在使用 Python 处理分析数据的时候,用的最多的算是 Pandas 时,由于 Pandas 是个非常强大的工具,涉及到的功能非常多,所以平常使用的时候经常需要查询文档。这里记载了自己常用的一些功能及知识点。
Pandas 简介
Pandas 是 python 的一个数据分析包,最初由 AQR Capital Management 于 2008 年 4 月开发,并于 2009 年底开源出来,目前由专注于 Python 数据包开发的 PyData 开发 team 继续开发和维护,属于 PyData 项目的一部分。Pandas 最初被作为金融数据分析工具而开发出来,因此,pandas 为时间序列分析提供了很好的支持。

Pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据
- 有序和无序(非固定频率)的时间序列数据
- 带行列标签的矩阵数据,包括同构或异构型数据
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记。
Pandas 的优势:
- 处理浮点与非浮点数据里的缺失数据,表示为 NaN
- 大小可变:插入或删除 DataFrame 等多维对象的列
- 自动、显式数据对齐:显式地将对象与一组标签对齐,也可以忽略标签,在 Series、DataFrame 计算时自动与数据对齐
- 强大、灵活的分组(groupby)功能:拆分-应用-组合数据集,聚合、转换数据
- 把 Python 和 NumPy 数据结构里不规则、不同索引的数据轻松地转换为 DataFrame 对象
- 基于智能标签,对大型数据集进行切片、花式索引、子集分解等操作
- 直观地合并(merge)、连接(join)数据集
- 灵活地重塑(reshape)、透视(pivot)数据集
- 轴支持结构化标签:一个刻度支持多个标签
- 成熟的 IO 工具:读取文本文件(CSV 等支持分隔符的文件)、Excel 文件、数据库等来源的数据,利用超快的 HDF5 格式保存/加载数据
- 时间序列:支持日期范围生成、频率转换、移动窗口统计、移动窗口线性回归、日期位移等时间序列功能。
Series 与 DataFrame
Pandas 的主要数据结构是 Series(一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。Pandas 基于 NumPy 开发,可以与其它第三方科学计算支持库完美集成。
- Series 是一种类似与一维数组的对象,它由一组数据以及一组与之相关的数据便签(即索引)组成,仅由一组数据即可产生最简单的 Series。
- DataFrame 是一个表格型数据,含有一组有序的列,每一列可以是不同的类型值。DataFrame 可以看成是由多个 Series 组成的字典,它们共用一个索引。
序列(Series)是一维结构,DataFrame 的每一列都是一个序列(Series),序列结构只有行索引(row index),没有列名称(column name),但是序列有 Name、dtype 和 index 属性,其中 Name 属性是指序列的名称,dtype 属性是指序列值的类型,index 属性是序列的索引。序列存储的数据的数据类型是相同的。

数据框(DataFrame)存储的是二维数据,数据框的结构由 row 和 column 构成,每一行都有一个 row label,每一列都有一个 column label,把 row 和 column 称作 axis,把 row label 和 column label 称作 axis label。通常情况下,column label 是文本类型,是列名称(column name),而 row label 是数值类型,也称作行索引(row index)。
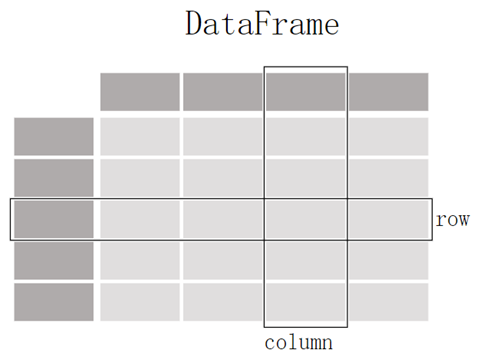
对于这两个数据结构,有两个最基本的概念:轴(Axis)和标签(Label),对于二维数据结构,轴是指行和列,轴标签是指行的索引和列的名称,存储轴标签的数据结构是 Index 结构。每行都有一个索引,通过索引可以定位到该行;每列都有一个列名,通过列名可以定位到该列;通过行索引和列名称,可以唯一定位到一个唯一的数据点(cell)的数据值。
轴标签
存储轴标签的数据结构是 Index,对于数据框,行标签(即行索引)和列名称(即列索引)是由 Index 对象存储的;对于序列,行索引是由 Index 对象存储的。索引对象是不可修改的,类似一个固定大小的数组。
对于索引,还可以通过序号来访问,序号是自动生成的,从 0 开始。
轴标签的最重要的作用是:
- 唯一标识数据,用于定位数据
- 用于数据对齐
- 获取和设置数据集的子集。
数据框和序列对象都有一个属性 index,用于获取行标签,对于数据框,还有一个 columns 属性,用于获取列标签:
>>> df.index RangeIndex(start=0, stop=3, step=1) >>> df.columns Index(['Name', 'Age', 'Sex'], dtype='object')
Pandas 库 axis=0,axis=1 轴的用法
刚学习 Pandas,被 axis=0 或者 axis=’index’,axis=1 或者 axis=’columns’ 给搞蒙了,甚至经常觉得书是不是写错了,有点反直觉。
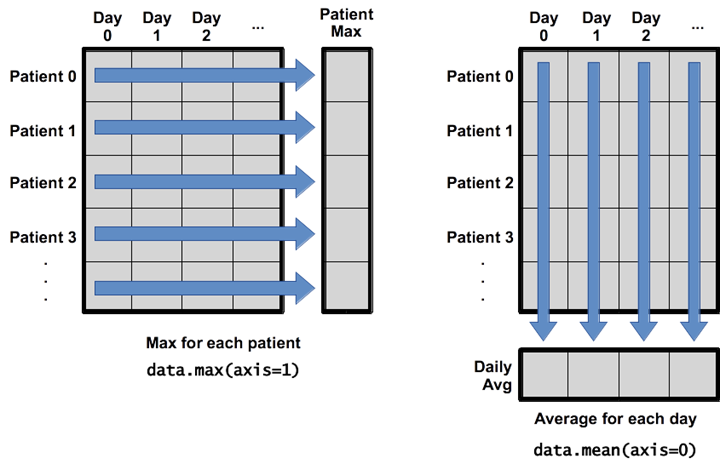
上图中:
- axis=1:指的是沿着行求所有列的最大值,代表了横轴。
- axis=0:就是沿着列求所有行的平均值,代表了纵轴。
创建 Series 和 DataFrame 对象
在 Python 中,使用 Pandas 库可以很方便地从列表、字典和数组创建 Series 和 DataFrame。以下是一些常见的创建方法:
从列表创建 Series
import pandas as pd # 创建一个列表 data_list = [10, 20, 30, 40] # 从列表创建 Series series_from_list = pd.Series(data_list) print(series_from_list)
从字典创建 Series
import pandas as pd
# 创建一个字典
data_dict = {'a': 10, 'b': 20, 'c': 30}
# 从字典创建 Series
series_from_dict = pd.Series(data_dict)
print(series_from_dict)
从数组创建 Series
import pandas as pd import numpy as np # 创建一个数组 data_array = np.array([10, 20, 30, 40]) # 从数组创建 Series series_from_array = pd.Series(data_array) print(series_from_array)
从列表创建 DataFrame
列表中的元素为行数据
import pandas as pd # 创建一个列表 data_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # 从列表创建 DataFrame df_from_list = pd.DataFrame(data_list, columns=['A', 'B', 'C']) print(df_from_list)
从字典创建 DataFrame
字典的键为列名,值为列数据
import pandas as pd
# 创建一个字典
data_dict = {'A': [1, 4, 7], 'B': [2, 5, 8], 'C': [3, 6, 9]}
# 从字典创建 DataFrame
df_from_dict = pd.DataFrame(data_dict)
print(df_from_dict)
从数组创建 DataFrame
import pandas as pd import numpy as np # 创建一个数组 data_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 从数组创建 DataFrame df_from_array = pd.DataFrame(data_array, columns=['A', 'B', 'C']) print(df_from_array)
数据导入与导出
- 读取数据
- CSV 文件:read_csv()
- Excel 文件:read_excel()
- JSON 文件:read_json()
- SQL 数据库:read_sql()
- 保存数据
- 保存为 CSV:to_csv()
- 保存为 Excel:to_excel()
- 保存为 JSON:to_json()
详细内容:
- Pandas 读取与导出 Excel、CSV 文件–标点符(biaodianfu.com)
- Pandas+SQLAlchemy 与数据库交互–标点符(biaodianfu.com)
- Pandas 中 DataFrame 的合并与连接–标点符(biaodianfu.com)
Pandas 的行、列、索引操作
Pandas 行、列、索引常规操作
print(df.columns) # 输出列名
df.columns = ['a', 'b', 'c'] # 重命名列名
df = df[['a', 'b', 'c']] # 只选取想要的列
df = df.transpose() # 行列转换
df = df.T # 行列转换的简写方式
df = df.set_index('c') # 以 c 列作为索引
df.reset_index() # 重新变为默认的数值索引
Pandas 中的 loc 和 iloc
loc 与 iloc 的区别:
- .loc 主要是基于标签(label)的,包括行标签(index)和列标签(columns),即行名称和列名称,可以使用 loc[index_name, col_name]
- .iloc 是基于位置的索引,利用元素在各个轴上的索引序号进行选择
示例代码:
# .loc 的用法 df.loc[3] # 选择 index 为 3 的一行,这里的’3’是 index 的名称,而不是序号 df.loc['a'] # 获取 index 是 a 的某一行 df.loc[['a', 'b', 'c']] # 获取 index 为 a,b,c 的行 df.loc['c':'h'] # 获取 c 到 h 行,包含 c 和 h(左闭右闭) df.loc[df['A'] > 5] # 筛选出所有 A 列 >5 的行 df.loc[df['A'] > 5, ['C', 'D']] # 筛选出所有 A 列 >5 的行的 C 和 D 列 # .iloc 的用法 df.iloc[3] # 选择第四行,下标从 0 开始 df.iloc[[1, 3, 5]] # 选择第 2、4、6 行 df.iloc[0:3] # 选择 1~3 行,和 loc 不同的是这里是左闭右开 df.iloc[0:3, 1:3] # 选择 1~3 行, 2~3 列 df.iloc[df['A'] > 5] # 同上
常用操作:
X = df.iloc[:, :-1] y = df.iloc[:, -1]
Pandas条件选择
Pandas 的条件选择是一种强大的功能,允许用户基于条件筛选数据。这对于数据分析和数据清洗非常有用。以下是一些关于 Pandas 条件选择的详细讲解:
基本条件选择
假设我们有以下 DataFrame:
import pandas as pd
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, 27, 22, 32],
'Score': [85, 62, 78, 90]
}
df = pd.DataFrame(data)
单条件选择
选择年龄大于 25 的行
age_filter = df['Age'] > 25 result = df[age_filter] print(result)
选择得分小于 80 的行
score_filter = df['Score'] < 80 result = df[score_filter] print(result)
多条件选择
选择年龄大于 25 且得分大于 80 的行
combined_filter = (df['Age'] > 25) & (df['Score'] > 80) result = df[combined_filter] print(result)
选择年龄小于 30 或得分大于 85 的行
combined_filter = (df['Age'] < 30) | (df['Score'] > 85) result = df[combined_filter] print(result)
使用 loc 和iloc
使用 loc 进行条件选择。loc 可以基于标签选择行和列,适合于条件选择。
result = df.loc[df['Age'] > 25, ['Name', 'Score']] print(result)
使用 iloc 进行条件选择。iloc 是基于位置的选择,通常不用于条件选择,但可以与 numpy 的 where 函数结合使用。
使用 query 方法
Pandas 提供了 query 方法,可以使用表达式进行筛选。
选择年龄大于 25 的行
result = df.query('Age > 25')
print(result)
选择年龄大于 25 且得分大于 80 的行
result = df.query('Age > 25 and Score > 80')
print(result)
处理缺失值
在条件选择中,处理缺失值是一个重要的部分。
使用 isnull 和 notnull
# 选择 Age 列中为空的行 result = df[df['Age'].isnull()] # 选择 Age 列中不为空的行 result = df[df['Age'].notnull()]
通过这些方法,Pandas 提供了灵活且强大的工具来进行条件选择和数据筛选,帮助用户高效地分析和处理数据。
Pandas 与时间序列
依托 NumPy 的 datetime64、timedelta64 等数据类型,pandas 可以处理各种时间序列数据,还能调用 scikits.timeseries 等 Python 支持库的时间序列功能。
# 解析时间格式字符串、np.datetime64、datetime.datetime 等多种时间序列数据。
dti = pd.to_datetime(['1/1/2018', np.datetime64('2018-01-01'), datetime.datetime(2018, 1, 1)])
# 生成 DatetimeIndex、TimedeltaIndex、PeriodIndex 等定频日期与时间段序列。
dti = pd.date_range('2018-01-01', periods=3, freq='H')
# 处理、转换带时区的日期时间数据。
dti = dti.tz_localize('UTC')
dti.tz_convert('US/Pacific')
# 按指定频率重采样,并转换为时间序列。
idx = pd.date_range('2018-01-01', periods=5, freq='H')
ts = pd.Series(range(len(idx)), index=idx)
ts.resample('2H').mean()
# 用绝对或相对时间差计算日期与时间。
friday = pd.Timestamp('2018-01-05')
print(friday.day_name())
saturday = friday + pd.Timedelta('1 day')
print(saturday.day_name())
monday = friday + pd.offsets.BDay() # 添加 1 个工作日,从星期五跳到星期一
print(monday.day_name())
针对时间索引数据的切片:
ts['2021'] # 查询整个 2021 年的 ts['2021-6'] # 查询 2021 年 6 月的 ts['2021-6':'2021-10'] # 6 月到 10 月的 dft['2013-1':'2013-2-28 00:00:00'] # 精确时间 dft['2013-1-15':'2013-1-15 12:30:00'] dft.loc['2013-01-05']
更多参考:Pandas 时间序列数据处理与分析–标点符(biaodianfu.com)
Pandas 的数据类型
Pandas 中主要的数据类型有:
- float
- int
- bool
- datetime64[ns]
- datetime64[ns, tz]
- timedelta64[ns]
- timedelta[ns]
- category
- object
默认的数据类型是 int64 和 float64,文字类型是 object。
和 Python、NumPy 类型的对应关系:
| Pandas 类型 | Python 类型 | NumPy 类型 | 使用场景 |
| object | str or mixed | string_, unicode_, mixed types | 文本或者混合数字 |
| int64 | int | int_, int8, int16, int32, int64, uint8, uint16, uint32, uint64 | 整型数字 |
| float64 | float | float_, float16, float32, float64 | 浮点数字 |
| bool | bool | bool_ | True/False 布尔型 |
| datetime64[ns] | nan | datetime64[ns] | 日期时间 |
| timedelta[ns] | nan | nan | 两个时间之间的距离,时间差 |
| category | nan | nan | 有限文本值,枚举 |
常用方法:
df.dtypes # 各字段的数据类型 df['a'].dtype # 某个字段的类型 df['a'].astype(float) # 转换类型
DataFrame.astype()
DataFrame.astype() 是 Pandas 中用于转换 DataFrame 列的数据类型的方法。数据类型转换在数据处理和分析中非常常见,特别是在需要确保数据类型一致性或者准备数据进行机器学习时。astype() 方法允许你将一个或多个列转换为指定的数据类型。
import pandas as pd
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3],
'B': ['4', '5', '6'],
'C': [7.1, 8.2, 9.3]
}
df = pd.DataFrame(data)
转换单个列的数据类型
假设我们想将列 B 的数据类型从字符串转换为整数:
df['B'] = df['B'].astype(int) print(df)
转换多个列的数据类型
如果你需要同时转换多个列的数据类型,可以传递一个字典给 astype(),字典的键为列名,值为目标数据类型:
df = df.astype({'A': float, 'B': int})
print(df)
常见的数据类型
Pandas 支持多种数据类型,常见的包括:
- int: 整数类型
- float: 浮点数类型
- str 或 object: 字符串类型
- bool: 布尔类型
- category: 分类数据类型(用于节省内存)
- datetime64: 日期时间类型
使用场景
- 确保数据类型一致性:在数据分析和处理过程中,确保列的数据类型一致性非常重要。例如,在进行数学运算时,数值列应为 int 或 float。
- 数据格式化:将数据转换为适当的格式以便于进一步分析。例如,将日期列转换为 datetime64 以便于日期操作。
- 内存优化:将数据类型转换为更节省内存的类型,例如将整数转换为更小的整数类型或使用 category 类型。
错误处理
在进行数据类型转换时,可能会遇到数据不符合目标类型的情况。这时可以使用 errors 参数来处理:
- errors='raise'(默认):如果转换失败,则引发错误。
- errors='ignore':忽略错误,保持原始数据类型。
- errors='coerce':将无法转换的值设置为 NaN。
# 尝试将不符合的字符串转换为整数 df['B'] = df['B'].astype(int, errors='coerce') print(df)
Pandas 用于探索数据
查看数据基本情况
查看、检查数据:
- head(n):查看 DataFrame 对象的前 n 行
- tail(n):查看 DataFrame 对象的最后 n 行
- shape():查看行数和列数
- info():查看索引、数据类型和内存信息
- describe():查看数值型列的汇总统计
- describe(include=[np.number]) # 指定数字类型
- describe(include=[np.object]) # 指定 object 类型
- describe(include=['category']) # 指定列名
- value_counts(dropna=False):查看 Series 对象的唯一值和计数
- apply(pd.Series.value_counts):查看 DataFrame 对象中每一列的唯一值和计数
- unique():返回唯一值
- corr():返回列与列之间的相关性
DataFrame.corr(method='pearson', min_periods=1)
参数说明:
- method:可选值为 {'pearson', 'kendall', 'spearman'}
- min_periods:样本最少的数据量
异常数据的处理
检查空值
Pandas 中存在两个检查空值的方法,pandas.DataFrame.isna() 和 pandas.DataFrame.isnull(),两个方法使用起来完全一致。
使用示例:
- isna().sum()
值的替换
示例:
- replace('-', 'np.nan'):用 Null 值替换 '-'
- replace(1, 'one'):用 'one' 代替所有等于 1 的值
- replace([1, 3], ['one', 'three']):用 'one' 代替 1,用 'three' 代替 3
删除空值
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:它决定轴是行还是列。
- 如果它是 0 或 'index',那么它将删除包含缺失值的行。
- 如果它是 1 或 'column',那么它将删除包含缺失值的列。默认情况下,它的值是 0
- how:这个参数决定函数如何删除行或列。它只接受两个字符串,可以是 all 或 any。默认情况下,它被设置为 any。
- any - 如果行或列中有任何空值,就会删除它。
- all - 如果行或列中缺少所有值,则放弃该行或列
- thresh:它是一个整数,指定了防止行或列丢失的非缺失值的最少数量
- subset:它是一个数组,其中有行或列的名称,用于指定删除程序
- inplace:它是一个布尔值,如果设置为 True,将就地改变调用者 DataFrame。默认情况下,它的值是 False
示例:
- dropna():删除所有包含空值的行
- dropna(axis=1):删除所有包含空值的列
- dropna(axis=1, thresh=n):删除所有小于 n 个非空值的行
填充空值
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
参数说明:
- value: 用于填充空值的值
- method: {'backfill', 'bfill', 'pad', 'ffill', None}, 默认 None,pad/ffill 表示向后填充空值,backfill/bfill 表示向前填充空值
- axis: 填充缺失值所沿的轴
- inplace: boolean, 默认为 False。若为 True,在原地填满
- limit: int, 默认为 None,如果指定了方法,则这是连续的 NaN 值的前向/后向填充的最大数量
- downcast: dict, 默认 None,字典中的项为类型向下转换规则。
示例:
- fillna(x):用 x 替换 DataFrame 对象中所有的空值
- fillna(s.mean()):用均值填充
- fillna(s.median()):用中位数填充
去除重复
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
参数说明:
- subset:输入要进行去重的列名,默认为 None
- keep:可选参数有三个:'first'、'last'、False,默认值 'first'。其中,
- first 表示:保留第一次出现的重复行,删除后面的重复行。
last表示:删除重复项,保留最后一次出现。
- False表示:删除所有重复项。
示例:
df.drop_duplicates(subset=['A','B'], keep='first', inplace=True)
数据的汇总统计
Pandas中常用的统计函数:
- .count() #非空元素计算
- .size() #包含NaN的计数
- .min() #最小值
- .max() #最大值
- .idxmin() #最小值的位置,类似于R中的min函数
- .idxmax() #最大值的位置,类似于R中的max函数
- .quantile(0.1) #10%分位数
- .sum() #求和
- .mean() #均值
- .median() #中位数
- .mode() #众数
- .var() #方差
- .std() #标准差
- .mad() #平均绝对偏差
- .skew() #偏度
- .kurt() #峰度
当我们想查看DataFrame每列数据的时候,可以自定义一个函数方便的将统计指标汇总在一起(效果类似df.describe()):
import pandas as pd
import numpy as np
def status(x):
return pd.Series(
[x.count(), x.min(), x.idxmin(), x.quantile(.25), x.median(), x.quantile(.75), x.mean(), x.max(), x.idxmax(),
x.mad(), x.var(), x.std(), x.skew(), x.kurt()],
index=['总数','最小值','最小值位置','25%分位数','中位数','75%分位数','均值','最大值','最大值位数','平均绝对偏差','方差','标准差','偏度',
'峰度'])
if __name__ == "__main__":
#df = pd.DataFrame(status(d1))
df = pd.DataFrame(np.array([d1,d2,d3]).T, columns=['x1','x2','x3'])
df.apply(status)
Pandas中的分组groupby()
最简单的方式,指定要进行分组的列和统计函数:
df.groupby(by=['col1','col2']).size()
通常统计出来的值没有列名,通过此方法可指定列名:
df.groupby(by=['col1','col2']).size().reset_index(name='counts')
groupby结合agg进行聚合:
df[['col1','col2','col3','col4']].groupby(['col1','col2']).agg(['mean','count'])
以上代码与以下SQL类似:
SELECT col1, col2, avg(col1), count(col2) FROM df GROUP BY col1, col2
添加列名:
key1 = df.groupby(["key1"], as_index=False)["data1"].agg({"col_name":"count"})
DataFrame.sort_index()
DataFrame.sort_index()是Pandas中用于按索引排序的方法。这个方法非常有用,尤其是在处理时间序列数据或需要按特定顺序排列数据时。
基本语法
DataFrame.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, ignore_index=False, key=None)
参数详解
- axis:指定排序的轴。默认值为0(按行索引排序),1表示按列索引排序。
- 0或 'index':按行索引排序。
- 1或 'columns':按列索引排序。
- level:如果索引是多级索引,指定按哪一级进行排序。可以是整数或级别名称。默认值为None,表示按所有级别排序。
- ascending:布尔值,指定排序顺序。默认值为True(升序),False表示降序。
- inplace:布尔值,指定是否在原DataFrame上进行排序。默认值为False,表示返回一个新的排序后的DataFrame。
- kind:指定排序算法。可选值包括:
- 'quicksort':快速排序(默认)。
- 'mergesort':归并排序。
- 'heapsort':堆排序。
- 'stable':稳定排序(使用归并排序)。
- na_position:指定NaN值的位置。可选值包括:
- 'last':将NaN值放在最后(默认)。
- 'first':将NaN值放在最前。
- sort_remaining:仅在多级索引中使用。指定是否对剩余级别进行排序。默认值为True。
- ignore_index:布尔值,指定是否忽略原始索引,生成新的默认整数索引。默认值为False。
- key:可选的函数,用于在排序之前对索引值进行转换。默认值为None。
按行索引排序
import pandas as pd
# 创建一个示例DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
}
df = pd.DataFrame(data, index=[2, 1, 3])
# 按行索引升序排序
df_sorted = df.sort_index()
print(df_sorted)
# 按行索引降序排序
df_sorted_desc = df.sort_index(ascending=False)
print(df_sorted_desc)
按列索引排序
#按列索引升序排序 df_sorted_columns = df.sort_index(axis=1) print(df_sorted_columns) #按列索引降序排序 df_sorted_columns_desc = df.sort_index(axis=1, ascending=False) print(df_sorted_columns_desc)
多级索引排序
#创建一个多级索引的DataFrame
index = pd.MultiIndex.from_tuples([(2, 'a'), (1, 'b'), (3, 'c')])
df_multi = pd.DataFrame({'A': [1, 2, 3]}, index=index)
#按第一级索引排序
df_sorted_level_0 = df_multi.sort_index(level=0)
print(df_sorted_level_0)
#按第二级索引排序
df_sorted_level_1 = df_multi.sort_index(level=1)
print(df_sorted_level_1)
忽略原始索引
#按行索引排序并忽略原始索引 df_sorted_ignore_index = df.sort_index(ignore_index=True) print(df_sorted_ignore_index)
自定义排序键
#定义一个自定义排序键函数
def custom_key(x):
return -x
#使用自定义排序键进行排序
df_sorted_custom_key = df.sort_index(key=custom_key)
print(df_sorted_custom_key)
DataFrame.sort_values()
DataFrame.sort_values()是Pandas中用于根据一个或多个列的值对DataFrame进行排序的方法。这在数据分析中非常有用,尤其是当你需要按照特定的列对数据进行排序以便更好地观察或处理数据时。
基本语法
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
参数详解
- by:指定要排序的列名称或列名称的列表。这是一个必需的参数。
- axis:指定排序的轴。默认值为0(按行排序)。
- 0或 'index':按行排序。
- 1或 'columns':按列排序(较少使用)。
- ascending:布尔值或布尔值列表,指定排序顺序。默认值为True(升序)。如果传递列表,则其长度应与by参数相同。
- inplace:布尔值,指定是否在原DataFrame上进行排序。默认值为False,表示返回一个新的排序后的DataFrame。
- kind:指定排序算法。可选值包括:
- 'quicksort':快速排序(默认)。
- 'mergesort':归并排序。
- 'heapsort':堆排序。
- 'stable':稳定排序(使用归并排序)。
- na_position:指定NaN值的位置。可选值包括:
- 'last':将NaN值放在最后(默认)。
- 'first':将NaN值放在最前。
- ignore_index:布尔值,指定是否忽略原始索引,生成新的默认整数索引。默认值为False。
- key:可选的函数,用于在排序之前对列的值进行转换。默认值为None。
单列排序
import pandas as pd
#创建一个示例DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, 27, 22, 32],
'Score': [85, 62, 78, 90]
}
df = pd.DataFrame(data)
#按'Age'列升序排序
df_sorted = df.sort_values(by='Age')
print(df_sorted)
#按'Age'列降序排序
df_sorted_desc = df.sort_values(by='Age', ascending=False)
print(df_sorted_desc)
多列排序
#按'Age'和'Score'列排序 df_sorted_multi = df.sort_values(by=['Age', 'Score']) print(df_sorted_multi) #按'Age'升序和'Score'降序排序 df_sorted_multi_mixed = df.sort_values(by=['Age', 'Score'], ascending=[True, False]) print(df_sorted_multi_mixed)
处理NaN值
#创建一个包含NaN值的DataFrame
data_with_nan = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [24, None, 22, 32],
'Score': [85, 62, None, 90]
}
df_nan = pd.DataFrame(data_with_nan)
#按'Age'列排序,将NaN放在最前面
df_sorted_nan_first = df_nan.sort_values(by='Age', na_position='first')
print(df_sorted_nan_first)
忽略原始索引
#按'Score'列排序并忽略原始索引 df_sorted_ignore_index = df.sort_values(by='Score', ignore_index=True) print(df_sorted_ignore_index)
自定义排序键
#定义一个自定义排序键函数
def custom_key(series):
return series % 10
#使用自定义排序键进行排序
df_sorted_custom_key = df.sort_values(by='Score', key=custom_key)
print(df_sorted_custom_key)
透视表pd.pivot_table()
pd.pivot_table()是Pandas提供的一个强大函数,用于创建数据透视表。数据透视表是一种用于汇总和重新排列数据的工具,常用于数据分析和报告生成。它允许你根据一个或多个键对数据进行分组,并对这些分组应用聚合函数,从而提供对数据的多维分析视角。
基本语法
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
参数详解
- data:DataFrame对象,表示要进行透视操作的数据。
- values:要聚合的列名称或列名称列表。默认值为None,表示使用所有数值列。
- index:用于分组的列名称或列名称列表。结果DataFrame的行索引将基于这些列。
- columns:用于创建新列的列名称或列名称列表。结果DataFrame的列索引将基于这些列。
- aggfunc:用于聚合的函数或函数列表。默认值为'mean'。可以是NumPy函数、用户自定义函数或多个函数的列表(如['mean','sum'])。
- fill_value:用于填充缺失值的标量值。默认值为None。
- margins:布尔值,默认值为False。如果为True,则在行和列的末尾添加汇总值。
- margins_name:用于汇总行/列的名称。默认值为'All'。
- dropna:布尔值,默认值为True。如果为True,则删除所有包含NA的列。
- observed:布尔值,默认值为False。对于分类数据,是否只展示出现的分类组合。
- sort:布尔值,默认值为True。是否对结果DataFrame的行和列进行排序。
创建一个简单的数据透视表
假设我们有以下DataFrame:
import pandas as pd
data = {
'Date': ['2023-01-01', '2023-01-02', '2023-01-01', '2023-01-02'],
'Category': ['A', 'A', 'B', 'B'],
'Value': [10, 20, 30, 40]
}
df = pd.DataFrame(data)
# 创建数据透视表
pivot_table = pd.pivot_table(df, values='Value', index='Date', columns='Category', aggfunc='sum')
print(pivot_table)
使用多个聚合函数
你可以对数据应用多个聚合函数:
# 使用多个聚合函数 pivot_table_multi_agg = pd.pivot_table(df, values='Value', index='Date', columns='Category', aggfunc=['sum', 'mean']) print(pivot_table_multi_agg)
填充缺失值
在某些情况下,数据透视表中可能会有缺失值。可以使用fill_value参数来填充这些缺失值:
# 填充缺失值 pivot_table_fill = pd.pivot_table(df, values='Value', index='Date', columns='Category', aggfunc='sum', fill_value=0) print(pivot_table_fill)
添加汇总行/列
可以使用margins=True添加汇总行和列:
# 添加汇总行和列 pivot_table_margins = pd.pivot_table(df, values='Value', index='Date', columns='Category', aggfunc='sum', margins=True) print(pivot_table_margins)
注意事项
- 性能:对于大数据集,pivot_table()可能会比较慢,尤其是在应用多个复杂的聚合函数时。
- 数据类型:确保数据中用于聚合的列是数值类型,否则可能会导致聚合操作失败。
- 灵活性:pivot_table()提供了非常灵活的多维数据分析功能,可以根据需要自定义行、列和聚合函数。
Pandas Dataframe的遍历
在Pandas中,遍历DataFrame是一个常见的操作,尤其是在需要对每个行或列进行处理时。虽然Pandas提供了多种方法来遍历DataFrame,但需要注意的是,遍历DataFrame通常比使用矢量化操作要慢,因此在可能的情况下应优先考虑使用矢量化操作。以下是几种遍历DataFrame的方法:
使用 iterrows()
iterrows()是Pandas中用于逐行遍历DataFrame的方法。它返回每行的索引和数据(作为一个Pandas Series)。
import pandas as pd
# 创建一个示例DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Score': [85, 90, 95]
}
df = pd.DataFrame(data)
# 使用iterrows()遍历DataFrame
for index, row in df.iterrows():
print(f"Index: {index}")
print(f"Name: {row['Name']}, Age: {row['Age']}, Score: {row['Score']}")
使用 itertuples()
itertuples()方法返回每行的一个命名元组,访问速度通常比iterrows()更快。
# 使用itertuples()遍历DataFrame
for row in df.itertuples(index=True, name='Pandas'):
print(f"Index: {row.Index}")
print(f"Name: {row.Name}, Age: {row.Age}, Score: {row.Score}")
使用 apply()
apply()方法可以沿着指定轴应用函数,通常用于对每行或每列进行操作。
# 使用apply()对每行进行操作
def process_row(row):
return f"{row['Name']} is {row['Age']} years old and scored {row['Score']}."
result = df.apply(process_row, axis=1)
print(result)
使用 items()
items()方法用于遍历DataFrame的每一列,返回列名和列数据(作为一个Pandas Series)。
#使用items()遍历每一列
for column_name, column_data in df.items():
print(f"Column: {column_name}")
print(column_data)
使用 iteritems()
iteritems()方法类似于items(),但它是一个旧的API,返回的也是列名和列数据。
#使用iteritems()遍历每一列
for column_name, column_data in df.iteritems():
print(f"Column: {column_name}")
print(column_data)
注意事项
- 性能:在Pandas中,尽量避免对DataFrame进行逐行遍历,因为这通常会导致性能问题。使用矢量化操作或聚合函数通常更高效。
- 数据修改:使用iterrows()返回的Series是一个视图而非副本,因此对其进行的更改不会反映在原始DataFrame中。
- 数据类型:iterrows()会将每行转换为Series,这可能会导致数据类型的变化,特别是对于整数类型。
DataFrame.apply()
DataFrame.apply()是Pandas提供的一个强大且灵活的方法,用于沿着指定轴(行或列)应用函数。这在数据处理和分析中非常有用,因为它允许对DataFrame中的每个元素、行或列进行操作。
基本语法
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
参数详解
- func:要应用的函数。可以是NumPy函数或用户自定义的Python函数。
- axis:指定函数应用的轴。默认值为0,表示沿着列(即对每一行)应用函数。
- 0或 'index':沿着列方向应用(对每一行应用)。
- 1或 'columns':沿着行方向应用(对每一列应用)。
- raw:布尔值,默认为False。如果为True,则传递给函数的是一个NumPy数组,而不是Pandas Series。通常在性能优化时使用。
- result_type:指定返回类型。可选值包括:
- 'expand':如果结果是一个Series,则将其扩展为多个列。
- 'reduce':尝试减少返回结果的维度。
- 'broadcast':将结果广播回原始形状。
- 默认情况下,None表示自动选择。
- args:元组,传递给函数的额外位置参数。
- kwds:传递给函数的其他关键字参数。
对每个元素应用函数
假设我们有一个DataFrame,我们想要对每个元素进行平方运算:
import pandas as pd
#创建一个示例DataFrame
data = {
'A': [1, 2, 3],
'B': [4, 5, 6]
}
df = pd.DataFrame(data)
#对每个元素进行平方运算
df_squared = df.apply(lambda x: x**2)
print(df_squared)
对每一列应用函数
我们可以使用axis=0来对每一列应用函数。例如,计算每列的均值:
#计算每列的均值 column_means = df.apply(lambda x: x.mean(), axis=0) print(column_means)
对每一行应用函数
我们可以使用axis=1来对每一行应用函数。例如,计算每行的和:
#计算每行的和 row_sums = df.apply(lambda x: x.sum(), axis=1) print(row_sums)
使用自定义函数
我们可以定义一个自定义函数,并将其应用到DataFrame上。例如,定义一个函数来判断每个元素是否大于3:
#定义自定义函数
def greater_than_three(x):
return x > 3
#应用自定义函数
df_greater_than_three = df.applymap(greater_than_three)
print(df_greater_than_three)
使用 result_type
使用result_type='expand'可以将返回的Series扩展为多个列。例如:
#定义一个返回多个值的函数
def return_multiple(x):
return x, x**2
#使用expand将返回的Series扩展为多个列
df_expanded = df.apply(lambda x: pd.Series(return_multiple(x['A'])), axis=1, result_type='expand')
print(df_expanded)
注意事项
- apply()是对DataFrame的行或列进行操作,而 applymap() 是对DataFrame的每个元素进行操作。
- 当需要对整个DataFrame的每个元素进行操作时,applymap()可能更合适。
- 在性能要求高的场景中,考虑使用raw=True来提高性能。
Pandas平移函数shift()与diff()
shift()函数
shift()函数主要的功能就是使数据框中的数据移动,若freq=None时,根据axis的设置,行索引数据保持不变,列索引数据可以在行上上下移动或在列上左右移动;若行索引为时间序列,则可以设置freq参数,根据periods和freq参数值组合,使行索引每次发生periods*freq偏移量滚动,列索引数据不会移动。
DataFrame.shift(periods=1, freq=None, axis=0, fill_value=<no_default>)
参数说明:
- period:表示移动的幅度,可以是正数,也可以是负数,默认值是1,1就表示移动一次,注意这里移动的都是数据,而索引是不移动的,移动之后没有对应值的,就赋值为NaN。
- freq:DateOffset, timedelta, or time rule string,可选参数,默认值为None,只适用于时间序列,如果这个参数存在,那么会按照参数值移动时间索引,而数据值没有发生变化。
- axis:{0, 1, ‘index’, ‘columns’},表示移动的方向,如果是0或者’index’表示上下移动,如果是1或者’columns’,则会左右移动。
- fill_value:空行需要填充的数值
diff()函数
从官方的说明中已经很明确的可以知道其 shift 函数的关系为:df.diff() = df – df.shift()
DataFrame.diff(periods=1, axis=0)
参数说明:
- periods:移动的幅度,int 类型,默认值为 1。
- axis:移动的方向,{0 or ‘index’, 1 or ‘columns’},如果为 0 或者’index’,则上下移动,如果为 1 或者’columns’,则左右移动。
Pandas 数据可视化
Pandas 提供了简单易用的内置数据可视化功能,主要是通过其 plot 方法与 Matplotlib 集成实现的。这些可视化功能能够帮助用户快速生成常见类型的图表,便于进行数据分析和展示。
基本用法
在 Pandas 中,DataFrame 和 Series 都有一个 plot 方法,允许用户创建各种类型的图表。基本语法如下:
DataFrame.plot(kind='line', **kwargs) Series.plot(kind='line', **kwargs)
参数说明:
- kind:指定图表类型,如 'line', 'bar', 'hist', 'scatter', 'pie', 'box' 等。
- x:指定 x 轴数据的列名。
- y:指定 y 轴数据的列名(或多个列名的列表)。
- title:设置图表标题。
- xlabel/ylabel:设置 x 轴和 y 轴标签。
- legend:布尔值,是否显示图例。
- figsize:指定图表大小,格式为(宽, 高)。
- grid:布尔值,是否显示网格。
常见图表类型
线形图(Line Plot)
线形图是默认的图表类型,适用于展示数据的趋势和变化。
import pandas as pd
import matplotlib.pyplot as plt
data = {'Year': [2010, 2011, 2012, 2013, 2014],
'Sales': [200, 250, 300, 350, 400]}
df = pd.DataFrame(data)
df.plot(x='Year', y='Sales', kind='line')
plt.show()
柱状图(Bar Plot)
柱状图适用于比较不同类别之间的数值大小。
df.plot(x='Year', y='Sales', kind='bar') plt.show()
水平柱状图可以通过 kind='barh' 实现。
df.plot(x='Year', y='Sales', kind='barh') plt.show()
直方图(Histogram)
直方图用于显示数据的分布。
data = {'Age': [23, 25, 29, 30, 35, 40, 45, 50, 55, 60]}
df = pd.DataFrame(data)
df['Age'].plot(kind='hist', bins=5)
plt.show()
散点图(Scatter Plot)
散点图用于显示两个变量之间的关系。
data = {'Height': [150, 160, 170, 180, 190],
'Weight': [50, 60, 70, 80, 90]}
df = pd.DataFrame(data)
df.plot(x='Height', y='Weight', kind='scatter')
plt.show()
饼图(Pie Chart)
饼图用于显示各部分占整体的比例。
data = {'Category': ['A', 'B', 'C'],
'Values': [30, 50, 20]}
df = pd.DataFrame(data)
df.set_index('Category').plot(kind='pie', y='Values', autopct='%1.1f%%')
plt.ylabel('')
plt.show()
箱线图(Box Plot)
箱线图用于显示数据的分布特征,如中位数、四分位数等。
data = {'Math': [90, 85, 78, 92, 88],
'Science': [85, 80, 88, 90, 95]}
df = pd.DataFrame(data)
df.plot(kind='box')
plt.show()
使用 Matplotlib 进行定制
由于 Pandas 的可视化功能是基于 Matplotlib 的,因此可以使用 Matplotlib 的功能对图表进行进一步的定制。例如,可以添加标题、标签、网格等。
ax = df.plot(kind='line')
ax.set_title('Sales Over Years')
ax.set_xlabel('Year')
ax.set_ylabel('Sales')
ax.grid(True)
plt.show()
Pandas 多级索引
Pandas 的多级索引(MultiIndex)是一个强大的功能,允许在一个轴上使用多个索引级别。这种结构可以帮助你更灵活地组织和访问数据,尤其是在处理多维数据时。多级索引可以应用于行索引和列索引,支持复杂的数据操作和分析。
创建多级索引
使用 pd.MultiIndex.from_arrays()
从多个数组创建多级索引。
import pandas as pd
arrays = [
['A', 'A', 'B', 'B'],
['one', 'two', 'one', 'two']
]
index = pd.MultiIndex.from_arrays(arrays, names=('first', 'second'))
df = pd.DataFrame({'data': [1, 2, 3, 4]}, index=index)
print(df)
使用 pd.MultiIndex.from_tuples()
从一个元组列表创建多级索引。
tuples = [('A', 'one'), ('A', 'two'), ('B', 'one'), ('B', 'two')]
index = pd.MultiIndex.from_tuples(tuples, names=('first', 'second'))
df = pd.DataFrame({'data': [1, 2, 3, 4]}, index=index)
print(df)
使用 pd.MultiIndex.from_product()
从多个数组的笛卡尔积创建多级索引。
index = pd.MultiIndex.from_product([['A', 'B'], ['one', 'two']], names=('first', 'second'))
df = pd.DataFrame({'data': [1, 2, 3, 4]}, index=index)
print(df)
多级索引的操作
访问数据
使用 loc 或 iloc 访问多级索引的数据。
# 使用 loc 访问数据
print(df.loc['A'])
# 使用多个索引级别访问数据
print(df.loc[('A', 'one')])
切片操作
多级索引支持复杂的切片操作。
# 按第一级索引切片
print(df.loc['A':'B'])
# 按多个级别进行切片
print(df.loc[('A', 'one'):('B', 'two')])
交换索引级别
使用 swaplevel() 方法交换索引级别。
df_swapped = df.swaplevel('first', 'second')
print(df_swapped)
重设索引
使用 reset_index() 方法将多级索引转换为列。
df_reset = df.reset_index() print(df_reset)
排序索引
使用 sort_index() 方法对多级索引进行排序。
df_sorted = df.sort_index() print(df_sorted)
应用场景
- 数据透视表:多级索引常用于数据透视表的结果中,以支持多维数据分析。
- 时间序列数据:在处理复杂的时间序列数据时,可以使用多级索引来表示不同的时间层次(如年、月、日)。
- 分层数据:适合具有层次结构的数据,如地理数据(国家、省、市)等。
注意事项
- 性能:虽然多级索引非常灵活,但在某些情况下可能会导致性能下降,尤其是在大数据集上进行复杂的索引操作时。
- 可读性:多级索引可能会使数据框架的结构变得复杂,从而降低可读性。使用时应注意保持数据的清晰性和可解释性。
Pandas 性能优化
Pandas 是一个功能强大的数据分析库,但在处理大规模数据集时,性能可能成为一个问题。为了提高 Pandas 的性能,可以采用多种优化策略。
使用 inplace 参数
Pandas 中的许多方法都有一个 inplace 参数,用于指定操作是否在原地(即对原始对象)进行修改。默认情况下,Pandas 的许多操作会返回一个新对象,但这可能会导致不必要的内存开销,尤其是在处理大型数据集时。
优势
- 内存效率:通过在原地修改对象,可以减少内存使用,因为不需要创建数据的副本。
- 速度:在某些情况下,原地修改可能会稍微加快操作速度,因为减少了对象创建和内存分配的开销。
示例
import pandas as pd
# 创建示例 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 使用 inplace=True 删除列
df.drop('B', axis=1, inplace=True)
print(df)
注意事项
- 并非所有操作都支持 inplace 参数。
- 在使用 inplace=True 时,要小心,因为操作是不可逆的(除非提前创建了副本)。
使用 copy() 方法避免数据副本问题
在 Pandas 中,赋值操作可能会导致数据共享,即修改一个对象可能会影响到其他引用该对象的数据。这种行为是因为 Pandas 使用了 NumPy 的底层数组,而 NumPy 的数组是引用类型。
问题
- 意外修改:对一个 DataFrame 或 Series 的切片进行修改时,可能会意外地修改原始数据。
- 数据完整性:在进行需要保持原始数据完整的操作时,数据共享可能导致数据不一致。
解决方案
使用 copy() 方法可以创建数据的深拷贝,从而避免上述问题。
# 创建示例 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# 创建 DataFrame 的副本
df_copy = df.copy()
# 修改副本
df_copy['A'] = [10, 20, 30]
print("Original DataFrame:")
print(df)
print("\nModified Copy:")
print(df_copy)
注意事项
- 性能开销:copy() 会创建数据的完整副本,这在处理大数据集时可能会增加内存使用和处理时间。
- 深拷贝 vs 浅拷贝:默认情况下,copy() 创建深拷贝。如果只需要浅拷贝,可以使用 copy(deep=False)。
参考链接:


