文章内容如有错误或排版问题,请提交反馈,非常感谢!
Trino简介
Trino(原名PrestoSQL)是一个开源的分布式SQL查询引擎,设计用于对各种数据源进行高速查询。Trino的设计初衷是为了解决大规模数据分析的需求,能够在数据湖、数据仓库和其他数据存储系统上进行交互式分析。

Trino的由来
PrestoSQL改名为Trino的主要原因是与Presto项目相关的商标和社区治理问题。以下是这一名称变更背后的详细背景和原因:
背景
- 项目分裂: Presto项目最初由Facebook开发,并在开源社区中获得了广泛的关注。然而,随着时间的推移,Presto社区出现了分裂。2019年,Presto的原始创始者之一以及一些核心开发人员因为对项目治理和发展方向的分歧,决定从Facebook的Presto项目中分离出来,创建了一个新的分支,称为PrestoSQL。
- 商标问题: 由于Presto的商标由Facebook控制,PrestoSQL团队在使用Presto名称时面临法律和商标限制。这限制了他们在项目的推广和商业化上的灵活性。
- 社区治理: PrestoSQL团队希望建立一个更加开放和社区驱动的治理模式,以促进项目的长期发展和开源社区的参与。他们选择通过创建一个新的品牌来实现这一目标。
改名为Trino
- 独立品牌: 改名为Trino使得该项目能够在法律上和品牌上与原始的Presto项目区分开来。这为Trino社区提供了更大的独立性和灵活性。
- 统一社区: Trino名称的引入帮助凝聚了PrestoSQL社区,并吸引了更多的开发者和用户参与项目的发展。
- 持续发展: 改名后,Trino团队可以专注于项目的技术改进和功能扩展,而不受商标问题的制约。
PrestoSQL改名为Trino是为了解决商标和社区治理问题,并为项目的长期发展奠定基础。通过创建一个独立的品牌,Trino能够更好地实现其技术目标和社区愿景,继续在大数据分析领域发挥重要作用。这一改名不仅促进了项目的发展,也为用户提供了一个明确的品牌标识,帮助他们更好地理解和使用这一强大的分布式SQL查询引擎。
核心功能
- 分布式查询引擎: Trino是一个高度并行的分布式查询引擎,能够在多个节点上同时处理查询,以提高性能和扩展性。
- 多数据源支持: 支持从多种数据源中查询数据,包括HDFS、S3、Kafka、MySQL、PostgreSQL、Cassandra、MongoDB等。
- SQL标准支持: 支持ANSI SQL,提供丰富的SQL功能,包括窗口函数、子查询、聚合、连接等。
- 无数据复制: Trino可以直接在原始数据存储上运行查询,而无需预先提取或复制数据,减少了数据管理的复杂性。
- 可扩展性: 设计为可水平扩展,能够通过添加更多的计算节点来提高查询性能和处理能力。
- 实时查询: 支持低延迟的实时查询,适用于交互式数据分析和报表生成。
应用场景
Trino是一个灵活且高性能的分布式SQL查询引擎,适用于各种数据分析和处理场景。以下是Trino的一些典型应用场景:
- 交互式分析: Trino的低延迟和高并发能力使其非常适合用于交互式数据分析。用户可以使用熟悉的SQL语法对大规模数据集进行快速查询和分析,支持实时决策和数据探索。
- 多源数据查询: Trino支持从多种数据源(如HDFS、S3、Kafka、MySQL、PostgreSQL、Cassandra、MongoDB等)查询数据。它能够跨多个数据源进行联合查询,帮助企业在不移动数据的情况下整合和分析数据。
- 数据湖查询: 在数据湖场景中,Trino可以直接查询存储在HDFS或S3上的海量非结构化和半结构化数据。其高效的查询引擎能够在数据湖上实现复杂的分析任务。
- 大数据ETL: Trino可以用作数据管道中的一个组件,执行大规模的ETL(Extract, Transform, Load)任务。其强大的计算能力和灵活的SQL支持,使得数据转换和加载过程更加高效。
- 商业智能(BI)集成: Trino可以与各种BI工具(如Tableau、Power BI、Looker)集成,提供后端数据查询支持。用户可以通过这些工具对Trino的查询结果进行可视化和报告生成。
- 数据科学与机器学习: 数据科学家可以使用Trino从多个数据源中提取数据,用于机器学习模型训练和数据分析。其快速的查询能力有助于加速数据准备过程。
- 实时数据处理: Trino支持对实时数据流(如Kafka)的查询和处理,适用于需要实时数据分析的场景,如监控、告警和实时报告。
- 数据合规和治理: 通过与数据治理工具的集成,Trino可以帮助企业管理和监控数据使用情况,确保数据访问的合规性和安全性。
Trino是一个强大的分布式SQL查询引擎,适合用于处理大规模和多样化的数据分析任务。其灵活的架构设计允许用户直接在多种数据源上运行查询,提供了高性能和可扩展的解决方案。无论是在数据湖、数据仓库还是实时数据流环境中,Trino都能够帮助企业和组织实现高效的数据查询和分析。
Trino的架构
架构概览
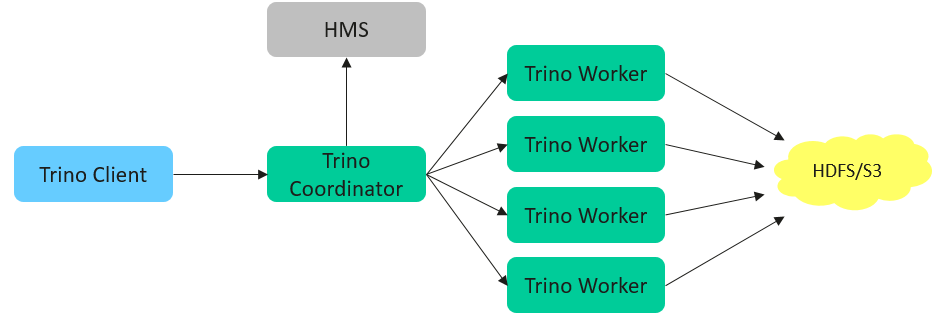
Trino的架构设计为分布式系统,主要包括以下组件:
- Coordinator(协调器): 负责解析SQL查询、生成查询计划、调度任务以及管理整个查询执行过程。协调器还负责与客户端的交互。
- Worker(工作节点): 执行实际的查询任务,处理数据扫描、过滤、聚合和传输等操作。多个工作节点协同工作以提高查询效率。
- Connector(连接器): 提供与各种数据源的集成接口,允许Trino直接查询不同类型的数据存储系统。每种数据源通常有一个对应的连接器。
- Catalog(目录): 通过连接器配置的数据源集合。用户可以通过SQL查询指定要使用的目录和数据源。
工作流程
- 查询提交: 用户通过SQL客户端向Trino提交查询请求。
- 查询解析与计划: 协调器解析SQL查询,生成逻辑和物理查询计划,并将查询任务分解为多个阶段。
- 任务调度: 协调器将任务调度到多个工作节点,分布式执行查询。
- 数据处理: 工作节点从数据源读取数据,执行计算任务,如过滤、聚合、排序等。
- 结果合并与返回: 各工作节点将计算结果返回给协调器,协调器合并结果并返回给客户端。
参考链接:


