文章内容如有错误或排版问题,请提交反馈,非常感谢!
Cassandra简介
Apache Cassandra是一个开源的分布式NoSQL数据库系统,旨在处理大型数据集并提供高可用性和无单点故障。它最初由Facebook开发,用于解决其收件箱搜索问题,并在2008年开源。Cassandra以其可扩展性和高性能著称,适合需要快速写入和读取大量数据的应用。
核心特点
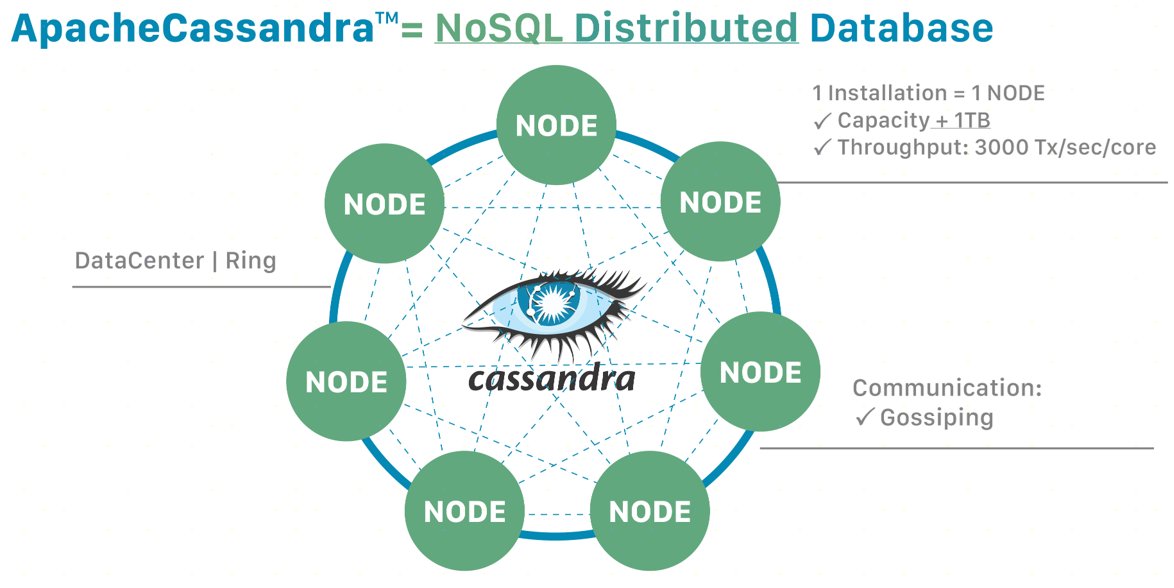
- 分布式和去中心化架构:
- Cassandra使用对等(peer-to-peer)架构,没有单点故障。所有节点在集群中具有相同的角色,数据和请求可以在任何节点上处理。
- 这种架构允许Cassandra轻松地进行横向扩展,以应对不断增长的数据需求。
- 高可用性和无单点故障:
- 数据在多个节点上复制,确保即使部分节点故障,数据也能继续可用。
- 通过配置不同的数据复制策略,Cassandra能够在多个数据中心之间进行数据复制,以实现地理上的高可用性。
- 线性可扩展性:
- Cassandra能够通过增加更多节点来线性增加其处理能力和存储容量。
- 在不影响系统性能的情况下,集群可以动态地添加或移除节点。
- 强大的写入和读取性能:
- Cassandra优化了写入路径,支持高吞吐量的写入操作,同时提供低延迟的读取。
- 它使用日志结构合并树(LSM-Tree)来有效地管理磁盘I/O。
- 灵活的数据模型:
- 支持基于键值的列族数据模型,可以存储结构化或半结构化的数据。
- 允许定义复杂的表结构,包括主键、分区键和集群列。
- 可调的一致性:
- Cassandra提供可调的一致性级别,允许用户根据需求在一致性和可用性之间进行权衡。
- 支持从单节点的强一致性到最终一致性的不同级别配置。
技术架构
- 数据模型:
- 键空间(Keyspace):相当于传统数据库中的数据库,包含多个列族。
- 列族(ColumnFamily):类似于关系数据库中的表,由行组成。
- 行(Row):由唯一的行键标识,包含多个列。
- 列(Column):每个列由名称、值和时间戳组成。
- 一致性和复制:
- Cassandra通过配置复制因子来决定数据在集群中的复制次数。
- 支持多种一致性级别,如ONE、QUORUM和ALL,以在读取和写入时进行不同的权衡。
- 数据分片和分区:
- 使用一致性哈希算法对数据进行分片和分区,确保数据在集群中的均匀分布。
- 分区键决定数据的分布,影响查询性能和负载均衡。
- 写路径:
- 写入操作首先记录到提交日志(CommitLog),然后写入内存表(Memtable)。
- 当Memtable达到阈值时,数据会被刷新到磁盘形成SSTable。
- 读路径:
- 读取操作首先从内存表和缓存中查找数据,然后在必要时从SSTable中查找。
适用场景
- 需要处理大规模数据集的应用,如社交媒体、物联网和实时分析。
- 要求高可用性和低延迟的分布式系统,如金融交易和电商平台。
- 跨数据中心的地理分布式部署,确保数据的高可用性和容灾能力。
优势和局限
- 优势:
- 高可用性和无单点故障。
- 可线性扩展,支持大规模数据处理。
- 强大的写入性能和灵活的数据模型。
- 局限:
- 对于复杂的查询和事务支持较弱。
- 学习曲线较陡,配置和管理相对复杂。
- 需要精心设计分区键和数据模型以优化性能。
Cassandra作为一款强大的分布式数据库,适用于需要处理海量数据且要求高可用性和高性能的应用场景。其去中心化架构和可扩展性使其成为许多大规模系统的首选。
Cassandra与关系型数据库的区别
Apache Cassandra和传统的关系型数据库(RDBMS,如MySQL、PostgreSQL、Oracle等)在设计理念、数据模型和应用场景上存在显著差异。以下是两者之间的主要区别:
数据模型
- Cassandra:
- 使用基于列族的数据模型,适合宽行存储。
- 数据以键空间(Keyspace)和列族(ColumnFamily)的形式组织,类似于数据库和表。
- 支持动态列,可以为每一行定义不同的列。
- 关系型数据库:
- 使用基于表的关系型数据模型。
- 数据以行和列的结构存储,表与表之间通过外键建立关系。
- 数据模式严格,通常需要预定义表结构(Schema)。
一致性和可用性
- Cassandra:
- 提供可调一致性,支持从强一致性到最终一致性。
- 设计为高可用性和无单点故障的分布式系统。
- 通过数据复制实现高可用性,允许在不同数据中心之间进行数据复制。
- 关系型数据库:
- 通常提供强一致性,通过事务保证ACID(原子性、一致性、隔离性、持久性)特性。
- 高可用性通常通过主从复制、集群或分片来实现。
- 在高可用性和性能之间进行权衡时,往往倾向于强一致性。
扩展性
- Cassandra:
- 线性可扩展,能够通过增加节点来提高性能和容量。
- 使用对等(peer-to-peer)架构,没有中心节点,适合大规模分布式环境。
- 关系型数据库:
- 垂直扩展为主,通过增加硬件资源提升性能。
- 水平扩展相对复杂,通常依赖分片或其他集群技术。
查询语言和操作
- Cassandra:
- 使用Cassandra Query Language (CQL),类似SQL,但不支持复杂查询操作(如JOIN和子查询)。
- 适合简单的CRUD操作和基于主键的快速查询。
- 关系型数据库:
- 使用SQL,支持复杂查询、JOIN、子查询和事务操作。
- 适合需要复杂查询和数据操作的应用场景。
应用场景
- Cassandra:
- 适合需要高可用性、低延迟和大规模写入的应用,如物联网、社交媒体、实时分析和日志管理。
- 适合需要跨数据中心的地理分布式部署。
- 关系型数据库:
- 适合需要复杂事务和强一致性的应用,如金融系统、ERP 和传统业务应用。
- 适合需要严格数据模式和关系的场景。
性能
- Cassandra:
- 优化的写入性能,支持高吞吐量的写入操作。
- 读取性能也较好,但主要依赖于查询模式和数据模型设计。
- 关系型数据库:
- 读取和写入性能都良好,尤其是在事务处理和复杂查询方面表现出色。
- 性能优化通常依赖于索引、查询优化和缓存机制。
总结
- Cassandra 是一个分布式 NoSQL 数据库,设计用于处理大规模数据集,提供高可用性和可扩展性,适合需要快速写入和读取的应用。
- 关系型数据库提供强一致性和复杂事务支持,适合需要复杂数据操作和严格数据模型的传统应用。
Cassandra 与其他 NoSQL 的区别
Cassandra 是一种流行的分布式 NoSQL 数据库,与其他 NoSQL 数据库(如 MongoDB、HBase 和 Couchbase 等)相比,各有其独特的特点和适用场景。下面是 Cassandra 与其他常见分布式 NoSQL 数据库的对比:
Cassandra vs. MongoDB
| 特性 | Cassandra | MongoDB |
| 数据模型 | 基于列族的模型,类似于表结构,支持宽行存储。 | 基于文档的模型,使用 JSON-like BSON 格式。 |
| 一致性模型 | 提供可调一致性,支持从强一致性到最终一致性。 | 默认强一致性,支持分片和副本集以实现高可用性。 |
| 扩展性 | 线性可扩展,支持大规模数据处理。 | 良好的水平扩展能力,通过分片实现。 |
| 高可用性 | 无单点故障,所有节点角色相同。 | 通过副本集提供高可用性,存在主节点。 |
| 写入性能 | 优化的写入路径,支持高吞吐量的写入操作。 | 写入性能良好,适合文档型数据。 |
| 适用场景 | 适合需要高可用性和大规模写入的应用。 | 适合需要灵活数据模型和复杂查询的应用。 |
Cassandra vs. HBase
| 特性 | Cassandra | HBase |
| 数据模型 | 基于列族,适合宽行存储。 | 基于列族,适合宽行存储。 |
| 一致性模型 | 可调一致性,支持最终一致性。 | 强一致性,基于 HDFS 的持久化存储。 |
| 扩展性 | 线性可扩展,适合横向扩展。 | 良好的扩展性,依赖 Hadoop 生态系统。 |
| 高可用性 | 无单点故障,节点角色相同。 | 主从架构,主节点是单点故障。 |
| 集成 | 独立运行,支持多种客户端。 | 与 Hadoop 生态系统紧密集成,适合大数据应用。 |
| 适用场景 | 需要高可用性和地理分布式部署的场景。 | 适合大数据分析和需要与 Hadoop 集成的场景。 |
Cassandra vs. Couchbase
| 特性 | Cassandra | Couchbase |
| 数据模型 | 基于列族,适合宽行存储。 | 基于文档,使用 JSON 格式。 |
| 一致性模型 | 可调一致性,支持最终一致性。 | 默认强一致性,支持多种一致性级别。 |
| 扩展性 | 线性可扩展,支持大规模数据处理。 | 水平扩展,支持自动分片和负载均衡。 |
| 高可用性 | 无单点故障,节点角色相同。 | 支持高可用性,通过副本和自动故障转移实现。 |
| 查询能力 | 支持 CQL 查询,类似 SQL。 | 支持 N1QL 查询,SQL-like 查询语言。 |
| 适用场景 | 适合需要高写入吞吐量和高可用性的场景。 | 适合需要灵活查询和快速响应的应用。 |
总结
- Cassandra:适合需要高可用性、低延迟和大规模数据写入的应用,尤其是在分布式环境中。
- MongoDB:适合需要灵活数据模型和复杂查询的应用,广泛用于 web 应用开发。
- HBase:适合与 Hadoop 生态系统集成的大数据应用,提供强一致性和海量数据存储。
- Couchbase:适合需要快速响应和灵活查询的应用,提供强一致性和高可用性。
参考链接:


