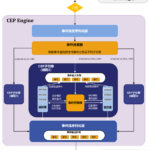
复杂事件处理(Complex Event Processing,CEP)是一种能够实时分析并响应海量数据流中事件的技术框架。其核心目标是从庞杂、源源不断的数据流中,通过预定义的规则,识别出有意义的事件模式或将简单事件组合成具有…
本文基于知名创业孵化器Y Combinator创始人保罗·格雷厄姆(Paul Graham)的核心理念,系统梳理了创业从构思到执行、从增长到融资的全过程关键原则。内容经过优化与重组,旨在为创业者提供一份清晰、实用的行动指南…

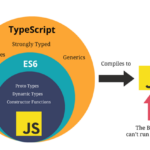
TypeScript 作为现代前端开发的核心工具之一,已从一种可选的增强语言演变为构建大型、可维护应用的事实标准。它不仅是 JavaScript 的超集,更是一套完整的工程化解决方案。以下将从定义、核心特性、与 JavaScript …
在暴雪娱乐(Blizzard Entertainment)出品的《魔兽争霸》《星际争霸》等经典游戏中,大部分游戏数据都被封装在一个名为MPQ的大型档案文件中。如果采用最朴素的查找方式——从文件头部开始逐个比对字符串,直到找到目…

在当今的网页浏览体验中,我们常常会遇到各种不便,例如恼人的广告、不友好的界面设计,或是希望自动化某些重复操作。Tampermonkey(俗称油猴或篡改猴)作为一款强大的浏览器扩展,允许用户通过编写JavaScript脚本…

在当代中国文学史上,王小波的名字如同一颗划过天际的流星——短暂、耀眼,却留下了难以磨灭的轨迹。他被誉为中国近半世纪苦难与荒谬所结晶的天才,其作品以彻底的讽刺与清醒的思考,刺穿了生活的虚伪与荒诞。他唾弃…

2025年,中国本地生活服务市场战火重燃,京东携百亿补贴高调进军外卖,阿里系整合淘宝、支付宝、高德三端流量发起立体攻势。然而,当我们回望数年前那场同样喧嚣的战役——2018年滴滴外卖与美团在无锡的“三国杀”,会…

在当今追求极致用户体验的互联网时代,前端性能优化已成为开发工作的核心环节。其中,合理利用内容分发网络(CDN)来加载公共库,是提升网站加载速度、减轻服务器压力、保障全球访问稳定性的关键技术手段。本文旨在…
在当今快速变化的商业环境中,产品经理的角色至关重要,但如何区分优秀与糟糕的实践却常令人困惑。本文基于行业洞察与经验总结,系统对比了优秀与糟糕产品经理在关键维度上的差异,旨在为从业者提供清晰的自我检视…

IFTTT (If This Then That) 是一个全球知名的自动化服务平台,其核心理念正是其名称的缩写“如果这样,那么就那样”。它旨在连接不同的网络应用、服务和智能设备,让用户无需编程即可创建个性化的自动化任务。通过定…