文章内容如有错误或排版问题,请提交反馈,非常感谢!
Kyuubi简介
Kyuubi是一个开源的多租户、大规模数据分析引擎服务,基于Apache Spark构建,旨在提供高效、易用和安全的SQL-on-Spark解决方案。它的设计目标是通过提供一个统一的接口来简化大数据分析的使用,使用户能够通过标准的SQL进行数据处理,而不必深入了解Spark的复杂性。
核心理念
- 高效性: Kyuubi通过优化Spark SQL的执行,提供高性能的查询能力,适合处理大规模数据集。
- 易用性: 提供类似数据库的SQL接口,使用户可以通过熟悉的SQL语法进行数据分析,而无需编写复杂的Spark作业。
- 多租户支持: 设计支持多租户场景,能够为不同用户和应用提供隔离的资源和安全控制。
- 安全性: 提供完善的身份认证和权限管理,确保数据访问的安全性。
主要特性
- 即插即用: Kyuubi提供即插即用的安装和配置,用户可以快速启动并运行,无需复杂的设置。
- 会话管理: 提供持久化的会话管理,支持长时间运行的查询和作业。
- 动态资源分配: 通过与Spark的集成,支持动态资源分配和自动扩展,优化资源利用率。
- 审计和监控: 提供详细的查询审计和监控功能,帮助用户跟踪和分析查询性能和资源使用情况。
- 高可用性: 设计支持高可用性部署,确保服务的稳定性和可靠性。
Kyuubi SQL Gateway
Kyuubi SQL Gateway是Kyuubi项目中的一个重要组件,旨在为用户提供一个统一的入口,简化与Apache Spark的交互。它通过标准的SQL接口,使用户能够在不直接处理Spark的复杂性的情况下,轻松执行分布式数据分析任务。

主要功能
- 统一接口: 提供标准的JDBC和ODBC接口,使用户可以通过常见的数据库客户端工具访问和查询数据。
- 会话管理: 管理用户的会话生命周期,包括会话的创建、维护和销毁,支持长时间运行的查询。
- 多租户支持: 为不同用户和应用提供资源隔离,确保各自操作的独立性和安全性。
- 高可用性: 支持高可用部署,确保服务的稳定性和连续性,即使在部分节点故障的情况下,也能继续处理请求。
- 安全性: 提供身份认证和权限管理,确保数据访问的安全性,防止未经授权的访问。
- 查询优化和执行: 通过与Spark的深度集成,利用Spark SQL的优化器和执行引擎,提升查询性能。
- 审计和监控: 提供详细的查询审计日志和监控功能,帮助用户跟踪查询历史和系统性能。
工作原理
- 客户端连接: 用户通过JDBC/ODBC客户端连接到Kyuubi SQL Gateway,建立会话。
- SQL请求处理: Kyuubi SQL Gateway接收SQL查询请求,解析和优化查询计划,然后将其提交给底层的Spark引擎执行。
- 查询执行: Spark SQL引擎在集群中执行查询,利用分布式计算能力处理大规模数据集。
- 结果返回: 查询结果通过Kyuubi SQL Gateway返回给客户端,用户可以在本地进行进一步分析和处理。
使用场景
- 大规模数据分析: 适合需要处理和分析大规模数据集的企业和组织,通过SQL接口简化复杂的数据分析任务。
- 商业智能和报表生成: 与BI工具集成,为企业提供实时数据分析和报表生成能力。
- 多租户环境: 在云环境中,为不同用户和应用提供隔离的分析服务,确保资源的有效利用和安全性。
优势
- 易用性: 用户可以通过熟悉的SQL语法和标准数据库工具进行大数据分析,无需深入了解Spark的内部机制。
- 高性能: 通过优化查询执行路径和资源管理,提供高性能的查询能力,适合交互式分析场景。
- 灵活性: 支持动态资源分配和扩展,能够适应不同的负载需求和使用场景。
Kyuubi SQL Gateway通过提供一个统一的SQL-on-Spark接口,简化了大数据分析的复杂性,使用户能够专注于数据本身,而无需处理底层计算引擎的复杂性。其高性能、多租户支持和安全性使其成为企业在大规模数据分析和商业智能领域的理想选择。
Kyuubi的架构
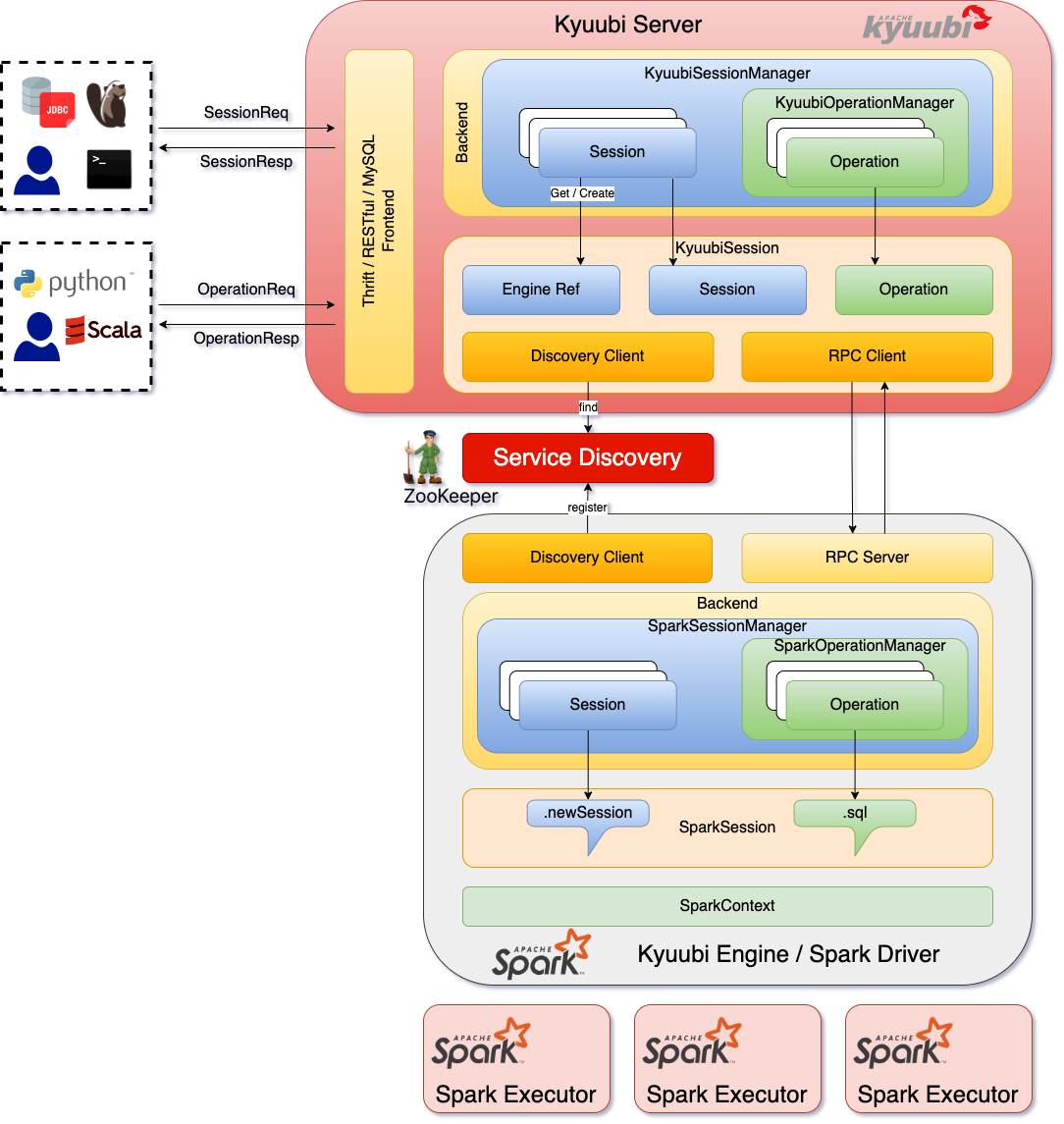
Kyuubi的架构设计旨在为用户提供一个高效、易用的SQL-on-Spark服务,支持多租户、大规模数据分析。以下是Kyuubi的核心架构组件及其功能:
Kyuubi Server
- 功能: Kyuubi Server是整个架构的核心组件,负责接收来自客户端的SQL请求、管理会话、协调查询执行和返回结果。
- 会话管理: 管理用户会话,包括会话的创建、维护和销毁。每个用户会话可以独立运行,确保资源隔离。
- 请求处理: 解析和优化SQL请求,将其转换为Spark作业,并调度到Spark SQL引擎执行。
Spark SQL引擎
- 功能: 作为底层执行引擎,负责实际的数据处理和查询执行。Kyuubi利用Spark的分布式计算能力来执行复杂的SQL查询。
- 资源管理: 通过与Spark的集成,实现动态资源分配和自动扩展,优化计算资源的使用。
- 优化执行: 利用Spark的Catalyst优化器和Tungsten执行引擎,提高查询执行效率。
多租户管理
- 功能: 支持多租户环境,为不同用户和应用提供资源隔离和安全控制。
- 资源隔离: 通过独立的Spark会话为每个用户分配资源,确保不同用户之间的操作互不影响。
- 安全控制: 提供身份认证和权限管理,确保数据访问的安全性。
客户端接口
- 功能: 提供多种客户端连接方式,如JDBC和ODBC,使用户可以通过常见的数据库工具和BI软件连接到Kyuubi。
- 兼容性: 支持标准的SQL语法和协议,用户可以通过熟悉的SQL接口进行数据查询和分析。
运行流程
- 连接与会话创建: 客户端通过JDBC/ODBC连接到Kyuubi Server,创建一个新的会话。
- SQL请求处理: 客户端发送SQL查询,Kyuubi Server解析请求,并将其转发给Spark SQL引擎。
- 查询执行: Spark SQL引擎根据优化后的执行计划,分布式地执行查询。
- 结果返回: 执行完成后,结果通过Kyuubi Server返回给客户端。
特性支持
- 高可用性: Kyuubi支持高可用部署,确保服务的连续性和稳定性。
- 审计与监控: 提供详细的查询审计和系统监控功能,帮助用户跟踪和优化查询性能。
- 动态扩展: 通过与Spark集成,实现计算资源的动态扩展,适应不同的负载需求。
Kyuubi的架构设计充分利用了Spark的强大计算能力,通过提供一个统一的SQL接口和多租户管理,简化了大数据分析的使用。其高效的查询执行、资源隔离和安全控制使其成为大规模数据分析的理想解决方案。对于需要在大规模数据集上执行复杂分析和查询的组织,Kyuubi提供了一种高效、灵活和安全的途径。
参考链接:


