Couchbase简介
Couchbase是一个高性能、分布式NoSQL数据库,专为现代应用程序的需求而设计。它结合了文档存储和键值存储的优点,提供了灵活的数据模型和强大的查询能力。

核心特性
- 分布式架构:Couchbase采用无共享架构,支持水平扩展,可以通过增加节点来提升存储容量和处理能力。这种架构确保了高可用性和数据的自动分片与复制。
- 多模式数据存储:支持文档存储(JSON格式)和键值存储,适合多种应用场景。JSON文档提供了灵活的数据模型,便于开发者存储复杂的嵌套数据结构。
- 强大的查询能力:Couchbase提供了N1QL(Not Only SQL),一种SQL-like查询语言,用于查询JSON文档。N1QL支持复杂查询、聚合、连接等操作,使得开发者可以灵活地处理数据。
- 全局二级索引(GSI):支持创建全局二级索引,以提高查询性能。索引机制经过优化,能够高效处理大规模数据集。
- 内存优先设计:Couchbase采用内存优先架构,确保低延迟的数据访问。数据首先存储在内存中,随后异步写入磁盘,从而实现快速读写操作。
- 跨数据中心复制(XDCR):支持跨数据中心复制,允许在多个地理位置的集群之间复制数据,增强灾难恢复能力和数据可用性。
- 实时分析和事件处理:Couchbase提供了Analytics服务,用于执行复杂的分析查询。此外,Eventing服务允许在数据变化时触发事件处理逻辑。
优势与限制
优势
- 高性能和低延迟:内存优先设计和分布式架构确保了快速的数据访问。
- 灵活的数据模型:支持JSON文档存储,提供了灵活的数据建模能力。
- 强大的查询和分析功能:N1QL和Analytics服务提供了强大的数据处理能力。
- 可扩展性和高可用性:水平扩展和跨数据中心复制确保了系统的可扩展性和高可用性。
限制
- 学习曲线:对于习惯于传统关系型数据库的开发者,可能需要时间来适应NoSQL的概念和Couchbase的特性。
- 复杂性:配置和管理大规模分布式系统可能较为复杂,特别是在跨数据中心部署的场景下。
- 资源消耗:内存优先设计可能需要较高的内存资源,特别是在处理大规模数据集时。
适用场景
- 实时Web应用:适用于需要快速响应和高并发的Web应用,如社交媒体平台、电子商务网站等。
- 移动应用后端:提供同步和离线数据访问能力,适合移动应用的后端服务。
- 物联网(IoT):适用于处理大量设备数据的物联网应用,支持快速数据摄取和实时分析。
- 个性化推荐系统:利用N1QL和索引机制,支持复杂的查询和分析,适合构建个性化推荐系统。
Couchbase的架构
Couchbase是一个高性能、可扩展的分布式NoSQL数据库,专为现代应用程序设计。它的架构设计旨在提供低延迟、高吞吐量和高可用性,特别适用于需要处理大量数据和高并发请求的应用场景。
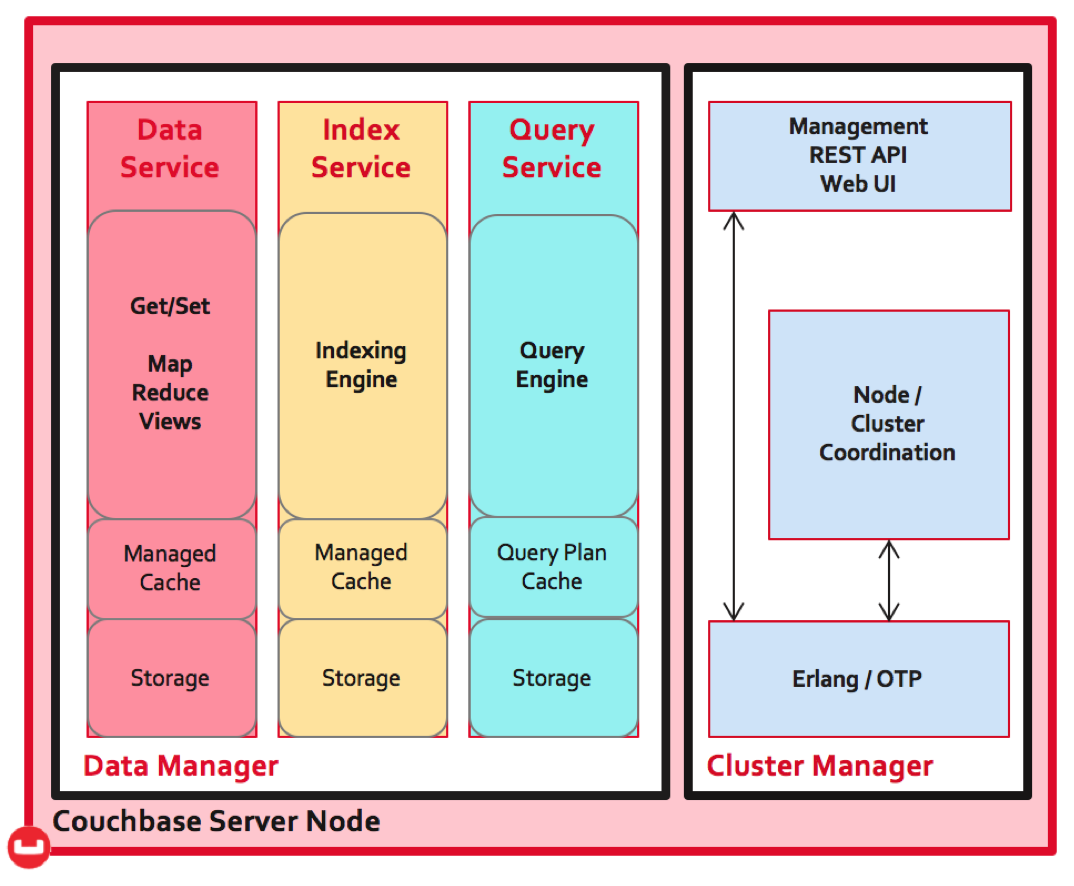
以下是Couchbase的主要架构组件和设计原则:
分布式架构
- 节点(Nodes):Couchbase集群由多个节点组成,每个节点运行相同的软件栈,共同协作处理数据和请求。
- 分片(Vbuckets):数据被分割成多个分片(称为vBuckets),每个分片可以独立存储在不同的节点上。这种分片机制使得数据可以均匀分布,提高读写性能和可扩展性。
核心组件
- 数据服务(Data Service)
- 功能:负责数据的存储和检索。每个节点都包含一个数据服务实例,处理CRUD操作(创建、读取、更新、删除)。
- 特点:支持内存缓存和持久化存储,确保数据的高性能和持久性。
- 查询服务(Query Service)
- 功能:提供SQL-like查询语言N1QL(Non-first Normal Form SQL),支持复杂的查询操作。
- 特点:通过分布式查询引擎,可以高效地处理大规模数据集的查询请求。
- 索引服务(Index Service)
- 功能:负责创建和管理索引,加速查询性能。
- 特点:支持多种索引类型,包括主键索引、二级索引和全文索引。
- 搜索服务(Search Service)
- 功能:提供全文搜索功能,支持复杂的搜索查询和相关性排序。
- 特点:基于Apache Lucene,支持丰富的搜索功能和高效的全文索引。
- 事件服务(Eventing Service)
- 功能:提供事件驱动的编程模型,支持数据变更触发的自动化处理。
- 特点:可以用于数据同步、数据转换和业务逻辑处理。
- 分析服务(Analytics Service)
- 功能:提供大规模数据的实时分析能力,支持复杂的分析查询。
- 特点:与数据服务分离,确保分析操作不会影响在线事务处理的性能。
数据管理
- 内存缓存:Couchbase使用内存缓存来提高数据访问速度,支持数据的快速读取和写入。
- 持久化存储:数据可以配置为异步或同步持久化到磁盘,确保数据的持久性和可靠性。
- 复制:支持数据的跨节点复制,确保高可用性和数据冗余。每个分片可以有多个副本,分布在不同的节点上。
高可用性和故障恢复
- 自动故障检测和恢复:Couchbase能够自动检测节点故障,并将故障节点的数据重新分配到其他健康节点上,确保系统的高可用性。
- 多数据中心支持:支持跨多个数据中心的部署,提供地理分布的高可用性和灾难恢复能力。
扩展性
- 水平扩展:通过添加新的节点,Couchbase 可以轻松扩展存储和计算能力,适应数据和负载的增长。
- 动态再平衡:在节点加入或离开集群时,Couchbase 会自动进行数据再平衡,确保数据的均匀分布和负载均衡。
安全性
- 认证和授权:支持多种认证机制,如 LDAP、SAML 和本地用户管理,确保数据访问的安全性。
- 数据加密:支持数据传输和存储的加密,保护数据的机密性和完整性。
- 审计日志:记录详细的审计日志,帮助用户监控和审计数据访问和操作。
管理工具
- 管理控制台:提供图形用户界面(GUI),用于集群管理、监控和配置。
- 命令行工具:提供丰富的命令行工具,支持脚本化管理和自动化操作。
Couchbase 的架构设计旨在提供一个高性能、可扩展、高可用的分布式 NoSQL 数据库系统。通过分片、内存缓存、多服务组件和自动故障恢复机制,Couchbase 能够有效处理大规模数据和高并发请求,适用于现代应用程序的各种场景。其灵活的扩展性和强大的管理工具进一步增强了系统的易用性和可靠性。
Couchbase 与 MongoDB 对比
Couchbase 和MongoDB 是两种流行的 NoSQL 数据库解决方案,各自具有独特的特性和优势。以下是对这两种数据库的详细对比:
| 特性 | Couchbase | MongoDB |
| 数据模型 | JSON 文档存储和键值存储 | BSON(二进制 JSON)文档存储 |
| 查询语言 | N1QL(SQL-like 查询语言) | MongoDB 查询语言(MQL) |
| 索引机制 | 全局二级索引(GSI)和视图索引 | 多种索引类型(单字段、多字段、地理空间、全文搜索) |
| 架构 | 无共享架构,水平扩展,自动分片 | 分片和复制集架构,水平扩展 |
| 内存管理 | 内存优先设计,数据首先存储在内存中 | 内存映射文件,尽可能将数据保留在内存中 |
| 复制和高可用性 | 多副本机制,支持跨数据中心复制(XDCR) | 复制集提供数据冗余,支持分片 |
| 实时分析与事件处理 | 提供实时分析(Analytics)和事件处理(Eventing)服务 | 提供聚合框架和数据处理管道 |
| 全文搜索 | 支持全文搜索和地理空间查询 | 支持全文搜索和地理空间索引 |
| 适用场景 | 实时 Web 应用、移动应用后端、物联网、推荐系统 | 内容管理系统、电子商务、物联网、社交网络 |
| 社区与支持 | 活跃的开源社区和商业支持 | 庞大的开源社区和广泛的企业支持 |
| 性能特点 | 低延迟、高性能数据访问 | 灵活数据模型,复杂查询能力 |
Couchbase 和 MongoDB 都是强大的 NoSQL 数据库,各自有着独特的优势和适用场景。Couchbase 以其内存优先设计和实时处理能力见长,适合高性能、低延迟的应用。MongoDB 则以其灵活的数据模型和强大的查询能力广受欢迎,适合多种应用场景。选择哪种数据库取决于具体的应用需求、数据特性和性能要求。
查询语言 N1QL
N1QL(Not Only SQL)是 Couchbase 数据库提供的 SQL-like 查询语言,用于在 NoSQL 数据库中执行复杂的查询操作。N1QL 的设计目的是为了在 JSON 文档存储中提供类似于 SQL 的查询能力,使得开发者可以使用熟悉的 SQL 语法来查询和操作非结构化数据。

核心特性
- SQL-like 语法:N1QL 使用类似于 SQL 的语法,使得熟悉 SQL 的开发者可以快速上手。它支持常见的 SQL 操作,如 SELECT、FROM、WHERE、JOIN、GROUP BY、ORDER BY 等。
- JSON 文档支持:N1QL 专门设计用于查询和操作 JSON 文档。它可以处理嵌套的 JSON 结构,支持数组和对象类型的查询。
- 灵活的查询能力:N1QL 支持复杂的查询操作,包括子查询、聚合函数、全文搜索、地理位置查询等。
- 高性能:N1QL 查询引擎经过优化,可以高效地处理大规模数据集,支持索引和分区以提高查询性能。
- 分布式查询:N1QL 可以在 Couchbase 的分布式集群中执行,支持水平扩展和高可用性。
优势与限制
优势
- 熟悉性:使用 SQL-like 语法,降低了学习成本,使得开发者可以快速上手。
- 灵活性:支持复杂的查询操作,适用于多种数据模型和应用场景。
- 高性能:优化的查询引擎和索引机制,确保高效的数据处理。
- 可扩展性:支持分布式部署,可以水平扩展以处理大规模数据集。
限制
- 学习曲线:虽然语法类似于 SQL,但处理 JSON 文档的特性和方法可能需要一些时间来掌握。
- 性能依赖:查询性能受索引和数据分布的影响较大,需要合理设计索引和数据模型。
- 生态系统:相对于成熟的 SQL 数据库,N1QL 的工具和社区支持可能相对有限。
适用场景
- JSON 文档存储:适用于需要存储和查询复杂 JSON 文档的应用,如内容管理系统、日志分析、物联网数据存储等。
- 实时数据分析:用于实时分析和处理大量数据,如实时监控、事件流处理等。
- 混合事务和分析处理(HTAP):N1QL 支持在同一个数据库中同时处理事务和分析查询,适用于需要高性能和高并发的应用。
- 大数据应用:适用于处理大规模数据集,支持分布式查询和水平扩展。
语法示例
以下是一些 N1QL 查询示例,展示了其基本用法:
基本查询
SELECT name, age FROM users WHERE age>30;
这个查询从users集合中选择name和age字段,条件是age大于30。
嵌套查询
SELECT user.name, hobbies.hobby FROM users AS user UNNEST user.hobbies AS hobbies WHERE hobbies.type='indoor';
这个查询从users集合中选择用户的姓名和室内爱好。UNNEST关键字用于展开嵌套的数组。
聚合查询
SELECT department, COUNT(*) AS num_employees FROM employees GROUP BY department;
这个查询按部门分组统计员工数量。
JOIN查询
SELECT o.order_id, c.customer_name FROM orders AS o JOIN customers AS c ON KEYS o.customer_id WHERE o.status='shipped';
这个查询从orders集合中选择订单ID,并从customers集合中选择客户名称,条件是订单状态为”已发货”。
N1QL通过提供SQL-like的查询语言,使得开发者可以在NoSQL数据库中高效地查询和操作JSON文档。它结合了SQL的易用性和NoSQL的灵活性,适用于多种数据存储和分析场景。随着Couchbase和其他NoSQL数据库的普及,N1QL在现代数据处理中的应用将越来越广泛。
参考链接:


