日常工作很多自动化的任务使用的是 Spark 运行,这里抽时间地 SparkSQL 进行系统的学习。

SparkSQL 与 HiveSQL 的区别
Hive 和 Spark 都是 Apache 的开源框架,而HiveSQL 和 SparkSQL 是这两种框架上运行的 SQL 引擎。它们各自有各自的特点和优势,以下列出了它们之间的一些主要区别:
- 执行速度:SparkSQL 通常比 HiveSQL 快,因为 SparkSQL 在内存中执行操作,而 HiveSQL 在硬盘上执行操作。
- 处理能力:SparkSQL 可以处理各种数据格式(如 JSON, Parquet, 数据库),同时它也支持复杂的 SQL 查询。而 HiveSQL 主要针对 Hadoop 上的批处理任务,优化了 MapReduce 的作业执行过程。
- 易用性:SparkSQL 支持 SQL 和复杂的分析操作,因此对于需要进行复杂数据处理和分析的用户更友好。而 HiveSQL 更符合传统 SQL 用户的使用习惯,因为它的语法和传统 SQL 更接近。
- 内存管理:SparkSQL 有更好的内存管理机制,它可以根据需要自动调整内存使用,这使得 SparkSQL 在处理大数据时可以更有效地利用资源。而 HiveSQL 则需要用户手动设置内存限制。
- 兼容性:SparkSQL 可以与各种数据源进行交互,包括 HDFS、HBase、Cassandra 等。而 Hive 主要与 Hadoop 进行交互。
SparkSQL 的 ANSI 兼容性
SparkSQL 的设计目标之一就是尽可能地满足 ANSI SQL 的兼容性。尽管 SparkSQL 支持大部分的 SQL 语法,但是要注意,SparkSQL 并不完全符合 ANSI SQL 标准。
从 Spark 3.0 版本开始,Apache Spark 项目开始着力提高 SparkSQL 的 ANSI SQL 兼容性,引入了一个新的配置 spark.sql.ansi.enabled,默认为 false。当设置为 true 时,SparkSQL 将遵循更严格的 ANSI SQL 规范。
例如,当开启 ANSI 模式后:
- SparkSQL 会对不合规的 SQL 语句抛出异常。例如,如果在聚合操作中有非聚合的列,或者 INSERT 语句中的列数与值的数目不匹配,这将导致语法错误。
- 对于除法操作,如果分母为零,SparkSQL 将会抛出异常,而不是返回无穷或者 NaN。
- SparkSQL 将不再自动进行类型强制转换。例如,在非 ANSI 模式下,如果你尝试将字符串列与整数列进行比较,Spark 会自动将字符串列转换为整数列。但在 ANSI 模式下,这将导致一个类型错误。
请注意,虽然 ANSI 模式可以增加 SQL 行为的一致性,但也可能导致一些现有的查询无法运行。因此在开启此模式之前,最好先进行充分的测试。
算术运算
在 SparkSQL 中,默认情况下不会检查对数字类型(小数除外)执行的算术运算是否存在溢出。这意味着,如果一个操作导致溢出,结果与 Java/Scala 程序中的相应操作相同(例如,如果 2 个整数的总和高于可表示的最大值,则结果为负数)。另一方面,SparkSQL 对于十进制溢出返回 null。当 spark.sql.ansi.enabled 设置为 true,并且在数值和区间算术运算中发生溢出时,它会在运行时引发算术异常。
CAST 强制转换
当 spark.sql.ansi.enabled 设置为 true 时,CAST 强制转换会为标准中定义的非法强制转换模式抛出运行时异常。
此外,ANSI SQL 模式不允许以下类型转换,当 ANSI 模式关闭时允许这些类型转换:
下表给出了 CAST 表达式中源数据类型和目标数据类型的有效组合。“Y”表示组合在语法上是有效的,没有限制,“N”表示组合无效。
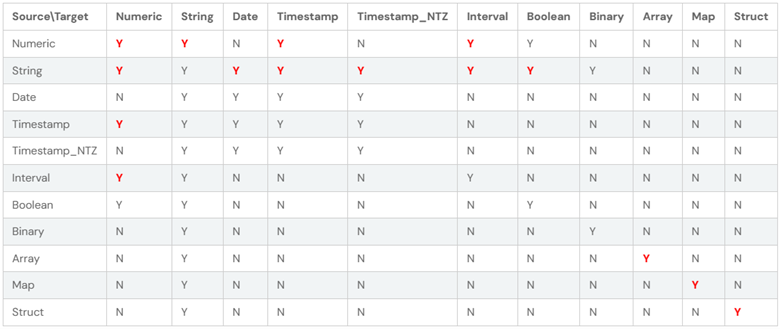
在上表中,所有具有新语法的 CAST 都标记为红色 Y:
- CAST(Numeric AS Numeric): 如果值超出目标数据类型的范围,则引发溢出异常。
- CAST(String AS (Numeric/Date/Timestamp/Timestamp_NTZ/Interval/Boolean)): 如果无法将值解析为目标数据类型,则引发运行时异常。
- CAST(Timestamp AS Numeric): 如果自 epoch 以来的秒数超出目标数据类型的范围,则引发溢出异常。
- CAST(Numeric AS Timestamp): 如果数值乘以 1000000(微秒/秒)超出 Long 类型的范围,则引发溢出异常。
- CAST(Array AS Array): 如果元素的转换中有异常,则引发异常。
- CAST(Map AS Map): 如果在键和值的转换上有任何异常,则引发异常。
- CAST(Struct AS Struct): 如果在结构字段的转换上存在异常,则引发异常。
- CAST(Numeric AS String): 将十进制值强制转换为字符串时,始终使用纯字符串表示法,而不是在需要指数时使用科学表示法
- CAST(Interval AS Numeric): 如果日时间间隔的微秒数或年-月间隔的月数超出目标数据类型的范围,则引发溢出异常。
- CAST(Numeric AS Interval): 如果目标时间间隔的结束单位的数值时间超出 Int 类型(年-月时间间隔)或 Long 类型(日-时间间隔)的范围,则引发溢出异常。
存储分配策略
当 spark.sql.storeAssignmentPolicy 设置为 ANSI(这是默认值)时,SparkSQL 在进行表插入操作时会遵守 ANSI 存储分配规则。所谓的 ANSI 存储分配规则,指的是在进行插入操作时,源数据类型和目标数据类型必须是有效的组合。换句话说,只有符合某些规定的数据类型间才能进行转换和存储,这些有效的组合通常由一张表格给出。这种策略是为了保证数据的一致性和准确性,避免在插入表时进行不合理的数据类型转换,从而导致数据错误或精度丢失。
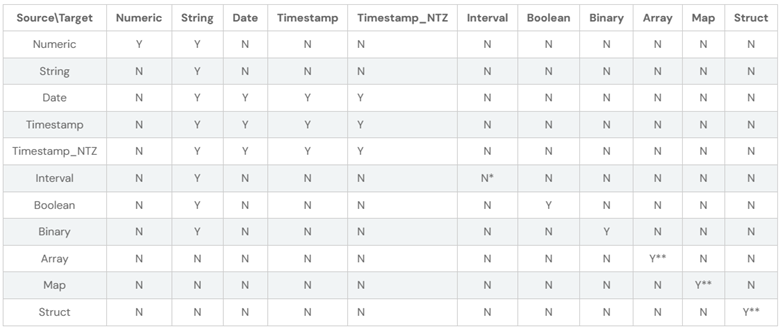
类型强制转换
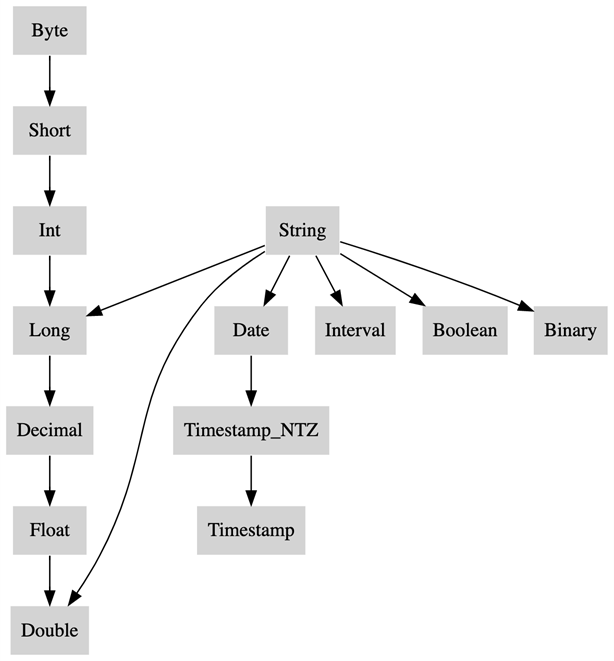
当 spark.sql.ansi.enabled 设置为 true 时,SparkSQL 会使用一些规则来解决数据类型之间的冲突。这些规则主要是关于当两种不同的数据类型需要相互转换时,如何进行转换。
在这种冲突解决的核心是类型优先级列表(Type Precedence List)。这个列表定义了给定的数据类型的值是否可以隐式地提升为另一种数据类型。所谓的提升,指的是一种数据类型可以无损地转换为另一种数据类型。例如,在许多情况下,一个整数可以无损地转换为一个浮点数。
这种类型强制转换和提升的主要目的是为了在执行 SQL 查询时,可以处理不同的数据类型,而不需要用户显式地进行类型转换。这样不仅简化了 SQL 查询的编写,也确保了数据的准确性和一致性。
SQL 函数
在 ANSI 模式(即 spark.sql.ansi.enabled=true)下,一些 SQL 函数的行为可能与非 ANSI 模式下有所不同。
- size:这个函数在输入为 null 时返回 null。
- element_at:如果使用了无效的索引,这个函数会抛出 ArrayIndexOutOfBoundsException。
- elt:如果使用了无效的索引,这个函数会抛出 ArrayIndexOutOfBoundsException。
- parse_url:如果输入字符串不是一个有效的 URL,这个函数会抛出 IllegalArgumentException。
- to_date:如果输入字符串无法解析,或者模式字符串无效,这个函数应当抛出异常。
- to_timestamp:如果输入字符串无法解析,或者模式字符串无效,这个函数应当抛出异常。
- unix_timestamp:如果输入字符串无法解析,或者模式字符串无效,这个函数应当抛出异常。
- to_unix_timestamp:如果输入字符串无法解析,或者模式字符串无效,这个函数应当抛出异常。
- make_date:如果结果日期无效,这个函数应当抛出异常。
- make_timestamp:如果结果时间戳无效,这个函数应当抛出异常。
- make_interval:如果结果间隔无效,这个函数应当抛出异常。
- next_day:如果输入不是一个有效的一周中的某一天,这个函数会抛出 IllegalArgumentException。
总的来说,这些函数在 ANSI 模式下的行为更加严格,对于无效的输入或者无法进行正确操作的情况,会抛出异常,而不是返回可能误导的结果。这样做的目的是为了确保数据的准确性和一致性。
在 ANSI 模式(即 spark.sql.ansi.enabled=true)下,某些 SQL 操作符的行为可能与非 ANSI 模式下有所不同。具体来说,对于数组列的索引操作 array_col[index],如果使用了无效的索引,那么在 ANSI 模式下,这个操作将会抛出 ArrayIndexOutOfBoundsException 异常。
在 ANSI 模式(即 spark.sql.ansi.enabled=true)下,对于无效的操作,SparkSQL 会抛出异常。但是,你可以使用以下的一些 SQL 函数来避免这些异常,这些函数会在出现运行时错误时返回 NULL 结果,而不是抛出异常:
- try_cast: 与 CAST 函数相同,但在出现运行时错误时返回 NULL,而不是抛出异常。
- try_add: 与加法操作符 + 相同,但在整数溢出时返回 NULL,而不是抛出异常。
- try_subtract: 与减法操作符 – 相同,但在整数溢出时返回 NULL,而不是抛出异常。
- try_multiply: 与乘法操作符 * 相同,但在整数溢出时返回 NULL,而不是抛出异常。
- try_divide: 与除法操作符 / 相同,但在除以 0 时返回 NULL,而不是抛出异常。
- try_sum: 与 sum 函数相同,但在整数/小数/时间间隔值溢出时返回 NULL,而不是抛出异常。
- try_avg: 与 avg 函数相同,但在小数/时间间隔值溢出时返回 NULL,而不是抛出异常。
- try_element_at: 与 element_at 函数相同,但在数组索引越界时返回 NULL,而不是抛出异常。
- try_to_timestamp: 与 to_timestamp 函数相同,但在字符串解析错误时返回 NULL,而不是抛出异常。
这些函数在出现可能会抛出异常的错误时,提供了一种更加安全的操作方式,可以保证查询的连续性,而不是因为一个错误而中断整个查询。
SQL 关键字(可选,默认禁用)
当 spark.sql.ansi.enabled 和 spark.sql.ansi.enforceReservedKeywords 都为 true 时,sparksql 将使用 ansi 模式解析器。
使用 ANSI 模式解析器,SparkSQL 有两种关键字:
- Non-reserved 关键字:仅在特定上下文中具有特殊含义,并可在其他上下文中用作标识符的关键字。例如,EXPLAIN SELECT … 是一个命令,但 EXPLAIN 可以在其他地方用作标识符。
- Reserved 关键字:保留的关键字,不能用作表、视图、列、函数、别名等的标识符。
使用默认的解析器,SparkSQL 有两种关键字:
- Non-reserved 关键字:与启用 ANSI 模式时的定义相同。
- Strict-non-reserved 严格非保留关键字:非保留关键字的严格版本,不能用作表别名。
默认情况下,spark.sql.ansi.enabled 和 spark.sql.ansi.enforceReservedKeywords 均为 false。
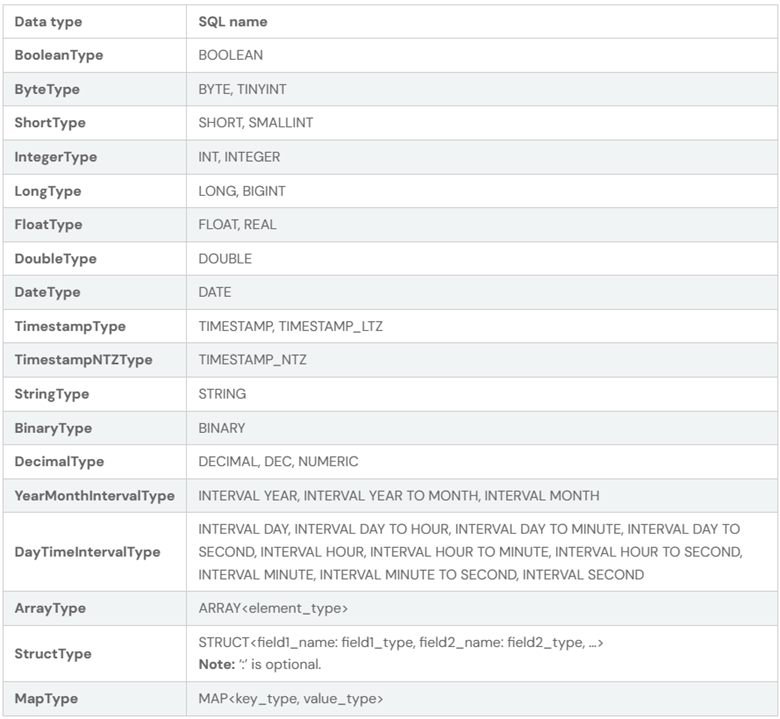
SparkSQL 数据类型
支持的数据类型:
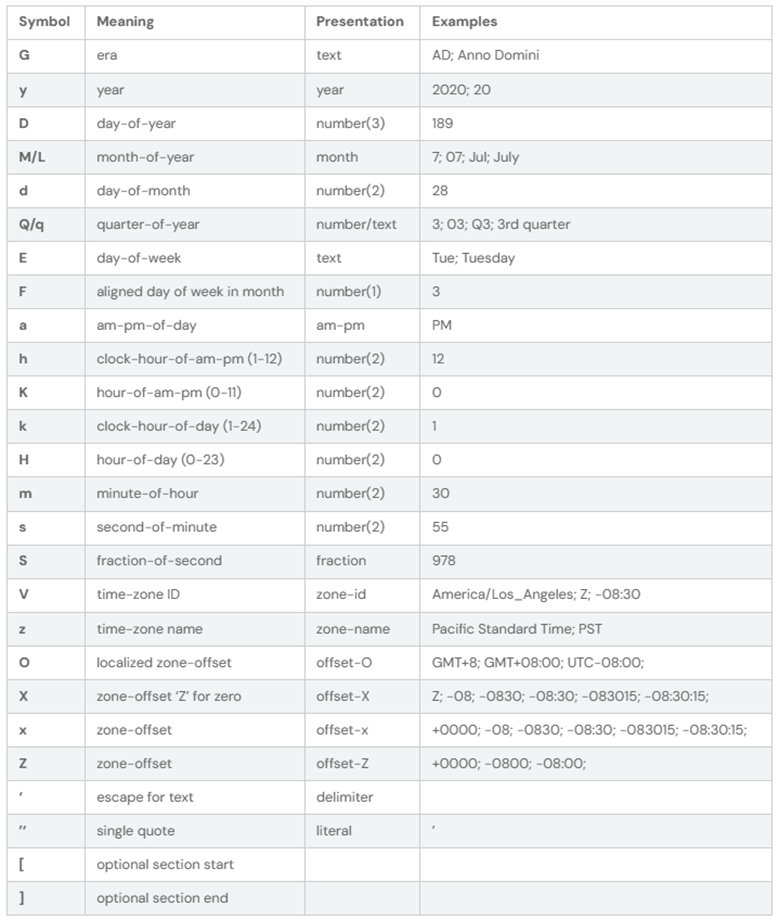
SparkSQL 日期时间格式
Spark 中有几种常见的日期时间使用场景:
- CSV/JSON 数据源使用模式字符串来解析和格式化日期时间内容。
- 与将 StringType 转换为 DateType 或 TimestampType 相关的 Datetime 函数。例如,unix_timestamp、date_format、to_unix_timestamp、from_unix_time、to_date、to_timestamp、from_utc_timestamp 和 to_utc_timestamp 等。
Spark 使用下表中的模式字母进行日期和时间戳解析和格式化:
SparkSQL 内置函数
在 SparkSQL 中,函数可以被分类为三种主要类型:标量函数(Scalar Functions)、聚合函数(Aggregate-like Functions)和生成器函数(Generator Functions):
- 标量函数(Scalar Functions):这种类型的函数作用于单个行上并返回单个值。例如,ABS()、UPPER()、SUBSTR() 等。标量函数通常用于转换数据,比如改变数据的类型或者对数据进行数学计算。
- 聚合函数(Aggregate-like Functions):聚合函数作用于一组行上,然后返回单个值。这些函数用于执行计算,比如求和、求平均值、计数、找最大值或最小值等。一些常见的聚合函数包括 SUM()、AVG()、COUNT()、MAX() 和 MIN() 等。
- 生成器函数(Generator Functions):生成器函数是一种特殊的函数,它可以从每一行生成多行。这种函数通常用于处理数组或者映射类型的数据。比如,explode 函数可以将数组或者映射类型的列“展开”为多行。
这三种类型的函数为 SparkSQL 提供了强大的数据处理能力,使得用户可以方便地进行各种复杂的数据操作。
标量函数
数组函数
| 函数 | 描述 |
| array(expr, …) | 返回具有给定元素的数组。 |
| array_append(array, element) | 在作为第一个参数传递的数组末尾添加元素。元素的类型应和数组的元素类型相似。NULL 元素也被追加到数组中。 |
| array_compact(array) | 从数组中删除 NULL 值。 |
| array_contains(array, value) | 如果数组包含值,则返回 true。 |
| array_distinct(array) | 从数组中删除重复的值。 |
| array_except(array1, array2) | 返回 array1 中的元素数组,但不返回 array2 中的元素。 |
| array_insert(x, pos, val) | |
| array_intersect(array1, array2) | 返回 array1 和 array2 相交处的元素数组,不重复。 |
| array_join(array, delimiter[, nullReplacement]) | 使用分隔符和可选字符串连接给定数组的元素以替换 null。如果没有为 nullReplacement 设置任何值,则会过滤任何 null 值。 |
| array_max(array) | 返回数组中的最大值。对于双精度/浮点型,NaN 大于任何非 NaN 元素。跳过 NULL 元素。 |
| array_min(array) | 返回数组中的最小值。对于双精度/浮点型,NaN 大于任何非 NaN 元素。跳过 NULL 元素。 |
| array_position(array, element) | 返回数组中第一个匹配元素的索引(从 1 开始),如果没有找到匹配项,则返回 0。 |
| array_prepend(array, element) | 在作为第一个参数传递的数组的开头添加元素。元素的类型应与数组中元素的类型相同。Null 元素也已预先添加到数组中。但如果传递的数组为 NULL,则输出为 NULL |
| array_remove(array, element) | 从数组中移除所有等于元素的元素。 |
| array_repeat(element, count) | 返回包含元素计数次数的数组。 |
| array_union(array1, array2) | 返回 array1 和 array2 并集中元素的数组,不重复。 |
| arrays_overlap(a1, a2) | 如果 a1 中至少包含一个非 null 元素,则返回 true。如果数组没有公共元素,并且它们都不是空的,并且其中任何一个包含 null 元素,则返回 null,否则返回 false。 |
| arrays_zip(a1, a2, …) | 返回一个合并的结构数组,其中第 N 个结构包含输入数组的所有第 N 个值。 |
| flatten(arrayOfArrays) | 将数组数组转换为单个数组。 |
| get(array, index) | 返回给定(从 0 开始)索引处的数组元素。如果索引指向数组边界之外,则此函数返回 NULL。 |
| sequence(start, stop, step) | 生成一个元素数组,从开始到结束(包含),按步长递增。返回的元素的类型与参数表达式的类型相同。支持的类型有:字节、短、整数、长、日期、时间戳。开始表达式和停止表达式必须解析为相同的类型。如果开始表达式和停止表达式解析为“date”或“timestamp”类型,则步骤表达式必须解析为“interval”或“year-month-interval”或者“day-time interval”类型,否则解析为与开始表达式和结束表达式相同的类型。 |
| shuffle(array) | 返回给定数组的随机排列。 |
| slice(x, start, length) | 将数组 x 从索引开始(数组索引从 1 开始,或者如果 start 为负数,则从末尾开始)以指定的长度子集。 |
| sort_array(array[, ascendingOrder]) | 根据数组元素的自然顺序,按升序或降序对输入数组进行排序。对于双精度/浮点型,NaN 大于任何非 NaN 元素。空元素将按升序放置在返回数组的开头,或按降序放置在返回阵列的末尾。 |
Map 函数
| 函数 | 描述 |
| element_at(array, index) | 返回给定(从 1 开始)索引处的数组元素。如果 Index 为 0,Spark 将抛出一个错误。如果索引<0,则从最后一个到第一个访问元素。如果索引超过数组的长度,并且“spark.sql.ansi.enabled”设置为 false,则函数返回 NULL。如果“spark.sql.ansi.enabled”设置为 true,则会引发无效索引的 ArrayIndexOutOfBoundsException。 |
| element_at(map, key) | 返回给定键的值。如果映射中不包含该键,则函数返回 NULL。 |
| map(key0, value0, key1, value1, …) | 使用给定的键值对创建映射。 |
| map_concat(map, …) | 返回所有给定映射的并集 |
| map_contains_key(map, key) | 如果映射包含键,则返回 true。 |
| map_entries(map) | 返回给定映射中所有条目的无序数组。 |
| map_from_arrays(keys, values) | 使用一对给定的键/值数组创建贴图。键中的所有元素都不应为 null |
| map_from_entries(arrayOfEntries) | 返回根据给定的条目数组创建的映射。 |
| map_keys(map) | 返回一个无序数组,其中包含映射的键。 |
| map_values(map) | 返回一个包含映射值的无序数组。 |
| str_to_map(text[, pairDelim[, keyValueDelim]]) | 使用分隔符将文本拆分为键/值对后创建映射。“pairDelim”的默认分隔符为“,”,“keyValueDelim”为“:”。“pairDelim”和“keyValueDelim”都被视为正则表达式。 |
| try_element_at(array, index) | 返回给定(从 1 开始)索引处的数组元素。如果 Index 为 0,Spark 将抛出一个错误。如果索引<0,则从最后一个到第一个访问元素。如果索引超过数组的长度,函数总是返回 NULL。 |
| try_element_at(map, key) | 返回给定键的值。如果映射中不包含键,则函数始终返回 NULL。 |
日期与时间戳函数
| 函数 | 描述 |
| add_months(start_date, num_months) | 返回“start_date”之后的“num_months”日期。 |
| convert_timezone([sourceTz, ]targetTz, sourceTs) | 将没有时区“sourceTs”的时间戳从“sourceTz”时区转换为“targetTz”。 |
| curdate() | 返回查询评估开始时的当前日期。同一查询中对 curdate 的所有调用都返回相同的值。 |
| current_date() | 返回查询评估开始时的当前日期。同一查询中的所有 current_date 调用都返回相同的值。 |
| current_date | 返回查询评估开始时的当前日期。 |
| current_timestamp() | 返回查询评估开始时的当前时间戳。同一查询中的所有 current_timestamp 调用都返回相同的值。 |
| current_timestamp | 返回查询评估开始时的当前时间戳。 |
| current_timezone() | 返回当前会话本地时区。 |
| date_add(start_date, num_days) | 返回”start_date”之后的”num_days”日期。 |
| date_diff(endDate, startDate) | 返回从”startDate”到”endDate”的天数。 |
| date_format(timestamp, fmt) | 将”timestamp”转换为日期格式”fmt”指定的格式的字符串值。 |
| date_from_unix_date(days) | 根据 1970 年 1 月 1 日以来的天数创建日期。 |
| date_part(field, source) | 提取日期/时间戳或间隔源的一部分。 |
| date_sub(start_date, num_days) | 返回”start_date”之前的”num_days”日期。 |
| date_trunc(fmt, ts) | 返回截断为格式模型”fmt”指定的单位的时间戳”ts”。 |
| dateadd(start_date, num_days) | 返回”start_date”之后的”num_days”日期。 |
| datediff(endDate, startDate) | 返回从”startDate”到”endDate”的天数。 |
| datepart(field, source) | 提取日期/时间戳或间隔源的一部分。 |
| day(date) | 返回日期/时间戳的月份日期。 |
| dayofmonth(date) | 返回日期/时间戳的月份日期。 |
| dayofweek(date) | 返回日期/时间戳的星期几(1=星期日,2=星期一,…,7=星期六)。 |
| dayofyear(date) | 返回日期/时间戳的年份中的哪一天。 |
| extract(field FROM source) | 提取日期/时间戳或间隔源的一部分。 |
| from_unixtime(unix_time[, fmt]) | 在指定的”fmt”中返回”unix_time”。 |
| from_utc_timestamp(timestamp, timezone) | 给定类似”2017-07-14 02:40:00.0″的时间戳,将其解释为 UTC 中的时间,并将该时间呈现为给定时区中的时间戳。例如,”GMT+1″将生成”2017-07-14 03:40:00.0″。 |
| hour(timestamp) | 返回字符串/时间戳的小时部分。 |
| last_day(date) | 返回日期所属月份的最后一天。 |
| localtimestamp() | 返回查询评估开始时不带时区的当前时间戳。同一查询中对 localtimestamp 的所有调用都返回相同的值。 |
| localtimestamp | 返回查询评估开始时会话时区的当前本地日期时间。 |
| make_date(year, month, day) | 从年、月和日字段创建日期。如果配置”spark.sql.ansi.enabled”为 false,则该函数在无效输入时返回 NULL。否则,它将引发错误。 |
| make_dt_interval([days[, hours[, mins[, secs]]]]) | 使 DayTimeIntervalType 持续时间从天、小时、分钟和秒开始。 |
| make_interval([years[, months[, weeks[, days[, hours[, mins[, secs]]]]]]]) | 从年、月、周、日、小时、分钟和秒开始间隔。 |
| make_timestamp(year, month, day, hour, min, sec[, timezone]) | 从年、月、日、小时、分钟、秒和时区字段创建时间戳。结果数据类型与配置”spark.sql.timestampType”的值一致。如果配置”spark.sql.ansi.enabled”为 false,则该函数在无效输入时返回 NULL。否则,它将引发错误。 |
| make_timestamp_ltz(year, month, day, hour, min, sec[, timezone]) | 从年、月、日、小时、分钟、秒和时区字段创建具有本地时区的当前时间戳。如果配置”spark.sql.ansi.enabled”为 false,则该函数在无效输入时返回 NULL。否则,它将引发错误。 |
| make_timestamp_ntz(year, month, day, hour, min, sec) | 从年、月、日、小时、分钟、秒字段创建本地日期时间。如果配置”spark.sql.ansi.enabled”为 false,则该函数在无效输入时返回 NULL。否则,它将引发错误。 |
| make_ym_interval([years[, months]]) | 从年、月开始以年-月为间隔。 |
| minute(timestamp) | 返回字符串/时间戳的分钟分量。 |
| month(date) | 返回日期/时间戳的月份部分。 |
| months_between(timestamp1, timestamp2[, roundOff]) | 如果”timestamp1″晚于”timestamp2″,则结果是积极的。如果”timestamp1″和”timestamp2″位于月份的同一天,或两者兼而有之是每月的最后一天,一天中的时间将被忽略。否则,区别在于根据每月 31 天计算,并四舍五入为 8 位数字,除非 roundOff=false。 |
| next_day(start_date, day_of_week) | 返回晚于”start_date”并按指示命名的第一个日期。如果至少有一个输入参数为 NULL,则该函数返回 NULL。当两个输入参数都不是 NULL 并且 day_of_week 是无效输入时,如果”spark.sql.ansi.enabled”设置为 true,则该函数将引发 IllegalArgumentException,否则为 NULL。 |
| now() | 返回查询评估开始时的当前时间戳。 |
| quarter(date) | 返回日期的季度,范围为 1 到 4。 |
| second(timestamp) | 返回字符串/时间戳的第二个组件。 |
| session_window(time_column, gap_duration) | |
| timestamp_micros(microseconds) | 根据 UTC 纪元以来的微秒数创建时间戳。 |
| timestamp_millis(milliseconds) | 根据 UTC 纪元以来的毫秒数创建时间戳。 |
| timestamp_seconds(seconds) | 根据 UTC 纪元以来的秒数(可以是小数)创建时间戳。 |
| to_date(date_str[, fmt]) | 将”date_str”表达式与”fmt”表达式解析为一个日期。返回 null 且输入无效。默认情况下,它遵循强制转换规则到日期,如果省略”FMT”。 |
| to_timestamp(timestamp_str[, fmt]) | 使用”fmt”表达式解析”timestamp_str”表达式到时间戳。返回 null 且输入无效。默认情况下,它遵循强制转换规则如果省略了”fmt”,则为时间戳。结果数据类型与配置 ‘spark.sql.timestampType’。 |
| to_timestamp_ltz(timestamp_str[, fmt]) | 使用”fmt”表达式解析”timestamp_str”表达式设置为具有本地时区的时间戳。返回 null 且输入无效。默认情况下,它遵循强制转换规则如果省略了”fmt”,则为时间戳。 |
| to_timestamp_ntz(timestamp_str[, fmt]) | 使用”fmt”表达式解析”timestamp_str”表达式到没有时区的时间戳。返回 null 且输入无效。默认情况下,它遵循强制转换规则如果省略了”fmt”,则为时间戳。 |
| to_unix_timestamp(timeExp[, fmt]) | 返回给定时间的 UNIX 时间戳。 |
| to_utc_timestamp(timestamp, timezone) | 给定类似”2017-07-14 02:40:00.0″的时间戳,将其解释为给定时区中的时间,并将该时间呈现为 UTC 中的时间戳。例如,”GMT+1″将生成”2017-07-14 01:40:00.0″。 |
| trunc(date, fmt) | 返回 ‘date’,其中一天中的时间部分被截断为格式模型 ‘fmt’ 指定的单位。 |
| try_to_timestamp(timestamp_str[, fmt]) | 使用”fmt”表达式解析”timestamp_str”表达式到时间戳。该函数始终在有/没有 ANSI SQL 的无效输入上返回 null 模式已启用。默认情况下,如果省略”fmt”,它会遵循时间戳的强制转换规则。结果数据类型与配置”spark.sql.timestampType”的值一致。 |
| unix_date(date) | 返回自 1970 年 1 月 1 日以来的天数。 |
| unix_micros(timestamp) | 返回自 1970-01-01 00:00:00 UTC 以来的微秒数。 |
| unix_millis(timestamp) | 返回自 1970-01-01 00:00:00 UTC 以来的毫秒数。截断更高级别的精度。 |
| unix_seconds(timestamp) | 返回自 1970-01-01 00:00:00 UTC 以来的秒数。截断更高级别的精度。 |
| unix_timestamp([timeExp[, fmt]]) | 返回当前时间或指定时间的 UNIX 时间戳。 |
| weekday(date) | 返回日期/时间戳的星期几(0=星期一,1=星期二,…,6=星期日)。 |
| weekofyear(date) | 返回给定日期的一年中的星期。一周被认为是从星期一开始的,第 1 周是第一周,有 >3 天。 |
| window(time_column, window_duration[, slide_duration[, start_time]]) | 在给定指定列的时间戳的情况下,将行存储为一个或多个时间窗口。窗口开始是包含的,但窗口结束是排他性的,例如 12:05 将在窗口[12:05,12:10]中,但不在[12:00,12:05]中。Windows 可以支持微秒级精度。不支持按月顺序排列的 Windows。有关详细说明和示例,请参阅结构化流式处理指南文档中的”事件时间的窗口操作”。 |
| window_time(window_column) | 从时间/会话窗口列中提取时间值,该值可用于窗口的事件时间值。提取的时间是(window.end-1),它反映了聚合 Windows 具有独占上限-[开始、结束]有关详细说明和示例,请参阅结构化流式处理指南文档中的”事件时间的窗口操作”。 |
| year(date) | 返回日期/时间戳的年份部分。 |
事件时间的窗口操作
在 Spark SQL 中,时间窗口函数是处理时间序列数据的重要工具。以下是一些常见的时间窗口函数:
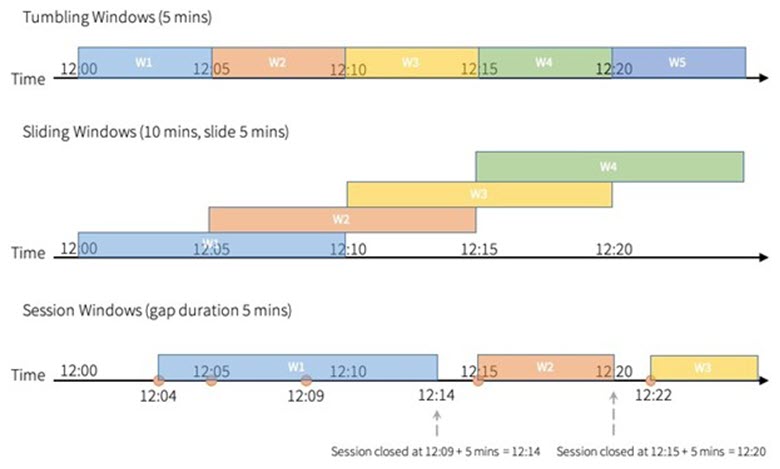
- session_window(time_column, gap_duration):session_window 函数创建了一种叫做”会话窗口”的窗口。这种窗口基于活动的连续性,即如果在指定的 gap_duration 时间段内没有新的行到来,那么当前的会话窗口就结束,新的会话窗口开始。这个函数具有两个参数:time_column 指定了时间列,gap_duration 定义了两个会话窗口之间的间隔。
- window(time_column, window_duration[, slide_duration[, start_time]]):window 函数创建了一种固定大小的窗口,这种窗口可以滑动。这个函数需要至少两个参数,可以有最多四个参数。time_column 指定了时间列,window_duration 定义了窗口的长度。可选的 slide_duration 参数定义了窗口滑动的频率,而可选的 start_time 参数定义了第一个窗口开始的时间。
- window_time(window_column):这个函数返回一个字符串,这个字符串描述了窗口的开始和结束时间。这个函数的参数 window_column 应该是一个类型为窗口的列,通常是通过 window 函数创建的。
这些时间窗口函数允许你在时间序列数据上进行各种复杂的聚合和分析操作,比如计算每分钟的平均交易量,或者找出用户的活跃时间段等。
JSON 函数
| 函数 | 描述 |
| from_json(jsonStr, schema[, options]) | 返回具有给定”jsonStr”和”schema”的结构值。 |
| get_json_object(json_txt, path) | 从”path”中提取 json 对象。 |
| json_array_length(jsonArray) | 返回最外层 JSON 数组中的元素数。 |
| json_object_keys(json_object) | 以数组形式返回最外层 JSON 对象的所有键。 | 返回一个类似于函数 get_json_object 的元组,但它采用多个名称。所有输入参数和输出列类型均为字符串。 |
| schema_of_json(json[, options]) | 以 JSON 字符串的 DDL 格式返回架构。 |
| to_json(expr[, options]) | 返回具有给定结构值的 JSON 字符串 |
具体使用方法,详见:SparkSQL JSON 数据的解析
数学函数
| 函数 | 描述 |
| expr1 % expr2 | 返回 ‘expr1’ / ‘expr2’ 之后的余数。 |
| expr1 * expr2 | 返回 ‘expr1’ * ‘expr2’。 |
| expr1 + expr2 | 返回 ‘expr1’ + ‘expr2’。 |
| expr1 – expr2 | 返回 ‘expr1’ – ‘expr2’。 |
| expr1 / expr2 | 返回 ‘expr1’ / ‘expr2’。它始终执行浮点除法。 |
| abs(expr) | 返回数值或间隔值的绝对值。 |
| acos(expr) | 返回 ‘expr’ 的反余弦(又名反余弦),同 ‘java.lang.Math.acos’。 |
| acosh(expr) | 返回 ‘expr’ 的反双曲余弦。 |
| asin(expr) | 返回反正弦(又名弧正弦)’expr’ 的弧正弦,同 “java.lang.Math.asin”。 |
| asinh(expr) | 返回 ‘expr’ 的反双曲正弦。 |
| atan(expr) | 返回 ‘expr’ 的反正切(又名弧正切),同 ‘java.lang.Math.atan’。 |
| atan2(exprY, exprX) | 返回平面的正 x 轴之间的角度(以弧度为单位)以及坐标给出的点(’exprX’,’exprY’),同 ‘java.lang.Math.atan2’。 |
| atanh(expr) | 返回 ‘expr’ 的反双曲正切。 |
| bin(expr) | 返回以二进制形式表示的长值 “expr” 的字符串表示形式。 |
| bround(expr, d) | 使用舍入模式返回舍入到小数点后 “d” 位。 |
| cbrt(expr) | 返回 “expr” 的多维数据集根目录。 |
| ceil(expr[, scale]) | 返回舍入后不小于 “expr” 的最小数字。可以指定可选的 “scale” 参数来控制舍入行为。 |
| ceiling(expr[, scale]) | 返回舍入后不小于 “expr” 的最小数字。可以指定可选的 “scale” 参数来控制舍入行为。 |
| conv(num, from_base, to_base) | 将 “num” 从 “from_base” 转换为 “to_base”。 |
| cos(expr) | 返回 ‘expr’ 的余弦,同 ‘java.lang.Math.cos’。 |
| cosh(expr) | 返回 ‘expr’ 的双曲余弦,同 ‘java.lang.Math.cosh’。 |
| cot(expr) | 返回 ‘expr’ 的余切值,同 ‘1/java.lang.Math.tan’。 |
| csc(expr) | 返回 ‘expr’ 的余割,同 ‘1/java.lang.Math.sin’。 |
| degrees(expr) | 将弧度转换为度数。 |
| expr1 div expr2 | 将 “expr1” 除以 “expr2″。如果操作数为 NULL 或 “expr2” 为 0,则返回 NULL。结果被强制转换为多头。 |
| e() | 返回欧拉数 e。 |
| exp(expr) | 将 e 返回给 ‘expr’ 的幂。 |
| expm1(expr) – Returns exp(`expr`) | 1. |
| factorial(expr) | 返回 ‘expr’ 的阶乘。’expr’ 的数据类型为 [0..20]。否则为 null。 |
| floor(expr[, scale]) | 返回四舍五入后不大于 “expr” 的最大数字。可以指定可选的 “scale” 参数来控制舍入行为。 |
| greatest(expr, …) | 返回所有参数的最大值,跳过 null 值。 |
| hex(expr) | 将 “expr” 转换为十六进制。 |
| hypot(expr1, expr2) | 返回 sqrt(’expr1’**2 + ‘expr2’**2)。 |
| least(expr, …) | 返回所有参数的最小值,跳过 null 值。 |
| ln(expr) | 返回 ‘expr’ 的自然对数(以 e 为底)。 |
| log(base, expr) | 返回带有 ‘base’ 的 ‘expr’ 的对数。 |
| log10(expr) | 返回以 10 为底的 “expr” 的对数。 |
| log1p(expr) | 返回 log(1 + ‘expr’)。 |
| log2(expr) | 返回以 2 为底的 ‘expr’ 的对数。 |
| expr1 mod expr2 | 返回 ‘expr1’ / ‘expr2’ 之后的余数。 |
| negative(expr) | 返回 “expr” 的否定值。 |
| pi() | 返回 pi。 |
| pmod(expr1, expr2) | 返回 ‘expr1’ mod ‘expr2’ 的正值。 |
| positive(expr) | 返回 ‘expr’ 的值。 |
| pow(expr1, expr2) | 将 “expr1” 提升到 “expr2” 的幂。 |
| power(expr1, expr2) | 将 “expr1” 提升到 “expr2” 的幂。 |
| radians(expr) | 将度数转换为弧度。 |
| rand([seed]) | 返回一个随机值,该值在 [0,1] 中具有独立且相同分布的(i.i.d.)均匀分布值。 | 返回一个随机值,该值具有从标准正态分布中抽取的独立且相同分布的(i.i.d.)值。 |
| random([seed]) | 返回一个随机值,该值在[0,1]中具有独立且相同分布的(i.i.d.)均匀分布值。 |
| rint(expr) | 返回值最接近参数且等于数学整数的双精度值。 |
| round(expr, d) | 使用舍入模式返回舍入到小数点后位 HALF_UP “expr”。 |
| sec(expr) | 返回 ‘expr’ 的正割点,同 ‘1/java.lang.Math.cos’。 |
| shiftleft(base, expr) | 按位左移。 |
| sign(expr) | 返回 -1.0、0.0 或 1.0,因为 “expr” 为负数、0 或正数。 |
| signum(expr) | 返回 -1.0、0.0 或 1.0,因为 “expr” 为负数、0 或正数。 |
| sin(expr) | 返回 ‘expr’ 的正弦值,同 ‘java.lang.Math.sin’。 |
| sinh(expr) | 返回 ‘expr’ 的双曲正弦,同 ‘java.lang.Math.sinh’。 |
| sqrt(expr) | 返回 ‘expr’ 的平方根。 |
| tan(expr) | 返回 ‘expr’ 的切线,就像由 ‘java.lang.Math.tan’ 计算一样。 |
| tanh(expr) | 返回 ‘expr’ 的双曲正切,同 ‘java.lang.Math.tanh’。 |
| try_add(expr1, expr2) | 返回 ‘expr1’ 和 ‘expr2’ 的总和,结果在溢出时为 null。可接受的输入类型与 “+” 运算符相同。 |
| try_divide(dividend, divisor) | 返回 ‘dividend’/’divisor’。它始终执行浮点除法。如果 ‘expr2’ 为 0,则其结果始终为 null。”dividend” 必须是数字或区间。”除数” 必须是数字。 |
| try_multiply(expr1, expr2) | 返回 ‘expr1’*’expr2’,结果在溢出时为 null。可接受的输入类型与 “*” 运算符相同。 |
| try_subtract(expr1, expr2) | 返回 ‘expr1’-‘expr2’,结果在溢出时为 null。可接受的输入类型与 “-” 运算符相同。 |
| unhex(expr) | 将十六进制 “expr” 转换为二进制。 |
| width_bucket(value, min_value, max_value, num_bucket) | 返回存储桶编号 ‘value’ 将在具有 ‘num_bucket’ 桶的等角直方图中分配,在 ‘min_value’ 到 ‘max_value’ 的范围内。 |
字符串函数
| 函数 | 描述 |
| ascii(str) | 返回第一个字符 “str” 的数值。 |
| base64(bin) | 将参数从二进制 “bin” 转换为以 64 为基数的字符串。 |
| bit_length(expr) | 返回字符串数据的位长度或二进制数据的位数。 |
| btrim(str) | 从 “str” 中删除前导和尾随空格字符。 |
| btrim(str, trimStr) | 从 “str” 中删除前导和尾随的 “trimStr” 字符。 |
| char(expr) | 返回二进制与 “expr” 等效的 ASCII 字符。如果 n 大于 256,则结果等价于 chr(n%256) |
| char_length(expr) | 返回字符串数据的字符长度或二进制数据的字节数。字符串数据的长度包括尾随空格。二进制数据的长度包括二进制零。 |
| character_length(expr) | 返回字符串数据的字符长度或二进制数据的字节数。字符串数据的长度包括尾随空格。二进制数据的长度包括二进制零。 |
| chr(expr) | 返回二进制与 “expr” 等效的 ASCII 字符。如果 n 大于 256,则结果等价于 chr(n%256) |
| concat_ws(sep[, str|array(str)]+) | 返回以 “sep” 分隔的字符串的串联,跳过 null 值。 |
| contains(left, right) | 返回一个布尔值。如果在 left 中找到 right,则值为 True。如果任一输入表达式为 NULL,则返回 NULL。否则,返回 False。left 或 right 都必须是 STRING 或 BINARY 类型。 |
| decode(bin, charset) | 使用第二个参数字符集对第一个参数进行解码。 |
| decode(expr, search, result[, search, result]…[, default]) | 比较 expr 按顺序添加到每个搜索值。如果 expr 等于搜索值,则 decode 返回相应的结果。如果未找到匹配项,则返回 default。如果默认省略,则返回 null。 |
| elt(n, input1, input2, …) | 返回第 n’ 个输入,例如,当 ‘n’ 为 2 时返回 ‘input2’。如果索引超过数组的长度,则该函数返回 NULL 并且 “spark.sql.ansi.enabled” 设置为 false。如果 ‘spark.sql.ansi.enabled’ 设置为 true,它为无效的索引抛出 ArrayIndexOutOfBoundsException。 |
| encode(str, charset) | 使用第二个参数字符集对第一个参数进行编码。 |
| endswith(left, right) | 返回一个布尔值。如果 left 以 right 结尾,则值为 True。如果任一输入表达式为 NULL,则返回 NULL。否则,返回 False。left 或 right 都必须是 STRING 或 BINARY 类型。 |
| find_in_set(str, str_array) | 返回逗号分隔列表(’str_array’)中给定字符串(’str’)的索引(从 1 开始)。如果找不到字符串或给定字符串(’str’)包含逗号,则返回 0。 |
| format_number(expr1, expr2) | 格式化数字 “expr1″,如 “#,###,###.##”,四舍五入为 “expr2” 小数点后位数。如果 “expr2″ 为 0,则结果没有小数点或小数部分。”expr2” 也接受用户指定的格式。这应该像 MySQL 的 FORMAT 一样运行。 |
| format_string(strfmt, obj, …) | 从 printf 样式的格式字符串返回格式化的字符串。 |
| initcap(str) | 返回 “str”,每个单词的第一个字母为大写。所有其他字母均为小写字母。单词由空格分隔。 | 返回 ‘str’ 中第一次出现的 ‘substr’ 的(从1开始的)索引。 |
| lcase(str) | 返回 “str”,并将所有字符更改为小写。 |
| left(str, len) | 从字符串 ‘str’ 返回最左边的 ‘len’(’len’ 可以是字符串类型)字符,如果 ‘len’ 小于或等于0,则结果为空字符串。 |
| len(expr) | 返回字符串数据的字符长度或二进制数据的字节数。字符串数据的长度包括尾随空格。二进制数据的长度包括二进制零。 |
| length(expr) | 返回字符串数据的字符长度或二进制数据的字节数。字符串数据的长度包括尾随空格。二进制数据的长度包括二进制零。 |
| levenshtein(str1, str2[, threshold]) | 返回两个给定字符串之间的 Levenshtein 距离。如果设置了阈值且距离大于阈值,则返回 -1。 |
| locate(substr, str[, pos]) | 返回位置 ‘pos’ 之后 ‘str’ 中第一个出现的 ‘substr’ 的位置。给定的 “pos” 和返回值是从1开始的。 |
| lower(str) | 返回 “str”,并将所有字符更改为小写。 |
| lpad(str, len[, pad]) | 返回 ‘str’,用 ‘pad’ 左填充到 ‘len’ 的长度。如果 ‘str’ 比 ‘len’ 长,则返回值将缩短为 ‘len’ 字符或字节。如果未指定 “pad”,则 “str” 将在左侧填充空格字符(如果是字符串,如果是字节序列,则为零。 |
| ltrim(str) | 从 “str” 中删除前导空格字符。 |
| luhn_check(str) | 根据 Luhn 算法检查数字字符串是否有效。这种校验和功能广泛应用于信用卡号和政府身份证明数字,用于区分有效数字和输入错误、不正确的数字。 |
| mask(input[, upperChar, lowerChar, digitChar, otherChar]) | 屏蔽给定的字符串值。该函数将字符替换为 “X” 或 “x”,将数字替换为 “n”。这对于创建删除了敏感信息的表副本非常有用。 |
| octet_length(expr) | 返回字符串数据的字节长度或二进制数据的字节数。 |
| overlay(input, replace, pos[, len]) | 将 “input” 替换为 “replace”,该 “替换” 从 “pos” 开始,长度为 “len”。 |
| position(substr, str[, pos]) | 返回位置 ‘pos’ 之后 ‘str’ 中第一个出现的 ‘substr’ 的位置。给定的 “pos” 和返回值是从1开始的。 |
| printf(strfmt, obj, …) | 从 printf 样式的格式字符串返回格式化的字符串。 |
| regexp_count(str, regexp) | 返回正则表达式模式 “regexp” 在字符串 “str” 中匹配的次数的计数。 |
| regexp_extract(str, regexp[, idx]) | 提取 “str” 中与 “regexp” 匹配的第一个字符串表达式,并对应于正则表达式组索引。 |
| regexp_extract_all(str, regexp[, idx]) | 提取 “str” 中与 “regexp” 匹配的所有字符串表达式,并对应于正则表达式组索引。 |
| regexp_instr(str, regexp) | 在字符串中搜索正则表达式,并返回一个整数,该整数指示匹配子字符串的起始位置。仓位以1为基础,而不是以0为基础。如果未找到匹配项,则返回0。 |
| regexp_replace(str, regexp, rep[, position]) | 将匹配 ‘regexp’ 的 ‘str’ 的所有子字符串替换为 ‘rep’。 |
| regexp_substr(str, regexp) | 返回与字符串 “str” 中的正则表达式 “regexp” 匹配的子字符串。如果未找到正则表达式,则结果为 null。 |
| repeat(str, n) | 返回重复给定字符串值 n 次的字符串。 |
| replace(str, search[, replace]) | 将所有出现的 “search” 替换为 “replace”。 |
| right(str, len) | 从字符串 ‘str’ 返回最右边的 ‘len’(’len’ 可以是字符串类型)字符,如果 ‘len’ 小于或等于0,则结果为空字符串。 |
| rpad(str, len[, pad]) | 返回 ‘str’,用 ‘pad’ 右填充到 ‘len’ 的长度。如果 ‘str’ 比 ‘len’ 长,则返回值将缩短为 ‘len’ 字符。如果未指定 “pad”,则 “str” 将在右侧填充空格字符(如果是字符串,如果是二进制字符串,则为零。 |
| rtrim(str) | 从 “str” 中删除尾随空格字符。 |
| sentences(str[, lang, country]) | 将 “str” 拆分为单词数组。 |
| soundex(str) | 返回字符串的 Soundex 代码。 |
| space(n) | 返回由 “n” 个空格组成的字符串。 |
| split(str, regex, limit) | 在与 “regex” 匹配的匹配项周围拆分 “str”,并返回长度最多为 ‘limit’ 的数组 |
| split_part(str, delimiter, partNum) | 按分隔符拆分 “str” 并返回请求部分拆分(从1开始)。如果任何输入为 null,则返回 null。如果 “partNum” 超出拆分部分的范围,则返回空字符串。如果 ‘partNum’ 为0,抛出错误。如果 ‘partNum’ 为负数,则从字符串的末尾。如果 “分隔符” 是空字符串,则不会拆分 “str”。 |
| startswith(left, right) | 返回一个布尔值。如果 left 以 right 开头,则值为 True。如果任一输入表达式为 NULL,则返回 NULL。否则,返回 False。left 或 right 都必须是 STRING 或 BINARY 类型。 |
| substr(str, pos[, len]) | 返回从 “pos” 开始且长度为 “len” 的 “str” 的子字符串,或从 “pos” 开始且长度为 “len” 的字节数组切片。 |
| substr(str FROM pos[ FOR len]]) | 返回从 “pos” 开始且长度为 “len” 的 “str” 的子字符串,或从 “pos” 开始且长度为 “len” 的字节数组切片。 |
| substring(str, pos[, len]) | 返回从 “pos” 开始且长度为 “len” 的 “str” 的子字符串,或从 “pos” 开始且长度为 “len” 的字节数组切片。 |
| substring(str FROM pos[ FOR len]]) | 返回从 “pos” 开始且长度为 “len” 的 “str” 的子字符串,或从 “pos” 开始且长度为 “len” 的字节数组切片。 |
| substring_index(str, delim, count) | |
| to_binary(str[, fmt]) | 根据提供的“fmt”将输入“str”转换为二进制值。“fmt”可以是“hex”、“utf-8”、“utf8”或“base64”的不区分大小写的字符串文本。默认情况下,如果省略“fmt”,则转换的二进制格式为“十六进制”。如果至少有一个输入参数为 NULL,则该函数返回 NULL。 |
| to_char(numberExpr, formatExpr) | 根据“formatExpr”将“numberExpr”转换为字符串。如果转换失败,则引发异常。格式可以包含以下内容字符,不区分大小写:“0”或“9”:指定介于 0 和 9 之间的预期数字。格式为 0 或 9 的序列 string 匹配输入值中的数字序列,生成与格式字符串中的相应序列长度相同。结果字符串为如果 0/9 序列包含的数字多于的匹配部分,则用零向左填充十进制值,从 0 开始,位于小数点之前。否则,它是用空格填充。’.’或’D’:指定小数点的位置(可选,只允许一次)。’,’或’G’:指定分组(千)分隔符(,)的位置。必须有每个分组分隔符的左侧和右侧为 0 或 9。“$”:指定 $ 货币符号的位置。只能指定此字符一次。“S”或“MI”:指定“-”或“+”符号的位置(可选,仅允许在格式字符串的开头或结尾)。请注意,“S”打印“+”表示正值但“MI”打印一个空格。“PR”:只允许在格式字符串的末尾;指定结果字符串将为如果输入值为负数,则用尖括号括起来。('<1>’)。 |
| to_number(expr, fmt) | 根据字符串格式“fmt”将字符串“expr”转换为数字。如果转换失败,则引发异常。格式可以包含以下内容字符,不区分大小写:“0”或“9”:指定介于 0 和 9 之间的预期数字。格式为 0 或 9 的序列 string 匹配输入字符串中的数字序列。如果 0/9 序列以 0 并且在小数点之前,它只能匹配相同大小的数字序列。否则,如果序列以 9 开头或位于小数点之后,则可以匹配具有相同或更小大小的数字序列。’.’或’D’:指定小数点的位置(可选,只允许一次)。’,’或’G’:指定分组(千)分隔符(,)的位置。必须有每个分组分隔符的左侧和右侧为 0 或 9。“expr”必须与与数字大小相关的分组分隔符。“$”:指定 $ 货币符号的位置。只能指定此字符一次。“S”或“MI”:指定“-”或“+”符号的位置(可选,仅允许在格式字符串的开头或结尾)。请注意,“S”允许“-”,但“MI”不允许。“PR”:只允许在格式字符串的末尾;指定“expr”表示负数,带圆括号。('<1>’)。 |
| to_varchar(numberExpr, formatExpr) | 根据“formatExpr”将“numberExpr”转换为字符串。如果转换失败,则引发异常。格式可以包含以下内容字符,不区分大小写:“0”或“9”:指定介于 0 和 9 之间的预期数字。格式为 0 或 9 的序列 string 匹配输入值中的数字序列,生成与格式字符串中的相应序列长度相同。结果字符串为如果 0/9 序列包含的数字多于的匹配部分,则用零向左填充十进制值,从 0 开始,位于小数点之前。否则,它是用空格填充。’.’或’D’:指定小数点的位置(可选,只允许一次)。’,’或’G’:指定分组(千)分隔符(,)的位置。必须有每个分组分隔符的左侧和右侧为 0 或 9。“$”:指定 $ 货币符号的位置。只能指定此字符一次。“S”或“MI”:指定“-”或“+”符号的位置(可选,仅允许在格式字符串的开头或结尾)。请注意,“S”打印“+”表示正值但“MI”打印一个空格。“PR”:只允许在格式字符串的末尾;指定结果字符串将为如果输入值为负数,则用尖括号括起来。('<1>’)。 |
| translate(input, from, to) | 通过将“from”字符串中的字符替换为“to”字符串中的相应字符来转换“input”字符串。 |
| trim(str) | 从“str”中删除前导和尾随空格字符。 |
| trim(BOTH FROM str) | 从“str”中删除前导和尾随空格字符。 |
| trim(LEADING FROM str) | 从“str”中删除前导空格字符。 |
| trim(TRAILING FROM str) | 从“str”中删除尾随空格字符。 |
| trim(trimStr FROM str) | 从“str”中删除前导和尾随的“trimStr”字符。 |
| trim(BOTH trimStr FROM str) | 从“str”中删除前导和尾随的“trimStr”字符。 |
| trim(LEADING trimStr FROM str) | 从“str”中删除前导的“trimStr”字符。 |
| trim(TRAILING trimStr FROM str) | 从“str”中删除尾随的“trimStr”字符。 |
| try_to_binary(str[, fmt]) | 这是“to_binary”的特殊版本,它执行相同的操作,但如果无法执行转换,则返回 NULL 值而不是引发错误。 |
| try_to_number(expr, fmt) | 根据字符串格式“fmt”将字符串“expr”转换为数字。如果字符串“expr”与预期格式不匹配,则返回 NULL。格式遵循与 to_number 函数的语义相同。 |
| ucase(str) | 返回“str”,并将所有字符更改为大写。 |
| unbase64(str) | 将参数从以 64 为基数的字符串“str”转换为二进制。 |
| upper(str) | 返回“str”,并将所有字符更改为大写。 |
位运算函数
| 函数 | 描述 |
| expr1 & expr2 | 返回“expr1”和“expr2”的按位 AND 的结果。 |
| expr1 ^ expr2 | 返回“expr1”和“expr2”的按位互斥 OR 的结果。 |
| bit_count(expr) | 返回参数 expr 中设置为无符号 64 位整数的位数,如果参数为 NULL,则返回 NULL。 |
| bit_get(expr, pos) | 返回指定位置的位值(0 或 1)。位置从右到左编号,从零开始。position 参数不能为负数。 |
| getbit(expr, pos) | 返回指定位置的位值(0 或 1)。位置从右到左编号,从零开始。position 参数不能为负数。 |
| shiftright(base, expr) | 按位(有符号)右移。 |
| shiftrightunsigned(base, expr) | 按位无符号右移。 |
| expr1 | expr2 | 返回“expr1”和“expr2”的按位 OR 结果。 |
| ~expr | 返回按位的结果,而不是“expr”的结果。 |
转换函数
| 函数 | 描述 |
| bigint(expr) | 将值“expr”强制转换为目标数据类型“bigint”。 |
| binary(expr) | 将值“expr”强制转换为目标数据类型“binary”。 |
| boolean(expr) | 将值“expr”强制转换为目标数据类型“boolean”。 |
| cast(expr AS type) | 将值“expr”强制转换为目标数据类型“type”。 |
| date(expr) | 将值“expr”强制转换为目标数据类型“date”。 |
| decimal(expr) | 将值“expr”强制转换为目标数据类型“decimal”。 |
| double(expr) | 将值“expr”强制转换为目标数据类型“double”。 |
| float(expr) | 将值“expr”强制转换为目标数据类型“float”。 |
| int(expr) | 将值“expr”强制转换为目标数据类型“int”。 |
| smallint(expr) | 将值“expr”强制转换为目标数据类型“smallint”。 |
| string(expr) | 将值“expr”强制转换为目标数据类型“string”。 |
| timestamp(expr) | 将值“expr”强制转换为目标数据类型“timestamp”。 |
| tinyint(expr) | 将值“expr”强制转换为目标数据类型“tinyint”。 |
条件函数
| 函数 | 描述 |
| coalesce(expr1, expr2, …) | 如果存在,则返回第一个非null参数。否则为null。 |
| if(expr1, expr2, expr3) | 如果’expr1’的计算结果为true,则返回’expr2′;否则返回“expr3”。 |
| ifnull(expr1, expr2) | 如果“expr1”为null,则返回“expr2”,否则返回“expr1”。 |
| nanvl(expr1, expr2) | 如果不是NaN,则返回“expr1”,否则返回“expr2”。 |
| nullif(expr1, expr2) | 如果“expr1”等于“expr2”,则返回null,否则返回“expr1”。 |
| nvl(expr1, expr2) | 如果“expr1”为null,则返回“expr2”,否则返回“expr1”。 |
| nvl2(expr1, expr2, expr3) | 如果“expr1”不为null,则返回“expr2”,否则返回“expr3”。 |
| CASE WHEN expr1 THEN expr2 [WHEN expr3 THEN expr4]* [ELSE expr5] END | 当’expr1’=true时,返回’expr2′;否则,当’expr3’=true时,返回’expr4′;else返回’expr5’。 |
条件函数
| 函数 | 描述 |
| !expr | 逻辑not |
| expr1 < expr2 | 如果“expr1”小于“expr2”,则返回true。 |
| expr1 <= expr2 | 如果“expr1”小于或等于“expr2”,则返回true。 |
| expr1 <=> expr2 | 返回与非null操作数的EQUAL(=)运算符相同的结果,但是,如果两者都为null,则返回true,如果其中一个为null,则返回false。 |
| expr1 = expr2 | 如果’expr1’等于’expr2’,则返回true,否则返回false。 |
| expr1 == expr2 | 如果’expr1’等于’expr2’,则返回true,否则返回false。 |
| expr1 > expr2 | 如果’expr1’大于’expr2’,则返回true。 |
| expr1 >= expr2 | 如果“expr1”大于或等于“expr2”,则返回true。 |
| expr1 and expr2 | 逻辑AND。 |
| str ilike pattern [ESCAPE escape] | 如果str与’pattern’与’escape’不区分大小写匹配,则返回true,如果任何参数为null,则返回null,否则返回false。 |
| expr1 in (expr2, expr3, …) | 如果’expr’等于任何valN,则返回true。 |
| isnan(expr) | 如果’expr’为NaN,则返回true,否则返回false。 |
| isnotnull(expr) | 如果“expr”不为null,则返回true,否则返回false。 |
| isnull(expr) | 如果’expr’为null,则返回true,否则返回false。 |
| str like pattern [ESCAPE escape] | 如果str与’pattern’与’escape’匹配,则返回true,如果任何参数为null,则返回null,否则返回false。 |
| not expr | 逻辑not. |
| expr1 or expr2 | 逻辑OR. |
| regexp(str, regexp) | 如果’str’与’regexp’匹配,则返回true,否则返回false。 |
| regexp_like(str, regexp) | 如果’str’与’regexp’匹配,则返回true,否则返回false。 |
| rlike(str, regexp) | 如果’str’与’regexp’匹配,则返回true,否则返回false。 |
Csv函数
| 函数 | 描述 |
| from_csv(csvStr, schema[, options]) | 返回具有给定“csvStr”和“schema”的结构值。 |
| schema_of_csv(csv[, options]) | 以CSV字符串的DDL格式返回架构。 |
| to_csv(expr[, options]) | 返回具有给定结构值的CSV字符串 |
其他函数
| Function | Description |
| aes_decrypt(expr, key[, mode[, padding[, aad]]]) | 返回解密值“expr”,在“mode”和“padding”中使用AES。支持16、24和32位的密钥长度。(’mode’,’padding’)支持的组合包括(’ECB’,’PKCS’)、(’GCM’,’NONE’)和(’CBC’,’PKCS’)。可选的其他经过身份验证的数据(AAD)仅支持GCM。如果为加密提供,则必须提供相同的AAD值进行解密。默认模式为GCM。 |
| aes_encrypt(expr, key[, mode[, padding[, iv[, aad]]]]) | 在给定的“模式”下使用具有指定“填充”的AES返回加密值“expr”。支持16、24和32位的密钥长度。(’mode’,’padding’)支持的组合包括(’ECB’,’PKCS’)、(’GCM’,’NONE’)和(’CBC’,’PKCS’)。可选初始化向量(IV)仅支持CBC和GCM模式。CBC的这些字节必须为16个字节,GCM的这些字节必须为12个字节。如果未提供,将生成一个随机向量并将其附加到输出之前。可选的其他经过身份验证的数据(AAD)仅支持GCM。如果为加密提供,则必须提供相同的AAD值进行解密。默认模式为GCM。 |
| assert_true(expr) | 如果“expr”不为true,则引发异常。 |
| bitmap_bit_position(child) | 返回给定输入子表达式的位位置。 |
| bitmap_bucket_number(child) | 返回给定输入子表达式的存储桶编号。 |
| bitmap_count(child) | 返回子位图中设置的位数。 |
| current_catalog() | 返回当前目录。 |
| current_database() | 返回当前数据库。 |
| current_schema() | 返回当前数据库。 |
| current_user() | 当前执行上下文的用户名。 |
| equal_null(expr1, expr2) | 返回与非null操作数的EQUAL(=)运算符相同的结果,但是,如果两者都为null,则返回true,如果其中一个为null,则返回false。 |
| hll_sketch_estimate(expr) | 返回给定二进制表示形式的唯一值的估计数的Datasketches HllSketch。 |
| hll_union(first, second, allowDifferentLgConfigK) | 合并Datasketches HllSketch对象,使用Datasketches Union对象。设置allowDifferentLgConfigK设置为true,以允许草图与不同的草图并集lgConfigK值(默认为false)。 |
| input_file_block_length() | 返回正在读取的块的长度,如果不可用,则返回-1。 |
| input_file_block_start() | 返回正在读取的块的起始偏移量,如果不可用,则返回-1。 |
| input_file_name() | 返回正在读取的文件的名称,如果不可用,则返回空字符串。 |
| java_method(class, method[, arg1[, arg2..]]) | 调用具有反射的方法。 |
| monotonically_increasing_id() | 返回单调递增的64位整数。生成的ID是有保证的单调增加和唯一,但不是连续的。当前实现将分区ID放在上面的31位,下面的33位表示记录编号在每个分区中。假设数据帧少于10亿分区,每个分区的记录少于80亿条。该函数是非确定性的,因为它的结果取决于分区ID。 |
| reflect(class, method[, arg1[, arg2..]]) | 调用具有反射的方法。 |
| spark_partition_id() | 返回当前分区ID。 |
| try_aes_decrypt(expr, key[, mode[, padding[, aad]]]) | 这是“aes_decrypt”的特殊版本,它执行相同的操作,但如果无法执行解密,则返回NULL值而不是引发错误。 |
| typeof(expr) | 返回输入数据类型的DDL格式类型字符串。 |
| user() | 当前执行上下文的用户名。 |
| uuid() | 返回通用唯一标识符(UUID)字符串。该值以36个字符的规范UUID字符串形式返回。 |
| version() | 返回Spark版本。该字符串包含2个字段,第一个是发布版本,第二个是git修订版。 |
聚合函数
聚合函数
| 函数 | 描述 |
| any(expr) | 如果至少有一个值“expr”为true,则返回true。 |
| any_value(expr[, isIgnoreNull]) | 返回一组行的某个值“expr”。如果“isIgnoreNull”为true,则仅返回非null值。 |
| approx_count_distinct(expr[, relativeSD]) | 返回HyperLogLog++的估计基数。“relativeSD”定义允许的最大相对标准偏差。 |
| approx_percentile(col, percentage[, accuracy]) | 返回数值的近似“百分位数”或ANSI间隔列“col”,它是有序“col”值中的最小值(已排序从最小到最大),使得不超过“col”值的“百分比”小于该值或等于该值。百分比值必须介于0.0和1.0之间。“accuracy”参数(默认值:10000)是一个正数文本,用于控制以内存为代价的近似精度。“准确性”值越高,效果越好精度,“1.0/精度”是近似值的相对误差。当“percentage”为数组时,百分比数组的每个值必须介于0.0和1.0之间。在本例中,返回给定列“col”的近似百分位数组percentage数组。 |
| array_agg(expr) | 收集并返回非唯一元素的列表。 |
| avg(expr) | 返回根据组的值计算的平均值。 |
| bit_and(expr) | 返回所有非null输入值的按位AND,如果没有,则返回null。 |
| bit_or(expr) | 返回所有非null输入值的按位OR,如果没有,则返回null。 |
| bit_xor(expr) | 返回所有非null输入值的按位XOR,如果没有,则返回null。 |
| bitmap_construct_agg(child) | 返回组中非空对的确定系数,其中“y”是因变量,“x”是自变量。 |
| regr_slope(y,x) | 返回组中非空对的单变量线性回归线的斜率,其中“y”是因变量,“x”是自变量。 |
| regr_sxx(y,x) | 返回组中非空对的平方和,其中“y”是因变量,“x”是自变量。 |
| regr_sxy(y,x) | 返回组中非空对的乘积和,其中“y”是因变量,“x”是自变量。 |
| regr_syy(y,x) | 返回组中非空对的因变量平方和,其中“y”是因变量,“x”是自变量。 |
| skewness(expr) | 返回根据组的值计算出的偏度值。 |
| stddev(expr) | 返回“expr”的样本标准差。 |
| stddev_pop(expr) | 返回“expr”的总体标准差。 |
| stddev_samp(expr) | 返回“expr”的样本标准差。 |
| sum(expr) | 返回“expr”的总和。 |
| sum_distinct(expr) | 返回“expr”的唯一值总和。 |
| var_pop(expr) | 返回“expr”的总体方差。 |
| var_samp(expr) | 返回“expr”的样本方差。 |
| variance(expr) | 返回“expr”的样本方差。 |
| regr_slope(y, x) | 返回组中非空对的线性回归线的斜率,其中“y”是因变量,“x”是自变量。 |
| regr_sxx(y, x) | 对于组中的非空对,返回 REGR_COUNT(y, x) * VAR_POP(x),其中’y’是因变量,“x”是自变量。 |
| regr_sxy(y, x) | 对于组中的非空对返回 REGR_COUNT(y, x) * COVAR_POP(y, x),其中“y”是因变量,“x”是自变量。 |
| regr_syy(y, x) | 对于组中的非空对,返回 REGR_COUNT(y, x) * VAR_POP(y),其中’y’是因变量,“x”是自变量。 |
| skewness(expr) | 返回根据组的值计算出的偏度值。 |
| some(expr) | 如果至少有一个值“expr”为 true,则返回 true。 |
| std(expr) | 返回根据组的值计算出的样本标准差。 |
| stddev(expr) | 返回根据组的值计算出的样本标准差。 |
| stddev_pop(expr) | 返回根据组的值计算出的总体标准差。 |
| stddev_samp(expr) | 返回根据组的值计算出的样本标准差。 |
| sum(expr) | 返回根据组的值计算的总和。 |
| try_avg(expr) | 返回根据组的值计算出的平均值,结果在溢出时为 null。 |
| try_sum(expr) | 返回根据组的值计算的总和,结果在溢出时为 null。 |
| var_pop(expr) | 返回根据组的值计算出的总体方差。 |
| var_samp(expr) | 返回根据组的值计算出的样本方差。 |
| variance(expr) | 返回根据组的值计算出的样本方差。 |
窗口函数
| 函数 | 描述 |
| cume_dist() | 计算值相对于分区中所有值的位置。 |
| dense_rank() | 计算值在一组值中的排名。结果是 1 加以前分配的排名值。与函数等级不同,dense_rank 不会产生差距在排名序列中。 |
| lag(input[, offset[, default]]) | 返回“offset”第行的’input’值在窗口中的当前行之前。“offset”的默认值为 1,默认值为“default”的值为 null。如果“offset”第行的’input’值为 null,返回 null。如果没有这样的偏移量行(例如,当偏移量为 1 时,第一个窗口的行没有任何前一行),返回“default”。 |
| lead(input[, offset[, default]]) | 返回“offset”第行的’input’值在窗口中的当前行之后。“offset”的默认值为 1,默认值为“default”的值为 null。如果“offset”第行的’input’值为 null,返回 null。如果没有这样的偏移量行(例如,当偏移量为 1 时,最后一个窗口的行没有任何后续行),返回“default”。 |
| nth_value(input[, offset]) | 返回作为“偏移”第行的行的“input”值从窗框的开始。偏移量从 1 开始。如果 ignoreNulls=true,我们将跳过查找“偏移量”第行时为 null。否则,每一行都计入“偏移量”。如果没有这样的“偏移量”行(例如,当偏移量为 10 时,窗框的大小小于 10),则返回 null。 |
| ntile(n) | 将每个窗口分区的行划分为“n”个存储桶,范围从 1 到最多’n’。 |
| percent_rank() | 计算值在一组值中的百分比排名。 |
| rank() | 计算值在一组值中的排名。结果是 1 加 1 加在分区顺序中,行数在当前行之前或等于当前行。价值观将在序列中产生间隙。 |
| row_number() | 为每一行分配一个唯一的序列号,从 1 开始,根据窗口分区内行的顺序。 |
生成器函数
| 函数 | 描述 |
| explode(expr) | 将数组“expr”的元素分隔为多行,或将映射“expr”的元素分隔为多行和多列。除非另有说明,否则对数组的元素使用默认列名“col”,对映射的元素使用默认列名“key”和“value”。 |
| explode_outer(expr) | 将数组“expr”的元素分隔为多行,或将映射“expr”的元素分隔为多行和多列。除非另有说明,否则对数组的元素使用默认列名“col”,对映射的元素使用默认列名“key”和“value”。 |
| inline(expr) | 将结构体数组分解到表中。除非另有说明,否则默认使用列名 col1、col2 等。 |
| inline_outer(expr) | 将结构体数组分解到表中。除非另有说明,否则默认使用列名 col1、col2 等。 |
| posexplode(expr) | 将数组“expr”的元素分隔为多行和位置,或将映射“expr”的元素分隔为多行和多列和多行和多列。除非另有说明,否则使用列名’pos’表示位置,使用列名’col’表示数组的元素,或使用’key’和’value’表示映射的元素。 |
| posexplode_outer(expr) | 将数组“expr”的元素分隔为多行和位置,或将映射“expr”的元素分隔为多行和多列和多行和多列。除非另有说明,否则使用列名’pos’表示位置,使用列名’col’表示数组的元素,或使用’key’和’value’表示映射的元素。 |
| stack(n, expr1, …, exprk) | 将’expr1’,…,’exprk’分隔成’n’行。除非另有说明,否则默认使用列名 col0、col1 等。 |
SparkSQL 自定义函数
在 SparkSQL 中,用户可以自定义函数来处理数据。这些函数主要有以下几种:
- Scalar User-Defined Functions (UDFs):这种类型的函数接受一组输入值,并返回一个单一的值。例如,如果你想创建一个将文本转换为小写的函数,或者一个将数字平方的函数,这都可以使用 Scalar UDF 实现。
- User-Defined Aggregate Functions (UDAFs):这种类型的函数接受一组值,并返回一个聚合后的值。例如,你可以定义一个 UDAF 来计算某列值的平均值,或者求某列的最大值等。UDAF 的使用场景可以非常复杂,它们可以在 GROUP BY 操作中使用,也可以在 Window 操作中使用。
Integration with Hive UDFs/UDAFs/UDTFs:Spark SQL 支持与 Hive 的 UDFs、UDAFs 和 UDTFs 集成。你可以在 Spark SQL 中直接调用已经在 Hive 中定义的函数。这使得用户可以在 Spark 中利用到 Hive 的强大函数库。
在创建和使用自定义函数时,应该注意的是,虽然自定义函数提供了强大的功能,但是由于 Spark 无法对其进行内部优化,因此其性能可能会低于内置函数。因此,在可能的情况下,应优先考虑使用 Spark SQL 的内置函数。
更多内容:Hive UDF 的开发简介
Spark SQL 语法
数据定义语句
DDL Statements(数据定义语句):这类语句用于定义或修改数据库中的对象结构。比如创建、删除或修改表、视图和索引等。常见的 DDL 语句包括 CREATE TABLE、DROP TABLE、ALTER TABLE 等。
- ALTER DATABASE:这个命令用于修改数据库的属性。例如,你可以使用 ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value,…); 来设置数据库的属性。
- ALTER TABLE:这个命令用于改变现有表的结构,例如添加、删除或重命名列,或者修改列的数据类型。例如,ALTER TABLE table_name ADD COLUMNS (col_name data_type,…);。
- ALTER VIEW:这个命令用于改变现有视图的定义。例如,ALTER VIEW view_name AS SELECT…;。
- CREATE DATABASE:这个命令用于创建新的数据库。例如,CREATE DATABASE database_name;。
- CREATE FUNCTION:这个命令用于创建新的用户定义函数。例如,CREATE FUNCTION function_name AS class_name USING JAR|FILE|ARCHIVE ‘file_uri’;。
- CREATE TABLE:这个命令用于创建新的表。例如,CREATE TABLE table_name (col_name data_type,…);。
- CREATE VIEW:这个命令用于创建新的视图。例如,CREATE VIEW view_name AS SELECT…;。
- DROP DATABASE:这个命令用于删除数据库。例如,DROP DATABASE IF EXISTS database_name CASCADE;。
- DROP FUNCTION:这个命令用于删除用户定义函数。例如,DROP FUNCTION IF EXISTS function_name;。
- DROP TABLE:这个命令用于删除表。例如,DROP TABLE IF EXISTS table_name;。
- DROP VIEW:这个命令用于删除视图。例如,DROP VIEW IF EXISTS view_name;。
- REPAIR TABLE:这个命令用于修复表的元数据。例如,MSCK REPAIR TABLE table_name;。
- TRUNCATE TABLE:这个命令用于删除表中的所有数据,但不删除表本身。例如,TRUNCATE TABLE table_name;。
- USE DATABASE:这个命令用于设置当前的数据库。例如,USE database_name;。
数据操作语句
在 Spark SQL 中,DML(数据操纵语言)语句主要用于插入数据。下面是你提到的这些语句的详细介绍:
- INSERT TABLE:这个命令用于向现有表中插入数据。你可以使用 INSERT INTO 或 INSERT OVERWRITE 选项来确定插入数据时是要追加数据还是覆盖现有数据。
- INSERT INTO:追加方式。例如,INSERT INTO table_name SELECT…; 或 INSERT INTO table_name VALUES (…),(…),…;
- INSERT OVERWRITE:覆盖方式。例如,INSERT OVERWRITE TABLE table_name SELECT…; 或 INSERT OVERWRITE TABLE table_name VALUES (…),(…),…;
- INSERT OVERWRITE DIRECTORY:这个命令用于将查询结果写入到 HDFS 目录中,并覆盖其中的现有数据。例如,INSERT OVERWRITE DIRECTORY ‘hdfs_directory’ SELECT…;。你可以选择文件的格式(例如 AS TEXTFILE 或 AS PARQUET),并可以选择是否压缩数据。
- LOAD DATA:这个命令用于将数据从本地文件系统或 HDFS 加载到表中。你可以选择 LOAD DATA LOCAL INPATH 来从本地文件系统加载数据,也可以选择 LOAD DATA INPATH 来从 HDFS 加载数据。例如,LOAD DATA (LOCAL) INPATH ‘file_path’ [OVERWRITE] INTO TABLE table_name;。此命令默认情况下将追加数据,除非你指定了 OVERWRITE 关键字。
数据检索语句
在 Spark SQL 中,SELECT 语句用于从一个或多个表中检索数据。SELECT 语句可以配合各种子句使用,如 WHERE、GROUP BY、ORDER BY 等,以进行复杂的数据查询和处理。
以下是 SELECT 语句的基本语法:
SELECT column1, column2, ... FROM table_name WHERE condition GROUP BY column1, column2, ... HAVING condition ORDER BY column1, column2, ... ASC|DESC;
- WHERE:这个子句用于过滤行,只有满足条件的行才会被选中。
- GROUP BY:这个子句用于将选中的行按照一个或多个列进行分组。
- HAVING:这个子句用于过滤分组,只有满足条件的分组才会被选中。注意,HAVING 子句必须配合 GROUP BY 子句使用。
- ORDER BY:这个子句用于对选中的行或分组进行排序。
Spark SQL 还提供了 EXPLAIN 语句,用于生成给定查询的逻辑和物理执行计划。例如,你可以使用以下语句来获取查询的执行计划:
EXPLAIN SELECT column1, column2, ... FROM table_name WHERE condition;
EXPLAIN 语句可以帮助你理解 Spark 是如何执行你的查询的,从而有助于你优化查询性能。
SELECT 语句
以下是你提到的各种 SELECT 语句的功能和使用方法:
- Common Table Expression (CTE):CTE 提供了一种临时的、在单个查询中使用的视图。例如,可以使用 WITH 子句定义一个 CTE,然后在后续的 SELECT 语句中引用它。
- CLUSTER BY Clause:CLUSTER BY 语句先对数据进行分区,然后在每个分区内部进行排序,确保在每个分区内部具有相同的键的数据聚集在一起。
- DISTRIBUTE BY Clause:DISTRIBUTE BY 用于对数据进行分区。它确保所有具有相同值的行被分到同一个分区。
- GROUP BY Clause:GROUP BY 用于根据一个或多个列对结果集进行分组,通常与聚合函数(如 SUM、AVG、COUNT 等)一起使用。
- HAVING Clause:HAVING 用于过滤 GROUP BY 子句生成的结果集。它的行为类似于 WHERE 子句,但作用在分组后的结果集上。
- Hints:提示用于向查询优化器提供关于如何优化查询的额外信息。
- Inline Table:内联表是由 VALUES 子句生成的表。例如,你可以使用 SELECT * FROM VALUES (1,’one’),(2,’two’),(3,’three’) AS t(num,word); 来生成一个内联表。
- File:你可以使用 SELECT * FROM parquet.`file.parquet` 来从 Parquet 文件中读取数据。
- LIKE Predicate:LIKE谓词用于在WHERE子句中进行模式匹配。例如,你可以使用SELECT * FROM table WHERE column LIKE ‘pattern’;来选择匹配给定模式的行。
- LIMIT Clause:LIMIT子句用于限制返回的行数。例如,你可以使用SELECT * FROM table LIMIT 10;来只返回前10行。
- OFFSET Clause:OFFSET子句用于指定返回结果的起始位置,通常与LIMIT子句一起使用。
- ORDER BY Clause:ORDER BY子句用于对结果集进行排序。
- Set Operators:集合运算符(如UNION、INTERSECT、EXCEPT)用于组合多个SELECT语句的结果。
- SORT BY Clause:SORT BY子句用于对结果集进行排序,但与ORDER BY不同的是,SORT BY不保证全局的排序顺序。
- TABLESAMPLE:TABLESAMPLE子句用于从表中随机选择一部分行。
- Table-valued Function:表值函数返回一个表,可以在FROM子句中使用。
- WHERE Clause:WHERE子句用于过滤行,只有满足条件的行才会被选中。
- Aggregate Function:聚合函数对多个行进行操作,返回一个单一的结果。例如,SUM、AVG、COUNT等。
- Window Function:窗口函数对一组行进行操作,返回一个结果。例如,ROW_NUMBER、RANK、DENSE_RANK等。
- CASE Clause:CASE子句用于基于一系列条件进行选择。
- PIVOT Clause:PIVOT子句用于将行转化为列,生成一个透视表。
- UNPIVOT Clause:UNPIVOT子句是PIVOT的逆操作,将列转化为行。
- LATERAL VIEW Clause:LATERAL VIEW子句用于与生成的表结合,生成一个虚拟表。
- LATERAL SUBQUERY:LATERAL SUBQUERY子句用于在FROM子句中生成一个子查询。
- TRANSFORM Clause:TRANSFORM子句用于对数据进行转换,通常与脚本语言(如Python、Scala、Java等)结合使用。
JOIN:JOIN子句用于在两个或多个表之间进行关联。SparkSQL支持内连接、左外连接、右外连接和全外连接等多种类型的连接。
Common Table Expression (CTE)
在SparkSQL中,Common Table Expression(CTE)是一个临时的结果集,它在一个SQL语句中被定义,然后在这个SQL语句的剩余部分被引用。CTE提供了一种方式来将复杂的SQL语句分解为一系列简单的步骤。
你可以使用WITH关键字来定义一个CTE。例如:
WITH cte_sales AS ( SELECT date, sum(sales) as total_sales FROM sales_table GROUP BY date ) SELECT date, total_sales FROM cte_sales WHERE total_sales > 1000;
在上面的例子中,我们首先定义了一个名为cte_sales的CTE,这个CTE的结果是通过对sales_table表的销售数据进行汇总得到的。
然后,在WITH语句后面的主查询中,我们从cte_sales中选择了那些总销售额超过1000的日期。
使用CTE的好处是可以将复杂的查询分解为简单的、易于理解的步骤。并且,由于CTE是在执行时计算的,因此它们可以提供更好的性能,特别是对于大型数据集。
CLUSTER BY Clause
在SparkSQL中,CLUSTER BY子句会将数据按照某种方式分区和排序,确保在每个分区内部具有相同的键的数据聚集在一起。
CLUSTER BY子句等价于先使用DISTRIBUTE BY进行分区,然后对每个分区使用SORT BY进行排序。这个子句通常用于大数据处理,确保具有相同键的数据在一起,这样可以提供更高效的数据处理。
例如:
SELECT * FROM table CLUSTER BY column;
上述语句将根据”column”对表中的数据进行分区和排序。所有具有相同”column”值的行都会被分到同一个分区,并在该分区内按照”column”的值进行排序。
注意,CLUSTER BY子句只能在SELECT语句中使用。并且,由于CLUSTER BY需要对数据进行分区和排序,所以它可能会消耗大量的计算资源,因此在使用时需要谨慎。
DISTRIBUTE BY Clause
在SparkSQL中,DISTRIBUTE BY子句用于根据指定的列的值将数据分发到不同的分区。DISTRIBUTE BY子句确保所有具有相同值的行都进入同一个分区。
这在你需要进行某种类型的全局聚合(例如全局排序或计算总和)时特别有用,因为这需要所有相关的行都在同一个分区内。
例如:
SELECT * FROM table DISTRIBUTE BY column;
在这个例子中,DISTRIBUTE BY子句将根据”column”列的值将表中的数据分发到不同的分区。所有具有相同”column”值的行都会被分到同一个分区。
注意,在大数据处理中,数据分区的方式有很大的影响。通过合理地选择分区键可以有效地优化数据处理性能。当你选择一个分区键时,应该尽量选择能够使数据均匀分布的列,以避免数据倾斜。
另外,虽然DISTRIBUTE BY子句可以将数据分发到不同的分区,但它并不会对每个分区的数据进行排序。如果你需要在每个分区内对数据进行排序,可以使用CLUSTER BY子句或者在DISTRIBUTE BY之后使用SORT BY子句。
GROUP BY Clause
在SparkSQL中,GROUP BY子句用于根据一个或多个列对结果集进行分组。GROUP BY子句通常与聚合函数(如SUM、AVG、COUNT等)一起使用,对每个组进行计算。
例如:
SELECT column1, AVG(column2) FROM table GROUP BY column1;
在这个例子中,首先根据”column1″的值将表中的数据分组,然后对每个组计算”column2″的平均值。
GROUP BY子句还可以与HAVING子句一起使用,对分组后的结果进行过滤。例如:
SELECT column1, COUNT(*) FROM table GROUP BY column1 HAVING COUNT(*) > 100;
在这个例子中,首先根据”column1″的值将表中的数据分组,然后对每个组计算行数,最后只选择那些行数超过100的组。
注意,GROUP BY子句在执行时可能需要大量的内存,因为它需要在内存中存储每个组的数据。因此,如果你的数据集非常大,或者你的组非常多,GROUP BY子句可能会导致内存溢出。在这种情况下,你可能需要考虑使用更有效的数据处理策略,例如使用更大的集群,或者对数据进行预处理,以减少需要处理的组的数量。
HAVING Clause
在SparkSQL中,HAVING子句用于过滤由GROUP BY子句生成的结果集。HAVING子句的行为类似于WHERE子句,但是WHERE子句不能与聚合函数一起使用,而HAVING子句则可以。
HAVING子句常常和GROUP BY子句一起使用。例如:
SELECT column1, COUNT(*) FROM table GROUP BY column1 HAVING COUNT(*) > 100;
在这个例子中,GROUP BY 子句根据 “column1” 的值将表中的数据分组,然后 HAVING 子句选择出那些组的行数超过 100 的组。
注意,HAVING 子句中的条件是在聚合操作后应用的,这意味着 HAVING 子句可以引用所有在 SELECT 子句中的列和表达式,包括那些不在 GROUP BY 子句中的列和表达式。
需要注意的是,虽然 HAVING 子句可以过滤聚合结果,但它并不能替代 WHERE 子句。在大多数情况下,你应该尽可能地使用 WHERE 子句来过滤数据,因为 WHERE 子句在聚合操作之前执行,可以减少需要处理的数据量,从而提高查询性能。
Hints
在 SparkSQL 中,提示(Hints)是一种向查询优化器提供额外信息,以影响查询执行计划的方式。
使用提示可以在查询执行过程中对一些操作(如连接操作)进行优化。这通常在自动查询优化不能生成最优执行计划时使用。例如,你可能知道某个表非常大,而另一个表非常小,所以希望优化器在处理连接操作时倾向于使用特定的算法。
在 SparkSQL 中,可以使用 /*+…*/ 的语法来添加提示。例如:
SELECT /*+ BROADCAST(table1) */ * FROM table1 JOIN table2 ON table1.id = table2.id;
在上面的例子中,BROADCAST(table1) 是一个广播提示,它告诉查询优化器在处理连接操作时应将 table1 广播到所有节点,而不是进行分布式的混洗操作。这对于 table1 非常小的情况非常有用,因为广播小表通常比混洗大表更有效。
然而,使用查询提示需要谨慎,因为不正确的提示可能会导致性能下降。只有在你了解查询和数据特性,并且确定查询优化器不能生成最优执行计划时,才应使用查询提示。
Inline Table
在 SparkSQL 中,”Inline Table” 是一种临时的、在查询中定义的表,也被称为子查询生成的表或派生表。
这种类型的表在查询执行过程中创建并使用,查询结束时,该表就会被自动删除。这对于一次性的查询或需要在查询中创建临时视图的情况非常有用。
以下是一个使用 Inline Table 的例子:
SELECT customers.name, orders.order_total
FROM (
SELECT id, SUM(total) as order_total
FROM orders
GROUP BY id
) AS orders
JOIN customers ON customers.id = orders.id;
在这个例子中,我们首先创建了一个名为 orders 的 Inline Table,该表对 orders 表进行了分组并计算了每个 id 的总订单金额。然后,我们将这个 Inline Table 与 customers 表进行了连接,以获取每个客户的名字和订单总额。
注意,虽然 Inline Table 在一些情况下很有用,但由于它们在查询执行过程中创建并删除,因此可能会增加查询的执行时间,尤其是当 Inline Table 很大时。因此,如果可能,应该尽量避免在性能敏感的查询中使用 Inline Table。
File
在 SparkSQL 中,你可以使用 SELECT * FROM parquet.file.parquet 这样的语句直接从 Parquet 文件中读取数据,其中 parquet.file.parquet 是你的 Parquet 文件的路径。
然而,要注意的是,首先你需要将 Parquet 文件注册为一个表(或视图)。具体的步骤可能如下:
spark.sql("CREATE OR REPLACE TEMPORARY VIEW parquet_view USING parquet OPTIONS (path '/path/to/your/parquet.file.parquet')")
然后,你就可以使用 SELECT 语句从这个视图中查询数据:
spark.sql("SELECT * FROM parquet_view").show()
上述步骤首先创建了一个临时视图 parquet_view,该视图映射到你的 Parquet 文件。然后,你就可以像查询普通的数据库表一样查询这个视图。
这个方法的好处是,你可以使用 SQL 语句来查询和处理数据,而无需编写复杂的数据处理代码。此外,由于 Parquet 是一种列式存储格式,所以这种方法还可以提供良好的查询性能。
JOIN
在 SparkSQL 中,JOIN 操作用于将两个或多个表(DataFrame)基于某个或某些共享的列(键)进行合并。
以下是一些常用的 JOIN 类型:
- INNER: 这是最常见的类型的 JOIN,也被称为内连接。只有当在两个表中的指定列上的值匹配时,才会返回行。
- CROSS: CROSS JOIN 会产生两个表的笛卡尔积,即会返回所有可能的组合。如果表 A 有 n 行,表 B 有 m 行,那么结果将有 n*m 行。
- LEFT [OUTER]: 左连接(或左外连接)返回左表的所有行,无论在右表中是否有匹配的行。如果在右表中没有匹配的行,那么结果中右表的所有列的值将为 NULL。
- [LEFT] SEMI: 左半连接只返回左表中在右表中有匹配行的那些行。与内连接不同,它不会返回右表的任何列。
- RIGHT [OUTER]: 右连接(或右外连接)返回右表的所有行,无论在左表中是否有匹配的行。如果在左表中没有匹配的行,那么结果中左表的所有列的值将为 NULL。
- FULL [OUTER]: 全连接(或全外连接)返回左表和右表的所有行。如果某一行在另一张表中没有匹配的行,那么结果中另一张表的所有列的值将为 NULL。
- [LEFT] ANTI: 左反连接只返回左表中在右表中没有匹配行的那些行。它不会返回右表的任何列。
注意,JOIN 操作可以是计算密集型的,尤其是在处理大量数据时。必要时,应使用查询优化技术,比如分区修剪、过滤器传播和使用广播变量等,来提高处理性能。
LIKE Predicate
在 SparkSQL 中,LIKE 谓词用于进行基于模式匹配的字符串比较。它通常用于 WHERE 子句中,来过滤出符合指定模式的字符串。
LIKE 谓词的用法如下:
SELECT column_name FROM table_name WHERE column_name LIKE pattern;
这里,pattern 是用于匹配的模式,可以包含以下通配符:
- %:匹配任意长度的字符串,包括空字符串。
- _:匹配任意单个字符。
例如,如果你想从名为 employees 的表中,找出所有名字以 J 开始的员工,可以使用以下查询:
SELECT name FROM employees WHERE name LIKE 'J%';
这将会返回所有名字以 J 开始的员工名字。
如果你想找出所有名字的第二个字母是 a 的员工,可以使用以下查询:
SELECT name FROM employees WHERE name LIKE '_a%';
这将会返回所有名字的第二个字母是 a 的员工名字。
注意,LIKE 谓词是区分大小写的。如果你想进行不区分大小写的匹配,可以使用 ILIKE 谓词。
LIMIT Clause
在 SparkSQL 中,LIMIT 子句用于限制查询返回的结果数量。
LIMIT 子句的语法如下:
SELECT column1, column2, ... FROM table_name LIMIT number;
这里的 number 是你想要返回的最大结果数量。
例如,你可以使用以下的查询从名为 employees 的表中获取前 10 个员工的名字:
SELECT name FROM employees LIMIT 10;
这将返回前10个员工的名字。
值得注意的是,当使用LIMIT子句时,返回的结果并不一定是在数据库中的前number个,因为没有定义返回结果的顺序。如果你想按照某种顺序返回结果,可以使用ORDER BY子句。例如,以下的查询将返回工资最高的10个员工:
SELECT name, salary FROM employees ORDER BY salary DESC LIMIT 10;
这将返回工资最高的10个员工的名字和工资。
OFFSET Clause
在SparkSQL中,OFFSET子句用于跳过开始的一些行,然后返回剩余的行。常常与LIMIT子句一起使用,以实现在结果集中进行分页。
OFFSET子句的语法如下:
SELECT column1, column2, ... FROM table_name LIMIT number OFFSET number_to_skip;
这里的number是你想要返回的结果数量,number_to_skip是开始的行数,你想要跳过。
例如,在员工表中,如果你想跳过前10个,然后查询接下来的10个员工,可以使用以下查询:
SELECT name FROM employees LIMIT 10 OFFSET 10;
这将跳过第一个到第十个员工,然后返回第十一个到第二十个员工的名字。
但是要注意的是,OFFSET在SparkSQL中并不直接支持。不过,你可以通过结合使用ROW_NUMBER()或rank()函数和子查询来实现类似的功能。
另外,对于大数据集,OFFSET可能效率低下,因为它需要扫描所有的前置行。在可能的情况下,寻找更有效的数据访问策略是推荐的。
ORDER BY Clause
在SparkSQL中,ORDER BY子句用于对查询结果进行排序。你可以根据一个或者多个列进行排序。
ORDER BY子句的语法如下:
SELECT column1, column2, ... FROM table_name ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
这里的ASC和DESC关键字用于指定排序是升序还是降序。默认是升序。
例如,你可以使用以下查询从名为employees的表中获取所有员工的名字,并按照薪水升序排序:
SELECT name, salary FROM employees ORDER BY salary;
这将返回所有员工的名字和薪水,并按照薪水升序排序。
如果你想按照薪水降序排序,可以使用以下查询:
SELECT name, salary FROM employees ORDER BY salary DESC;
这将返回所有员工的名字和薪水,并按照薪水降序排序。
如果你想根据多个列进行排序,可以在ORDER BY子句中指定多个列。例如,以下查询将按照部门和薪水排序:
SELECT name, department, salary FROM employees ORDER BY department, salary DESC;
这将返回所有员工的名字、部门和薪水,并首先按照部门升序排序,然后在每个部门内按照薪水降序排序。
Set Operators
SparkSQL支持多个集合运算符,主要用于组合SELECT查询的结果。这包括UNION和EXCEPT。在某些版本的Spark中,也支持INTERSECT。
UNION:UNION运算符用于组合两个SELECT语句的结果。它会删除重复的行。这是一个示例:
SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2;
UNION ALL:UNION ALL运算符与UNION类似,但不会删除重复的行。
SELECT column_name(s) FROM table1 UNION ALL SELECT column_name(s) FROM table2;
EXCEPT:EXCEPT运算符返回在第一个SELECT语句中存在,但在第二个SELECT语句中不存在的记录。这是一个示例:
SELECT column_name(s) FROM table1 EXCEPT SELECT column_name(s) FROM table2;
INTERSECT:(在某些版本的Spark中可用)INTERSECT运算符返回两个SELECT语句的结果的交集。
SELECT column_name(s) FROM table1 INTERSECT SELECT column_name(s) FROM table2;
在使用这些运算符时,你需要确保每个SELECT语句选择的列的数量和类型都是相同的。
SORT BY Clause
在SparkSQL中,SORT BY子句用于对查询结果进行排序。与ORDER BY子句不同,SORT BY子句在Spark中按照分区进行排序。
当你在Spark中对数据进行排序时,SORT BY和ORDER BY有一些关键的区别:
ORDER BY会对所有返回的数据进行全局排序,这可能需要进行额外的shuffle操作,因此可能会比SORT BY慢。另外,ORDER BY只返回一个文件,或者每个分区返回一个文件。
SORT BY会在每个分区内进行排序,而不是全局排序。结果可能是多个分区,每个分区内部的数据是排序的,但是跨分区的数据可能并不是有序的。这通常会比ORDER BY更快,因为它不需要全局shuffle。
以下是SORT BY子句的基本语法:
SELECT column1, column2, ... FROM table_name SORT BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
这里的ASC和DESC关键字用于设置是升序还是降序排序。默认是升序。
例如,你可以使用以下查询从名为employees的表中取得所有员工的名字,并按照薪水在每个分区内进行升序排序:
SELECT name, salary FROM employees SORT BY salary;
这将返回所有员工的名字和薪水,并且在每个分区内按照薪水升序排序。但是跨分区的数据可能并不是有序的。
TABLESAMPLE
在SparkSQL中,TABLESAMPLE子句允许你从表中抽取一部分行以进行分析。这对于大型数据集非常有用,因为你可以使用样本来估计整个数据集的特性。
TABLESAMPLE可以用在FROM子句中,接在表名后面。它的语法如下:
SELECT column1, column2, ... FROM table_name TABLESAMPLE (BUCKET num_buckets ON column_name);
其中,
- num_buckets是你想分割的桶的数量。Spark将尝试将表分割成这么多桶,并从每个桶中选择行。
- column_name 是你想基于其值进行桶分割的列。通常,这应该是一个可以均匀分布数据的列。
例如,以下查询从名为 employees 的表中选择一部分员工,并返回他们的名字和薪水:
SELECT name, salary
FROM employees TABLESAMPLE(BUCKET 10 ON employee_id);
这将尝试将 employees 表按照 employee_id 列的值分割成 10 个桶,并从每个桶中选择一部分行。
请注意,TABLESAMPLE 的实际行为可能会根据你所使用的 Spark 版本和配置而变化。在某些情况下,你可能会得到比你期望的更多或更少的行。因此,当你使用 TABLESAMPLE 时,最好在小数据集上进行测试,以确保它的行为符合你的期望。
Table-valued Function
在 SparkSQL 中,表值函数(Table-valued Functions)也是被支持的。一个表值函数在被调用时返回一个 DataFrame。这个 DataFrame 可以像其他 DataFrame 那样被操作:可以对其进行选择、过滤、分组等操作,也可以将其与其他 DataFrame 进行连接。
SparkSQL 内置了一些表值函数,例如 explode,posexplode,inline 等,用于处理复杂的数据类型,如数组和 Map。
explode:explode 函数用于将数组或者 Map 类型的列”展开”为多行。例如,假设你有一个包含多个值的数组列,explode 函数会为数组中的每个值创建一个新的行。
SELECT explode(arr) as val FROM values array(1,2,3), array(2,3,4) T(arr)
posexplode:posexplode 函数与 explode 函数类似,但是它还会提供一个表示位置(从 0 开始)的额外列。
SELECT posexplode(arr) as (pos, val) FROM values array(1,2,3), array(2,3,4) T(arr)
inline:inline 函数用于将数组 of structs 类型的列”展开”为多行,每个 struct 的字段成为一个列。
SELECT inline(arr) as (val1, val2) FROM values array(struct(1,"a"), struct(2,"b")) T(arr)
注意,表值函数可能会产生大量的行,因此在处理大型数组或者 Map 时要谨慎使用。
WHERE Clause
在 SparkSQL 中,WHERE 子句用于过滤查询结果,只返回满足指定条件的行。WHERE 子句可以使用各种比较运算符,如 =、<>、<、>、<=、>=,还可以使用逻辑运算符,如 AND、OR 和 NOT。
以下是 WHERE 子句的基本语法:
SELECT column1, column2, ... FROM table_name WHERE condition;
其中,condition 是你想用来过滤行的条件。这个条件可以引用任何在 FROM 子句中提到的表的列。
例如,以下查询从名为 employees 的表中选择所有薪水超过 50000 的员工:
SELECT name, salary FROM employees WHERE salary > 50000;
这将返回所有薪水超过 50000 的员工的名字和薪水。
你还可以使用 AND 和 OR 运算符来组合多个条件。例如,以下查询选择所有薪水超过 50000 并且在 Sales 部门的员工:
SELECT name, salary FROM employees WHERE salary > 50000 AND department = 'Sales';
这将返回所有薪水超过 50000 并且在 Sales 部门的员工的名字和薪水。
Aggregate Function
在 SparkSQL 中,聚合函数用于计算一组值的某种汇总数据,例如计算总和、平均值、最大值、最小值等。聚合函数常与 GROUP BY 子句一起使用,以对分组的数据进行汇总计算。
以下是一些常见的 SparkSQL 聚合函数:
- COUNT(column):返回指定列中非空值的数量。
- SUM(column):返回指定列的所有值的总和。
- AVG(column):返回指定列的所有值的平均值。
- MAX(column):返回指定列的最大值。
- MIN(column):返回指定列的最小值。
例如,以下查询计算 employees 表中所有员工的平均薪水:
SELECT AVG(salary) as avg_salary FROM employees;
在这个查询中,AVG(salary) 是一个聚合函数,它计算 salary 列的平均值。
你还可以使用 GROUP BY 子句与聚合函数一起使用,以对分组的数据进行汇总。例如,以下查询计算每个部门的平均薪水:
SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department;
在这个查询中,GROUP BY department 子句将员工按部门分组,然后 AVG(salary) 聚合函数计算每个部门的平均薪水。返回的表将为每个部门有一行,并包含该部门的平均薪水。
Window Function
在 SparkSQL 中,窗口函数可以在数据的特定窗口或子集上执行计算。这使得你可以在每行上执行涉及相邻(在某种有意义的方式)行的复杂计算,例如,计算移动平均或累计和。
窗口函数需要定义一个窗口规范,它决定了数据的排序方式,以及每行的窗口范围。窗口规范使用 OVER 子句定义,可能包含 PARTITION BY、ORDER BY 和 ROWS 子句。
以下是一些常用的 SparkSQL 窗口函数:
- ROW_NUMBER(): 分配一个唯一的整数行号,从 1 开始,对于每个窗口分区。
- RANK(): 计算窗口分区中每行的排名,具有相同值的行会接收相同的排名。
- DENSE_RANK(): 与 RANK() 函数类似,但是与 RANK() 不同的是,它不会跳过排名。
- LEAD(column, offset, default): 返回指定的偏移行的列值。
- LAG(column, offset, default): 与 LEAD() 函数相反,返回指定偏移的上一行的列值。
这是一个 SparkSQL 中窗口函数的示例:
SELECT department, name, salary, RANK() OVER(PARTITION BY department ORDER BY salary DESC) as rank FROM employees
在这个查询中,RANK() OVER(PARTITION BY department ORDER BY salary DESC) 是窗口函数。PARTITION BY department 将员工按部门分组,ORDER BY salary DESC 将每个部门的员工按薪水降序排序,然后 RANK() 函数为每个部门的员工分配排名。返回的表将为每个员工有一行,并包含该员工的部门、姓名、薪水和在其部门中的薪水排名。
CASE Clause在SparkSQL中,CASE子句用于在查询中添加条件逻辑。它的工作方式与编程语言中的if-else语句类似。CASE子句可以有两种形式:简单的CASE子句和搜索的CASE子句。
简单的CASE子句:这种形式的CASE子句允许我们根据列或表达式的值来改变结果。
语法:
CASE column WHEN value1 THEN result1 WHEN value2 THEN result2 ... ELSE default_result END
例子:
SELECT name, salary,
CASE department
WHEN 'Sales' THEN 'SalesDept'
WHEN 'Engineering' THEN 'EnggDept'
ELSE 'OtherDept'
END as dept_name
FROM employees;
搜索的CASE子句:这种形式的CASE子句允许我们根据多个列或表达式的复合条件来改变结果。
语法:
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE default_result END
例子:
SELECT name, salary, CASE WHEN salary>100000 THEN 'HighSalary' WHEN salary<=100000 AND salary>50000 THEN 'MediumSalary' ELSE 'LowSalary' END as salary_level FROM employees;
在这两种形式的CASE子句中,每个WHEN后面都跟着一个条件(对于简单的CASE子句,这是一个值;对于搜索的CASE子句,这是一个布尔表达式)。如果该条件为真,那么它后面的THEN子句中的结果就会被返回。如果所有的WHEN子句中的条件都不为真,那么ELSE子句中的结果将被返回。如果没有ELSE子句,并且所有的WHEN子句中的条件都不为真,那么CASE表达式将返回NULL。
PIVOT Clause
SparkSQL的PIVOT子句可用于将行数据转为列数据,常用于生成报告和分析,使输出数据更易于理解。基本上,它是从原始数据中创建透视报告的方法。
例如,假设我们有一个销售数据表,包含product(产品)、region(地区)和sales(销售额)三列,我们可以使用PIVOT子句创建一个包含每种产品在每个地区的销售额的报告。
这是使用PIVOT子句的基本语法:
SELECT... FROM... PIVOT(aggregate_function(column_to_aggregate) FOR column_to_pivot IN (list_of_values))
- aggregate_function(column_to_aggregate)是一个聚合函数,应用于你想在报告中计算的列。
- column_to_pivot是你想要转为列的列。
- list_of_values是column_to_pivot列中的值,你想要成为新列的值。
这是一个使用PIVOT子句的示例:
SELECT * FROM (
SELECT product, region, sales
FROM sales_data)
PIVOT(
SUM(sales)
FOR product
IN ('ProductA','ProductB','ProductC')
)
这个查询将返回一个包含region列和一个列每种产品的表,其中每行表示一个地区,每个产品列包含该地区的总销售额。
注意,目前SparkSQL的PIVOT子句不支持IN子句中使用子查询,所以你必须显式地列出你想要转为列的所有值。
UNPIVOT Clause
UNPIVOT语法用于将列转换为行。这是UNPIVOT的基本语法:
SELECT...FROM table UNPIVOT(value FOR key IN (column1 AS key1, column2 AS key2,...))
其中,
- value:是新生成的值的列名。
- key:是新生成的键的列名。
- column1, column2,…:是要进行unpivot操作的原始列。
- key1, key2,…:是原始列在结果表中对应的键值。
LATERAL VIEW Clause
LATERAL VIEW子句在SparkSQL中用于与复杂数据类型一起使用,如数组和映射,以便可以从一个列产生多行(将一个列拆分为多行)。LATERAL VIEW子句通常与一种表生成函数(如explode)一起使用。
下面是使用LATERAL VIEW子句的基本语法:
SELECT... FROM table LATERAL VIEW function(column) alias AS column_alias
- function(column)是一个表生成函数,它对column进行操作并创建新的行。
- alias是LATERAL VIEW子句的别名,可以在查询的其余部分中引用它。
- column_alias是新生成的列的别名。
这是一个LATERAL VIEW子句的示例:
SELECT name, word FROM documents LATERAL VIEW explode(split(text,' ')) exploded_text AS word
在此查询中,documents表有两列:name和text。text列包含由空格分隔的单词。split(text,’ ‘)将text列拆分为一个单词数组,然后explode函数将每个单词变为新的行。LATERAL VIEW子句的结果是一个包含原始的name列和一个新的word列的表,其中每个单词有一行。如果原始的text列包含n个单词,那么原始的一行将变为n行。
注意:LATERAL VIEW子句可以在单个查询中使用多次,以处理多个复杂类型的列。
LATERAL SUBQUERY
LATERAL子查询可以在FROM子句中引用其左侧的其他项,包括JOIN子句的左侧部分。这是一个基本的语法:
...LATERAL (subquery)[AS] alias[(col_name[,col_name...])]
以下是在SparkSQL中使用LATERAL子查询的示例:
SELECT * FROM s LATERAL (SELECT key, s.value*2 FROM s WHERE key>1) AS t(key,value)
在这个示例中,子查询(SELECT key, s.value*2 FROM s WHERE key>1)从FROM子句的左侧表“s”中选择行。
TRANSFORM Clause在SparkSQL中,TRANSFORM子句用于对输入行应用用户定义的函数。这个函数以一种编程语言(如Python或Scala)写成,并可以处理复杂的数据转换。
以下是TRANSFORM子句的基本语法:
SELECT TRANSFORM(column_list) USING 'script' [AS (column_list)] FROM table
其中,
- column_list是输入到用户定义函数的列。
- ‘script’是用户定义函数的脚本,可以是任何可以读取标准输入,写入标准输出,并接收命令行参数的程序。
- AS (column_list)是用户定义函数的输出列的列表。如果省略,Spark会将输出列命名为key和value。
这是使用TRANSFORM子句的一个例子:
SELECT TRANSFORM(id, text) USING 'python script.py' AS (id, words) FROM documents
在此查询中,documents表有两列:id和text。TRANSFORM子句将每一行的id和text作为输入传递给Python脚本script.py。脚本的输出是一个id和一个words列,其中words是text列中单词的数量。
请注意,Spark会在每个分区上单独运行脚本,这意味着脚本应该是无状态的,并且不能依赖于在不同分区之间共享的任何信息。由于需要在每个分区上启动和管理外部进程,TRANSFORM子句可能会比其他Spark操作更消耗资源。
EXPLAIN
在SparkSQL中,EXPLAIN命令用于展示一个SQL语句的执行计划,包括它如何被转换为物理操作。通过查看这个执行计別,开发者可以理解Spark是如何执行特定查询的,这对于调试性能问题和优化查询非常有帮助。
EXPLAIN命令的基本用法如下:
EXPLAIN [EXTENDED|CODEGEN|COST|FORMATTED] SELECT…
- EXTENDED: 展示逻辑执行计划和物理执行计划。
- CODEGEN: 展示将查询计划转换为执行代码的过程。
- COST: 展示成本模型估计的查询计划。
- FORMATTED: 以易于理解的格式化形式展示关键阶段的详细执行计划。
如果没有指定任何选项,EXPLAIN仅展示物理执行计划。
假设我们有一个简单的查询:
EXPLAIN SELECT * FROM myTable WHERE id > 100
这将显示该查询的物理执行计划,帮助我们理解Spark是如何处理这个SELECT语句的。
如果我们想要更详细的信息,可以使用EXTENDED选项:
EXPLAIN EXTENDED SELECT * FROM myTable WHERE id > 100
这将展示逻辑执行计划和物理执行计划的更多细节,包括解析后的查询、分析后的逻辑计划以及优化后的逻辑计划和最终的物理计划。
注意
- 在解读EXPLAIN输出时,应注意到SparkSQL的执行计划优化是动态的,依赖于数据的大小、分布和查询本身,因此对于相同的查询,不同的环境或数据集可能导致不同的执行计划。
- 对于复杂的查询,执行计划可能会变得非常详细,解读需要一定的经验和对Spark内部工作机制的了解。
辅助声明
- ADDFILE: 将文件添加到Spark环境中。文件将被复制到所有执行器上。可以使用get(“file”)来获取其绝对路径。
- ADDJAR: 将JAR文件添加到Spark环境中。JAR文件中的类对于后续的命令和查询将是可用的。
- ANALYZE TABLE: 用于计算表或表的一部分的统计信息,主要用于优化查询。可以分析列的统计信息,也可以分析表的行计数。
- CACHE TABLE: 将表的结果缓存到内存中,以加快后续查询的访问速度。
- CLEAR CACHE: 清除所有缓存表。
- DESCRIBE DATABASE: 描述数据库的元数据,如其位置,评论等。
- DESCRIBE FUNCTION: 描述函数的功能和用法。
- DESCRIBE QUERY: 描述查询的逻辑计划。
- DESCRIBE TABLE: 描述表的模式。
- LIST FILE: 列出由ADDFILE命令添加的文件。
- LIST JAR: 列出由ADDJAR命令添加的JAR文件。
- REFRESH: 使缓存的表和视图的元数据和数据无效。
- REFRESH TABLE: 使缓存的表的元数据和数据无效。
- REFRESH FUNCTION: 使缓存的函数的元数据无效。
- RESET: 重置所有Spark和SQLConf到默认状态。
- SET: 设置配置参数的值,或者获取当前的配置参数。
- SHOW COLUMNS: 显示表中的列。
- SHOW CREATE TABLE: 显示创建表的命令。
- SHOW DATABASES: 显示数据库列表。
- SHOW FUNCTIONS: 显示函数列表。
- SHOW PARTITIONS: 显示表的分区。
- SHOW TABLE EXTENDED: 显示数据库中的表,包括视图。
- SHOW TABLES: 显示数据库中的表。
- SHOW TBLPROPERTIES: 显示表的属性。
- SHOW VIEWS: 显示数据库中的视图。
- UNCACHE TABLE: 否决之前的CACHE TABLE命令,从内存中移除表的缓存。


