PRQL简介 PRQL(Pipelined Relational Query Language)是一种现代化的数据查询语言,旨在提供一种比SQL更简洁和直观的方式来表达数据查询。PRQL的设计目标是通过更具可读性和可维护性的语法,简化数据分析师和开发…

Malloy是什么? Malloy是一个现代开源语言,专为数据建模、分析和转换而设计。它允许用户通过直观易懂的语法,定义数据模型、创建度量标准、建立数据之间的关系,以及执行复杂的数据查询和分析。Malloy的核心目标是…

PostgreSQL 简介 PostgreSQL 是一个功能强大、开源的对象关系型数据库管理系统(ORDBMS),以其可靠性、特性丰富和性能卓越而闻名。它最初于 1986 年由加州大学伯克利分校的计算机科学研究团队开发,目前由全球开…

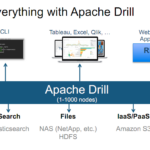
Apache Drill简介 Apache Drill是一个开源的分布式SQL查询引擎,设计用于大数据处理和分析。它的目标是为多种数据源提供统一的查询接口,支持对结构化和半结构化数据进行高效的查询和分析。 产生背景 Apache…
Trino简介 Trino(原名PrestoSQL)是一个开源的分布式SQL查询引擎,设计用于对各种数据源进行高速查询。Trino的设计初衷是为了解决大规模数据分析的需求,能够在数据湖、数据仓库和其他数据存储系统上进行交互式分…

Kyuubi简介 Kyuubi是一个开源的多租户、大规模数据分析引擎服务,基于Apache Spark构建,旨在提供高效、易用和安全的SQL-on-Spark解决方案。它的设计目标是通过提供一个统一的接口来简化大数据分析的使用,使用户能…
Hue简介 Hue(Hadoop User Experience)是一个开源的Web界面应用,旨在为使用Apache Hadoop生态系统的用户提供一个友好的用户界面。它集成了多种Hadoop组件,简化了大数据操作和管理,使用户能够更容易地进行数据分…
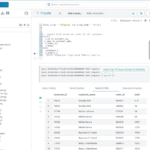
在SQL中,IN和EXISTS(以及它们的否定形式NOT IN和NOT EXISTS)是常用的子查询条件,用于检查某个值是否在子查询结果集中存在。虽然它们可以实现类似的功能,但在语法、性能和行为上存在一些差异。 IN IN 用于检…

在日常的工作中,使用较多的是 Presto,原因是它比 Spark 快非常多。当然,使用过程中也会遇到一些问题,其中主要的是一些内置函数与SparkSQL 存在较大的差异。这里对 Presto SQL 一个简单的整理。关于 Presto 的相…
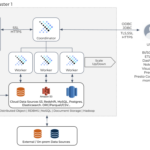
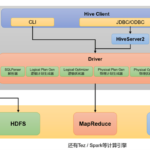
Apache Hive 是一个开源的数据仓库框架,用于查询和分析大数据集存储在 Hadoop 文件系统中。 Hive 提供了一种类 SQL 的查询语言,叫做 HiveQL,它使得熟悉 SQL 的用户可以在 Hive 上查询、汇总和分析数据。同时,…