TransBigData 简介
TransBigData 是一个为交通时空大数据处理、分析和可视化而开发的 Python 包。TransBigData 为处理常见的交通时空大数据(如出租车 GPS 数据、共享单车数据和公交车 GPS 数据)提供了快速而简洁的方法。TransBigData 为交通时空大数据分析的各个阶段提供了多种处理方法,代码简洁、高效、灵活、易用,可以用简洁的代码实现复杂的数据任务。对于一些特定类型的数据,TransBigData 还提供了针对特定需求的工具,如从出租车 GPS 数据中提取出租车行程的起点和终点信息(OD),从公交车 GPS 数据中识别到离站信息。
技术特点
- 面向交通时空大数据分析不同阶段的处理需求提供不同处理功能。
- 代码简洁、高效、灵活、易用,通过简短的代码即可实现复杂的数据任务。
主要功能
目前,TransBigData 主要提供以下方法:
- 数据质量分析: 提供快速获取数据集一般信息的方法,包括数据量、时间段和采样间隔。
- 数据预处理: 提供清洗多种类型的数据错误的方法。
- 数据栅格化: 提供在研究区域内生成多种类型的地理网格(矩形网格、六角形网格)的方法。提供快速算法将 GPS 数据映射到生成的网格上。
- 数据聚合集计: 提供将 GPS 数据和 OD 数据聚合到地理多边形的方法。
- 数据可视化: 内置的可视化功能,利用可视化包 keplergl,用简单的代码在 Jupyter 笔记本上交互式地可视化数据。
- 轨迹数据处理: 提供处理轨迹数据的方法,包括从 GPS 点生成轨迹线型,轨迹增密等。
- 地图底图: 提供在 matplotlib 上显示 Mapbox 地图底图的方法。
TransBigData 核心方法
数据栅格化
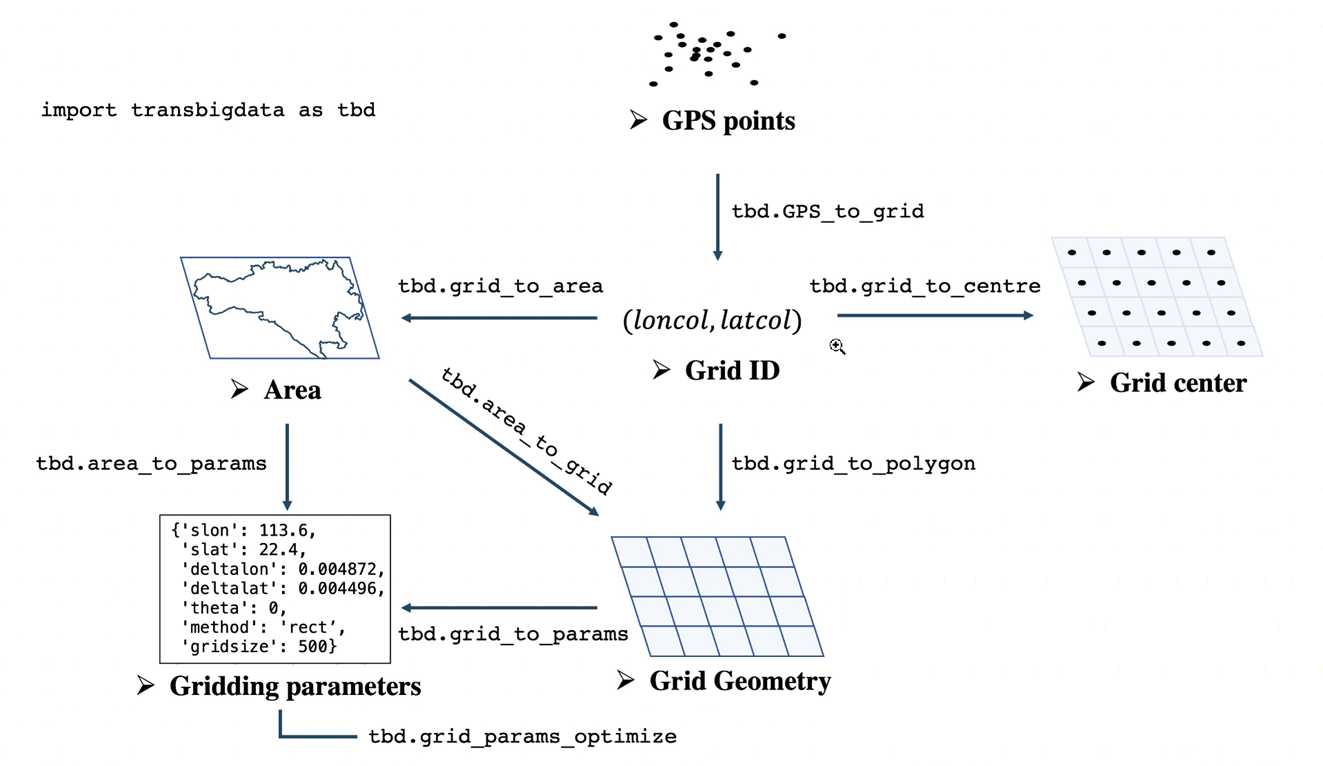
transbigdata.area_to_grid(location, accuracy=500, method='rect', params='auto')
在边界或形状中生成矩形栅格
参数:
- location (bounds (List) or shape (GeoDataFrame)) – 生成栅格的位置。如果边界为 [lon1,lat1,lon2,lat2](WGS84),其中 lon1,lat1 是左下角坐标,lon2,lat2 是右上角坐标如果是形状,则应为 GeoDataFrame
- accuracy (number) – 栅格尺寸(米)
- method (str) – 直角、三角或六角
- params (list or dict) – 栅格化参数。给出格网参数时,将不使用精度。
返回:
- grid (GeoDataFrame) – GridGeoDataFrame、LONCOL 和 LATCOL 是栅格的索引,HBLON 和 HBLAT 是栅格的中心
- 参数 (列表或字典) – 栅格参数。
transbigdata.area_to_params(location, accuracy=500, method='rect')
生成栅格化参数
参数:
- location (bounds (List) or shape (GeoDataFrame)) – 生成栅格的位置。如果边界为 [lon1,lat1,lon2,lat2](WGS84),其中 lon1,lat1 是左下角坐标,lon2,lat2 是右上角坐标如果是形状,则应为 GeoDataFrame
- accuracy (number) – 栅格尺寸(米)
- method (str) – 直角、三角或六角
返回:
- 参数 – 栅格参数。。
返回类型:
- list or dict
transbigdata.GPS_to_grid(lon, lat, params)
将 GPS 数据与栅格匹配。输入是经度、纬度和格网参数列。输出是栅格 ID。
- 参数:
- lon (Series) – 经度栏
- lat (Series) – 纬度栏
- params (list or dict) – 栅格化参数。
返回:
- 矩形栅格,[LONCOL,LATCOL] (list) – 两列 LONCOL 和 LATCOL 一起可以指定栅格。
- 三角形和六边形栅格,[loncol_1,loncol_2,loncol_3] (list) – 栅格纬度的索引。两列 LONCOL 和 LATCOL 一起可以指定一个栅格。
transbigdata.grid_to_centre(gridid, params)
栅格的中心位置。输入是格网 ID 和参数,输出是格网中心位置。
参数:
- gridid (list) – 如果“矩形栅格”[LONCOL,LATCOL]:系列两列 LONCOL 和 LATCOL 一起可以指定栅格。如果“三角形和六边形栅格”[loncol_1,loncol_2,loncol_3]:系列栅格纬度的索引。两列 LONCOL 和 LATCOL 一起可以指定一个栅格。
- params (list or dict) – 栅格化参数。
返回:
- HBLON (Series) – 栅格中心的经度
- HBLAT (Series) – 栅格中心的纬度
transbigdata.grid_to_polygon(gridid, params)
基于格网 ID 生成几何列。输入是栅格 ID,输出是几何图形。支持矩形、三角形和六边形栅格
参数:
- gridid (list) – 如果“矩形栅格”[LONCOL,LATCOL]:系列两列 LONCOL 和 LATCOL 一起可以指定栅格。如果“三角形和六边形栅格”[loncol_1,loncol_2,loncol_3]:系列栅格纬度的索引。两列 LONCOL 和 LATCOL 一起可以指定一个栅格。
- params (list or dict) – 栅格化参数。
返回:
- geometry – 栅格地理多边形的列
返回类型:
- Series
transbigdata.grid_to_area(data, shape, params, col=['LONCOL', 'LATCOL'])
输入格网 ID 两列、地理面和格网参数。输出是栅格。
参数:
- data (DataFrame) – 数据,有两列栅格 ID
- shape (GeoDataFrame) – 地理多边形
- params (list or dict) – 栅格化参数。
- col (List) – 列名称 [LONCOL,LATCOL] 用于矩形栅格,或 [loncol_1,loncol_2,loncol_3] 表示三和六栅格
返回:
- data1 – 数据栅格化和映射到相应的地理多边形
返回类型:
- DataFrame
transbigdata.grid_to_params(grid)
从栅格重新生成栅格化参数。
参数:
- grid(GeoDataFrame) – transbigdata 生成的栅格
返回:
- 参数 – 栅格参数。
返回类型:
- list or dict
transbigdata.grid_params_optimize(data, initialparams, col=['uid', 'lon', 'lat'], optmethod='centerdist', printlog=False, sample=0, pop=15, max_iter=50, w=0.1, c1=0.5, c2=0.5)
优化栅格参数
参数:
- data (DataFrame) – 轨迹数据
- initialparams (List) – 初始栅格参数
- col (List) – 列名 [uid, lon, lat]
- optmethod (str) – 优化方法:centerdist, gini, gridscount
- printlog (bool) – 是否打印明细结果
- sample (int) – 采样数据作为输入,为 0 则不采样
- pop – 来自 scikit-opt 的 PSO 中的参数
- max_iter – 来自 scikit-opt 的 PSO 中的参数
- w – 来自 scikit-opt 的 PSO 中的参数
- c1 – 来自 scikit-opt 的 PSO 中的参数
- c2 – 来自 scikit-opt 的 PSO 中的参数
返回:
- params_optimized – 优化的参数
返回类型:
- List
数据可视化
数据点分布可视化
transbigdata.visualization_data(data, col=['lon', 'lat'], accuracy=500, height=500, maptype='point', zoom='auto')
输入是数据点,此函数将聚合然后可视化
参数:
- data (DataFrame) – 数据点
- col (List) – 列名。用户可以按 [经度,纬度] 的顺序选择非权重的起点-目的地(OD)数据。为此,聚合是自动的。或者,用户也可以输入加权 OD 数据,按 [经度、纬度、计数] 的顺序排列。
- zoom (number) – 地图缩放级别(可选)。
- height (number) – 地图框的高度
- accuracy (number) – 栅格大小
- maptype (str) – 地图类型,‘点’或‘热图’
返回:
- vmap – keplergl 提供的可视化
返回类型:
- keplergl.KeplerGl
轨道可视化
transbigdata.visualization_trip(trajdata, col=['Lng', 'Lat', 'ID', 'Time'], zoom='auto', height=500)
输入是轨迹数据和列名称。输出是基于开普勒的可视化结果
参数:
- trajdata (DataFrame) – 轨迹点数据
- col (List) – 列名称,按 [经度、纬度、车辆 ID、时间] 的顺序排列
- zoom (number) – 地图缩放级别
- height (number) – 地图框的高度
返回:
- vmap – keplergl 提供的可视化
返回类型:
- keplergl.KeplerGl
OD 可视化
transbigdata.visualization_od(oddata, col=['slon', 'slat', 'elon', 'elat'], zoom='auto', height=500, accuracy=500, mincount=0)
输入是 OD 数据和列。输出是基于开普勒的可视化结果
参数:
- oddata (DataFrame) – 外径数据
- col (List) – 列名。用户可以按 [原点经度、原点纬度、目的地经度、目的地纬度] 的顺序选择非权重的起点-目的地(OD)数据。为此,聚合是自动的。或者,用户也可以输入加权 OD 数据,按 [原点经度、原点纬度、目的地经度、目的地纬度、计数] 的顺序排列。
- zoom (number) – 地图缩放级别(可选)。
- height (number) – 地图框的高度
- accuracy (number) – 栅格大小
- mincount (number) – 最小 OD 数,OD 数少的不显示
返回:
- vmap – keplergl 提供的可视化
返回类型:
- keplergl.KeplerGl
活动分析
transbigdata.plot_activity(data, col=['stime', 'etime', 'group'], figsize=(10, 5), dpi=250, shuffle=True, xticks_rotation=0, xticks_gap=1, yticks_gap=1, fontsize=12)
绘制个体的活动图
参数:
- data (DataFrame) – 一个人的活动信息
- col (List) – 列名 [starttime, endtime, group],`group` 控制颜色分组
- figsize (List) – 体形尺寸
- dpi (Number) – 图形的 dpi
- shuffle (bool) – 是否将活动顺序随机打乱
- xticks_rotation (Number) – xticks 的旋转角度
- xticks_gap (Number) – xticks 的间隙
- yticks_gap (Number) – yticks 的间隙
- fontsize (Number) – xticks 和 yticks 的字体大小
特定数据处理方法
手机数据处理
transbigdata.mobile_stay_duration(staydata, col=['stime', 'etime'], start_hour=8, end_hour=20)
输入停留点数据以识别夜间和白天的持续时间。
参数:
- staydata (DataFrame) – 停留数据
- col (List) – 列名,顺序为 [‘starttime’, ’endtime’]
- start_hour (Number) – 一天中的开始时间
- end_hour (Number) – 一天时间的结束时间
返回:
- duration_night (Series) – 夜间持续时间
- duration_day (Series) – 白天的持续时间
transbigdata.mobile_identify_home(staydata, col=[‘uid’, ‘stime’, ‘etime’, ‘LONCOL’, ‘LATCOL’], start_hour=8, end_hour=20)
从手机停留数据中识别居住地位置。规则是确定夜间持续时间最长的位置。
参数:
- staydata (DataFrame) – 停留数据
- col (List) – 列名,按[‘uid’, ‘stime’, ‘etime’, ‘locationtag1’, ‘locationtag2’, …]的顺序排列。可以有多个”位置标签”列来指定位置。
- start_hour (Number) – 一天时间的开始时间和结束时间
- end_hour (Number) – 一天时间的开始时间和结束时间
返回:
- home – 手机用户的家位置
返回类型:
- DataFrame
transbigdata.mobile_identify_work(staydata, col=['uid', 'stime', 'etime', 'LONCOL', 'LATCOL'], minhour=3, start_hour=8, end_hour=20, workdaystart=0, workdayend=4)
从手机停留数据中识别工作地点。规则是确定工作日白天持续时间最长的位置(平均持续时间应超过”minhour”)。
参数:
- staydata (DataFrame) – 停留数据
- col (List) – 列名,按[‘uid’, ‘stime’, ‘etime’, ‘locationtag1’, ‘locationtag2’, …]的顺序排列。可以有多个”locationtag”列来指定位置。
- minhour (Number) – 工作日的最短持续时间(小时)。
- workdaystart (Number) – 一周中工作日的开始和结束。
- workdayend (Number) – 一周中工作日的开始和结束。
- start_hour (Number) – 一天时间的开始时间和结束时间
- end_hour (Number) – 一天时间的开始时间和结束时间
返回:
- work – 手机用户的工作地
返回类型:
- DataFrame
出租汽车GPS数据处理
transbigdata.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'], timelimit=None)
从出租车数据中删除乘客携带状态的瞬时变化记录。这些异常记录会影响旅行订单判断。判断方法:如果同一车辆上一条记录和下一条记录的乘客状态与该记录不同,则应删除该记录。
参数:
- data (DataFrame) – 数据
- col (List) – 列名,顺序为[‘VehicleNum’, ‘Time’, ‘OpenStatus’]
- timelimit (number) – 可选,以秒为单位。如果上一条记录和下一条记录之间的时间小于时间阈值,则将删除该记录
返回:
- data1 – 清理后的数据
返回类型:
- DataFrame
transbigdata.taxigps_to_od(data, col=['VehicleNum', 'Stime', 'Lng', 'Lat', 'OpenStatus'])
输入出租车GPS数据,提取OD信息
参数:
- data (DataFrame) – 出租车GPS数据
- col (List) – 列名在数据中,需要按顺序排列[车辆ID、时间、经度、纬度、乘客状态]
返回:
- oddata – OD信息
返回类型:
- DataFrame
transbigdata.taxigps_traj_point(data, oddata, col=['Vehicleid', 'Time', 'Lng', 'Lat', 'OpenStatus'])
输入出租车数据和OD数据,提取配送和闲置行程的轨迹点
参数:
- data (DataFrame) – 出租车GPS数据,col变量指定的字段名
- oddata (DataFrame) – 出租车OD数据
- col (List) – 栏目名称,需按顺序排列[车辆ID、时间、经度、纬度、旅客状态]
返回:
- data_deliver (DataFrame) – 送货行程的轨迹点
- data_idle (DataFrame) – 空闲行程的轨迹点
共享单车数据处理
transbigdata.bikedata_to_od(data, col=['BIKE_ID', 'DATA_TIME', 'LONGITUDE', 'LATITUDE', 'LOCK_STATUS'], startend=None)
输入共享单车订单数据(仅在锁打开和关闭时生成数据),指定列名称,并从中提取乘车和停车信息
参数:
- data (DataFrame) – 共享单车订单数据
- col (List) – 列名,顺序不能更改。[‘BIKE_ID’, ‘DATA_TIME’, ‘经度’, ‘纬度’, ‘LOCK_STATUS’]
- startend (List) – 观察周期的开始时间和结束时间,例如[‘2018-08-27 00:00:00’, ‘2018-08-28 00:00:00’]。如果通过,则考虑骑行和停车情况(从观察期开始到自行车首次出现)和(从自行车最后一次出现到观察期结束)。
返回:
- move_data (DataFrame) – 骑行数据
- stop_data (DataFrame) – 停车数据
公交GPS数据处理
transbigdata.busgps_arriveinfo(data, line, stop, col=['VehicleId', 'GPSDateTime', 'lon', 'lat', 'stopname'], stopbuffer=200, mintime=300, disgap=200, project_epsg='auto', timegap=1800, projectoutput=False)
输入公交GPS数据、公交线路和车站GeoDataFrame,该方法可以识别公交车的到达和出发信息
参数:
- data (DataFrame) – 总线全球定位系统数据。它应该是来自一条公交路线的数据,并且需要包含车辆ID,GPS时间,纬度和经度(wgs84)
- line (GeoDataFrame) – 公交线路的GeoDataFrame
- stop (GeoDataFrame) – 公交车站的GeoDataFrame
- col (List) – 列名称,按[车辆ID、时间、经度、纬度、车站名称]的顺序排列
- stopbuffer (number) – 米。当车辆在此一定距离内接近车站时,视为到达车站。
- mintime (number) – 秒。在短时间内,巴士再次到达公交车站,将不被视为再次到达
- disgap (number) – 米。车辆前点和后点之间的距离,用于确定车辆是否在移动
project_epsg(number) – 匹配算法将数据转换为投影坐标系来计算距离,这里给出投影坐标系的 epsg 代码
- arrive_info – 公交到发信息
- DataFrame
transbigdata.busgps_onewaytime(arrive_info, start, end, col=['VehicleId', 'stopname', 'arrivetime', 'leavetime'])
输入出发信息表 drive_info 和车站信息表停靠点计算单程行车时间
参数:
- arrive_info(DataFrame) – 发车信息表 drive_info
- start(Str) – 起始站名
- end(Str) – 终点站名
- col(List) – 列名[车号, 站名, 到达时间, 离开时间]
返回:
- onewaytime – 公交车单程时间
返回类型:
- DataFrame
TransBigData 实战
使用数据集:深圳市 2013 年 10 月 22 日大约 600 辆出租车轨迹数据。此部分数据可网上获取。
导入要用到的包
import transbigdata as tbd
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import pprint
tbd.set_mapboxtoken('')
tbd.set_imgsavepath('/home/biaodianfu/')
加载数据
data = pd.read_csv('shenzhen_taxi_gps.csv', header=None)
data.columns = ['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus', 'Speed']
data.head()
输出数据集的一般信息
tbd.data_summary(data, col=['VehicleNum', 'Time'], show_sample_duration=False, roundnum=4)
输出内容为:
Amount of data ----------------- Total number of data items: 544999 Total number of individuals: 180 Data volume of individuals(Mean): 3027.7722 Data volume of individuals(Upper quartile): 4056.25 Data volume of individuals(Median): 2600.5 Data volume of individuals(Lower quartile): 1595.75 Data time period ----------------- Start time: 00:00:00 End time: 23:59:59
数据点分布可视化
tbd.visualization_data(data, col=['Lng', 'Lat'], accuracy=20)
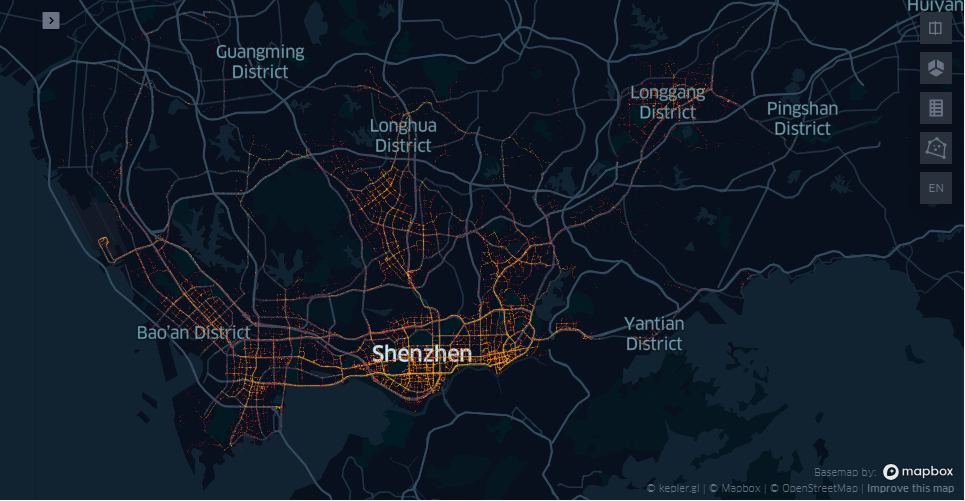
tbd.visualization_data(data, col=['Lng', 'Lat'], accuracy=1000)
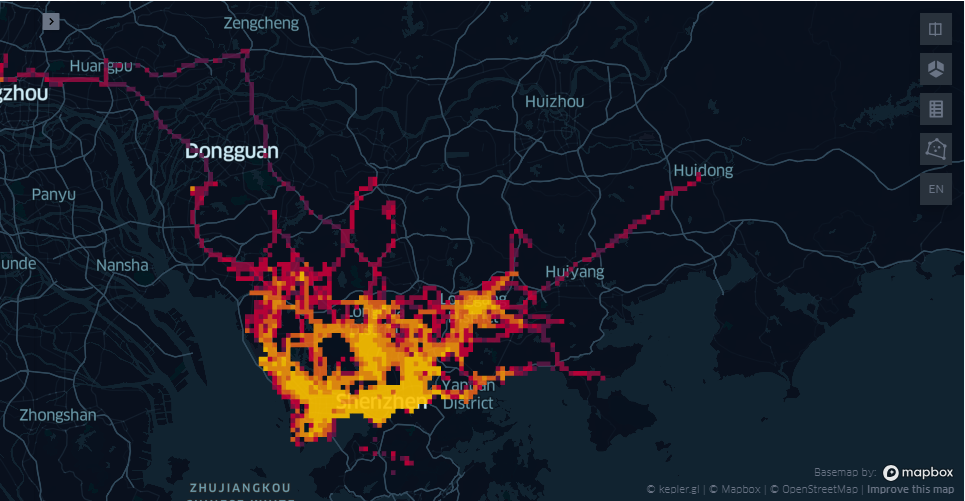
可以看到不同精度下数据统计存在差异。
获取深圳的行政区 geojson
数据来源:https://datav.aliyun.com/portal/school/atlas/area_selector
sz = gpd.read_file('440300_full.json')
sz.crs = None
sz.head()
sz.plot()
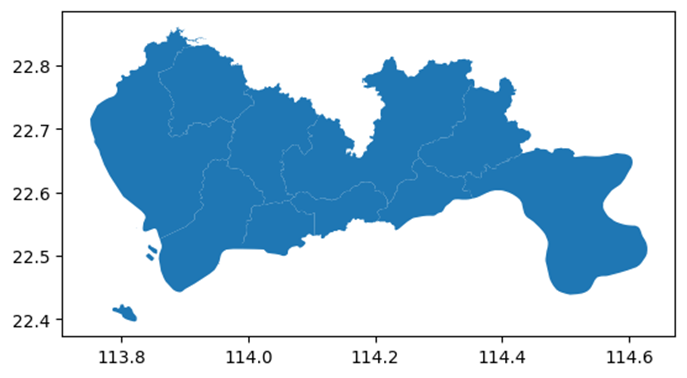
将深圳的区域绘制到地图上
bounds = [113.6, 22.4, 114.8, 22.9] # 设定研究范围的边界
fig = plt.figure(1, (6, 6), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
tbd.plot_map(plt, bounds, zoom=12, style=6)
sz.plot(ax=ax, alpha=0.5)
plt.axis('off');
数据预处理
# 数据预处理,删除深圳区域以外数据 data = tbd.clean_outofshape(data, sz, col=['Lng', 'Lat'], accuracy=500) # 从出租车数据中删除乘客携带状态的瞬时变化记录。 # 这些异常记录会影响旅行订单判断。 # 判断方法:如果同一车辆上一条记录和下一条记录的乘客状态与该记录不同,则应删除该记录。 data = tbd.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'])
clean_taxi_status 的代码实现:
def clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'],
timelimit=None):
'''
Deletes records of instantaneous changes in passenger carrying status from
taxi data. These abnormal records can affect travel order judgments.
Judgement method: If the passenger status of the previous record and the
next record are different from this record for the same vehicle, then this
record should be deleted.
Parameters
-------
data: DataFrame
Data
col: List
Column names, in the order of [‘VehicleNum’, ‘Time’, ‘OpenStatus’]
timelimit: number
Optional, in seconds. If the time between the previous record and the
next record is less than the time threshold, then it will be deleted
Returns
-------
data1: DataFrame
Cleaned data
'''
data1 = data.copy()
[VehicleNum, Time, OpenStatus] = col
# Sort the VehicleNum and Time columns
data1 = data1.sort_values(by=[VehicleNum, Time])
if timelimit:
data1[Time] = pd.to_datetime(data1[Time])
data1 = data1[
-((data1[OpenStatus].shift(-1) == data1[OpenStatus].shift()) &
(data1[OpenStatus] != data1[OpenStatus].shift()) &
(data1[VehicleNum].shift(-1) == data1[VehicleNum].shift()) &
(data1[VehicleNum] == data1[VehicleNum].shift()) &
((data1[Time].shift(-1) - data1[Time].shift()
).dt.total_seconds() <= timelimit)
)]
else:
data1 = data1[
-((data1[OpenStatus].shift(-1) == data1[OpenStatus].shift()) &
(data1[OpenStatus] != data1[OpenStatus].shift()) &
(data1[VehicleNum].shift(-1) == data1[VehicleNum].shift()) &
(data1[VehicleNum] == data1[VehicleNum].shift()))]
return data1
对数据进行栅格化处理
深圳地图栅格化:
grid, params = tbd.area_to_grid(sz) # 栅格参数,accuracy默认为500米 pprint.pprint(params) grid.head()
可视化刚才创建的方形栅格:
GPS点栅格化:
data['LONCOL'], data['LATCOL'] = tbd.GPS_to_grid(data['Lng'], data['Lat'], params) data.head()
统计栅格内的车票数量,并生成数据集:
datatest = data.groupby(['LONCOL', 'LATCOL'])['VehicleNum'].count().reset_index() datatest['geometry'] = tbd.grid_to_polygon([datatest['LONCOL'], datatest['LATCOL']], params) # 生成栅格地理图形 datatest = gpd.GeoDataFrame(datatest) datatest.head()
绘制栅格后的数据
fig = plt.figure(1, (16, 6), dpi=600)
ax = plt.subplot(111)
# tbd.plot_map(plt, bounds, zoom=14, style=1)
datatest.plot(ax=ax, column='VehicleNum', legend=True)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
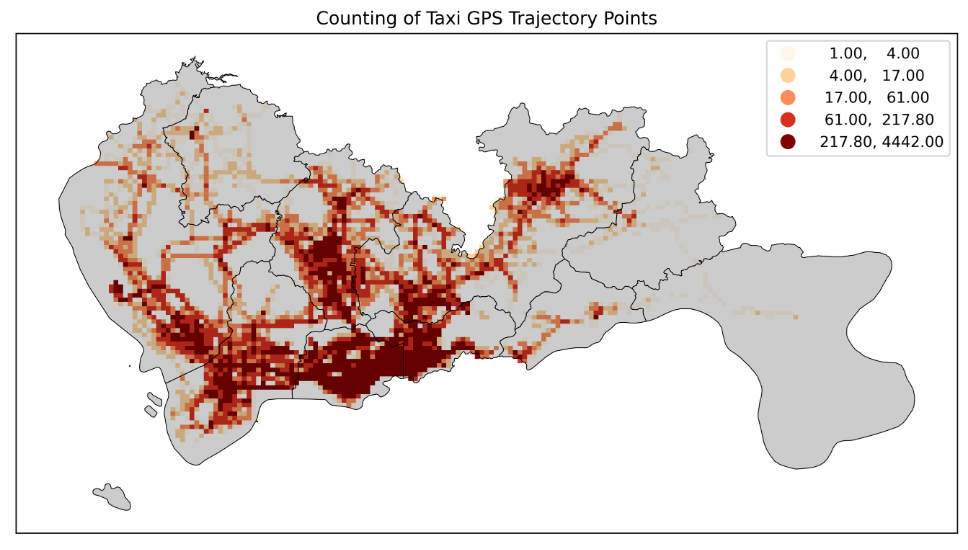
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
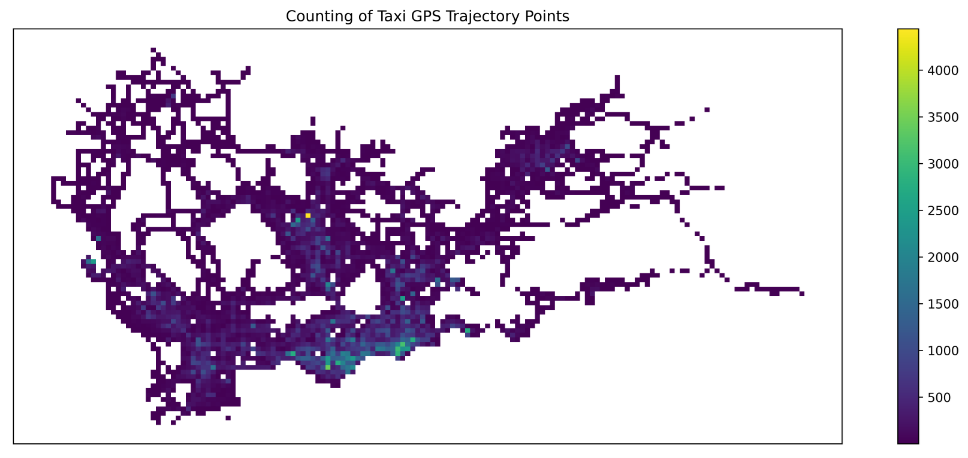
在网格基础上添加深圳行政区边界:
fig = plt.figure(1, (16, 6), dpi=600)
ax = plt.subplot(111)
# tbd.plot_map(plt, bounds, zoom=14, style=1)
datatest.plot(ax=ax, column='VehicleNum', legend=True)
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
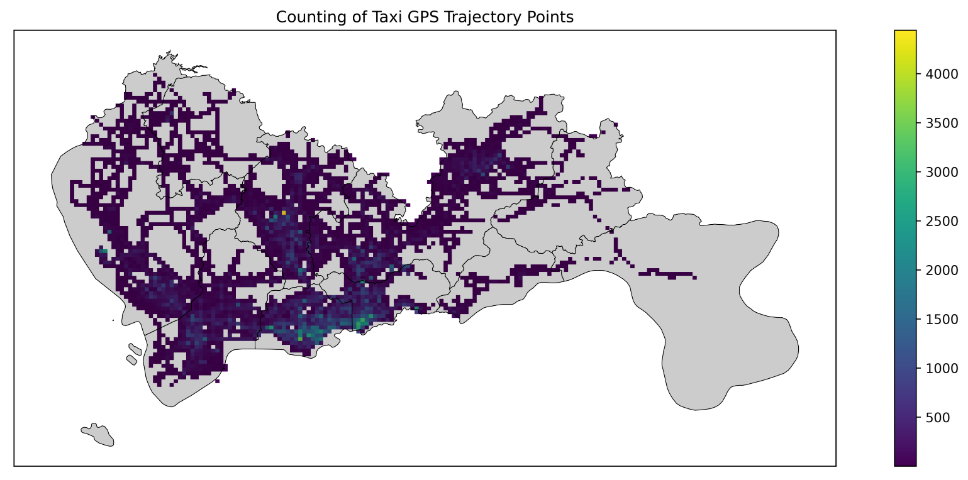
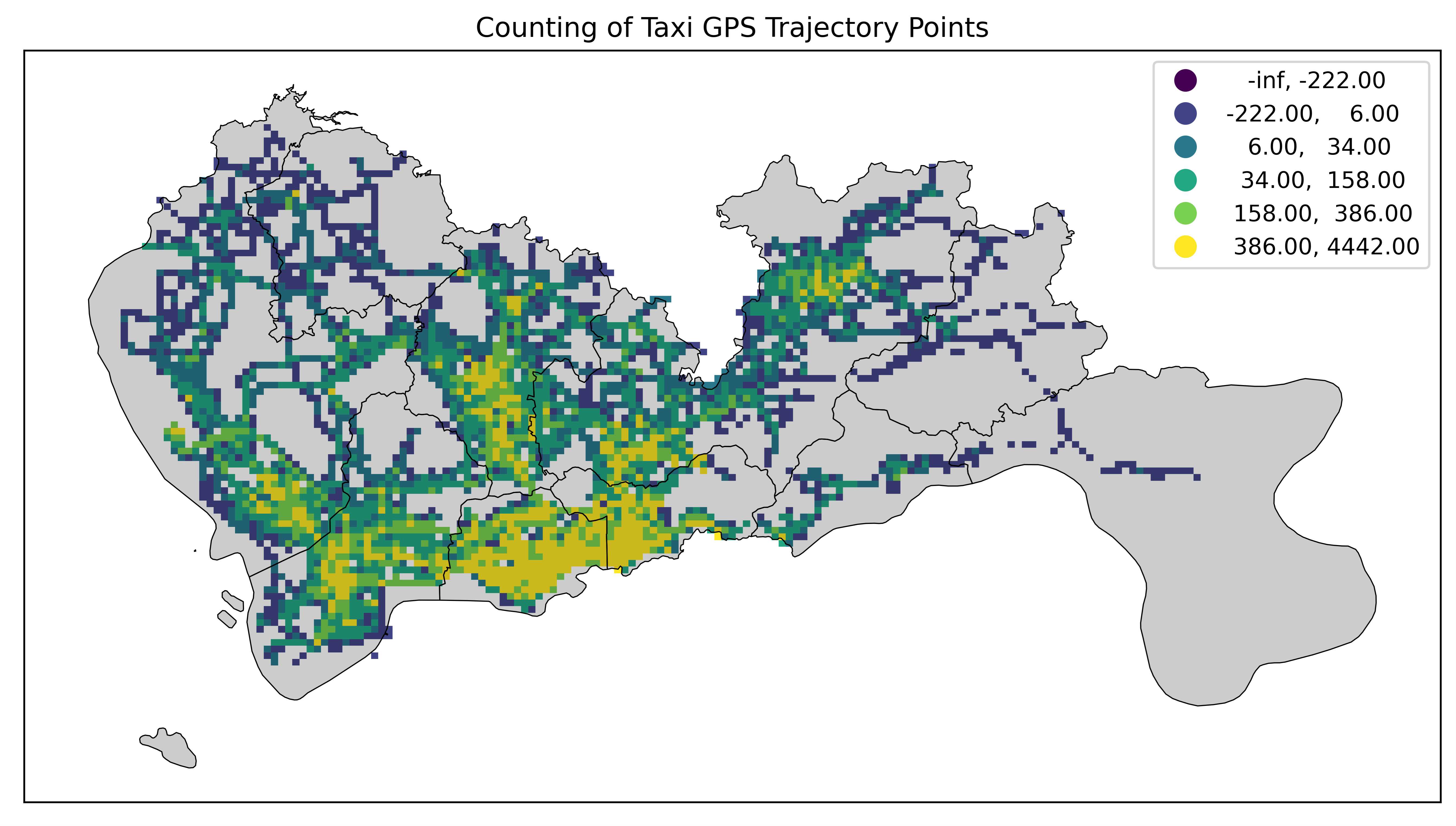
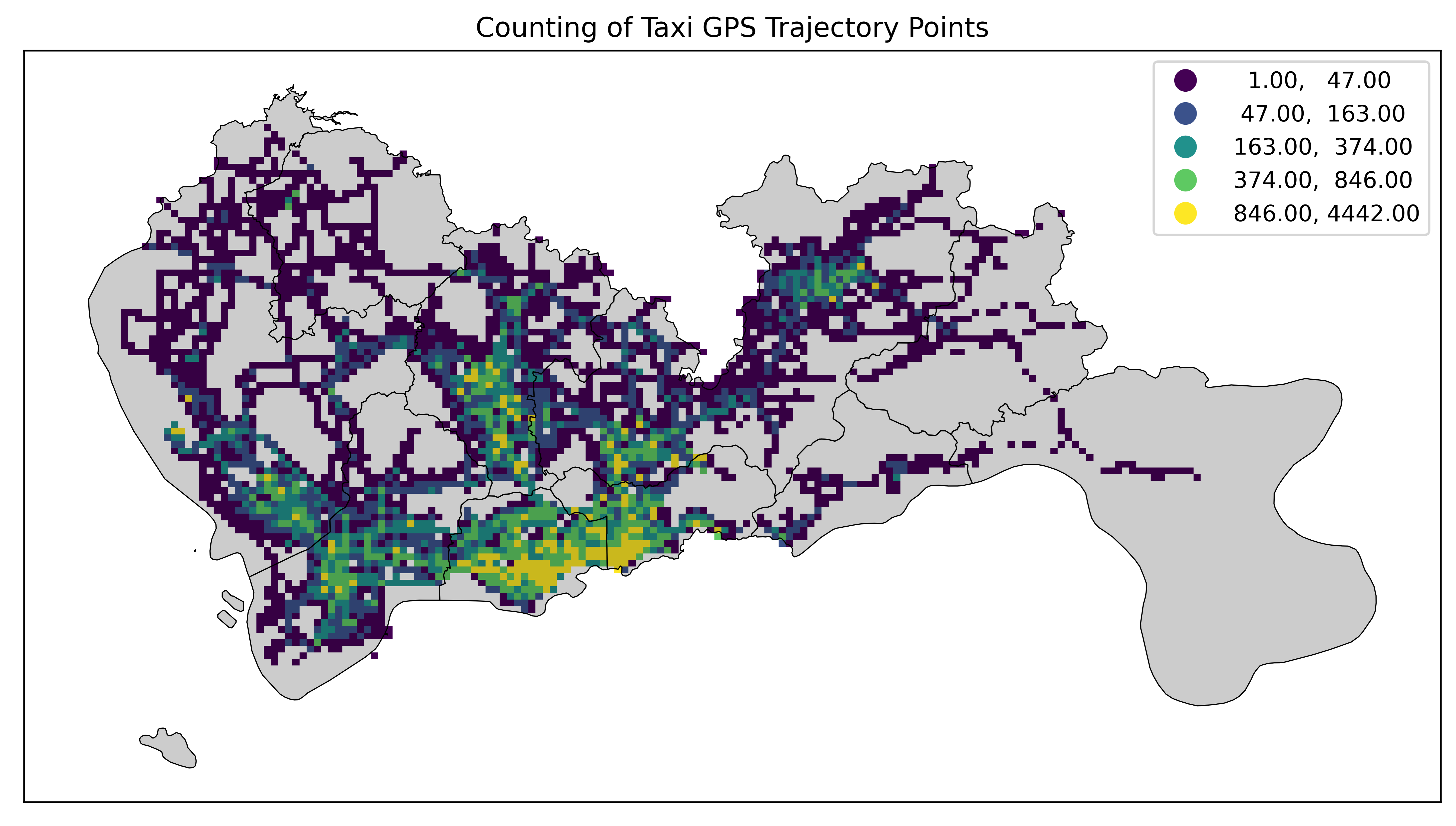
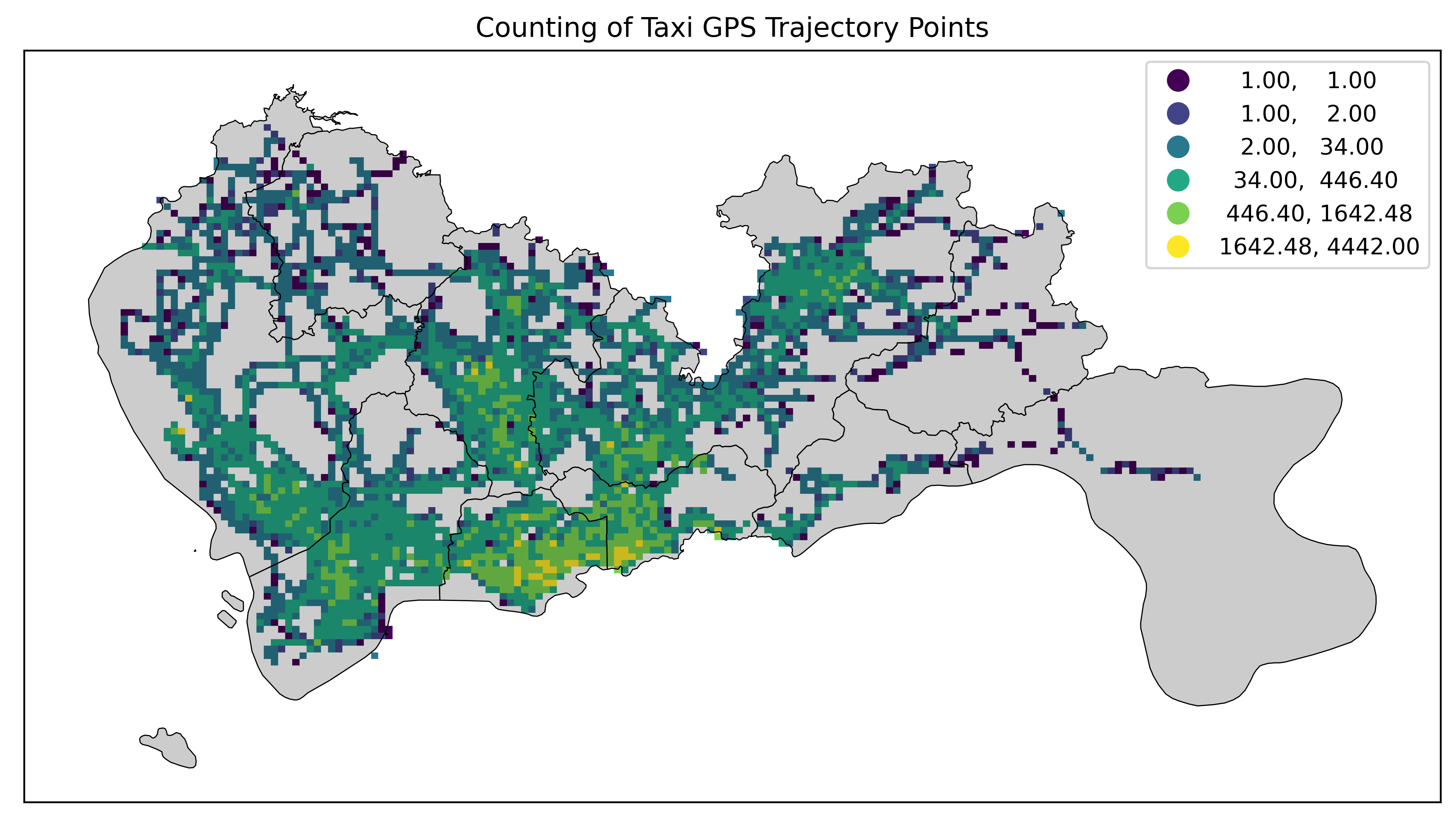
改分位数分类法显示数据:
fig = plt.figure(1, (16, 6), dpi=600)
ax = plt.subplot(111)
# tbd.plot_map(plt, bounds, zoom=14, style=1)
datatest.plot(ax=ax, column='VehicleNum', legend=True, scheme='quantiles')
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
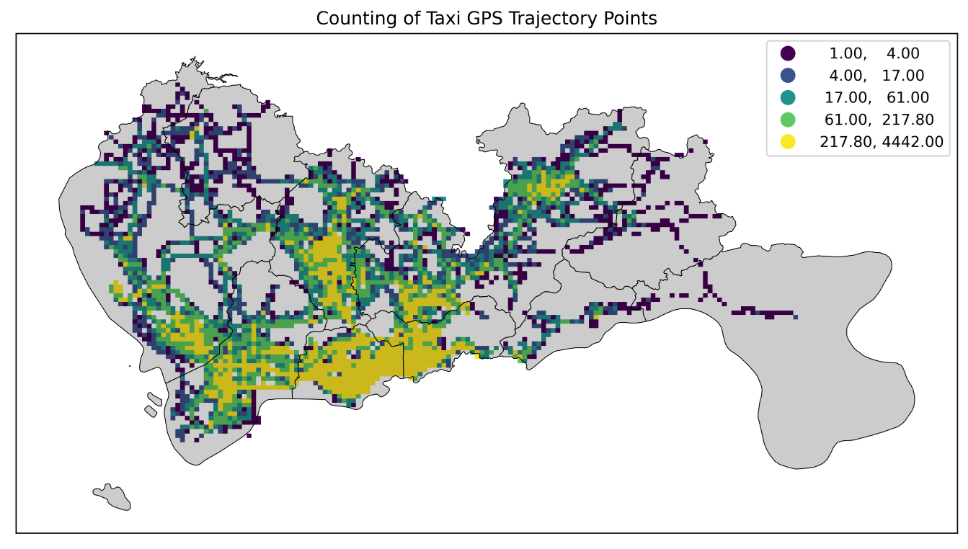 改变图像的图例颜色:
改变图像的图例颜色:
fig = plt.figure(1, (16, 6), dpi=600)
ax = plt.subplot(111)
#tbd.plot_map(plt, bounds, zoom=14, style=1)
datatest.plot(ax=ax, column='VehicleNum', legend=True, cmap='OrRd', scheme='quantiles')
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
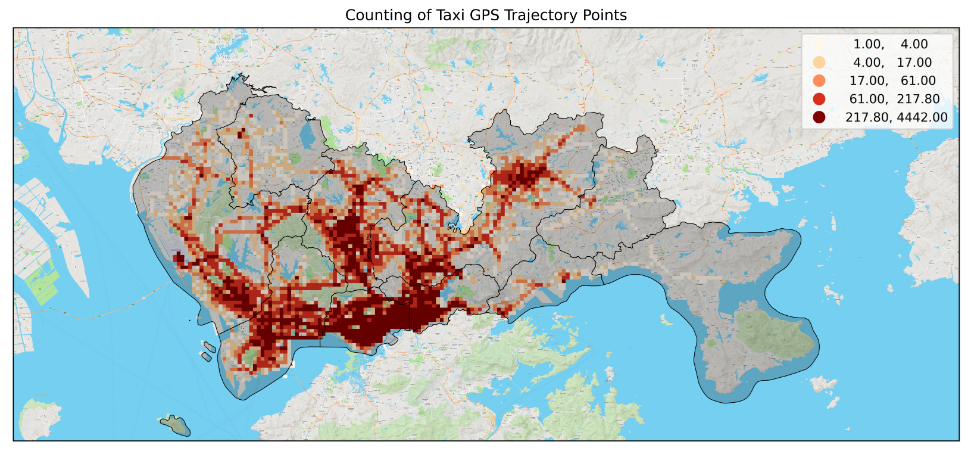
在此基础上添加地图底图:
fig = plt.figure(1, (16, 6), dpi=600)
ax = plt.subplot(111)
tbd.plot_map(plt, bounds, zoom=14, style=1)
datatest.plot(ax=ax, column='VehicleNum', legend=True, cmap='OrRd', scheme='quantiles')
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
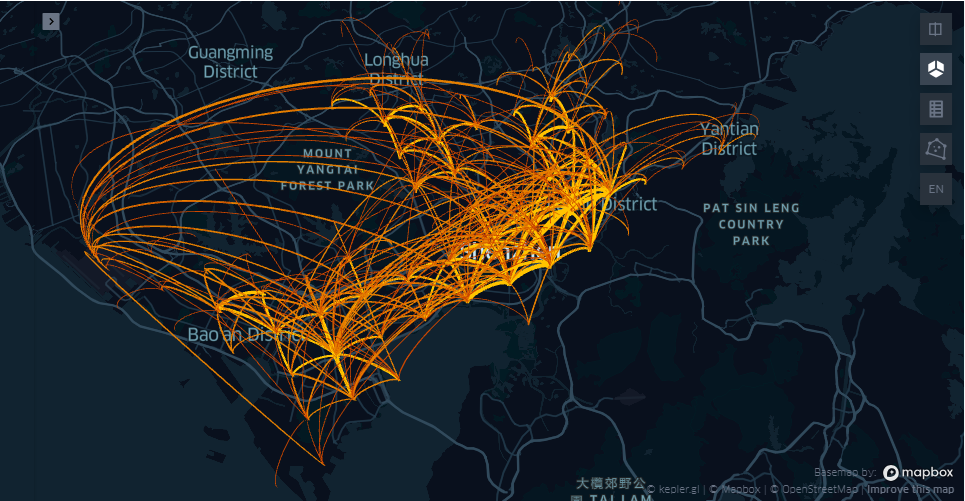
提取OD信息
oddata = tbd.taxigps_to_od(data, col=['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus'])
taxigps_to_od函数的代码实现:
def taxigps_to_od(data,
col=['VehicleNum', 'Stime', 'Lng', 'Lat', 'OpenStatus']):
'''
Input Taxi GPS data, extract OD information
Parameters
-------
data: DataFrame
Taxi GPS data
col: List
Column names in the data, need to be in order [vehicle id, time,
longitude, latitude, passenger status]
Returns
-------
oddata: DataFrame
OD information
'''
[VehicleNum, Stime, Lng, Lat, OpenStatus] = col
data1 = data[col]
data1 = data1.sort_values(by=[VehicleNum, Stime])
data1['StatusChange'] = data1[OpenStatus] - data1[OpenStatus].shift()
oddata = data1[((data1['StatusChange'] == -1) |
(data1['StatusChange'] == 1)) &
(data1[VehicleNum].shift() == data1[VehicleNum])]
oddata = oddata.drop([OpenStatus], axis=1)
oddata.columns = [VehicleNum, 'stime', 'slon', 'slat', 'StatusChange']
oddata['etime'] = oddata['stime'].shift(-1)
oddata['elon'] = oddata['slon'].shift(-1)
oddata['elat'] = oddata['slat'].shift(-1)
oddata = oddata[(oddata['StatusChange'] == 1) &
(oddata[VehicleNum] == oddata[VehicleNum].shift(-1))]
oddata = oddata.drop('StatusChange', axis=1)
oddata['ID'] = range(len(oddata))
return oddata
可视化OD信息
tbd.visualization_od(oddata, accuracy=3000, height=600) #a = tbd.visualization_od(oddata, accuracy=3000) #a.save_to_html(file_name='od_visua.html')
按栅格进行OD的展示:
params = tbd.area_to_params(bounds, accuracy=3000) od_gdf = tbd.odagg_grid(oddata, params) od_gdf.head()
绘制OD展示信息:
fig = plt.figure(1, (16, 6), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
od_gdf.plot(ax=ax, column='count', legend=True, cmap='Blues_r')
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('OD Trips', fontsize=12);
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
#tbd.plot_map(plt, bounds, zoom=12, style=1)
调整下标尺颜色:
fig = plt.figure(1, (16, 6), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
od_gdf.plot(ax=ax, column='count', legend=True, cmap='autumn_r')
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('OD Trips', fontsize=12);
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
# tbd.plot_map(plt, bounds, zoom=12, style=1)
可以看到上述展示中线路过细,尝试采取按照行政区进行OD的展示:
od_gdf = tbd.odagg_shape(oddata, sz, round_accuracy=6) od_gdf.plot(column='count')
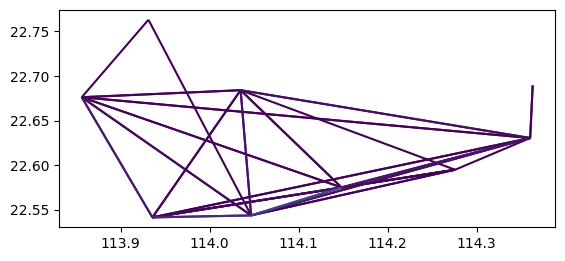
优化可视化内容:
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
# 添加地图底图
# tbd.plot_map(plt, bounds, zoom=12, style=1)
# 绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('OD\nMatrix')
plt.sca(ax)
# 绘制OD
od_gdf.plot(ax=ax, vmax=100, column='count', cax=cax, legend=True)
# 绘制小区底图
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
# 添加比例尺和指北针
tbd.plotscale(ax, bounds=bounds, textsize=10, compasssize=1, accuracy=2000, rect=[0.06, 0.03], zorder=10)
plt.axis('off')
plt.xlim(bounds[0], bounds[2])
plt.ylim(bounds[1], bounds[3])
plt.show()
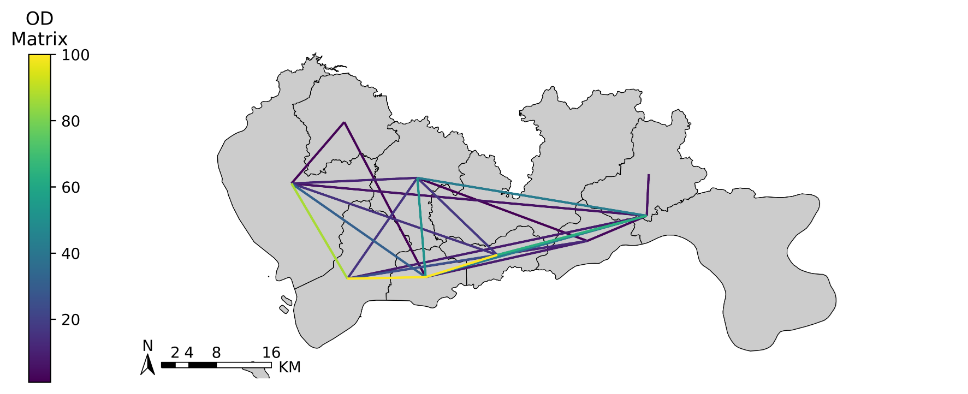
车辆载客与空闲的数据展示
data_deliver, data_idle = tbd.taxigps_traj_point(data, oddata, col=['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus'])
taxigps_traj_point的代码实现:
def taxigps_traj_point(data, oddata, col=['Vehicleid', 'Time', 'Lng', 'Lat', 'OpenStatus']): ''' Input Taxi data and OD data to extract the trajectory points for delivery and idle trips Parameters ------- data: DataFrame Taxi GPS data, field name specified by col variable oddata: DataFrame Taxi OD data col: List Column names, need to be in order [vehicleid, time, longitude, latitude, passenger status] Returns ------- data_deliver: DataFrame Trajectory points for delivery trips data_idle: DataFrame Trajectory points for idle trips ''' VehicleNum, Time, Lng, Lat, OpenStatus = col oddata1 = oddata.copy() odata = oddata1[[VehicleNum, 'stime', 'slon', 'slat', 'ID']].copy() odata.columns = [VehicleNum, Time, Lng, Lat, 'ID'] odata.loc[:, 'flag'] = 1 odata.loc[:, OpenStatus] = -1 ddata = oddata1[[VehicleNum, 'etime', 'elon', 'elat', 'ID']].copy() ddata.columns = [VehicleNum, Time, Lng, Lat, 'ID'] ddata.loc[:, 'flag'] = -1 ddata.loc[:, OpenStatus] = -1 data1 = pd.concat([data, odata, ddata]) data1 = data1.sort_values(by=[VehicleNum, Time, OpenStatus]) data1['flag'] = data1['flag'].fillna(0) data1['flag'] = data1.groupby(VehicleNum)['flag'].cumsum() data1['ID'] = data1['ID'].ffill() data_deliver = data1[(data1['flag'] == 1) & (-data1['ID'].isnull()) & (data1[OpenStatus] != -1)] data_idle = data1[(data1['flag'] == 0) & (-data1['ID'].isnull()) & (data1[OpenStatus] != -1)] return data_deliver, data_idle
展示载客行程:
# 创建图框
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
# 添加地图底图
# tbd.plot_map(plt, bounds, zoom=12, style=1)
# 绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('OD\nMatrix')
plt.sca(ax)
# 绘制OD
traj_deliver = tbd.traj_to_linestring(data_deliver)
traj_deliver.plot(ax=ax);
# 绘制小区底图
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
# 添加比例尺和指北针
tbd.plotscale(ax, bounds=bounds, textsize=10, compasssize=1, accuracy=2000, rect=[0.06, 0.03], zorder=10)
plt.axis('off')
plt.xlim(bounds[0], bounds[2])
plt.ylim(bounds[1], bounds[3])
plt.title('Driver carrying passengers', fontsize=12);
plt.show()
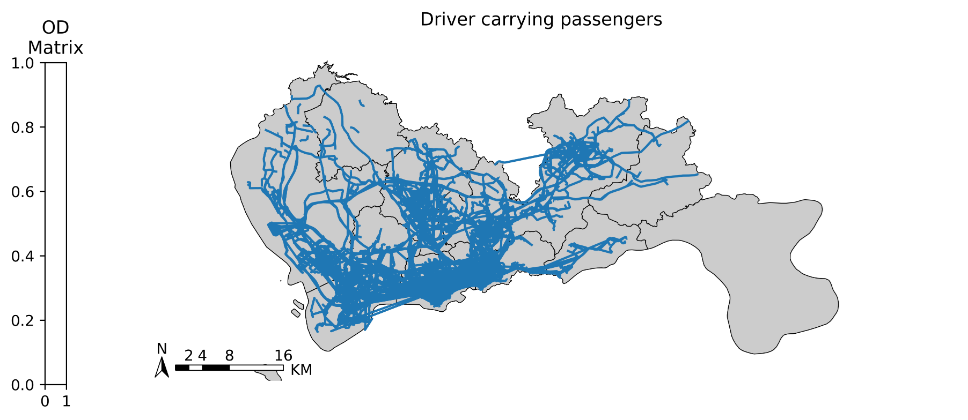
司机空载路径:
# 创建图框
fig = plt.figure(1, (10, 10), dpi=800)
ax = plt.subplot(111)
plt.sca(ax)
# 添加地图底图
# tbd.plot_map(plt, bounds, zoom=12, style=1)
# 绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('OD\nMatrix')
plt.sca(ax)
# 绘制OD
traj_deliver = tbd.traj_to_linestring(data_idle)
traj_deliver.plot(ax=ax);
# 绘制小区底图
sz.plot(ax=ax, edgecolor=(0, 0, 0, 1), facecolor=(0, 0, 0, 0.2), linewidths=0.5)
# 添加比例尺和指北针
tbd.plotscale(ax, bounds=bounds, textsize=10, compasssize=1, accuracy=2000, rect=[0.06, 0.03], zorder=10)
plt.axis('off')
plt.xlim(bounds[0], bounds[2])
plt.ylim(bounds[1], bounds[3])
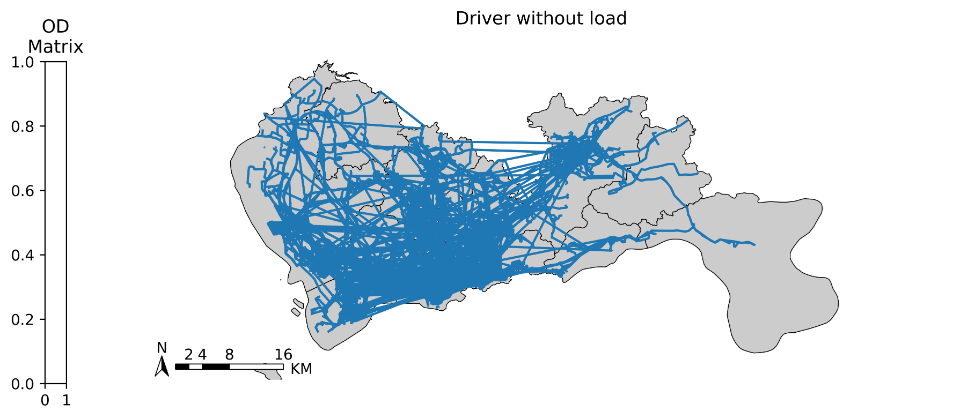
plt.title('Driver without load', fontsize=12);
plt.show()
司机动态轨迹图:
tbd.visualization_trip(data_deliver) # 一天当中的所有载客轨迹 # a = tbd.visualization_trip(data_deliver) # a.save_to_html(file_name='data_visua_vedio.html')
拓展知识:GeoPandas的scheme参数
在GeoPandas的plot方法中,scheme参数用于对数据进行分类(分箱),这是在绘制分类地图时非常有用的功能。scheme参数通常与column参数一起使用,以便根据某一列的数据值进行分类显示。
GeoPandas中的scheme参数依赖于mapclassify库来实现数据分类。mapclassify提供了多种分类算法,如自然断点、分位数、等间距等。
以下是一些常见的分类方法:
- BoxPlot: 盒形图分类法
- EqualInterval: 等间隔分类法
- FisherJenks: Fisher-Jenks最优分类法
- HeadTailBreaks: 头尾分类法
- JenksCaspall: Jenks-Caspall最优分类法
- MaxP: 最大概率分类法
- NaturalBreaks: 自然断点分类法
- Quantiles: 分位数分类法
- StdMean: 标准差分类法
box_plot
盒形图分类法(BoxPlot)基于统计学中的盒须图(Boxplot)。这种方法将数据分为四分位数(Q1,Q2,Q3),Q1代表第一四分位数,Q2代表中位数(第二四分位数),Q3代表第三四分位数。数据被分成四个区间:低于Q1-1.5(IQR)的区间,Q1到Q2的区间,Q2到Q3的区间,以及高于Q3+1.5(IQR)的区间。这种方法可以帮助识别异常值和数据分布的对称性。
equal_interval
等间隔分类法(EqualInterval)将数据范围划分为相等大小的区间。例如,如果你有10个类,且数据范围是0到100,每个区间将是10(100/10)。这种方法简单直观,但可能不均匀地分布数据,导致某些区间内数据过于密集,而其他区间内数据稀疏。
fisher_jenks
Fisher-Jenks最优分类法(Fisher-Jenks)是一种迭代算法,旨在最小化类别内部的方差(变异性)并最大化类别间的差异。它通过不断尝试不同分割点来寻找最优的分类。这种方法对于分类具有连续分布的数据特别有效。
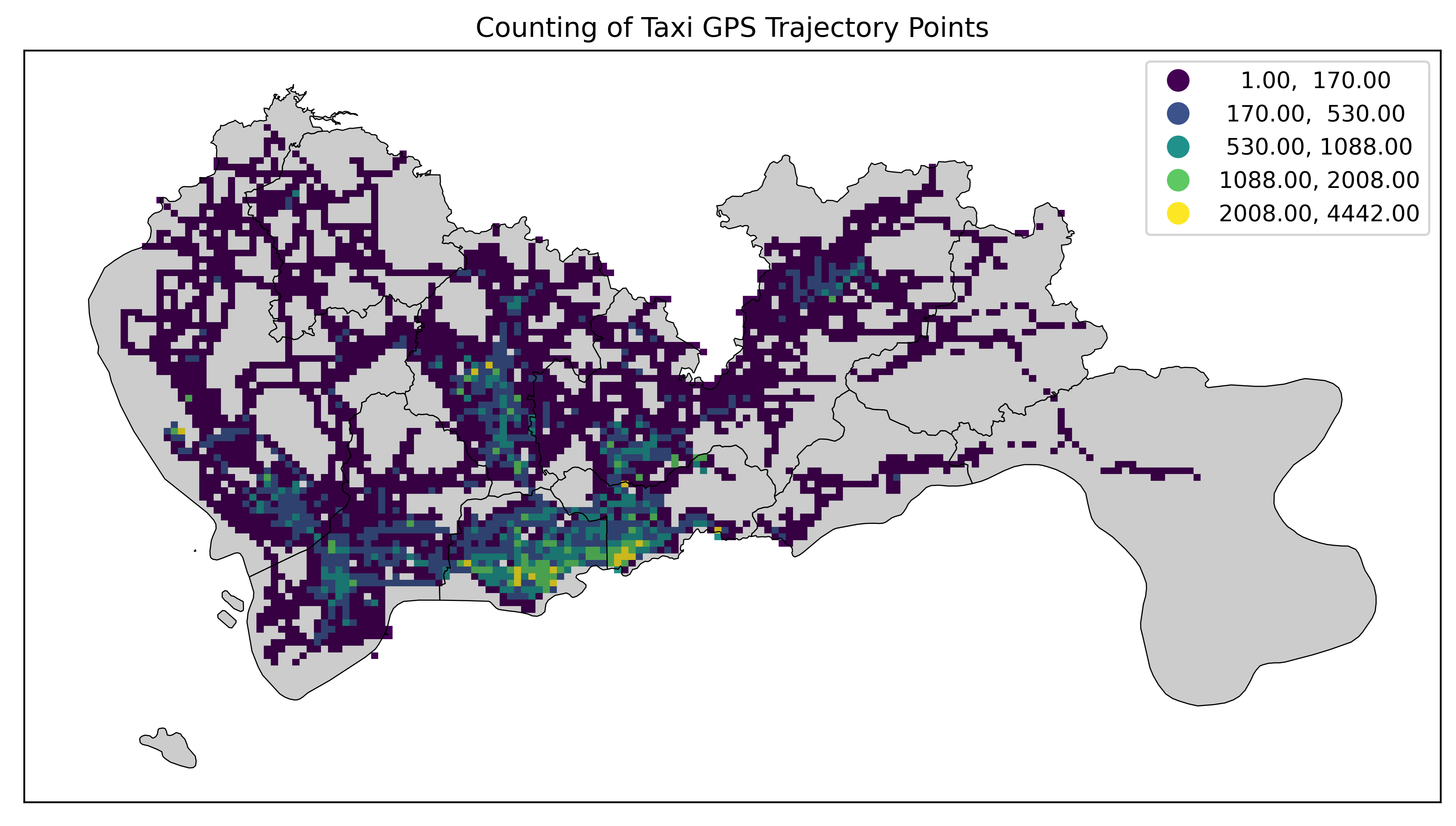
fisher_jenks_sampled
FisherJenks算法的采样版本,适用于大数据集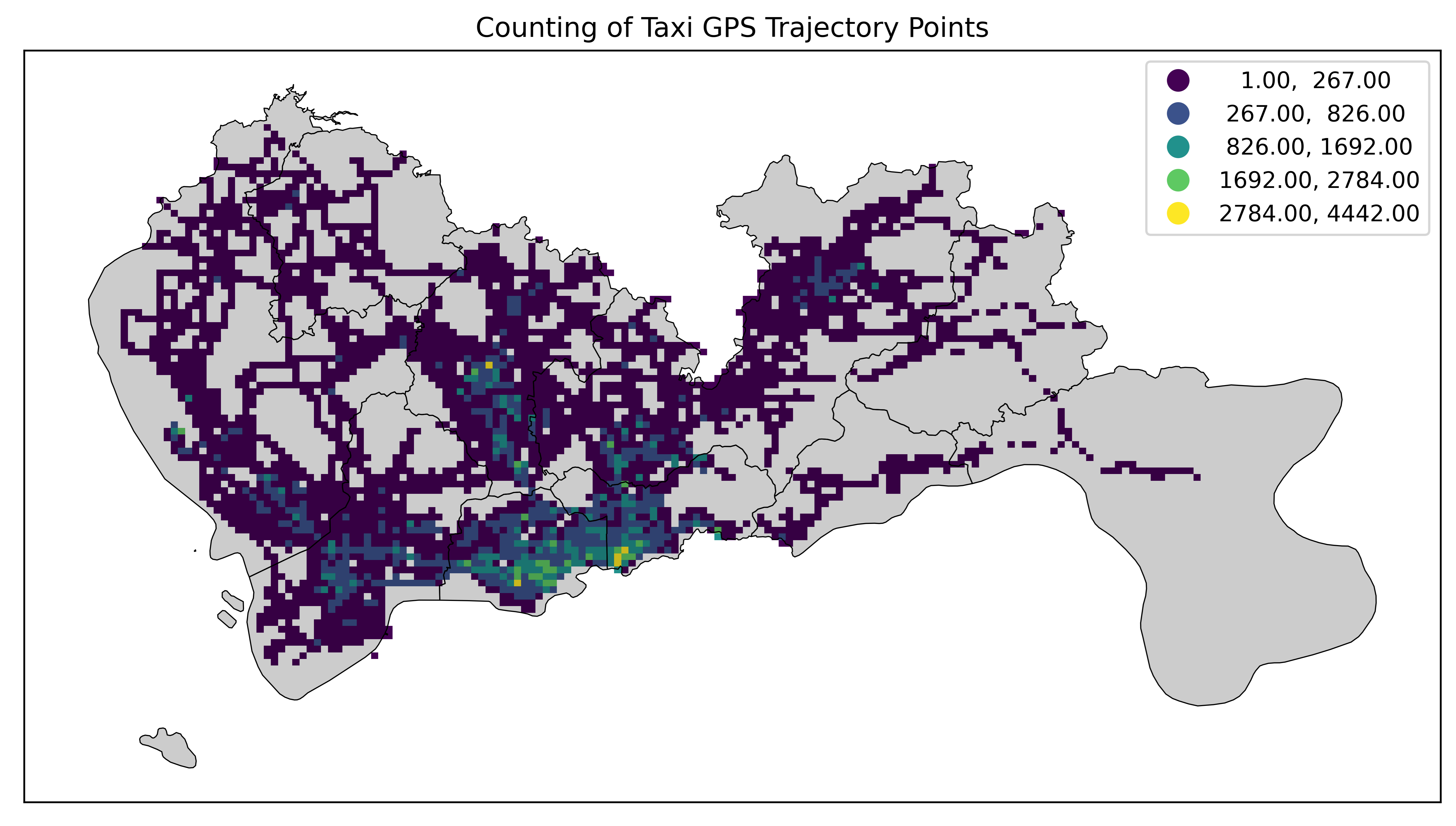
headtail_breaks
头尾分类法(Head-TailBreaks)是一种分箱方法,旨在突出显示数据的长尾分布。它通过识别数据中的“头”(高值)和“尾”(低值)来创建分类,以减少高密度区域的影响并突出显示低密度区域。这种方法特别适用于城市人口密度、交通流量等具有明显峰值和尾部的数据。
jenks_caspall
Jenks-Caspall最优分类法是Fisher-Jenks分类法的一种变体,同样基于最小化内部方差和最大化类别间差异的原则。它通过计算每种可能的分类组合的方差来确定最佳分类。
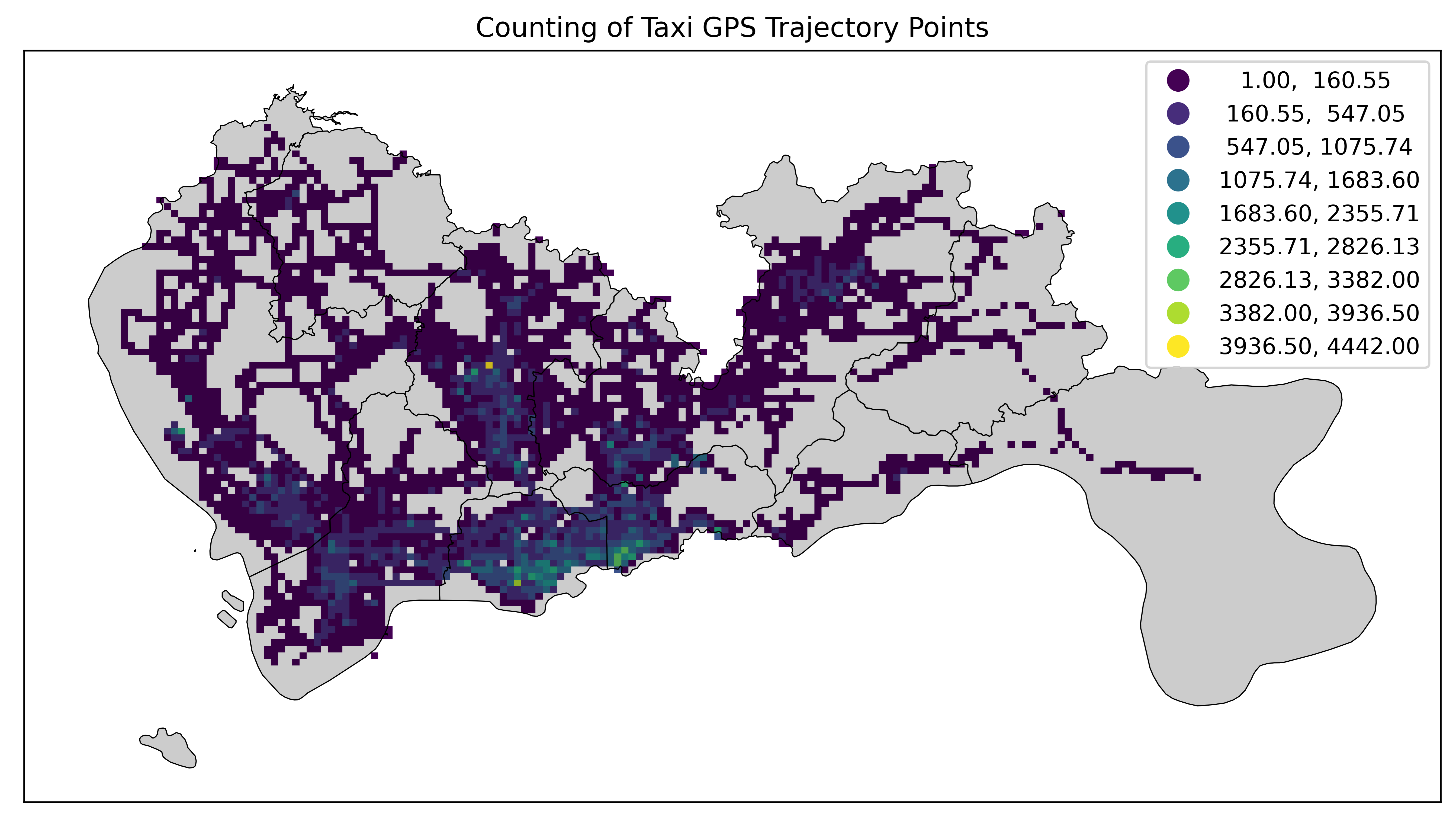
maximum_breaks
MaximumBreaks(最大断点分类法)是一种用于地理空间数据分类的方法,其目标是通过最大化类别之间的差异来进行数据分级。这种方法通过找到数据中的断点,使得断点尽可能将数据分成具有显著差异的组。
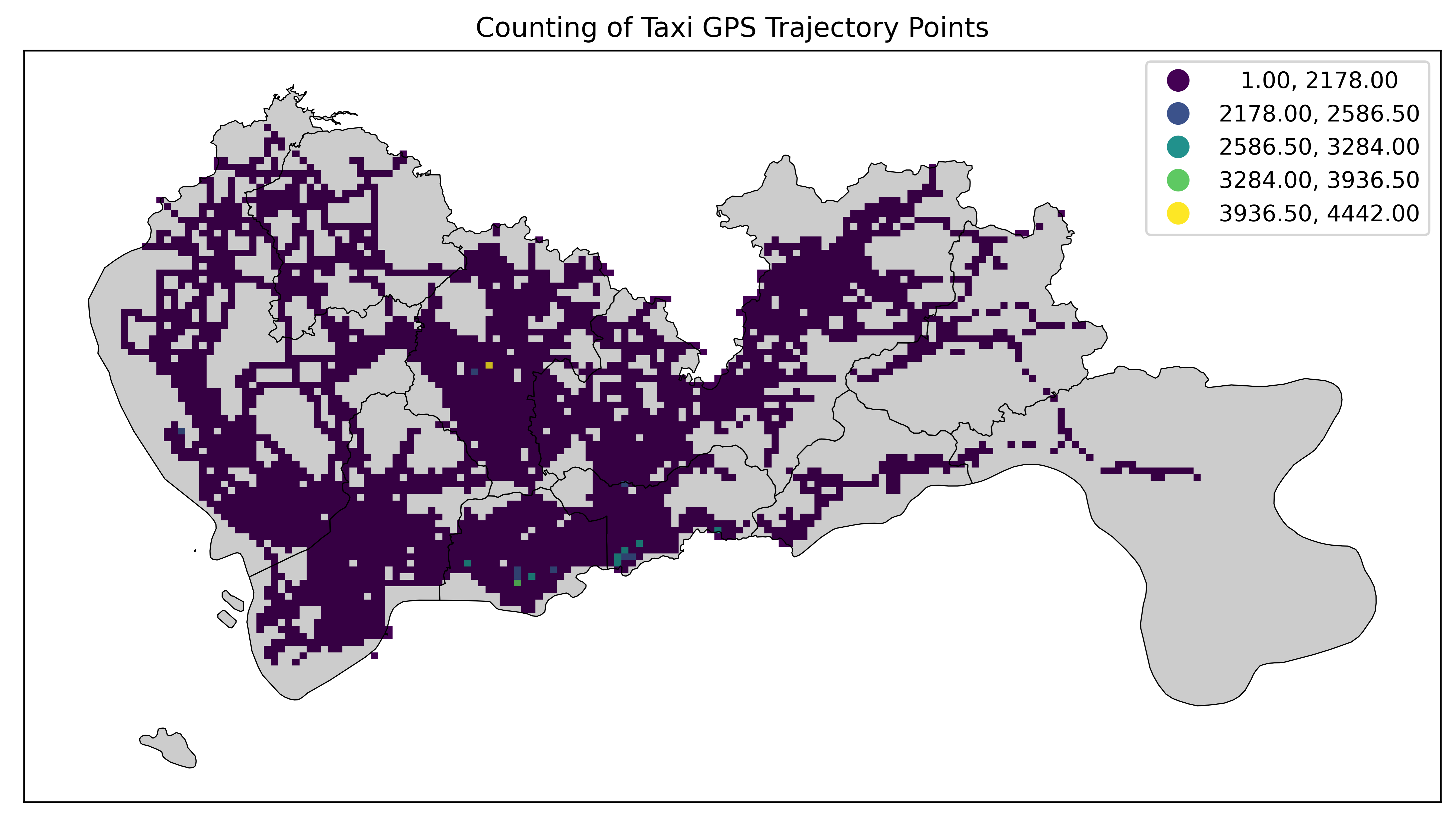 Natural Breaks
Natural Breaks
自然断点分类法(Natural Breaks)类似于Fisher-Jenks,也试图最小化内部方差并最大化类别间差异。它基于数据的内在分组模式,而不是固定数量的区间。这种方法对于数据分布不均匀的情况很有用。
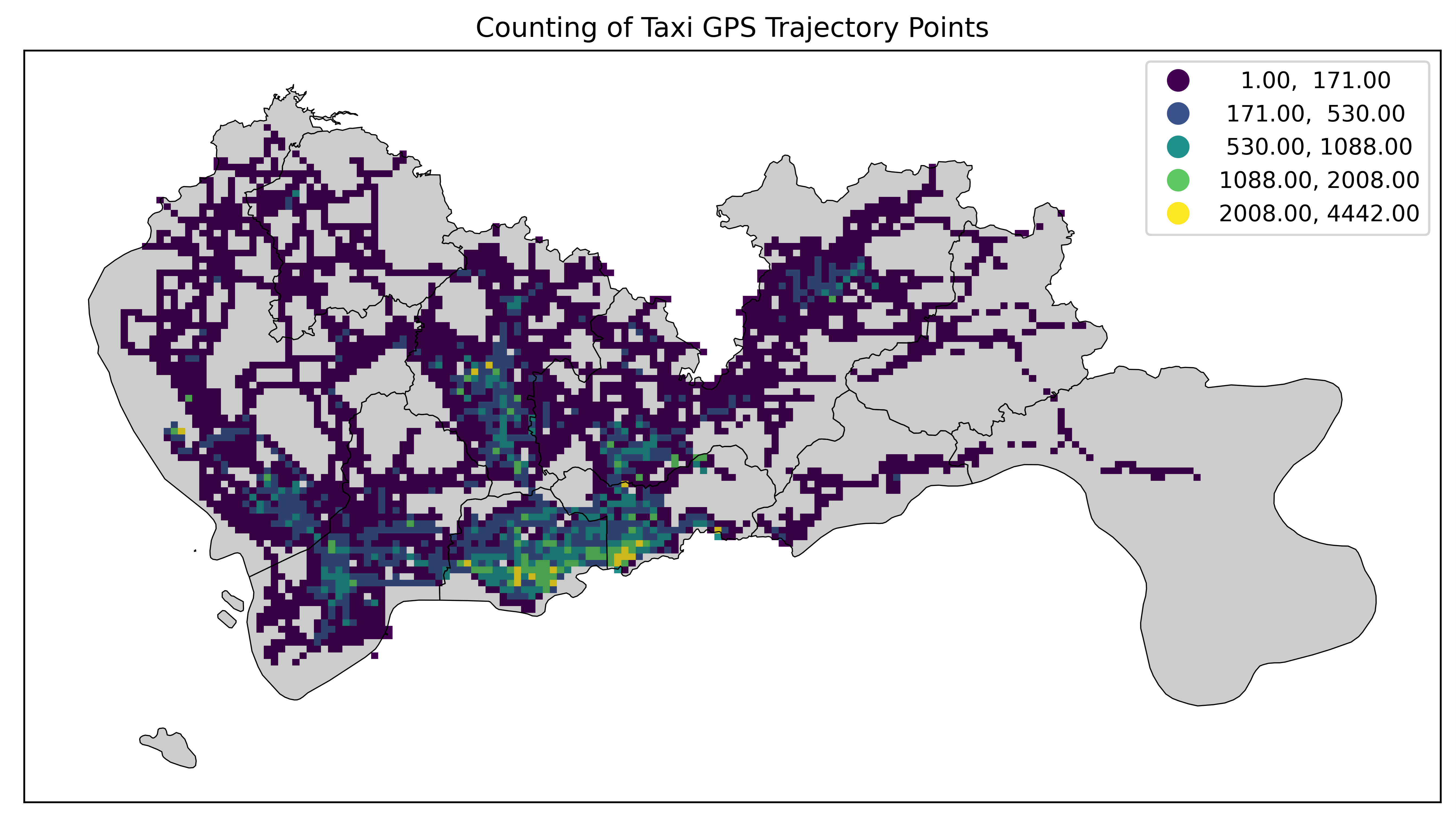
Max P
Max P分类法(Maximum Purity)寻找每个类别的纯度最大。它试图找到一种划分方式,使得每个类别的数据点都尽可能属于同一类。这种方法适用于多分类问题,特别是当类别数量未知时。
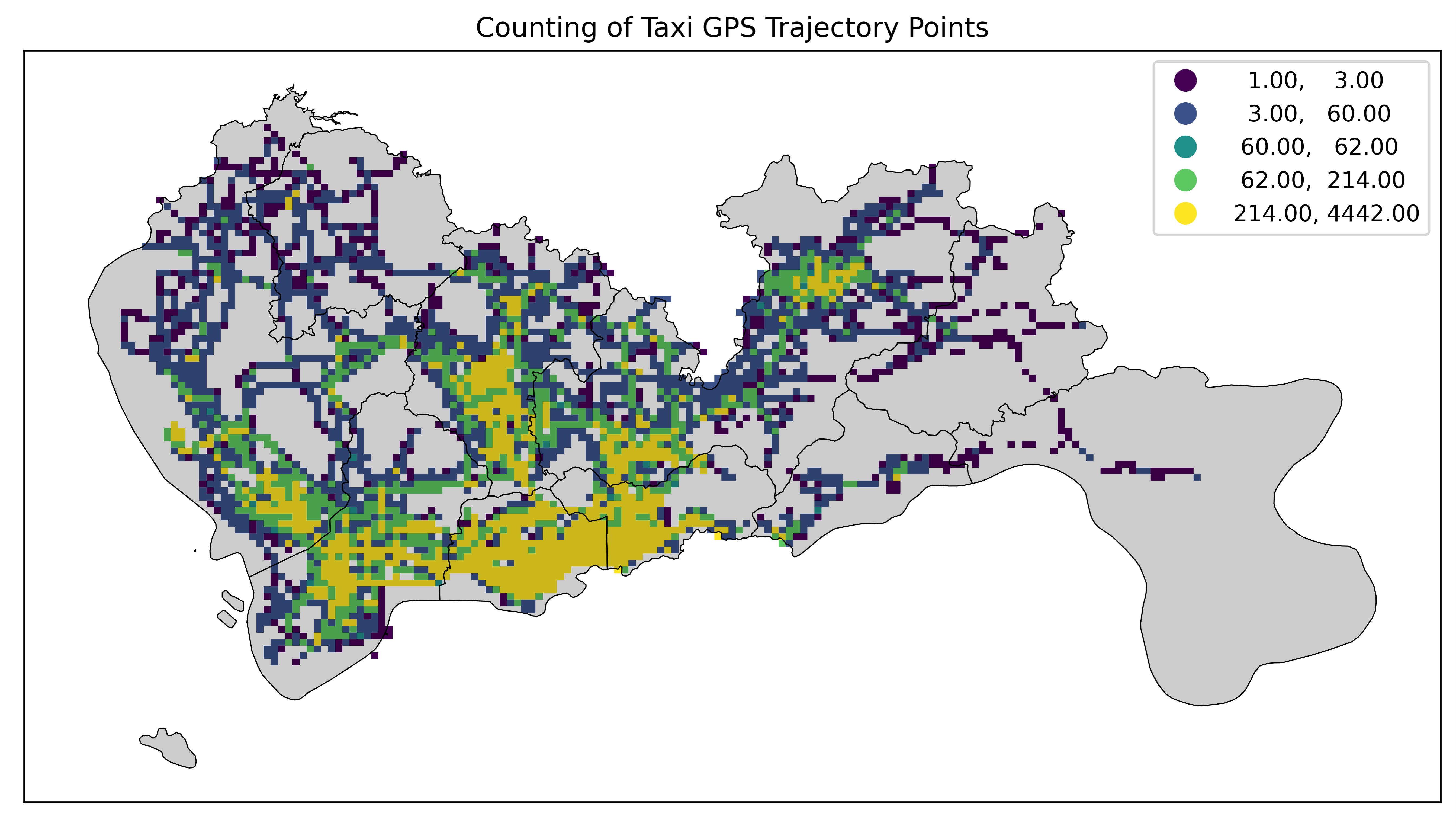
quantiles
分位数分类法(Quantiles)将数据分为相等数量的类,每个类包含相同数量的数据点(如果数据点总数是类数的倍数)。例如,如果数据有100个点,且分为4类,那么每个类将有25个点。这种方法确保了每个类别的大小大致相等,但可能会忽略数据的分布特征。
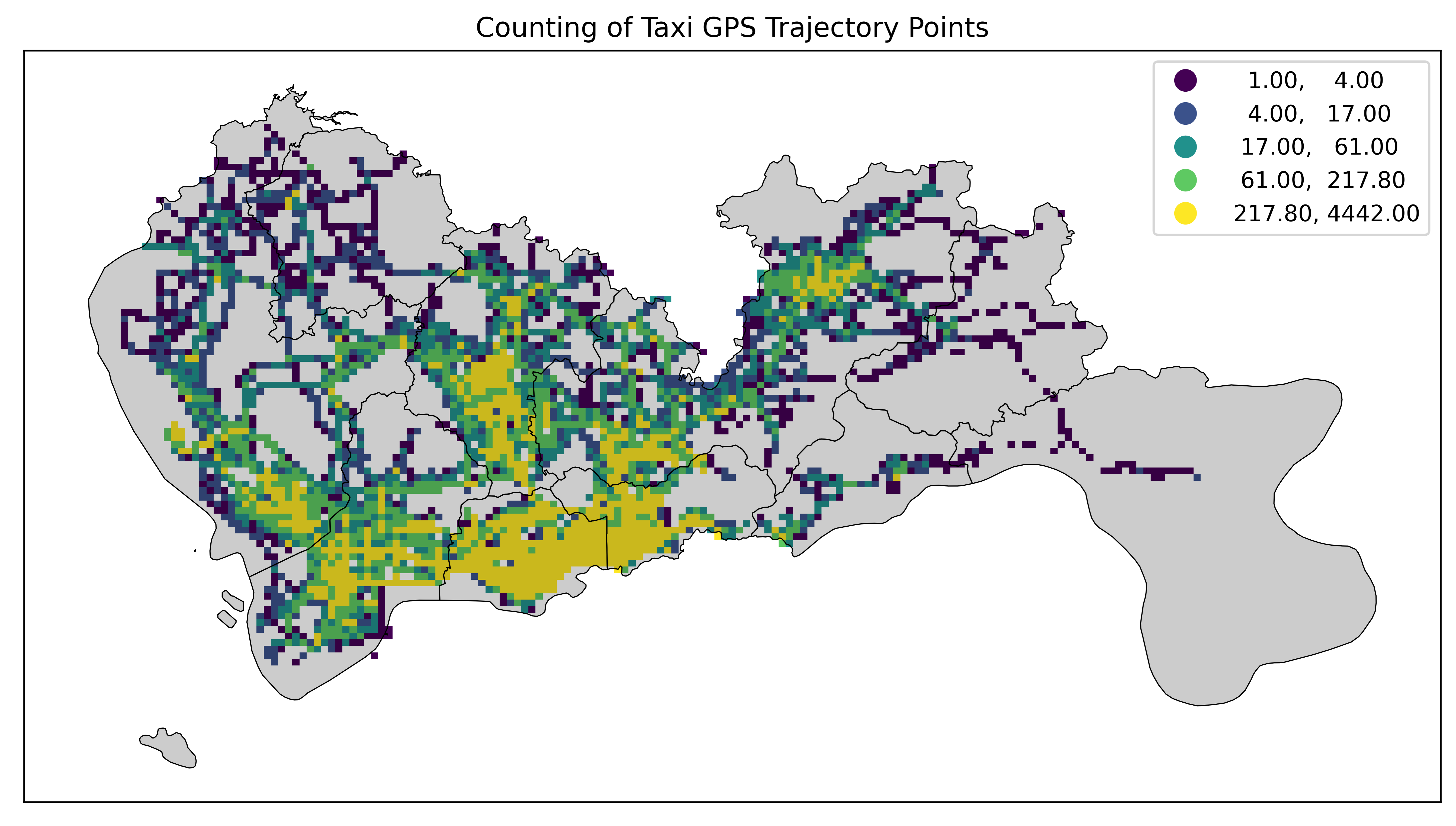
percentiles
百分位数分类法(Percentiles)是一种基于数据的百分位数将数据划分成若干个区间的分类方法。每个区间包含相同比例的数据点。与分位数(Quantiles)分类法类似,但更加细化,通常用于需要更高精度的数据分类。
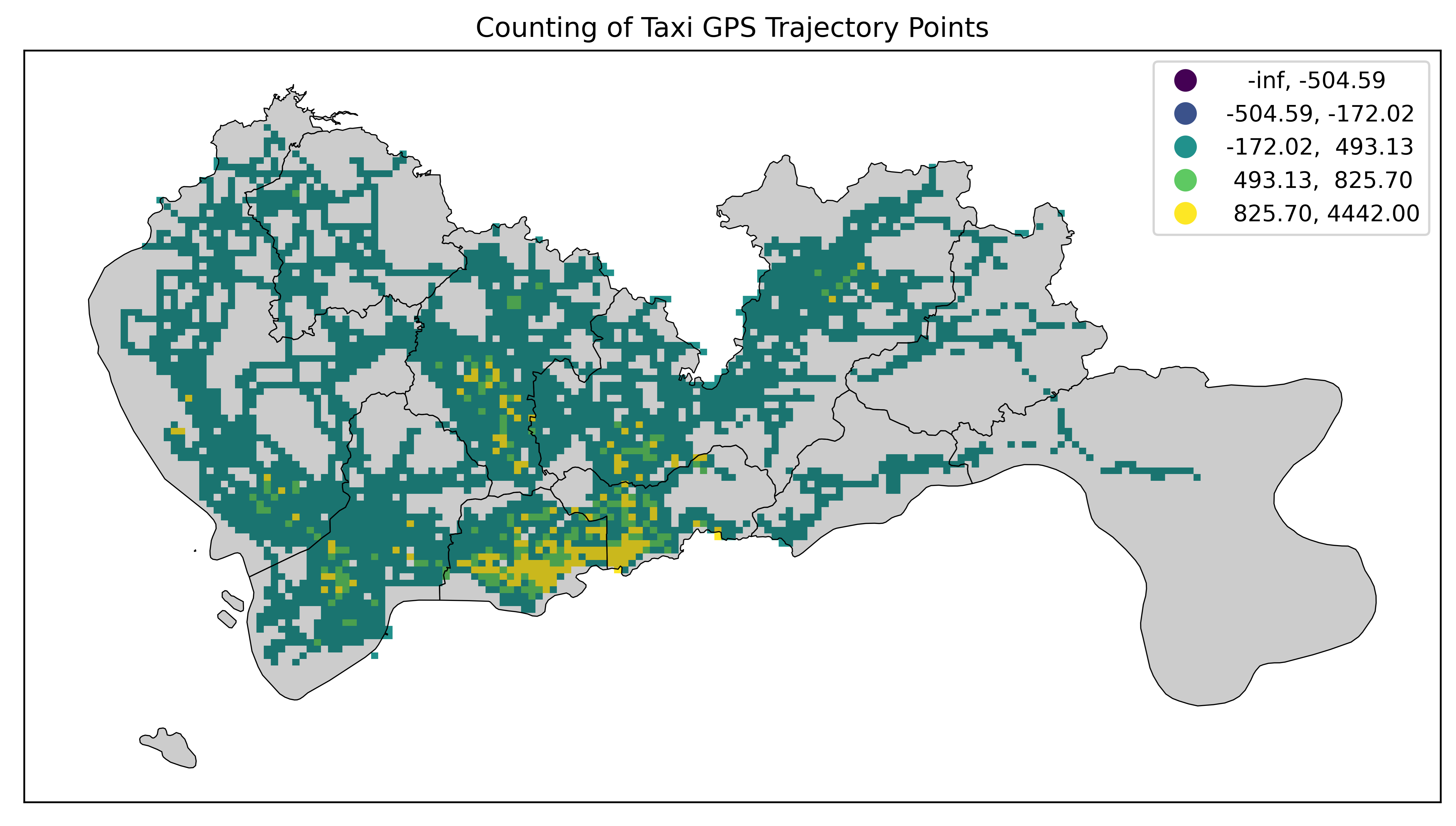
std_mean
标准差分类法(Std Mean)基于数据的平均值(均值)和标准差。它将数据分为几个区间,每个区间内的数据点距离均值的偏差小于一定倍数的标准差。这种方法强调了数据的离群值和集中趋势。
参考链接:


