在Python生态中,依赖管理工具的效率和可靠性直接关系到开发体验与项目交付速度。传统的pip虽然作为官方标准,但其在大型项目中的依赖解析速度和环境一致性方面常显不足。而由Astral团队(Ruff工具的创造者)用Rust…

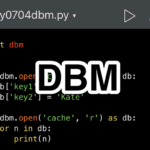
dbm简介 Python 的 dbm 模块是一个用于实现简单键值对数据库的模块。它是基于 Unix 系统上的数据库管理工具 dbm (Database Manager) 的概念引入的。以下是 dbm 及其在 Python 中实现的背景: dbm 的起源 …
pprint(Pretty-Printer)是Python标准库中一个用于美化输出复杂数据结构的模块,特别适用于嵌套较深或元素较多的字典、列表、元组等。相比普通的print(),它能自动格式化输出,使其更具可读性。 主要特点 …

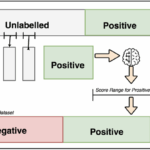
什么是 PU Learning? PU Learning 的全称是 Positive-Unlabeled Learning,即正例-无标记学习。它是一种在半监督学习范畴内的特殊机器学习设定。 与传统的监督学习(数据有明确的“正例”和“负例”标签)不同…
Newspaper3k Newspaper3k 是一个专门用于新闻文章抓取和内容提取的Python库。该项目由 Lucas Ou-Yang 开发,灵感来源于Requests库的简洁性,底层使用lxml实现高效解析。 核心特性 文章内容提取 自…

@property装饰器简介 在Python中,@property装饰器是一种优雅的属性管理工具,它允许你将类的方法伪装成属性(即无需使用()调用),同时可以在属性访问时添加逻辑(如数据校验、动态计算等)。 @property 的核心…

类型注解的概念 类型注解(Type Hints)是 Python 3.5+ 引入的特性(通过PEP 484),允许开发者为变量、函数参数和返回值等标注期望的数据类型。它不会影响代码运行时行为,但可通过静态检查工具(如 mypy)提前发…

以下是根据规则修复空格后的内容: ```html 以下是一份结合PEP8规范、最佳实践及常见注意事项的Python编码规范整理,适用于团队协作与个人项目: 代码布局与格式 缩进 规则:使用4个空格(禁止使用Tab键)。 …

Pygwalker(Python binding for GraphicWalker)是一个用于Python的数据可视化工具,旨在帮助数据科学家和分析师以更交互和直观的方式探索和理解数据。Pygwalker是GraphicWalker的Python绑定,提供类似Tableau的用…
Ray简介 Ray是一个开源的分布式计算框架,专为机器学习和人工智能应用设计。它提供了一种灵活、高效的方式来构建和运行分布式应用程序,特别是在需要大规模并行计算的场景中。Ray的核心是一个通用的分布式执行引擎…






