子曰:学而时习之,不亦说乎!有朋自远方來,不亦乐乎!人不知而不愠,不亦君子乎! 在重读论语之前,我对这句话的理解是:“经常学习,不也喜悦吗?从远方来了朋友,不也快乐吗?别人不了解我也不怨恨,不也是君子吗?” 重读《论语》,总感觉上面的解释有点“跳”…
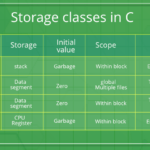
查看全文在C语言中,存储类定义了变量/函数的范围(可见性)和生命周期。这些说明符放在编译器前以理解变量的工作方式。C语言中有以下类型的存储类: 自动(Auto):这是所有局部变量的默认存储类。在函数体、循环…
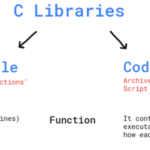
什么是头文件? 在C语言中,头文件是包含一系列声明和宏定义的文件,它们用于共享函数声明、宏定义和其他的公共对象。在C语言中,头文件通常用 .h 作为文件扩展名。 头文件可以被划分为两类: 标准头文件:…
CLion简介 CLion是一款先进的专业IDE,用于C和C++语言开发。由JetBrains公司开发,提供一个支持C、C++、以及其他语言如JavaScript、XML等的集成开发环境。 以下是一些CLion的特性: 智能代码助手:可以进…
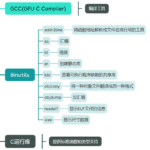
GCC简介 GCC(GNU Compiler Collection)是由GNU项目开发的程序语言编译器。原名为GNU C Compiler(GNU C编译器),因为最初只能处理C语言。GCC现在已经能支持多种编程语言,包括C、C++、Objective-C、Fortran、Ad…
在介绍 WebP 的时候,我们已经知道了相比 JPG 和 PNG 来说,WebP 已经兼顾了高呈现质量以及更小的文件体积,可以说已经非常优秀了,然后还是有一群人不满足于此,他们开发出了 AVIF 这种号称下一代图像压缩格式的玩…

范围:本规范适用于公司内使用C语言编码的所有软件。本规范自发布之日起生效,以后新编写的和修改的代码应遵守本规范。 简介:本规范制定了编写C语言程序的基本原则、规则和建议。从代码的清晰、简洁、可测试、…

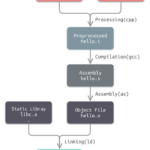
C程序的完整生命周期 一个C程序的完整生命周期包括以下步骤: 编写代码:C程序的生命周期从我们编写源代码开始。源代码通常使用文本编辑器编写,并保存为.c扩展名的文件。 预处理:预处理器接收源代码作为…
C语言是一种通用的、面向过程式的计算机程序设计语言。C语言不但提供了丰富的库函数,还允许用户定义自己的函数。每个函数都是一个可以重复使用的模块,通过模块间的相互调用,有条不紊地实现复杂的功能。可以说C程…

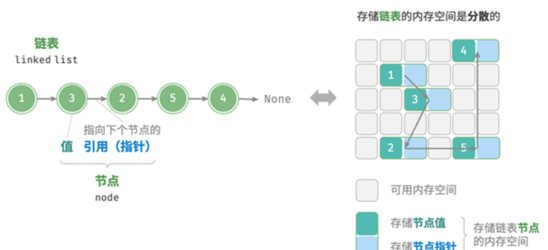
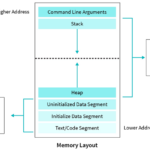
C 语言的内存管理,分成两部分。一部分是系统管理的,另一部分是用户手动管理的。 系统管理的内存,主要是函数内部的变量(局部变量)。这部分变量在函数运行时进入内存,函数运行结束后自动从内存卸载。这些…
什么是文件? 文件其实是指一组相关数据的有序集合。这个数据集有一个名称,叫做文件名。文件通常是驻留在外部介质(如磁盘等)上的,在使用时才调入内存中来。 从文件功能上来讲,一般可分为:程序文件与数据文…