Spark简介
ApacheSpark是一个开源的分布式计算框架,专为大规模数据处理而设计。它提供了丰富的工具和库,支持多种数据处理任务,包括批处理、流处理、机器学习和图计算。Spark以其速度、易用性和通用性而闻名,广泛应用于各个行业的数据分析和处理任务。
ApacheSpark的产生背景可以追溯到大数据处理需求的演变,以及对更高效、更易用的数据处理框架的需求。以下是Spark产生的主要背景因素:
- Hadoop MapReduce的局限性:
- 高延迟:Hadoop MapReduce采用批处理模式,通常需要将数据写入磁盘以进行不同阶段之间的数据交换,导致较高的延迟。
- 复杂性:开发人员需要编写大量代码来实现复杂的数据处理任务,尤其是在需要进行多次迭代计算的情况下(如机器学习算法)。
- 不适合实时处理:MapReduce不适合实时数据流处理和交互式查询。
- 内存计算的需求:
- 由于硬件成本的降低,内存价格逐渐下降,基于内存的计算变得更加可行。
- 内存计算可以显著提高数据处理的速度,特别是对于需要多次迭代的数据处理任务,如机器学习和图计算。
- 多样化的数据处理需求:
- 随着数据应用的多样化,企业需要一个统一的框架来处理不同类型的任务,包括批处理、流处理、机器学习和图计算。
- 传统的MapReduce生态系统需要多个不同的工具来处理不同类型的任务,增加了系统的复杂性。
- 学术研究的推动:
- Spark最初由加州大学伯克利分校的AMPLab开发,作为一个研究项目,旨在探索大数据处理的新方法。
- AMPLab的研究重点是提高大数据处理的速度和效率,Spark是其重要的研究成果之一。
- 开源社区的支持:
- 2010年,Spark在Apache软件基金会下作为开源项目发布,迅速吸引了广泛的关注和贡献。
- 开源社区的支持加速了Spark的发展,使其迅速成为大数据处理领域的重要工具。
- 企业需求的驱动:
- 企业对实时数据处理、交互式分析和机器学习的需求不断增加,推动了对更高效的数据处理框架的需求。
- Spark的出现提供了一种灵活且高效的解决方案,能够满足企业的多样化数据处理需求。
总结来说,ApacheSpark的产生是对传统大数据处理框架的改进和创新,旨在解决高延迟、复杂性和多样化处理需求等问题。其内存计算特性和统一的处理框架使其成为大数据领域的重要组成部分。

SparkCore
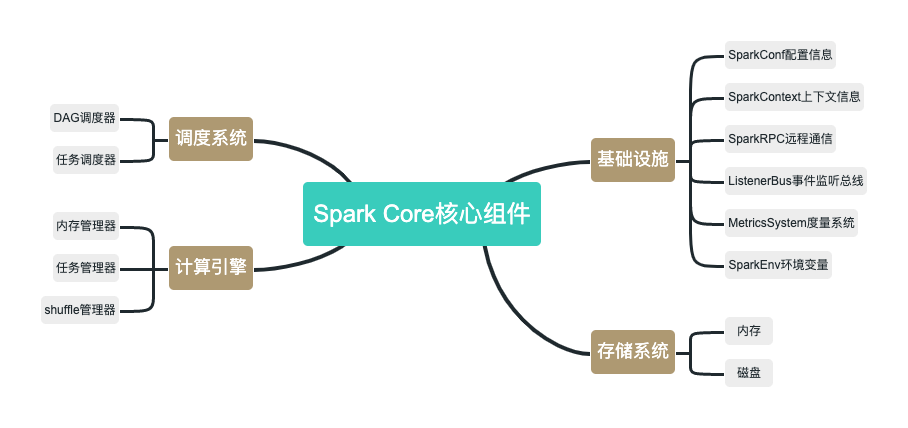
SparkCore是Spark的核心,各类核心组件都依赖于SparkCore。如下图所示,SparkCore核心组件包括基础设施、存储系统、调度系统、计算引擎四个部分。
Spark基础设施
Spark基础设施为其他组件提供最基础的服务,是Spark中最底层、最常用的一类组件。
- SparkConf:用于定义Spark应用程序的配置信息。
- SparkContext:是Spark中的应用入口,实现了网络通信、分布式、消息机制、存储、计算、运维监控、文件系统等各类常用功能,并且封装为简单易用的API,是开发人员只需要简单的几行代码就可以实现相应功能。
- SparkRPC:基于Netty实现的Spark组件间的网络通信组件。
- ListenerBus:Spark事件监听总线,主要用于内部组件间的交互。
- MetricsSystem:Spark度量系统,用于监控整个Spark集群中各个组件的运行状态。
- SparkEnv:Spark执行环境变量。内部封装了Rpc环境、序列化管理器、广播管理器、map任务输出跟踪器、存储等Spark运行所需的基础环境组件。
Spark存储系统
Spark另一个核心组件就是存储系统,主要用于管理Spark运行过程中的数据存储。Spark存储系统会按照存储层次,将数据优先保存在内存,在内存不足时使用是本机磁盘,并且支持远程存储。
Spark调度系统
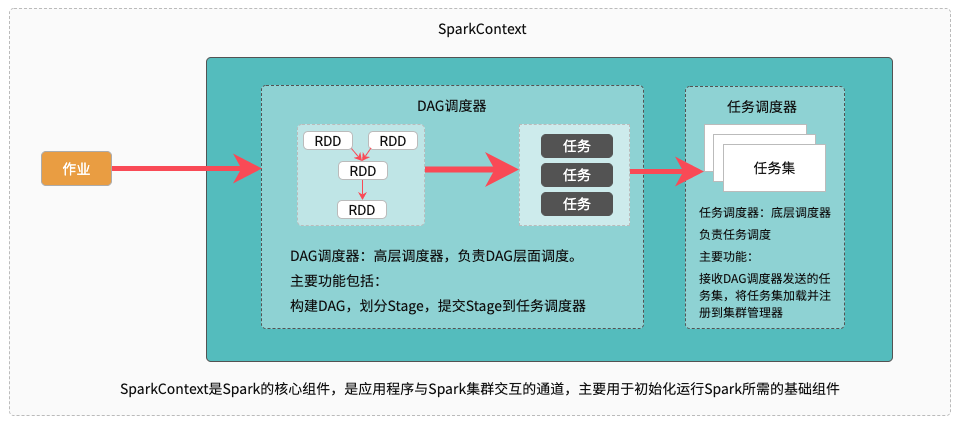
Spark调度系统主要包括DAG调度器和任务调度器两个部分。如下图所示,DAG调度器负责创建DAG并划分Stage,并基于Stage创建任务,并以任务集的形势提交任务。
任务调度器,主要负责对任务进行批量调度。
Spark计算引擎
Spark计算引擎主要包括内存管理器、作业管理器、任务管理器、Shuffle管理器几个部分。Spark计算引擎负责Spark在任务执行过程中的内存分配、作业和任务运行、状态监控于管理等。
SparkRDD
RDD(Resilient Distributed Dataset,弹性分布式数据集)是ApacheSpark的核心抽象,提供了一种在分布式内存中进行计算的数据结构。RDD是Spark中最基本的数据结构,支持对大规模数据集进行高效的、容错的并行计算。
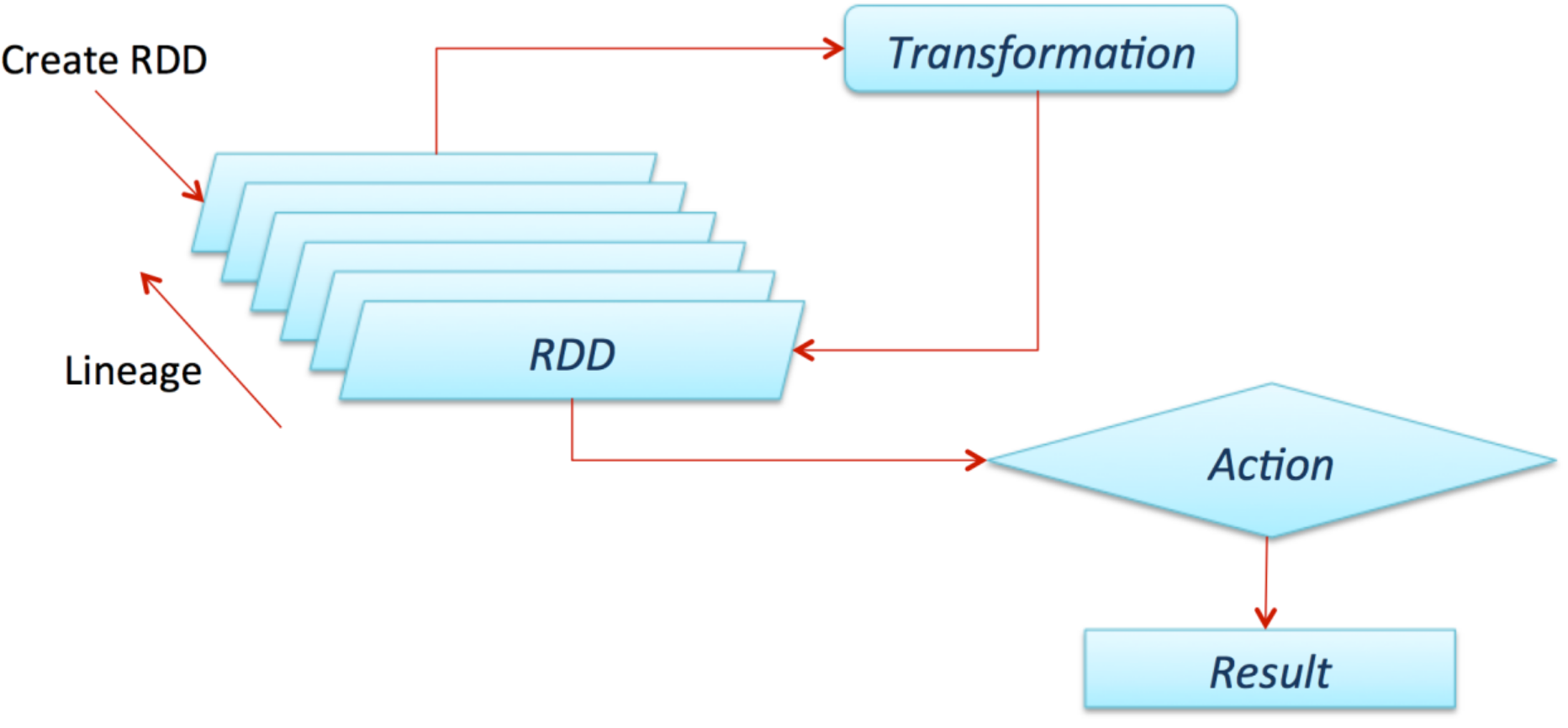
核心特性
- 弹性(Resilient):
- RDD提供了容错能力,可以从数据丢失中自动恢复。
- RDD的容错性是通过将转换操作(Transformation)的逻辑记录成一个有向无环图(DAG)实现的。如果某个分区的数据丢失,Spark可以通过重新计算来恢复数据。
- 分布式(Distributed):
- RDD是分布式的数据集,分布在集群的多个节点上。
- 用户可以在这些节点上并行执行计算,提高计算效率。
- 不可变(Immutable):
- 一旦创建,RDD就是不可变的,不能直接修改。
- 用户可以通过转换操作生成新的RDD,这种不可变性有助于确保数据一致性。
- 并行计算:
- RDD支持多种并行计算操作,包括map、filter、reduce、join等。
- 通过这些操作,用户可以对数据集进行复杂的处理和分析。
RDD的创建
- 从集合(Collection)创建:
- 用户可以通过 SparkContext 的 parallelize 方法将本地集合转换为 RDD。
- 适用于小规模数据集的快速测试和实验。
- 从外部存储读取:
- 可以从外部存储系统(如 HDFS、S3、HBase)中读取数据创建 RDD。
- 适用于大规模数据集的处理和分析。
- 从其他 RDD 转换:
- 通过对已有 RDD 进行转换操作(Transformation)生成新的 RDD。
RDD 的操作
RDD 提供了两类操作:转换(Transformations)和行动(Actions)。
- 转换(Transformations):
- 转换操作用于从一个 RDD 创建另一个 RDD,是惰性求值的,不会立即计算结果。
- 常见的转换操作包括:
- map(func):对 RDD 的每个元素应用函数 func,返回一个新的 RDD。
- filter(func):保留 RDD 中使函数 func 返回 true 的元素。
- flatMap(func):类似于 map,但每个输入元素可以映射到 0 个或多个输出元素。
- groupByKey():对 (K,V) 对的 RDD 进行分组。
- reduceByKey(func):对 (K,V) 对的 RDD 按键进行聚合。
- join(other):对两个 RDD 进行连接。
- 行动(Actions):
- 行动操作用于触发计算,并返回结果或将结果写入外部存储。
- 常见的行动操作包括:
- collect():在驱动程序中收集 RDD 的所有元素。
- count():返回 RDD 中元素的个数。
- reduce(func):使用函数 func 合并 RDD 的元素。
- take(n):返回 RDD 的前 n 个元素。
- saveAsTextFile(path):将 RDD 保存为文本文件。
优势
- 高效性:RDD 的分布式内存计算显著提高了大规模数据处理的效率。
- 容错性:通过血统(Lineage)信息,RDD 能够在节点失败时自动恢复数据。
- 灵活性:支持多种数据源和数据格式,用户可以灵活地对数据进行处理和转换。
- 易用性:提供了丰富的 API,用户可以使用熟悉的编程语言(如 Scala、Java、Python)进行开发。
应用场景
- 大规模数据处理:适用于需要在分布式环境中处理和分析大规模数据集的任务。
- 实时数据处理:结合 Spark Streaming,RDD 可以用于实时数据流的处理。
- 复杂数据分析:通过组合多种转换和行动操作,RDD 可以实现复杂的数据分析任务。
RDD 是 Spark 的基础抽象,尽管在 Spark 的后续版本中,DataFrame 和 Dataset 提供了更高层次的抽象和优化,但 RDD 仍然是理解 Spark 工作原理的重要组成部分,尤其是在需要精细控制数据分区和处理逻辑时,RDD 仍然是一个强大的工具。
SparkSQL
SparkSQL 是 Spark 提供的分布式 SQL 查询引擎。Spark 基于抽象变成对象 DataFrame 和 Dataset 构建了基于 SQL 的数据处理方式,从而使大幅简化了分布式数据处理。SparkSQL 允许开发人员将数据加载到 Spark 并映射成表,从而通过 SQL 语句来进行数据分析工作。
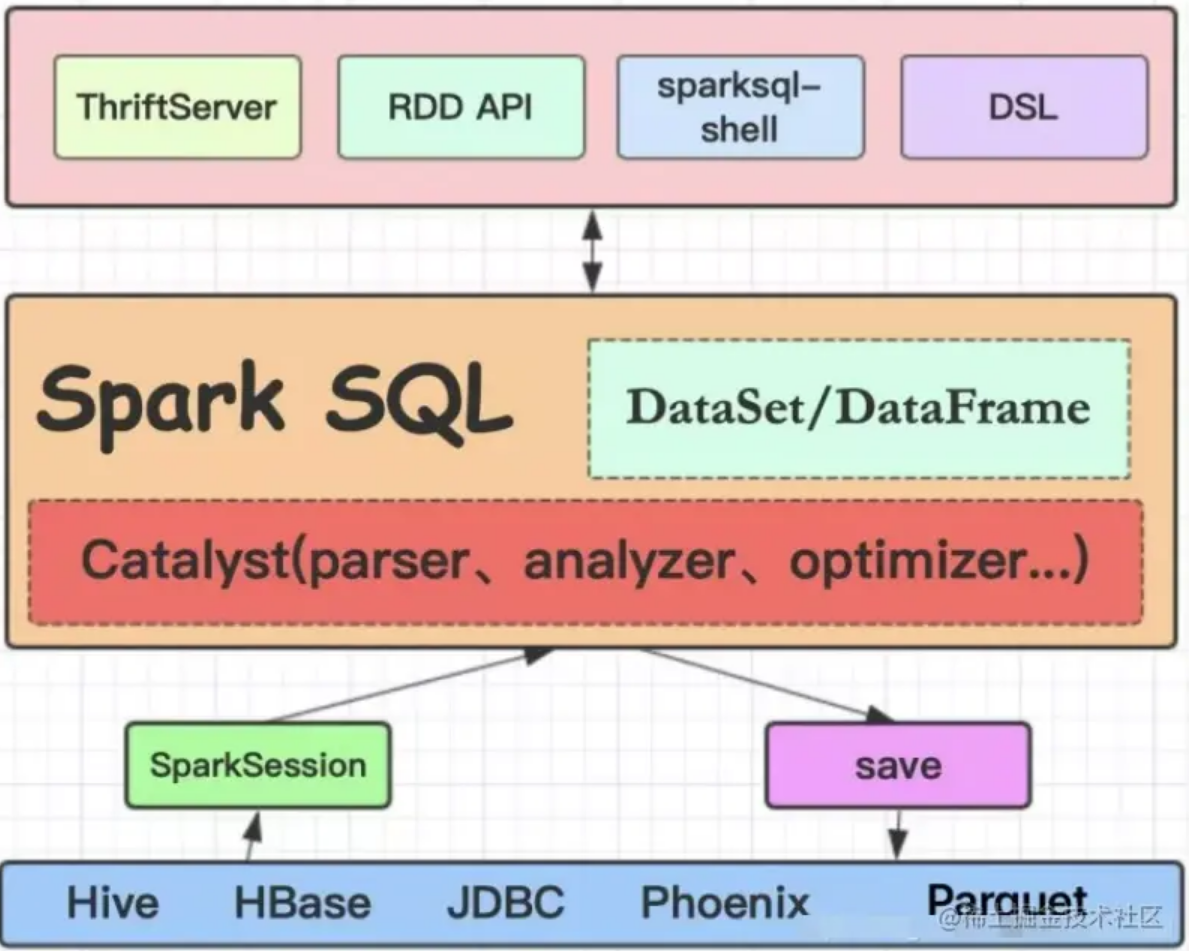
- DataFrame。DataFrame 是 SaprkSQL 的结构化数据的抽象,实现数据表的作用。Dataframe 在 RDD 的基础上增加了数据结构信息 Schema。基于 Schema 信息,Spark 可以根据不同的数据结构,对数据的运算自动进行不同维度的优化。Spark 的 DataFrame 可以通过多种方式构建。支持 RDD、CSV、XML、Hive、Parquet 等数据转换为 DataFrame。构建好 DataFrame 之后,开发人员就可以将 DataFrame 映射为表,并使用 SQL 语句进行数据分析工作。
- Dataset。Dataset 是 Spark 的分布式数据集合,同时具备 RDD 强类型化的有点和 SparkSQL 优化后执行引擎的有点。开发人员可以从 JVM 构建 Dataset,并使用 Map() 等函数进行操作。
主要功能
- 统一的数据访问:
- SparkSQL 支持从多种数据源读取数据,包括 Hive 表、Parquet 文件、JSON 文件、JDBC 数据源等。
- 提供了统一的接口来访问不同类型的数据,简化了数据处理流程。
- 丰富的 API:
- 提供了多种 API,适合不同的编程语言,包括 SQL、DataFrame 和 Dataset API。
- SQL API:允许用户通过标准的 SQL 查询来处理数据。
- DataFrame API:提供了类似于 R 或 Pandas 的数据框架结构,支持丰富的操作和转换。
- Dataset API:提供了类型安全的、面向对象的编程接口,结合了 RDD 的优点和 DataFrame 的优点。
- 与 Hive 的集成:
- 支持直接查询 Hive 表,并能够使用 Hive 的 UDF 和 UDAF。
- 可以无缝访问 Hive 的元数据,支持 HiveQL 查询。
- Catalyst 优化器:
- SparkSQL 内置了 Catalyst 查询优化器,能够自动优化查询计划,提高查询性能。
- Catalyst 通过规则重写和代价模型优化等技术,生成高效的执行计划。
- 支持 ANSI SQL:
- SparkSQL 逐步支持 ANSI SQL 标准,使得用户可以使用熟悉的 SQL 语法进行数据查询和操作。
- 内存计算和缓存:
- 通过将数据集缓存到内存中,SparkSQL 可以显著提高查询性能,特别是在重复查询相同数据时。
架构
- SQLContext 和 SparkSession:
- SQLContext 是 SparkSQL 的入口点,用于执行 SQL 查询。
- 从 Spark 2.0 开始,SparkSession 取代了 SQLContext,成为新的统一入口点,简化了用户接口。
- Catalyst 优化器:
- 负责解析 SQL 查询,生成逻辑执行计划。
- 通过一系列优化规则,将逻辑计划转换为物理执行计划。
- 执行引擎:
- 将物理计划转换为可执行的任务,并在 Spark 集群上运行。
使用场景
- 交互式查询:使用 SparkSQL 可以对大规模数据集进行交互式查询和分析,适合数据分析师和业务用户。
- ETL 处理:SparkSQL 支持复杂的 ETL(提取、转换、加载)任务,能够高效地处理和转换数据。
- 数据整合:通过统一的数据访问接口,SparkSQL 可以将来自不同数据源的数据进行整合和分析。
- 数据仓库:SparkSQL 可以作为大数据环境中的数据仓库解决方案,支持复杂的查询和分析任务。
优势
- 性能:通过内存计算和 Catalyst 优化器,SparkSQL 提供了高性能的数据处理能力。
- 易用性:支持 SQL 查询,使得用户可以使用熟悉的 SQL 语法进行数据操作。
- 灵活性:支持多种数据源和数据格式,能够灵活适应不同的数据处理需求。
- 可扩展性:能够处理大规模数据集,支持在分布式集群上运行。
SparkSQL 的出现大大提升了 Spark 在结构化数据处理方面的能力,使得用户能够更高效地进行数据分析和查询。
SparkStreaming
SparkStreaming 是 Apache Spark 的一个组件,专门用于处理实时数据流。它扩展了 Spark 的核心功能,使得用户能够以一种高效、可扩展和容错的方式处理实时数据。

主要特性
- 微批处理架构:
- SparkStreaming 将实时数据流分成小批次(micro-batches),然后对每个批次的数据进行处理。
- 这种架构结合了批处理的高吞吐量和流处理的低延迟,适合需要近实时处理的应用。
- 与 Spark 的无缝集成:
- SparkStreaming 与 SparkCore、SparkSQL、MLlib 等组件无缝集成,用户可以在流处理应用中使用这些组件的功能。
- 共享 Spark 的相同执行引擎和调度器,简化了开发和部署。
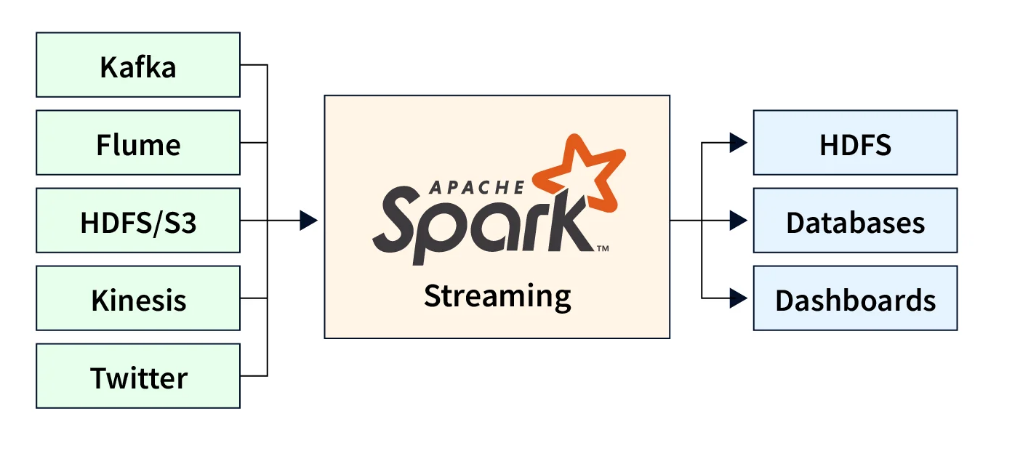
- 丰富的数据源支持:
- 支持从多种数据源接收数据,包括 Apache Kafka、Flume、Kinesis、TCP 套接字、文件系统等。
- 提供简单的 API 来连接和处理这些数据源。
- 容错和精确一次语义:
- 通过将数据存储在持久存储中(如 HDFS),SparkStreaming 提供了容错能力。
- 支持精确一次(exactly-once)处理语义,确保每条数据在流处理应用中仅被处理一次。
- 窗口操作:
- 支持对数据流进行窗口操作,例如时间窗口、滑动窗口等,适合需要在特定时间范围内进行聚合和分析的应用。
- 易于扩展:
- 通过在集群上运行多个 Executor 来处理数据流,SparkStreaming 可以轻松扩展以处理更大规模的数据。
核心概念
- DStream(DiscretizedStream):
- SparkStreaming 的基本抽象,代表一个连续的数据流。
- 由一系列的 RDD(弹性分布式数据集)组成,每个 RDD 处理一个时间间隔内的数据。
- 窗口操作:
- 允许用户在数据流上定义时间窗口,以便在指定时间范围内聚合和分析数据。
- 支持滑动窗口,用户可以定义窗口长度和滑动间隔。
- 转换操作:
- 类似于 RDD 的转换操作,DStream 支持 map、filter、reduceByKey、join 等操作。
工作流程

- 数据接收:
- 从外部数据源(如 Kafka、Flume)接收实时数据流。
- 数据被分成小批次,每个批次形成一个 RDD。
- 数据处理:
- 对每个 RDD 执行定义的转换和操作。
- 可以使用 SparkSQL、MLlib 等库进行复杂的处理和分析。
- 结果输出:
- 处理后的数据可以输出到外部存储系统,如 HDFS、数据库、仪表盘等。
使用场景
- 实时数据分析:处理和分析来自传感器、日志文件、社交媒体等的实时数据流。
- 实时监控和报警:监控系统状态,检测异常并实时触发报警。
- 实时 ETL:对实时数据进行提取、转换和加载,适合需要快速数据更新的应用。
- 实时推荐系统:基于用户行为数据流实时更新推荐结果。
SparkStreaming 提供了一种高效和可扩展的方式来处理实时数据流,适用于各种需要低延迟和高吞吐量的应用场景。其与 Spark 生态系统的无缝集成使得用户可以充分利用 Spark 的强大功能来进行实时数据处理和分析。
MLlib
MLlib(Machine Learning Library)是 Apache Spark 的机器学习库,提供了丰富的机器学习算法和工具,支持大规模数据的机器学习任务。MLlib 的设计目标是提供高效、易用且可扩展的机器学习解决方案,使得用户能够在分布式环境中轻松构建和部署机器学习模型。
主要功能
- 算法支持:
- 分类:逻辑回归、决策树、随机森林、梯度提升树、朴素贝叶斯等。
- 回归:线性回归、决策树回归、随机森林回归、梯度提升树回归等。
- 聚类:K-means、高斯混合模型(GMM)、层次聚类等。
- 协同过滤:ALS(交替最小二乘法)。
- 降维:PCA(主成分分析)、SVD(奇异值分解)、LDA(潜在狄利克雷分配)等。
- 特征提取和转换:TF-IDF、词嵌入、标准化、归一化等。
- 模型选择和评估:交叉验证、网格搜索、AUC、准确率、召回率等。
- 数据处理:
- DataFrame 和 Dataset API:支持使用 DataFrame 和 Dataset 进行数据处理,提供了丰富的操作和转换功能。
- Pipeline:支持构建和管理机器学习流水线,包括数据预处理、特征提取、模型训练和评估等步骤。
- 模型持久化:
- 支持模型的保存和加载,方便模型的复用和部署。
- 分布式计算:
- 利用 Spark 的分布式计算能力,能够处理大规模数据集,支持并行训练和预测。
核心概念
- DataFrame 和 Dataset:
- DataFrame:类似于关系型数据库中的表,提供了丰富的操作和转换功能。
- Dataset:类型安全的 DataFrame,结合了 RDD 的优点和 DataFrame 的优点,适合复杂的数据处理任务。
- Transformer 和 Estimator:
- Transformer:将一个 DataFrame 转换为另一个 DataFrame,例如特征缩放、编码等。
- Estimator:从训练数据中学习模型参数,例如分类器、回归器等。
- Pipeline:
- Pipeline:将多个 Transformer 和 Estimator 组合成一个完整的机器学习流水线,简化了模型的构建和管理。
- PipelineModel:训练好的 Pipeline,可以用于预测和评估。
- Evaluator:
- 用于评估模型的性能,例如二分类评估器、回归评估器等。
工作流程
- 数据准备:
- 从数据源(如 HDFS、数据库、CSV 文件等)加载数据。
- 使用 DataFrame 和 Dataset API 进行数据清洗和预处理。
- 特征工程:
- 使用 Transformer 进行特征提取和转换,例如 TF-IDF、词嵌入、标准化等。
- 模型训练:
- 使用 Estimator 训练模型,例如逻辑回归、随机森林等。
- 可以使用 CrossValidator 或 TrainValidationSplit 进行超参数调优。
- 模型评估:
- 使用 Evaluator 评估模型的性能,例如准确率、AUC、MSE 等。
- 模型持久化:
- 保存训练好的模型,以便后续使用。
- 加载模型进行预测和评估。
优势
- 高效性:利用 Spark 的分布式计算能力,能够高效处理大规模数据集。
- 易用性:提供了丰富的 API 和工具,使得用户可以轻松构建和管理机器学习模型。
- 可扩展性:支持在分布式集群上运行,能够轻松扩展以处理更大规模的数据。
- 集成性:与 Spark 生态系统无缝集成,可以与其他 Spark 组件(如 Spark SQL、Spark Streaming)结合使用。
应用场景
- 推荐系统:基于用户行为数据进行个性化推荐。
- 欺诈检测:检测金融交易中的欺诈行为。
- 情感分析:分析社交媒体上的用户情绪。
- 客户细分:根据用户行为和属性进行客户细分。
- 预测分析:预测销售趋势、股票价格等。
MLlib 的强大功能和灵活性使其成为大数据环境下进行机器学习任务的理想选择,广泛应用于各个行业和领域。
GraphX
GraphX 是 Apache Spark 的图计算库,专为处理大规模图数据而设计。它将图计算与数据并行计算结合在一起,使得用户可以在一个统一的编程模型中进行图计算和数据处理。
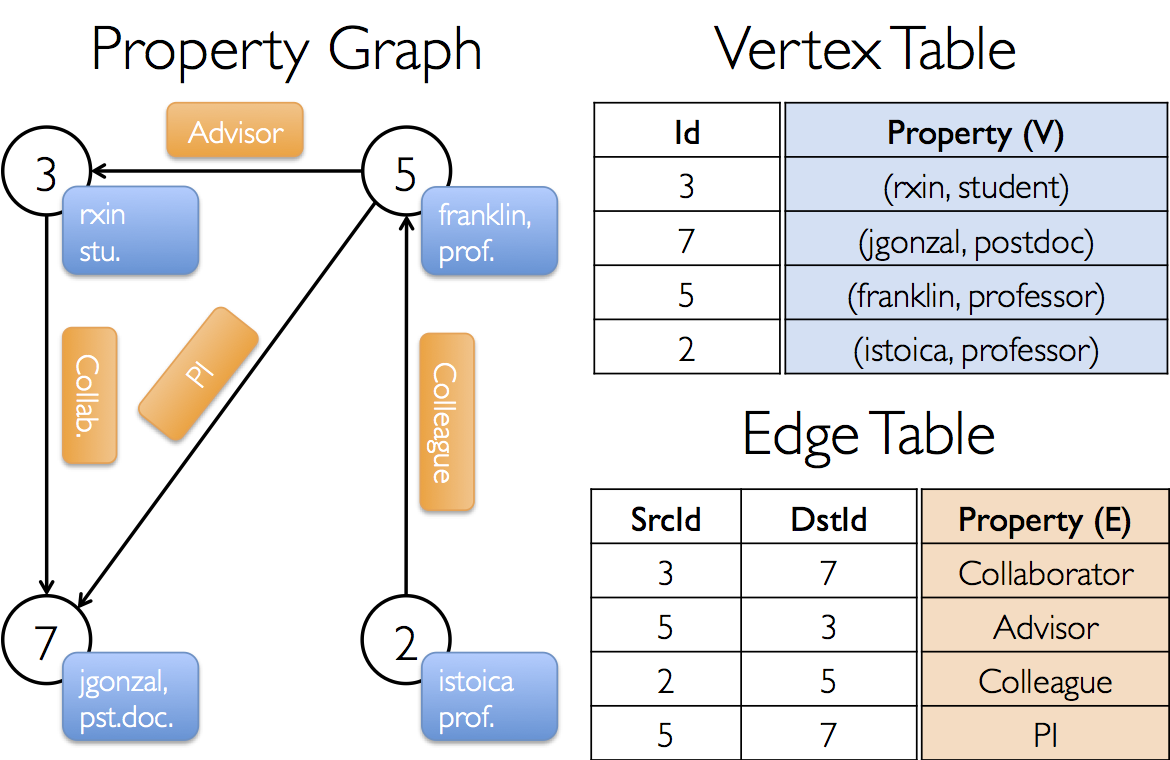
核心概念
- 图(Graph):
- GraphX 中的图由顶点(Vertex)和边(Edge)组成。
- 顶点和边可以携带属性,例如顶点可以表示用户,属性可以是用户信息;边可以表示关系,属性可以是关系强度。
- RDD(弹性分布式数据集):
- GraphX 使用 RDD 来表示图的顶点和边。
- 顶点和边的 RDD 可以与其他 RDD 进行转换和操作,支持复杂的数据处理任务。
- Pregel API:
- Pregel 是 Google 提出的一个大规模图计算模型,GraphX 提供了 Pregel API,用于迭代式图计算。
- Pregel API 允许用户定义消息传递和聚合操作,用于实现复杂的图算法。
- Triplets:
- Triplets 是顶点和边的组合,GraphX 提供了对 Triplets 的操作接口,方便进行复杂的图计算。
主要功能
- 图操作:
- 支持常见的图操作,如子图、连接、反转、聚合等。
- 提供简单的 API 来创建和转换图。
- 图算法:
- GraphX 内置了多种常用的图算法,如 PageRank、ConnectedComponents、TriangleCounting、ShortestPaths 等。
- 用户可以使用这些算法进行复杂的图分析任务。
- 灵活的数据模型:
- GraphX 支持属性图模型,顶点和边可以携带任意类型的属性。
- 提供了灵活的 API 来操作和转换图数据。
- 与 Spark 的集成:
- GraphX 与 Spark 的其他组件(如 Spark SQL、Spark Streaming)无缝集成,用户可以在一个应用中结合使用多种功能。
- 共享 Spark 的执行引擎和调度器,支持在分布式集群上运行。
使用场景
- 社交网络分析:分析社交网络中的用户关系和行为模式,例如影响力分析、社区检测等。
- 推荐系统:基于用户和物品的关系进行推荐,例如使用 CollaborativeFiltering 算法。
- 网络安全:分析网络中的连接和流量模式,检测异常行为和潜在威胁。
- 路径优化:计算最短路径和最优路径,用于物流、交通等领域的路径优化。
- 知识图谱:构建和分析知识图谱,提取有价值的信息和关系。
优势
- 高效性:利用 Spark 的分布式计算能力,GraphX 能够高效处理大规模图数据。
- 易用性:提供了简单易用的 API,用户可以轻松实现复杂的图计算任务。
- 灵活性:支持灵活的数据模型和多种图操作,适应不同的应用需求。
- 可扩展性:能够在分布式集群上运行,支持大规模图数据的处理和分析。
GraphX 的强大功能和灵活性使其成为大规模图计算的理想选择,广泛应用于社交网络分析、推荐系统、网络安全等领域。
SparkR
SparkR 是 Apache Spark 提供的一个 R 语言接口,旨在为 R 用户提供分布式数据处理和分析能力。通过 SparkR,R 用户可以利用 Spark 的分布式计算引擎来处理大规模数据集,同时继续使用熟悉的 R 语法和环境。以下是对 SparkR 的详细介绍:
主要功能
- 分布式数据框(DataFrame):
- SparkR 提供了一个类似于 R 数据框的分布式数据框 API,允许用户在分布式环境中进行数据操作。
- 用户可以使用类似于 R 的语法来进行数据选择、过滤、聚合等操作。
- 与 SparkSQL 集成:
- SparkR 可以与 SparkSQL 无缝集成,允许用户编写 SQL 查询来操作数据框。
- 提供了 sql 函数,用户可以直接在 SparkR 中执行 SQL 查询。
- 机器学习:
- SparkR 包含一个机器学习库,提供了基本的机器学习算法,如线性回归、逻辑回归等。
- 用户可以使用这些算法在分布式数据集上训练模型。
- 数据源支持:
- SparkR 支持从多种数据源读取数据,包括 CSV、JSON、Parquet、Hive 等。
- 提供了简单的接口来加载和保存数据。
- 分布式计算:
- 通过 Spark 的分布式计算能力,SparkR 可以处理比传统 R 更大规模的数据集。
- 用户可以在分布式集群上运行 R 脚本,实现高效的数据处理和分析。
使用场景
- 大规模数据处理:使用 SparkR 可以处理超出单机内存限制的大规模数据集,适合需要处理大量数据的分析任务。
- 数据预处理和特征工程:在机器学习任务中,使用 SparkR 可以高效地进行数据清洗、转换和特征提取。
- 机器学习:使用 SparkR 提供的机器学习算法,可以在大规模数据集上训练和评估模型。
交互式数据分析:通过与 R 的集成,SparkR 提供了交互式的数据分析能力,适合数据科学家进行探索性数据分析。
优势
- 易用性:SparkR 提供了类似于 R 的语法,使得 R 用户可以快速上手,降低了学习成本。
- 高效性:利用 Spark 的分布式计算引擎,SparkR 可以处理大规模数据集,提高了计算效率。
- 灵活性:支持多种数据源和数据格式,能够适应不同的数据处理需求。
- 集成性:与 Spark 的其他组件(如 SparkSQL、MLlib)无缝集成,用户可以在一个应用中结合使用多种功能。
限制和注意事项
- 功能有限:与 R 的本地数据框相比,SparkR 的功能可能稍显有限,特别是在一些复杂的数据操作和统计计算方面。
- 性能:由于 SparkR 是基于 Spark 的分布式计算引擎,某些操作可能会引入额外的开销,导致性能不如本地 R。
- 依赖 Spark 版本:SparkR 的功能和 API 可能会随着 Spark 版本的更新而变化,用户需要注意版本兼容性。
SparkR 为 R 用户提供了一个强大的工具,可以在大数据环境中进行高效的数据处理和分析。它结合了 R 的易用性和 Spark 的分布式计算能力,是数据科学家和分析师在大规模数据集上进行分析的理想选择。
Spark 运行模式
运行模式
Spark 的运行模式主要可以分为三类:Local 模式、集群模式和云服务模式。其中集群模式可以分 Standalone、Yarn 和 Mesos 三种,云服务模式主要是 Kubernetes 模式。
- Local 模式。Local 模式也就是本地模式,将 Spark 应用程序中任务 Task 运行在一个本地 JVM Process 进程中,通常开发测试使用。
- Standalone 模式。搭建采用 Master + Worker 模式的集群,使用 Spark 内置的任务调度模块进行任务调度和资源管理。
- Yarn 模式。搭建采用 Master + Worker 模式的集群,借助 Yarn 进行任务调度和资源管理,Spark 只负责计算,生产环境用的最多。
- Mesos。运行在 Mesos 资源管理器框架之上,由 Mesos 负责资源管理,Spark 负责任务调度和计算。国内很少使用。
- Kubernetes。Spark 2.3 开始支持将 Spark 开发应用运行到 Kubernetes 上。
部署模式
Spark Application 的部署模式分为 Client 和 Cluster 两种。两种模式的主要区别是 Driver 程序运行在哪个主机上,默认是 Client 模式,但是在工作中都采用 Cluster 模式,通过 –deploy-mode cluster 参数指定。
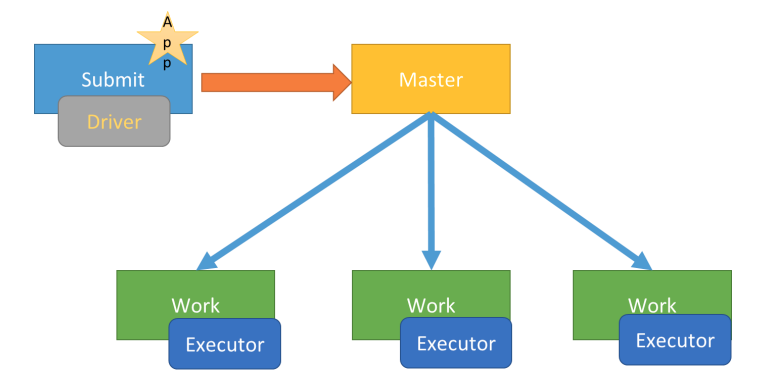
Client 模式
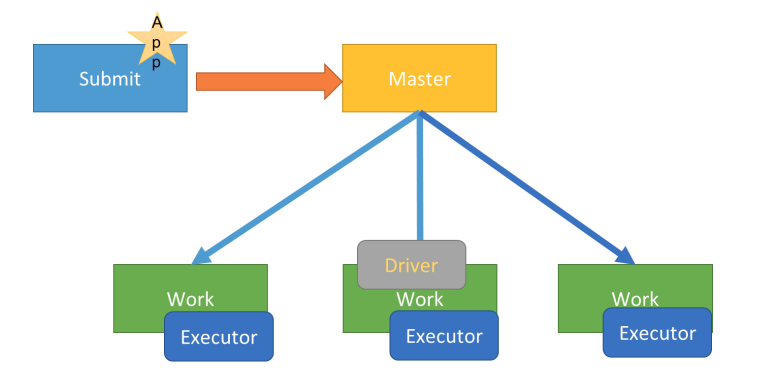
表示应用 Driver 运行在提交应用的 Client 主机上(启动 JVM Process 进程),示意图如下:
Cluster 模式
应用 Driver 运行在集群从节点 Worker 某台机器上,示意图如下: