Hive简介
Hive由Facebook实现并开源,是基于Hadoop的一个数据仓库工具。可以将结构化的数据映射为一张数据库表并提供HQL(Hive SQL)查询功能。底层数据是存储在HDFS上,Hive的本质是将SQL语句转换为MapReduce任务运行,使不熟悉MapReduce的用户很方便地利用HQL处理和计算HDFS上的结构化的数据,适用于离线的批量数据计算。

Hive与普通关系型数据库的区别:
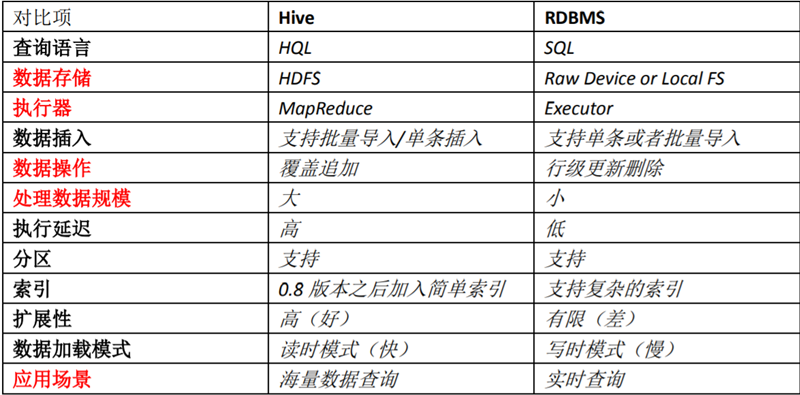
- 查询语言。Hive提供了类SQL的查询语言HQL,熟悉SQL的开发者可直接使用。
- 数据存储位置。Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
- 数据格式。Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、\t、\x001)、行分隔符(\n)以及读取文件数据的方法(Hive中默认有三个文件格式TextFile,SequenceFile以及RCFile)。由于在加载数据的过程中,不需要从用户数据格式到Hive定义的数据格式的转换,因此,Hive在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的HDFS目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
- 数据更新。由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用INSERT INTO…VALUES 添加数据,使用UPDATE…SET修改数据。
- 索引。Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于MapReduce的引入,Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了Hive不适合在线数据查询。
- 执行。Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现的。而数据库通常有自己的执行引擎。
- 执行延迟。Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive执行延迟高的因素是MapReduce框架。由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
- 可扩展性。由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的。而数据库由于ACID语义的严格限制,扩展行非常有限。目前最先进的并行数据库Oracle在理论上的扩展能力也只有100台左右。
- 数据规模。由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的数据库可以支持的数据规模较小。
需明确的是,Hive作为数仓应用工具,对比RDBMS(关系型数据库)有3个”不能”:
- 不能像RDBMS一般实时响应,Hive查询延时大
- 不能像RDBMS做事务型查询,Hive没有事务机制
- 不能像RDBMS做行级别的变更操作(包括插入、更新、删除)
另外,Hive相比RDBMS是一个更”宽松”的世界,比如:
- Hive没有定长的varchar这种类型,字符串都是string
- Hive是读时模式,它在保存表数据时不会对数据进行校验,而是在读数据时校验不符合格式的数据设置为NULL
Hive的架构
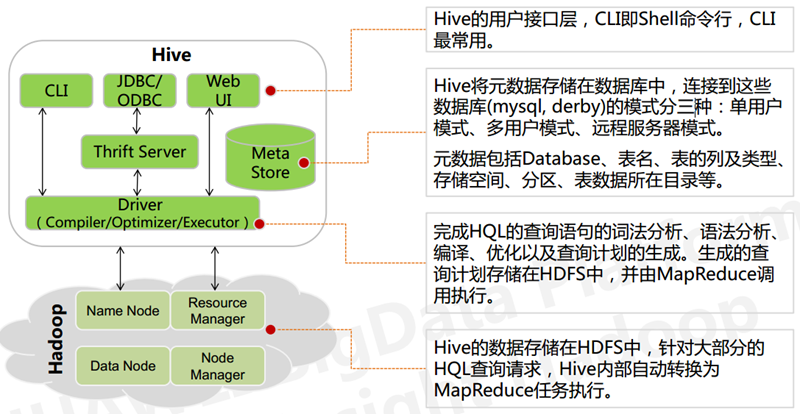
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件可以分为两大类:
- 服务端组件:
- Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
- Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性,这个方面的知识,我会在后面的metastore小节里做详细的讲解。
- Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
- 客户端组件:
- CLI:command line interface,命令行接口。
- Thrift客户端:上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
- WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
Hive数据存储
Hive的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对应HDFS上的一个目录。表数据对应HDFS对应目录下的文件。Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式,因为Hive是读模式(Schema On Read),可支持TextFile,SequenceFile,RCFile或者自定义格式等。
Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。其次,Hive中所有的数据都存储在HDFS中,Hive中包含以下数据模型:Table,External Table,Partition,Bucket。
- Hive中的Table和数据库中的Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录存储数据。例如,一个表pvs,它在HDFS中的路径为:/wh/pvs,其中,wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。
- Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020
- ExternalTable 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
- Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中,之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
- ExternalTable 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 ExternalTable 时,仅删除。
Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds=20090801, ctry=US 的 HDFS 子目录为:/wh/pvs/ds=20090801/ctry=US;对应于 ds=20090801, ctry=CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/ctry=CA
Hive 元数据存储
Hive 的 metastore 组件是 hive 元数据集中存放地。Metastore 组件包括两个部分:metastore 服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如 hive 默认的嵌入式磁盘数据库 derby,还有 mysql 数据库。Metastore 服务是建立在后台数据存储介质之上,并且可以和 hive 服务进行交互的服务组件,默认情况下,metastore 服务和 hive 服务是安装在一起的,运行在同一个进程当中。我也可以把 metastore 服务从 hive 服务里剥离出来,metastore 独立安装在一个集群里,hive 远程调用 metastore 服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问 hive 服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的 metastore 服务,可以让 metastore 服务和 hive 服务运行在不同的进程里,这样也保证了 hive 的稳定性,提升了 hive 服务的效率。
Hive 将元数据存储在 RDBMS 中,有三种模式可以连接到数据库:
- Single User Mode:此模式连接到一个 In-memory 的数据库 Derby,一般用于 Unit Test。
- Multi User Mode:通过网络连接到一个数据库中,是最经常使用到的模式。
- Remote Server Mode:用于非 Java 客户端访问元数据库,在服务器端启动一个 MetaStoreServer,客户端利用 Thrift 协议通过 MetaStoreServer 访问元数据库。
Hive 字段类型
| 分类 | 类型 | 描述 | 字面量示例 |
| 原始类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1 字节的有符号整数 -128~127 | 1Y | |
| SMALLINT | 2 个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4 个字节的带符号整数 | 1 | |
| BIGINT | 8 个字节的带符号整数 | 1L | |
| FLOAT | 4 字节单精度浮点数 | 1.0 | |
| DOUBLE | 8 字节单精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,变长 | abc | |
| VARCHAR | 变长字符串 | abc | |
| CHAR | 固定长度字符串 | abc | |
| BINARY | 字节数组 | 无法表示 | |
| TIMESTAMP | 时间戳,毫秒精度 | 1642123232761 | |
| DATE | 日期 | 2022-01-14 | |
| INTERVAL | 时间频率间隔 | ||
| 复杂类型 | ARRAY | 有序的的同类型的集合 | array(1,2) |
| MAP | key-value, key 必须为原始类型,value 可以任意类型 | map(‘a’,1,’b’,2) | |
| STRUCT | 字段集合, 类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
decimal 用法:用法:decimal(11,2) 代表最多有 11 位数字,其中后 2 位是小数,整数部分是 9 位;如果整数部分超过 9 位,则这个字段就会变成 null;如果小数部分不足 2 位,则后面用 0 补齐两位,如果小数部分超过两位,则超出部分四舍五入。也可直接写 decimal,后面不指定位数,默认是 decimal(10,0) 整数 10 位,没有小数
HiveSQL 简介
Hive 查询语句
Hive Select 常规语法与 Mysql 等 RDBMS SQL 几乎无异,下面附注语法格式,具体不做详细讲解。
SELECT 语法及语序
SELECT [ALL|DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY order_condition] [DISTRIBUTE BY distribute_condition [SORT BY sort_condition]] [LIMIT number]
多维度聚合分析 grouping sets/cube/roolup
不使用多维聚合方法:
SELECT NULL, NULL, NULL, COUNT(*) FROM requests UNION ALL SELECT os, device, NULL, COUNT(*) FROM requests GROUP BY os, device UNION ALL SELECT null, null, city, COUNT(*) FROM requests GROUP BY city;
使用 grouping sets:
SELECT os, device, city, COUNT(*) FROM requests GROUP BY os, device, city GROUPING SETS ((os, device), (city), ());
cube 会枚举指定列的所有可能组合作为 grouping sets,而 rollup 会以按层级聚合的方式产生 grouping sets。如:
GROUP BY CUBE(a, b, c) --等价于以下语句。 GROUPING SETS ((a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), ()) GROUP BY ROLLUP(a, b, c) --等价于以下语句。 GROUPING SETS ((a, b, c), (a, b), (a), ())
正则方法指定 SELECT 字段列
说是指定,其实是排除,如:`(num|uid)?+.+` 排除 num 和 uid 字段列。另外,where 使用正则可以如此:where A Rlike B、where A Regexp B。
Lateral View(一行变多行)
Lateral View 和表生成函数(例如 Split、Explode 等函数)结合使用,它能够将一行数据拆成多行数据,并对拆分后的数据进行聚合。
假设您有一张表 pageAds,它有两列数据,第一列是 pageid string,第二列是 adid_list,即用逗号分隔的广告 ID 集合。现需要统计所有广告在所有页面的出现次数,则先用 Lateral View + explode 做处理,即可正常分组聚合统计:
SELECT pageid, adid FROM pageAds LATERAL VIEW explode(adid_list) adTable AS adid;
窗口函数
Hive 的窗口函数非常丰富,其中最常用的窗口函数当属 row_number() over(partition by col order by col_2),它可以实现按指定字段的分组排序。
- COUNT 计算计数值。
- AVG 计算平均值。
- MAX 计算最大值。
- MIN 计算最小值。
- MEDIAN 计算中位数。
- STDDEV 计算总体标准差。
- STDDEV_SAMP 计算样本标准差。
- SUM 计算汇总值。
- DENSE_RANK 计算连续排名。
- RANK 计算跳跃排名。
- LAG 按偏移量取当前行之前第几行的值。
- LEAD 按偏移量取当前行之后第几行的值。
- PERCENT_RANK 计算一组数据中某行的相对排名。
- ROW_NUMBER 计算行号。
- CLUSTER_SAMPLE 用于分组抽样。
- CUME_DIST 计算累计分布。
- NTILE 将分组数据按照顺序切片,并返回切片值。
Hive 定义变量
SET aa='10';
SELECT ${hiveconf:aa};
SET hivevar:aa='10';
SELECT ${hivevar:aa};
SET hiveconf:aa='10';
SELECT ${hiveconf:aa};
CTE 语法和定义变量
with t1 as ( select user_id from user where ... ) @var := select shop_id from shop where ...; select * from user_shop where user_id in (select * from t1) and shop_id in (select * from @var);
Hive 定义语句
Hive 建表语句格式
方法一:独立声明
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [DEFAULT value] [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC|DESC] [, col_name [ASC|DESC]...])] INTO number_of_buckets BUCKETS] [STORED BY StorageHandler] -- 仅限外部表 [WITH SERDEPROPERTIES (Options)] -- 仅限外部表 [LOCATION OSSLocation]; -- 仅限外部表 [LIFECYCLE days] [AS select_statement]
方法二:从已有表直接复制
CREATE TABLE [IF NOT EXISTS] table_name LIKE existing_table_name
下面对当中关键的声明语句做解释:
- [EXTERNAL]:声明为外部表,往往在该表需要被多个工具共享时声明,外部表删表不会删数据,只会删元数据。
- col_name data_type:data_type 一定要严谨定义,避免 bigint、double 等等统统用 string 的偷懒做法,否则不知某天数据就出错了。(团队内曾有同事犯过此错误)
- [if not exists]:创建时不指定,若存在同名表则返回出错。指定此选项,若存在同名表忽略后续,不存在则创建。
- [DEFAULT value]:指定列的默认值,当 INSERT 操作不指定该列时,该列写入默认值。
- [PARTITIONED BY]:指定表的分区字段,当利用分区字段对表进行分区时,新增分区、更新分区内数据和读取分区数据均不需做全表扫描,可以提高处理效率。
- [LIFECYCLE]:是表的生命周期,分区表则每个分区的生命周期与表生命周期相同
- [AS select_statement]:意味着可直接跟 select 语句插入数据
简单示例:创建表 sale_detail 来保存销售记录,该表使用销售时间 sale_date 和销售区域 region 作为分区列。
create table if not exists sale_detail ( shop_name string, customer_id string, total_price double ) partitioned by (sale_date string, region string);
创建成功的表可以通过 desc 查看定义信息:
desc <table_name>; desc extended <table_name>; -- 查看外部表信息。
如果需要不记得完整的表名,可以通过 show tables 在 db(数据库)范围内查找:
use db_name;
show tables('tb.*'); --- tb.* 为正则表达式
Hive 删表语句格式
DROP TABLE [IF EXISTS] table_name; --- 删除表 ALTER TABLE table_name DROP [IF EXISTS] PARTITION (partition_col1=partition_col_value1,...); --- 删除某分区
Hive 变更表定义语句格式
ALTER TABLE table_name RENAME TO table_name_new; --- 重命名表 ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION (partition_col1=partition_col_value1...); --- 增加分区 ALTER TABLE table_name ADD COLUMNS (col_name1 type1 comment 'XXX'); --- 增加列,同时定义类型与注释 ALTER TABLE table_name CHANGE COLUMN old_col_name new_col_name column_type COMMENT column_comment; --- 修改列名和注释 ALTER TABLE table_name SET lifecycle days; --- 修改生命周期
Hive 操作语句
Hive insert 语句格式:
INSERT OVERWRITE | INTO TABLE tablename [PARTITION (partcol1=val1...] select_statement FROM from_statement;
下面对当中关键的声明语句做解释:
- into | overwrite:into – 直接向表或表的分区中追加数据;overwrite – 先清空表中的原有数据,再向表或分区中插入数据。
- [PARTITION (partcol1=val1…]:不允许使用函数等表达式,只能是常量。
关于 PARTITION 这里展开说明指定分区插入和动态分区插入
- 输出到指定分区:在 INSERT 语句中直接指定分区值,将数据插入指定的分区。
- 输出到动态分区:在 INSERT 语句中不直接指定分区值,只指定分区列名。分区列的值在 SELECT 子句中提供,系统自动根据分区字段的值将数据插入到相应分区。
HIVE SQL 优化
列裁剪
例如某表有 a,b,c,d,e 五个字段,但是我们只需要 a 和 b,那么请用 select a,b from table 而不是 select * from table分区裁剪
在查询的过程中减少不必要的分区,即尽量指定分区小表放前大表放后
在编写带有 join 的代码语句时,应该将条目少的表/子查询放在 join 操作符的前面
因为在 Reduce 阶段,位于 join 操作符左边的表会先被加载到内存,载入条目较少的表可以有效的防止内存溢出(OOM)。所以对于同一个 key 来说,对应的 value 值小的放前面,大的放后面尽量避免使用 distinct
尽量避免使用 distinct 进行重排,特别是大表,容易产生数据倾斜(key 一样在一个 reduce 处理)。使用 group by 替代:
select distinct key from a select key from a group by key
参考链接:


