我们都知道,在 Python 中,我们可以 for 循环去遍历一个列表,元组或者 range 对象。那底层的原理是什么样的呢?
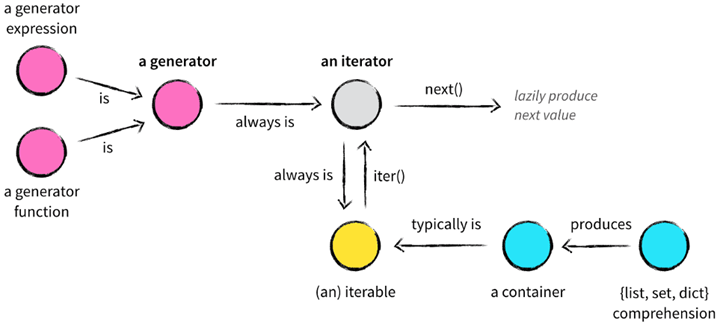
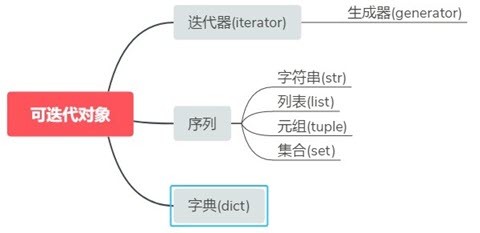
在了解 Python 的数据结构时,容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)、列表/集合/字典推导式(list, set, dict comprehension)等众多概念参杂在一起,让初学者一头雾水。他们之间的关系:
容器(container)
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用 in, not in 关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特例,并不是所有的元素都放在内存,比如迭代器和生成器对象)在 Python 中,常见的容器对象有:
- list, deque, ….
- set, frozensets, ….
- dict, defaultdict, OrderedDict, Counter, ….
- tuple, namedtuple, …
- str
从技术角度来说,当它可以用来询问某个元素是否包含在其中时,那么这个对象就可以认为是一个容器,比如列表、集合、元组都是容器对象。一般容器都是可迭代对象,但并非所有容器都可迭代。
可迭代对象(iterable)
对于 Python 中的任意对象,只要定义了可以返回⼀个迭代器的 __iter__ ⽅法,或者定义了以⽀持下标索引的 __getitem__ ⽅法,则该对象为可迭代对象。在 Python 中,所有的容器,比如列表、元组、字典、集合等,都是可迭代的(iterable)。
判断是否可迭代对象的方法:
from collections.abc import Iterable
def iterable_test_1(obj):
return isinstance(obj, Iterable)
def iterable_test_2(obj):
try:
iter(obj)
return True
except TypeError:
return False
def iterable_test_3(obj):
try:
for i in obj:
pass
return True
except TypeError:
return False
if __name__ == "__main__":
print(iterable_test_1("Hello World!"))
print(iterable_test_2("Hello World!"))
print(iterable_test_3("Hello World!"))
print(iterable_test_1(123))
print(iterable_test_2(123))
print(iterable_test_3(123))
在实际应用推荐使用 isinstance() 进行判断。
迭代器(iterator)
迭代器指的是迭代取值的工具;迭代是一重复的过程;每一次重复都是基于上一次的结果而来;迭代器提供了一种通用的且不依赖于索引的迭代取值方式。
迭代器不仅要实现 __iter__ 方法,还需要实现 __next__ 方法:
- __iter__:返回迭代器本身 self。
- __next__:返回迭代器下一个可用的元素,当最后没有元素时抛出 StopIteration 异常。
迭代器的特点:
- 迭代器一定是可迭代对象,因为实现了 __iter__ 方法。
- 迭代器的 __iter__ 方法返回的是自身,并不产生新的迭代器对象,只能遍历一次。若想再次迭代需要重建迭代器。
- 迭代器是惰性计算,只有在调用时才返回值,没有调用的时候就等待下一次调用。这样就节省了大量内存空间。
迭代器协议:对象必须提供一个 next 方法,执行该方法要么返回迭代的下一项,要么就引起一个 StopIteration 异常,以终止迭代(只能往后走不能往前推)。
优点:
- 提供一种通用的且不依赖于索引的迭代取值方式
- 同一时刻在内存中只存在一个值,更节省内存
缺点:
- 取值不如按照索引的方式灵活,(不能取指定的某一个值,而且只能往后取)
- 无法预测迭代器的长度
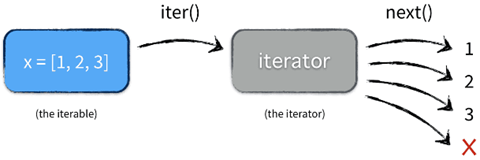
# 创建一个迭代器类
class Fib:
def __init__(self):
self.prev = 0
self.curr = 1
def __iter__(self):
return self
def __next__(self):
value = self.curr
self.curr += self.prev
self.prev = value
if value > 500:
raise StopIteration
return value
print(Fib())
# 根据可迭代对象创建一个迭代器
lst = [1, 2, 3]
res = iter(lst)
print(res)
# 判断可迭代对象是否为迭代器
from collections.abc import Iterator
print(isinstance(lst, Iterator))
print(isinstance(res, Iterator))
生成器(generator)
一个生成器既是可迭代的也是迭代器,定义生成器有两种方式:
- 生成器函数(generator function)
- 生成器表达式(generator expression)
生成器函数(generator function)
如果一个函数定义中包含 yield 关键字,则整个函数为生成器函数。在执行生成器函数过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值,并在下一次执行 next() 方法时从当前位置继续运行。
def fibonacci(n):
a, b, counter = 1, 1, 0
while counter < n:
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10)
print(next(f))
print(next(f))
print('----')
for item in f:
print(item)
生成器函数的外观和行为与常规函数一样,但具有一个定义特征。生成器函数使用 Python yield 关键字而不是 return。yield 指示将值发送回调用者的位置,与 return 不同的是之后您不会退出该函数。相反,它会记住函数的状态。这样,当 next() 在生成器对象上调用时(在 for 循环中显式或隐式)会再次生成值。
生成器表达式 (generator expression)
生成器表达式是列表推倒式的生成器版本,看起来像列表推导式,但是它返回的是一个生成器对象而不是列表对象。生成器表达式是按需求计算(或称惰性计算),需要的时候才计算值,返回一个迭代器,而列表解析式是立即返回值,返回可迭代对象列表。在内存占用上,生成器表达式要更省内存。
nums_squared_lc = [num**2 for num in range(5)]
nums_squared_gc = (num**2 for num in range(5))
if __name__ == "__main__":
print(nums_squared_lc)
print(nums_squared_gc)
# 输出
# [0, 1, 4, 9, 16]
# <generator object <genexpr> at 0x0000022D4FD5EDC8>
生成器使用示例
示例1:读取大文件
生成器的一个常见用例是处理数据流或大文件,如 CSV 文件。现在,如果您想计算 CSV 文件中的行数怎么办?以下代码给出了一些思路:
csv_gen = csv_reader("some_csv.txt")
row_count = 0
for row in csv_gen:
row_count += 1
print(f"Row count is {row_count}")
你可能希望 csv_gen 是一个列表。要填充此列表,需要 csv_reader() 打开一个文件并将其内容加载到 csv_gen. 然后,程序遍历列表并 row_count 为每一行递增。
这是一个合理的逻辑,但是如果文件非常大,这种设计是否仍然有效?如果文件大于可用内存怎么办?我们先假设 csv_reader() 只是打开文件并将其读入数组:
def csv_reader(file_name):
file = open(file_name)
result = file.read().split("\n")
return result
此函数打开一个给定的文件,并使用 file.read()、with.split() 将每一行作为单独的元素添加到列表中。当执行时你可能获得如下输出:
Traceback (most recent call last):
File "ex1_naive.py", line 22, in <module>
main()
File "ex1_naive.py", line 13, in main
csv_gen = csv_reader("file.txt")
File "ex1_naive.py", line 6, in csv_reader
result = file.read().split("\n")
MemoryError
在这种情况下,open() 返回一个生成器对象,您可以逐行懒惰地迭代它。但是,file.read().split() 一次将所有内容加载到内存中,导致 MemoryError。那么,如何处理这些庞大的数据文件呢?看看重新定义 csv_reader():
def csv_reader(file_name):
for row in open(file_name, "r"):
yield row
在这个版本中,你打开文件,遍历它,并产生一行。此代码应产生以下输出,没有内存错误。这里发生了什么事?实际上你将 csv_reader() 变成了一个生成器函数。打开一个文件,遍历每一行,并产生每一行,而不是返回它。
您还可以定义生成器表达式,其语法与列表推导式非常相似。这样就可以不用调用函数就可以使用生成器了:
csv_gen = (row for row in open(file_name))
示例2:生成无限序列
在 Python 中,要获得有限序列,您 range() 可以在列表上下文中调用并评估它:
a = range(5) print(list(a))
但是,生成无限序列需要使用生成器,因为您的计算机内存是有限的:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
if __name__ == "__main__":
for i in infinite_sequence():
print(i, end="")
程序将一致执行直到你手动停止它。除了使用 for 循环,您还可以 next() 直接调用生成器对象。这对于在控制台中测试生成器特别有用:
gen = infinite_sequence() print(next(gen))
示例3:回文探测
您可以通过多种方式使用无限序列,但它们的一个实际用途是构建回文探测器。一个回文探测器将找到所有的字母或序列是回文。就是向前和向后能够读取到相同的单词或数字,例如 121。首先,定义您的数字回文探测器:
def infinite_sequence():
num = 0
while True:
yield num
num += 1
def is_palindrome(num):
# Skip single-digit inputs
if num // 10 == 0:
return False
temp = num
reversed_num = 0
while temp != 0:
reversed_num = (reversed_num * 10) + (temp % 10)
temp = temp // 10
if num == reversed_num:
return num
else:
return False
if __name__ == "__main__":
for i in infinite_sequence():
pal = is_palindrome(i)
if pal:
print(i)
不要太担心理解这段代码中的基础数学。该函数接受一个输入数字,将其反转,并检查反转后的数字是否与原始数字相同。打印到控制台的唯一数字是那些向前或向后相同的数字。
生成器性能
您之前了解到生成器是优化内存的好方法。虽然无限序列生成器是这种优化的一个极端示例,但让我们放大您刚刚看到的数字平方示例并检查结果对象的大小。你可以通过调用来做到这一点 sys.getsizeof():
nums_squared_lc = [num**2 for num in range(10000)]
nums_squared_gc = (num**2 for num in range(10000))
if __name__ == "__main__":
import sys
print(sys.getsizeof(nums_squared_lc))
print(sys.getsizeof(nums_squared_gc))
# 输出
# 87624
# 120
在这种情况下,您从列表推导中得到的列表是87624个字节,而生成器对象只有120个。这意味着列表比生成器对象大700多倍!不过,有一件事情要记住。如果列表小于运行机器的可用内存,那么列表推导式的计算速度会比等效的生成器表达式更快:
import cProfile
print(cProfile.run('sum([i*2 for i in range(10000)])'))
print(cProfile.run('sum((i*2 for i in range(10000)))'))
# 输出
# 5 function calls in 0.001 seconds
#
# Ordered by: standard name
#
# ncalls tottime percall cumtime percall filename:lineno(function)
# 1 0.001 0.001 0.001 0.001 <string>:1(<listcomp>)
# 1 0.000 0.000 0.001 0.001 <string>:1(<module>)
# 1 0.000 0.000 0.001 0.001 {built-in method builtins.exec}
# 1 0.000 0.000 0.000 0.000 {built-in method builtins.sum}
# 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
#
#
# None
# 10005 function calls in 0.002 seconds
#
# Ordered by: standard name
#
# ncalls tottime percall cumtime percall filename:lineno(function)
# 10001 0.001 0.000 0.001 0.000 <string>:1(<genexpr>)
# 1 0.000 0.000 0.002 0.002 <string>:1(<module>)
# 1 0.000 0.000 0.002 0.002 {built-in method builtins.exec}
# 1 0.001 0.001 0.002 0.002 {built-in method builtins.sum}
# 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
#
#
# None
高级生成器方法
您已经看到了生成器最常见的用途和构造,但还有一些技巧需要介绍。除了 yield 之外,生成器对象还可以使用以下方法:
- .send()
- .throw()
- .close()
如何使用 .send()
def infinite_palindromes():
num = 0
while True:
if is_palindrome(num):
i = (yield num)
if i is not None:
num = i
num += 1
def is_palindrome(num):
# Skip single-digit inputs
if num // 10 == 0:
return False
temp = num
reversed_num = 0
while temp != 0:
reversed_num = (reversed_num * 10) + (temp % 10)
temp = temp // 10
if num == reversed_num:
return True
else:
return False
if __name__ == "__main__":
pal_gen = infinite_palindromes()
for i in pal_gen:
digits = len(str(i))
pal_gen.send(10 ** (digits))
print(i)
这个程序将像以前一样打印数字回文,但有一些调整。遇到回文时,您的新程序将添加一个数字并从那里开始搜索下一个。
- infinite_palindromes() 中 i = (yield num),检查 if i is not None,如果 next() 在生成器对象上调用可能会发生这种情况。
- send(),将执行 10 ** digits 给 i,更新 num
你在这里创建的是一个 coroutine(协程),或者一个可以传递数据的生成器函数。这些对于构建数据管道很有用。
如何使用 .throw()
.throw() 允许您使用生成器抛出异常。在下面的示例中,此代码将在抛出 digits = 5 时抛出 ValueError:
if __name__ == "__main__":
pal_gen = infinite_palindromes()
for i in pal_gen:
print(i)
digits = len(str(i))
if digits == 5:
pal_gen.throw(ValueError("We don't like large palindromes"))
pal_gen.send(10 ** (digits))
print(i)
.throw() 在您可能需要捕获异常的任何领域都很有用。
如何使用 .close()
顾名思义,.close() 允许您停止生成器。这在控制无限序列生成器时特别方便。
if __name__ == "__main__":
pal_gen = infinite_palindromes()
for i in pal_gen:
print(i)
digits = len(str(i))
if digits == 5:
pal_gen.close()
pal_gen.send(10 ** (digits))
print(i)
.close() 是它引发了 StopIteration 一个异常,用于表示有限迭代器的结束。
使用生成器创建数据管道
file_name = "techcrunch.csv"
lines = (line for line in open(file_name))
list_line = (s.rstrip().split(",") for s in lines)
cols = next(list_line)
company_dicts = (dict(zip(cols, data)) for data in list_line)
funding = (int(company_dict["raisedAmt"]) for company_dict in company_dicts if company_dict["round"] == "a")
total_series_a = sum(funding)
print(f"Total series A fundraising: ${total_series_a}")
for 循环工作机制
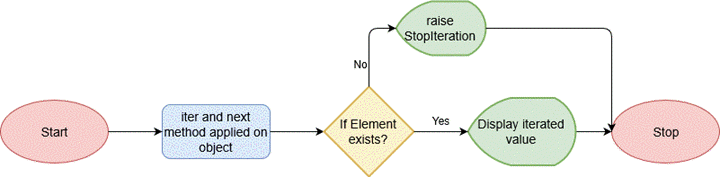
在介绍了可迭代对象和迭代器,我们进一步总结一下可迭代对象和迭代器中的 for 循环工作机制。
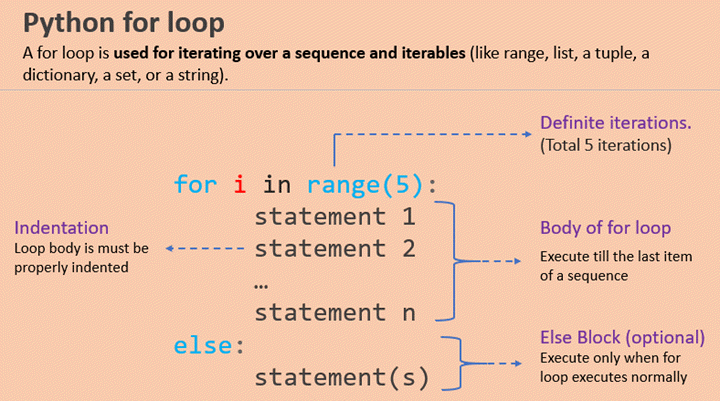
可迭代对象中 for 循环工作机制:
- 先判断对象是否为可迭代对象(等价于判断有没有 iter 或 getitem 方法),如果不可迭代则抛出 TypeError 异常。如果为可迭代对象则调用 __iter__ 方法,返回一个迭代器。
- 不断调用迭代器的 __next__ 方法,每次按序返回迭代器中的一个值。
- 迭代到最后没有元素时,就抛出异常 StopIteration。这个异常 Python 自己会处理,不会暴露给开发者。
迭代器中 for 循环工作机制:
- 调用 __iter__ 方法,返回自身 self,也就是返回迭代器。
- 不断调用迭代器的 next() 方法,每次按序返回迭代器中的一个值。
- 迭代到最后没有元素时,就抛出异常 StopIteration。
在 Python 中,for 循环兼容两种机制:
- 如果对象定义了 __iter__,则会返回一个迭代器。
- 如果对象没有定义 __iter__,但是实现了 __getitem__,会改用下标迭代的方式。
当 for 循环发现没有 __iter__ 但是有 __getitem__ 的时候,会从 0 开始依次读取相应的下标,直到发生 IndexError 为止。iter() 方法也会处理这种情况,在不存在 __iter__ 的时候,返回一个下标的迭代器对象来代替。
标准库中的生成器函数
用于过滤的生成器函数:
| 模块 | 函数 | 说明 |
| itertools | compress(it, selector_it) | 并行处理两个可迭代对象。若 selector_it 中的元素是真值,产出 it 中对应的元素 |
| itertools | dropwhile(predicate, it) | 把可迭代对象 it 中的元素传给 predicate,跳过 predicate(item) 为真值的元素,在 predicate(item) 为假时停止,产出剩余(未跳过)的所有元素(不再继续检查) |
| 内置 | filter(predicate, it) | 把 it 中的各个元素传给 predicate,若 predicate(item) 返回真值,产出对应元素 |
| itertools | filterfalse(predicate, it) | 与 filter 函数类似,不过 predicate(item) 返回假值时产出对应元素 |
| itertools | takewhile(predicate, it) | predicate(item) 返回真值时产出对应元素,然后立即停止不再继续检查 |
| itertools | islice(it, stop) 或 islice(it, start, stop, step=1) | 产出 it 的切片,作用类似于 s[:stop] 或 s[start:stop:step],不过 it 可以是任何可迭代对象,且实现的是惰性操作 |
用于映射的生成器函数:
| 模块 | 函数 | 说明 |
| itertools | accumulate(it, [func]) | 产出累积的总和。若提供了 func,则把 it 中的前两个元素传给 func,再把计算结果连同下一个元素传给 func,以此类推,产出结果 |
| 内置 | enumerate(it, start=0) | 产出由两个元素构成的元组,结构是 (index, item)。其中 index 从 start 开始计数,item 则从 it 中获取 |
| 内置 | map(func, it1, [it2, …, itN]) | 把 it 中的各个元素传给 func,产出结果;若传入 N 个可迭代对象,则 func 必须能接受 N 个参数,且并行处理各个可迭代对象 |
合并多个可迭代对象的生成器函数:
| 模块 | 函数 | 说明 |
| itertools | chain(it1, …, itN) | 先产出 it1 中的所有元素,然后产出 it2 中的所有元素,以此类推,无缝连接 |
| itertools | chain.from_iterable(it) | 产出 it 生成的各个可迭代对象中的元素,一个接一个无缝连接;it 中的元素应该为可迭代对象(即 it 是嵌套了可迭代对象的可迭代对象) |
| itertools | product(it1, …, itN, repeat=1) | 计算笛卡尔积。从输入的各个可迭代对象中获取元素,合并成 N 个元素组成的元组,与嵌套的 for 循环效果一样。repeat 指明重复处理多少次输入的可迭代对象 |
| 内置 | zip(it1, …, itN) | 并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组。只要其中任何一个可迭代对象到头了,就直接停止 |
| itertools | zip_longest(it1, …, itN, fillvalue=None) | 并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组,等到最长的可迭代对象到头后才停止。空缺的值用 fillvalue 填充 |
用于重新排列元素的生成器函数:
| 模块 | 函数 | 说明 |
| itertools | groupby(it, key=None) | 产出由两个元素组成的元素,形式为 (key, group),其中 key 是分组标准,group 是生成器,用于产出分组里的元素 |
| 内置 | reversed(seq) | 从后向前,倒序产出 seq 中的元素;seq 必须是序列,或者实现了 __reversed__ 特殊方法的对象 |
| itertools | tee(it, n=2) | 产出一个有 n 个生成器组成的元组,每个生成器都可以独立地产出输入的可迭代对象中的元素 |
读取迭代器,返回单个值的函数:
| 模块 | 函数 | 说明 |
| 内置 | all(it) | it 中的所有元素都为真值时返回 True,否则返回 False;all([]) 返回 True |
| 内置 | any(it) | 只要 it 中有元素为真值就返回 True,否则返回 False;any([]) 返回 False |
| 内置 | max(it, [key=], [default=]) | 返回 it 中值最大的元素;key 是排序函数,与 sorted 中的一样;若可迭代对象为空,返回 default |
| 内置 | min(it, [key=], [default=]) | 返回 it 中值最小的元素;key 是排序函数;若可迭代对象为空,返回 default |
| functools | reduce(func, it, [initial]) | 把前两个元素传给 func,然后把计算结果和第三个元素传给 func,以此类推,返回最后的结果。若提供了 initial,则将其作为第一个元素传入 |
| 内置 | sum(it, start=0) | it 中所有元素的总和,若提供可选的 start,会把它也加上 |
参考链接: