在日常的工作中,使用较多的是 Presto,原因是它比 Spark 快非常多。当然,使用过程中也会遇到一些问题,其中主要的是一些内置函数与SparkSQL 存在较大的差异。这里对 Presto SQL 一个简单的整理。关于 Presto 的相关内容可以查看先前的文章:开源分布式查询引擎 Presto
Presto 数据类型
以下是对 Presto 支持的一些数据类型的详细介绍:
- Boolean
- BOOLEAN:表示真或假的逻辑数据类型。
- Integer
- TINYINT:表示 8 位有符号整数,范围从 -128 到 127。
- SMALLINT:表示 16 位有符号整数,范围从 -32,768 到 32,767。
- INTEGER:表示 32 位有符号整数,范围从 -2,147,483,648 到 2,147,483,647。
- BIGINT:表示 64 位有符号整数,范围从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807。
- Floating-Point
- REAL:表示 IEEE 754 单精度浮点数。
- DOUBLE:表示 IEEE 754 双精度浮点数。
- Fixed-Precision
- DECIMAL:表示精确的定点数。
- String
- VARCHAR:表示可变长度的字符串。
- CHAR:表示固定长度的字符串。
- VARBINARY:表示二进制字符串。
- JSON:表示 JSON 文档。
- Date and Time
- DATE:表示日期。
- TIME:表示时间。
- TIME WITH TIME ZONE:表示带有时区的时间。
- TIMESTAMP:表示日期和时间。
- TIMESTAMP WITH TIME ZONE:表示带有时区的日期和时间。
- INTERVAL YEAR TO MONTH:表示从年到月的时间间隔。
- INTERVAL DAY TO SECOND:表示从天到秒的时间间隔。
- Structural
- ARRAY:表示值的有序列表。
- MAP:表示键值对的集合。
- ROW:表示一组命名的字段。
- Network Address
- IPADDRESS:表示 IPv4 或 IPv6 地址。
- IPPREFIX:表示 IPv4 或 IPv6 网络。
- UUID
- UUID:表示通用唯一标识符。
- HyperLogLog
- HyperLogLog:用于近似计数唯一值的算法。
- P4HyperLogLog:是 HyperLogLog 的一种变体。
- KHyperLogLog:是 HyperLogLog 的一种变体。
- Set Digest
- SetDigest:用于近似集合运算的数据类型。
- Quantile Digest
- QDigest:用于计算数据流的百分位数或其他任意分位数的数据类型。
- T-Digest
- TDigest:用于计算大型数据流的近似百分位数的数据类型。
- KLL Sketch
- KLLSketch:用于计算数据流的近似分位数的数据类型。
Presto SQL 语法简介
Presto 是一个分布式 SQL 查询引擎,设计用于查询大规模数据集。它主要用于执行读取操作,如 SELECT 查询,而不是更新操作,如 INSERT,UPDATE 或 DELETE。支持哪些特定操作可能取决于您的 Presto 版本以及正在使用的连接器。例如,某些连接器可能会支持额外的操作,而其他连接器则可能不支持。总的来说,确保了解您正在使用的具体 Presto 环境的功能是很重要的。
Presto SQL DDL(数据定义语言)
用于定义或更改表的结构、索引、触发器等数据库对象。
在 Presto SQL 中,Catalog、Schema 和 Table 是三个主要的命名空间,每个都表示不同的数据组织层次。
- Catalog:在 Presto 中,catalog 对应到数据源。例如,一个 catalog 可能连接到一个 MySQL 数据库,另一个 catalog 可能连接到 Hadoop。一个 Presto 实例可以有多个 catalog,每个 catalog 对应到一个不同的数据源。
- Schema:在 Presto 中,schema 相当于其他数据库系统中的 database。schema 是 catalog 内部的命名空间,它包含一组 tables。一个 catalog 可以有多个 schema。
- Table:table 是数据的基本存储单元。一个 table 属于一个特定的 schema,包含一系列的列和行。
因此,database 在传统的数据库系统中代表一个独立的数据存储单位,可能包含多个 tables、views 等,而在 Presto 中,这个概念对应的是 schema。
在使用 Presto 进行查询时,通常需要指定完整的 catalog.schema.table 格式来引用一个表。例如:
SELECT * FROM catalog.schema.table;
在这个例子中,catalog 是你的数据源,schema 是你的数据库,table 是你的数据表。
SCHEMA:
- CREATE SCHEMA: 这个语句用于创建一个新的 schema。例如:CREATE SCHEMA schema_name;
- ALTER SCHEMA: 用于更重命名 schema。例如:ALTER SCHEMA schema_name RENAME TO new_schema_name
- DROP SCHEMA: 这个语句用于删除一个已存在的 schema。例如:DROP SCHEMA schema_name;
TABLE:
- CREATE TABLE: 这个语句用于创建一个新的表。例如:CREATE TABLE table_name (column1 type1, column2 type2, …);
- CREATE TABLE AS: 这个语句用于根据一个 SELECT 查询的结果创建一个新的表。例如:CREATE TABLE table_name AS SELECT column1, column2 FROM another_table;
- ALTER TABLE: 这个语句用于修改已存在的表,如添加、删除或重命名列,或者更改表的名称。例如:ALTER TABLE table_name RENAME TO new_table_name;
- DROP TABLE: 这个语句用于删除一个已存在的表。例如:DROP TABLE table_name;
VIEW:
- CREATE VIEW: 这个语句用于创建一个新的视图。视图是一个数据库对象,是一个存储的 SQL 查询,可以像表一样被查询。例如:CREATE VIEW view_name AS SELECT column1, column2 FROM table_name;
DROP VIEW: 这个语句用于删除一个已存在的视图。例如:DROP VIEW view_name;
Presto SQL DML(数据操作语言)
以下是SQL中的一些基本数据操作语句的介绍:
DELETE
DELETE语句用于删除表中的记录。你可以通过WHERE子句来指定要删除的记录。例如:
DELETE FROM table_name WHERE condition;
如果不使用WHERE子句,DELETE语句将删除表中的所有记录。
INSERT
INSERT语句用于向表中插入新的记录。你可以指定要插入的列和值,或者通过一个SELECT语句来插入数据。例如:
INSERT INTO table_name (column1, column2) VALUES (value1, value2); INSERT INTO table_name (column1, column2) SELECT column1, column2 FROM another_table;
SELECT
SELECT语句用于从一个或多个表中查询数据。你可以通过WHERE子句来过滤结果,通过GROUP BY子句来分组结果,通过ORDER BY子句来排序结果。例如:
SELECT column1, column2 FROM table_name WHERE condition GROUP BY column1 ORDER BY column2;
TRUNCATE
TRUNCATE语句用于删除表中的所有记录。不同于DELETE语句,TRUNCATE语句不会记录每个删除的记录的信息,因此通常比DELETE语句更快。例如:
TRUNCATE TABLE table_name;
UPDATE
UPDATE语句用于更新表中的记录。你可以通过SET子句来指定要更新的列和新的值,通过WHERE子句来指定要更新的记录。例如:
UPDATE table_name SET column1=value1, column2=value2 WHERE condition;
Presto SQL DCL(数据控制语言)
用于控制不同数据的访问级别的语言,包括授权和撤销。
这些命令主要关于SQL的角色管理和权限控制:
- GRANT: GRANT语句用于给用户授予特定的权限。例如,你可以授予一个用户对特定表的选择权限:GRANT SELECT ON table_name TO user_name;
- REVOKE: REVOKE语句用于撤销用户的特定权限。例如,你可以撤销一个用户对特定表的选择权限:REVOKE SELECT ON table_name FROM user_name;
- SET ROLE: SET ROLE语句用于设置当前会话的角色。例如:SET ROLE role_name;
- CREATE ROLE: CREATE ROLE语句用于创建新的角色。例如:CREATE ROLE role_name;
- DROP ROLE: DROP ROLE语句用于删除已存在的角色。例如:DROP ROLE role_name;
- GRANT ROLES: GRANT ROLES语句用于将一组角色授予一个用户。例如:GRANT role1, role2 TO user_name;
- REVOKE ROLES: REVOKE ROLES语句用于从一个用户撤销一组角色。例如:REVOKE role1, role2 FROM user_name;
Presto SQL TCL(事务控制语言)
在Presto SQL中,以下是你询问的命令的介绍:
- START TRANSACTION: 该命令用于开始一个新的数据库事务。事务是一个由一个或多个SQL语句组成的序列,这个序列被作为一个整体来执行,即要么全部执行成功,要么全部不执行(如果事务中的某个操作失败,之前在该事务中的所有操作都会被回滚)。在Presto中,你不能使用START TRANSACTION命令,因为Presto不支持事务。
- COMMIT: 该命令用于提交一个数据库事务,保存所有自事务开始以来对数据库所做的更改。在Presto中,你不能使用COMMIT命令,因为Presto不支持事务。
- ROLLBACK: 该命令用于回滚一个数据库事务,取消所有自事务开始以来对数据库所做的更改。在Presto中,你不能使用ROLLBACK命令,因为Presto不支持事务。
Presto SQL 函数与过程
ALTER FUNCTION
用于修改函数的属性,重新定义函数的行为。
以下是一些例子:
ALTER FUNCTION function_name CALL handler_name
CREATE FUNCTION
该命令用于创建新的用户自定义函数。在Presto中,你可以创建标量函数和聚合函数。例如,下面是创建一个标量函数的例子:
CREATE FUNCTION plus(x integer, y integer) RETURNS integer LANGUAGE SQL AS 'SELECT $1 + $2';
DROP FUNCTION
该命令用于删除已存在的用户自定义函数。例如:
DROP FUNCTION IF EXISTS plus(integer, integer);
CALL
CALL命令用于调用一个存储过程。在Presto中,存储过程通常用于执行不能用标准SQL语句表示的操作,如数据清理、数据迁移等。
Presto 会话和系统控制
SET SESSION
SET SESSION命令在当前会话中设置一个或多个配置参数的值。例如:
SET SESSION query_max_run_time='30m';
上述命令将query_max_run_time配置参数的值设置为30分钟。
RESET SESSION
RESET SESSION命令用于重置当前会话中所有配置参数的值为默认值。例如:
RESET SESSION;
USE
USE命令用于设置当前会话的默认catalog和schema。例如:
USE catalog.schema;
DEALLOCATE PREPARE
DEALLOCATE PREPARE命令用于取消预编译的SQL语句。
PREPARE
PREPARE命令用于预编译一个SQL语句,以后可以通过一个标识符来快速执行这个预编译的SQL语句。
Presto 查询与分析
- ANALYZE: ANALYZE命令用于计算表的统计信息,以便优化查询。例如:ANALYZE table_name;
- EXECUTE: EXECUTE命令在Presto中用于执行一个已经准备好的语句。在Presto中,你可以使用PREPARE语句来创建一个已准备好的语句,然后通过EXECUTE命令来执行它。
- DESCRIBE INPUT: 用于获取存储过程的输入参数的信息。对于已注册的存储过程,你可以使用下列语句来获取输入参数的信息:DESCRIBE INPUT procedure_name
- DESCRIBE OUTPUT: 提供了对指定查询产生的输出列的描述。
- EXPLAIN: EXPLAIN 命令用于显示一个 SQL 语句的执行计划,这可以帮助理解和优化 SQL 语句。例如:EXPLAIN SELECT * FROM table_name;
- EXPLAIN ANALYZE: EXPLAIN ANALYZE 命令用于显示一个 SQL 语句的执行计划以及实际的执行统计信息。例如:EXPLAIN ANALYZE SELECT * FROM table_name;
- SHOW CATALOGS: SHOW CATALOGS 命令用于列出可用的 catalogs。例如:SHOW CATALOGS;
- SHOW COLUMNS: SHOW COLUMNS 命令用于列出表的列信息。例如:SHOW COLUMNS FROM table_name;
- SHOW CREATE FUNCTION: 在 Presto 中查看函数的定义,常常使用 SHOW FUNCTIONS 命令。这个命令可以显示当前环境中所有可用函数的列表。对于函数的具体实现,用户需要查看函数在源代码中的定义。
- SHOW CREATE TABLE: SHOW CREATE TABLE 命令用于显示创建表的 SQL 语句。例如:SHOW CREATE TABLE table_name;
- SHOW CREATE VIEW: SHOW CREATE VIEW 命令用于显示创建视图的 SQL 语句。例如:SHOW CREATE VIEW view_name;
- SHOW FUNCTIONS: SHOW FUNCTIONS 命令用于列出可用的函数。例如:SHOW FUNCTIONS;
- SHOW GRANTS: 这个命令用于列出特定用户在特定模式下的权限。
- SHOW ROLE GRANTS: 此命令用于列出当前用户的角色授权。
- SHOW ROLES: 这个命令用于列出当前或指定目录中的所有角色。
- SHOW SCHEMAS: SHOW SCHEMAS 命令用于列出 catalog 中的 schemas。例如:SHOW SCHEMAS FROM catalog_name;
- SHOW SESSION: SHOW SESSION 命令用于列出当前会话的配置参数。例如:SHOW SESSION;
- SHOW STATS: SHOW STATS 命令用于显示表的统计信息。例如:SHOW STATS FOR table_name;
- SHOW TABLES: SHOW TABLES 命令用于列出 schema 中的表。例如:SHOW TABLES FROM schema_name;
- VALUES: VALUES 命令用于构造一个行的集合,每个元素都是一个常量表达式。例如:VALUES (expression1, expression2), (expression3, expression4);
DESCRIBE: DESCRIBE 命令用于显示表的结构,包括列名、数据类型、是否为空等信息。例如:DESCRIBE table_name;
Presto SQL 函数说明
Presto 的内置函数和其他 SQL 有较大的差异,使用起来要特别注意,以下整理的函数可能与你当前使用 Presto 的版本不一致。
Logical Operators
包括 AND, OR, NOT,用于组合或反转条件。
Comparison Functions and Operators
包括 =, !=, <, >, <=, >=, 等,用于比较两个值。
Conditional Expressions
包括 CASE,IF,NULLIF,COALESCE 等,用于基于条件逻辑进行操作。
Lambda Expressions
允许你编写一个小的函数可以在表达式中使用。
在 Presto 中,Lambda 表达式是用于创建匿名函数的一种手段。Lambda 表达式可在函数参数中使用,常常配合如 filter(), transform() 或 reduce() 等函数一起使用。Lambda 表达式的形式如下:
(x, y, ..., z -> expression)
在这个表达式中,x, y, …, z 是参数列表,箭头 -> 用于分隔参数列表和表达式,expression 是对参数进行操作的表达式。
举几个例子:
将数组中所有元素乘以 2:
SELECT transform(array[1, 2, 3], x -> x * 2); -- 输出:[2, 4, 6]
使用 filter 函数过滤数组中的元素:
SELECT filter(array[1, 2, 3, 4], x -> x % 2 = 0); -- 输出:[2, 4]
使用 reduce 函数计算数组的和:
SELECT reduce(array[1, 2, 3], 0, (s, x) -> s + x, s -> s); -- 输出:6
在这个 reduce 例子中,我们使用了两个 Lambda 表达式:第一个 (s, x) -> s + x 用于求和,第二个 s -> s 返回最终结果。初始值为 0。
需要注意的是,Presto 的 Lambda 表达式不能在其他表达式之间共享。也就是不能抽取出来作为公共部分重新使用。每个 Lambda 表达式都必须是自包含的。
另外,Lambda 表达式中的变量名不能与查询中的其他列名或别名重复。如果重复,Presto 将会抛出异常。
以上就是关于 Presto 中 Lambda 表达式的简单介绍,希望对你有所帮助。
Conversion Functions
提供 CAST,TRY_CAST 等,用于数据类型之间的转换。
在 Presto 中,CAST 和 TRY_CAST 都是用来进行数据类型转换的功能,但它们之间的行为在转换失败时有所不同。
CAST:它是标准的 SQL 功能,用于将一个值从一种数据类型转换为另一种数据类型。例如,将字符串转换为整数,或将浮点数转换为布尔值。如果转换不成功,那么 CAST 会抛出一个异常。
例如:
SELECT CAST('123' AS INTEGER); -- 成功,输出:123
SELECT CAST('abc' AS INTEGER); -- 失败,抛出异常
TRY_CAST:这是 Presto 特有的功能。它的行为与 CAST 类似,但是在转换失败时不会抛出异常,而是返回 NULL。
例如:
SELECT TRY_CAST('123' AS INTEGER); -- 成功,输出:123
SELECT TRY_CAST('abc' AS INTEGER); -- 失败,输出:NULL
所以,你如果想在转换失败时避免异常,并且能够容忍 NULL 值,你应该使用 TRY_CAST。如果你希望在转换失败时能够得到异常,那么你应该使用 CAST。
Mathematical Functions and Operators
包括加法,减法,乘法,除法和模,以及函数如 ROUND,CEILING,FLOOR 等。
数学函数
- abs(x):返回 x 的绝对值。
- cbrt(x):返回 x 的立方根。
- ceil(x) 或 ceiling(x):向上取整,返回大于或等于 x 的最小整数。
- cosine_similarity(a, b):返回两个向量 a 和 b 之间的余弦相似性。
- degrees(x):将弧度转换为度。
- e():返回欧拉数,即 71828。
- exp(x):返回 e 的 x 次方。
- floor(x):向下取整,返回小于或等于 x 的最大整数。
- from_base(x, y):将字符串 x 从基数 y 转换为基数 10。
- ln(x):返回 x 的自然对数。
- log2(x):返回以 2 为底的 x 的对数。
- log10(x):返回以 10 为底的 x 的对数。
- pi():返回圆周率 π,即 14159。
- pow(x, y) 或 power(x, y):返回 x 的 y 次方。
- radians(x):将度转换为弧度。
- rand() 或 random():返回一个介于 0(包含)和 1(不包含)之间的伪随机双精度值。
- secure_rand() 或 secure_random():返回一个介于 0(包含)和 1(不包含)之间的加密安全伪随机双精度值。此值适合用于密码学。
- round(x):四舍五入 x 到最接近的整数。
- sign(x):如果 x 为负,则返回 -1;如果 x 为零,则返回 0;如果 x 为正,则返回 1。
- sqrt(x):返回 x 的平方根。
- to_base(x, y):将基数 10 的数字 x 转换为基数 y 的字符串。
- truncate(x, y):将 x 截断到小数点后 y 位。
- width_bucket(x, y, z, p):返回一个桶编号,该编号表示 x 在由 y 到 z 的区间内均匀划分的 p 个桶中的位置。
mod(x, y):返回 x 除以 y 的余数。
概率函数计算特定分布下的累积分布函数(CDF)
- beta_cdf(alpha, beta, v):计算 Beta 分布的累积分布函数(CDF)。参数 alpha 和 beta 是 Beta 分布的形状参数,v 是要计算 CDF 的值。
- binomial_cdf(trials, p, successes):计算二项分布的 CDF。参数 trials 是试验次数,p 是每次试验成功的概率,successes 是成功次数。
- cauchy_cdf(location, scale, v):计算柯西分布的 CDF。参数 location 和 scale 分别表示柯西分布的位置参数和尺度参数,v 是要计算 CDF 的值。
- chi_squared_cdf(df, v):计算卡方分布的 CDF。参数 df 表示自由度,v 是要计算 CDF 的值。
- f_cdf(df1, df2, v):计算 F 分布的 CDF。参数 df1 和 df2 表示两个自由度,v 是要计算 CDF 的值。
- gamma_cdf(shape, scale, v):计算伽玛分布的 CDF。参数 shape 和 scale 分别表示伽玛分布的形状参数和尺度参数,v 是要计算 CDF 的值。
- laplace_cdf(location, scale, v):计算拉普拉斯分布的 CDF。参数 location 和 scale 分别表示拉普拉斯分布的位置参数和尺度参数,v 是要计算 CDF 的值。
- normal_cdf(mean, sd, v):计算正态分布的 CDF。参数 mean 和 sd 分别表示正态分布的均值和标准差,v 是要计算 CDF 的值。
- poisson_cdf(lambda, v):计算泊松分布的 CDF。参数 lambda 表示泊松分布的率参数,v 是要计算 CDF 的值。
- weibull_cdf(alpha, beta, v):计算韦氏分布的 CDF。参数 alpha 和 beta 分别表示韦氏分布的形状参数和尺度参数,v 是要计算 CDF 的值。
概率函数,计算特定分布下的累积分布函数的逆函数(Inverse CDF),也叫做分位数函数。
- inverse_beta_cdf(alpha, beta, p):计算 Beta 分布的逆 CDF。参数 alpha 和 beta 是 Beta 分布的形状参数,p 是累积概率。
- inverse_binomial_cdf(trials, p, p):计算二项分布的逆 CDF。参数 trials 是试验次数,p 是每次试验成功的概率,p 是累积概率。
- inverse_cauchy_cdf(location, scale, p):计算柯西分布的逆 CDF。参数 location 和 scale 分别表示柯西分布的位置参数和尺度参数,p 是累积概率。
- inverse_chi_squared_cdf(df, p):计算卡方分布的逆 CDF。参数 df 表示自由度,p 是累积概率。
- inverse_gamma_cdf(shape, scale, p):计算伽玛分布的逆 CDF。参数 shape 和 scale 分别表示伽玛分布的形状参数和尺度参数,p 是累积概率。
- inverse_f_cdf(df1, df2, p):计算 F 分布的逆 CDF。参数 df1 和 df2 表示两个自由度,p 是累积概率。
- inverse_laplace_cdf(location, scale, p):计算拉普拉斯分布的逆 CDF。参数 location 和 scale 分别表示拉普拉斯分布的位置参数和尺度参数,p 是累积概率。
- inverse_normal_cdf(mean, sd, p):计算正态分布的逆 CDF。参数 mean 和 sd 分别表示正态分布的均值和标准差,p 是累积概率。
- inverse_poisson_cdf(lambda, p):计算泊松分布的逆 CDF。参数 lambda 表示泊松分布的率参数,p 是累积概率。
- inverse_weibull_cdf(alpha, beta, p):计算韦氏分布的逆 CDF。参数 alpha 和 beta 分别表示韦氏分布的形状参数和尺度参数,p 是累积概率。
统计函数
Wilson 置信区间是用于估计具有二项分布的总体参数的置信区间,通常用于样本比例的置信区间计算。
- wilson_interval_lower(pos, neg, z):计算 Wilson 置信区间的下限。参数 pos 是成功的次数,neg 是失败的次数,z 是正态分布的分位数(例如,对于 95% 的置信区间,z 值通常取 96)。
- wilson_interval_upper(pos, neg, z):计算 Wilson 置信区间的上限。参数与 wilson_interval_lower 相同。
三角函数
- acos(x):返回 x 的反余弦值,结果的单位是弧度,x 的范围在 -1 到 1 之间。
- asin(x):返回 x 的反正弦值,结果的单位是弧度,x 的范围在 -1 到 1 之间。
- atan(x):返回 x 的反正切值,结果的单位是弧度,x 的范围为所有实数。
- atan2(y, x):返回点 (x, y) 与 x 轴的夹角,单位为弧度,y 和 x 的范围为所有实数。
- cos(x):返回 x 的余弦值,x 的单位是弧度。
- cosh(x):返回 x 的双曲余弦值,x 的范围为所有实数。
- sin(x):返回 x 的正弦值,x 的单位是弧度。
- tan(x):返回 x 的正切值,x 的单位是弧度。
- tanh(x):返回 x 的双曲正切值,x 的范围为所有实数。
浮点数函数
- infinity():返回正无穷大。
- is_finite(x):如果 x 是有限的(即,它既不是无穷大也不是 NaN),则返回 true,否则返回 false。
- is_infinite(x):如果 x 是无穷大(无论正还是负),则返回 true,否则返回 false。
- is_nan(x):如果 x 是 NaN,返回 true,否则返回 false。
- nan():返回非数字(NaN)值。
Bitwise Functions
位运算函数
- bit_count(x, bits):返回二进制表示中位值为 1 的次数。参数 x 是要进行位计数的值,bits 是要考虑的最大位数。
- bitwise_and(x, y):返回 x 和 y 的按位与(AND)结果。
- bitwise_not(x):返回 x 的按位非(NOT)结果。
- bitwise_or(x, y):返回 x 和 y 的按位或(OR)结果。
- bitwise_xor(x, y):返回 x 和 y 的按位异或(XOR)结果。
- bitwise_shift_left(x, shift):返回 x 向左移动 shift 位的结果。如果 shift 为负,则会移动相反的方向。
- bitwise_logical_shift_right(x, shift):返回 x 向右逻辑移动 shift 位的结果。如果 shift 为负,则会移动相反的方向。
- bitwise_arithmetic_shift_right(x, shift):返回 x 向右算术移动 shift 位的结果。如果 shift 为负,则会移动相反的方向。与逻辑右移不同,算术右移会保留符号位。
位移函数
- bitwise_left_shift(x, shift):返回 x 向左移动 shift 位的结果。x 是要进行移位的值,shift 是移位的位数。如果 shift 为负,则会移动相反的方向。
- bitwise_right_shift(x, shift):返回 x 向右逻辑移动 shift 位的结果。逻辑右移会在左侧插入零。x 是要进行移位的值,shift 是移位的位数。如果 shift 为负,则会移动相反的方向。
- bitwise_right_shift_ari(x, shift):返回 x 向右算术移动 shift 位的结果。算术右移会保留符号位。x 是要进行移位的值,shift 是移位的位数。如果 shift 为负,则会移动相反的方向。
Decimal Functions and Operators
处理十进制数的函数和操作,例如 DECIMAL 构造函数。DECIMAL 构造函数:用于创建一个十进制数。例如,DECIMAL ‘3.14’ 会创建一个值为 3.14 的十进制数。
String Functions and Operators
字符串操作
|| 操作符是一种字符串连接操作符,它将两个或多个字符串组合成一个单一的字符串。例如,假设我们有两个字符串 “Hello” 和 “World”,我们可以使用 “||” 操作符将它们连接起来,如下所示:SELECT ‘Hello’ || ” || ‘World’;
字符串函数:
- chr(integer):返回由所给整数表示的 Unicode 字符。
- codepoint(string):返回字符串中第一个字符的 Unicode 代码点。
- concat(string1, string2, …): 连接两个或更多字符串。
- ends_with(string, substring):如果字符串以子串结束,则返回 true。
- hamming_distance(string1, string2):返回两个字符串之间的汉明距离。
- length(string):返回字符串的长度。
- levenshtein_distance(string1, string2):返回两个字符串之间的莱文斯坦距离。
- lower(string):返回全部转换为小写的字符串。
- lpad(string, size, fill):返回通过在左侧添加填充字符串 fill,使字符串达到指定长度的新字符串。
- ltrim(string):返回删除了左侧空格的字符串。
- replace(string, search):返回一个由替换了所有出现的搜索字符串的字符串。
- replace_first(string, pattern, replacement):返回一个由替换了第一个匹配模式的字符串。
- reverse(string):返回反转后的字符串。
- rpad(string, size, fill):返回通过在右侧添加填充字符串 fill,使字符串达到指定长度的新字符串。
- rtrim(string):返回删除了右侧空格的字符串。
- split(string, delimiter):返回由分隔符分隔的字符串数组。
- split_part(string, delimiter, field):返回由分隔符分隔的字符串的字段。
- split_to_map(string, entryDelimiter, keyValueDelimiter):返回由条目分隔符和键值分隔符分隔的字符串的映射。
- split_to_multimap(string, entryDelimiter, keyValueDelimiter):返回由条目分隔符和键值分隔符分隔的字符串的多重映射。
- strpos(string, substring):返回子串在字符串中第一次出现的位置。
- starts_with(string, substring):如果字符串以子串开始,则返回 true。
- strrpos(string, substring):返回子串在字符串中最后一次出现的位置。
- position(substring in string):返回子串在字符串中第一次出现的位置。
- substr(string, start, length):返回字符串的子串。
- trim(string):返回删除了前导和尾随空格的字符串。
- upper(string):返回全部转换为大写的字符串。
- word_stem(string, language):返回字符串的词干。
Unicode 函数
- normalize(string[, form]):返回在给定的 Unicode 正规化形式下正规化的字符串。form 是一个可选参数,表示正规化形式,可以是 “NFC”、”NFD”、”NFKC”、”NFKD” 之一。如果不指定 form,则默认为 “NFC”。
- to_utf8(string):将字符串转换为 UTF-8 编码的 varbinary。
- from_utf8(bytes[, replace]):将 UTF-8 编码的 varbinary 转换为字符串。replace 是一个可选参数,表示在发现无效 UTF-8 序列时是否应该替换无效字符。如果设置为 true,无效字符将被 Unicode 替换字符(U+FFFD)替换。如果设置为 false 或省略,函数将在遇到无效 UTF-8 序列时失败。
- key_sampling_percent():此函数不是一个通用的 Unicode 函数,它没有明确的应用在 Unicode 字符串处理中。
Regular Expression Functions
正则表达式是用于处理字符串的强大工具,它有一套复杂的语法和一系列的函数可以帮助我们处理和操作字符串。下面是一些常见的正则表达式函数的介绍:
- regexp_extract_all(string, pattern): 这个函数返回一个数组,该数组包含了所有匹配到的子字符串。如果没有匹配到任何子字符串,它将返回一个空数组。
- regexp_extract(string, pattern, index): 这个函数返回第一个匹配到的子字符串。如果没有匹配到任何子字符串,它将返回 NULL。index 参数表示返回匹配到的第几个子字符串,索引从 1 开始。
- regexp_like(string, pattern): 这个函数返回一个布尔值,表示字符串是否匹配给定的模式。如果字符串匹配模式,它将返回 true,否则返回 false。
- regexp_replace(string, pattern, replacement): 这个函数返回一个新字符串,该字符串是通过将原始字符串中匹配到的所有子字符串替换为 replacement 得到的。如果没有匹配到任何子字符串,它将返回原始字符串。
- regexp_split(string, pattern): 这个函数返回一个数组,该数组是通过将字符串按照匹配到的模式分割得到的。如果没有匹配到任何模式,它将返回一个只包含原始字符串的单元素数组。
Binary Functions and Operators
以下是一些常见的二进制函数及其描述:
- to_base64() 和 from_base64(): 将二进制数据转换为 Base64 字符串和从 Base64 字符串转换回二进制数据。
- to_base64url() 和 from_base64url(): 将二进制数据转换为 Base64Url 安全的字符串和从 Base64Url 安全的字符串转换回二进制数据。
- to_base32() 和 from_base32(): 将二进制数据转换为 Base32 字符串和从 Base32 字符串转换回二进制数据。
- to_hex() 和 from_hex(): 将二进制数据转换为十六进制字符串和从十六进制字符串转换回二进制数据。
- to_big_endian_64() 和 from_big_endian_64(): 将 64 位整数转换为大端字节序的二进制数据,以及从大端字节序的二进制数据转换回 64 位整数。
- to_big_endian_32() 和 from_big_endian_32(): 将 32 位整数转换为大端字节序的二进制数据,以及从大端字节序的二进制数据转换回 32 位整数。
- to_ieee754_64() 和 from_ieee754_64(): 将 64 位浮点数转换为 IEEE 754 标准形式的二进制数据,以及从 IEEE 754 标准形式的二进制数据转换回 64 位浮点数。
- crc32(): 计算数据的 CRC32 校验和。
- md5(): 计算数据的 MD5 哈希值。
- murmur3_x64_128(): 计算数据的 MurmurHash3 哈希值。
- sha1(), sha256(), sha512(): 计算数据的 SHA-1, SHA-256, SHA-512 哈希值。
- xxhash64(): 计算数据的 XXHash 哈希值。
- spooky_hash_v2_32() 和 spooky_hash_v2_64(): 计算数据的 SpookyHash 哈希值。
- hmac_md5(), hmac_sha1(), hmac_sha256(), hmac_sha512(): 使用 HMAC 方法(使用 MD5, SHA-1, SHA-256, SHA-512)计算数据的哈希值。
“`html
to_ieee754_32() 和 from_ieee754_32(): 将 32 位浮点数转换为 IEEE 754 标准形式的二进制数据,以及从 IEEE 754 标准形式的二进制数据转换回 32 位浮点数。
这些函数主要用于数据的编码、解码、哈希和校验等操作。
JSON Functions and Operators
Cast to JSON 与 Cast from JSON
- Cast to JSON: 这个操作是将其他数据类型转换为 JSON 格式。这通常在你需要将数据存储为 JSON 格式或者将数据发送到一个接收 JSON 数据的服务时使用。例如,你可能有一个包含多个字段的数据,你可以将这个数据转换为一个 JSON 对象,这样你就可以在一个单一的 JSON 对象中访问所有的字段。SELECT CAST(‘{“name”:”John”,”age”:30}’ AS JSON); 上述 SQL 语句将一个字符串转换为 JSON 对象。
- Cast from JSON: 这个操作是将 JSON 格式的数据转换为其他数据类型。这通常在你接收到一个 JSON 数据,并需要将它转换为你的应用程序可以更容易处理的格式时使用。例如,你可以将一个包含姓名和年龄的 JSON 对象转换为一个可以直接访问姓名和年龄字段的数据类型。SELECT CAST(‘{“name”:”John”,”age”:30}’ AS JSON) ->> ‘name’;
JSON 函数
在处理 JSON 数据时,以下是一些常用的 JSON 函数及其描述:
- is_json_scalar(json_value): 返回一个布尔值,表示给定的 JSON 值是否为标量(即,是否为字符串、数字、布尔值或 null)。
- json_array_contains(json_array, value): 返回一个布尔值,表示 JSON 数组是否包含给定的值。
- json_array_get(json_array, index): 返回 JSON 数组中给定索引的值。索引从零开始。
- json_array_length(json_array): 返回 JSON 数组的长度。
- json_extract(json, path): 使用给定的路径从 JSON 值中提取数据。路径是由字符串、数字和两个特殊关键字(’.’ 和 ‘*’)组成的表达式。
- json_extract_scalar(json, path): 类似于 json_extract(),但它将结果转换为标量值。
- json_format(json): 返回一个人类可读的字符串,它表示给定的 JSON 值。
- json_parse(json_string): 将字符串解析为 JSON 值。
- json_size(json): 返回 JSON 值的大小(以字节为单位)。
每个函数都有其特定的作用和返回类型。在处理 JSON 数据时,可能需要一种或多种这样的函数。
Date and Time Functions and Operators
日期和时间操作符
日期和时间操作符在 SQL 和许多其他编程语言中都非常常见。它们用于执行日期和时间的各种运算,例如比较、加减、提取特定部分等。以下是一些常见的日期和时间操作符:
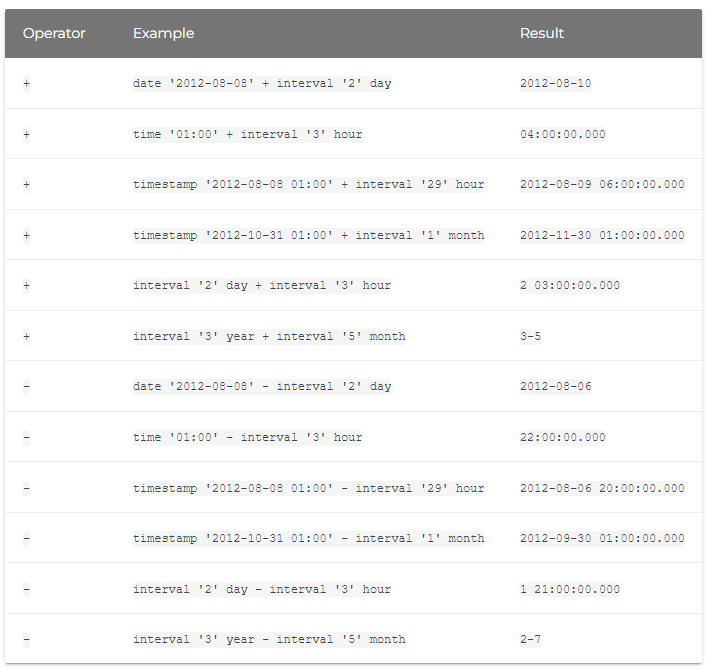
+ 和 –
加法和减法运算可以用来将天数、月数或年数加到日期上,或从日期中减去。例如:
SELECT DATE '2022-01-01' + INTERVAL '1' DAY; -- 返回 '2022-01-02' SELECT DATE '2022-01-01' - INTERVAL '1' DAY; -- 返回 '2021-12-31'
–: 用于比较两个日期之间的差异。例如:
SELECT DATE '2022-01-01' - DATE '2021-01-01'; -- 返回 365,代表两个日期之间的天数差
时区转换
时区转换是在处理日期和时间数据时常见的需求。许多数据库提供了处理时区的内置功能。以下是一些常见的时区转换方法:
AT TIME ZONE 关键字:这是进行时区转换的通用方法,它将一个日期或时间戳从一个时区转换到另一个时区。例如,在 PostgreSQL 中,你可以这样使用:
SELECT TIMESTAMP '2022-01-01 00:00:00' AT TIME ZONE 'UTC' AT TIME ZONE 'America/New_York';
这将 UTC 时区的时间转换为 New York 时区的时间。
CONVERT_TZ 函数:在 MySQL 中,你可以使用这个函数来进行时区转换:
SELECT CONVERT_TZ('2022-01-01 00:00:00', 'UTC', 'America/New_York');
date_add 或 date_sub 函数:如果你知道时区之间的时间差,你也可以使用这些函数来手动更改时间。例如,如果你知道 New York 比 UTC 时间晚 5 小时,你可以这样做:
SELECT DATE_ADD('2022-01-01 00:00:00', INTERVAL 5 HOUR);
注意,具体的函数和关键字可能因不同的数据库系统而异,所以在使用时需要查阅相应的数据库文档。同时,由于夏令时的影响,时区之间的差异可能会有所改变,因此在处理不同时区的数据时需要特别注意。
日期/时间函数
- current_timezone(): 返回当前的时区。
- date(): 返回当前日期或将给定的日期/时间戳转换为日期。
- last_day_of_month(): 返回给定日期所在月份的最后一天的日期。
- from_iso8601_timestamp(): 将 ISO 8601 格式的字符串转换为时间戳。
- from_iso8601_date(): 将 ISO 8601 格式的字符串转换为日期。
- from_unixtime(): 将 UNIX 时间戳(即,自 1970 年 1 月 1 日以来的秒数)转换为日期/时间字符串。
- now(): 返回当前的日期和时间。
- to_iso8601(): 将日期或时间戳转换为 ISO 8601 格式的字符串。
- to_milliseconds(): 将日期或时间戳转换为自 1970 年 1 月 1 日以来的毫秒数。
- to_unixtime(): 将日期或时间戳转换为 UNIX 时间戳(即,自 1970 年 1 月 1 日以来的秒数)。
日期/时间截取函数
“`
date_trunc()是一种在PrestoSQL中使用的函数,用于截断日期或时间戳字段到指定的单位。这意味着在指定的单位之后的所有字段都将变为零。格式如下:
date_trunc('interval', timestamp)在这里,'interval'是你想要截断的日期或时间的级别,比如'year', 'quarter', 'month', 'day'等。'timestamp'是你想要截断的日期或时间戳。
例如,如果你有一个日期'2022-12-31',并且你使用date_trunc('year', date),结果将是'2022-01-01',因为它会截断日期到年份,把月和日都设为最小单位。
下面是一个具体的例子:
SELECT date_trunc('month', DATE '2022-12-31');上述查询的结果将是'2022-12-01',因为date_trunc()函数截断日期到月份,把日设为月份的第一天。
日期/时间间隔函数
PrestoSQL中的date_add()和date_diff()是用于操作日期和时间的函数。以下是它们的定义和使用案例:
date_add()
此函数用于将特定的时间间隔添加到日期或时间戳上。
格式如下:
date_add('unit', interval, timestamp)在这里,'unit'是你想要添加的时间单位(如'day', 'hour', 'minute', 'second'等),'interval'是你想要添加的量,'timestamp'是你想要更改的日期或时间戳。
例如:
SELECT date_add('day', 3, DATE '2022-01-01');上述查询的结果将是'2022-01-04',因为我们添加了3天。
date_diff()
此函数用于计算两个日期或时间戳之间的差异。
格式如下:
date_diff('unit', timestamp1, timestamp2)在这里,'unit'是你想要得到差异的时间单位(如'day', 'hour', 'minute', 'second'等),'timestamp1'和'timestamp2'是你想要比较的日期或时间戳。
例如:
SELECT date_diff('day', DATE '2022-01-01', DATE '2022-01-04');上述查询的结果将是'3',因为两个日期相差3天。
持续时间函数
parse_duration()是PrestoSQL中的一个函数,用于将ISO8601持续时间格式的字符串解析为Presto的间隔。
Presto的parse_duration()函数会自动将解析的间隔转换为Presto内部可处理的最小时间单位。例如,如果你解析一个表示几个小时和分钟的持续时间,你得到的结果将是以毫秒为单位的间隔。
MySQL日期函数
在PrestoSQL中,date_format()和date_parse()函数用于处理日期和时间,这些函数的工作方式类似于MySQL中的同名函数。以下是它们的定义和使用方法:
date_format()
此函数用于将日期或时间戳格式化为指定的格式。
格式如下:
date_format(timestamp, format)在这里,'timestamp'是你要格式化的日期或时间戳,'format'是你希望的输出格式。
例如:
SELECT date_format(TIMESTAMP '2022-01-01 13:15:36 UTC', '%Y-%m-%d %H:%i:%s');上述查询将返回字符串'2022-01-01 13:15:36'。
date_parse()
此函数用于将字符串解析为日期或时间戳。
格式如下:
date_parse(string, format)在这里,'string'是你想要解析的日期或时间的字符串,'format'是字符串的格式。
例如:
SELECT date_parse('2022-01-01 13:15:36', '%Y-%m-%d %H:%i:%s');上述查询将返回一个日期时间戳'2022-01-01 13:15:36.000 UTC'。
记住,你需要根据你的日期/时间字符串的实际格式调整格式字符串('%Y-%m-%d %H:%i:%s')。例如,如果你的日期字符串是"2022/01/01",你应该使用"%Y/%m/%d"作为格式化字符串。
JAVA日期函数
在PrestoSQL中,format_datetime()和parse_datetime()函数用于处理日期和时间的格式。以下是它们的定义和使用方法:
format_datetime()
此函数用于将日期或时间戳格式化为指定的格式。
格式如下:
format_datetime(timestamp, format)在这里,'timestamp'是你要格式化的日期或时间戳,'format'是你希望的输出格式。
例如:
SELECT format_datetime(TIMESTAMP '2022-01-01 13:15:36 UTC', 'yyyy-MM-dd HH:mm:ss');上述查询将返回字符串'2022-01-01 13:15:36'。
parse_datetime()
此函数用于将字符串解析为日期或时间戳。
格式如下:
parse_datetime(string, format)在这里,'string'是你想要解析的日期或时间的字符串,'format'是字符串的格式。
例如:
SELECT parse_datetime('2022-01-01 13:15:36', 'yyyy-MM-dd HH:mm:ss');上述查询将返回一个日期时间戳'2022-01-01 13:15:36.000 UTC'。
记住,你需要根据你的日期/时间字符串的实际格式调整格式字符串('yyyy-MM-dd HH:mm:ss')。例如,如果你的日期字符串是"2022/01/01",你应该使用"yyyy/MM/dd"作为格式化字符串。
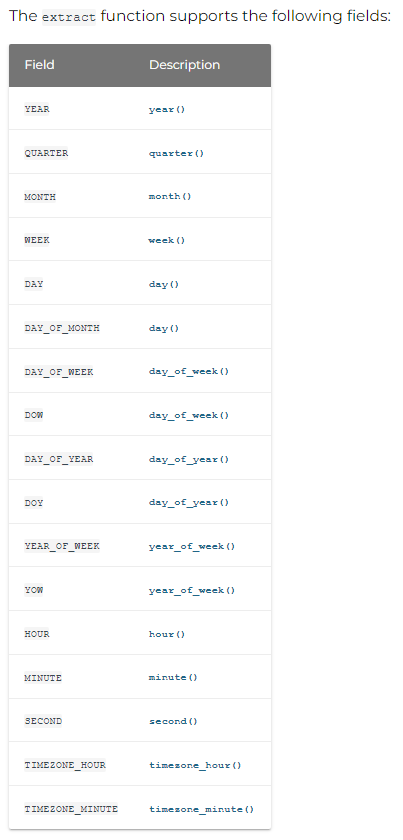
提取函数
extract(unit FROM expression)unit是你希望从日期或时间中提取的部分。它可以是YEAR(年份),QUARTER(季度),MONTH(月份),WEEK(周),DAY(日),HOUR(小时),MINUTE(分钟),SECOND(秒)等。
expression是你希望从中提取unit的日期或时间列。
以下是如何使用它的示例:
SELECT extract(MONTH FROM date_column) as month FROM table_name;在上述的SQL查询中,extract()函数用于从table_name表的date_column字段中提取月份。结果别名为month。这将返回表中每个记录的日期的月份部分。
PrestoSQL提供了一系列便利的提取函数(Convenience Extraction Functions),使我们能够更直观地从日期/时间表达式中提取特定的部分。以下是这些函数的一些示例:
- day(expression)或day_of_month(expression): 从日期/时间表达式中提取日。
- day_of_week(expression)或dow(expression): 从日期/时间表达式中提取星期几(1表示星期一,7表示星期日)。
- day_of_year(expression)或doy(expression): 从日期/时间表达式中提取一年中的第几天(1-366)。
- hour(expression): 从日期/时间表达式中提取小时(0-23)。
- millisecond(expression): 从日期/时间表达式中提取毫秒。
- minute(expression): 从日期/时间表达式中提取分钟(0-59)。
- month(expression): 从日期/时间表达式中提取月份(1-12)。
- quarter(expression): 从日期/时间表达式中提取季度(1-4)。
- second(expression): 从日期/时间表达式中提取秒(0-59)。
- timezone_hour(expression): 从日期/时间表达式中提取时区的小时部分。
- timezone_minute(expression): 从日期/时间表达式中提取时区的分钟部分。
- week(expression)或week_of_year(expression): 从日期/时间表达式中提取一年中的第几周(1-53)。
- year(expression): 从日期/时间表达式中提取年份。
- year_of_week(expression)或yow(expression): 从日期/时间表达式中提取周年(在周年结束时年份增加)。
请注意,这些函数的输入expression应该是日期/时间类型的列或表达式。
Aggregate Functions
特殊聚合函数array_agg()
array_agg()是PrestoSQL中的一个聚合函数,它用于将多个输入值合并成一个数组。如果你想要对输入值进行排序,你可以使用ORDER BY子句。这在你希望结果数组按特定顺序返回时非常有用。
array_agg(x ORDER BY y DESC)
这个函数会收集x的值,并根据y的值以降序方式进行排序。换句话说,y的最大值将出现在结果数组的开头。
例如:
SELECT array_agg(name ORDER BY age DESC) as names FROM people;
该查询将返回一个包含所有人名的数组,数组中的名字按照对应人的年龄降序排列。
array_agg(x ORDER BY x, y, z)
这个函数会收集x的值,并首先根据x自身的值进行排序,如果x的值相同,则继续根据y的值进行排序,如果y的值也相同,则根据z的值进行排序。
例如:
SELECT array_agg(name ORDER BY name, age, city) as names FROM people;
该查询将返回一个包含所有人名的数组,数组中的名字首先按照名字本身进行排序,如果名字相同,则按照年龄排序,如果年龄也相同,则按照城市进行排序。
通用聚合函数
PrestoSQL提供了许多通用的聚合函数,下面是它们的简要介绍:
- any_value(): 返回输入列中的任意值。
- arbitrary(): 返回输入列中的任意值。
- array_agg(): 收集所有输入值并返回一个数组。
- avg(): 计算输入列的平均值。
- bool_and(): 如果所有输入值都为TRUE,则返回TRUE,否则返回FALSE。
- bool_or(): 如果任何输入值为TRUE,则返回TRUE,否则返回FALSE。
- checksum(): 返回输入列的校验和。
- count(): 计算输入列的行数。
- count_if(): 计算满足特定条件的输入列的行数。
- every(): 如果所有输入值都为TRUE,则返回TRUE,否则返回FALSE。
- geometric_mean(): 计算输入值的几何平均数。
- max_by(): 返回使某列最大化的输入列的值。
- min_by(): 返回使某列最小化的输入列的值。
- max(): 返回输入列的最大值。
- min(): 返回输入列的最小值。
- reduce_agg(): 对输入列应用reduce函数以生成一个结果。
- set_agg(): 返回输入列的集合。
- set_union(): 返回所有输入集合的并集。
- sum(): 计算输入列的总和。
每个函数都有其特定的用途,可以满足不同的数据分析需求。在使用时,你需要根据所处理的数据类型和特定的分析目标来选择合适的函数。
位运算聚合函数
在PrestoSQL中,你可以使用特定的位运算聚合函数来对输入值执行位运算。下面是它们的简要介绍:
- bitwise_and_agg(): 对所有输入数值执行位与运算。它将每一个输入值视为二进制数,并执行AND运算。只有所有值的某位都是1,结果的这一位才是1。
- bitwise_or_agg(): 对所有输入数值执行位或运算。它将每一个输入值视为二进制数,并执行OR运算。只要有一个值的某位是1,结果的这一位就是1。
- bitwise_xor_agg(): 对所有输入数值执行位异或运算。它将每一个输入值视为二进制数,并执行XOR运算。如果某位上的输入值有奇数个1,结果的这一位就是1;如果有偶数个1,结果的这一位就是0。
以下是一些示例:
SELECT bitwise_and_agg(column) FROM table; -- 对'column'列所有值执行位与运算 SELECT bitwise_or_agg(column) FROM table; -- 对'column'列所有值执行位或运算 SELECT bitwise_xor_agg(column) FROM table; -- 对'column'列所有值执行位异或运算
这些函数通常在需要对二进制数值执行位运算的场景中使用。
针对Map类型数据的聚合函数
PrestoSQL提供了一些针对Map类型数据的聚合函数。以下是这些函数的简要介绍:
- histogram(): 这个函数接受一个列名作为输入,返回一个map,其中的键是列中出现的不同值,值是这些不同值出现的次数。这可以用来快速生成直方图。
- map_agg(): 这个函数接受两个列名作为输入,生成一个map,其中的键是第一个列中的值,值是第二个列中的值。
- map_union(): 这个函数接受一个map类型的列名作为输入,返回一个map,其中包含输入所有map的并集。如果同一个键在多个map中出现,返回的map中此键的值会是这些map中此键的值的任意一个。
- map_union_sum(): 这个函数接受一个map类型的列名作为输入,返回一个map,其中包含输入所有map的并集。如果同一个键在多个map中出现,返回的map中此键的值会是这些map中此键的值的总和。
- multimap_agg(): 这个函数接受两个列名作为输入,生成一个map,其中的键是第一个列中的值,值是第二个列中的值组成的数组。
以下是一些使用示例:
SELECT histogram(column) FROM table; --生成'column'列值的直方图 SELECT map_agg(key_column, value_column) FROM table; --根据'key_column'和'value_column'生成map SELECT map_union(map_column) FROM table; --计算'map_column'的并集 SELECT map_union_sum(map_column) FROM table; --计算'map_column'的并集并对重复键的值求和 SELECT multimap_agg(key_column, value_column) FROM table; --根据'key_column'和'value_column'生成map,值为数组
这些函数在处理Map类型数据时非常有用,可以帮助你更有效地分析和理解数据。
近似聚合函数
这些是Presto中的一些近似聚合函数,它们用于在计算效率和精确度之间达到一种权衡。
approx_distinct()
这个函数用于计算一列中不同值的近似数量。这是一个优化过的操作,比去重后的计数要快得多,但是结果可能不是完全准确的。例子:
SELECT approx_distinct(user_id) FROM visits;
此查询将返回访问的近似唯一用户数。
approx_percentile()
函数返回指定百分位的近似值。比如approx_percentile(x, 0.5)将计算x列的中位数。可以用于找到数值的近似分布。例子:
SELECT approx_percentile(duration, 0.95) FROM calls;
此查询将返回呼叫持续时间的95th百分位数。
numeric_histogram()
这个函数创建一个数值的直方图,可用于可视化数据的分布。你需要指定桶(bin)的数量作为函数的第一个参数。例子:
SELECT numeric_histogram(10, score) FROM reviews;
此查询将返回评论分数的直方图,分数被划分为10个桶。
noisy_count_gaussian()
这个函数返回数据集的大小,并添加了满足高斯分布的噪声以保护隐私。例子:
SELECT noisy_count_gaussian(user_id) FROM visits;
此查询将返回添加了高斯噪声的近似访问用户数。
noisy_count_if_gaussian()
这个函数添加了高斯噪声的计数,但只有在满足特定条件的行才被计数。例子:
SELECT noisy_count_if_gaussian(user_id, duration > 10) FROM visits;
此查询将返回访问持续时间超过10分钟的用户数,并添加了高斯噪声。
noisy_sum_gaussian()
这个函数返回列的和,并添加了满足高斯分布的噪声,以保护隐私。例子:
SELECT noisy_sum_gaussian(sales) FROM transactions;
此查询将返回总销售额,并添加了高斯噪声。
这些函数都为大数据场景提供了有用的工具,可以在短时间内提供可接受的近似结果。
统计聚合函数
下面是PrestoSQL中这些统计聚合函数的详细解释:
- corr(column1, column2): 计算column1和column2之间的皮尔逊相关系数。
- covar_pop(column1, column2): 计算column1和column2之间的总体协方差。
- covar_samp(column1, column2): 计算column1和column2之间的样本协方差。
- entropy(column): 计算指定列中概率分布的香农熵。
- kurtosis(column): 计算指定列的峰度(四阶中心矩)。
- regr_intercept(column1, column2): 对column1和column2进行线性回归,并返回截距。
- regr_slope(column1, column2): 对column1和column2进行线性回归,并返回斜率。
- regr_avgx(column1, column2): 对column1和column2进行线性回归,并返回column1的平均值。
- regr_avgy(column1, column2): 对column1和column2进行线性回归,并返回column2的平均值。
- regr_count(column1, column2): 对column1和column2进行线性回归,并返回非null对的数量。
- regr_r2(column1, column2): 对column1和column2进行线性回归,并返回决定系数(R-squared)。
- regr_sxy(column1, column2): 对column1和column2进行线性回归,并返回协方差。
- regr_syy(column1, column2): 对column1和column2进行线性回归,并返回column2的平方误差。
- regr_sxx(column1, column2): 对column1和column2进行线性回归,并返回column1的平方误差。
- skewness(column): 计算指定列的偏度(三阶中心矩)。
- stddev(column)或stddev_samp(column): 计算指定列的样本标准差。
- stddev_pop(column): 计算指定列的总体标准差。
- variance(column)或var_samp(column): 计算指定列的样本方差。
- var_pop(column): 计算指定列的总体方差。
这些函数非常有用,它们可以在SQL查询中进行复杂的统计计算。
数据分类聚合函数
Presto提供了一系列有关分类度量的聚合函数,用于评估分类模型的性能。以下是它们的详细解释:
- classification_miss_rate(buckets, y, y_hat): 误分类率(Miss Rate)是被错误分类的实例在所有实例中的比例。这个函数需要三个参数:buckets是分组列,y是实际的标签列,y_hat是预测的标签列。
- classification_fall_out(buckets, y, y_hat): 假正例率(Fall Out)也称为假阳性率,是实际为负例但被错误地预测为正例的实例在所有负例中的比例。这个函数的参数与classification_miss_rate相同。
- classification_precision(buckets, y, y_hat): 精确率(Precision)也称为查准率,是被正确预测为正例的实例在所有被预测为正例的实例中的比例。这个函数的参数与上述两个函数相同。
- classification_recall(buckets, y, y_hat): 召回率(Recall)也称为查全率,是被正确预测为正例的实例在所有实际为正例的实例中的比例。这个函数的参数与上述函数相同。
- classification_threshold(buckets, y, y_hat): 这个函数有待补充完整,如果是用于计算阈值的话,通常情况下,阈值是用于将连续变量转化为二元变量的分界点。
例如,你可以运行以下查询来计算一个分类模型的误分类率:
SELECT classification_miss_rate(buckets, actual_label, predicted_label) FROM predictions;
在这个例子中,buckets是分组列(可能是数据集的一个子集),actual_label是真实的分类标签,predicted_label是模型预测的分类标签。
差分熵函数
differential_entropy(bucket_count, sample, weight)
其中,bucket_count是分桶数,sample是样本数,weight是权重。这是一个估计差分熵的函数。在信息论中,差分熵用于描述连续随机变量的随机性或混乱程度。
approx_most_frequent(buckets, value)
这个函数返回元组(value, frequency),其中value是出现次数最多的值,frequency是该值出现的频率。buckets是用于分组的列,value是要计算频率的列。
蓄水池抽样函数
reservoir_sample()是Presto SQL中的一个蓄水池抽样函数。蓄水池抽样是一种随机抽样方法,特别适用于从不知道大小的(或非常大的)数据集中抽取固定数量的样本。这种抽样方法保证每个元素被抽取的概率都是相等的。
reservoir_sample()函数的使用方法如下:
reservoir_sample(max_samples, value)
其中,max_samples是你想要抽取的样本数量,value是你要从中抽取样本的列。
例如,如果你想从一个包含数百万行的大表中随机抽取1000行,你可以像下面这样使用reservoir_sample()函数:
SELECT reservoir_sample(1000, value) FROM large_table;
在上面的查询中,value列的1000个随机样本将被抽取出来。
这个函数在处理大数据集时非常有用,因为它可以在固定、有限的内存下工作,而不需要知道数据集的实际大小。
Window Functions
聚合函数
在SQL中,聚合函数是对一组值进行操作并返回单个值的函数,例如SUM(), AVG(), COUNT(), MIN()和MAX()等。当你添加OVER子句时,这些聚合函数就变成了窗口函数。窗口函数允许你在一个数据子集(窗口)上进行计算,而非整个结果集。
你给出的查询示例:
SELECT clerk, orderdate, orderkey, totalprice,
sum(totalprice) OVER(PARTITION BY clerk
ORDER BY orderdate) AS rolling_sum
FROM orders
ORDER BY clerk, orderdate, orderkey
在这个查询中,sum(totalprice) OVER(PARTITION BY clerk ORDER BY orderdate)是一个窗口函数。它计算了每个clerk(通过PARTITION BY子句定义)的totalprice的累计和(通过ORDER BY子句定义)。这个窗口对每个clerk的每一天都重新计算,因此它会给出一个滚动总和(或累计和)。
PARTITION BY子句将数据分为多个分区,每个分区都有自己的窗口。在这个例子中,每个clerk都有自己的分区。
ORDER BY子句定义了每个分区内的行顺序。在这个例子中,每个clerk分区内的行按orderdate排序。
所以,这个查询会返回一个表,其中包含每个订单的clerk,orderdate,orderkey,totalprice,以及到当前日期为止的clerk的totalprice的滚动总和。
排序函数
在SQL中,排名函数是一种特殊类型的窗口函数,用于对结果集中的行进行排序或排名。以下是你提到的几个Presto SQL中的排名函数及其用途:
- cume_dist(): 计算当前行在其窗口分区内的累积分布。结果是一个介于0和1之间的值,其中1表示当前行不小于分区中的任何行。
- dense_rank(): 为窗口分区内的每一行分配一个排名,排名值在整个分区内是连续的。排名相等的行(即,根据ORDER BY子句排序结果相同的行)会得到相同的排名。
- ntile(n): 将窗口分区内的行分成n个大致相等的组,为每一行分配一个tile(分组)号。例如,ntile(4)会将结果集划分为四分之一。
- percent_rank(): 计算当前行在其窗口分区内的百分比排名。结果是一个介于0(表示第一名)和1(表示最后一名)之间的值。
- rank(): 为窗口分区内的每一行分配一个排名。排名相等的行(即,根据ORDER BY子句排序结果相同的行)会得到相同的排名。如果存在排名相等的行,则下一个排名值会跳过。
- row_number(): 为窗口分区内的每一行分配一个唯一的序号。即使多行的排序结果相同,序号也会各不相同。
注意,所有这些函数都需要配合OVER子句使用,可以包含PARTITION BY和ORDER BY来定义窗口分区和排序。例如:
SELECT product, sales, RANK() OVER(ORDER BY sales DESC) as rank FROM sales_table;
这个查询会返回一个表,其中包含每个产品的销售额,以及它们按销售额降序排名的排名。
值函数
在SQL中,值函数是一种窗口函数,它允许你获取窗口内特定位置的值。以下是你提到的一些Presto SQL中的值函数及其作用:
- first_value(): 返回窗口分区内的第一个值。例如,first_value(sales) OVER(ORDER BY date)将返回每个窗口中日期最早的销售额。
- last_value(): 返回窗口分区内的最后一个值。例如,last_value(sales) OVER(ORDER BY date)将返回每个窗口中日期最晚的销售额。
- nth_value(n): 返回窗口分区内的第n个值。例如,nth_value(sales, 3) OVER(ORDER BY date)将返回每个窗口中日期第三早的销售额。
- lead(): 返回当前行之后的行的值。例如,lead(sales) OVER(ORDER BY date)将返回当前行日期之后的销售额。你还可以指定一个偏移量和默认值,例如lead(sales, 2, 0) OVER(ORDER BY date)将返回两行之后的销售额,如果没有那么多行,则返回0。
lag(): 返回当前行之前的行的值。例如,lag(sales) OVER (ORDER BY date) 将返回当前行日期之前的销售额。你还可以指定一个偏移量和默认值,例如 lag(sales, 3, 0) OVER (ORDER BY date) 将返回三行之前的销售额,如果没有那么多行,则返回 0。
这些函数在分析数据时非常有用,因为它们允许你在同一行中访问其他行的值。然而,它们的结果可能会受窗口大小和偏移量的影响,所以在使用时需要注意定义这些参数。
Array Functions and Operators
在 PrestoSQL 中,你可以使用特定的操作符来处理数组类型的数据。
下标操作符 []
这个操作符用于访问数组中的一个元素,数组的索引从 1 开始。例如:
SELECT my_array[1] AS first_element
这个查询将返回 my_array 数组的第一个元素。
连接操作符 ||
这个操作符用于连接两个数组,或者一个数组和一个相同类型的元素。例如:
SELECT ARRAY[1] || ARRAY[2]; -- 结果是: [1, 2] SELECT ARRAY[1] || 2; -- 结果是: [1, 2] SELECT 2 || ARRAY[1]; -- 结果是: [2, 1]
这些查询分别演示了如何使用 || 操作符来连接两个数组,以及如何将元素添加到数组的开始或结束。
这些操作符可以帮助你更方便地在 SQL 查询中处理数组数据。
数组函数
在 PrestoSQL 中,提供了一系列的数组函数来帮助你处理数组类型的数据。以下是你所提到的这些函数的简要介绍:
- all_match(array(T), function(T, boolean)): 判断数组中的所有元素是否都满足指定的条件。
- any_match(array(T), function(T, boolean)): 判断数组中是否有任何元素满足指定的条件。
- array_average(array(T)): 计算数组中所有元素的平均值。
- array_cum_sum(array(T)): 计算数组元素的累积和。
- array_distinct(array(T)): 移除数组中的重复元素。
- array_duplicates(array(T)): 返回数组中的重复元素。
- array_except(array1(T), array2(T)): 返回在第一个数组中但不在第二个数组中的元素。
- array_frequency(array(T)): 返回一个 Map,其中包含了每个元素及其出现的次数。
- array_has_duplicates(array(T)): 判断数组中是否有重复元素。
- array_intersect(array1(T), array2(T)): 返回两个数组的交集。
- array_join(array(T), delimiter, [null_replacement]): 将数组元素连接成字符串。
- array_least_frequent(array(T)): 返回数组中出现频率最低的元素。
- array_max(array(T)): 返回数组中的最大值。
- array_min(array(T)): 返回数组中的最小值。
- array_max_by(array(T), function(T, V)), array_min_by(array(T), function(T, V)): 分别返回使函数返回最大值和最小值的数组元素。
- array_normalize(array(T)): 返回数组中每个元素的值除以数组元素的总和。
- array_position(array(T), element): 返回元素在数组中的位置,如果不存在则返回 0。
- array_remove(array(T), element): 返回一个数组,其中移除了所有和给定元素相等的元素。
- array_sort(array(T)), array_sort_desc(array(T)): 分别返回按升序和降序排序的数组。
- array_sum(array(T)): 返回数组元素的总和。
- array_top_n(array(T), n): 返回数组中的前 n 个最大元素。
- arrays_overlap(array1(T), array2(T)): 判断两个数组是否有交集。
- array_union(array1(T), array2(T)): 返回两个数组的并集。
- cardinality(array(T)): 返回数组的长度。
- combinations(array(T), n): 返回数组所有可能的 n 元组。
- contains(array(T), element): 判断数组是否包含指定元素。
- element_at(array(T), index): 返回数组指定位置的元素。
- filter(array(T), function(T, boolean)): 返回数组中满足指定条件的元素。
- flatten(array(T)): 将多维数组转化为一维数组。
- find_first(array(T), element), find_first_index(array(T), element): 分别返回数组中第一个与给定元素相等的元素和其索引。
- ngrams(array(T), n): 返回数组所有可能的 n 元组。
- none_match(array(T), function(T, boolean)): 判断数组中是否没有元素满足指定的条件。
- reduce(array(T), initialState S, inputFunction(S, T, V), outputFunction(S, R)): 将数组元素以指定的方式进行合并。
- remove_nulls(array(T)): 返回一个数组,其中移除了所有的 NULL 元素。
- repeat(element, count): 返回一个数组,其中包含了 count 个 element。
- sequence(start, stop, [step]): 返回一个包含指定序列的数组。
- shuffle(array(T)): 返回一个随机排列的数组。
- slice(array(T), start, length): 返回数组的一个子数组。
- trim_array(array(T)): 返回一个数组,其中移除了开始和结束的 NULL 元素。
- transform(array(T), function(T, V)): 返回一个数组,其中的每个元素都是将函数应用在原数组元素上的结果。
- zip(array1(T), array2(U), …), zip_with(array(T), array(U), function(T, U, V)): 分别返回一个由数组元素组成的元组的数组,和一个由函数应用在元组上的结果组成的数组。
注意,上述中的 T, U, V, S, R 都表示数据的类型。希望这些信息能帮助你更好地理解和使用 Presto 中的数组函数。
Map Functions and Operators
[] 操作符
在 PrestoSQL 中,[] 操作符也可以用于从 map 类型的字段中获取对应键(key)的值。例如:
SELECT name_to_age_map['Bob'] AS bob_age;
在这个查询中,name_to_age_map 是一个 map 类型的字段,它的键是名字(字符串类型),值是年龄(整数类型)。name_to_age_map[‘Bob’] 将返回 map 中键为 ‘Bob’ 的值,也就是 Bob 的年龄。
请注意,如果 map 中不存在给定的键,该操作将返回 NULL。你可以使用 map_contains() 函数来检查 map 是否包含指定的键,避免出现 NULL 结果。
map 函数
在 PrestoSQL 中,map 函数用于处理 map 类型数据。以下是你提到的这些函数的简要介绍:all_keys_match(map(K, V), function(K, boolean)), any_keys_match(map(K, V), function(K, boolean)): 判断 map 中的所有键/任何一个键是否满足指定函数。
在这些函数中,K, V, W, R, U 都代表数据的类型。希望这些信息可以帮助你更好地理解和使用 Presto 中的 map 函数。
URL Functions
URL 抽取函数
在 Presto SQL 中,提供了一系列的抽取函数(Extraction Functions),可以用来从 URL 中抽取特定部分。这些函数包括:
- url_extract_fragment(url): 这个函数返回给定 URL 中的片段部分。片段是 URL 中 # 后面的部分。例如,url_extract_fragment(‘http://example.com/path#fragment’) 返回 ‘fragment’。
- url_extract_host(url): 这个函数返回给定 URL 中的主机名。例如,url_extract_host(‘http://example.com/path’) 返回 ‘example.com’。
- url_extract_parameter(url, parameter_name): 这个函数返回给定 URL 查询字符串中指定参数的值。如果参数不存在,则返回 NULL。例如,url_extract_parameter(‘http://example.com/path?name=value’, ‘name’) 返回 ‘value’。
- url_extract_path(url): 这个函数返回给定 URL 的路径部分。路径是 URL 中主机名和查询字符串之间的部分。例如,url_extract_path(‘http://example.com/path’) 返回 ‘/path’。
- url_extract_port(url): 这个函数返回给定 URL 的端口号。如果 URL 中没有指定端口号,则返回默认的 HTTP 或 HTTPS 端口。例如,url_extract_port(‘http://example.com:8080/path’) 返回 8080。
- url_extract_protocol(url): 这个函数返回给定 URL 的协议部分。例如,url_extract_protocol(‘http://example.com/path’) 返回 ‘http’。
- url_extract_query(url): 这个函数返回给定 URL 的查询字符串部分。查询字符串是 URL 中 ? 后面的部分。例如,url_extract_query(‘http://example.com/path?name=value’) 返回 ‘name=value’。
这些函数使得在 SQL 查询中处理和分析 URL 数据变得简单方便。
URL 编码函数
在 Presto SQL 中,编码函数(Encoding Functions)是用来对字符串进行编码或解码的。以下是你所提到的这两个函数的简要介绍:
- url_encode(string): 这个函数返回 URL 编码后的字符串。URL 编码也被称为百分号编码,它是一种将非字母数字字符编码为 %XY 格式的机制,其中 XY 是字符在 ASCII 表中的十六进制代码。这在构建有效的 URL 时非常有用,特别是对于查询参数的编码。例如,url_encode(‘hello world!’) 返回 ‘hello%20world%21’。
- url_decode(string): 这个函数返回 URL 解码后的字符串。它执行的操作与 url_encode 函数相反,将 %XY 格式的编码转换回原始字符。例如,url_decode(‘hello%20world%21’) 返回 ‘hello world!’。
注意,url_encode 和 url_decode 是互逆的操作,也就是说对一个字符串先进行 URL 编码,然后再进行 URL 解码,得到的结果应该是原始字符串。同样的,对一个字符串先进行 URL 解码,然后再进行 URL 编码,如果原始字符串已经是正确的 URL 编码,那么得到的结果应该是原始字符串。
IP Functions
在 Presto SQL 中,IP 函数(IP Functions)可以用来处理 IP 地址和子网。以下是你所提到的这些函数的简要介绍:
- ip_prefix(ip_address, subnet_size): 这个函数接收一个 IP 地址和一个子网大小,然后返回该子网的 CIDR 表示。例如,ip_prefix(‘192.0.2.0’, 24) 返回 ‘192.0.2.0/24’。
- ip_subnet_min(subnet_address): 这个函数接收一个子网地址,然后返回该子网中的最小 IP 地址。例如,ip_subnet_min(‘192.0.2.0/24’) 返回 ‘192.0.2.0’。
- ip_subnet_max(subnet_address): 这个函数接收一个子网地址,然后返回该子网中的最大 IP 地址。例如,ip_subnet_max(‘192.0.2.0/24’) 返回 ‘192.0.2.255’。
- ip_subnet_range(subnet_address): 这个函数接收一个子网地址,然后返回一个表示该子网中所有 IP 地址的数组。例如,ip_subnet_range(‘192.0.2.0/30’) 返回 [‘192.0.2.0’, ‘192.0.2.1’, ‘192.0.2.2’, ‘192.0.2.3’]。
is_subnet_of(ip_address, subnet_address): 这个函数接收一个 IP 地址和一个子网地址,如果 IP 地址位于子网中,则返回 true,否则返回 false。例如,is_subnet_of(‘192.0.2.3’, ‘192.0.2.0/24’) 返回 true,而 is_subnet_of(‘192.0.3.3’, ‘192.0.2.0/24’) 返回 false。
这些函数可以帮助你在 SQL 查询中处理和分析 IP 地址和子网。
Geospatial Functions
构造函数
在 Presto SQL 中,构造函数 (Constructors) 用来创建新的几何对象。以下是您所提到的这些函数的简要介绍:
- ST_AsBinary(geometry): 这个函数返回给定几何对象的 Well-Known Binary (WKB) 表示。
- ST_AsText(geometry): 这个函数返回给定几何对象的 Well-Known Text (WKT) 表示。
- ST_GeometryFromText(wkt): 这个函数根据输入的 Well-Known Text (WKT) 创建一个新的几何对象。
- ST_GeomFromBinary(wkb): 这个函数根据输入的 Well-Known Binary (WKB) 创建一个新的几何对象。
- ST_LineFromText(wkt): 这个函数根据输入的 Well-Known Text (WKT) 创建一个新的线对象。
- ST_LineString(point1, point2, …): 这个函数根据输入的点创建一个新的线对象。
- ST_MultiPoint(point1, point2, …): 这个函数根据输入的点创建一个新的多点对象。
- ST_Point(x, y): 这个函数创建一个新的点对象。
- ST_Polygon(lineString): 这个函数根据输入的线字符串创建一个新的多边形对象。
- to_spherical_geography(geometry): 这个函数将输入的几何对象转换为球面地理几何对象。
- to_geometry(spherical_geography): 这个函数将输入的球面地理几何对象转换为几何对象。
这些函数对于处理和分析地理和地理空间数据非常有用。
关系测试函数
在 Presto SQL 中,关系测试函数 (Relationship Tests) 用于确定两个几何对象之间的空间关系。以下是你提到的这些函数的简要介绍:
- ST_Contains(geometry1, geometry2): 如果几何对象 1 包含几何对象 2,则返回 true。
- ST_Crosses(geometry1, geometry2): 如果几何对象 1 和几何对象 2 交叉,则返回 true。
- ST_Disjoint(geometry1, geometry2): 如果几何对象 1 和几何对象 2 在空间上是不相交的,则返回 true。
- ST_Equals(geometry1, geometry2): 如果几何对象 1 在空间上等于几何对象 2,则返回 true。
- ST_Intersects(geometry1, geometry2): 如果几何对象 1 和几何对象 2 在空间上相交,则返回 true。
- ST_Overlaps(geometry1, geometry2): 如果几何对象 1 和几何对象 2 在空间上重叠,则返回 true。
- ST_Relate(geometry1, geometry2, pattern): 根据给定的 9 交矩阵模式字符串,判断几何对象 1 和几何对象 2 的空间关系。
- ST_Touches(geometry1, geometry2): 如果几何对象 1 和几何对象 2 在空间上接触,即它们至少有一个公共点,但他们的内部并不相交,则返回 true。
- ST_Within(geometry1, geometry2): 如果几何对象 1 在几何对象 2 内,则返回 true。
这些函数对于处理和分析地理和地理空间数据非常有用,特别是在确定几何对象之间的空间关系时。
操作函数
在 Presto SQL 中,操作函数 (Operations) 用于对几何对象进行一些空间操作。以下是你提到的这些函数的简要介绍:
- geometry_union(array(geometry)): 这个函数返回一个数组中所有几何对象的并集。
- ST_Boundary(geometry): 这个函数返回一个几何对象的边界。
- ST_Buffer(geometry, distance): 这个函数返回一个几何对象的缓冲区,即包含与原始几何对象的所有点的距离不超过指定距离的所有点的几何对象。
- ST_Difference(geometry1, geometry2): 这个函数返回几何对象 1 和几何对象 2 的差集,即只存在于几何对象 1 中的部分。
- ST_Envelope(geometry): 这个函数返回一个几何对象的最小边界矩形。
- ST_EnvelopeAsPts(geometry): 这个函数返回一个表示几何对象最小边界矩形的点数组。
- expand_envelope(envelope, point): 这个函数扩展一个最小边界矩形以包含一个额外的点。
- ST_ExteriorRing(polygon): 这个函数返回一个多边形的外环。
- ST_Intersection(geometry1, geometry2): 这个函数返回几何对象 1 和几何对象 2 的交集。
- ST_SymDifference(geometry1, geometry2): 这个函数返回几何对象 1 和几何对象 2 的对称差集,即只存在于一个几何对象中但不是两者共有的部分。
- ST_Union(geometry1, geometry2): 这个函数返回几何对象 1 和几何对象 2 的并集。
这些函数对于处理和分析地理和地理空间数据非常有用,特别是在执行几何对象之间的空间操作时。
访问函数
在 Presto SQL 中,访问函数 (Accessors) 用于获取几何对象的属性或执行对其的某些计算。以下是你提到的这些函数的简要介绍:
- ST_Area(geometry): 计算几何对象的面积。
- ST_Centroid(geometry): 计算几何对象的质心。
- ST_ConvexHull(geometry): 计算几何对象的凸包。
- ST_CoordDim(geometry): 返回几何对象的坐标维数。
- ST_Dimension(geometry): 返回几何对象的维度。
- ST_Distance(geometry1, geometry2): 计算两个几何对象之间的最短距离。
- geometry_nearest_points(geometry1, geometry2): 返回两个几何对象之间最近点的对。
- ST_GeometryN(geometry, n): 返回几何集合中第 n 个几何对象。
- ST_InteriorRingN(geometry, n): 返回多边形的第 n 个内环。
- ST_GeometryType(geometry): 返回几何对象的类型。
- ST_IsClosed(geometry): 如果几何对象是封闭的,返回 true。
- ST_IsEmpty(geometry): 如果几何对象是空的,返回 true。
- ST_IsSimple(geometry): 如果几何对象是简单的,返回 true。
- ST_IsRing(geometry): 如果线对象是环,返回 true。
- ST_IsValid(geometry): 如果几何对象是有效的,返回 true。
- ST_Length(geometry): 计算线或多线的长度。
- ST_PointN(geometry, n): 返回线上的第 n 个点。
- ST_Points(geometry): 返回线或多线的所有点。
- ST_XMax(geometry), ST_YMax(geometry), ST_XMin(geometry), ST_YMin(geometry): 返回几何对象的最大或最小 X 或 Y 坐标。
- ST_StartPoint(geometry), ST_EndPoint(geometry): 返回线或多线的起点或终点。
- ST_InteriorRings(geometry): 返回多边形的所有内环。
- ST_NumGeometries(geometry): 返回几何集合中的几何对象数量。
- ST_Geometries(geometry): 返回几何集合中的所有几何对象。
- flatten_geometry_collections(geometry): 返回几何集合的所有几何对象,但不包括几何集合。
- ST_NumPoints(geometry): 返回线或多线的点数。
- ST_NumInteriorRing(geometry): 返回多边形的内环数量。
- simplify_geometry(geometry, tolerance): 返回一个简化的几何对象,以给定的公差为界。
- line_locate_point(line, point): 返回线上最接近给定点的点的比例距离。
- line_interpolate_point(line, fraction): 返回线上给定比例距离的点。
- geometry_invalid_reason(geometry): 如果几何对象无效,返回原因。
- great_circle_distance(point1, point2): 返回两点间的大圆距离。
- geometry_as_geojson(geometry), geometry_from_geojson(json): 返回几何对象的GeoJSON表示,或从GeoJSON创建几何对象。
ST_X(geometry), ST_Y(geometry): 返回点的X或Y坐标。
这些函数有助于处理和分析地理和地理空间数据,特别是在获取几何对象的属性或执行计算时。
聚合函数
在Presto SQL中,聚合函数(Aggregations)用于对几何对象的集合进行一些计算和操作:
- convex_hull_agg(geometry): 这个函数对输入的几何对象集合进行聚合,并返回这些对象的凸包。凸包是包含输入集合中所有点,并且所有内角都小于180度的最小凸多边形。例如,SELECT convex_hull_agg(geometry) FROM table返回表中所有几何对象的凸包。
- geometry_union_agg(geometry): 这个函数对输入的几何对象集合进行聚合,并返回这些对象的并集。结果几何对象包含输入集合中所有几何对象的所有点。例如,SELECT geometry_union_agg(geometry) FROM table返回表中所有几何对象的并集。
这些函数在处理和分析地理和地理空间数据时非常有用,特别是在需要对大量几何对象进行操作时。
Bing Tiles函数
在Presto SQL中,Bing Tiles函数用于处理Bing Maps的切片系统相关的操作。以下是你提到的这些函数的简要介绍:
- bing_tile(quad_key), bing_tile(x, y, zoom_level): 这两个函数返回一个Bing Tile,通过四键值或x、y坐标和缩放级别指定。
- bing_tile_parent(tile): 这个函数返回给定Bing Tile的父Tile。
- bing_tile_children(tile): 这个函数返回给定Bing Tile的所有子Tile。
- bing_tile_at(latitude, longitude, zoom_level): 这个函数返回包含给定纬度和经度的Bing Tile。
- bing_tiles_around(latitude, longitude, radius, zoom_level): 这个函数返回包含给定纬度和经度周围的所有Bing Tile。
- bing_tile_coordinates(tile): 这个函数返回一个给定Bing Tile的x, y坐标。
- bing_tile_polygon(tile): 这个函数返回一个表示给定Bing Tile的多边形。
- bing_tile_quadkey(tile): 这个函数返回一个给定Bing Tile的四键值。
- bing_tile_zoom_level(tile): 这个函数返回一个给定Bing Tile的缩放级别。
- geometry_to_bing_tiles(geometry, zoom_level): 这个函数返回一个数组,包含与给定几何对象相交的所有Bing Tiles。
- geometry_to_dissolved_bing_tiles(geometry, zoom_level, max_tiles): 这个函数返回一个几何对象,它表示所有与给定几何对象相交的Bing Tiles的并集。
这些函数可以帮助处理与Bing Maps切片系统相关的操作,包括创建Bing Tiles、查询Bing Tiles的属性和与Bing Tiles相关的地理空间计算。
HyperLogLog Functions
Presto提供了一套HyperLogLog函数,用于对大数据集进行基数估计。HyperLogLog是一种概率数据结构,用于估计数据集的不同元素数量,也就是基数。它相较于精确计数,可以显著降低存储和计算的开销。以下是Presto中的一些HyperLogLog函数:
在Presto SQL中,以下是你提到的这些函数的简要介绍:
- approx_set(value): 这个函数在一个HyperLogLog数据结构中添加一个元素,该结构用于基数估计。可以使用此函数来创建一个唯一值的近似集合,消耗的内存将远远低于精确的唯一计数。
- empty_approx_set(): 这个函数返回一个空的HyperLogLog数据结构,可以用于基数估计。
- merge(HyperLogLog): 这个函数合并多个HyperLogLog数据结构,结果是一个新的HyperLogLog,包含所有输入HyperLogLog的所有元素。此函数可用于合并通过approx_set函数创建的多个集合。
- merge_hll(HyperLogLog): 这个函数与merge函数相同,都是用来合并多个HyperLogLog数据结构。在早期的Presto版本中,merge函数被命名为merge_hll,现在已经被merge函数取代。
这些函数提供了一种进行基数估计的方法,这对于大规模数据集的处理非常有用,尤其是当需要进行唯一值计数,但内存有限时。
KHyperLogLog Functions
Presto的KHyperLogLog函数是用于处理KHyperLogLog数据结构的。KHyperLogLog是一种概率数据结构,用于估计数据集中不同元素的数量,即基数。与HyperLogLog类似,KHyperLogLog提供了对存储和计算需求的优化,但它还提供了对集合运算的支持,例如交集和差集。
以下是Presto中的一些KHyperLogLog函数:
- khyperloglog_agg(x): 这个函数聚合一组值,并返回一个KHyperLogLog实例,该实例包含所有的输入值。
- intersection_cardinality(KHyperLogLog1, KHyperLogLog2): 这个函数用于估计两个KHyperLogLog实例的交集的基数。
- jaccard_index(KHyperLogLog1, KHyperLogLog2): 这个函数返回两个KHyperLogLog实例的Jaccard索引,即他们的交集大小与并集大小之比。
- uniqueness_distribution(KHyperLogLog): 这个函数返回一个KHyperLogLog实例的唯一性分布,即每个基数的频率。
- reidentification_potential(KHyperLogLog): 这个函数返回一个KHyperLogLog实例的重识别潜力,即任何给定元素被误识别为另一个元素的可能性。
- merge_khll(KHyperLogLog): 这个函数合并多个KHyperLogLog实例,并返回一个新的KHyperLogLog实例,该实例包含所有输入实例的元素。
这些函数可以用来进行大规模数据集的基数估计,并支持集合运算,这对于处理大数据特别有用。
Quantile Digest Functions
Presto的 QuantileDigest 函数是用于处理 QuantileDigest 数据结构的。QuantileDigest 是一种概率数据结构,用于估算数据流中的百分位数和频率。与精确计算相比,QuantileDigest 消耗的存储和计算开销要小得多。
以下是 Presto 中的一些 QuantileDigest 函数:
- value_at_quantile(qdigest(T), quantile): 这个函数返回指定 q-digest 在给定百分位数处的值。这对于寻找数据集中特定百分位数的值非常有用。
- quantile_at_value(qdigest(T), value): 这个函数返回指定 q-digest 中给定值所对应的百分位数。这可以帮助你理解给定值在整个数据集中的相对位置。
- scale_qdigest(qdigest(T), scale_factor): 这个函数调整 q-digest 的规模,该规模决定了 q-digest 的精度和大小。增加规模因子将增加精度和大小,减少规模因子将减少精度和大小。
- values_at_quantiles(qdigest(T), array(quantile)): 这个函数返回指定 q-digest 在给定多个百分位数处的值。这对于同时寻找数据集中多个百分位数的值非常有用。
- qdigest_agg(x): 这个函数对一组值进行聚合,生成一个 q-digest 实例。这是创建 q-digest 的主要方法,可以用于大规模数据集的百分位数和频率估计。
这些函数提供了一种处理大规模数据集的百分位数和频率估算的方法,特别适合内存有限的情况。
UUID functions
Presto 中的 UUID 函数是一组处理 UUID(Universally Unique Identifier,通用唯一识别码)的函数。这些函数提供了生成、比较和解析 UUID 的功能。
uuid(): 这个函数生成一个随机的 UUID。
T-Digest Functions
Presto 的 T-Digest 函数是一组处理 T-Digest(T-分位数摘要)数据结构的函数。T-Digest 是一种概率型数据结构,用于估计数据流中的百分位数,特别适合处理大规模和动态数据。
以下是 Presto 中的一些 T-Digest 函数:
- value_at_quantile(tdigest(double), double): 这个函数返回指定的 T-Digest 在给定百分位数处的值。这种函数可以用于找到数据集中特定百分位的值。
- quantile_at_value(tdigest(double), double): 这个函数返回 T-Digest 中给定值对应的百分位数。这可以帮助你理解给定值在整个数据集中的相对位置。
- scale_tdigest(tdigest(double), double): 这个函数返回一个新的 T-Digest,它的规模因子为原始 T-Digest 的规模因子与给定值的乘积。规模因子越大,T-Digest 的精度越高,但所需的存储空间也越大。
- values_at_quantiles(tdigest(double), array(double)): 这个函数返回指定的 T-Digest 在给定多个百分位数处的值。你可以用这个函数找到数据集中多个百分位的值。
- trimmed_mean(tdigest(double), min_quantile, max_quantile): 这个函数返回指定的 T-Digest 在给定的最小和最大百分位数之间的所有值的平均值。
- tdigest_agg(double): 这个函数对一组值进行聚合,生成一个 T-Digest 实例。它是创建 T-Digest 的主要方法,可以用于大规模数据集的百分位数和频率估计。
- destructure_tdigest(tdigest(double)): 这个函数将 T-Digest 分解为一个由结构元组组成的数组,每个元组包含一个 centroid 的 mean 和 weight。这可以让你检查 T-Digest 的内部结构。
- construct_tdigest(array(row(double, double))): 这个函数接受一个数组,每个元素是一个包含 mean 和 weight 的行,返回一个由这些 centroid 构成的 T-Digest。
- merge_tdigest(tdigest(double)): 这个函数合并多个 T-Digest 实例,并返回一个新的 T-Digest 实例,包含所有输入 T-Digest 的所有元素。
这些函数提供了一种强大的工具,可以用于处理大规模数据集的百分位数估计,特别适合内存有限的情况。
Color Functions
Presto 的 Color 函数是一组处理颜色和颜色代码的函数。这些函数提供了颜色的解析、转换和处理功能。
以下是 Presto 中的一些 Color 函数:
- bar(double, double, varchar, varchar, varchar): 这个函数生成一个简单的柱状图,其中的每一项都由特定的字符表示。第一个参数是值,第二个参数是最大值,第三个参数是全角字符,第四个参数是半角字符,第五个参数是空白字符。例如,bar(5, 10, ‘=’, ‘-‘, ”) 将生成一个长度为 10 的柱状图,其中前半部分是由等号表示,后半部分是由空格表示。
- color(string): 这个函数将颜色名称或颜色代码转换为十六进制数。支持的颜色名称包括基本的 16 种 HTML 颜色名称,如 “black”、”white”、”red” 等,也支持 RGB 颜色代码,如 “#RRGGBB” 或 “#RGB”。
- render(varchar, map(varchar, varchar)): 这个函数使用一个模板和一个变量映射来渲染一个字符串。模板中的变量用 ${variable} 的形式表示,映射中的键是变量名,值是要替换变量的字符串。
- rgb(int, int, int): 这个函数根据提供的红、绿、蓝三种颜色的值生成一个颜色。颜色值的范围在 0 到 255 之间。返回的颜色是一个 6 位的十六进制数,代表颜色的 RGB 代码。
这些函数使得在处理涉及颜色的数据时更加方便,包括解析颜色代码、生成颜色和生成简单的柱状图。
Session Information
Presto 的会话信息 (Session Information) 是指在一个 Presto 查询会话中的一系列参数和配置。这些信息主要用于在 Presto 查询时确定运行环境和行为。
Teradata Functions
Presto 的 Teradata 函数是一组函数,它们模拟 Teradata 数据库中相同名称的函数的行为。这些函数主要用于处理字符串、日期和时间,以及数值计算。
以下是一些常见的 Presto Teradata 函数:
字符串函数 (String Functions):
- char2hexint(string): 这个函数返回一个十六进制表示的字符串,对应于输入字符串中的每个字符的 Unicode 代码点。
- index(string, substring): 这个函数返回 substring 在 string 中的起始位置。如果没有找到 substring,那么返回值为 0。
- substring(string, start, length): 这个函数返回 string 的一个子串,从 start 位置开始,长度为 length。如果只给出 start 参数而没有给出 length 参数,那么子串将包含从 start 位置开始到 string 末尾的所有字符。
日期函数 (Date Functions):
- to_char(value, format): 这个函数返回一个字符串,表示 value 的值,使用给定的格式。value 可以是日期、时间或时间戳,格式是一个表示日期和时间格式的字符串。
- to_timestamp(string, format): 这个函数根据给定的格式将一个字符串解析为一个时间戳。
- to_date(string, format): 这个函数根据给定的格式将一个字符串解析为一个日期。
以上只是一部分 Teradata 函数,你可以在 Presto 的官方文档中查看所有的 Teradata 函数。这些函数为在 Presto 中处理数据提供了更多的灵活性和方便性,特别是对于熟悉 Teradata 数据库系统的用户。
Internationalization Functions
在 Presto 中,Myanmar 函数是一系列专门用于处理缅甸语文字的函数。以下是你提到的这些函数的介绍:
- myanmar_font_encoding(string): 这个函数返回一个表示输入字符串所使用的字体编码的字符串。可能的返回值包括 ‘zawgyi’、’unicode’ 或 ‘unknown’。
- myanmar_normalize_unicode(string): 这个函数将输入字符串中的缅甸语字符标准化为Unicode表示形式。如果输入字符串已经是Unicode,那么返回值与输入相同。
这些函数对于处理缅甸语文本非常有用,特别是在涉及到字体编码和字符标准化的情况下。
SetDigest functions
在Presto中,SetDigest函数是用于创建和操作setdigest数据类型的一组函数。SetDigest数据类型是一种特殊的数据结构,用于存储一组唯一的元素,并支持高效的集合操作。
以下是一些常见的SetDigest函数:
- make_set_digest(value): 这个函数用于创建一个新的setdigest,其中包含给定的值。
- merge_set_digest(setDigest1, setDigest2): 这个函数用于合并两个setdigest,结果是一个包含两个输入setdigest所有元素的新setdigest。
- cardinality(setDigest): 这个函数返回给定setdigest中元素的数量。
- intersection_cardinality(setDigest1, setDigest2): 这个函数返回两个setdigest的交集的大小。
- jaccard_index(setDigest1, setDigest2): 这个函数返回两个setdigest的Jaccard指数,这是一个衡量两个集合相似度的指标,范围是0到1。
- hash_counts(setDigest): 这个函数返回一个map,其中的键是setdigest中的元素,值是各元素在setdigest中出现的次数。
使用SetDigest函数,你可以有效地处理大规模的集合数据,并进行如并集、交集等集合操作。这对于处理涉及大量唯一元素的数据分析非常有用。
Sketch Functions
在Presto中,ThetaSketches和KLLSketches是两种用于数据流分析的模型。ThetaSketches主要用于估算不重复元素的数量,KLLSketches用于分位数和排名的估算。
以下是你提到的这些函数的介绍:
ThetaSketches
- sketch_theta(): 创建一个空的Theta sketch。
- sketch_theta_estimate(sketch): 返回Theta sketch的估计元素数量。
- sketch_theta_summary(sketch): 返回Theta sketch的一些统计摘要信息,例如存储的元素数量、存储容量等。
KLLSketches
- sketch_kll(): 创建一个空的KLL sketch。
- sketch_kll_with_k(k): 创建一个带有指定参数k的KLL sketch。参数k决定了KLL sketch的准确性和内存使用情况。
- sketch_kll_quantile(sketch, probability): 返回KLL sketch在指定概率下的分位数。
- sketch_kll_rank(sketch, value): 返回指定值在KLL sketch中的排名,结果是一个介于0和1之间的浮点数。
这些函数在处理大规模数据分析时非常有用,ThetaSketches可以用于估计大数据集中的唯一元素数量,KLLSketches可以用于估算大数据集的分位数和排名。
参考链接:Presto Documentation — Presto 0.287 Documentation (prestodb.io)


