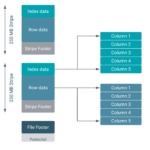
Apache Parquet 简介 Apache Parquet 是一种列式存储格式,专为高效处理大规模数据而设计。它最初由 Twitter 和 Cloudera 开发,现在是 Apache 软件基金会的顶级项目。Parquet 的设计目标是优化存储效率和查询性能…
Apache Hive 是一个开源的数据仓库框架,用于查询和分析大数据集存储在 Hadoop 文件系统中。 Hive 提供了一种类 SQL 的查询语言,叫做 HiveQL,它使得熟悉 SQL 的用户可以在 Hive 上查询、汇总和分析数据。同时,…
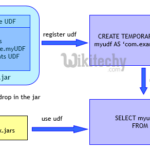
Hive内置了很多函数,可以参考Hive Built-In Functions。但是有些情况下,这些内置函数还是不能满足我们的需求,这时候就需要UDF出场了。 UDF全称:User-Defined Functions,即用户自定义函数,在Hive SQL编译成Ma…
HiveSQL概述 为什么要学SQL? 性价比高:学习一周,受用终生。(有小学英语能力即可,相当简单,不用害怕学不会) 高效便捷:免去数据需求的排期与沟通,可根据自己需要及时调整取数逻辑 思维拓展:了解业务存…

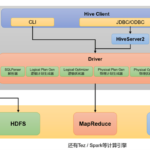
Hive简介 Hive由Facebook实现并开源,是基于Hadoop的一个数据仓库工具。可以将结构化的数据映射为一张数据库表并提供HQL(Hive SQL)查询功能。底层数据是存储在HDFS上,Hive的本质是将SQL语句转换为MapReduce任务运…

公司的数据存放在 HDFS 上,但是模型的训练时需要用到这部分数据,于是就有了数据同步的需求。以下是个人整理的数据同步流程,仅适用于公司内部,其他地方由于环境不同可能不可用。 数据从 Hive 同步到 JupyterLa…

在数据统计分析中,经常会遇到需要对时间进行格式转化或其他层面的内容。由于每种数据库自带的相关函数存在一定的差异,所以经常会记不得如何使用。今天做下简单的梳理。 在开始学习日期/时间函数先,先来了解下…

HiveSQL中的datediff函数返回的是2个日期的间隔天数。在使用过程中发现了一个比较有趣的坑: SELECT customer_id, COUNT(DISTINCT date(createdate))-1 AS frequency , datediff(MAX(createdate), MIN(createdate))…

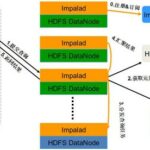
Impala是 Cloudera 公司主导开发的新型查询系统,它提供 SQL 语义,能查询存储在 Hadoop 的 HDFS 和 HBase 中的 PB 级大数据。已有的 Hive 系统虽然也提供了 SQL 语义,但由于 Hive 底层执行使用的是 MapReduce 引…