HiveSQL概述
为什么要学SQL?
- 性价比高:学习一周,受用终生。(有小学英语能力即可,相当简单,不用害怕学不会)
- 高效便捷:免去数据需求的排期与沟通,可根据自己需要及时调整取数逻辑
- 思维拓展:了解业务存储逻辑,理解状态变更或数据流转,更好的理解业务
- 发现先知:深入细节,发现新的数据维度和思考模式
什么是Hive?
Hive不是数据库。Hive是一个将结构化数据映射成数据表,将SQL翻译成MapReduce任务的工具。
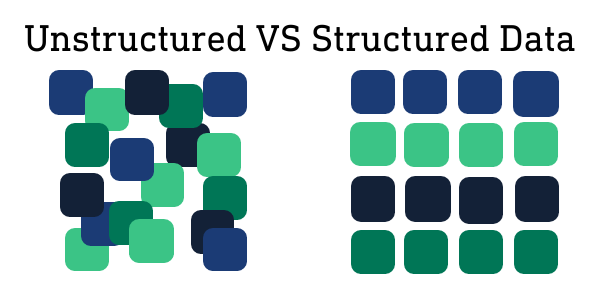
所谓的结构化数据,简单的理解就是比较规整的数据,类似将Excel文件保存为csv的数据。
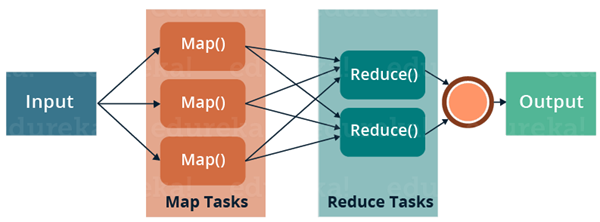
所谓的MapReduce任务,其实就是将现有的SQL转化成分布式任务,就是将一条SQL拆分到多台服务器运行,完成后在将数据合并。
什么是HiveSQL?
HiveSQL=HiveQL=HQL
- 以SQL-92标准语法为蓝本建立,查询语法与标准SQL基本一致
- 不支持行级别的增、删、改。
- 支持分析超大数据集,执行时间长。
数据库基础概念
数据库中的库、表、字段理解起来也非常的简单。我们可以这样直观的认为:
- 库=Excel文件
- 表=Excel Sheet
- 字段=Excel中列名
在日常使用Hive的过程中还会遇到一个分区(Partitions)的概念,在查询时必须制定。
分区也比较容易理解,分区的目的就是规避全表扫描,把查询限制在一定的分区范围内,类似词典中的”按字母索引”。

Hive中的常见数据类型
数据类型指的是存储的数据的格式,以下为常见的Hive数据格式:
| 类型 | 描述 | 字面量示例 |
| BOOLEAN | True/False | True |
| TINYINT | 8位有符号整型。
取值范围:-128~127。 |
1Y、-127Y |
| SMALLINT | 16位有符号整型。
取值范围:-32768~32767。 |
32767S、-100S |
| INT | 32位有符号整型。
取值范围:-2^{31}~2^{31}-1。 |
1000、-15645787 |
| BIGINT | 64位有符号整型。
取值范围:-2^{63}+1~2^{63}-1。 |
100000000000L、-1L |
| FLOAT | 32位二进制浮点型。 | 1.0 |
| DOUBLE | 64位二进制浮点型。 | 1.0 |
| DECIMAL(precision,scale) | 10进制精确数字类型。
precision:表示最多可以表示多少位的数字。取值范围:1<=precision<=38。 scale:表示小数部分的位数。取值范围:0<=scale<=38。 如果不指定以上两个参数,则默认为decimal(10,0)。 |
1.0 |
| STRING | 字符串,变长 | “abc”、”bcd” |
| VARCHAR(n) | 变长字符类型,n为长度。
取值范围:1~65535。 |
“abc”、”bcd” |
| CHAR(n) | 固定长度字符类型,n为长度。最大取值255。长度不足则会填充空格,但空格不参与比较。 | “abc”、”bcd” |
| BINARY | 二进制数据类型,目前长度限制为8MB。 | unhex(‘FA34E10293CB42848573A4E39937F479’) |
| TIMESTAMP | 与时区无关的时间戳类型。
取值范围:0000-01-01 00:00:00.000000000~9999-12-31 23:59:59.999999999,精确到纳秒。 |
‘2017-11-11 00:00:00.123456789’ |
| DATE | 日期类型,格式为yyyy-mm-dd。
取值范围:0000-01-01~9999-12-31。 |
‘2017-11-11’ |
| DATETIME | 日期时间类型。
取值范围:0000-01-01 00:00:00.000~9999-12-31 23:59:59.999,精确到毫秒。 |
‘2017-11-11 00:00:00’ |
| INTERVAL | 时间频率间隔 |
复杂数据类型:(不常用)
| 类型 | 定义方法 | 构造方法 |
| ARRAY | array<int>
array<struct<a:int,b:string>> |
array(1,2,3)
array(array(1,2),array(3,4)) |
| MAP | map<string,string>
map<smallint,array<string>> |
map(“k1″,”v1″,”k2″,”v2”)
map(1S,array(‘a’,’b’),2S,array(‘x’,’y’)) |
| STRUCT | struct<x:int,y:int>
struct<field1:bigint,field2:array<int>,field3:map<int,int>> |
named_struct(‘x’,1,’y’,2)
named_struct(‘field1′,100L,’field2′,array(1,2),’field3’,map(1,100,2,200)) |
SQL查询语法
SQL查询的核心关键字:SELECT、FROM、JOIN、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT(JOIN、GROUP BY、HAVING涉及的内容理解起来比较麻烦,后面会单独讲解)
- 通过 SELECT 指定想要查询的字段
- 查询多个字段,用逗号(,)隔开
- 查询表的所有字段,可用星号(*),非必要,不推荐使用
- 可结合 DISTINCT 关键词对字段进行去重,类似 Excel 中的删除重复项
- 可使用 as 关键词对字段设置别名,as 关键词可省略,可读性查,不推荐
- 字段别名也可以用中文,中文需要用(“)括起来。
- 可对选择的字段应用 SQL 函数,函数部分会在后面的课程中单独讲解
- 通过 FROM 指定想要查询的库与表
- 通过 WHERE 筛选查询内容
- 可使用逻辑关键词 AND、OR、NOT 来组合多个条件
- 可使用=、>、<、>=、<=、!= 和 <> 进行比较操作,!= 和 <> 都表示“不等于”
- 条件中包含字符串时,需要用单引号(”)括起来,否则会被误认为字段名或关键词
- 可使用 IN 关键词实现多项匹配,匹配项放在括号()中,用逗号(,)分隔
- 可使用 BETWEEN…AND 关键词匹配一个范围,由于各数据库边界取值逻辑不同,不推荐使用
- 可使用 LIKE 进行字符串模糊匹配,% 代表任意个字符,_ 代表一个字符
- 可使用 IS NULL/IS NOT NULL 判断字段是否缺失。注意:字段缺失和空字符串是完全不同的概念
- 通过 ORDER BY 设定结果集的排序规则
- 可以不使用 ORDER BY,查询结果可能会乱序或按数据库默认的顺序排序
- 指定排序的字段,默认按照升序(ASC)排序,即 ASC 可省略不写
- 降序排序必须显式声明,使用 DESC 关键词
- 可指定多个字段进行多重排序,中间用逗号(,)分隔
- 小技巧:抽样分析时,可使用随机排序 rand(),再限定数据量来获取。
- 通过 LIMIT 限定返回的数据条数
- 从头部的 Y 个数据:LIMIT Y
- 跳过 X 个数据,读取 Y 个数据:LIMIT Y OFFSET X;简写形式:LIMIT X,Y
学习要点:
- SQL 中的关键词顺序不能乱,比如:WHERE 必须在 GROUP BY 前面
- 查询语句中无需包含所有关键词,示例: SELECT 1;
- SQL 中的关键词不区分大小写,示例: select 1;
- SQL 语句以“;”结尾,只有 1 个语句时可省略
SQL 汇总统计
汇总统计类似 Excel 中的透视表功能,汇总统计基本流程:
- 指定要分组的列
- 使用聚集函数统计想要的结果
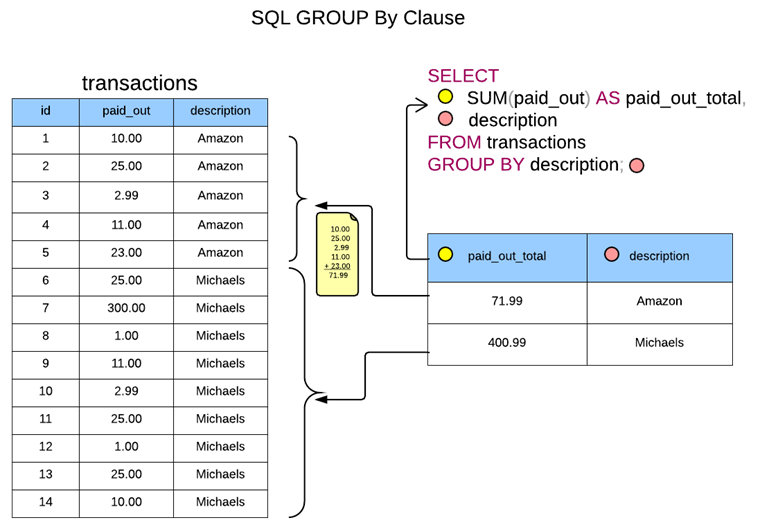
关键词:GROUP BY
- 分组关键词 GROUP BY 允许指定一个或多个字段进行分组
- 汇总统计中 GROUP BY 可不使用,即只汇总不分组
- 只有 GROUP BY 的字段才能使用 SELECT 原值取出,非 GROUP BY 的字段必须使用聚合函数
关键词:HAVING
- 和 WHERE 条件不同的是它针对的是使用 GROUP BY 以后的聚合函数的值。
- 聚合后的字段不是数据表里的真实字段。

聚集函数
聚集函数,简单的理解就是分组后用于统计的函数。常见聚集函数如下:(大小写不敏感)
| 函数名 | 描述 |
| count(1)
count(*) count(col) count(distinct col) |
count(1), count(*):统计所有的行数,包含 NULL count(col):统计不是 NULL 的行数量 count(distinct col):统计去重后非 NULL 的行数量 |
| sum(col), sum(DISTINCT col) | 求和 |
| avg(col), avg(DISTINCT col) | 求平均 |
| min(col) | 最小值 |
| max(col) | 最大值 |
| variance(col), var_pop(col) | 求方差 |
| var_samp(col) | 求无偏样本方差 |
| stddev_pop(col) | 求标准差 |
| stddev_samp(col) | 求无偏样本标准差 |
| covar_pop(col1, col2) | 返回组内两个数字列的总体协方差 |
| covar_samp(col1, col2) | 返回组内两个数字列的样本协方差 |
| corr(col1, col2) | 返回组内两个数字列的皮尔逊相关系数 |
| percentile(BIGINT col, p) | 返回组内某个列精确的第 p 位百分数,p 必须在 0 和 1 之间 |
| percentile(BIGINT col, array(p1[, p2]…)) | 返回组内某个列精确的第 p1,p2,……位百分数,p 必须在 0 和 1 之间 |
| percentile_approx(DOUBLE col, p[, B]) | 返回组内数字列近似的第 p 位百分数(包括浮点数),参数 B 控制近似的精确度,B 值越大,近似度越高,默认值为 10000。当列中非重复值的数量小于 B 时,返回精确的百分数 |
| percentile_approx(DOUBLE col, array(p1[, p2]…)[, B]) | 同上,但接受并返回百分数数组 |
| histogram_numeric(col, b) | 使用 b 个非均匀间隔的箱子计算组内数字列的柱状图(直方图),输出的数组大小为 b,double 类型的(x,y)表示直方图的中心和高度 |
| collect_set(col) | 返回消除了重复元素的数组,去重 |
| collect_list(col) | 返回允许重复元素的数组,不去重 |
| ntile(INTEGER x) | 该函数将已经排序的分区分到 x 个桶中,并为每行分配一个桶号。这可以容易的计算三分位,四分位,十分位,百分位和其它通用的概要统计 |
SQL 条件判断
- 条件判断在一般查询中也会使用,但在分组统计中用的较多。
- 由 CASE 关键词开始,END 关键词结束
- 条件语句 WHEN 和 THEN 成对出现,WHEN 后边为条件,THEN 后为最终输出的值
- 使用关键词 ELSE 作为兜底逻辑,直接给出值,可没有(没有被条件覆盖的值为 NULL)
- 在 SELECT 中使用时,最好起个别名
SQL多表连接
多表连接,类似Excel中的vlookup,用法是将不同的表格中的数据关联起来。
多表连接基础语法:
- 指定想要关联的表
- 在FROM关键词后面的为主表
- 关联的表放在主表后面,使用LEFT JOIN/INNER JOIN等指定关联方式连接
- 多张表可能存在相同的字段名,一般都会给表设置别名(AS关键词可省略),如示例中的a,b
- 指定需要关联的“键”
- 使用ON关键词声明需要关联的键
- 关键词ON后面必须是等值条件,即两表中可关联的相同字段
- 关键词ON后面可跟多个条件,中间需加AND
- 取各表字段时,加入表别名,如:pageid
- 添加过滤条件和选择想要的字段
- 关键词WHERE和SELECT的语法同一般查询语句
- 选取字段时字段名前加上表别名,如productid
- 多表SELECT时,如出现字段重复,使用AS给字段取别名
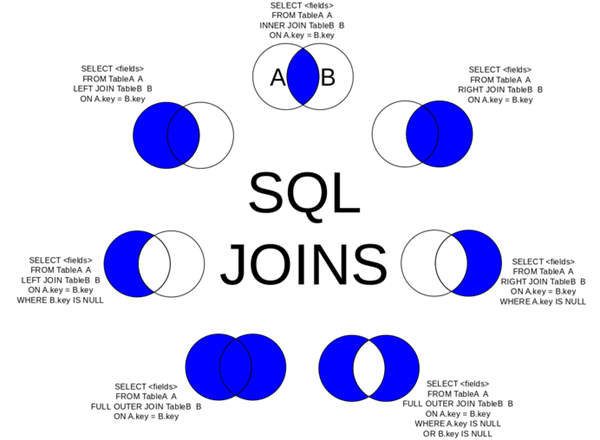
常见表连接方式:
红色为左表,蓝色为右表,灰色(包括淡灰)部分为最终结果。
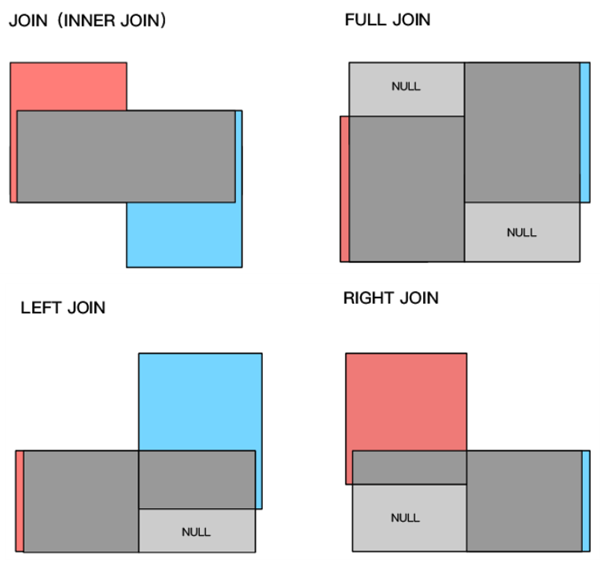
学习要点:
- 最常使用的连接类型INNER JOIN和LEFT JOIN
- 使用INNER JOIN时,INNER可以省略但不建议
数据集合:并集、交集、差集…
SQL多表合并
SQL多表合并,相当于将两个有相同列名的Excel数据合并在一起。使用的关键词词是UNION。
SQL多表连接:UNION是纵向合并,JOIN是横向拓展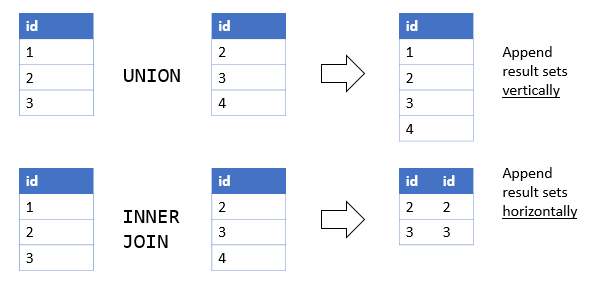
UNION与UNION ALL的区别:
UNION是去重合并(相当于Excel中的去除重复项),UNION ALL是不去重合并。
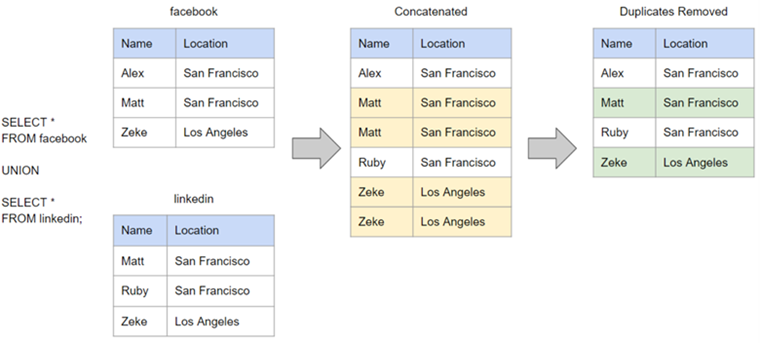
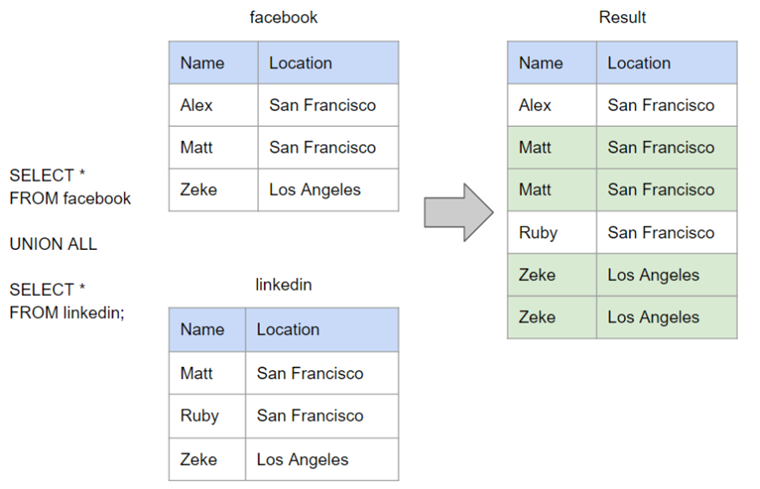
注意:多表合并的字段名要一样
SQL子查询
子查询=将查询结果视为新表
- 子查询也叫嵌套查询,即将查询结果用于新的查询语句
- 子查询必须放在圆括号内
- 子查询语句中不能使用ORDER BY,子查询括号内不能出现ORDER BY
- 子查询可出现在FROM语句后面
- 子查询同样可出现在SELECT、WHERE语句后面(标量子查询)
标量子查询=返回单一值的子查询
子查询出现在SELECT后面:
SELECT name, math, math-( SELECT avg(math) FROM students ) AS diff_math FROM students
子查询出现在WHERE后面:
SELECT name, math FROM students WHERE math>( SELECT avg(math) FROM students )
内存临时表
CTE语法相当于生成内存临时表,临时表在SQL执行时创建,SQL执行完毕后自动删除,优点:
- 提高代码可读性(结构清晰)
- 提高代码执行效率(with字句只需执行一次)
学习要点:可同时定义多个临时表,但只能用一个WITH,多个CTE中间用逗号(,)分隔。WITH t1 as(…), t2 as(…)…
实体临时表
将查询结果保存为实体表:
DROP TABLE IF EXISTS tmp_db.qw_hotel_info_1000528_20220112; CREATE TABLE tmp_db.qw_order_list_1000528_20220112 AS SELECT * FROM hotel_db.hotel_info WHERE is_vaild=1;
学习要点:
- 以上SQL示例其实是2个语句(注意分号)
- 创建实体表前需要有数据库写入权限
- 创建实体表前需要确保数据库里没有同名表,使用DROP TABLE IF EXISTS…删除可能存在的同名表
- 使用CREATE TABLE…AS…将查询结果保存为实体表
使用建议:
- 表命名使用统一的规则(个人标识_数据标识_身份ID_创建日期),方便后期管理
- 为节约服务器空间,定期清理不再使用的实体表,查询方法:SHOW TABLES FROM tmp_cvg LIKE ‘qw_*’;
SQL函数
类型转化
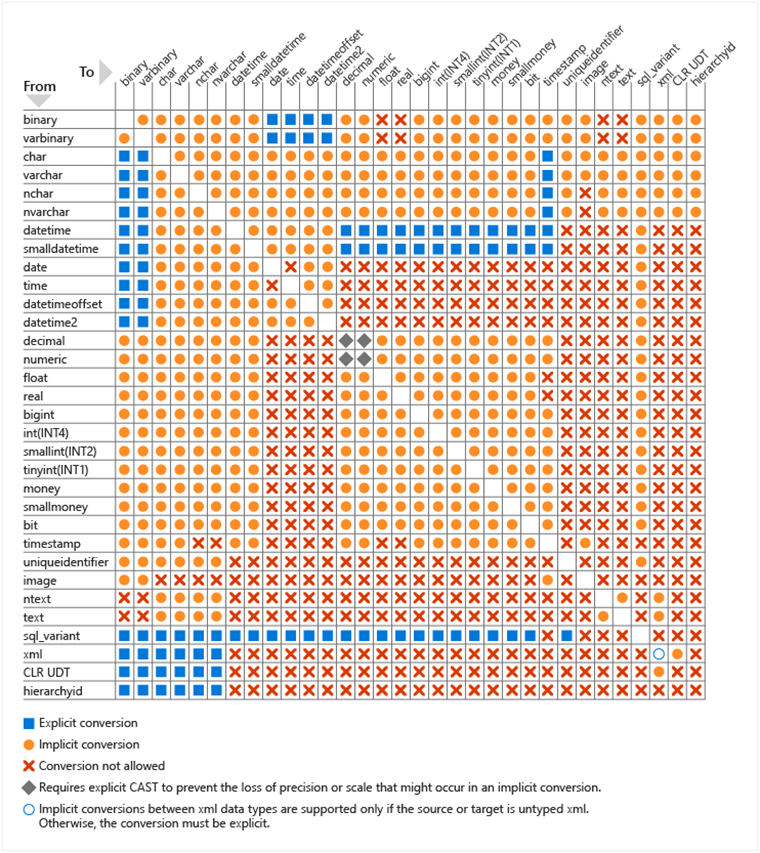
隐式转化:
- Hive在需要时会对数值型数据进行隐式转化
- 任何隐式转化都会转化成更大范围的数值
- 字符串也可以隐式转化,比如字符串转化为日期
显式转化:
- 使用CAST关键词显式的将一个类型的数据转化为另一个数据类型
- CAST的语法为CAST(value AS TYPE)
- 显式转化可以将大范围值转化为小范围数值(截取),如double转化为int
数值处理函数
| 用法 | 功能说明 |
| round(DOUBLE a) | 四舍五入到整数 |
| round(DOUBLE a, INT d) | 四舍五入到指定小数位 |
| floor(DOUBLE a) | 向下取整 |
| ceil(DOUBLE a), ceiling(DOUBLE a) | 向上取整 |
| rand(), rand(INT seed) | 生成一个0~1之间的随机数 |
字符串处理函数
| 用法 | 描述 | 字符串连接 |
| get_json_object(string json_string, string path) | JSON字符串解析 |
| length(string A) | 字符串长度 |
| regexp_extract(string subject, string pattern, int index) | 正则表达式提取 |
| regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) | 正则替换 |
| split(string str, string pat) | 字符串拆分 |
| substr(string|binary A, int start) substring(string|binary A, int start) | 字符截取 |
| substr(string|binary A, int start, int len) substring(string|binary A, int start, int len) | 字符截取 |
| trim(string A) | 去除前后空字符 |
字符串截取:
- SUBSTR()语法:substr(string A, int start, int length)
- string A:需要处理的字符串
- int start:开始截取的位置索引,注意:索引从1开始
- int length:截取的长度
JSON字符串解析:
- 第一个参数填写json对象变量,第二个参数使用$表示json变量标识
- 用.或[]读取对象或数组
- 如果输入的json字符串无效,那么返回NULL
正则表达式
正则表达式与SQL是完全独立的内容,在这里介绍的主要是在SQL处理文本时经常遇到,所以也做下介绍。
字符:
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| 一般字符 | 匹配自身 | abc | abc |
| . | 匹配除换行符”\n”外的任何字符 | a.c | abc |
| \ | 转移字符,使后一个字符改变原来的意思 | a\.c
a\\c |
a.c
a\c |
| […] | 字符集。对应的位置可以是字符集中任一字符
可以逐个给出,也可给出范围,如[abc]或[a-c] 第一个字符如果是^则表示取反,如[^abc] |
a[bcd]e | abe
ace ade |
预定义字符集:
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| \d | 数字:[0-9] | a\dc | a1c |
| \D | 非数字:[^\d] | a\Dc | abc |
| \s | 空白字符:[<空格>\t\r\n\f\v] | a\sc | a c |
| \S | 非空白字符:[^\s] | a\Sc | abc |
| \w | 单词字符:[A-Za-z0-9_] | a\wc | abc |
| \W | 非单词字符:[^\w] | a\Wc | a c |
备注:HIVE SQL中所有\需要使用\\替换,如\d→\\d数量词(用在字符或(…)之后):
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| * | 匹配前一个字符0或无限次 | abc* | ab
abcc |
| + | 匹配前一个字符1或无限次 | abc+ | abc
abcc |
| ? | 匹配前一个字符0次或1次 | abc? | ab
abc |
| {m} | 匹配前一个字符m次 | ab{2}c | abbc |
| {m,n} | 匹配前一个字符m至n次,可省略m或n | ab{1,2}c | abc
abbc |
开发结尾:
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| ^ | 匹配字符串开头 | ^abc | abc |
| $ | 匹配字符串末尾 | abc$ | abc |
SQL时间函数
常见时间格式
| 类型 | 说明 | 示例 |
| Unix时间戳 | 10位,单位为秒
13位,单位为微秒 |
1605191559
1605191559123 |
| DATE类型 | 日期 | 2020-11-12 |
| DATETIME类型 | 日期+时间 | 2020-11-12 22:39:08 |
| STRING字符串 | 2020-11-12、2020/11/12、20201112
2020-11-12 22:39:08 |
|
| INT整数 | 数值型 | 20201112 |
时间处理函数
获取当前时间:
| 函数 | 返回内容 | 示例 |
| UNIX_TIMESTAMP() | 当前时间的时间戳,单位秒 | 1605194959 | CURRENT_TIMESTAMP() | 当前 DATETIME 类型时间 | 2020-11-12 23:18:51 |
| CURRENT_DATE
CURRENT_DATE() |
获取当前日期 | 2020-11-12 00:00:00 |
日期/时间格式化
时间格式转化方法:
| 需求 | 方法 |
| 将 Unix 时间戳转化为 DATETIME 类型时间 | from_unixtime(unix_timestamp(), ‘yyyy-MM-dd HH:mm:ss’)
from_unixtime(CAST(microsecond/1000 AS INT), ‘yyyy-MM-dd’) |
| 将 DATETIME 类型时间转化为 Unix 时间戳 | unix_timestamp(‘2020-11-12 22:39:08’, ‘yyyy-MM-dd HH:mm:ss’) |
| 将 DATETIME 类型时间转为 DATE 类型的日期 | TO_DATE(‘2020-11-12 22:39:08’) |
| 将字符创类型时间转化为 DATE 类型 | CAST(date_string as DATE) |
常用格式化符号:
| 符号 | 含义 | 示例 |
| d | 一月中的某一天(1-31) | 1、20 |
| dd | 一月中的某一天(01-31) | 01、31 |
| D | 一年中的某一天(1-366) | 3、80、100 |
| DD | 一年中的某一天(01-366) | 03、80、366 |
| DDD | 一年中的某一天(001-366) | 003 |
| e | 一周中的某一天(1-7) | 2 |
| h | 用 AM 或 PM 表示的小时(1-12) | 6 |
| hh | 用 AM 或 PM 表示的小时(01-12) | 06 |
| H | 24 小时格式的时间(0-23) | 7 |
| HH | 24 小时格式的时间(00-23) | 07 |
| m | 分 | 4 |
| mm | 分 | 04 |
| M | 月(数值) | 5、12 |
| MM | 月(数值) | 05、12 |
| s | 秒 | 5 |
| ss | 秒 | 05 |
| S | 分秒 | 7 |
| SS | 厘秒 | 70 |
| w | 一年中的某一周 | 7、53 |
| ww | 一年中的某一周 | 07、53 |
| W | 一月中的某一周 | 2 |
| yy | 年 | 06 |
| yyyy | 年 | 2006 |
日期/时间提取
| 函数 | 返回内容 | 示例 |
| YEAR(‘2020-11-12 22:39:08’) | 获取日期中的年份 | 2020 |
| MONTH(‘2020-11-12 22:39:08’) | 获取日期中的月份 | 11 |
| DAY(‘2020-11-12 22:39:08’) | 获取月份中的天数 | 12 |
| DAYOFMONTH(‘2020-11-12 22:39:08’) | 获取月份中的天数 | 12 |
| HOUR(‘2020-11-12 22:39:08’) | 获取小时数 | 22 |
| MINUTE(‘2020-11-12 22:39:08’) | 获取分钟数 | 39 |
| SECOND(‘2020-11-12 22:39:08’) | 获取秒数 | 8 |
| WEEKOFYEAR(‘2020-11-12 22:39:08’) | 获取日期属于第几周 | 46 |
日期/时间计算
| 函数 | 返回内容 | 示例 |
| DATEDIFF(‘2020-11-12’, ‘2020-01-01’) | 计算两个日期的天数差 | 316 |
| DATE_ADD(‘2020-11-12’, 5) | 日期+天数,可传负数 | 2020-11-17 |
| DATE_SUB(‘2020-11-12’, 5) | 日期-天数,可传负数 | 2020-11-07 |
| ADD_MONTHS(‘2020-11-12’, 2) | 日期+月数,可传负数 | 2021-01-12 |
SQL 窗口函数
什么是窗口函数(Window Function)?
不同于普通函数和聚合函数,它为每行数据进行一次计算:输入多行(一个窗口)、返回一个值。
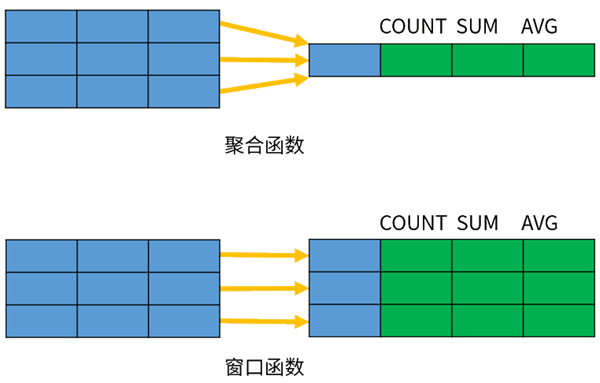 窗口函数出现在SELECT子句的表达式列表中,它最显著的特点就是OVER关键字。
窗口函数出现在SELECT子句的表达式列表中,它最显著的特点就是OVER关键字。
语法:
window_function(expression) OVER(
[PARTITION BY part_list]
[ORDER BY order_list]
[{ROWS | RANGE} BETWEEN frame_start AND frame_end])
作用:同时具有分组和排序的功能,且不减少原表的行数常用窗口函数
| 函数 | 说明 |
| COUNT() | 计数 |
| AVG() | 求平均值 |
| MAX() | 取最大值 |
| MIN() | 取最大值 |
| MEDIAN() | 取中位数 |
| STDDEV() | 计算标准差 |
| STDDEV_SAMP() | 计算样本标准差 |
| SUM() | 求汇总值 |
| CUME_DIST() | 计算累计分布 |
| ROW_NUMBER() | 计算行号 |
| DENSE_RANK() | 计算连续排名 |
| RANK() | 计算跳跃排名 |
| PERCENT_RANK() | 计算一组数据中某行的相对排名 |
| LAG() | 按偏移量取当前行之前第几行的值 |
| LEAD() | 按偏移量取当前行之后第几行的值 |
| CLUSTER_SAMPLE() | 用于分组抽样 |
| NTILE() | 将分组数据按照顺序切片并返回切片值 |


