itertools是Python标准库中的一个模块,提供了用于操作迭代器的函数工具集合。这个模块中的函数可以高效地处理遍历和组合数据,特别适合用于函数式编程和数据流处理。
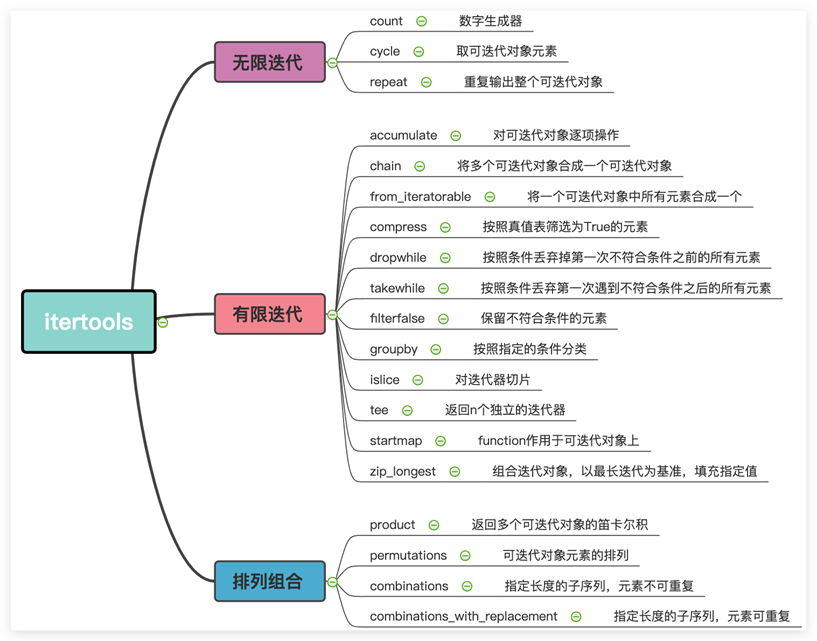
无限迭代器
itertools.count
itertools.count是Python的itertools模块中的一个函数,它返回一个无限迭代器,生成一系列等差数列的数字。这个函数非常有用,可以用于需要无限迭代的场景,比如生成无限序列的数字,或者用作其他迭代器的辅助工具。
用法
itertools.count(start=0, step=1)
- start: 序列的起始值,默认为0。
- step: 序列的步长,默认为1。
特性
- 无限迭代: count是一个无限迭代器,这意味着如果不加限制地使用它,它将会无限生成数字。因此,通常需要结合其他函数(如islice)来限制迭代次数。
- 灵活性: 可以通过设置start和step参数来生成不同的数列。例如,生成一个从10开始,每次增加2的数列。
示例
import itertools
# 创建一个从0开始的无限序列
counter = itertools.count()
# 打印前5个数字
for i in range(5):
print(next(counter)) # 输出: 0, 1, 2, 3, 4
# 创建一个从10开始,每次增加2的无限序列
counter = itertools.count(start=10, step=2)
# 打印前5个数字
for i in range(5):
print(next(counter)) # 输出: 10, 12, 14, 16, 18
# 使用islice限制输出
limited_counter = itertools.islice(itertools.count(5, 3), 5)
print(list(limited_counter)) # 输出: [5, 8, 11, 14, 17]
注意事项
- 由于 count 是一个无限迭代器,在使用时要小心,确保不会无意中导致无限循环。
- 在需要有限序列的场景下,可以结合 islice 等方法来限制迭代次数。
- count可以用于生成浮点数序列,只需将 start 和 step 设置为浮点数即可。
itertools.cycle
itertools.cycle是Python itertools模块中的一个函数,它用于创建一个无限迭代器,可以循环遍历给定的可迭代对象。该函数会不断重复遍历传入的可迭代对象,从第一个元素到最后一个元素,然后从头开始重复。
用法
itertools.cycle(iterable)
- iterable: 需要循环遍历的可迭代对象,比如列表、字符串、元组等。
特性
- 无限循环: cycle会无限循环地遍历给定的可迭代对象,因此需要注意控制迭代次数,以避免无限循环导致程序无法终止。
- 适用性: 适用于需要反复迭代的场景,比如在动画中循环播放一组帧,或在算法中循环使用一组参数。
示例
import itertools
# 创建一个循环遍历的迭代器
colors = ['red', 'green', 'blue']
color_cycle = itertools.cycle(colors)
# 打印前10个颜色
for _ in range(10):
print(next(color_cycle))
# 输出: red, green, blue, red, green, blue, red, green, blue, red
# 使用cycle来重复字符串中的字符
string_cycle = itertools.cycle('AB')
# 打印前6个字符
for _ in range(6):
print(next(string_cycle))
# 输出: A, B, A, B, A, B
注意事项
- 由于 cycle 会无限地重复给定的可迭代对象,所以在使用时要注意控制迭代次数,以避免程序进入无限循环。
- cycle会在内存中缓存传入的可迭代对象的所有元素,以便在每次循环时重用。因此,传入的可迭代对象不应过大,以避免占用过多内存。
- cycle的输出可以通过 islice 等方法进行限制,以便在需要有限输出时使用。
itertools.repeat
itertools.repeat是Python itertools模块中的一个函数,用于创建一个无限迭代器,该迭代器会无限次地重复一个指定的对象。这个函数非常适合于需要重复某个固定值的情况。
用法
itertools.repeat(object, times=None)
- object: 要重复的对象,可以是任何类型的对象(如整数、字符串、列表等)。
- times: 重复次数,默认为None,表示无限重复。如果指定了 times,则迭代器将在重复 times 次后停止。
特性
- 无限重复: 如果不指定 times 参数,repeat 将无限重复指定的对象。
- 有限重复: 如果指定了 times 参数,则迭代器将在重复 times 次后停止。
- 灵活性: 可以重复任何类型的对象,包括基本类型(如整数、字符串)以及复杂类型(如列表、字典)。
无限重复
import itertools
# 创建一个无限重复'A'的迭代器
repeater = itertools.repeat('A')
# 打印前5个重复的元素
for _ in range(5):
print(next(repeater))
# 输出: A, A, A, A, A
有限重复
import itertools
# 创建一个重复'B'5次的迭代器
repeater = itertools.repeat('B', times=5)
# 打印所有重复的元素
print(list(repeater))
# 输出: ['B', 'B', 'B', 'B', 'B']
复杂类型的重复
import itertools # 创建一个重复列表[1, 2, 3]3次的迭代器 repeater = itertools.repeat([1, 2, 3], times=3) # 打印所有重复的元素 print(list(repeater)) # 输出: [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
结合其他函数使用
itertools.repeat经常与其他函数结合使用,以实现更复杂的逻辑。
结合 islice
import itertools # 创建一个无限重复1的迭代器,并取前5个元素 repeater = itertools.repeat(1) sliced_repeater = itertools.islice(repeater, 5) # 打印所有重复的元素 print(list(sliced_repeater)) # 输出: [1, 1, 1, 1, 1]
结合 zip
import itertools # 创建两个无限重复的迭代器,并取前3个元素 repeater1 = itertools.repeat(1) repeater2 = itertools.repeat(2) # 使用 zip 合并两个迭代器 zipped = itertools.zip_longest(repeater1, repeater2, fillvalue=None) # 打印前3对元素 print(list(itertools.islice(zipped, 3))) # 输出: [(1, 2), (1, 2), (1, 2)]
注意事项
- 无限重复: 如果不指定 times 参数,repeat 将无限重复指定的对象。因此,在实际应用中,建议使用 islice 或其他方法来限制重复次数。
- 内存占用: 由于 repeat 本身不需要额外的内存来缓存数据,所以它在内存占用方面是非常高效的。
- 适用场景: repeat 常用于需要重复某个固定值的场景,例如初始化数组、填充数据等。
终止于最短输入序列的迭代器
itertools.accumulate
itertools.accumulate 是 Python itertools 模块中的一个函数,用于生成一个迭代器,该迭代器会返回输入可迭代对象的累计结果。默认情况下,它执行累加操作,但可以通过传递不同的函数来执行其他类型的累计操作。
用法
itertools.accumulate(iterable, func=operator.add, *, initial=None)
- iterable: 要进行累计操作的可迭代对象。
- func: 用于指定累计操作的函数,默认为 add,即执行累加操作。可以使用任何接受两个参数的函数。
- initial: 可选参数,用于指定累计的初始值。如果指定了 initial,则会将其作为序列的第一个元素。
特性
- 灵活性: 可以通过更改 func 参数来实现不同的累计操作,如乘积、最大值、最小值等。
- 可选初始值: 可以通过 initial 参数来指定累计的初始值,这在某些情况下非常有用。
默认累加操作
import itertools # 累加一个列表 numbers = [1, 2, 3, 4, 5] accumulated = itertools.accumulate(numbers) print(list(accumulated)) # 输出: [1, 3, 6, 10, 15]
使用自定义函数
import itertools import operator # 累乘一个列表 numbers = [1, 2, 3, 4, 5] accumulated = itertools.accumulate(numbers, operator.mul) print(list(accumulated)) # 输出: [1, 2, 6, 24, 120]
使用初始值
import itertools # 累加一个列表,指定初始值为10 numbers = [1, 2, 3, 4, 5] accumulated = itertools.accumulate(numbers, initial=10) print(list(accumulated)) # 输出: [10, 11, 13, 16, 20, 25]
使用最大值函数
import itertools # 计算一个列表的累计最大值 numbers = [1, 5, 2, 8, 3] accumulated = itertools.accumulate(numbers, max) print(list(accumulated)) # 输出: [1, 5, 5, 8, 8]
注意事项
- 性能: accumulate 是一个生成器,因此在处理大数据集时,它非常高效,因为它不会将所有中间结果存储在内存中。
- 自定义函数: 任何接受两个参数的函数都可以作为 func 使用,这使得 accumulate 非常灵活,可以用于各种复杂的累计计算。
itertools.batched
itertools.batched() 是 Python 3.12 中新增的一个函数,用于将一个可迭代对象分割成大小相等的批次(或块)。这是一个非常有用的工具,尤其是在需要对数据进行分块处理时,比如批量处理大数据集、分页显示等。
用法
itertools.batched(iterable, n)
- iterable: 需要分块的可迭代对象。
- n: 每个批次的大小。
特性
- 批次大小: batched 将可迭代对象按指定大小 n 分割成多个子迭代器,每个子迭代器的长度最多为 n。
- 最后一块: 如果可迭代对象的总长度不是 n 的整数倍,那么最后一块可能会小于 n。
- 惰性求值: batched 是惰性求值的,意味着它不会一次性将所有批次加载到内存中,而是逐个生成,这在处理大数据集时非常高效。
基本用法
import itertools
# 创建一个可迭代对象
data = range(10)
# 使用 batched 将其分割为大小为3的批次
batches = itertools.batched(data, 3)
# 打印每个批次
for batch in batches:
print(list(batch))
# 输出:
# [0, 1, 2]
# [3, 4, 5]
# [6, 7, 8]
# [9]
处理字符串
import itertools
# 创建一个字符串
text = "HelloWorld"
# 使用 batched 将其分割为大小为4的批次
batches = itertools.batched(text, 4)
# 打印每个批次
for batch in batches:
print(''.join(batch))
# 输出:
# Hell
# oWor
# ld
结合其他函数使用
itertools.batched 可以与其他函数结合使用,实现更复杂的操作。
import itertools # 创建一个可迭代对象 data = range(10) # 使用 batched 将其分割为大小为3的批次,并处理每个批次 batches = itertools.batched(data, 3) # 计算每个批次的和 sums = [sum(batch) for batch in batches] print(sums) # 输出: [3, 12, 21, 9]
注意事项
- 输入大小: 如果 n 大于可迭代对象的长度,那么 batched 只会返回一个批次,该批次包含所有元素。
- 惰性特性: batched 是惰性求值的,因此在处理无限迭代器或大数据集时特别有用。
- 批次完整性: 如果最后一个批次的元素数量少于 n,它仍然会被返回,这点需要在某些情况下加以注意。
实际应用场景
- 批量处理:在需要对大数据集进行批量处理时,batched 提供了一种简单有效的方法。
- 分页显示:在需要将数据分页显示的应用场景中,可以使用 batched 来生成每页的数据。
- 资源管理:在处理需要分块的任务(如批量数据库操作、批量网络请求)时,使用 batched 可以更好地管理资源。
itertools.chain
itertools.chain 是 Python itertools 模块中的一个函数,用于将多个可迭代对象连接成一个单一的迭代器。它可以用于遍历多个序列(如列表、元组、集合等)而不需要显式地嵌套循环。
用法
itertools.chain(*iterables)
- iterables: 任意数量的可迭代对象,可以是列表、元组、字符串等。
特性
- 连接多个迭代器: chain 可以将多个可迭代对象连接起来,形成一个连续的迭代器。
- 内存效率高: chain 是惰性求值的,即它不会一次性将所有元素加载到内存中,而是逐个生成元素,这使得它在处理大数据集时非常高效。
连接多个列表
import itertools # 连接多个列表 list1 = [1, 2, 3] list2 = [4, 5, 6] list3 = [7, 8, 9] combined = itertools.chain(list1, list2, list3) print(list(combined)) # 输出: [1, 2, 3, 4, 5, 6, 7, 8, 9]
连接不同类型的可迭代对象
import itertools # 连接列表、元组和字符串 list1 = [1, 2, 3] tuple1 = (4, 5, 6) string1 = "789" combined = itertools.chain(list1, tuple1, string1) print(list(combined)) # 输出: [1, 2, 3, 4, 5, 6, '7', '8', '9']
结合其他函数使用
itertools.chain 可以与其他函数结合使用,实现更复杂的操作。
import itertools # 连接多个列表并限制输出 list1 = [1, 2, 3] list2 = [4, 5, 6] list3 = [7, 8, 9] combined = itertools.chain(list1, list2, list3) limited = itertools.islice(combined, 5) print(list(limited)) # 输出: [1, 2, 3, 4, 5]
注意事项
- 输入顺序: chain 按照传入的顺序连接可迭代对象,因此元素的顺序会保持不变。
- 性能: 由于 chain 是惰性求值的,它不会在内存中创建一个新的完整序列,这对于处理大数据集非常有利。
- 无限迭代器: 如果传入的任何一个可迭代对象是无限的,那么 chain 也会是无限的,除非使用其他方法(如 islice)限制迭代次数。
itertools.chain.from_iterable
itertools.chain.from_iterable 是 itertools 模块中的一个方法,用于将一个包含多个可迭代对象的容器(如列表、元组等)展开成一个单一的迭代器。与 itertools.chain 直接连接多个可迭代对象不同,itertools.chain.from_iterable 接受一个包含多个可迭代对象的容器,并将其内部的每个可迭代对象依次展开。
用法
itertools.chain.from_iterable(iterables)
- iterables: 包含多个可迭代对象的容器,如列表、元组等。
特性
- 展开容器: from_iterable 会将容器中的每个可迭代对象依次展开,形成一个连续的迭代器。
- 惰性求值: 与 chain 类似,chain.from_iterable 也是惰性求值的,不会一次性将所有元素加载到内存中。
展开多个列表
import itertools # 创建一个包含多个列表的列表 lists = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # 使用 chain.from_iterable 展开这些列表 flattened = itertools.chain.from_iterable(lists) print(list(flattened)) # 输出: [1, 2, 3, 4, 5, 6, 7, 8, 9]
展开不同类型的可迭代对象
import itertools # 创建一个包含不同类型的可迭代对象的列表 iterables = [[1, 2, 3], (4, 5, 6), "789"] # 使用 chain.from_iterable 展开这些可迭代对象 flattened = itertools.chain.from_iterable(iterables) print(list(flattened)) # 输出: [1, 2, 3, 4, 5, 6, '7', '8', '9']
结合其他函数使用
itertools.chain.from_iterable 可以与其他函数结合使用,实现更复杂的操作。
import itertools # 创建一个包含多个列表的列表 lists = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # 使用 chain.from_iterable 展开这些列表,并限制输出 flattened = itertools.chain.from_iterable(lists) limited = itertools.islice(flattened, 5) print(list(limited)) # 输出: [1, 2, 3, 4, 5]
注意事项
- 输入容器: from_iterable 接受的是一个包含多个可迭代对象的容器,而不是直接传入多个可迭代对象。
- 性能: 由于 from_iterable 是惰性求值的,它不会一次性将所有元素加载到内存中,这对于处理大数据集非常有利。
- 无限迭代器: 如果容器中的任何一个可迭代对象是无限的,那么 from_iterable 也会是无限的,除非使用其他方法(如 itertools.islice)限制迭代次数。
itertools.compress
itertools.compress 是 Python itertools 模块中的一个函数,用于根据一个选择序列(selectors)从另一个数据序列(data)中筛选出相应的元素。compress 函数可以根据选择序列中的布尔值来决定是否保留数据序列中的相应元素。
用法
itertools.compress(data, selectors)
- data: 需要筛选的数据序列。
- selectors: 选择序列,通常是一个布尔序列,其中 True 表示保留对应位置的元素,False 表示忽略对应位置的元素。
特性
- 筛选数据: 根据选择序列中的布尔值来决定是否保留数据序列中的相应元素。
- 灵活使用: 选择序列可以是任何可迭代的对象,只要它可以转换为布尔值(如数字、字符串等)。
基本用法
import itertools # 数据序列 data = [1, 2, 3, 4, 5] # 选择序列 selectors = [True, False, True, False, True] # 使用compress进行筛选 filtered_data = itertools.compress(data, selectors) print(list(filtered_data)) # 输出: [1, 3, 5]
不同类型的选择序列
import itertools # 数据序列 data = [1, 2, 3, 4, 5] # 选择序列 selectors = [1, 0, 1, 0, 1] # 1和0可以转换为True和False # 使用compress进行筛选 filtered_data = itertools.compress(data, selectors) print(list(filtered_data)) # 输出: [1, 3, 5]
字符串数据
import itertools
# 数据序列
data = "abcdef"
# 选择序列
selectors = [True, False, True, False, True, False]
# 使用compress进行筛选
filtered_data = itertools.compress(data, selectors)
print(''.join(filtered_data))
# 输出: ace
结合其他函数使用
itertools.compress可以与其他函数结合使用,实现更复杂的筛选逻辑。
结合 zip 和 map
import itertools # 数据序列 data = [1, 2, 3, 4, 5] # 选择序列 selectors = [True, False, True, False, True] # 使用zip和map进行筛选 filtered_data = itertools.compress(data, selectors) # 计算每个筛选后的元素的平方 squared_data = map(lambda x: x**2, filtered_data) print(list(squared_data)) # 输出: [1, 9, 25] 结合filter和compress import itertools # 数据序列 data = [1, 2, 3, 4, 5] # 选择序列 selectors = [True, False, True, False, True] # 使用filter进行筛选 filtered_data = itertools.compress(data, selectors) # 使用filter进一步筛选大于2的元素 filtered_data = filter(lambda x: x>2, filtered_data) print(list(filtered_data)) # 输出: [3, 5]
注意事项
- 选择序列长度: 选择序列的长度应该与数据序列的长度相同。如果选择序列较短,compress会停止处理剩余的数据;如果选择序列较长,多余的值将被忽略。
- 惰性求值: compress 是惰性求值的,这意味着它不会一次性将所有元素加载到内存中,而是逐个生成。
- 布尔转换: 选择序列中的元素可以是任何可以转换为布尔值的对象。例如,非零数字转换为True,零数字转换为 False。
实际应用场景
- 数据筛选: 在需要根据特定条件筛选数据时,compress非常有用。
- 特征选择: 在机器学习中,可以使用compress 来选择特定特征。
- 数据清洗: 在数据预处理阶段,可以使用compress 来过滤掉不符合条件的数据。
itertools.dropwhile
itertools.dropwhile是Python itertools模块中的一个函数,用于创建一个迭代器,该迭代器会跳过可迭代对象中满足指定条件的元素,直到遇到第一个不满足条件的元素为止。从该元素开始,返回剩余的所有元素。
用法
itertools.dropwhile(predicate, iterable)
- predicate: 一个函数,用于测试每个元素是否满足条件。函数返回True 时,元素会被跳过;返回 False 时,迭代器从该元素开始返回后续元素。
- iterable: 要处理的可迭代对象。
特性
- 条件跳过: dropwhile 只会跳过满足条件的连续元素,一旦遇到不满足条件的元素,就会返回该元素及其后的所有元素。
- 惰性求值: dropwhile 是惰性求值的,这意味着它不会一次性将所有元素加载到内存中,而是逐个生成。
基本用法
import itertools
# 定义一个谓词函数
def is_less_than_three(x):
return x<3
# 数据序列
data = [1, 2, 3, 4, 1, 2, 3]
# 使用dropwhile跳过小于3的元素
result = itertools.dropwhile(is_less_than_three, data)
print(list(result))
# 输出: [3, 4, 1, 2, 3]
使用lambda函数
import itertools # 数据序列 data = [1, 2, 3, 4, 1, 2, 3] # 使用dropwhile跳过小于3的元素 result = itertools.dropwhile(lambda x: x<3, data) print(list(result)) # 输出: [3, 4, 1, 2, 3]
处理字符串
import itertools
# 数据序列
data = "aaabbccdde"
# 使用dropwhile跳过'a'字符
result = itertools.dropwhile(lambda x: x=='a', data)
print(''.join(result))
# 输出: "bbccdde"
结合其他函数使用
itertools.dropwhile可以与其他函数结合使用,实现更复杂的逻辑。
结合 filterfalse
import itertools # 数据序列 data = [1, 2, 3, 4, 1, 2, 3] # 使用dropwhile跳过小于3的元素 dropped = itertools.dropwhile(lambda x: x<3, data) # 使用filterfalse过滤掉小于3的元素 filtered = itertools.filterfalse(lambda x: x<3, dropped) print(list(filtered)) # 输出: [3, 4, 3]
注意事项
- 连续性: dropwhile 只会跳过满足条件的连续元素,一旦遇到第一个不满足条件的元素,就会返回该元素及其后的所有元素。
- 惰性特性: 由于dropwhile 是惰性求值的,因此在处理大数据集或无限迭代器时特别有用。
- 谓词函数: 谓词函数应返回布尔值,以指示元素是否满足条件。
实际应用场景
- 数据清洗:在数据预处理阶段,可以使用 dropwhile 来跳过不需要的开头元素。
- 流处理:在处理流数据时,可以使用 dropwhile 来过滤掉初始不需要的部分。
- 日志分析:在日志文件中,可以使用 dropwhile 跳过不相关的初始日志条目。
itertools.filterfalse
itertools.filterfalse 是 Python itertools 模块中的一个函数,用于创建一个迭代器,该迭代器过滤掉可迭代对象中满足指定条件的元素,仅返回不满足条件的元素。这与内置函数 filter 的行为相反,filter 返回的是满足条件的元素。
用法
itertools.filterfalse(predicate, iterable)
- predicate: 一个函数,用于测试每个元素是否满足条件。函数返回 True 时,元素会被过滤掉;返回 False 时,元素会被保留。
- iterable: 要处理的可迭代对象。
特性
- 条件过滤: filterfalse 只返回不满足条件的元素。
- 惰性求值: filterfalse 是惰性求值的,这意味着它不会一次性将所有元素加载到内存中,而是逐个生成。
基本用法
import itertools
# 定义一个谓词函数
def is_even(x):
return x % 2 == 0
# 数据序列
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用 filterfalse 过滤掉偶数
result = itertools.filterfalse(is_even, data)
print(list(result))
# 输出: [1, 3, 5, 7, 9]
使用 lambda 函数
import itertools # 数据序列 data = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 使用 filterfalse 过滤掉偶数 result = itertools.filterfalse(lambda x: x % 2 == 0, data) print(list(result)) # 输出: [1, 3, 5, 7, 9]
处理字符串
import itertools
# 数据序列
data = "abcdefg"
# 使用 filterfalse 过滤掉元音字母
result = itertools.filterfalse(lambda x: x in 'aeiou', data)
print(''.join(result))
# 输出: "bcdfg"
结合其他函数使用
itertools.filterfalse 可以与其他函数结合使用,实现更复杂的逻辑。
结合 map
import itertools # 数据序列 data = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 使用 filterfalse 过滤掉偶数 filtered = itertools.filterfalse(lambda x: x % 2 == 0, data) # 使用 map 计算每个保留元素的平方 squared = map(lambda x: x ** 2, filtered) print(list(squared)) # 输出: [1, 9, 25, 49, 81]
注意事项
- 谓词函数: 谓词函数应返回布尔值,以指示元素是否满足条件。
- 惰性特性: 由于 filterfalse 是惰性求值的,因此在处理大数据集或无限迭代器时特别有用。
- 输入为空: 如果输入的可迭代对象为空,filterfalse 也会返回一个空迭代器。
实际应用场景
- 数据清洗: 在数据预处理阶段,可以使用 filterfalse 来过滤掉不需要的数据。
- 日志分析: 在分析日志文件时,可以使用 filterfalse 过滤掉不相关的日志条目。
- 异常检测: 在检测数据异常时,可以使用 filterfalse 来保留正常的数据。
itertools.groupby
itertools.groupby 是 Python itertools 模块中的一个函数,用于对一个可迭代对象进行分组。分组是基于提供的键函数(key function)计算的键值来实现的。需要注意的是,groupby 只会对连续相同键的元素进行分组,因此在使用时通常需要先对数据进行排序。
用法
itertools.groupby(iterable, key=None)
- iterable: 要进行分组的可迭代对象。
- key: 一个函数,用于计算每个元素的键。如果未提供,则使用元素自身作为键。
特性
- 分组依据: 元素的分组依据是键函数的返回值,默认情况下是元素本身。
- 连续性: groupby 只对连续相同键的元素进行分组,因此通常需要先对数据进行排序以确保正确分组。
- 惰性求值: groupby 是惰性求值的,它逐个生成分组结果。
基本用法
import itertools
# 数据序列
data = [("apple", 1), ("banana", 2), ("apple", 3), ("banana", 4), ("apple", 5)]
# 对数据按第一个元素分组
grouped = itertools.groupby(data, key=lambda x: x[0])
for key, group in grouped:
print(key, list(group))
# 输出:
# apple [('apple', 1)]
# banana [('banana', 2)]
# apple [('apple', 3)]
# banana [('banana', 4)]
# apple [('apple', 5)]
对排序后的数据进行分组
import itertools
# 数据序列
data = [("apple", 1), ("banana", 2), ("apple", 3), ("banana", 4), ("apple", 5)]
# 先对数据按第一个元素排序
data.sort(key=lambda x: x[0])
# 对排序后的数据进行分组
grouped = itertools.groupby(data, key=lambda x: x[0])
for key, group in grouped:
print(key, list(group))
# 输出:
# apple [('apple', 1), ('apple', 3), ('apple', 5)]
# banana [('banana', 2), ('banana', 4)]
处理字符串
import itertools
# 字符串数据
data = "aaabbccccdaa"
# 对字符串按字符分组
grouped = itertools.groupby(data)
for key, group in grouped:
print(key, list(group))
# 输出:
# a ['a', 'a', 'a']
# b ['b', 'b']
# c ['c', 'c', 'c', 'c']
# d ['d']
# a ['a', 'a']
结合其他函数使用itertools.groupby 可以与其他函数结合使用,实现更复杂的操作。
结合 sum 计算分组的总和
import itertools
# 数据序列
data = [("apple", 1), ("banana", 2), ("apple", 3), ("banana", 4), ("apple", 5)]
# 先对数据按第一个元素排序
data.sort(key=lambda x: x[0])
# 对排序后的数据进行分组并计算每组的总和
grouped = itertools.groupby(data, key=lambda x: x[0])
for key, group in grouped:
total = sum(item[1] for item in group)
print(key, total)
# 输出:
# apple 9
# banana 6
注意事项
- 排序: 由于 groupby 只对连续相同键的元素进行分组,通常需要先对数据进行排序以确保正确分组。
- 键函数: 键函数应返回一个可比较的值,以便分组操作正常进行。
- 惰性特性: 由于 groupby 是惰性求值的,它在处理大数据集时特别有用。
实际应用场景
- 日志分析: 在分析日志文件时,可以使用 groupby 按时间、类别或其他字段分组。
- 数据聚合: 在数据分析中,可以使用 groupby 对数据进行聚合操作,例如求和、计数等。
- 分类处理: 在需要对不同类别的数据进行分类处理时,groupby 提供了一种简单有效的方法。
itertools.islice
itertools.islice 是 Python itertools 模块中的一个函数,用于对可迭代对象进行切片操作。与 Python 内置的切片操作不同,islice 可以在不支持索引的可迭代对象(如生成器)上使用,并且支持通过指定起始位置、终止位置和步长来灵活地获取切片。
用法
itertools.islice(iterable, start, stop[, step])
- iterable: 要进行切片操作的可迭代对象。
- start: 切片的起始位置(包含)。
- stop: 切片的终止位置(不包含)。
- step: 步长(可选,默认为 1)。
特性
- 灵活切片: 可以指定起始位置、终止位置和步长进行切片。
- 惰性求值: islice 是惰性求值的,这意味着它不会一次性将所有元素加载到内存中,而是逐个生成。
- 适用范围广: 可用于任何可迭代对象,包括生成器和迭代器。
基本用法
import itertools # 数据序列 data = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 使用 islice 获取从索引 2 到 5 的元素 result = itertools.islice(data, 2, 6) print(list(result)) # 输出: [2, 3, 4, 5]
指定步长
import itertools # 数据序列 data = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 使用 islice 获取从索引 0 到 9 的元素,步长为 2 result = itertools.islice(data, 0, 10, 2) print(list(result)) # 输出: [0, 2, 4, 6, 8]
从起始位置到终止位置
import itertools # 数据序列 data = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 使用 islice 从索引 3 到结尾 result = itertools.islice(data, 3, None) print(list(result)) # 输出: [3, 4, 5, 6, 7, 8, 9]
处理生成器
import itertools
# 定义一个生成器
def count_up_to(n):
for i in range(n):
yield i
# 使用 islice 获取生成器中的前 5 个元素
result = itertools.islice(count_up_to(10), 5)
print(list(result))
# 输出: [0, 1, 2, 3, 4]
注意事项
- 惰性特性: 由于 islice 是惰性求值的,它不会在内存中创建一个完整的切片副本,这在处理大数据集时特别有用。
- 适用对象: islice 可以用于任何可迭代对象,但对于支持索引的对象(如列表),使用内置切片操作可能更直接。
- 无终止位置: 如果终止位置为 None,则切片会一直进行到可迭代对象的末尾。
实际应用场景
- 分页处理: 在需要对大数据集进行分页处理时,islice 提供了一种简单有效的方法。
- 数据采样: 可以使用 islice 从大数据流中提取样本。
- 流处理: 在处理流数据时,islice 可以用于从流中提取特定范围的数据。
itertools.pairwise
itertools.pairwise 是 Python 3.10 中引入的一个函数,用于生成一个迭代器,该迭代器返回输入可迭代对象中相邻元素的成对组合。这个函数非常有用,可以在需要对序列中的元素进行相邻比较或操作时使用。
用法
itertools.pairwise(iterable)
- iterable: 要进行成对组合的可迭代对象。
特性
- 相邻配对: pairwise 会返回一个迭代器,其中每个元素是输入序列中相邻元素组成的元组。
- 惰性求值: pairwise 是惰性求值的,这意味着它不会一次性将所有配对元素加载到内存中,而是逐个生成。
- 适用范围广: 可以用于任何可迭代对象,包括列表、字符串、生成器等。
基本用法
import itertools # 数据序列 data = [1, 2, 3, 4, 5] # 使用 pairwise 获取相邻元素的配对 result = itertools.pairwise(data) print(list(result)) # 输出: [(1, 2), (2, 3), (3, 4), (4, 5)]
处理字符串
import itertools
# 字符串数据
data = "ABCDE"
# 使用 pairwise 获取相邻字符的配对
result = itertools.pairwise(data)
print(list(result))
# 输出: [('A', 'B'), ('B', 'C'), ('C', 'D'), ('D', 'E')]
处理生成器
import itertools
# 定义一个生成器
def count_up_to(n):
for i in range(n):
yield i
# 使用 pairwise 获取生成器中相邻元素的配对
result = itertools.pairwise(count_up_to(5))
print(list(result))
# 输出: [(0, 1), (1, 2), (2, 3), (3, 4)]
注意事项
- 输入长度: 如果输入可迭代对象的长度小于2,则 pairwise 返回的迭代器为空,因为没有足够的元素来形成配对。
- 惰性特性: 由于 pairwise 是惰性求值的,它在处理大数据集或无限迭代器时特别有用。
- Python版本: pairwise 是在Python 3.10中引入的,因此在早期版本中不可用。
实际应用场景
- 相邻比较: 在需要对序列中的元素进行相邻比较(如查找递增对、计算相邻差异)时,pairwise非常有用。
- 路径计算: 在处理路径或坐标序列时,可以使用 pairwise 计算相邻点之间的距离。
- 模式检测: 在分析数据模式时,可以使用 pairwise 查找相邻元素之间的关系。
itertools.starmap
itertools.starmap是Python itertools模块中的一个函数,用于将可迭代对象中的元素解包后传递给一个函数。这在处理多个参数时非常有用,特别是当这些参数是以元组形式存储时。
用法
itertools.starmap(function, iterable)
- function: 接受多个参数的函数。
- iterable: 包含元组的可迭代对象,每个元组包含多个参数。
特性
- 解包参数: starmap 会自动解包每个元组,并将其作为单独的参数传递给函数。
- 惰性求值: starmap 是惰性求值的,这意味着它不会一次性将所有结果加载到内存中,而是逐个生成。
- 灵活性: 可以用于任何接受多个参数的函数,并且适用于多种类型的可迭代对象。
基本用法
假设我们有一个函数add,它接受两个参数并返回它们的和。
import itertools
# 定义一个函数
def add(a, b):
return a + b
# 数据序列
data = [(1, 2), (3, 4), (5, 6)]
# 使用 starmap 对每个元组解包并调用 add 函数
result = itertools.starmap(add, data)
print(list(result))
# 输出: [3, 7, 11]
复杂函数
假设我们有一个更复杂的函数,比如计算两点之间的欧几里得距离。
import itertools
import math
# 定义一个函数
def euclidean_distance(p1, p2):
return math.sqrt((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)
# 数据序列
data = [((1, 2), (3, 4)), ((5, 6), (7, 8))]
# 使用 starmap 对每个元组解包并调用 euclidean_distance 函数
result = itertools.starmap(euclidean_distance, data)
print(list(result))
# 输出: [2.8284271247461903, 2.8284271247461903]
处理字符串
假设我们需要对字符串进行拼接操作。
import itertools
# 定义一个函数
def concatenate_strings(s1, s2):
return s1 + s2
# 数据序列
data = [("hello", "world"), ("python", "programming")]
# 使用 starmap 对每个元组解包并调用 concatenate_strings 函数
result = itertools.starmap(concatenate_strings, data)
print(list(result))
# 输出: ['helloworld', 'pythonprogramming']
结合其他函数使用
itertools.starmap可以与其他函数结合使用,实现更复杂的功能。
结合 map 和 zip
假设我们有两个列表,需要将它们的元素两两相加。
import itertools
# 定义一个函数
def add(a, b):
return a + b
# 数据序列
list1 = [1, 2, 3]
list2 = [4, 5, 6]
# 使用 zip 将两个列表打包成元组
zipped_data = zip(list1, list2)
# 使用 starmap 对每个元组解包并调用 add 函数
result = itertools.starmap(add, zipped_data)
print(list(result))
# 输出: [5, 7, 9]
结合 filter 和 starmap
假设我们需要对某些元组进行过滤和处理。
import itertools
# 定义一个函数
def add(a, b):
return a + b
# 数据序列
data = [(1, 2), (3, 4), (5, 6)]
# 定义一个过滤函数
def should_process(pair):
return pair[0] > 2
# 使用 filter 过滤元组
filtered_data = filter(should_process, data)
# 使用 starmap 对每个元组解包并调用 add 函数
result = itertools.starmap(add, filtered_data)
print(list(result))
# 输出: [7, 11]
注意事项
- 解包顺序: starmap 解包元组的顺序是固定的,确保元组中的元素数量与函数的参数数量一致。
- 惰性特性: 由于 starmap 是惰性求值的,它在处理大数据集时特别有用。
- 适用范围: starmap 可以用于任何可迭代对象,包括列表、元组、生成器等。
实际应用场景
- 批量处理: 当需要对多个参数进行批量处理时,starmap提供了一种简洁的方法。
- 并行处理: 在并行处理场景中,可以使用 starmap 与多线程或多进程库结合,实现高效的并行计算。
- 数据处理: 在需要对数据进行复杂计算时,starmap可以简化代码实现,并提高处理效率。
itertools.takewhile
itertools.takewhile是Python itertools模块中的一个函数,用于从可迭代对象中获取满足特定条件的元素,直到条件不再满足为止。一旦条件不满足,它将停止并不再检查后续的元素。
用法
itertools.takewhile(predicate, iterable)
- predicate: 一个函数,用于测试每个元素是否满足条件。该函数应返回布尔值。
- iterable: 要进行过滤的可迭代对象。
特性
- 条件过滤: takewhile 会从可迭代对象的开头开始提取元素,直到遇到第一个不满足条件的元素为止。
- 惰性求值: takewhile 是惰性求值的,这意味着它不会一次性将所有结果加载到内存中,而是逐个生成。
- 适用范围广: 可以用于任何可迭代对象,包括列表、元组、字符串、生成器等。
基本用法
假设我们有一个数字列表,希望提取所有小于5的数字。
import itertools
# 定义一个条件函数
def less_than_five(x):
return x < 5
# 数据序列
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用 takewhile 提取满足条件的元素
result = itertools.takewhile(less_than_five, data)
print(list(result))
# 输出: [1, 2, 3, 4]
处理字符串
假设我们有一个字符串列表,希望提取以’A’开头的字符串。
import itertools
# 定义一个条件函数
def starts_with_A(s):
return s.startswith('A')
# 数据序列
data = ["Apple", "Avocado", "Banana", "Apricot", "Blueberry"]
# 使用 takewhile 提取满足条件的元素
result = itertools.takewhile(starts_with_A, data)
print(list(result))
# 输出: ['Apple', 'Avocado']
处理生成器
假设我们有一个生成器,希望提取所有偶数。
import itertools
# 定义一个生成器
def generate_numbers(n):
for i in range(n):
yield i
# 定义一个条件函数
def is_even(x):
return x % 2 == 0
# 使用 takewhile 提取满足条件的元素
result = itertools.takewhile(is_even, generate_numbers(10))
print(list(result))
# 输出: [0]
注意事项
- 停止条件: 一旦 takewhile 遇到第一个不满足条件的元素,它将停止提取,并且不会再检查后续元素。
- 惰性特性: 由于 takewhile 是惰性求值的,它在处理大数据集或无限迭代器时特别有用。
- 条件函数: 条件函数应返回布尔值,以便 takewhile 能够正确判断元素是否满足条件。
实际应用场景
- 数据过滤: 在需要从数据流中提取满足特定条件的元素时,takewhile 提供了一种简洁的方法。
- 流处理: 在处理无限数据流时,可以使用 takewhile 提取满足条件的前几个元素。
- 数据分析: 在数据分析中,takewhile 可以用于筛选出满足特定条件的数据,以便进一步分析。
itertools.tee
itertools.tee 是 Python itertools 模块中的一个函数,用于从单个可迭代对象创建多个独立的迭代器。每个迭代器都可以独立地遍历原始可迭代对象的元素,而不会相互影响。这在需要同时多次遍历同一数据流时非常有用。
用法
itertools.tee(iterable, n=2)
- iterable: 要复制的原始可迭代对象。
- n: 需要创建的迭代器的数量(默认为2)。
特性
- 多重迭代器: tee 可以创建多个迭代器,每个迭代器都可以独立地遍历相同的数据。
- 惰性求值: 创建的迭代器是惰性求值的,这意味着它们不会一次性将所有数据加载到内存中,而是根据需要生成数据。
- 适用范围广: 可以用于任何可迭代对象,包括列表、生成器、迭代器等。
基本用法
假设我们有一个简单的列表,并希望创建两个独立的迭代器。
import itertools # 数据序列 data = [1, 2, 3, 4, 5] # 使用 tee 创建两个独立的迭代器 iter1, iter2 = itertools.tee(data, 2) # 遍历第一个迭代器 print(list(iter1)) # 输出: [1, 2, 3, 4, 5] # 遍历第二个迭代器 print(list(iter2)) # 输出: [1, 2, 3, 4, 5]
处理生成器
假设我们有一个生成器,并希望创建三个独立的迭代器。
import itertools
# 定义一个生成器
def generate_numbers(n):
for i in range(n):
yield i
# 使用 tee 创建三个独立的迭代器
iter1, iter2, iter3 = itertools.tee(generate_numbers(5), 3)
# 遍历每个迭代器
print(list(iter1)) # 输出: [0, 1, 2, 3, 4]
print(list(iter2)) # 输出: [0, 1, 2, 3, 4]
print(list(iter3)) # 输出: [0, 1, 2, 3, 4]
注意事项
- 内存消耗: 虽然 tee 是惰性求值的,但它需要在内存中存储已经生成但尚未被所有迭代器消费的元素。因此,在处理非常大的数据集时,可能会导致较高的内存消耗。
- 迭代器独立性: 创建的迭代器是相互独立的,消费一个迭代器不会影响其他迭代器。
- 输入可迭代对象: 对于可变的输入可迭代对象,在调用 tee 后修改原始对象的内容可能会导致不可预测的结果。
实际应用场景
- 数据分析: 在数据分析中,可能需要对同一数据集进行多种不同的分析,tee 提供了一种简单的方法来实现这一点。
- 流处理: 在处理流数据时,可以使用 tee 同时进行多种不同的处理操作。
- 并行处理: 在需要同时对数据进行多种不同的处理时,可以使用 tee 创建多个迭代器来实现并行处理。
itertools.zip_longest
itertools.zip_longest 是 Python itertools 模块中的一个函数,用于将多个可迭代对象“拉链”到一起,生成一个包含元素元组的迭代器。与内置的 zip 函数不同,zip_longest 可以处理长度不一致的可迭代对象,并填充较短的可迭代对象,以确保所有输入都被完全遍历。
用法
itertools.zip_longest(*iterables, fillvalue=None)
- iterables: 需要组合的一个或多个可迭代对象。
- fillvalue: 用于填充较短可迭代对象的值(默认为 None)。
特性
- 处理不等长序列: zip_longest 会继续迭代最长的输入可迭代对象,使用 fillvalue 填充较短的可迭代对象。
- 灵活的填充值: 可以指定 fillvalue,以便用特定的值填充缺失的元素。
- 适用范围广: 可以用于任何可迭代对象,包括列表、元组、字符串、生成器等。
基本用法
假设我们有两个长度不等的列表,并希望将它们组合成元组。
import itertools
# 数据序列
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c', 'd']
# 使用 zip_longest 组合列表
result = itertools.zip_longest(list1, list2, fillvalue='-')
print(list(result))
# 输出: [(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')]
处理字符串
假设我们有两个字符串,并希望将它们的字符组合成元组。
import itertools
# 字符串数据
str1 = "AB"
str2 = "1234"
# 使用 zip_longest 组合字符串
result = itertools.zip_longest(str1, str2, fillvalue='*')
print(list(result))
# 输出: [('A', '1'), ('B', '2'), ('*', '3'), ('*', '4')]
处理生成器
假设我们有两个生成器,并希望将它们组合成元组。
import itertools
# 定义两个生成器
def generate_numbers(n):
for i in range(n):
yield i
def generate_letters():
for letter in 'XYZ':
yield letter
# 使用 zip_longest 组合生成器
result = itertools.zip_longest(generate_numbers(2), generate_letters(), fillvalue=None)
print(list(result))
# 输出: [(0, 'X'), (1, 'Y'), (None, 'Z')]
注意事项
- 内存消耗: zip_longest 会根据最长的可迭代对象来生成结果,因此在处理非常长的序列时可能会导致较高的内存消耗。
- 填充值: 如果没有指定 fillvalue,默认使用 None 作为填充值。
- 输入可迭代对象: 对于输入的可变可迭代对象,zip_longest 不会修改它们。
实际应用场景
- 数据对齐: 在数据处理和分析中,可以使用 zip_longest 对齐不同长度的数据集。
- 表格数据处理: 在处理表格数据时,可能需要对不同行的列进行组合和对齐。
- 序列比较: 在比较不同长度的序列时,可以使用 zip_longest 方便地处理缺失的元素。
组合生成器
itertools.product
itertools.product 是 Python itertools 模块中的一个函数,用于生成输入可迭代对象的笛卡尔积。它返回一个迭代器,该迭代器生成的元素是输入可迭代对象中元素的所有可能组合。product 可以用于多种场景,尤其是在需要生成所有可能的排列组合时。
用法
itertools.product(*iterables, repeat=1)
- iterables: 一个或多个可迭代对象,product 将计算这些对象的笛卡尔积。
- repeat: 可选参数,用于指定每个输入可迭代对象重复多少次(默认为1)。
特性
- 笛卡尔积: product 计算的是输入可迭代对象的笛卡尔积,即所有可能的元素组合。
- 重复选项: 可以使用 repeat 参数来指定可迭代对象的重复次数,从而生成更多的组合。
- 适用范围广: 可以用于任何可迭代对象,包括列表、元组、字符串、生成器等。
基本用法
假设我们有两个列表,并希望生成它们的笛卡尔积。
import itertools # 数据序列 list1 = [1, 2] list2 = ['a', 'b'] # 使用 product 计算笛卡尔积 result = itertools.product(list1, list2) print(list(result)) # 输出: [(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')]
使用重复选项
假设我们有一个列表,并希望生成其元素的所有可能的二重组合。
import itertools # 数据序列 data = [1, 2, 3] # 使用 product 计算二重组合 result = itertools.product(data, repeat=2) print(list(result)) # 输出: [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
处理字符串
假设我们有两个字符串,并希望生成它们字符的笛卡尔积。
import itertools
# 字符串数据
str1 = "AB"
str2 = "12"
# 使用 product 计算笛卡尔积
result = itertools.product(str1, str2)
print(list(result))
# 输出: [('A', '1'), ('A', '2'), ('B', '1'), ('B', '2')]
注意事项
- 输出大小: 笛卡尔积的输出大小是输入可迭代对象大小的乘积,因此在处理大数据集时可能会生成非常多的组合。
- 惰性求值: product 是惰性求值的,这意味着它不会一次性将所有组合加载到内存中,而是逐个生成。
- 输入可迭代对象: 可以传入任意数量的可迭代对象,product 将计算它们的笛卡尔积。
实际应用场景
- 排列组合: 在需要生成所有可能的排列组合时,product 提供了一种简单的方法。
- 配置生成: 在生成所有可能的配置或选项组合时,可以使用 product。
- 测试用例生成: 在生成自动化测试的测试用例时,product 可以用于生成所有可能的输入组合。
itertools.permutations
itertools.permutations 是 Python itertools 模块中的一个函数,用于生成输入可迭代对象中元素的所有可能排列(即所有可能的顺序组合)。它返回一个迭代器,该迭代器生成的元素是输入元素的不同排列。
用法
itertools.permutations(iterable, r=None)
- iterable: 需要排列的输入可迭代对象。
- r: 排列的长度。如果未指定,默认使用可迭代对象的全部长度。
特性
- 全排列: 默认情况下,permutations 生成输入可迭代对象中元素的全排列。
- 指定长度: 可以通过参数 r 指定排列的长度,从而生成部分排列。
- 适用范围广: 可以用于任何可迭代对象,包括列表、元组、字符串等。
基本用法
假设我们有一个简单的列表,并希望生成其元素的全排列。
import itertools # 数据序列 data = [1, 2, 3] # 使用 permutations 生成全排列 result = itertools.permutations(data) print(list(result)) # 输出: [(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
指定排列长度
假设我们有一个列表,并希望生成其元素的长度为2的排列。
import itertools # 数据序列 data = [1, 2, 3] # 使用permutations生成长度为2的排列 result = itertools.permutations(data, 2) print(list(result)) # 输出: [(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)]
处理字符串
假设我们有一个字符串,并希望生成其字符的全排列。
import itertools
# 字符串数据
s = "ABC"
# 使用permutations生成全排列
result = itertools.permutations(s)
print(list(result))
# 输出: [('A', 'B', 'C'), ('A', 'C', 'B'), ('B', 'A', 'C'), ('B', 'C', 'A'), ('C', 'A', 'B'), ('C', 'B', 'A')]
注意事项
- 输出大小: 排列的数量是n!(阶乘),其中n是输入可迭代对象的长度。因此,在处理大数据集时可能会生成非常多的排列。
- 惰性求值: permutations 是惰性求值的,这意味着它不会一次性将所有排列加载到内存中,而是逐个生成。
- 输入可迭代对象: 可以是任意可迭代对象,但生成的排列是元素的元组形式。
实际应用场景
- 组合与优化: 在组合优化问题中,permutations提供了一种生成所有可能排列的简单方法。
- 密码破解: 在尝试所有可能的密码组合时,可以使用permutations。
- 路径规划: 在路径规划问题中,可以生成所有可能的节点访问顺序以找到最优路径。
itertools.combinations
itertools.combinations是Python itertools模块中的一个函数,用于生成输入可迭代对象中元素的所有可能组合。与排列不同,组合不考虑元素的顺序。combinations返回一个迭代器,该迭代器生成的元素是输入元素的不同组合。
用法
itertools.combinations(iterable, r)
- iterable: 需要组合的输入可迭代对象。
- r: 组合的长度。
特性
- 组合: combinations 生成输入可迭代对象中元素的所有可能组合,且不考虑顺序。
- 固定长度: 必须指定组合的长度r,从而生成指定长度的组合。
- 适用范围广: 可以用于任何可迭代对象,包括列表、元组、字符串等。
基本用法
假设我们有一个简单的列表,并希望生成其元素的长度为2的组合。
import itertools # 数据序列 data = [1, 2, 3] # 使用combinations生成长度为2的组合 result = itertools.combinations(data, 2) print(list(result)) # 输出: [(1, 2), (1, 3), (2, 3)]
处理字符串
假设我们有一个字符串,并希望生成其字符的长度为2的组合。
import itertools
# 字符串数据
s = "ABC"
# 使用combinations生成长度为2的组合
result = itertools.combinations(s, 2)
print(list(result))
# 输出: [('A', 'B'), ('A', 'C'), ('B', 'C')]
生成全组合
假设我们有一个列表,并希望生成其所有可能的组合。
import itertools
# 数据序列
data = [1, 2, 3]
# 生成所有可能的组合
all_combinations = []
for r in range(1, len(data)+1):
all_combinations.extend(itertools.combinations(data, r))
print(all_combinations)
# 输出: [(1,), (2,), (3,), (1, 2), (1, 3), (2, 3), (1, 2, 3)]
注意事项
- 输出大小: 组合的数量是n!/(r!*(n-r)!),其中n是输入可迭代对象的长度,r是组合的长度。
- 惰性求值: combinations 是惰性求值的,这意味着它不会一次性将所有组合加载到内存中,而是逐个生成。
- 输入可迭代对象: 可以是任意可迭代对象,但生成的组合是元素的元组形式。
实际应用场景
- 选择问题: 在需要从一组元素中选择特定数量的元素时,combinations提供了一种简单的方法。
- 概率计算: 在计算组合概率时,可以使用combinations 生成所有可能的组合。
- 数据分析: 在数据分析中,可以用于生成特定长度的特征组合以进行特征选择或模型训练。
itertools.combinations_with_replacement
itertools.combinations_with_replacement是Python itertools模块中的一个函数,用于生成输入可迭代对象中元素的所有可能组合,允许每个元素被选择多次。与itertools.combinations不同的是,combinations_with_replacement允许元素在组合中重复出现。
用法
itertools.combinations_with_replacement(iterable, r)
- iterable: 需要组合的输入可迭代对象。
- r: 组合的长度。
特性
- 组合: combinations_with_replacement 生成输入可迭代对象中元素的所有可能组合,允许重复元素。
- 固定长度: 必须指定组合的长度r,从而生成指定长度的组合。
- 适用范围广: 可以用于任何可迭代对象,包括列表、元组、字符串等。
示例
基本用法
假设我们有一个简单的列表,并希望生成其元素的长度为2的组合,允许重复。
import itertools # 数据序列 data = [1, 2, 3] # 使用combinations_with_replacement生成长度为2的组合 result = itertools.combinations_with_replacement(data, 2) print(list(result)) # 输出: [(1, 1), (1, 2), (1, 3), (2, 2), (2, 3), (3, 3)]
处理字符串
假设我们有一个字符串,并希望生成其字符的长度为2的组合,允许重复。
import itertools
# 字符串数据
s = "AB"
# 使用 combinations_with_replacement 生成长度为 2 的组合
result = itertools.combinations_with_replacement(s, 2)
print(list(result))
# 输出: [('A', 'A'), ('A', 'B'), ('B', 'B')]
注意事项
- 输出大小: 组合的数量是 (n+r-1)!/(r!*(n-1)!),其中 n 是输入可迭代对象的长度,r 是组合的长度。
- 惰性求值: combinations_with_replacement 是惰性求值的,这意味着它不会一次性将所有组合加载到内存中,而是逐个生成。
- 输入可迭代对象: 可以是任意可迭代对象,但生成的组合是元素的元组形式。
实际应用场景
- 多重选择问题: 在需要从一组元素中选择特定数量的元素,并允许重复选择时,combinations_with_replacement 提供了一种简单的方法。
- 数学问题: 在数学问题中,例如生成多项式项的所有可能组合时,可以使用该函数。
- 数据分析: 在数据分析中,可以用于生成特定长度的特征组合以进行特征选择或模型训练,允许重复使用特征。
参考链接:


