在Quora上曾经有个问题:Computer Programming: How would you explain a database in three sentences to your 8-year-old nephew被搬到了知乎上。
来自知乎的答案
中药铺说
电脑里面存了好多好多数据。数据就像各种各样中药,在没有数据库之前,中药就是一包包这样杂乱无章地堆放着(unorganized data),找也不好找(inaccessible)。如果你是药店的掌柜,你怎么来管理这些药呢?

聪明的古人就想了办法:把所有的中药都放到柜子里面(data table),柜子里面都是大小一样的小盒子(organized data model),每个盒子(a row/record)都在外面标签上写上药名,按笔划排序帮助快速查找(index/primary key),比如你要找三七,那么一定是三笔的头几个——现在找东西是不是方便多了?

如果要找一味温热的药,按名字找可就不大灵了,除了打开抽屉一个一个舔过去,还有什么办法快速找到吗?对啦,就是在抽屉上涂上颜色,比如温热的用粉红色,凉性的用蓝色(secondary key),你还可以用不同大小的抽屉代表药的其他属性(another secondary key)

如果有的药卖空了没有货怎么办?把整个抽屉拿走(delete a row)!如果新增加一种药怎么办?找一个空抽屉放上新药贴个标签呗(add a row)!如果整柜子中药都过期了怎么最快处理?把柜子搬走(drop a table),换个新柜子(create a table),再往里面添加新鲜中药。

如果有一种药量特别大,放在另外一个抽屉大一点儿的柜子里怎么办呢(splitted table)?在这个抽屉里放一张纸条,写上”此药在后堂第三个柜子第二个抽屉”(Foreign key/linked table)。

图书馆说
- 图书馆就是一个数据库:图书馆的每本书都有一个编号,编号表示了书的类别和顺序号,同类别的书放在一个书架上,然后书按顺序摆在它所属的书架上,这么做的好处是方便查找书。
- 图书馆管理员就是访问接口:你想找一本书时,他先找到这本书的类别和顺序号,然后他就到指定的书架上按顺序找到那本书,交给你。
- 你和其他人提出的借书请求就是外部程序,一本书可以借给你也可以借给别人,但是图书馆管理员知道书的状态并负责把书放回原位。
一篇通俗解释文
什么是数据库呢?
每个人家里都会有冰箱,冰箱是用来干什么的?冰箱是用来存放食物的地方。同样的,数据库是存放数据的地方。正是因为有了数据库后,我们可以直接查找数据。例如你每天使用余额宝查看自己的账户收益,就是从数据库读取数据后给你的。
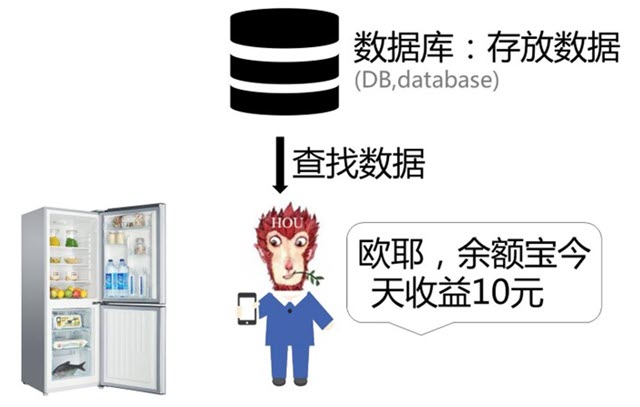
你可能会问了:我的数据就存放在自己电脑的excel表里就可以了,为什么还要搞个数据库呢?这是因为数据库比excel有更多的优势。数据库可以存放大量的数据,允许很多人同时使用里面的数据。
举个例子你就明白了,excel好比是一个移动硬盘,你使用了这个移动硬盘其他人就用不了了。数据库好比是网盘,很多人可以同时访问里面里的数据。而且网盘比移动硬盘能放更多的数据。
数据库是如何存放数据的?
数据库有很多种类,这里我们重点学习使用最广泛的关系数据库。关系数据库是由多个表组成的。如果你用过Excel,就会知道Excel是一张一张的二维表。每个表都是由行和列组成的。同样的,关系数据库里存放的也是一张一张的表,只不过各个表之间是有联系的。所以,简单来说:关系数据库=多张表+各表之间的关系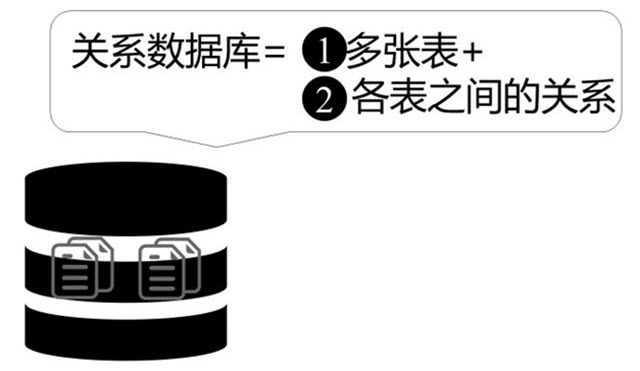
对应的,学会关系数据库我们只要掌握两点就可以:
- 多张表里面,每一张表的结构
- 各表之间的关系
我们接下来分别来看看这两个知识点。
表的结构
表的结构是指要了解关系数据库中每张表长什么样。每个表由一个名字标识。表包含带有列名的列,和记录数据的行。我们举个具体的例子就一目了然了。下面图片里的表名是:学生表,记录了每个学生的信息。
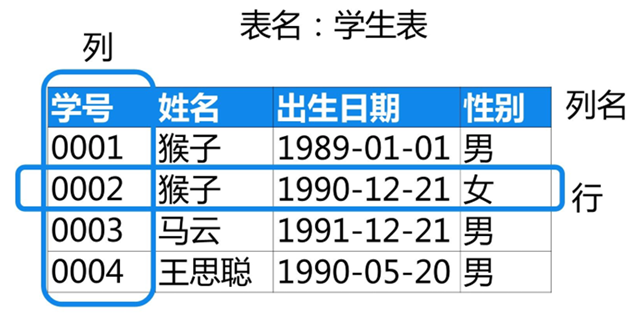
表中每一列都有一个名字来标识出该列,这个表里有4列,列名分别是学号,姓名,出生日期,性别。从列名上你也可以知道这一列对应记录的是什么数据。
表的每一行里记录着数据。这里的一行表示该名学生的信息,比如第2行是学号0002学生的信息,他的姓名是猴子,出生日期是1990-12-21,性别是女。
各表之间的关系
关系数据库是由多张表组成的,图片里是存放在学校数据库里的4张表。你能发现下面这4张表之间有什么关系吗?
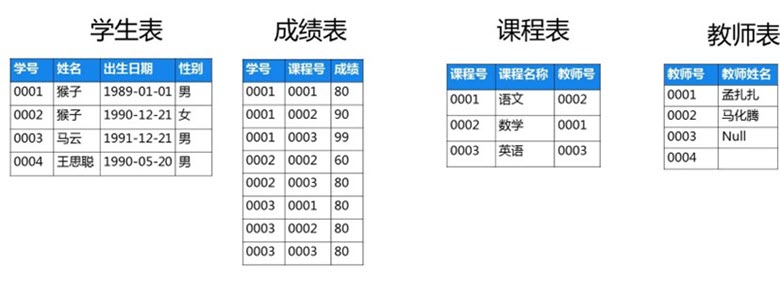
什么是关系呢?你是你爸爸的儿子,你是你的儿子的爸爸,这就是生活中的关系。其实,数据之间也是有关系的。关系数据库里各个表之间如何建立起关系呢?我们来看图中”学生表”,”成绩表”这两个表之前的关系。
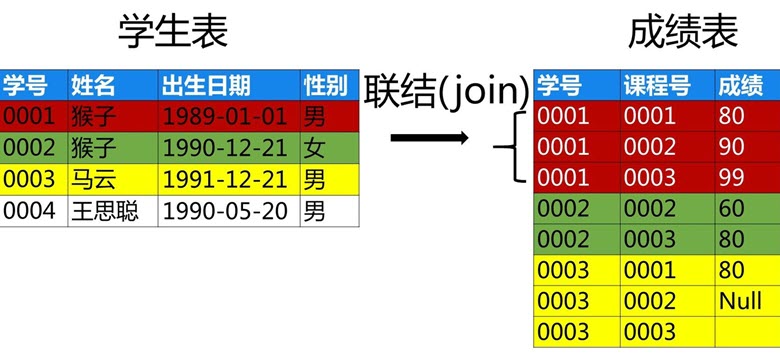 这两张表通过“学号”关联起来,为了更清楚的看到这两个表的关系,PPT里我用相同颜色代表同一个学生的信息。例如我想知道学生表里学号“0001”的成绩是多少?那么我就可以在成绩表里去查找“学号”值是0001的行,最后在成绩表里发现有3行数据的学号都是“0001”,对应的就找到了该学生的三门课程的成绩。
这两张表通过“学号”关联起来,为了更清楚的看到这两个表的关系,PPT里我用相同颜色代表同一个学生的信息。例如我想知道学生表里学号“0001”的成绩是多少?那么我就可以在成绩表里去查找“学号”值是0001的行,最后在成绩表里发现有3行数据的学号都是“0001”,对应的就找到了该学生的三门课程的成绩。
通过这个例子你应该对表之间的关系有了大概的了解。关系就是数据能够对应的匹配,在关系数据库中正式名称叫联结,对应的英文名称叫做 join。联结是关系型数据库中的核心概念,务必记住这个概念,后面会在多表查询中具体学到。
什么是数据库管理系统?
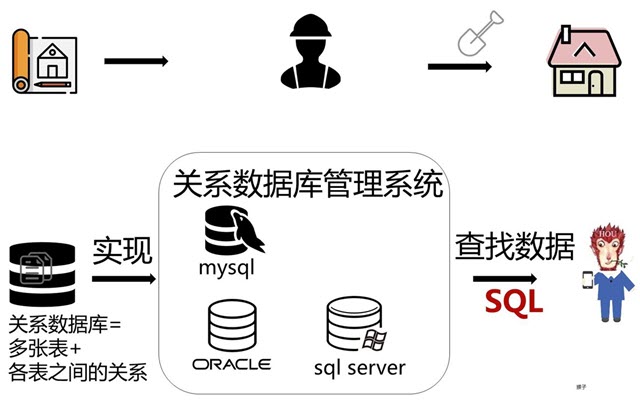
前面讲的都是关系数据库原理方面的基本理论。理论有了,当然的就的有对应的软件实现才能用起来,不然再强大的理论都是一堆无用的东东。这就好比,建筑师如果只有设计草图是无法盖起楼房的,得有具体的建筑人员才能盖起楼房。
所以,上面讲的关系数据库原理就是“设计草图”,那么对应的“建筑人员”是谁呢?实现数据库原理的“建筑人员”就是数据库管理系统,用来管理数据库的计算机软件。
关系数据库管理系统有很多种,比如 MySQL、Oracle、SQL Server 等都是实现上面理论的关系数据库。
什么是 SQL?
建筑施工人员通过使铲子,拉土机等工具来盖房子。那么,我们通过什么工具来操作数据库里的数据呢?这个工具就是 SQL。
SQL 是为操作数据库而开发的一种语言,它可以对数据库里的表进行操作,比如修改数据,查找数据。把数据库比如一碗米饭,里面放的米是数据。现在我们要吃碗里的米饭,怎么取出碗里的米饭呢?这时候我们拿一双筷子,用筷子操作碗里的米饭。这里的筷子就是 SQL,用来操作数据库里的数据。
认识数据库:简明数据库史
在工业时代,煤炭和钢铁的使用量是一个国家发达程度的指标。而到了信息时代,数据量将是新的发达程度指标,几乎所有行业竞争本质上都是数据的竞争。支撑数据增长的背后,是一代又一代不断演化的数据库引擎。
整个数据库大致经历了四个发展阶段。
第一阶段:非关系型数据库
在现代意义的数据库出来之前(20 世纪 60 年代),文件系统(Filesystem)可以说是最早的数据库,程序员们读取文本文件,并通过代码提取文件中的关键数据,在脑海中尝试构造数据与数据之间的关系。当年能流行起来的编程语言,往往都有很强的文件和数据处理能力(比如 Perl 语言)。随着数据量的增长,数据维度的多元化,以及对于数据可信和数据安全的要求不断提升,简单的将数据存储在 txt 文本中,成为极其具有挑战的事情。
随后,人们开始提出数据库管理系统(Database Management System, DBMS)的概念。数据库的演进抽象来看是人们对数据结构和数据关系这两个维度展开的思考和优化。
层次模型和网络模型(1960)
第一阶段的数据库模型(Database model) 是层次模型(Hierarchical Databases)。
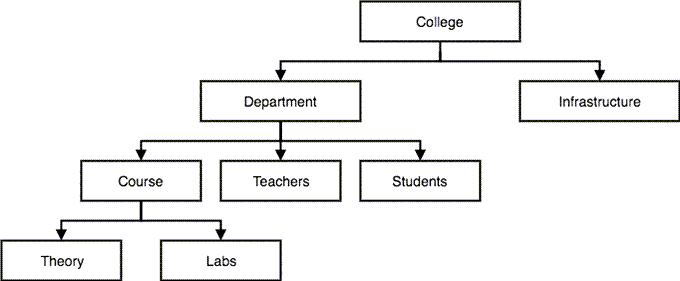
层次模型是最早的数据库模型。随着早期 IBM 大型机逐渐推广开来。这个模型相对于文本文件管理数据,是个巨大的提升,但也有很多问题。
层次模型的问题:
- 尽管能比较好的表达一对一(one to one) 结构,但在多对多(many to many) 结构上难以表达。如:图中能较好的表达一个系有多个老师,但很难表达一个老师可能属于多个系。
- 层次结构不够灵活。如:添加一个新的数据库关系有可能对整个数据库结构带来巨大变化,以至于在真正的开发中带来巨大的工作量
- 查询数据需要脑海中随时有最新的结构图,且需要遍历树状结构做推导
而后在层次模型的基础之上,人们提出了优化方案,即:网络模型(Network Model)。
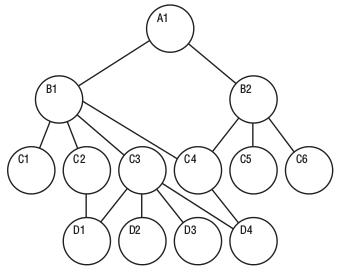
网络模型是关系型数据库出来之前最为流行的数据库模型。很好的解决了数据的多对多的问题。但依然存在以下问题:
- 难以从代码层面实现和维护
- 查询数据需要脑海中随时有最新的结构图
第二阶段:关系型数据库
模型初期(1970)
关系模型(Relational Model) 是相对网络模型的巨大飞跃。在网络模型中,不同类型的数据总是会依赖另一类数据,如图 1 中,Teachers 从属于 Departments,这是层次模型和网络模型在真实设计和开发中痛苦的根源(因为你总是要在脑海中记录当前的网络结构,想象一下一个拥有几千张表的复杂系统)
关系模型一大创新就是拆掉了表和表之间的链接,将关系只存储在当前表中的某一个字段中(fields),从而实现不同的表之间的相对独立。如下表:当你只看 Table2 的时候,你就知道 Product_code 会指向一个产品的具体细节,Table2 和 Table1 在保持相对独立的同时,又自然而然的连接了起来。
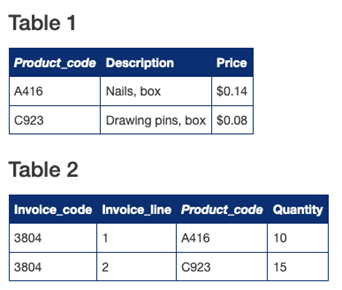
Table2 中的 Product_code 列指向了 Table1 中对应的数据,从而建立 Table2 和 Table1 的关系
1970 年,当 E.F.Codd 开发出这个模型时,人们认为是难以实现的,正如上面的例子一般,当你检索 Table2 时,遇到 Product_code 列,就需要再去 Table1 遍历一遍。受限于当时的硬件条件,这种检索方法总是会让机器难以负载。但很快,大家质疑的问题,在摩尔定律加持下,已经不再是问题。大家如今所听说的 IBM DB2, Ingres, Sybase, Oracle, Informix, MySQL 就是诞生在这个时代。
至此数据库领域诞生了一个大的分类:联机事务处理 OLTP(on-line transaction processing),代指一类专门用于日常事务的数据库,如银行交易用的增删改查数据库。后面还会提到另一类数据库,专门用于从大量数据中发现决策的辅助数据库 On-Line Analytical Processing – OLAP(联机分析处理)数据库。
数据仓库(1980s)
随着关系型数据库的发展,不同业务场景数据化,人们开始有了汇集不同业务场景数据,并尝试进行数据分析并辅助业务决策的想法(Decision Support System)。在此需求之上,诞生了数据仓库(Data warehouse)的概念。
如下图:一个企业往往把不同的业务场景数据存在不同的数据库中,在没有成熟的数据仓库产品之前,数据分析师往往需要自己做大量的前期准备工作来汇集自己所需的数据。而数据仓库本质上就是解决数据分析和挖掘的业务场景。
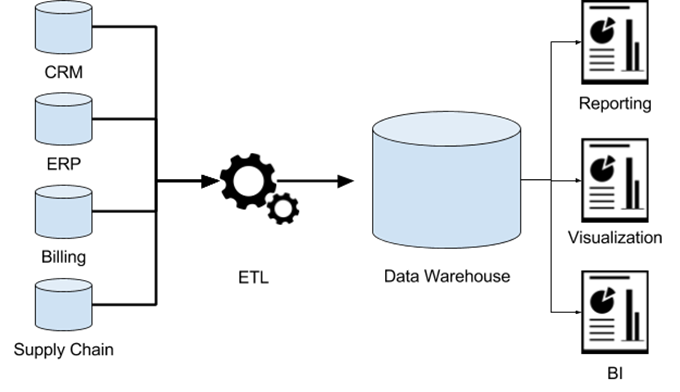
解释:ETL 是 Extract(提取),Transform(转换),Load(加载)的缩写。因为数据在不同的数据库或者系统中,可能存在格式不统一,单位不统一等等情况。需要做一次数据的预处理。
数据仓库是一个面向主题的、集成的、非易失的、随时间变化的用来支持管理人员决策数据集合。
OLAP(联机分析处理)1980年代有了数据仓库的概念和实现后,人们尝试在此基础上做数据分析。但分析的过程出现一些新的问题。最明显的是效率问题。因为之前的关系型数据库并不是为数据分析而打造。数据分析师想要的是一个支持多维的数据视图和多维数据操作的引擎。
如下面的数据魔方一般,相比于上面提到的关系型数据库中的二维数据展示和二维数据操作而言。OLAP数据库对多个维度的数据可以快速的组建和操作。
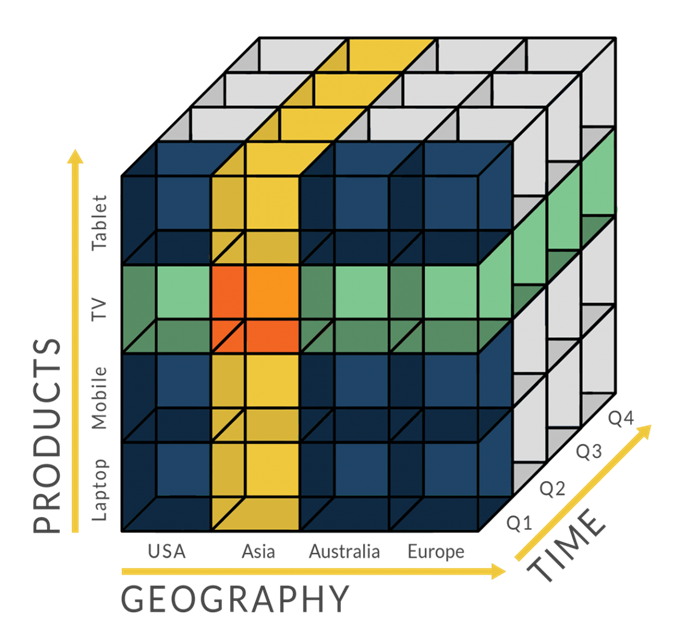
数据魔方:将多个维度的数据组织和展示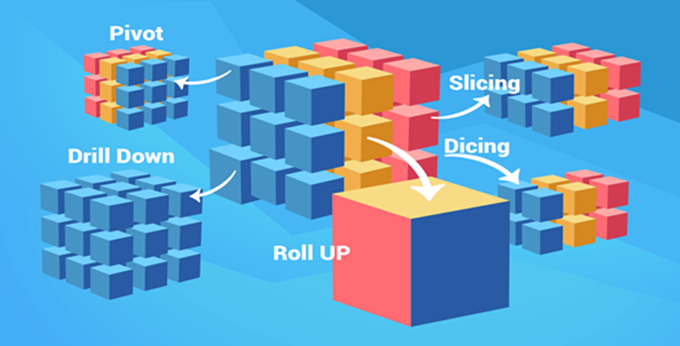
1993年,关系型数据库创始人 Edgar F. Codd 提出联机分析处理(OLAP)的概念。本质上是多维数据库和多维分析能力的概念。目标是满足决策支持或多维环境特定的查询和报表需求。
第三阶段:NoSQL
时间继续推进,互联网时代到来以后,数据量的暴增给关系型数据库也带来的新的挑战。最为明显的挑战有以下两点:
挑战一:数据列的扩展成本巨高
关系型数据库因为提前定义了 Table 的字段(Fields),当数据库已经拥有数以亿计条的数据之后,业务场景需要一列新的数据,你惊讶的发现,在关系型数据库的规则限制下,你必须要同时操作这数以亿计的数据爱完成新的一列的添加(不然数据库会有报错出现),对生产环境的服务器性能挑战极大。
可以想象一下 Facebook,Twitter, Weibo 这样的社交网站,每天字段都在不断的变化,来添加各种新的功能。
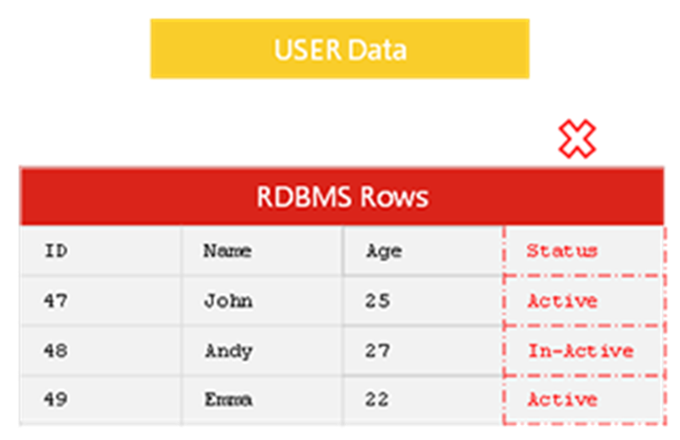
比如需要添加 status 列,你必须要在某一时刻同时为数以亿计的行,添加 Active 或者 In-Active 内容,否则数据库会无法满足合规约束挑战二:数据库性能的挑战
业务规模不断上升之后,关系型数据库的性能问题开始浮出水面,虽然数据库供应商都提出了各种解决方案,但底层关系绑定式的设计依然是性能天花板的根本原因。开发人员开始尝试分库、分表、加缓存等极限操作来挤出性能。
在此挑战之上,人们提出了新的数据库模型 – NoSQL。
针对扩展数据列的问题,NoSQL 提出了新的数据存储格式,去掉了关系模型的关系性。数据之间无关联,这样就换回了架构上的扩展性。
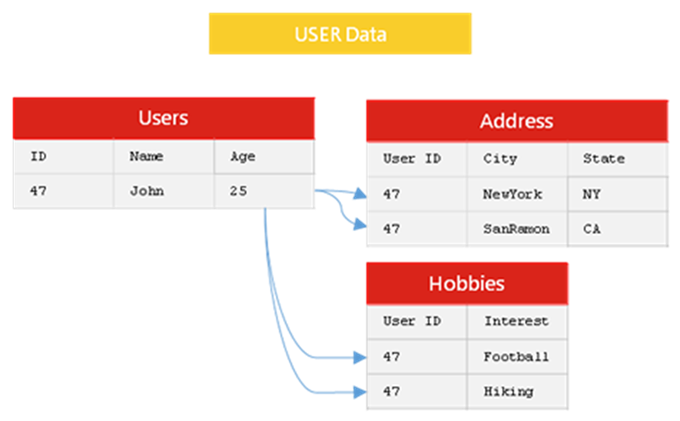

新的数据结构,将相关性数据都放在一起
NoSQL 更底层的创新源自于天生为集群可扩展场景所打造。
而在 NoSQL 理论基础之上,根据企业应用场景又拓展出了四大类型的数据库:
- 文档型数据库(Document-Oriented):如大名鼎鼎的 MongoDB、CouchDB。文档泛指一种数据的存储结构,如 XML、JSON、JSONB 等。
- 键值数据库(Key-Value Database):大家所听说的 Redis、Memcached、Riak 都是键值对数据库
- 列式存储数据库(Column-Family):如 Cassandra、HBase
- 图数据库(Graph-oriented):如 Neo4j、OrientDB 等。聚焦在数据间关系链的数据组织方式。
随着企业数据的不断变大,对数据处理能力也提出了新的要求。日常所听到的大数据(Big Data)一词,代表一个庞大的技术体系结构。包括了数据的采集,整理,计算,存储,分析等环节。数据库只是其中一环。如下图,饿了么2017年大数据架构,文中所提到的数据库,基本上只代表了图中存储环节。大家日常所听到的 Hadoop、Kafka、Hive、Spark、Materialize 等都是大数据引擎,千万不要搞混了。
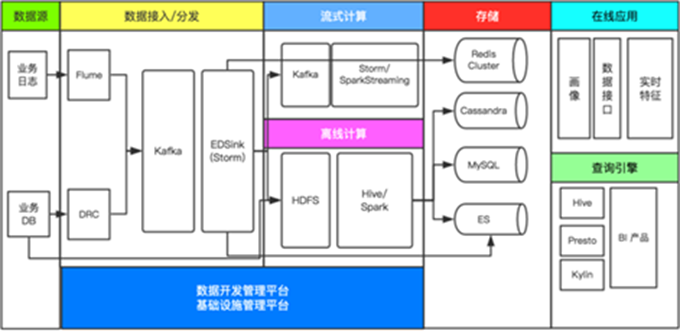
数据库只是大数据概念中的一部分。
第四阶段:云原生数据库
随着云时代的到来,基于云环境所打造的云原生数据库不断地开始占了数据库市场份额。
云原生数据库和托管/自建数据库最大的区别就是:云原生数据库是面向独立资源的云化,其 CPU、内存、存储等均可实现独立的弹性,利用大型云厂商的海量资源池,最大化其资源利用率,降低成本,同时支持独立扩展特定资源,满足多种用户不断变化的业务需求,实现完全的 Serverless; 而托管数据库还是局限于传统的服务器架构,各项资源等比率的限制在一个范围内,其弹性范围,资源利用率都受到较大的限制,无法充分利用云的红利。
基于云原生数据库技术,未来创业团队无需花费巨大精力来应对海量数据来袭,只需聚焦在业务即可。
云原生数据库的代表如:阿里云的 PolarDB、腾讯云的 CynosDB、华为云的 TaurusDB、亚马逊云的 Aurora。
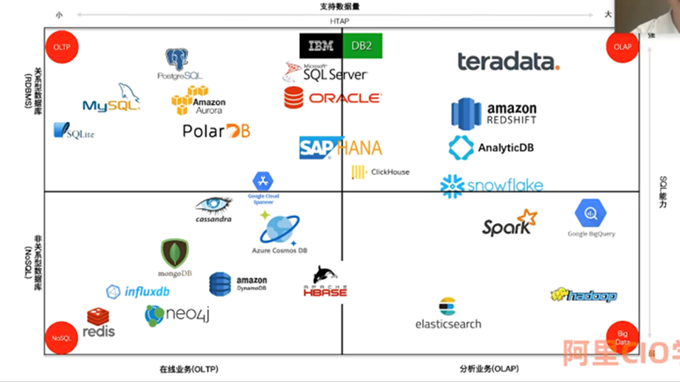
最后,以阿里 CIO 学院的一个数据库分布图结束这篇文章,图示中的数据库产品和分布图很好的代表了当前数据库产业的格局。
小结
数据库看起来相当复杂,但每个数据库的基本工作原理就像一个文件柜和存储程序的系统。当我们需要在许多地方保持信息的更新,并且我们希望对数据库的所有变化进行审计跟踪时,事情就开始变得更加复杂。但这种复杂性对于解决我们所解决的问题是必要的。
当谈到未来的计算机知识时,我知道并不是每个人都会成为程序员,但了解如何构建文件柜系统的细节,将使普通人能够从计算机中获得最大的好处。
参考链接:


