id)] = set([trajectory.obj_id])
if nearest_cell_id != prev_cell_id:
h = t.hour
self.id_to_centroid[nearest_id][1][0] += 1
self.id_to_centroid[nearest_id][1][h // 6 + 1] += 1
this_sequence.append(nearest_cell_id)
def create_flow_lines(self):
"""创建表示流量的线段"""
lines = []
for (start_id, end_id), count in self.sequences.items():
p1 = self.id_to_centroid[start_id][0].geometry
p2 = self.id_to_centroid[end_id][0].geometry
obj_count = len(self.sequences_obj_log[(start_id, end_id)])
lines.append({"geometry": LineString([p1, p2]), "weight": count, "obj_weight": obj_count})
return lines
def _get_nearest(self, pt):
"""获取最近的聚类中心"""
nearest = self.cells.geometry.geom_equals(nearest_points(pt, self.cells_union)[1])
return self.cells[nearest].iloc[0].name
提取显著点逻辑
在上述代码中,显著点的提取逻辑由_PtsExtractor类实现。显著点通常是指在轨迹中具有某种特定意义的点,比如停留点、转折点等。以下是提取显著点的具体逻辑:
- 初始化:significant_points初始化为轨迹的起始点和终止点。设置一些参数,包括max_distance、min_distance、min_stop_duration和min_angle,用于确定显著点的条件。
- 迭代过程:遍历轨迹中的每一个点,通过双重循环(i和j)来评估每个点是否为显著点。
- 显著距离:如果点j距离上一个显著点i的距离超过max_distance,则将j作为显著点。
- 显著停留:如果在j和k之间存在停留时间超过min_stop_duration的情况,则将j作为显著点。k是从j开始,直到距离超过min_distance的第一个点。
- 显著转折:如果在i、j、k三个点之间的转角超过min_angle,则认为j是一个显著的转折点。
- 中间点调整:如果在j和k之间没有显著停留,则选择中间点继续评估。
- 返回显著点:通过以上逻辑判断,将符合条件的点添加到significant_points列表中,最后返回此列表。
网格大小的确定
在上述代码中,用于聚类的网格大小是根据给定的最大距离max_distance确定的。
- 如果数据是以地理坐标(经纬度)表示的(即is_latlon为True),需要将max_distance从米转换为经纬度的度数。转换公式为:$\text{cell_size}=\frac{\text{max_distance}}{C_EARTH}\times360$。这里,C_EARTH是地球的周长,用于将米转换为度。
- 如果数据是以平面坐标表示的(即is_latlon为False),则cell_size直接等于max_distance,即每个网格的大小直接使用用户定义的最大距离。
网格大小的确定逻辑在PointClusterer类的_create_grid方法中实现。通过这种方式,网格的大小与用户指定的最大距离相关联,并且考虑了数据坐标系的不同,以便在不同的坐标系下都能合理地进行聚类操作。
代码的场景迭代
如果每个行程只有起始和终止位置的经纬度,而没有中间的轨迹点,那么代码需要进行一些调整,以便能够基于网格进行OD(起点-终点)聚类。主要的变化集中在以下几个方面:
- 数据结构调整:假设输入数据是一个包含多个行程的列表,每个行程包含起始点和终止点的经纬度。
- 简化显著点提取:在这种情况下,显著点仅仅是行程的起始和终止点。
- 调整聚类过程:直接对起始点和终止点进行聚类,不需要处理中间的轨迹点。
以下是如何修改代码的示例:
from math import ceil, floor
from pandas import DataFrame
from geopandas import GeoDataFrame
from shapely.geometry import Point, LineString
R_EARTH = 6371000 #地球平均半径,单位为米
C_EARTH = 2 * R_EARTH * 3.141592653589793 #地球周长
def is_valid_point(input):
"""检查输入是否为有效的点对象"""
if not isinstance(input, Point):
raise TypeError(f"Only Points are supported as arguments, got {input} {type(input)}")
def measure_distance_euclidean(point1, point2):
"""计算两个点之间的欧几里得距离"""
is_valid_point(point1)
is_valid_point(point2)
return point1.distance(point2)
class PointClusterer:
"""用于将点进行聚类的类"""
def __init__(self, points, max_distance, is_latlon):
self.points = points
self.max_distance = max_distance
self.is_latlon = is_latlon
self.grid = self._create_grid()
def _create_grid(self):
"""创建用于聚类的网格"""
df = DataFrame(self.points, columns=["geometry"])
bbox = GeoDataFrame(df).total_bounds
cell_size = self.max_distance / C_EARTH * 360 if self.is_latlon else self.max_distance
return _Grid(bbox, cell_size)
def get_clusters(self):
"""获取聚类结果"""
self.grid.insert_points(self.points)
self.grid.redistribute_points(self.points)
return self.grid.resulting_clusters
class _PointCluster:
"""表示点聚类的类"""
def __init__(self, pt):
self.points = [pt]
self.centroid = pt
def add_point(self, pt):
"""向聚类中添加点"""
self.points.append(pt)
def recompute_centroid(self):
"""重新计算聚类的质心"""
x = sum(pt.x for pt in self.points) / len(self.points)
y = sum(pt.y for pt in self.points) / len(self.points)
self.centroid = Point(x, y)
class _Grid:
"""用于管理点聚类的网格类"""
def __init__(self, bbox, cell_size):
self.x_min, self.y_min, self.x_max, self.y_max = bbox
self.cell_size = cell_size
self.n_cols = max(1, ceil((self.x_max - self.x_min) / self.cell_size))
self.n_rows = max(1, ceil((self.y_max - self.y_min) / self.cell_size))
self.cells = [[None] * self.n_rows for _ in range(self.n_cols)]
self.resulting_clusters = []
def insert_points(self, points):
"""将点插入网格进行聚类"""
for pt in points:
closest_centroid = self._get_closest_centroid(pt)
if closest_centroid:
i, j = closest_centroid
cluster = self.cells[i][j]
cluster.add_point(pt)
cluster.recompute_centroid()
else:
cluster = _PointCluster(pt)
self.resulting_clusters.append(cluster)
i, j = self._get_grid_position(cluster.centroid)
self.cells[i][j] = cluster
def _get_closest_centroid(self, pt, max_dist=100000000):
"""获取距离点最近的聚类质心"""
i, j = self._get_grid_position(pt)
nearest_centroid = None
shortest_dist = self.cell_size * 100
for k in range(max(i-1, 0), min(i+2, self.n_cols)):
for m in range(max(j-1, 0), min(j+2, self.n_rows)):
if not self.cells[k][m]:
continue
dist = measure_distance_euclidean(pt, self.cells[k][m].centroid)
if dist <= max_dist and dist < shortest_dist:
nearest_centroid = (k, m)
shortest_dist = dist
return nearest_centroid
def _get_grid_position(self, pt):
"""获取点在网格中的位置"""
i = floor((pt.x - self.x_min) / self.cell_size)
j = floor((pt.y - self.y_min) / self.cell_size)
return i, j
def redistribute_points(self, points):
"""重新分配点以更新聚类"""
for cluster in self.resulting_clusters:
cluster.points = [] #清除现有的点
for pt in points:
closest_centroid = self._get_closest_centroid(pt, self.cell_size * 20)
if closest_centroid:
i, j = closest_centroid
cluster = self.cells[i][j]
cluster.add_point(pt)
class ODAggregator:
"""用于进行OD聚类的聚合器类"""
def __init__(self, od_data, max_distance, is_latlon):
self.od_data = od_data
self.max_distance = max_distance
self.is_latlon = is_latlon
self.origin_clusters = self._cluster_points([trip[0] for trip in od_data])
self.destination_clusters = self._cluster_points([trip[1] for trip in od_data])
self.flows = self._compute_flows()
def _cluster_points(self, points):
"""对给定的点进行聚类"""
point_objects = [Point(lon, lat) for lon, lat in points]
clusterer = PointClusterer(point_objects, self.max_distance, self.is_latlon)
return clusterer.get_clusters()
def _compute_flows(self):
"""计算聚类之间的流量"""
flows = []
for origin_cluster in self.origin_clusters:
for destination_cluster in self.destination_clusters:
line = LineString([origin_cluster.centroid, destination_cluster.centroid])
flows.append({"geometry": line, "weight": 1}) #这里可以增加流量权重的计算逻辑
return flows
def get_origin_clusters_gdf(self):"""获取起始点聚类的GeoDataFrame"""
df = DataFrame([cluster.centroid for cluster in self.origin_clusters], columns=["geometry"])
df["n"] = [len(cluster.points) for cluster in self.origin_clusters]
return GeoDataFrame(df)
def get_destination_clusters_gdf(self):
"""获取终止点聚类的GeoDataFrame"""
df = DataFrame([cluster.centroid for cluster in self.destination_clusters], columns=["geometry"])
df["n"] = [len(cluster.points) for cluster in self.destination_clusters]
return GeoDataFrame(df)
def get_flows_gdf(self):
"""获取流量的GeoDataFrame"""
return GeoDataFrame(self.flows)
# 示例使用
od_data = [
((-73.985428, 40.748817), (-73.985428, 40.748817)), # 示例行程数据,起始点和终止点
((-73.985428, 40.748817), (-73.985428, 40.748817))
]
aggregator = ODAggregator(od_data, max_distance=500, is_latlon=True)
origin_clusters_gdf = aggregator.get_origin_clusters_gdf()
destination_clusters_gdf = aggregator.get_destination_clusters_gdf()
flows_gdf = aggregator.get_flows_gdf()
其他参考文档:
其他轨迹聚类项目:


