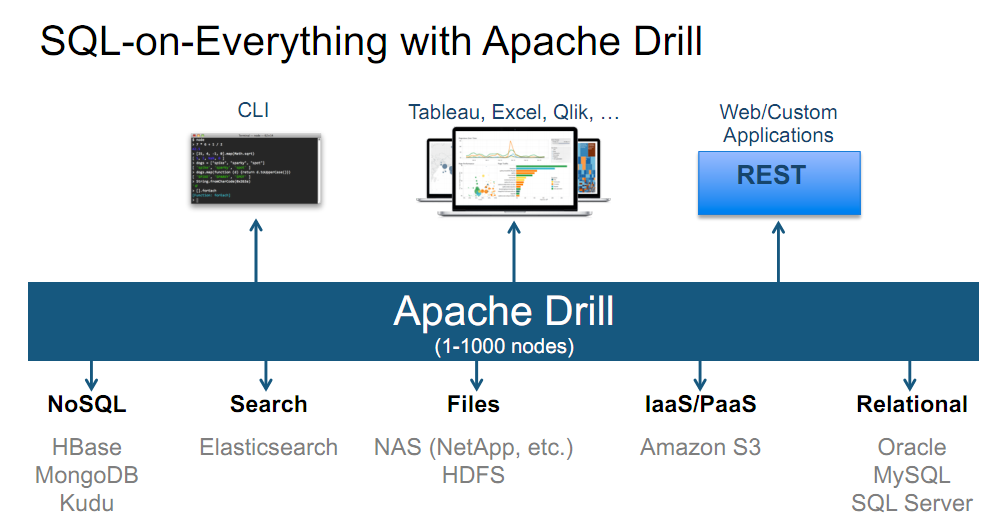
Apache Drill简介
Apache Drill是一个开源的分布式SQL查询引擎,设计用于大数据处理和分析。它的目标是为多种数据源提供统一的查询接口,支持对结构化和半结构化数据进行高效的查询和分析。
产生背景
Apache Drill的产生背景与大数据时代对灵活、高效数据查询和分析工具的需求密切相关。以下是Apache Drill产生的几个关键背景因素:
- 大数据的快速增长:随着互联网和数字化业务的快速发展,企业和组织产生的数据量呈指数级增长。这些数据不仅规模庞大,而且种类繁多,包括结构化数据、半结构化数据(如JSON、XML)和非结构化数据(如文本、日志)。
- 多样化的数据存储系统:数据存储不再局限于传统的关系型数据库。NoSQL数据库、分布式文件系统(如HDFS)、云存储服务(如Amazon S3)等多种数据存储系统被广泛使用。这些系统的多样性增加了数据访问和整合的复杂性。
- 对实时数据分析的需求:企业希望能够实时地从其大数据中提取有价值的信息,以支持快速决策和业务优化。这要求查询工具能够以低延迟、高性能的方式处理和分析数据。
- 半结构化数据的普及:许多新兴应用程序和服务(如社交媒体、物联网)生成大量半结构化数据。这些数据格式灵活,但传统的SQL查询引擎处理起来相对困难,因为它们通常需要预定义的schema。
- 现有大数据工具的局限性:许多传统的SQL查询引擎和大数据处理工具(如MapReduce)在处理多样化数据源和半结构化数据时存在性能和灵活性上的局限。这些工具通常需要复杂的ETL过程,难以支持快速数据探索和交互式分析。
在这样的背景下,Apache Drill诞生于2012年,最初由MapR Technologies提出,并于2013年成为Apache软件基金会的一个孵化项目。Drill的设计目标包括:
- 统一的数据查询接口:提供一个统一的SQL查询接口,能够访问和处理来自不同数据源的数据,无需复杂的ETL过程。
- 支持schema-free查询:允许用户在没有预定义schema的情况下查询半结构化数据,如JSON和Parquet。
- 高性能和扩展性:支持实时、交互式数据分析,能够水平扩展以处理大规模数据集。
- 灵活的数据源集成:通过存储插件机制,支持与多种数据源的无缝集成。
核心特性
Apache Drill是一个开源的分布式SQL查询引擎,专为大数据分析设计。它具有许多核心特性,使其能够高效地处理多种数据源和数据格式。以下是Apache Drill的一些关键特性:
- Schema-Free SQL查询:Drill支持schema-free查询,这意味着用户可以在没有预定义schema的情况下查询数据。这对于处理JSON、Parquet等半结构化数据格式特别有用,因为这些格式的数据结构可以是动态和不规则的。
- 多数据源支持:Drill能够查询来自不同数据源的数据,包括Hadoop分布式文件系统(HDFS)、NoSQL数据库(如MongoDB、Cassandra)、云存储(如Amazon S3)、关系型数据库(如MySQL、PostgreSQL)、本地文件系统等。这使得Drill成为一个统一的数据查询平台。
- ANSI SQL兼容性:Drill支持ANSI SQL标准,并扩展了SQL以便更好地处理JSON和其他半结构化数据格式。这使得使用者可以用熟悉的SQL语言进行复杂的数据查询和分析。
- 自适应执行:Drill的查询引擎具有自适应执行能力,可以在查询运行时根据数据的实际分布动态调整执行计划。这提高了查询的性能和效率。
- 高性能和扩展性:Drill的架构支持水平扩展,能够处理PB级别的数据集,并且可以在数千台节点上运行。这使得Drill能够在大规模数据环境中提供高性能的查询服务。
- 内存优化:Drill使用Apache Arrow作为其内存格式,优化了内存使用和数据处理速度。Arrow提供了高效的列式内存布局,使得Drill能够更快地进行数据扫描和处理。
- 灵活的存储插件架构:Drill通过存储插件与不同的数据源集成。每个插件定义了Drill如何与特定数据源进行通信和数据访问。用户可以轻松地添加新的存储插件以支持更多的数据源。
- 交互式查询:Drill支持低延迟、交互式查询,使得用户可以快速地进行数据探索和分析,而无需等待长时间的批处理。
- 数据格式支持:Drill能够直接查询多种数据格式,包括JSON、Parquet、Avro、CSV、TSV、ORC等。这消除了复杂的ETL过程,用户可以直接从源数据中获取洞察。
- 强大的Web UI:Drill提供了一个用户友好的Web界面,用户可以通过该界面执行查询、查看执行计划、监控查询性能以及配置存储插件。
Apache Drill的核心特性使其成为一个灵活、高效的SQL查询引擎,特别适合需要快速分析多样化和半结构化数据的场景。它的schema-free查询能力、多数据源支持和高性能架构使得Drill在大数据分析领域具有独特的优势。通过这些特性,Drill能够帮助用户更轻松地从大规模数据集中提取有价值的信息。
缺点与不足
- 成熟度和社区支持:虽然Drill是一个Apache顶级项目,但与其他成熟的大数据工具(如Apache Spark)相比,其社区规模和生态系统可能较小,可能导致支持和资源有限。
- 查询性能:对于某些复杂查询或特定数据源,Drill的性能可能不如专用的查询引擎。优化查询性能可能需要更多的调优工作。
- 资源消耗:在处理非常大的数据集时,Drill的内存和计算资源消耗可能较高,需要在资源配置上进行仔细规划。
- 功能特性:尽管Drill支持多种数据格式和源,但在一些高级分析功能上可能不如其他专用工具(如机器学习支持)丰富。
使用场景
Apache Drill是一个灵活的分布式SQL查询引擎,适用于多种大数据处理和分析场景。以下是一些典型的使用场景:
- 实时大数据分析:Drill支持低延迟的交互式查询,使其适合需要实时分析和快速响应的应用场景。例如,在线广告点击流分析、实时用户行为监测等。
- 多数据源集成:Drill能够查询来自不同数据源的数据(如HDFS、NoSQL数据库、云存储、关系型数据库等),适合需要整合多源数据进行统一分析的场景。例如,企业需要从多个业务系统中提取数据进行跨系统分析。
- 半结构化数据处理:Drill的schema-free查询特性使其特别适合处理JSON、Parquet、Avro等半结构化数据。这在物联网数据分析、社交媒体数据挖掘等场景中非常有用,因为这些领域的数据格式往往不固定且复杂。
- 数据湖分析:在数据湖环境中,数据以多种格式存储,Drill可以作为一个统一的查询层,直接分析存储在数据湖中的数据,而无需预处理或转换。这使得Drill成为数据湖分析的理想选择。
- 快速数据探索和原型开发:数据科学家和分析师可以使用Drill进行快速的数据探索和原型开发。由于Drill支持交互式查询,用户可以快速验证假设,探索数据特征,而无需繁琐的预处理步骤。
- 日志分析Drill能够高效地处理和分析日志数据,适用于系统运维、故障排查、性能监控等场景。用户可以使用Drill查询和分析存储在HDFS或云存储中的大规模日志文件。
- 商业智能(BI)和报告:Drill可以与BI工具集成,通过JDBC/ODBC接口提供实时数据查询能力,支持商业智能和报告需求。
- 数据迁移和转换:在需要将数据从一种格式转换到另一种格式,或从一个存储系统迁移到另一个存储系统时,Drill可以用作数据转换工具,帮助实现数据的平滑迁移。
Apache Drill的多数据源支持、schema-free查询能力和高性能架构使其在多种数据处理和分析场景中非常有用。无论是实时数据分析、多源数据整合,还是半结构化数据处理,Drill都能提供强大的支持。通过利用Drill的这些特性,用户可以在复杂的大数据环境中快速、灵活地获取数据洞察。
Apache Drill的架构
Apache Drill的架构设计旨在提供高性能、可扩展的分布式SQL查询能力,同时支持多种数据源和数据格式。
核心组件
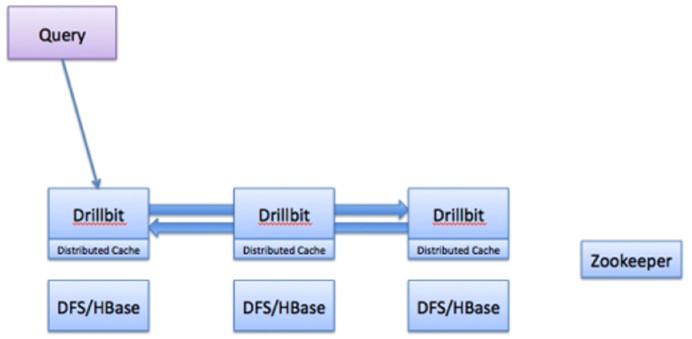
- Drillbit节点:Drillbit是Drill的核心服务组件,每个节点上都运行一个Drillbit实例。它负责处理客户端的查询请求,包括查询解析、优化和执行。所有Drillbit节点是对等的,能够相互协作以分布式方式执行查询任务。
- 查询优化器:Drill的查询优化器负责生成高效的查询执行计划。它采用基于成本的优化策略,能够根据数据的实际分布和查询条件动态调整执行计划,以提高查询性能。
- 执行引擎:Drill的执行引擎能够并行处理查询任务。它将查询划分为多个子任务,并在多个Drillbit节点上并行执行。这种并行执行机制可以显著提高查询的处理速度。
- 存储插件:Drill使用存储插件与不同的数据源集成。每个存储插件定义了Drill如何与特定数据源进行通信和数据访问。用户可以通过配置存储插件来扩展Drill的数据源支持。
- Apache Zookeeper:Drill使用Apache Zookeeper进行集群管理和服务发现。Zookeeper协调Drillbit节点的状态信息,并确保集群的高可用性和一致性。
数据流和查询执行过程
- 查询提交:用户通过Drill的JDBC/ODBC接口或Web控制台提交SQL查询请求。
- 查询解析和优化:Drillbit接收到查询请求后,会将SQL查询解析为逻辑查询计划。然后,查询优化器对逻辑计划进行优化,生成最优的物理执行计划。
- 任务分解和分发:优化后的查询计划被划分为多个可并行执行的子任务。这些子任务被分发到不同的Drillbit节点进行处理。
- 并行执行:各个Drillbit节点上的执行引擎并行处理分配到的子任务。它们从数据源中读取数据,进行必要的计算和转换操作。
- 结果合并和返回:各个节点处理完成后,结果被合并并返回给客户端。
关键特性
- 无中心化架构:Drill的架构设计为无中心化,每个Drillbit节点都可以处理查询请求。这种设计提高了系统的容错性和扩展性。
- 动态优化:Drill能够在查询运行时根据数据的实际分布动态调整执行计划,以优化查询性能。
- 灵活扩展:通过存储插件机制,Drill可以轻松集成新数据源,并支持多种数据格式。
Apache Drill的架构设计注重高性能、可扩展性和灵活性。通过无中心化的Drillbit节点、强大的查询优化器和灵活的存储插件机制,Drill能够高效地处理来自多种数据源和数据格式的查询请求。这使得Drill成为一个适用于复杂大数据环境的强大工具。
Apache Drill的未来
Apache Drill曾经因其灵活的查询能力和对多种数据源的支持而受到关注,但近年来,其受欢迎程度有所下降。这种趋势可能归因于多个因素:
- 竞争加剧:大数据领域的工具和技术发展迅速,出现了许多功能更强大、生态系统更完善的替代方案。例如,Apache Spark、Presto、Trino等工具在处理大规模数据集和提供交互式查询方面表现优异,并且拥有活跃的社区和丰富的功能扩展。
- 社区活跃度:相较于其他大数据项目,Apache Drill的社区活跃度和开发速度可能较低。这导致新功能和改进的推出速度较慢,影响了用户的长期信心和支持。
- 性能和可扩展性:虽然Drill设计上支持高性能和扩展性,但在某些复杂查询和大规模数据处理场景下,其性能可能不如专门优化的引擎(如Presto和Spark SQL)。此外,性能优化和调优可能需要较多的手动干预。
- 功能特性:Drill的主要优势在于schema-free查询和多数据源支持,但在机器学习、流处理等高级分析功能上,其能力可能不如其他综合性平台(如Apache Spark)。
- 商业支持和生态系统:一些替代方案背后有强大的商业公司支持,这带来了更好的产品化能力、企业级支持和营销推广。此外,这些公司通常提供更完整的生态系统和集成工具,吸引了更多的企业用户。
- 使用复杂性:尽管Drill提供了灵活的查询功能,但对于新用户而言,配置和优化可能具有一定的复杂性,特别是在处理特定数据源和格式时。
尽管Apache Drill在某些特定场景中仍然有其独特的优势(如快速数据探索、schema-free查询),但由于以上因素,其整体流行度有所下降。对于用户来说,选择合适的大数据处理工具需要考虑具体的应用需求、社区支持、性能表现以及生态系统的成熟度。在这种背景下,许多用户可能更倾向于选择那些功能更丰富、社区更活跃的替代方案。


