公司的 Jupyter 环境支持 PySpark。这样就可以非常方便的使用 PySpark 连接到 Hive 查询和使用。由于先前完全没有接触过 Spark,所以整理了一些参考资料。
SparkContext
PySpark 里最核心的模块是 SparkContext(简称 sc), 最重要的数据载体是 RDD。RDD 就像一个 NumPy array 或者一个 Pandas Series,可以视作一个有序的 item 集合。只不过这些 item 并不存在 driver 端的内存里,而是被分割成很多个 partitions,每个 partition 的数据存在集群的 executor 的内存中。
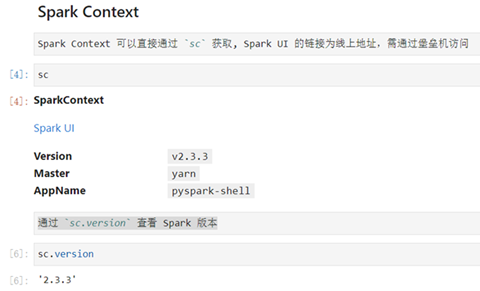
SparkContext 为 Spark 的主要入口点,如把 Spark 集群当作服务端那 Spark Driver 就是客户端,SparkContext 则是客户端的核心;如注释所说 SparkContext 用于连接 Spark 集群、创建 RDD、累加器(accumlator)、广播变量(broadcast variables),相当于应用程序的 main 函数。
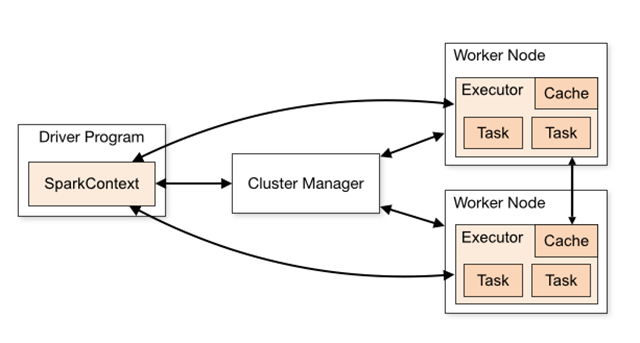
每个 JVM 里只能存在一个处于激活状态的 SparkContext,在创建新的 SparkContext 之前必须调用 stop() 来关闭之前的 SparkContext。
SparkSession
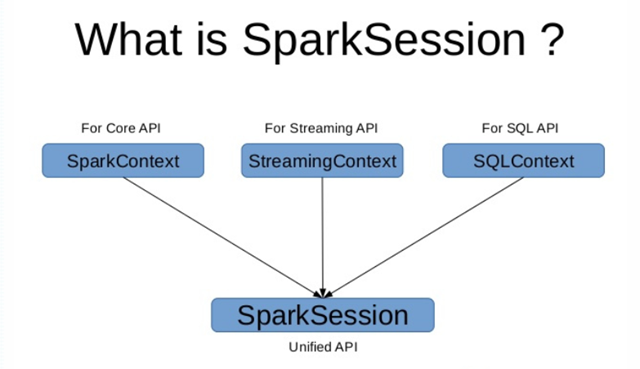
在 Spark 2.0 之前,SparkContext 是所有 Spark 功能的结构,驱动器(driver)通过 SparkContext 连接到集群(通过 resource manager),因为在 2.0 之前,RDD 就是 Spark 的基础。如果需要建立 SparkContext,则需要 SparkConf,通过 Conf 来配置 SparkContext 的内容。
在 Spark 2.0 之后,SparkSession 也是 Spark 的一个入口,为了引入 dataframe 和 dataset 的 API,同时保留了原来 SparkContext 的 functionality,如果想要使用 HIVE,SQL,Streaming 的 API,就需要 SparkSession 作为入口。
SparkSession 除了提供了对 sparkContext 所具有的所有 spark 功能的访问外,还提供了用于处理 DataFrame 和 DataSet 的 API。
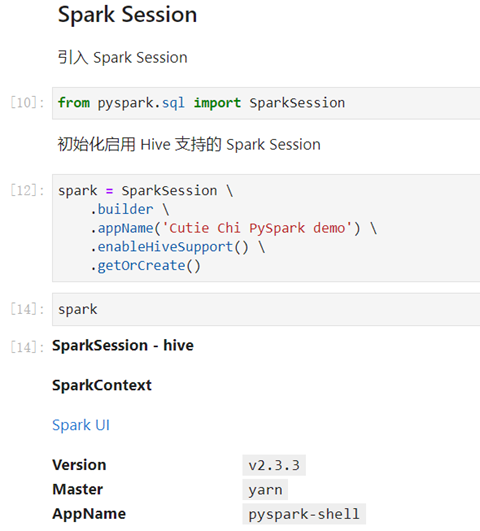
下面是如何创建一个 SparkSession:
val spark = SparkSession
.builder
.appName("Spark test")
.config("spark.some.config.option", "some-value")
.getOrCreate()
以下是 SparkContext 的参数。
- master – 它是连接到的集群的 URL。
- appName – 您的工作名称。
- sparkHome – Spark 安装目录。
- pyFiles – 要发送到集群并添加到 PYTHONPATH 的 .zip 或 .py 文件。
- environment – 工作节点环境变量。
- batchSize – 表示为单个 Java 对象的 Python 对象的数量。设置 1 以禁用批处理,设置 0 以根据对象大小自动选择批处理大小,或设置为 -1 以使用无限批处理大小。
- serializer – RDD 序列化器。
- Conf – L{SparkConf} 的一个对象,用于设置所有 Spark 属性。
- gateway – 使用现有网关和 JVM,否则初始化新 JVM。
- JSC – JavaSparkContext 实例。
- profiler_cls – 用于进行性能分析的一类自定义 Profiler(默认为 profiler.BasicProfiler)。
在上述参数中,主要使用 master 和 appname。
下面是我们如何使用 Hive 支持创建 SparkSession。
val spark = SparkSession
.builder
.appName("Spark Hive test")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
RDD、Dataset 和DataFrame
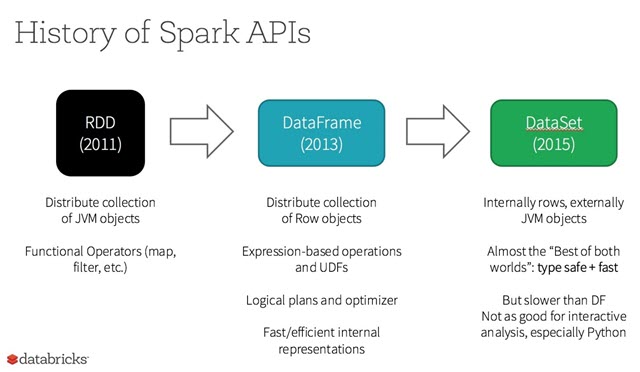
RDD
一个 RDD 就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层 API 进行并行处理。
使用 RDD 的场景:
- 你希望可以对你的数据集进行最基本的转换、处理和控制;
- 你的数据是非结构化的,比如流媒体或者字符流;
- 你想通过函数式编程而不是特定领域内的表达来处理你的数据;
- 你不希望像进行列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性;
- 你并不在意通过 DataFrame 和 Dataset 进行结构化和半结构化数据处理所能获得的一些优化和性能上的好处;
优点:
- 强大,内置很多函数操作,group,map,filter 等,方便处理结构化或非结构化数据
- 面向对象编程,直接存储的 java 对象,类型转化也安全
缺点:
- 由于它基本和 hadoop 一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于 sql 来比非常麻烦
- 默认采用的是 java 序列号方式,序列化结果比较大,而且数据存储在 java 堆内存中,导致 gc 比较频繁
DataFrame
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame 引入了 schema。
RDD 和 DataFrame 比较:
- 相同之处:都是不可变分布式弹性数据集。
- 不同之处:DataFrame 的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。
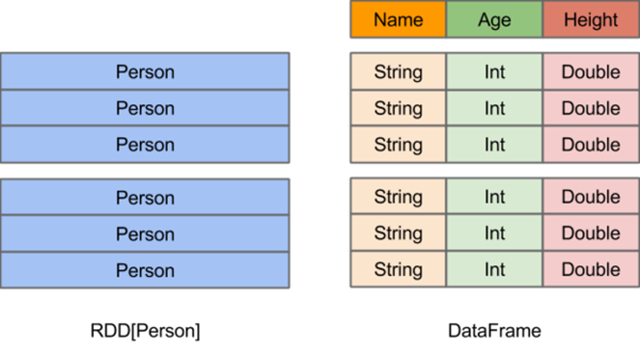
上图直观地体现了 DataFrame 和 RDD 的区别。
- 左侧的 RDD[Person] 虽然以 Person 为类型参数,但 Spark 框架本身不了解 Person 类的内部结构。右侧的 DataFrame 却提供了详细的结构信息,使得 SparkSQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame 多了数据的结构信息,即 schema。
- RDD 是分布式的 Java 对象的集合。DataFrame 是分布式的 Row 对象的集合。
- DataFrame 除了提供了比 RDD 更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如 filter 下推、裁剪等。
优点:
- 结构化数据处理非常方便,支持 Avro, CSV, elasticsearch, and Cassandra 等 kv 数据,也支持 HIVE tables, MySQL 等传统数据表
- 有针对性的优化,由于数据结构元信息 spark 已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了 gc 次数。
- hive 兼容,支持 hql,udf 等
缺点:
- 编译时不能类型转化安全检查,运行时才能确定是否有问题
- 对于对象支持不友好,rdd 内部数据直接以 java 对象存储,dataframe 内存存储的是 row 对象而不能是自定义对象
DataSet
Dataset 是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。每个 Dataset 都有一个称为 DataFrame 的非类型化的视图,这个视图是行的数据集。这种 DataFrame 是 Row 类型的 Dataset,即 Dataset[Row]。
你可以把 DataFrame 当作一些通用对象 Dataset[Row] 的集合的一个别名,而一行就是一个通用的无类型的 JVM 对象。与之形成对比,Dataset 就是一些有明确类型定义的 JVM 对象的集合,通过你在 Scala 中定义的 CaseClass 或者 Java 中的 Class 来指定。
Dataset 是“懒惰”的,只在执行行动操作时触发计算。本质上,数据集表示一个逻辑计划,该计划描述了产生数据所需的计算。当执行行动操作时,Spark 的查询优化程序优化逻辑计划,并生成一个高效的并行和分布式物理计划。
DataSet 和 RDD 主要的区别是:DataSet 是特定域的对象集合;然而 RDD 是任何对象的集合。DataSet 的 API 总是强类型的;而且可以利用这些模式进行优化,然而 RDD 却不行。
优点:
- dataset 整合了 rdd 和 dataframe 的优点,支持结构化和非结构化数据
- 和 rdd 一样,支持自定义对象存储
- 和 dataframe 一样,支持结构化数据的 sql 查询
- 采用堆外内存存储,gc 友好
- 类型转化安全,代码友好
- 官方建议使用 dataset
Spark DataFrame 与 Pandas DataFrame
DataFrame 的起源
最早的 “DataFrame”(开始被称作 “dataframe”),来源于贝尔实验室开发的 S 语言。”dataframe” 在 1990 年就发布了,《S 语言统计模型》第 3 章里详述了它的概念,书里着重强调了 dataframe 的矩阵起源。书中描述 DataFrame 看上去很像矩阵,且支持类似矩阵的操作;同时又很像关系表。
R 语言,作为 S 语言的开源版本,于 2000 年发布了第一个稳定版本,并且实现了 dataframe。pandas 于 2009 年被开发,Python 中于是也有了 DataFrame 的概念。这些 DataFrame 都同宗同源,有着相同的语义和数据模型。

DataFrame 数据模型
DataFrame 的需求来源于把数据看成矩阵和表。但是,矩阵中只包含一种数据类型,未免过于受限;同时,关系表要求数据必须要首先定义 schema。对于 DataFrame 来说,它的列类型可以在运行时推断,并不需要提前知晓,也不要求所有列都是一个类型。因此,DataFrame 可以理解成是关系系统、矩阵、甚至是电子表格程序(典型如 Excel)的合体。
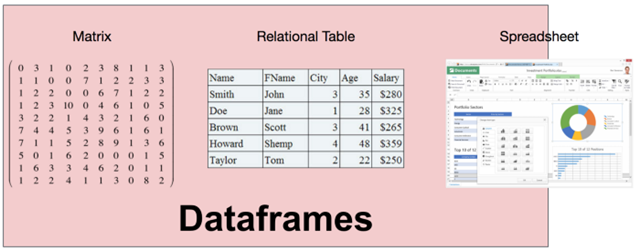
跟关系系统相比,DataFrame 有几个特别有意思的属性,让 DataFrame 因此独一无二。
保证顺序,行列对称
首先,无论在行还是列方向上,DataFrame 都是有顺序的;且行和列都是一等公民,不会区分对待。
拿 pandas 举例,当创建了一个 DataFrame 后,无论行和列上数据都是有顺序的,因此,在行和列上都可以使用位置来选择数据。
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: df = pd.DataFrame(np.random.rand(5, 4))
In [4]: df
Out[4]:
0 1 2 3
0 0.736385 0.271232 0.940270 0.926548
1 0.319533 0.891928 0.471176 0.583895
2 0.440825 0.500724 0.402782 0.109702
3 0.300279 0.483571 0.639299 0.778849
4 0.341113 0.813870 0.054731 0.059262
In [5]: df.iat[2, 2] # 第二行第二列元素
Out[5]: 0.40278182653648853
因为行和列的对称关系,因此聚合函数在两个方向上都可以计算,只需指定 axis 即可。
In [6]: df.sum() # 默认 axis==0,在行方向上做聚合,因此结果是 4 个元素
Out[6]:
0 2.138135
1 2.961325
2 2.508257
3 2.458257
dtype: float64
In [7]: df.sum(axis=1) # axis==1,在列方向上做聚合,因此是 5 个元素
Out[7]:
0 2.874434
1 2.266533
2 1.454032
3 2.201998
4 1.268976
dtype: float64
如果熟悉 numpy(数值计算库,包含多维数组和矩阵的定义),可以看到这个特性非常熟悉,从而可以看出 DataFrame 的矩阵本质。
丰富的 API
DataFrame 的 API 非常丰富,横跨关系(如 filter、join)、线性代数(如 transpose、dot)以及类似电子表格(如 pivot)的操作。
还是以 pandas 为例,一个 DataFrame 可以做转置操作,让行和列对调。
In [8]: df.transpose()
Out[8]:
0 1 2 3 4
0 0.736385 0.319533 0.440825 0.300279 0.341113
1 0.271232 0.891928 0.500724 0.483571 0.813870
2 0.940270 0.471176 0.402782 0.639299 0.054731
3 0.926548 0.583895 0.109702 0.778849 0.059262
直观的语法,适合交互式分析用户可以对DataFrame数据不断进行探索,查询结果可以被后续的结果复用,可以非常方便地用编程的方式组合非常复杂的操作,很适合交互式的分析。
列中允许异构数据
DataFrame的类型系统允许一列中有异构数据的存在,比如,一个int列中允许有string类型数据存在,它可能是脏数据。这点看出DataFrame非常灵活。
In[10]: df2 = df.copy() In[11]: df2.iloc[0,0] = 'a' In[12]: df2 Out[12]: 0 1 2 3 0 a 0.271232 0.940270 0.926548 1 0.319533 0.891928 0.471176 0.583895 2 0.440825 0.500724 0.402782 0.109702 3 0.300279 0.483571 0.639299 0.778849 4 0.341113 0.813870 0.054731 0.059262
数据模型
现在我们可以对什么是真正的DataFrame正式下定义:
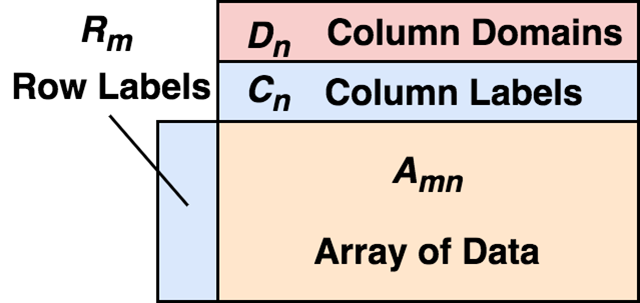
DataFrame由二维混合类型的数组、行标签、列标签、以及类型(types或者domains)组成。在每列上,这个类型是可选的,可以在运行时推断。从行上看,可以把DataFrame看做行标签到行的映射,且行之间保证顺序;从列上看,可以看做列类型到列标签到列的映射,同样,列间同样保证顺序。
行标签和列标签的存在,让选择数据时非常方便。
In[13]: df.index = pd.date_range('2020-4-15', periods=5)
In[14]: df.columns = ['c1', 'c2', 'c3', 'c4']
In[15]: df
Out[15]:
c1 c2 c3 c4
2020-04-15 0.736385 0.271232 0.940270 0.926548
2020-04-16 0.319533 0.891928 0.471176 0.583895
2020-04-17 0.440825 0.500724 0.402782 0.109702
2020-04-18 0.300279 0.483571 0.639299 0.778849
2020-04-19 0.341113 0.813870 0.054731 0.059262
In[16]: df.loc['2020-4-16':'2020-4-18', 'c2':'c3'] #注意这里的切片是闭区间
Out[16]:
c2 c3
2020-04-16 0.891928 0.471176
2020-04-17 0.500724 0.402782
2020-04-18 0.483571 0.639299
这里的index和columns就分别是行和列标签。我们可以很容易选择一段时间(行上选择)和几列(列上选择)数据。当然这些建立在数据是按顺序存储的基础上。
按顺序存储的特性让DataFrame非常适合用来做统计方面的工作。
In[17]: df3 = df.shift(1) #把df的数据整体下移一格,行列索引保持不变
In[18]: df3
Out[18]:
c1 c2 c3 c4
2020-04-15 NaN NaN NaN NaN
2020-04-16 0.736385 0.271232 0.940270 0.926548
2020-04-17 0.319533 0.891928 0.471176 0.583895
2020-04-18 0.440825 0.500724 0.402782 0.109702
2020-04-19 0.300279 0.483571 0.639299 0.778849
In[19]: df - df3 #数据减法会自动按标签对齐,因此这一步可以用来计算环比
Out[19]:
c1 c2 c3 c4
2020-04-15 NaN NaN NaN NaN
2020-04-16 -0.416852 0.620697 -0.469093 -0.342653
2020-04-17 0.121293 -0.391205 -0.068395 -0.474194
2020-04-18 -0.140546 -0.017152 0.236517 0.669148
2020-04-19 0.040834 0.330299 -0.584568 -0.719587
In[21]: (df - df3).bfill() #第一行的空数据按下一行填充
Out[21]:
c1 c2 c3 c4
2020-04-15 -0.416852 0.620697 -0.469093 -0.342653
2020-04-16 -0.416852 0.620697 -0.469093 -0.342653
2020-04-17 0.121293 -0.391205 -0.068395 -0.474194
2020-04-18 -0.140546 -0.017152 0.236517 0.669148
2020-04-19 0.040834 0.330299 -0.584568 -0.719587
从例子看到,正因为数据是按顺序存放的,因此我们可以索引保持不变,整体下移一行,这样,昨天的数据就到了今天的行上,然后拿原数据减去位移后的数据时,因为DataFrame会自动按标签做对齐,因此,对于一个日期,相当于用当天的数据减去了前天的数据,这样就可以做类似于环比的操作。这简直太方便了。试想,对于关系系统来说,恐怕需要想办法找一列作为join的条件,然后再做减法等等。最后,对于空数据,我们还可以填充上一行(ffill)或者下一行的数据(bfill)。想在关系系统里想达到同样效果,想必是需要大费周章的。
Spark的DataFrame
Spark把“DataFrame”的概念带到了大数据的领域。但其实它只是spark.sql的另一种形式。Spark DataFrame只包含了关系表的语义,schema需要确定,数据也并不保证顺序。
Pandas DataFrame与Spark DataFrame的区别
| Pandas | Spark | |
| 工作方式 | 单机 single machine tool,没有并行机制 parallelism
不支持Hadoop,处理大量数据有瓶颈 |
分布式并行计算框架,内建并行机制 parallelism,所有的数据和操作自动并行分布在各个集群结点上。以处理 in-memory 数据的方式处理 distributed 数据。
支持Hadoop,能处理大量数据 |
| 延迟机制 | not lazy-evaluated | lazy-evaluated |
| 内存缓存 | 单机缓存 | persist() or cache()将转换的RDDs保存在内存 |
| DataFrame可变性 | Pandas中DataFrame是可变的 | Spark中RDDs是不可变的,因此DataFrame也是不可变的 |
| 创建 | 从spark_df转换:pandas_df = spark_df.toPandas() | 从pandas_df转换:spark_df = SQLContext.createDataFrame(pandas_df)
另外,createDataFrame支持从list转换spark_df,其中list元素可以为tuple,dict,rdd |
| list,dict,ndarray转换 | 已有的RDDs转换 | |
| CSV数据集读取 | 结构化数据文件读取 | |
| HDF5读取 | JSON数据集读取 | |
| EXCEL读取 | Hive表读取 | |
| 外部数据库读取 | ||
| index索引 | 自动创建 | 没有 index 索引,若需要需要额外创建该列 |
| 行结构 | Series 结构,属于 Pandas DataFrame 结构 | Row 结构,属于 Spark DataFrame 结构 |
| 列结构 | Series 结构,属于 Pandas DataFrame 结构 | Column 结构,属于 Spark DataFrame 结构,如:DataFrame[name: string] |
| 列名称 | 不允许重名 | 允许重名 修改列名采用 alias 方法 |
| 列添加 | df[“xx”] = 0 | df.withColumn(“xx”, 0).show() 会报错
from pyspark.sql import functions df.withColumn(“xx”, functions.lit(0)).show() |
| 列修改 | 原来有 df[“xx”] 列,df[“xx”] = 1 | 原来有 df[“xx”] 列,df.withColumn(“xx”, 1).show() |
| 显示 | df 不输出具体内容,输出具体内容用 show 方法 输出形式:DataFrame[age: bigint, name: string] |
|
| df 输出具体内容 | df.show() 输出具体内容 | |
| 没有树结构输出形式 | 以树的形式打印概要:df.printSchema() | |
| df.collect() | ||
| 排序 | df.sort_index() 按轴进行排序 | |
| df.sort() 在列中按值进行排序 | df.sort() 在列中按值进行排序 | |
| 选择或切片 | df.name 输出具体内容 | df[] 不输出具体内容,输出具体内容用 show 方法
df[“name”] 不输出具体内容,输出具体内容用 show 方法 |
| df[] 输出具体内容,
df[“name”] 输出具体内容 |
df.select() 选择一列或多列
df.select(“name”) 切片 df.select(df[‘name’], df[‘age’] + 1) |
|
| df[0] df.ix[0] |
df.first() | |
| df.head(2) | df.head(2) 或者 df.take(2) | |
| df.tail(2) | ||
| 切片 df.ix[:3] 或者 df.ix[:”xx”] 或者 df[:”xx”] | ||
| df.loc[] 通过标签进行选择 | ||
| df.iloc[] 通过位置进行选择 | ||
| 过滤 | df[df[“age”] > 21] | df.filter(df[‘age’] > 21) 或者 df.where(df[‘age’] > 21) |
| 整合 | df.groupby(“age”)
df.groupby(“A”).avg(“B”) |
df.groupBy(“age”)
df.groupBy(“A”).avg(“B”).show() 应用单个函数 df.groupBy(“A”).agg(functions.avg(“B”), functions.min(“B”), functions.max(“B”)).show() 应用多个函数 |
| 统计 | df.count() 输出每一列的非空行数 | df.count() 输出总行数 |
| df.describe() 描述某些列的 count, mean, std, min, 25%, 50%, 75%, max | df.describe() 描述某些列的 count, mean, stddev, min, max | |
| 合并 | Pandas 下有 concat 方法,支持轴向合并 | |
| Pandas 下有 merge 方法,支持多列合并
同名列自动添加后缀,对应键仅保留一份副本 |
Spark 下有 join 方法即 df.join()
同名列不自动添加后缀,只有键值完全匹配才保留一份副本 |
|
| df.join() 支持多列合并 | ||
| df.append() 支持多行合并 | ||
| 缺失数据处理 | 对缺失数据自动添加 NaNs | 不自动添加 NaNs,且不抛出错误 |
| fillna 函数:df.fillna() | fillna 函数:df.na.fill() | |
| dropna 函数:df.dropna() | dropna 函数:df.na.drop() | |
| SQL 语句 | import sqlite3
pd.read_sql(“SELECT name, age FROM people WHERE age >= 13 AND age <= 19”) |
表格注册:把 DataFrame 结构注册成 SQL 语句使用类型 df.registerTempTable(“people”) 或者 sqlContext.registerDataFrameAsTable(df, “people”) sqlContext.sql(“SELECT name, age FROM people WHERE age >= 13 AND age <= 19”) |
| 功能注册:把函数注册成 SQL 语句使用类型 sqlContext.registerFunction(“stringLengthString”, lambda x: len(x)) sqlContext.sql(“SELECT stringLengthString(‘test’)”) |
||
| 两者互相转换 | pandas_df = spark_df.toPandas() | spark_df = sqlContext.createDataFrame(pandas_df) |
| 函数应用 | df.apply(f) 将 df 的每一列应用函数 f | df.foreach(f) 或者 df.rdd.foreach(f) 将 df 的每一列应用函数 f df.foreachPartition(f) 或者 df.rdd.foreachPartition(f) 将 df 的每一块应用函数 f |
| map-reduce 操作 | map(func, list),reduce(func, list) 返回类型 seq | df.map(func),df.reduce(func) 返回类型 seq RDDs |
| diff 操作 | 有 diff 操作,处理时间序列数据(Pandas 会对比当前行与上一行) | 没有 diff 操作(Spark 的上下行是相互独立,分布式存储的) |
DataFrameReader类与DataFrameWriter类
DataFrameReader类
从外部存储系统中读取数据,返回DataFrame对象,通常使用SparkSession.read来访问,通用语法是先调用format()函数来指定输入数据的格式,后调用load()函数从数据源加载数据,并返回DataFrame对象:
df = spark.read.format('json').load('python/test_support/sql/people.json')
对于不同的格式,DataFrameReader类有细分的函数来加载数据:
df_csv = spark.read.csv('python/test_support/sql/ages.csv')
df_json = spark.read.json('python/test_support/sql/people.json')
df_txt = spark.read.text('python/test_support/sql/text-test.txt')
df_parquet = spark.read.parquet('python/test_support/sql/parquet_partitioned')
# read a table as a DataFrame
df = spark.read.parquet('python/test_support/sql/parquet_partitioned')
df.createOrReplaceTempView('tmpTable')
spark.read.table('tmpTable')
还可以通过jdbc,从JDBC URL中构建DataFrame
jdbc(url, table, column=None, lowerBound=None, upperBound=None, numPartitions=None, predicates=None, properties=None)
DataFrameWriter类
用于把DataFrame写入到外部存储系统中,通过DataFrame.write来访问。
(df.write.format('parquet')
.mode("overwrite")
.saveAsTable('bucketed_table'))
函数注释:
- format(source):指定底层输出的源的格式
- mode(saveMode):当数据或表已经存在时,指定数据存储的行为,保存的模式有:append、overwrite、error和ignore。
- saveAsTable(name, format=None, mode=None, partitionBy=None, **options):把DataFrame存储为表
- save(path=None, format=None, mode=None, partitionBy=None, **options):把DataFrame存储到数据源中
对于不同的格式,DataFrameWriter类有细分的函数来加载数据:
df.write.csv(os.path.join(tempfile.mkdtemp(), 'data')) df.write.json(os.path.join(tempfile.mkdtemp(), 'data')) df.write.parquet(os.path.join(tempfile.mkdtemp(), 'data')) df.write.txt(os.path.join(tempfile.mkdtemp(), 'data')) # wirte data to external database via jdbc df.write.jdbc(url, table, mode=None, properties=None)
把DataFrame内容存储到源中:
df.write.mode("append").save(os.path.join(tempfile.mkdtemp(), 'data'))
把DataFrame的内容存到表中:
df.write.saveAsTable(name='db_name.table_name', format='delta')
PySpark与Hive数据库的交互
# 从SQL查询中创建DataFrame
df = spark.sql("SELECT field1 AS f1, field2 as f2 from table1")
# 直接把dataframe的内容写入到目标hive表
df.write().mode("overwrite").saveAsTable("tableName");
df.select(df.col("col1"), df.col("col2")).write().mode("overwrite").saveAsTable("schemaName.tableName");
df.write().mode(SaveMode.Overwrite).saveAsTable("dbName.tableName");
Spark DataFrame的操作
Spark dataframe是immutable,因此每次返回的都是一个新的dataframe列操作
# add a new column
data = data.withColumn("newCol", df.oldCol + 1)
# replace the old column
data = data.withColumn("oldCol", newCol)
# rename the column
data.withColumnRenamed("oldName", "newName")
# change column datatype
data.withColumn("oldColumn", data.oldColumn.cast("integer"))
条件筛选数据
# filter data by pass a string
temp1 = data.filter("col > 1000")
# filter data by pass a column of boolean value
temp2 = data.filter(data.col > 1000)
选择数据
# select based on column name
temp1 = data.select("col1", "col2")
temp1 = data.select("col1 * 100 as newCol1")
# select based on column object
temp2 = data.select(data.col1, data.col2)
temp2 = data.select(data.col1 + 1.alias(newCol1))
聚合函数
# get the minimum value of a column
data.groupBy().min("col1")
# group by on certain column and do calculation
data.groupBy("col1").max("col2")
# agg function
import pyspark.sql.functions as F
data.groupBy("a", "b").agg(F.stddev("c"))
合并数据表
newData = data1.join(data2, on="col", how="leftouter") newData = data1.join(data2, data1['col1'] == data2['col2'])
参考链接:


