Seaborn简介
Seaborn是一个基于Python的数据可视化库,它建立在Matplotlib库之上,提供了更高级的接口用于绘制统计图形。Seaborn的目标是使复杂的数据可视化工作变得更加简单和直观,同时生成具有吸引力、信息丰富的图形。它特别适合于探索性和解释性数据分析任务。下面是一些Seaborn的关键特性和功能:
- 数据集的高级接口:Seaborn设计了许多高级函数,可以直接从Pandas DataFrame中读取数据并进行绘图,这使得数据准备和可视化流程更加流畅。
- 内置主题和颜色palette:Seaborn提供了一系列预设的主题(如darkgrid, whitegrid, dark, white, ticks),以及精心设计的颜色调色板,帮助用户轻松地提升图表的视觉效果和专业度。
- 复杂统计图形:与Matplotlib相比,Seaborn更侧重于统计图形的绘制,如热力图、联合分布图、箱线图、小提琴图、SwarmPlot(散点分布图)、PairPlot(成对关系图)等,这些图形有助于展示数据的分布、相关性和复杂关系。
- Faceting(分面):Seaborn允许用户轻松地通过数据的一个或多个维度创建分面图,即根据不同的变量将数据分成多个子集,并为每个子集绘制一个图形。这对于探索数据中的模式和差异非常有用。
- Categorical Plotting(分类数据绘图):提供了多种针对分类数据的绘图方法,如条形图、点图、箱线图等,可以清晰地展示类别间的比较和分布情况。
- Regression Plotting(回归绘图):支持绘制带有回归线的散点图,以及更复杂的回归模型可视化,如残差图,这有助于分析变量间的关系和模型拟合情况。
- 分布估计和核密度图:Seaborn能够绘制数据的核密度估计图,帮助理解数据的连续分布特征。
- 与Pandas和Matplotlib的紧密集成:Seaborn能够很好地与Pandas的DataFrame对象配合使用,同时也保留了对Matplotlib的底层访问能力,这意味着用户可以在Seaborn的基础上进一步定制图形。
Seaborn的使用
Seaborn一共拥有50多个API类,相比于Matplotlib数千个的规模,可以算作是短小精悍了。其中,根据图形的适应场景,Seaborn的绘图方法大致分类6类,分别是:关联图、类别图、分布图、回归图、矩阵图和组合图。而这6大类下面又包含不同数量的绘图函数。
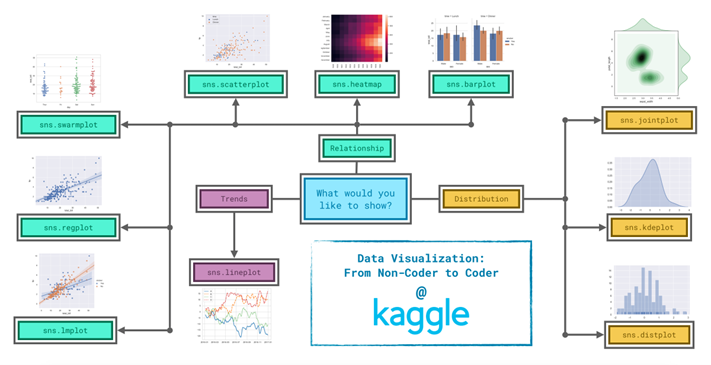
Relational plots(关联图)
数据分析中就是理解变量如何相互关联,当这些关系被正确可视化时,我们往往可以从中获取某种关系或模式。
当我们需要对数据进行关联性分析时,可能会用到Seaborn提供的以下几个API。
- scatterplot多维度分析散点图
- lineplot多维度分析线形图
- relplot绘制关系图
scatterplot(散点图)
Seaborn的scatterplot函数用于绘制散点图,是数据可视化中一种非常常用的图表类型。散点图通过在二维平面上绘制数据点来展示两个变量之间的关系。Seaborn的scatterplot提供了许多强大的功能,使用户能够轻松地对数据进行分组、着色和标记。以下是对scatterplot的一些详细介绍:
seaborn.scatterplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=True, style_order=None, legend='auto', ax=None, **kwargs)
Seaborn函数中的参数特别多,但是其实大部分都是相同的,因此,我们可以很容易类推到其他函数的使用。下面简单介绍这些参数的含义。
data(数据):pandas.DataFrame、numpy.ndarray、映射或序列。输入的数据结构。可以是一个长格式的向量集合,可以分配给命名变量,也可以是一个宽格式的数据集,内部将自动重塑。
- x,y(x和y):向量或数据中的键。指定x轴和y轴位置的变量。
- hue(色调):向量或数据中的键。分组变量,将根据不同的颜色生成点。可以是分类变量或数值变量,尽管在后者情况下颜色映射的行为会有所不同。
- size(大小):向量或数据中的键。分组变量,将根据不同的大小生成点。可以是分类变量或数值变量,尽管在后者情况下大小映射的行为会有所不同。
- style(样式):向量或数据中的键。分组变量,将根据不同的标记生成点。可以具有数值dtype,但始终被视为分类变量。
- palette(调色板):字符串、列表、字典或colors.Colormap。选择在映射色调语义时使用的颜色的方法。字符串值传递给color_palette()。列表或字典值意味着分类映射,而颜色图对象意味着数值映射。
- hue_order(色调顺序):字符串向量。指定色调语义的分类级别的处理和绘图顺序。
- hue_norm(色调归一化):元组或colors.Normalize。可以是一对设置数据单位内归一化范围的值,或一个将数据单位映射到[0,1]区间的对象。使用这个参数意味着数值映射。
- sizes(尺寸):列表、字典或元组。当使用size时,决定如何选择尺寸的对象。列表或字典参数应为每个唯一的数据值提供一个尺寸,强制进行分类解释。参数也可以是(min,max)元组。
- size_order(尺寸顺序):列表。指定尺寸变量级别出现的顺序,否则由数据决定。当尺寸变量为数值时不相关。
- size_norm(尺寸归一化):元组或Normalize对象。以数据单位进行归一化,用于在尺寸变量为数值时缩放绘图对象。
- markers(标记):布尔值、列表或字典。决定如何为不同级别的样式变量绘制标记的对象。设置为True将使用默认标记,或者可以传递标记列表或将样式变量级别映射到标记的字典。设置为False将绘制无标记线。标记的指定方式与matplotlib相同。
- style_order(样式顺序):列表。指定样式变量级别出现的顺序,否则由数据决定。当样式变量为数值时不相关。
- legend(图例):“auto”、“brief”、“full”或False。决定如何绘制图例。如果为“brief”,则会用均匀间隔的值样本来表示数值色调和大小变量。如果为“full”,则每个组都会在图例中获得一个条目。如果为“auto”,则根据级别数量在“brief”和“full”表示之间进行选择。如果为False,则不会添加图例数据,也不会绘制图例。
- ax(坐标轴):axes.Axes。用于绘图的预先存在的轴。否则,内部调用matplotlib.pyplot.gca()。
- kwargs(关键字参数):键值映射。其他关键字参数传递给axes.Axes.scatter()。
使用演示,由于seaborn的load_dataset需要请求境外地址,无法下载数据集,这里的数据从mwaskom/seaborn-data: Data repository for seaborn examples (github.com)手动获取。
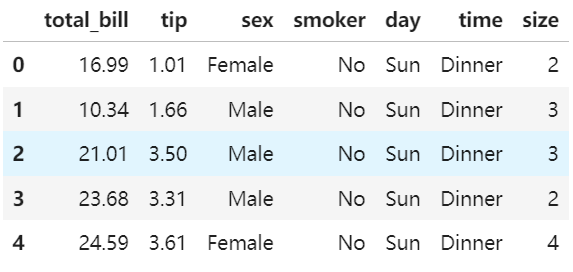
首先是加载数据集:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# tips = sns.load_dataset('tips')
tips = pd.read_csv("seaborn-data/tips.csv")
tips.head()
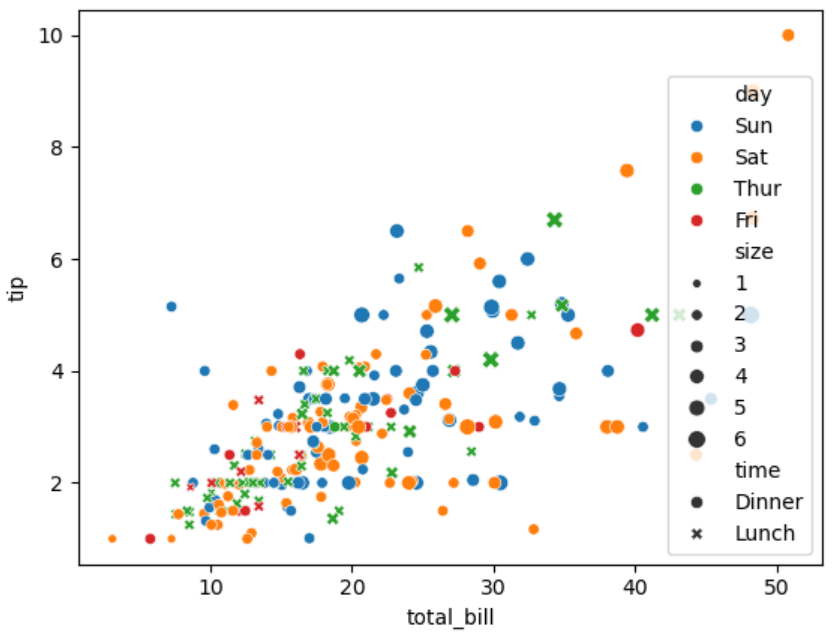
示例:
sns.scatterplot(data=tips, x='total_bill', y='tip', hue='day', style='time', size='size')
lineplot(线图)
Seaborn的lineplot函数用于绘制线图,是用于观察时间序列数据、展示变量间相对关系和趋势的非常有用的工具。线图通过在平面上连接数据点来显示数据的变化趋势。Seaborn的lineplot功能强大,提供了许多选项来处理数据的不同方面。以下是对lineplot的一些详细介绍:
seaborn.lineplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, units=None, weights=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, dashes=True, markers=None, style_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, orient='x', sort=True, err_style='band', err_kws=None, legend='auto', ci='deprecated', ax=None, **kwargs)
由于lineplot参数差不多,以下为独有参数:
- units:向量或数据中的键。识别采样单元的分组变量。使用时,将为每个单元绘制一条单独的线条,但不会添加图例条目。适用于不需要精确身份时显示实验重复的分布。
- weights:向量或数据中的键。用于计算加权估计的数据值或列。注意,使用权重会限制统计量的选择,仅为”均值”估计器和”ci”误差条。
- dashes:布尔值、列表或字典。确定如何为style变量的不同级别绘制线条的对象。设置为True将使用默认虚线代码,或者可以传递虚线代码的列表或将style变量级别映射到虚线代码的字典。设置为False将为所有子集使用实线。虚线的指定方法与matplotlib中相同:一个(段、间隙)长度的元组,或一个空字符串绘制实线。
- estimator:pandas方法名、可调用对象或None。在同一x水平上跨多个y变量观测值进行聚合的方法。如果为None,将绘制所有观测值。
- errorbar:字符串、(字符串,数字)元组或可调用对象。误差条方法的名称(可以是”ci”、”pi”、”se”或”sd”),或包含方法名称和级别参数的元组,或从向量映射到(最小值,最大值)区间的函数,或None以隐藏误差条。有关详细信息,请参阅误差条教程。
- n_boot:整数。用于计算置信区间的自助法次数。
- seed:整数、random.Generator或numpy.random.RandomState。可重复的自助法的种子或随机数生成器。
- orient:”x”或”y”。数据排序/聚合的维度。等效于结果函数的”自变量”。
- sort:布尔值。如果为True,数据将按x和y变量排序,否则线条将按数据集中出现的顺序连接点。
- err_style:”band”或”bars”。是否使用半透明误差带或离散误差条绘制置信区间。
- err_kws:关键字参数的字典。用于控制误差条美学的其他参数。根据err_style,这些参数传递给axes.Axes.fill_between()或matplotlib.axes.Axes.errorbar()。
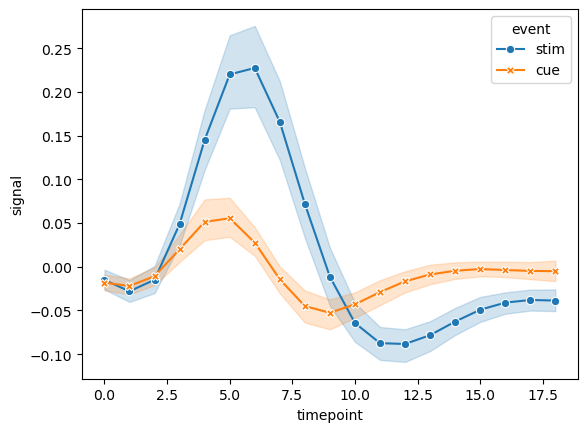
使用示例:
fmri = pd.read_csv("seaborn-data/fmri.csv")
fmri.head()

示例:
sns.lineplot(data=fmri, x="timepoint", y="signal", hue="event", style="event", markers=True, dashes=False)
 、
、
relplot(关系图)
Seaborn的relplot是一个用于绘制关系图的高级接口,它可以生成散点图(scatterplot)或线图(lineplot)。relplot的核心优势在于它建立在FacetGrid之上,允许轻松创建多图布局以探索数据集中不同变量之间的关系。它是一个通用的关系图函数,能够根据需求显示不同类型的关系。
seaborn.relplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, units=None, weights=None, row=None, col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None, style_order=None, legend='auto', kind='scatter', height=5, aspect=1, facet_kws=None, **kwargs)
参数说明:
- row,col:数据中的向量或键。定义要在不同面上绘制的子集的变量。
- col_wrap:整数。根据该宽度”折叠”列变量,以便列面跨越多行。与行面不兼容。
- row_order,col_order:字符串列表。按照指定顺序组织网格的行和/或列,否则顺序从数据对象中推断。
- style_order:列表。指定style变量级别的外观顺序,否则从数据中确定。当style变量是数值时不相关。
- kind:字符串。绘制的图类型,对应于seaborn关系图。选项有”scatter”或”line”。
- height:标量。每个面板的高度(以英寸为单位)。另请参见:aspect。
- aspect:标量。每个面板的纵横比,以便aspect*height给出每个面板的宽度(以英寸为单位)。
- facet_kws:字典。传递给FacetGrid的其他关键字参数的字典。
使用示例:
iris = pd.read_csv("seaborn-data/iris.csv")
iris.head()
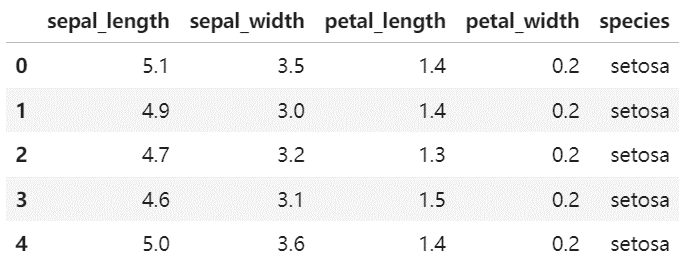
示例:
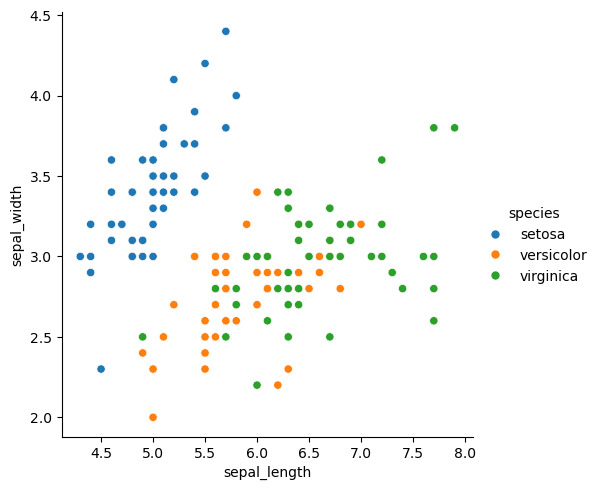
sns.relplot(data=iris, x="sepal_length", y="sepal_width", hue="species", style="species")
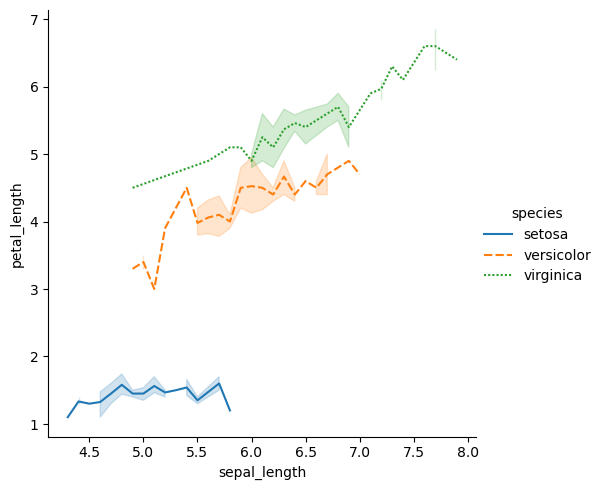
更换展示类型:
sns.relplot(data=iris, x="sepal_length", y="petal_length", hue="species", style="species", kind="line")
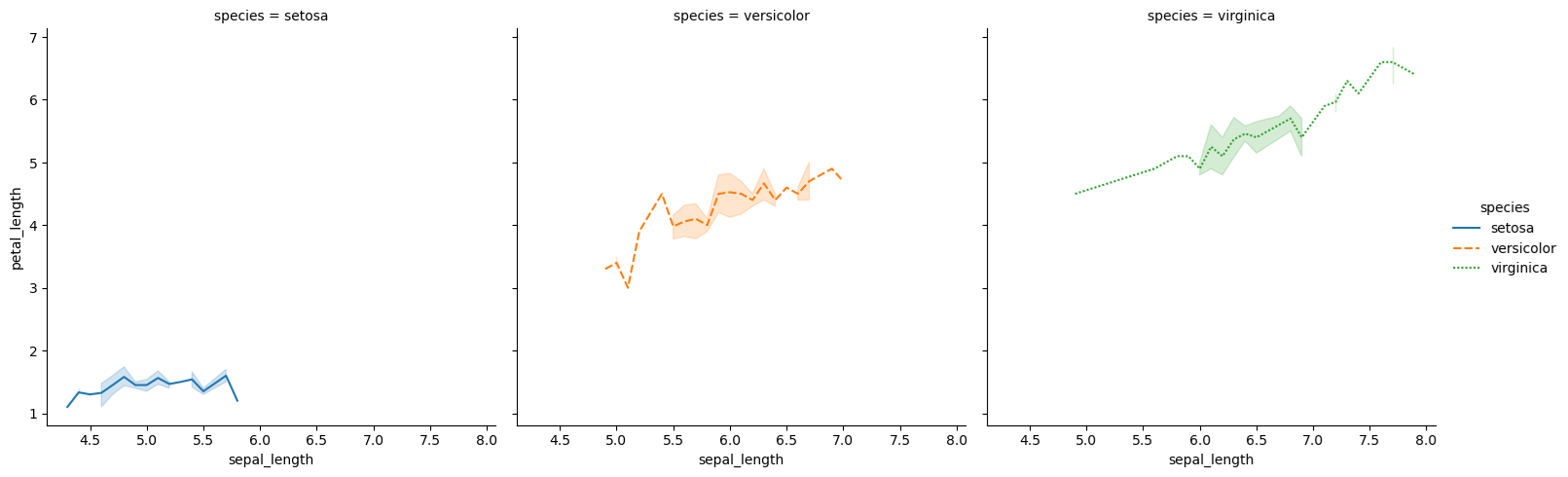
拆分多图展示:
sns.relplot(data=iris, x="sepal_length", y="petal_length", hue="species", style="species", kind="line", col="species")
Categorical plots (类别图)
与关联图相似,类别图的Figure-level接口是catplot,其为categorical plots的缩写。而catplot实际上是如下Axes-level绘图API的集合:
- 分类散点图:
- stripplot() (kind=”strip”)
- swarmplot() (kind=”swarm”)
- 分类分布图:
- boxplot() (kind=”box”)
- violinplot() (kind=”violin”)
- boxenplot() (kind=”boxen”)
- 分类估计图:
- pointplot() (kind=”point”)
- barplot() (kind=”bar”)
- countplot() (kind=”count”)
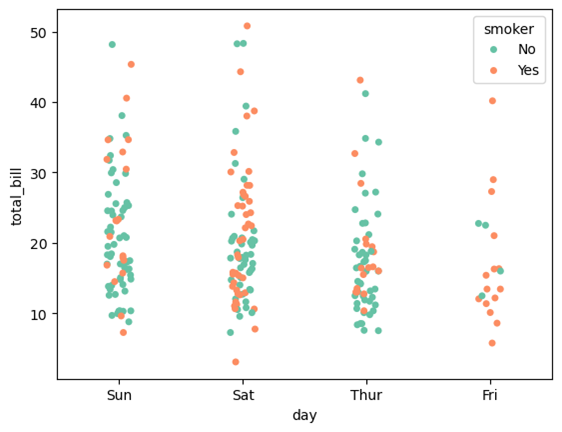
stripplot (分布散点图)
Seaborn的stripplot是用于绘制分类数据的单变量散点图的函数。它通过在一个分类轴上沿另一数值轴绘制数据点,展示每个类别的分布情况。stripplot是一个简单而直观的工具,适合用于显示小型数据集的分布或查看数据的离群点。
seaborn.stripplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, jitter=True, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor=<default>, linewidth=0, hue_norm=None, log_scale=None, native_scale=False, formatter=None, legend='auto', ax=None, **kwargs)
特殊参数说明:
- jitter:浮点数,True/1是特例要应用的抖动量(仅沿分类轴)。当有许多点并且它们重叠时,这可能很有用,以便更容易看到分布。您可以指定抖动量(均匀随机变量支持的一半宽度),或使用True以获得一个不错的默认值。
- dodge:布尔值当分配了hue变量时,将其设置为True会在分类轴上为不同的hue级别分离条带,并缩小每个条带分配的空间。否则,每个级别的点将绘制在同一条带中。
- orient:”v”|”h”|”x”|”y”图的方向(垂直或水平)。这通常根据输入变量的类型推断,但当x和y都是数值或绘制宽格式数据时,它可以用于解决歧义。
- edgecolor:matplotlib颜色,”gray”是特例每个点周围线的颜色。如果传递”gray”,亮度由用于点主体的调色板决定。注意,stripplot默认linewidth=0,因此只有在线宽非零时边缘颜色才可见。
- log_scale:布尔值或数值,或成对的布尔值或数值设置轴比例为对数。单个值为图中任何数值轴设置数据轴。成对的值独立设置每个轴。数值被解释为所需的底数(默认10)。当为None或False时,seaborn遵循现有Axes比例。
- native_scale:布尔值当为True时,分类轴上的数值或日期时间值将保持其原始比例,而不是转换为固定索引。
- formatter:可调用对象用于将分类数据转换为字符串的函数。影响分组和刻度标签。
使用示例:
sns.stripplot(data=tips, x="day", y="total_bill", hue="smoker", jitter=True, palette="Set2", dodge=False)
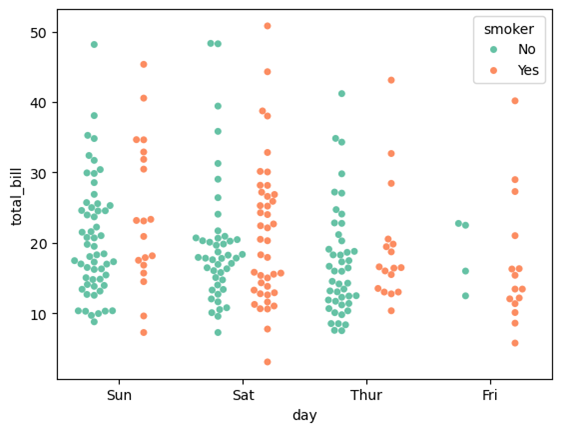
swarmplot (分布密度散点图)
Seaborn的swarmplot是用于绘制分类数据的单变量散点图的函数,与stripplot类似,但通过调整数据点的位置来避免重叠。swarmplot是一种增强型的散点图,通过在分类轴上对数据点进行”蜂群”排列,使得每个数据点都可见,即使在数据点密集的情况下也不例外。这使得swarmplot特别适合用于可视化小型数据集的分布和查看离群点。
seaborn.swarmplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor=None, linewidth=0, hue_norm=None, log_scale=None, native_scale=False, formatter=None, legend='auto', warn_thresh=0.05, ax=None, **kwargs)
使用示例:
sns.swarmplot(data=tips, x="day", y="total_bill", hue="smoker", palette="Set2", dodge=True)
boxplot(箱型图)
Seaborn的boxplot是用于显示数据分布的统计图表,通常用于可视化数据集的中位数、四分位数、以及潜在的异常值。箱线图是一种有效的工具,可以快速总结数据的主要特征,并帮助识别数据中的异常值和分布形态。
seaborn.boxplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, dodge='auto', width=0.8, gap=0, whis=1.5, linecolor='auto', linewidth=None, fliersize=None, hue_norm=None, native_scale=False, log_scale=None, formatter=None, legend='auto', ax=None, **kwargs)
参数说明:
- saturation:浮点数。用于绘制填充颜色的原始饱和度比例。较大的色块通常在去饱和颜色下看起来更好,但如果希望颜色与输入值完全匹配,请将此设置为1。
- fill:布尔值。如果为True,使用实心色块。否则,绘制为线条艺术。
- width:浮点数。在orient轴上分配给每个元素的宽度。当native_scale=True时,相对于本地尺度中两个值之间的最小距离。
- gap:浮点数。按此因子在orient轴上缩小以在错位元素之间添加间隙。
- whis:浮点数或浮点数对。控制须长度的参数。如果为标量,须将绘制到距最近铰链的whis*IQR的最远数据点。如果为元组,则解释为须表示的百分位数。
- linecolor:颜色。用于线条元素的颜色,当fill为True时。
- fliersize:浮点数。用于指示异常观察的标记大小。
使用示例:
sns.boxplot(data=tips, x="day", y="total_bill", hue="time", linewidth=0.5, saturation=1, width=1, fliersize=3)

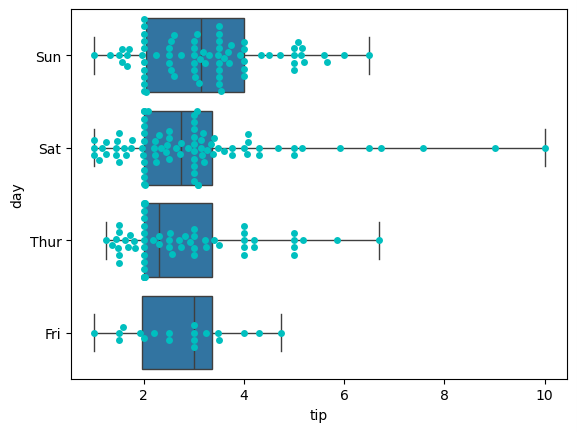
boxplot+swarmplot(箱线图+分布密度散点图):
sns.boxplot(x="tip", y="day", data=tips, whis=np.inf) sns.swarmplot(x="tip", y="day", data=tips, color="c")
violinplot(小提琴图)
Seaborn的violinplot是一种用于可视化数据分布的统计图表,它结合了箱线图和核密度估计的特点。这种图表通过显示数据的分布密度来提供比箱线图更多的信息,特别是在数据集较大时更为明显。下面详细介绍violinplot的使用方法和主要特性。
seaborn.violinplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, inner='box', split=False, width=0.8, dodge='auto', gap=0, linewidth=None, linecolor='auto', cut=2, gridsize=100, bw_method='scott', bw_adjust=1, density_norm='area', common_norm=False, hue_norm=None, formatter=None, log_scale=None, native_scale=False, legend='auto', scale=<deprecated>, scale_hue=<deprecated>, bw=<deprecated>, inner_kws=None, ax=None, **kwargs)
参数说明:
- inner:{“box”,“quart”,“point”,“stick”,None}。小提琴内部的数据表示。以下之一:
- “box”:绘制一个小型箱线图
- “quart”:显示数据的四分位数
- “point”或”stick”:显示每个观察值
- split:布尔值。显示未镜像的分布,在使用hue时交替显示。
- cut:浮点数。以带宽为单位的距离,将密度延伸到极端数据点之外。设置为0以将小提琴限制在数据范围内。
- gridsize:整数。用于评估KDE的离散网格中的点数。
- bw_method:{“scott”,“silverman”,float}。参考规则的名称或计算核带宽时使用的比例因子。实际的核大小将通过将比例因子乘以每组数据的标准差来确定。
- bw_adjust:浮点数。缩放带宽的因子,以使用更多或更少的平滑。
- density_norm:{“area”,“count”,“width”}。用于规范化每个密度以确定小提琴宽度的方法。如果是area,每个小提琴将具有相同的面积。如果是count,宽度将与观察次数成比例。如果是width,每个小提琴将具有相同的宽度。
- common_norm:布尔值。当为True时,规范化所有小提琴的密度。
- inner_kws:键值映射的字典。用于“inner”图的关键字参数,传递给以下之一:
- collections.LineCollection(与inner=”stick”一起使用)
- axes.Axes.scatter()(与inner=”point”一起使用)
- axes.Axes.plot()(与inner=”quart”或inner=”box”一起使用)
- 此外,对于inner=”box”,关键字box_width、whis_width和marker对“box”图的组件进行特殊处理。
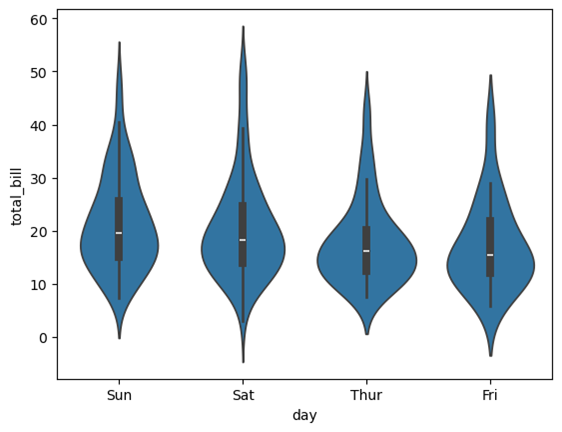
一般呈现:
sns.violinplot(data=tips, x="day", y="total_bill")
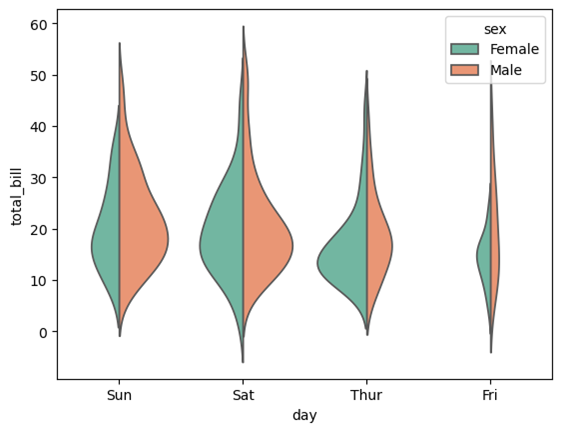
设置按性别分类,调色为“Set2”,分割,以计数的方式,不表示内部:
sns.violinplot(data=tips, x="day", y="total_bill", hue="sex", palette="Set2", split=True, density_norm='count', inner=None)
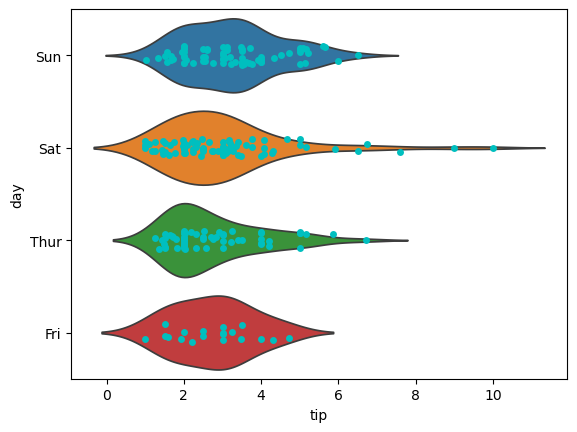
violinplot+stripplot(小提琴图+分布散点图):
sns.violinplot(data=tips, x="tip", y="day", inner=None, hue="day") sns.stripplot(data=tips, x="tip", y="day", jitter=True, color="c")
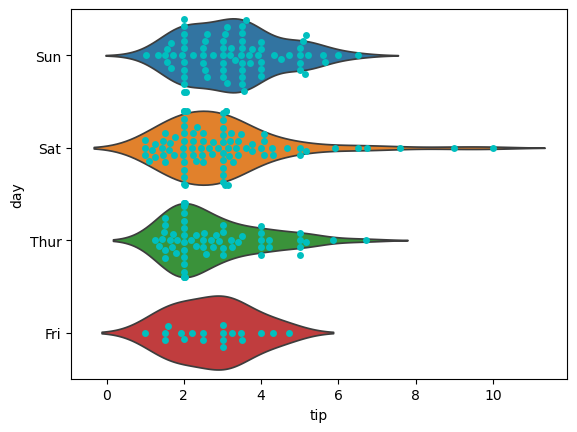
violinplot+swarmplot(小提琴图+分布密度散点图):
sns.violinplot(data=tips, x="tip", y="day", inner=None, hue="day") sns.swarmplot(data=tips, x="tip", y="day", color="c")
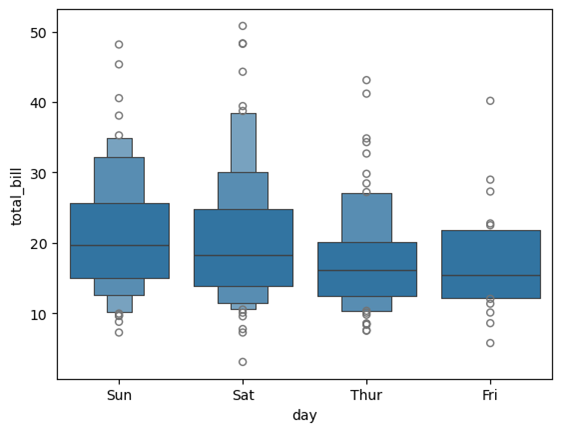
boxenplot
Seaborn的boxenplot是一种用于可视化数据分布的图表,特别适用于大数据集。它是一种增强版的箱线图(boxplot),通过显示更多的分位数来提供更详细的数据分布信息。boxenplot通过绘制多个箱体来展示数据的不同分位数,因此在分析大数据集时,能够更清晰地观察数据的分布情况。
seaborn.boxenplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, dodge='auto', width=0.8, gap=0, linewidth=None, linecolor=None, width_method='exponential', k_depth='tukey', outlier_prop=0.007, trust_alpha=0.05, showfliers=True, hue_norm=None, log_scale=None, native_scale=False, formatter=None, legend='auto', scale=<deprecated>, box_kws=None, flier_kws=None, line_kws=None, ax=None, **kwargs)
参数说明:
- width_method:{“exponential”, “linear”, “area”}。用于字母值箱宽度的方法:
- “exponential”:表示相应的百分位数
- “linear”:每个箱体减少一个常量量
- “area”:表示该箱体中数据点的密度
- k_depth:{“tukey”, “proportion”, “trustworthy”, “full”}或整数。计算和绘制每个尾部的级别数量:
- “tukey”:使用log2(n)-3级别,覆盖与箱线图须相似的范围
- “proportion”:留下大约outlier_prop 的异常值
- “trusthworthy”:扩展到至少trust_alpha 置信度的级别
- “full”:使用log2(n)+1级别并扩展到最极端的点
- outlier_prop:浮点数。预期为异常值的数据比例;在k_depth=”proportion” 时使用。
- trust_alpha:浮点数。最极端级别的置信度阈值;在k_depth=”trustworthy” 时使用。
- showfliers:布尔值。如果为False,抑制异常值的绘制。
- line_kws:字典。用于表示中位数的线的关键字参数;传递给axes.Axes.plot()。
- flier_kws:字典。用于表示异常值观察的散点的关键字参数;传递给axes.Axes.scatter()。
使用示例:
sns.boxenplot(data=tips, x="day", y="total_bill")
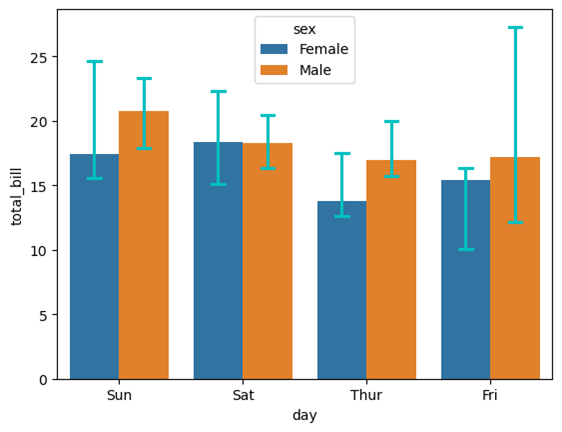
barplot(条形图)
Seaborn的barplot是一种用于展示分类数据和数值数据之间关系的统计图表。它主要用于展示不同类别的数值的平均值,并可以显示数值分布的置信区间。这种图表在比较不同类别的平均值时非常有用。
seaborn.barplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, units=None, weights=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, hue_norm=None, width=0.8, dodge='auto', gap=0, log_scale=None, native_scale=False, formatter=None, legend='auto', capsize=0, err_kws=None, ci=<deprecated>, errcolor=<deprecated>, errwidth=<deprecated>, ax=None, **kwargs)
参数说明:
- capsize:浮点数。相对于条形间距的误差条“帽子”的宽度。
使用示例:
sns.barplot(data=tips, x="day", y="total_bill", hue='sex', estimator=np.median, capsize=0.2, err_kws={'color':'c'})
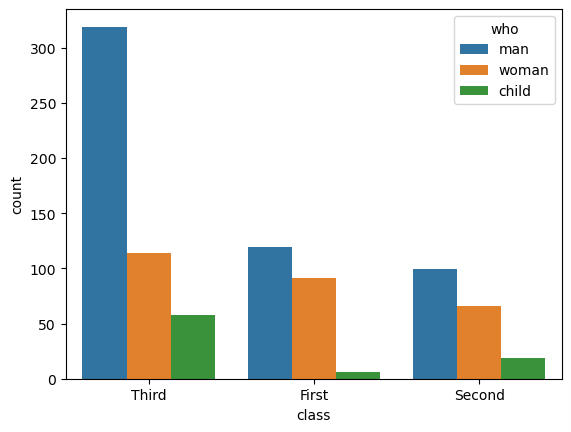
countplot(计数图)
Seaborn的countplot是一种用于显示分类数据中每个类别出现频率的图表。它通过条形图的形式展示数据集中不同类别的计数,因此非常适合用于可视化类别型变量的分布情况。
seaborn.countplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, hue_norm=None, stat='count', width=0.8, dodge='auto', gap=0, log_scale=None, native_scale=False, formatter=None, legend='auto', ax=None, **kwargs)
参数说明:
- stat:{‘count’, ‘percent’, ‘proportion’, ‘probability’}。要计算的统计量;当不为’count’时,条形的高度将被标准化,使它们在整个图中相加为100(对于’percent’)或1(对于其他情况)。
使用示例:
# 加载数据
titanic = pd.read_csv("seaborn-data/titanic.csv")
titanic.head()
sns.countplot(x="class", hue="who", data=titanic)
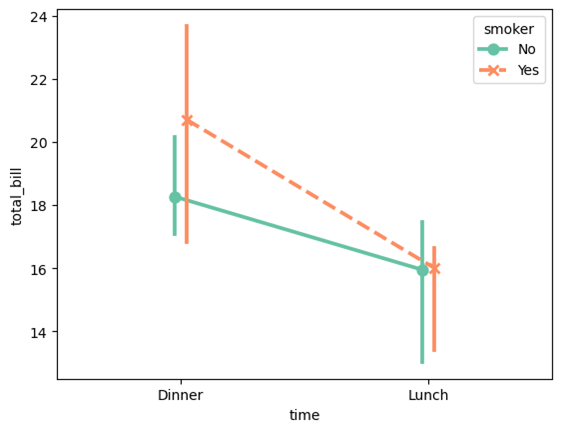
pointplot(点图)
Seaborn的pointplot是一种用于显示类别数据中点估计及其置信区间的图表。它通常用于比较不同类别之间的平均值或其他汇总统计量,并可以显示这些估计值的不确定性。
seaborn.pointplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, units=None, weights=None, color=None, palette=None, hue_norm=None, markers=<default>, linestyles=<default>, dodge=False, log_scale=None, native_scale=False, orient=None, capsize=0, formatter=None, legend='auto', err_kws=None, ci=<deprecated>, errwidth=<deprecated>, join=<deprecated>, scale=<deprecated>, ax=None, **kwargs)
参数说明:
- linestyles:字符串或字符串列表。用于每个hue级别的线条样式。
使用示例:
sns.pointplot(data=tips, x="time", y="total_bill", hue="smoker", estimator=np.median, dodge=True, palette="Set2", markers=["o", "x"], linestyles=["-", "--"])
catplot
seaborn.catplot是Seaborn库中一个非常灵活且强大的函数,用于绘制类别数据的多种类型的图表。它的设计目的是简化类别数据的可视化,并提供一致的API来创建不同类型的图表。通过使用catplot,你可以轻松地创建条形图、点图、箱线图、提琴图等多种类别图表。
seaborn.catplot(data=None, *, x=None, y=None, hue=None, row=None, col=None, kind='strip', estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, units=None, weights=None, order=None, hue_order=None, row_order=None, col_order=None, col_wrap=None, height=5, aspect=1, log_scale=None, native_scale=False, formatter=None, orient=None, color=None, palette=None, hue_norm=None, legend='auto', legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, ci=<deprecated>, **kwargs)
参数说明:
- kind:字符串。要绘制的图的类型,对应于分类轴级绘图函数的名称。选项包括:“strip”(条形图)、“swarm”(蜂群图)、“box”(箱线图)、“violin”(小提琴图)、“boxen”(增强箱线图)、“point”(点图)、“bar”(柱状图)或“count”(计数图)。
- legend_out:布尔值。如果为True,则图形的大小将会扩展,并且图例会被绘制在图形的右中心位置之外。
- share{x,y}:布尔值,‘col’,或‘row’(可选)。如果为True,则面板会在列间共享y轴(如果sharey为True),和/或在行间共享x轴(如果sharex为True)。
- margin_titles:布尔值。如果为True,则行变量的标题会绘制在最后一列的右侧。此选项处于实验阶段,可能在所有情况下都无法正常工作。
使用示例:
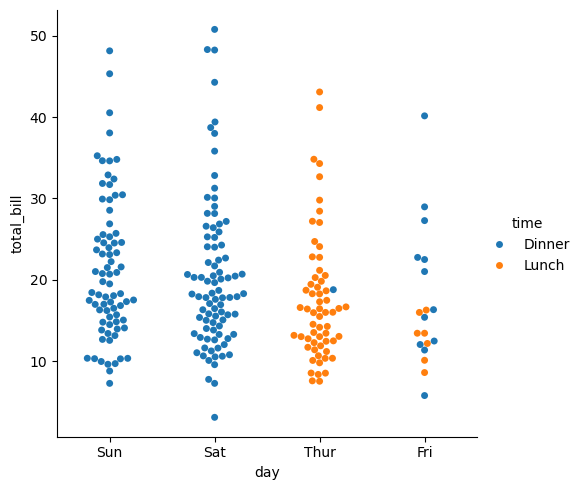
sns.catplot(data=tips, x="day", y="total_bill", hue="time", kind="swarm")
Distribution plots(分布图)
分布图主要是用于可视化变量的分布情况,一般分为单变量分布和多变量分布。当然这里的多变量多指二元变量,更多的变量无法绘制出直观的可视化图形。Seaborn提供的分布图绘制方法一般有这几个:jointplot,pairplot,distplot,kdeplot。Seaborn快速查看单变量分布的方法是distplot。默认情况下,该方法将会绘制直方图并拟合核密度估计图。
histplot(直方图)
seaborn.histplot是Seaborn库中的一个函数,用于绘制直方图和密度图。它能够有效地显示单变量或双变量数据的分布情况,是探索性数据分析中常用的工具。
参数说明:
- bins:字符串、数字、向量或成对的这些值。通用区间参数,可以是参考规则的名称、区间数量或区间的断点。传递给histogram_bin_edges()。
- binwidth:数字或数字对。每个区间的宽度,覆盖bins,但可以与binrange一起使用。
- binrange:数字对或成对的数字对。区间边界的最低和最高值;可以与bins或binwidth一起使用。默认为数据的极值。
- discrete:布尔值。如果为True,默认binwidth=1,并将条形绘制为居中于其对应的数据点。这避免了使用离散(整数)数据时可能出现的“间隙”。
- cumulative:布尔值。如果为True,绘制累积计数,随着区间增加。
- common_bins:布尔值。如果为True,当语义变量生成多个图时使用相同的区间。如果使用参考规则确定区间,将使用完整数据集计算。
- common_norm:布尔值。如果为True且使用归一化统计量,则归一化将应用于整个数据集。否则,分别归一化每个直方图。
- multiple:{“layer”,“dodge”,“stack”,“fill”}。当语义映射创建子集时解决多个元素的方法。仅与单变量数据相关。
- element:{“bars”,“step”,“poly”}。直方图统计量的视觉表示。仅与单变量数据相关。
- shrink:数字。按此因子相对于区间宽度缩放每个条形的宽度。仅与单变量数据相关。
- kde:布尔值。如果为True,计算核密度估计以平滑分布并在图中显示为一条或多条线。仅与单变量数据相关。
- kde_kws:字典。控制KDE计算的参数,如在kdeplot()中。
- line_kws:字典。控制KDE可视化的参数,传递给axes.Axes.plot()。
- thresh:数字或None。统计量小于或等于此值的单元格将是透明的。仅与双变量数据相关。
- pthresh:数字或None。类似于thresh,但在[0,1]范围内的值,使得总和达到此比例的单元格将是透明的。
- pmax:数字或None。在[0,1]范围内的值,设置颜色映射的饱和点,使得低于此比例的单元格构成总计数(或使用时的其他统计量)。
- cbar:布尔值。如果为True,添加颜色条以注释双变量图中的颜色映射。注意:当前不支持带有hue变量的图形。
- cbar_ax:axes.Axes。颜色条的预先存在的轴。
- cbar_kws:字典。传递给figure.Figure.colorbar()的附加参数。
使用示例:
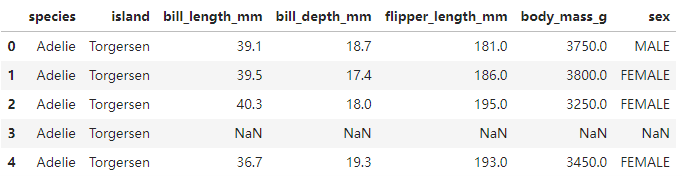
penguins = pd.read_csv("seaborn-data/penguins.csv")
penguins.head()
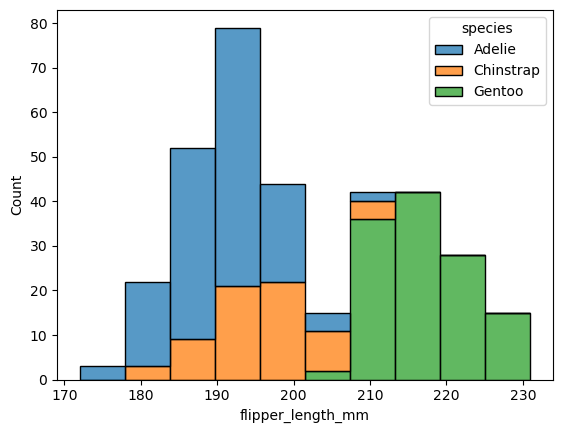
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
kdeplot(核密度图)
seaborn.kdeplot是Seaborn库中的一个函数,用于绘制核密度估计(KDE)图。KDE是一种用于估计数据分布的非参数方法,它通过在每个数据点上放置一个核(通常是高斯核)来平滑数据分布,从而生成连续的概率密度函数。kdeplot可以用于单变量和双变量数据的可视化。
seaborn.kdeplot(data=None, *, x=None, y=None, hue=None, weights=None, palette=None, hue_order=None, hue_norm=None, color=None, fill=None, multiple='layer', common_norm=True, common_grid=False, cumulative=False, bw_method='scott', bw_adjust=1, warn_singular=True, log_scale=None, levels=10, thresh=0.05, gridsize=200, cut=3, clip=None, legend=True, cbar=False, cbar_ax=None, cbar_kws=None, ax=None, **kwargs)
参数说明:
- multiple:{“layer”,“stack”,“fill”}。当语义映射创建子集时,用于绘制多个元素的方法。仅与单变量数据相关。
- common_grid:布尔值。如果为True,为每个核密度估计使用相同的评估网格。仅与单变量数据相关。
- cumulative:布尔值,可选。如果为True,估计累积分布函数。需要scipy。
- warn_singular:布尔值。如果为True,当尝试估计方差为零的数据的密度时发出警告。
- levels:整数或向量。等高线的数量或绘制等高线的值。向量参数必须在[0,1]范围内递增。等级对应于密度的等比例:例如,20%的概率质量将位于为2绘制的等高线以下。仅与双变量数据相关。
- clip:数字对或None,或成对的这些对。不要在这些限制之外评估密度。
- cbar:布尔值。如果为True,添加颜色条以注释双变量图中的颜色映射。注意:当前不支持带有hue变量的图形。
- cbar_ax:axes.Axes。颜色条的预先存在的轴。
- cbar_kws:字典。传递给figure.Figure.colorbar()的附加参数。
使用示例:
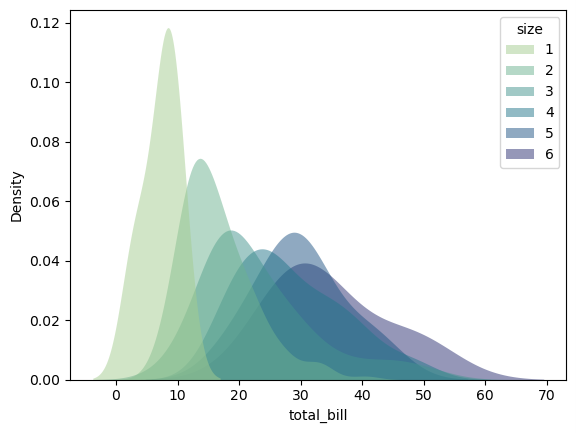
sns.kdeplot(data=tips, x="total_bill", hue="size", fill=True, common_norm=False, palette="crest", alpha=.5, linewidth=0)
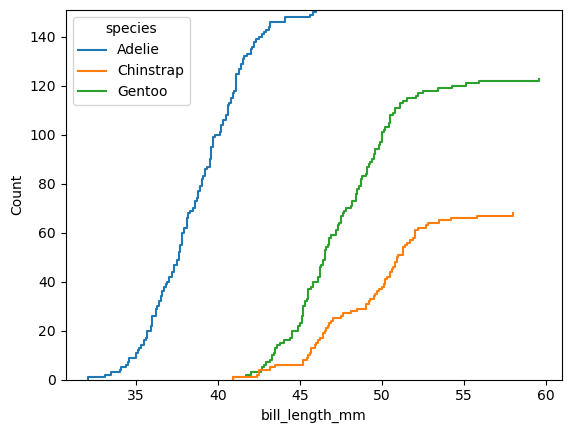
ecdfplot(累积分布图)
seaborn.ecdfplot 是 Seaborn 库中的一个函数,用于绘制经验累积分布函数(Empirical Cumulative Distribution Function, ECDF)。ECDF 是一种用来描述数据分布的图形方法,通过展示数据中每个值的累积概率,可以直观地看到数据的分布情况。
seaborn.ecdfplot(data=None, *, x=None, y=None, hue=None, weights=None, stat='proportion', complementary=False, palette=None, hue_order=None, hue_norm=None, log_scale=None, legend=True, ax=None, **kwargs)
参数说明:
- complementary:布尔值。如果为 True,则使用补充累积分布函数(1-CDF)。
使用示例:
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", stat="count")
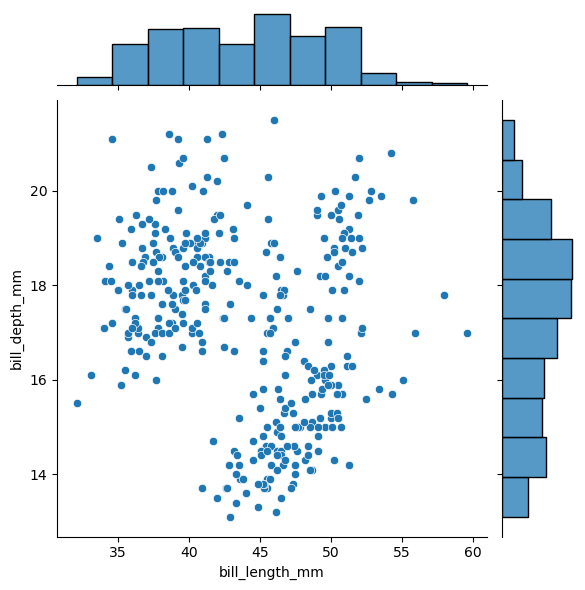
jointplot(联合分布图)
seaborn.jointplot 是 Seaborn 库中的一个强大函数,用于同时可视化两个变量之间的关系及其各自的单变量分布。它在一个图中结合了散点图或其他双变量图和两个边际单变量图(通常是直方图或密度图),提供了全面的数据分布和关系的视角。
seaborn.jointplot(data=None, *, x=None, y=None, hue=None, kind='scatter', height=6, ratio=5, space=0.2, dropna=False, xlim=None, ylim=None, color=None, palette=None, hue_order=None, hue_norm=None, marginal_ticks=False, joint_kws=None, marginal_kws=None, **kwargs)
参数说明:
- kind:{“scatter”|“kde”|“hist”|“hex”|“reg”|“resid”}。绘制的图类型。请参阅示例以了解底层函数的引用。
- space:数字。主图和边际图之间的空间。
- dropna:布尔值。如果为 True,删除 x 和 y 中缺失的观测值。
- {x,y}lim:数字对。在绘图之前设置的轴限制。
- marginal_ticks:布尔值。如果为 False,抑制边际图中计数/密度轴上的刻度。
- {joint,marginal}_kws:字典。图形组件的附加关键字参数。
使用示例:
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm")
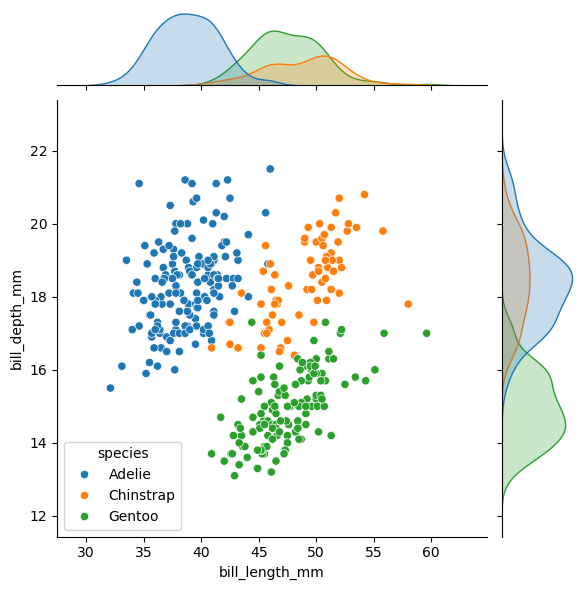
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species")
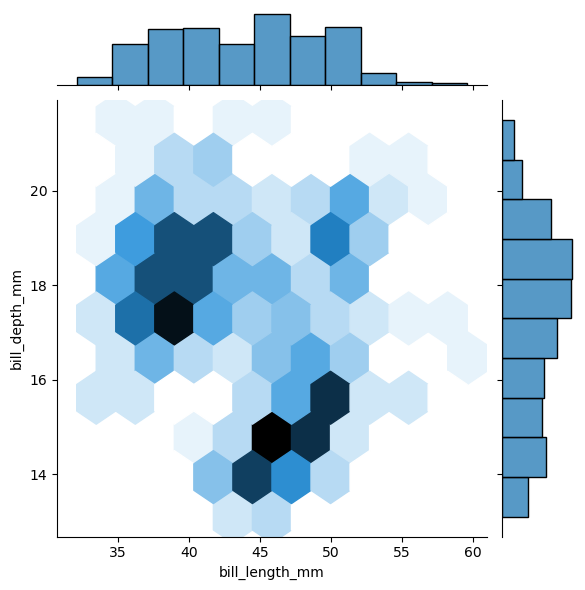
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", kind="hex")
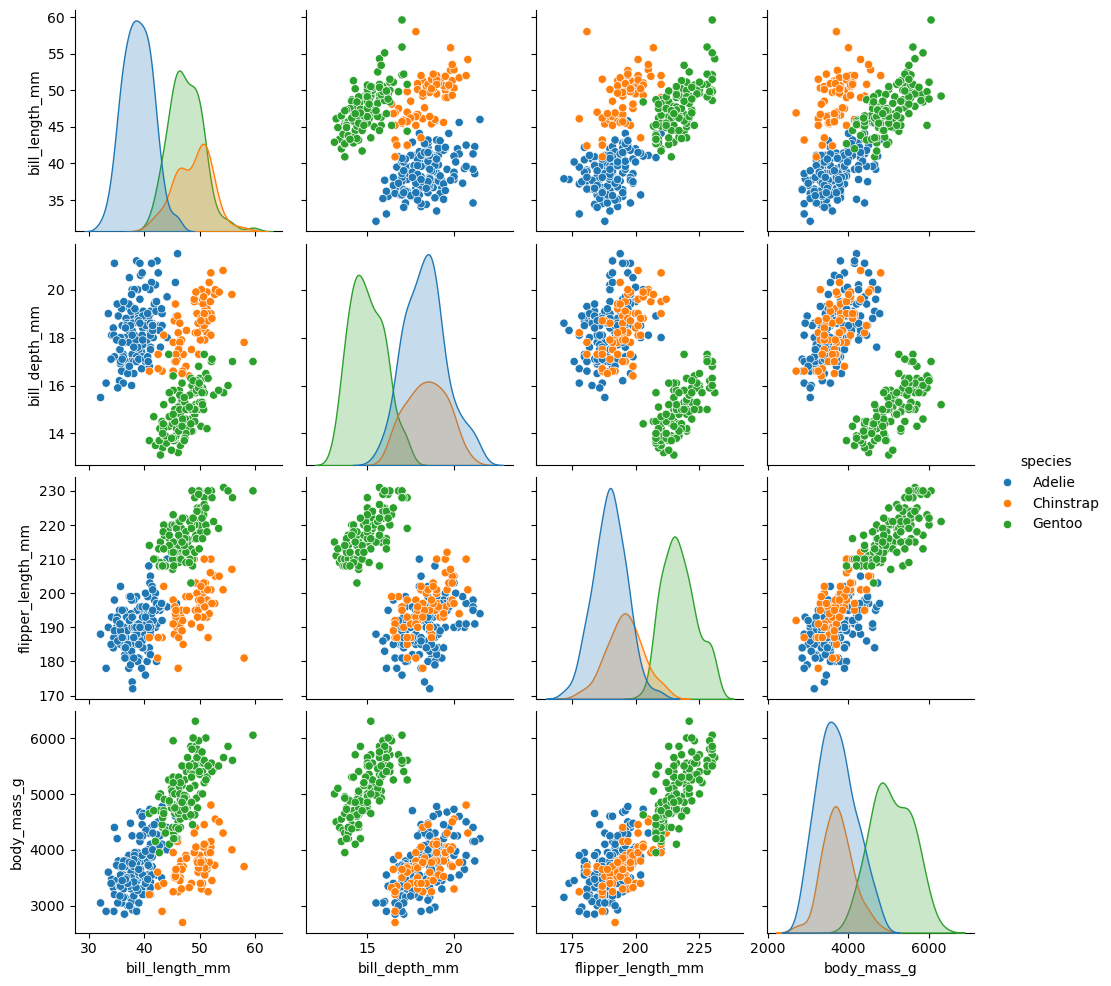
pairplot(变量关系组图)
seaborn.pairplot 是 Seaborn 库中的一个非常有用的函数,用于在一个图中可视化多变量数据集的变量对之间的关系。它通过创建一个矩阵图,其中每个变量对都有一个子图,来帮助分析变量之间的关系和单变量分布。
seaborn.pairplot(data, *, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind='scatter', diag_kind='auto', markers=None, height=2.5, aspect=1, corner=False, dropna=False, plot_kws=None, diag_kws=None, grid_kws=None, size=None)
参数说明:
- vars:变量名列表。要使用的数据中的变量,否则使用所有数值类型的列。
- {x,y}_vars:变量名列表。数据中分别用于图形行和列的变量;即用于创建非正方形图。
- kind:{‘scatter’,‘kde’,‘hist’,‘reg’}。要创建的图类型。
- diag_kind:{‘auto’,‘hist’,‘kde’,None}。对角线子图的图类型。如果为‘auto’,则根据是否使用 hue 进行选择。
- aspect:标量。宽度(以英寸为单位)为 aspect*height 的每个子图。
- corner:布尔值。如果为 True,则不在网格的上三角(非对角线)添加轴,使其成为“角落”图。
- {plot,diag,grid}_kws:字典。关键字参数的字典。plot_kws 传递给双变量绘图函数,diag_kws 传递给单变量绘图函数,grid_kws 传递给 PairGrid 构造函数。
使用示例:
sns.pairplot(penguins, hue="species")
Regression plots(回归图)
回归图的绘制函数主要有:lmplot 和 regplot。
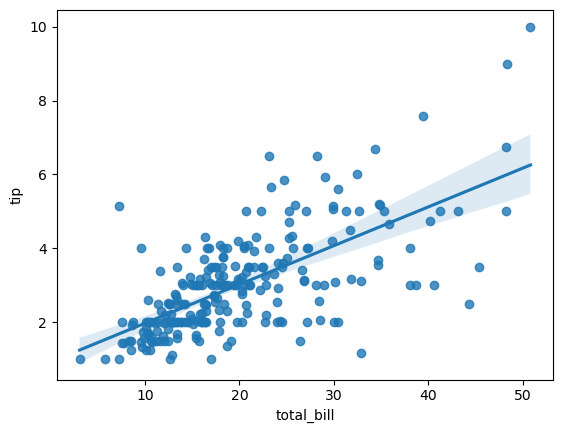
regplot(回归图)
seaborn.regplot 是 Seaborn 库中的一个函数,用于绘制散点图以及一个线性回归拟合线,以帮助分析两个连续变量之间的关系。它不仅可以展示原始数据点,还可以显示这些数据点之间的趋势,从而有助于理解变量之间的线性关系。
seaborn.regplot(data=None, *, x=None, y=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, dropna=True, x_jitter=None, y_jitter=None, label=None, color=None, marker='o', scatter_kws=None, line_kws=None, ax=None)
参数说明:
- x_estimator:可调用对象,将向量映射为标量,可选。对x的每个唯一值应用此函数并绘制结果估计值。当x是离散变量时,这很有用。如果提供了x_ci,则此估计值将进行自助法抽样,并绘制置信区间。
- x_bins:整数或向量,可选。将x变量分箱为离散箱,然后估计中心趋势和置信区间。此分箱仅影响散点图的绘制方式;回归仍然适用于原始数据。此参数可解释为等大小(不必等间距)箱的数量或箱中心的位置。当使用此参数时,默认的x_estimator为mean。
- x_ci:”ci”、”sd”、[0,100]之间的整数或None,可选。用于绘制x离散值中心趋势的置信区间大小。如果为”ci”,则依赖于ci参数的值。如果为”sd”,则跳过自助法抽样,并显示每个箱中的观测标准差。
- scatter:布尔值,可选。如果为True,则绘制带有基础观测值(或x_estimator值)的散点图。
- fit_reg:布尔值,可选。如果为True,则估计并绘制x和y变量之间的回归模型。
- ci:在[0,100]之间的整数或None,可选。回归估计的置信区间大小。这将使用回归线周围的半透明带绘制。置信区间使用自助法估计;对于大型数据集,建议通过将此参数设置为None来避免该计算。
- logistic:布尔值,可选。如果为True,假设y是二元变量,并使用statsmodels来估计逻辑回归模型。注意,这比线性回归计算量大得多,因此您可能希望减少自助法重采样次数(n_boot)或将ci设置为None。
- lowess:布尔值,可选。如果为True,使用statsmodels来估计非参数lowess模型(局部加权线性回归)。注意,目前无法为这种模型绘制置信区间。
- robust:布尔值,可选。如果为True,使用statsmodels来估计稳健回归。这将减轻异常值的影响。注意,这比标准线性回归计算量大得多,因此您可能希望减少自助法重采样次数(n_boot)或将ci设置为None。
- logx:布尔值,可选。如果为True,估计形式为y~log(x)的线性回归,但在输入空间中绘制散点图和回归模型。注意,x必须为正数才能工作。
- {x,y}_partial:数据中的字符串或矩阵。在绘图前从x或y变量中回归出的混杂变量。
- truncate:布尔值,可选。如果为True,回归线受数据限制。如果为False,则延伸到x轴的限制。
- {x,y}_jitter:浮点数,可选。向x或y变量添加此大小的均匀随机噪声。噪声在拟合回归后添加到数据的副本中,仅影响散点图的外观。当绘制离散值的变量时,这可能很有帮助。
- {scatter,line}_kws:字典。传递给scatter和plt.plot的其他关键字参数。
使用示例:
sns.regplot(x="total_bill", y="tip", data=tips)
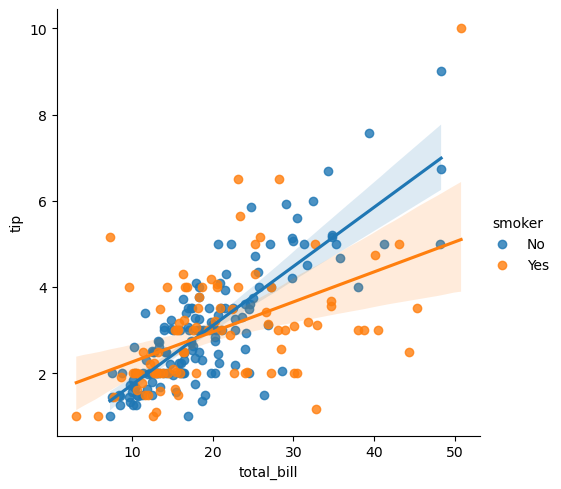
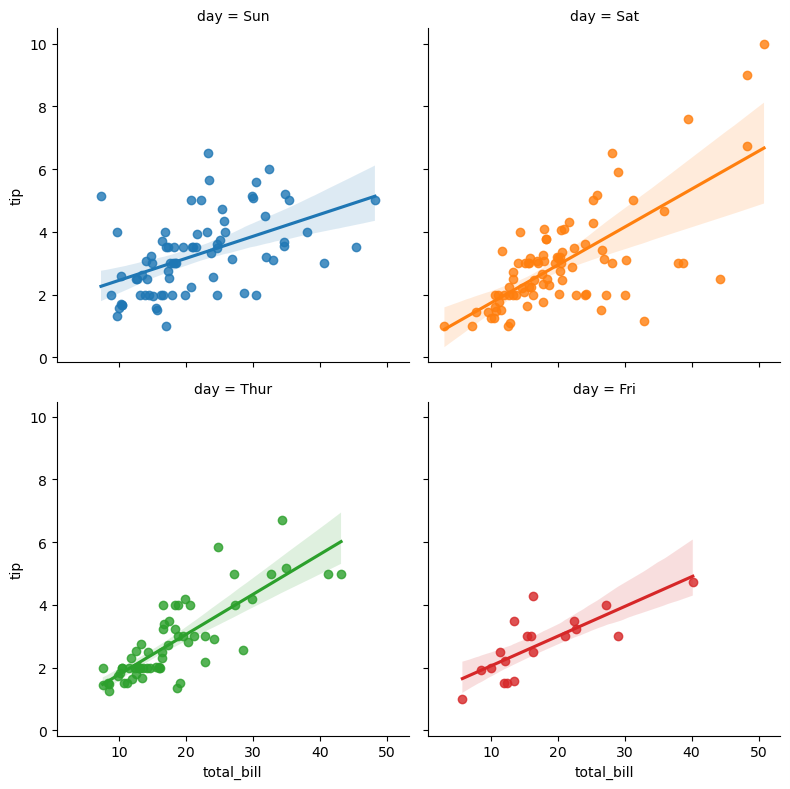
lmplot(网格+回归图)
seaborn.lmplot是Seaborn库中的一个函数,用于绘制线性模型图。它结合了散点图和回归线,帮助用户分析两个连续变量之间的关系。与regplot不同,lmplot是一个基于FacetGrid的高级接口,支持根据一个或多个分类变量分割数据,从而在多个子图中展示不同组的回归关系。
seaborn.lmplot(data, *, x=None, y=None, hue=None, col=None, row=None, palette=None, col_wrap=None, height=5, aspect=1, markers='o', sharex=None, sharey=None, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None, facet_kws=None)
参数说明:
- x_ci:”ci”,”sd”,[0,100]之间的整数或None,可选。用于绘制x的离散值的中心趋势的置信区间的大小。如果为”ci”,则延迟到ci参数的值。如果为”sd”,则跳过自举并显示每个箱中观测值的标准差。
- truncate:布尔值,可选。如果为True,回归线由数据限制。如果为False,则扩展到x轴限制。
- {scatter,line}_kws:字典。传递给scatter和plt.plot的其他关键字参数。
使用示例:
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)
sns.lmplot(x="total_bill", y="tip", col="day", hue="day", data=tips, col_wrap=2, height=4)
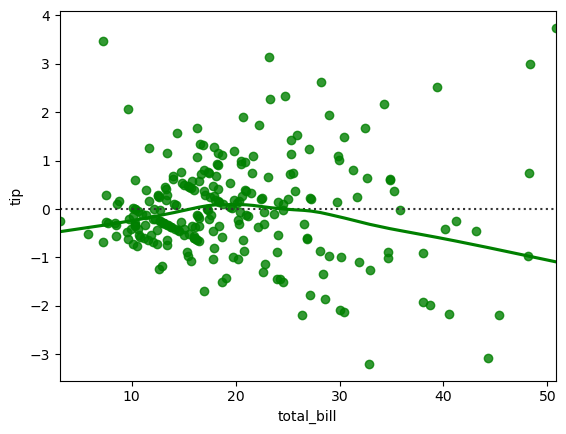
residplot(残差图)
seaborn.residplot是Seaborn库中的一个函数,用于绘制残差图(ResidualPlot)。残差图是分析回归模型的重要工具,通过绘制预测值与实际值之间的差异(即残差),可以帮助识别模型拟合中的潜在问题。
seaborn.residplot(data=None, *, x=None, y=None, x_partial=None, y_partial=None, lowess=False, order=1, robust=False, dropna=True, label=None, color=None, scatter_kws=None, line_kws=None, ax=None)
参数说明:
- x_partial,y_partial:数组或字符串,可选。指定在计算残差之前要从x或y中部分回归出去的变量。
sns.residplot(x="total_bill", y="tip", data=tips, lowess=True, color="g")
Matrixplots (矩阵图)
heatmap (热力图)
seaborn.heatmap是Seaborn库中的一个函数,用于绘制矩阵形式的数据的热图。热图是一种数据可视化技术,它通过颜色编码来表示数据的值,特别适合展示二维数据的分布和模式。
seaborn.heatmap(data, *, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
参数说明:
- vmin, vmax: 浮点数,可选。用于锚定颜色映射的值,否则将从数据和其他关键字参数推断。
- cmap: Matplotlib颜色映射名称或对象,或颜色列表,可选。数据值到颜色空间的映射。如果未提供,默认值将取决于是否设置了center参数。
- center: 浮点数,可选。在绘制发散数据时用于居中颜色映射的值。使用此参数会更改默认的cmap(如果未指定)。
- robust: 布尔值,可选。如果为True且vmin或vmax缺失,则使用稳健分位数而不是极值来计算颜色映射范围。
- annot: 布尔值或矩形数据集,可选。如果为True,则在每个单元格中写入数据值。如果提供了与数据形状相同的类似数组,则使用此数组来注释热图而不是数据。注意,DataFrames将按位置匹配,而不是索引。
- fmt: 字符串,可选。添加注释时使用的字符串格式代码。
- annot_kws: 关键字-值映射的字典,可选。当annot为True时,传递给axes.Axes.text()的关键字参数。
- linewidths: 浮点数,可选。分隔每个单元格的线的宽度。
- square: 布尔值,可选。如果为True,则将轴的纵横比设置为”相等”,以便每个单元格将是正方形。
- xticklabels, yticklabels: “auto”、布尔值、类列表或整数,可选。如果为True,则绘制数据框的列名。如果为False,则不绘制列名。如果为类列表,则绘制这些替代标签作为x轴标签。如果为整数,则使用列名但只绘制每隔n个标签。如果为”auto”,则尝试密集绘制不重叠的标签。
- mask: 布尔数组或DataFrame,可选。如果传递,则在mask为True的单元格中不显示数据。具有缺失值的单元格会自动被掩盖。
使用示例:
glue = pd.read_csv("seaborn-data/glue.csv")
glue.head()
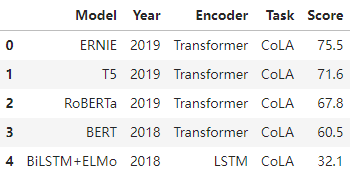
glue = sns.load_dataset("glue").pivot(index="Model", columns="Task", values="Score")
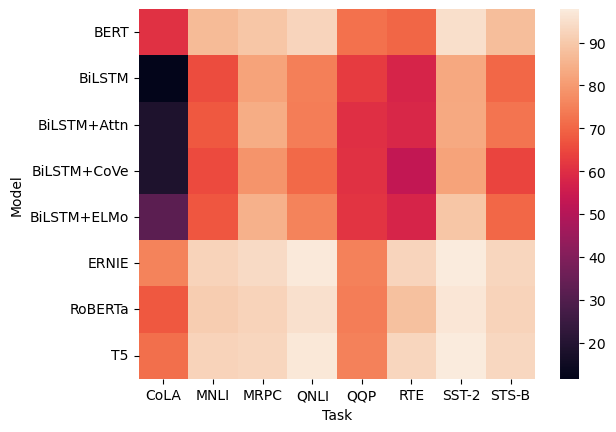
sns.heatmap(glue)
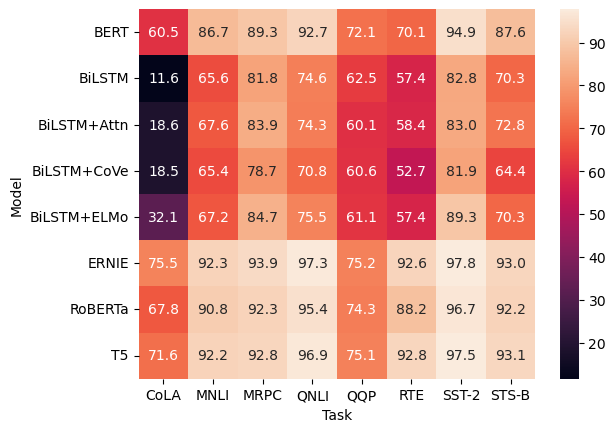
sns.heatmap(glue, annot=True, fmt=".1f")
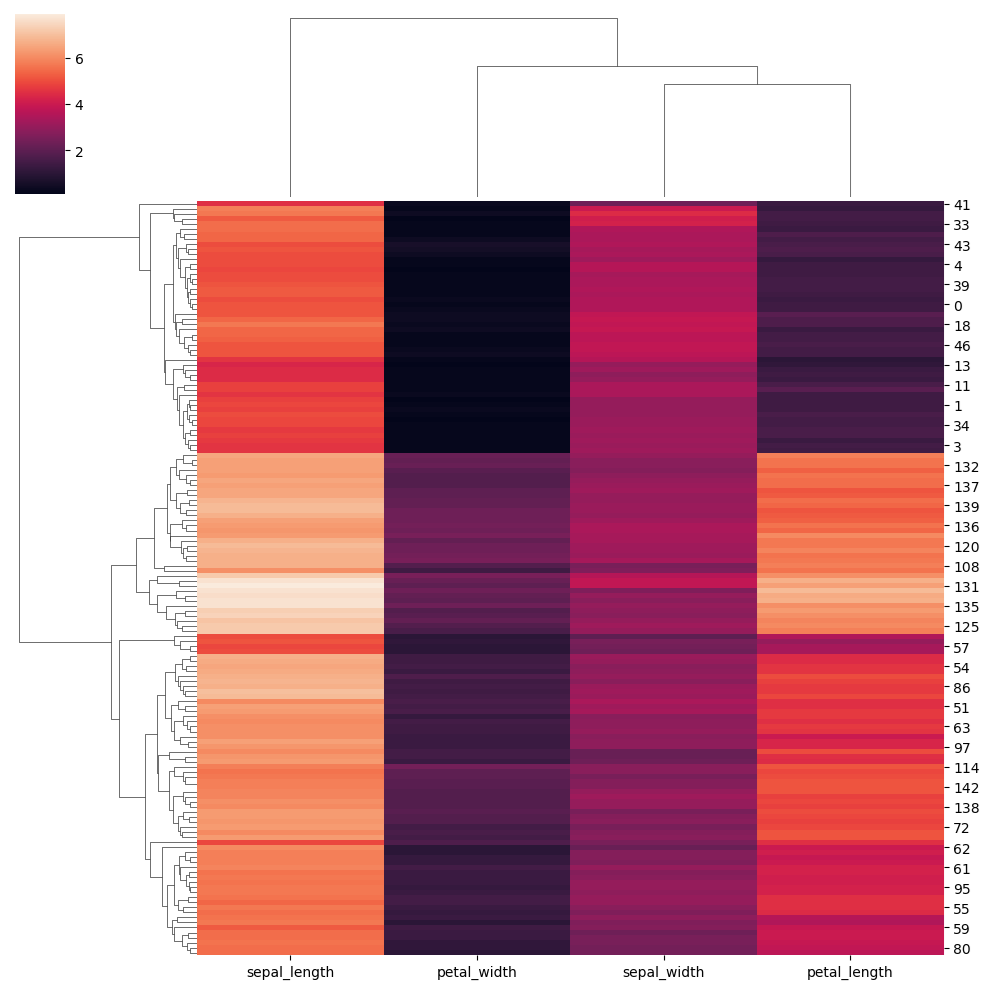
clustermap (聚类图)
seaborn.clustermap是Seaborn库中的一个函数,用于创建热图的层次聚类图。它不仅展示了数据的热图视图,还通过应用层次聚类算法来揭示数据中的结构和模式。这对于识别数据中的相关性和群组非常有用。
seaborn.clustermap(data, *, pivot_kws=None, method='average', metric='euclidean', z_score=None, standard_scale=None, figsize=(10, 10), cbar_kws=None, row_cluster=True, col_cluster=True, row_linkage=None, col_linkage=None, row_colors=None, col_colors=None, mask=None, dendrogram_ratio=0.2, colors_ratio=0.03, cbar_pos=(0.02, 0.8, 0.05, 0.18), tree_kws=None, **kwargs)
参数说明:
-
- pivot_kws: 字典,可选。如果数据是一个整洁的数据框,可以提供关键字参数用于pivot,以创建一个矩形的数据框。
- method: 字符串,可选。用于计算聚类的链接方法。有关更多信息,请参阅cluster.hierarchy.linkage()的文档。
- metric: 字符串,可选
用于数据的距离度量。有关更多选项,请参阅spatial.distance.pdist()的文档。要对行和列使用不同的度量(或方法),可以自行构建每个链接矩阵并将其作为{row,col}_linkage提供。 - z_score: 整数或None,可选。0(行)或1(列)。是否计算行或列的z分数。z分数的计算公式为:z=(x-mean)/std,因此每行(列)的值将减去该行(列)的平均值,然后除以该行(列)的标准差。这确保每行(列)的平均值为0,方差为1。
- standard_scale: 整数或None,可选
0(行)或1(列)。是否标准化该维度,意味着对每行或列减去最小值,然后除以最大值。 - figsize: (宽, 高)元组,可选
图形的整体大小。 - {row,col}_cluster: 布尔值,可选
如果为True,对{行,列}进行聚类。 - {row,col}_linkage: numpy.ndarray,可选
行或列的预计算链接矩阵。有关特定格式,请参阅cluster.hierarchy.linkage()。 - {row,col}_colors: 类列表或PandasDataFrame/Series,可选
用于标记行或列的颜色列表。用于评估组内样本是否聚集在一起。可以使用嵌套列表或DataFrame进行多层次的颜色标记。如果给定为DataFrame或pandas.Series,颜色的标签将从DataFrame的列名或Series的名称中提取。DataFrame/Series的颜色也将根据其索引与数据匹配,确保颜色以正确顺序绘制。
mask: 布尔数组或 DataFrame,可选
如果传递,则在 mask 为 True 的单元格中不显示数据。具有缺失值的单元格会自动被掩盖。仅用于可视化,不用于计算。
- {dendrogram,colors}_ratio: 浮点数或浮点数对,可选
分配给两个边际元素的图形大小比例。如果给定一对,它们对应于(行,列)比例。 - cbar_pos: (左, 底, 宽, 高) 元组,可选
颜色条轴在图形中的位置。设置为 None 将禁用颜色条。 - tree_kws: 字典,可选。用于绘制树形图的线条的 collections.LineCollection 的参数。
使用示例:
species = iris.pop("species")
sns.clustermap(iris)
FacetGrid()
seaborn.FacetGrid 是 Seaborn 库中的一个强大工具,用于创建多面板(facet)图形。通过在不同的面板中绘制数据的子集,可以帮助我们在多个维度上可视化数据。这对于比较不同组的分布、趋势或关系特别有用。
FacetGrid() 用于初始化网格对象,每一个子图都称为一个格子。它其实就是我们之前学的 relplot(),catplot() 以及 lmplot() 这几个函数的一个上层类,我们可以根据自己的需求定制每个格子中画什么样的图形,使用更加自由。
在大多数情况下,与直接使用 FacetGrid 相比,使用图形级函数(例如 relplot() 或 catart() 要好得多。
class seaborn.FacetGrid(data, *, row=None, col=None, hue=None, col_wrap=None, sharex=True, sharey=True, height=3, aspect=1, palette=None, row_order=None, col_order=None, hue_order=None, hue_kws=None, dropna=False, legend_out=True, despine=True, margin_titles=False, xlim=None, ylim=None, subplot_kws=None, gridspec_kws=None)
FacetGrid 并不能直接绘制我们想要的图像,它的基本工作流程是 FacetGrid 使用数据集和用于构造网格的变量初始化对象。然后,可以通过调用 FacetGrid.map() 或将一个或多个绘图函数应用于每个子集 FacetGrid.map_dataframe(),最后,可以使用其他修改参数的方法调整绘图。
sns.FacetGrid(tips, col="time", row="smoker") # 2*2
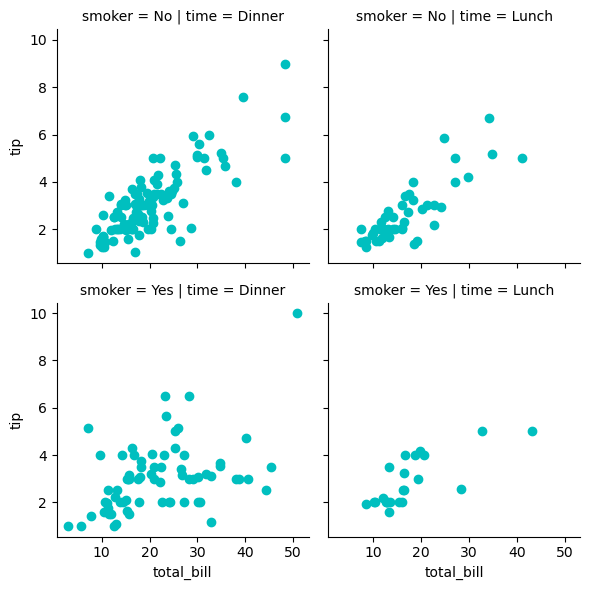
g = sns.FacetGrid(tips, col="time", row="smoker") g = g.map(plt.scatter, "total_bill", "tip", color="c") # g.map() 需要传入一个绘图函数
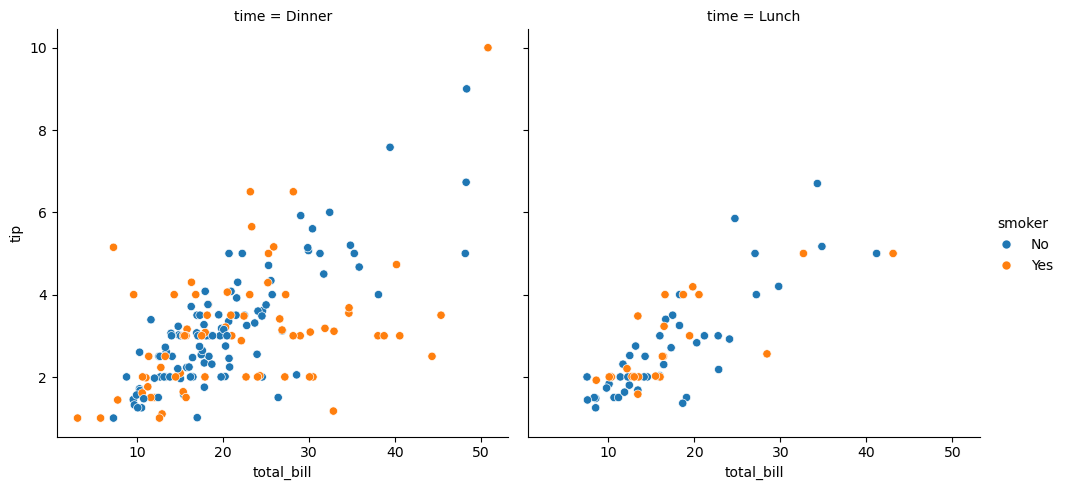
对比一下 FacetGrid.map() 绘图与 relplot()、catplot()、lmplot() 绘图的区别(这里只比较 relplot() 来绘制散点图):
sns.relplot(x="total_bill", y="tip", color="c", col="time", hue="smoker", data=tips)
在大多数情况下,与直接使用 FacetGrid 相比,使用图形级函数(例如 relplot() 或 catart() 要好得多。
PairGrid()
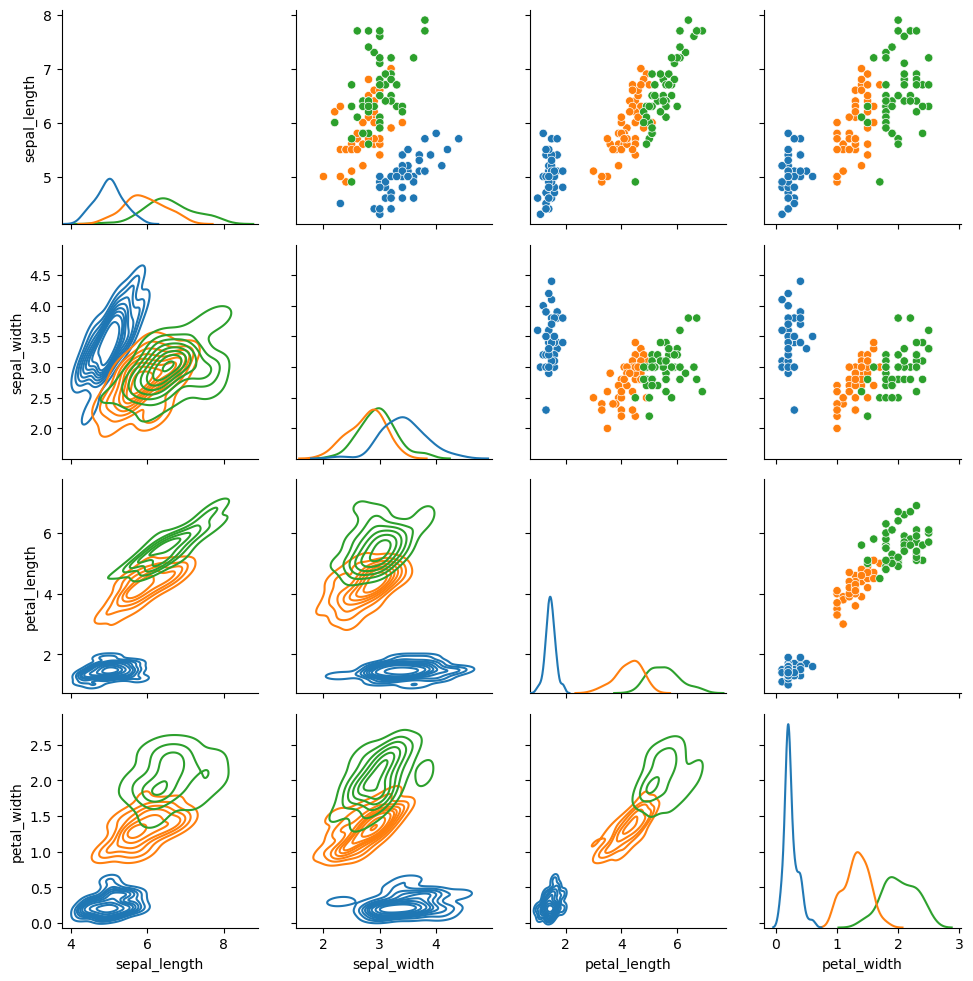
seaborn.PairGrid 是 Seaborn 库中的一个工具,用于创建成对变量的多面板网格图。它提供了一种方便的方法来可视化多个变量之间的关系,尤其是在进行探索性数据分析(EDA)时。
PairGrid() 用于绘制数据集中成对关系的子图网格。它的原理和我们之前的 pairplot 是一样的,但是前面我们可以发现 pairplot 绘制的图像上、下三角形是关于主对角线对称的,而 PairGrid 则可修改上、下三角形和主对角线的图像形状。
class seaborn.PairGrid(data, *, hue=None, vars=None, x_vars=None, y_vars=None, hue_order=None, palette=None, hue_kws=None, corner=False, diag_sharey=True, height=2.5, aspect=1, layout_pad=0.5, despine=True, dropna=False)
使用示例:
g = sns.PairGrid(iris, hue="species") g = g.map_upper(sns.scatterplot) # 在上对角线子图上用二元函数绘制的图 g = g.map_lower(sns.kdeplot) # 在下对角线子图上用二元函数绘制的图 g = g.map_diag(sns.kdeplot) # 对角线单变量子图
JointGrid()
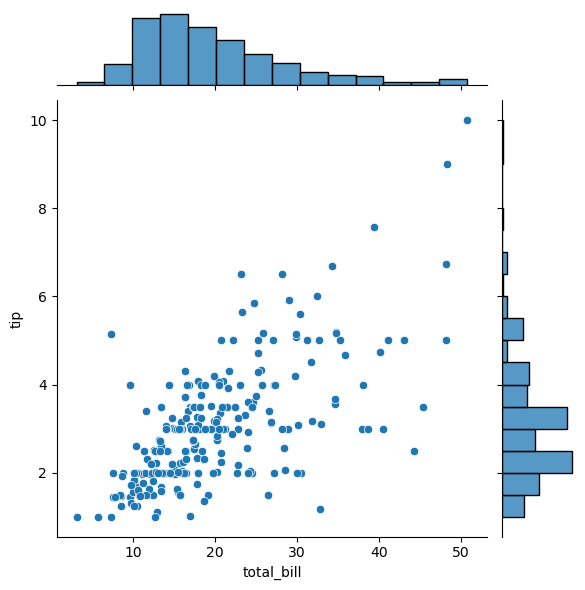
seaborn.JointGrid 是 Seaborn 库中的一个类,用于创建显示两个变量之间关系的图形网格。它允许在主轴上绘制两个变量的联合分布,同时在边缘轴上展示每个变量的单独分布。这种可视化方式有助于深入理解变量之间的关系和各自的分布特性。
JointGrid 提供了一个灵活的界面来创建带有联合分布和边缘分布的图形。用户可以自定义主图和边缘图的类型。
class seaborn.JointGrid(data=None, *, x=None, y=None, hue=None, height=6, ratio=5, space=0.2, palette=None, hue_order=None, hue_norm=None, dropna=False, xlim=None, ylim=None, marginal_ticks=False)
使用示例:
g = sns.JointGrid(data=tips, x="total_bill", y="tip") g.plot(sns.scatterplot, sns.histplot)
主题和颜色
风格(style)
seaborn设置风格的方法主要有三种:
- set,通用设置接口
- set_style,风格专用设置接口,设置后全局风格随之改变
- axes_style,设置当前图(axes级)的风格,同时返回设置后的风格系列参数,支持with关键字用法
seaborn中主要有以下几个主题:
sns.set_style("whitegrid") #白色网格背景
sns.set_style("darkgrid") #灰色网格背景
sns.set_style("dark") #灰色背景
sns.set_style("white") #白色背景
sns.set_style("ticks") #四周加边框和刻度
例子:
plt.subplot(231)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title('style=matplotlib')
with sns.axes_style('darkgrid'):
plt.subplot(232)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title('style=darkgrid')
with sns.axes_style('whitegrid'):
plt.subplot(233)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title('style=whitegrid')
with sns.axes_style('ticks'):
plt.subplot(234)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title('style=ticks')
with sns.axes_style('dark'):
plt.subplot(235)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title('style=dark')
with sns.axes_style('white'):
plt.subplot(236)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")
plt.title('style=white')
plt.tight_layout()
plt.show()
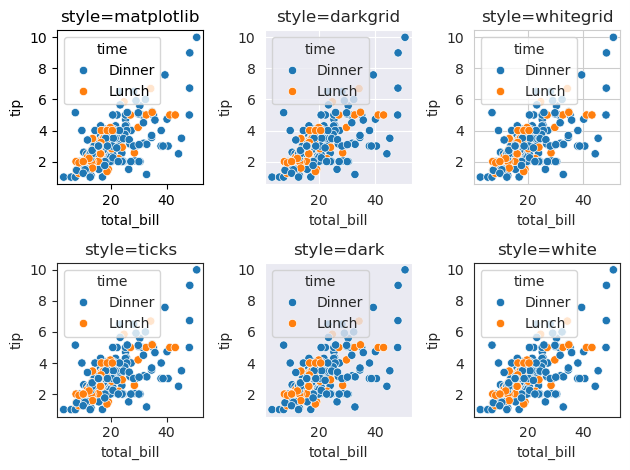
相比matplotlib绘图风格,seaborn绘制的直方图会自动增加空白间隔,图像更为清爽。而不同seaborn风格间,则主要是绘图背景色的差异。
环境(context)
设置环境的方法也有3种:
- set,通用设置接口
- set_context,环境设置专用接口,设置后全局绘图环境随之改变
- plotting_context,设置当前图(axes级)的绘图环境,同时返回设置后的环境系列参数,支持with关键字用法
预设上下文
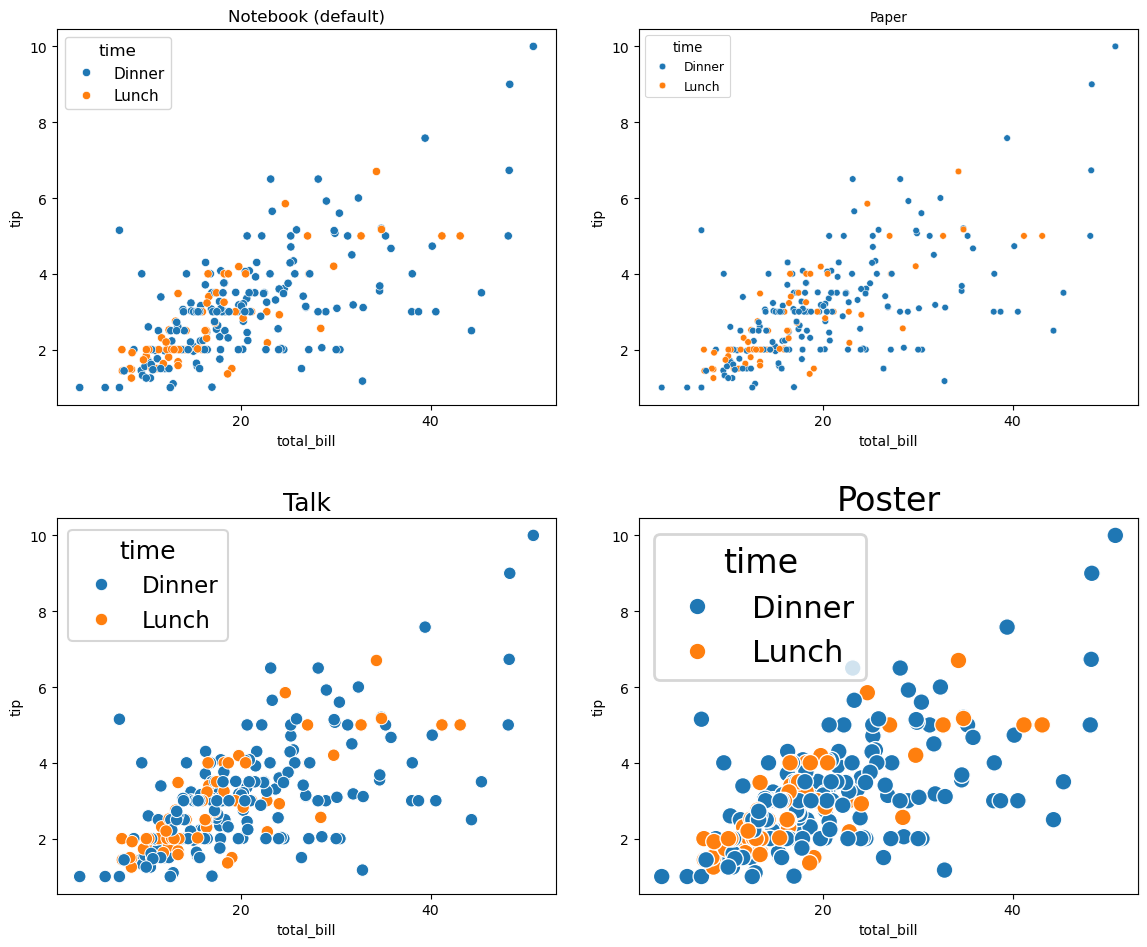
Seaborn提供了四种预设的上下文选项:
- paper:适合嵌入在学术论文中,缩放比例较小。
- notebook:适合在Jupyter Notebook中使用,默认上下文。
- talk:适合用于演讲或展示,缩放比例较大。
- poster:适合用于海报展示,缩放比例最大。
使用示例:
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
#定义上下文列表和对应的标题
contexts = ["notebook", "paper", "talk", "poster"]
titles = ["Notebook(default)", "Paper", "Talk", "Poster"]
#循环遍历每个上下文,设置并绘制相应的图形
for ax, context, title in zip(axes.flatten(), contexts, titles):
sns.set_context(context)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time", ax=ax)
ax.set_title(title)
#调整布局以避免重叠
plt.tight_layout()
自定义上下文
除了使用预设选项,你还可以通过传递rc参数来自定义上下文设置。rc参数是一个字典,允许你覆盖特定的rc参数(Matplotlib的配置参数),例如字体大小、线宽等。
sns.set_context("notebook", rc={"font.size":12, "axes.titlesize":14, "axes.labelsize":12})
颜色(color_plette())
seaborn风格多变的另一大特色就是支持个性化的颜色配置。颜色配置的方法有多种,常用方法包括以下两个:
- color_palette,基于RGB原理设置颜色的接口,可接收一个调色板对象作为参数,同时可以设置颜色数量
- hls_palette,基于Hue(色相)、Luminance(亮度)、Saturation(饱和度)原理设置颜色的接口,除了颜色数量参数外,另外3个重要参数即是hls
同时,为了便于查看调色板样式,seaborn还提供了一个专门绘制颜色结果的方法palplot。
color_palette()函数可以生成多种类型的调色板,适合不同的数据和视觉需求。它可以返回一个颜色列表,这些颜色可以直接用于绘图,也可以通过sns.set_palette()设置为全局调色板。
主要参数
- palette:字符串或列表。指定调色板的类型或颜色列表。常见的预设选项包括”deep”,”muted”,”bright”,”pastel”,”dark”,”colorblind”等。
- n_colors:整数,可选。指定调色板中的颜色数量。默认为6。
- desat:浮点数,可选。调整颜色的饱和度,范围在0和1之间。1表示原始饱和度。
默认调色板:
- “deep”:颜色鲜明,对比度高。
- “muted”:颜色柔和。
- “bright”:颜色鲜艳。
- “pastel”:颜色浅淡。
- “dark”:颜色深沉。
- “colorblind”:色盲友好调色板。
定性调色板:
- 使用color_palette(“husl”, n_colors=8)可以生成一个定性的调色板。
连续调色板:
- 使用 color_palette(“viridis”, as_cmap=True) 可以生成一个连续调色板。
自定义调色板:
- 可以传递自定义颜色列表,如 [“#FF5733”, “#33FF57”, “#3357FF”]。
示例代码:
palette = sns.color_palette("deep", n_colors=6)
sns.set_palette(palette)
tips = sns.load_dataset("tips")
sns.barplot(x="day", y="total_bill", data=tips, palette=palette)
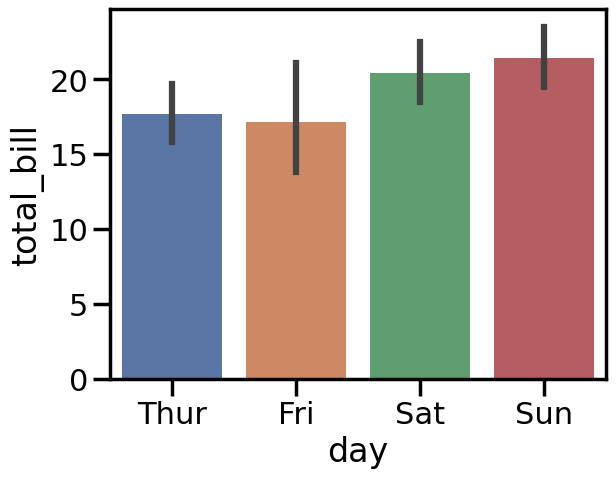
# 自定义颜色列表 custom_palette = ["#FF5733", "#33FF57", "#3357FF"] # 使用自定义调色板 sns.set_palette(custom_palette) # 绘制图形 sns.scatterplot(x="total_bill", y="tip", data=tips, hue="day")
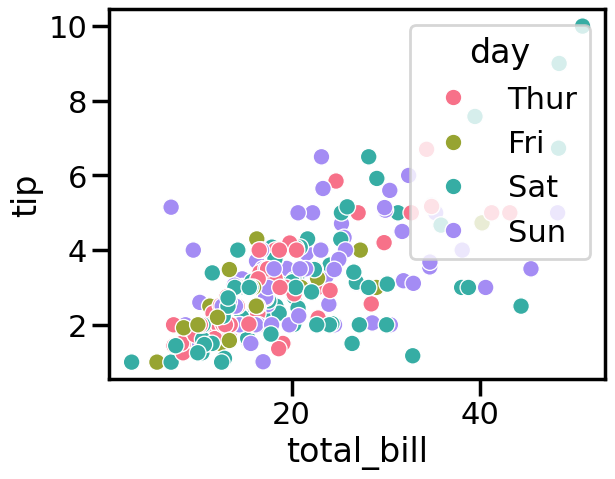
主题(theme)
set_theme() 是 Seaborn 0.11.0 引入的一个更高级的函数,它不仅可以设置样式,还可以设置调色板和上下文。set_theme() 提供了一种更为全面的方法来配置 Seaborn 图形的外观。
参数:
- style:同 set_style(),用于设置背景和网格样式。
- palette:用于设置颜色调色板。
- context:用于设置上下文(如 “paper”, “notebook”, “talk”, “poster”),以控制图形元素的缩放。
- rc:同样可以传递 rc 参数进行进一步自定义。
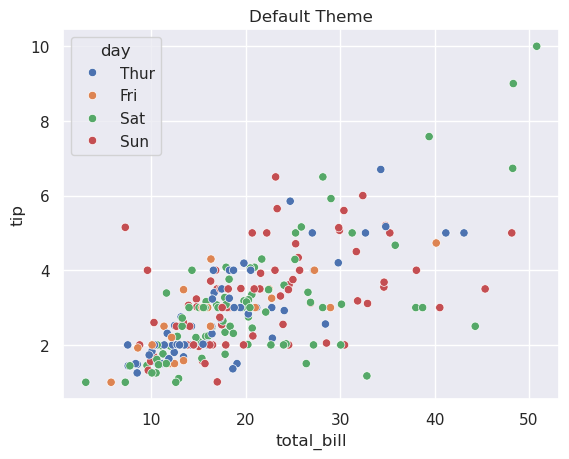
# 示例1: 使用默认设置
sns.set_theme()
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="day")
plt.title("Default Theme")
plt.show()
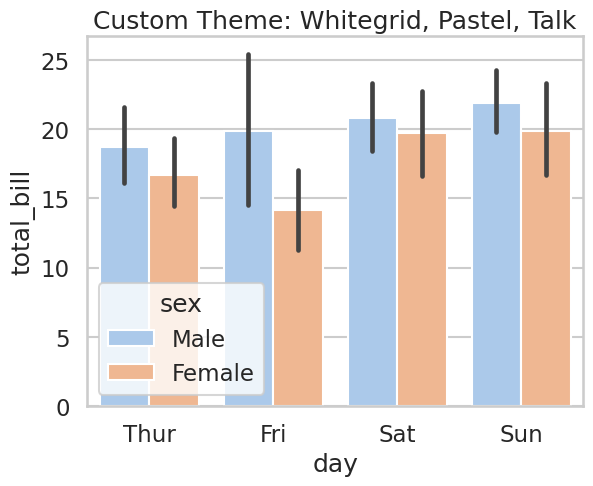
# 示例2: 使用自定义主题
sns.set_theme(style="whitegrid", palette="pastel", context="talk")
sns.barplot(data=tips, x="day", y="total_bill", hue="sex")
plt.title("Custom Theme: Whitegrid, Pastel, Talk")
plt.show()
# 示例3: 使用深色背景和亮色调色板
sns.set_theme(style="dark", palette="bright", context="notebook")
sns.boxplot(data=tips, x="day", y="total_bill", hue="smoker")
plt.title("Dark Theme with Bright Palette")
plt.show()
# 示例4: 使用色盲友好调色板
sns.set_theme(style="ticks", palette="colorblind", context="paper")
sns.violinplot(data=tips, x="day", y="total_bill", hue="sex", split=True)
plt.title("Colorblind Palette")
plt.show()
参考链接:



您好,从histplot开始文章排版有误,谢谢!