针对 Facebook Prophet 的使用,很多年以前就整理过一篇文章《Facebook 时间序列预测工具 fbprophet》,过了 N 年以后当重新需要使用这个工具的时候,发现部分内容已经更新,中间的很多细节内容都没有表述清楚。实际使用时还是有很多需要注意的内容。
为什么选择 Facebook Prophet?
传统时序建模:ARIMA
- 优点:思路清晰,方案成熟
- 缺点:数据预处理繁琐,操作繁琐,超参数确定
深度学习模型:LSTM
- 优点:深度模型可以加入更多的特征
- 缺点:需要必要的特征处理,需要更多的数据,训练时间比较久
Facebook Prophet
- 类似 STL 分解思路,比较容易理解
- 使用比较方便简单,方便控制
- 在可解释性上比传统时序模型更有优势
Facebook Prophet 的新版本
在历史的版本中,Facebook Prophet 的安装非常的麻烦,特别是在 Windows 系统上可能发生错误。主要原因是 fbprophet 基于 pystan,pystan 基于 cython。问题会卡在 pystan 的安装上。
但 prophet 包从 v1.0 开始从 fbprophet 调整为 prophet。使用搜索引擎找到的资料大部分还是介绍老版本 prophet 的使用,这给很多想要尝试的用户带来了极大的门槛。
在 v1.1 之前,pip install prophet 实际上在最终用户的计算机上启动了构建过程,这需要 PyStan(Stan 是用于适应底层模型的概率编程语言)和兼容的 C++ 工具链。这导致了对先决条件的很多混乱,并且错误消息因机器而异,因此很难调试。在此问题的基础上,prophet
将后端从 PyStan 更换为 CmdStanPy,这是核心 Stan 库(称为 CmdStan)的轻量级 Python 接口。一旦构建完成,Stan 可执行文件就可以按原样使用,只要有一个名为 TBB 的链接库。
在此基础上,当前安装 Prophet 的流程非常的简单,且已经没有特定 Python 版本的要求:
# 在 Anaconda 环境下的安装 conda install -c conda-forge prophet # 在 Python 3.7+ 环境下的安装 pip install prophet
新版本其他方面的一些修正:
- 引入了 holidays 包。覆盖了很多国家与区域。(实际上没什么用,后面会详细讲解)
- 在交叉验证和不确定性估计过程中正确处理额外的回归量。生成预测时,额外的回归量当前被假定为已知量,这对于假期指标有效,但不适用于需要估计的量。
- 修补正值时间序列的负预测。
Prophet 超参数优化
Prophet 的核心是调参,步骤如下:
- 首先我们去除数据中的异常点(outlier),直接赋值为 none 就可以,因为 Prophet 的设计中可以通过插值处理缺失值,但是对异常值比较敏感。
- 选择趋势模型,默认使用分段线性的趋势,但是如果认为模型的趋势是按照 log 函数方式增长的,可设置 growth=’logistic’从而使用分段 log 的增长方式
- 设置趋势转折点(changepoint),如果我们知道时间序列的趋势会在某些位置发现转变,可以进行人工设置,比如某一天有新产品上线会影响我们的走势,我们可以将这个时刻设置为转折点。如果自己不设置,算法会自己总结 changepoint。
- 设置周期性,模型默认是带有年和星期以及天的周期性,其他月、小时的周期性需要自己根据数据的特征进行设置,或者设置将年和星期等周期关闭。设置节假日特征,如果我们的数据存在节假日的突增或者突降,我们可以设置 holiday 参数来进行调节,可以设置不同的 holiday,例如五一一种,国庆一种,影响大小不一样,时间段也不一样。
- 此时可以简单的进行作图观察,然后可以根据经验继续调节上述模型参数,同时根据模型是否过拟合以及对什么成分过拟合,我们可以对应调节 seasonality_prior_scale、holidays_prior_scale、changepoint_prior_scale 参数。
class Prophet(object): """Prophet forecaster. Parameters ---------- growth: String 'linear', 'logistic' or 'flat' to specify a linear, logistic or flat trend. changepoints: List of dates at which to include potential changepoints. If not specified, potential changepoints are selected automatically. n_changepoints: Number of potential changepoints to include. Not used if input `changepoints` is supplied. If `changepoints` is not supplied, then n_changepoints potential changepoints are selected uniformly from the first `changepoint_range` proportion of the history. changepoint_range: Proportion of history in which trend changepoints will be estimated. Defaults to 0.8 for the first 80%. Not used if `changepoints` is specified. yearly_seasonality: Fit yearly seasonality. Can be 'auto', True, False, or a number of Fourier terms to generate. weekly_seasonality: Fit weekly seasonality. Can be 'auto', True, False, or a number of Fourier terms to generate. daily_seasonality: Fit daily seasonality. Can be 'auto', True, False, or a number of Fourier terms to generate. holidays: pd.DataFrame with columns holiday (string) and ds (date type) and optionally columns lower_window and upper_window which specify a range of days around the date to be included as holidays. lower_window=-2 will include 2 days prior to the date as holidays. Also optionally can have a column prior_scale specifying the prior scale for that holiday. seasonality_mode: 'additive' (default) or 'multiplicative'. seasonality_prior_scale: Parameter modulating the strength of the seasonality model. Larger values allow the model to fit larger seasonal fluctuations, smaller values dampen the seasonality. Can be specified for individual seasonalities using add_seasonality. holidays_prior_scale: Parameter modulating the strength of the holiday components model, unless overridden in the holidays input. changepoint_prior_scale: Parameter modulating the flexibility of the automatic changepoint selection. Large values will allow many changepoints, small values will allow few changepoints. mcmc_samples: Integer, if greater than 0, will do full Bayesian inference with the specified number of MCMC samples. If 0, will do MAP estimation. interval_width: Float, width of the uncertainty intervals provided for the forecast. If mcmc_samples=0, this will be only the uncertainty in the trend using the MAP estimate of the extrapolated generative model. If mcmc.samples>0, this will be integrated over all model parameters, which will include uncertainty in seasonality. uncertainty_samples: Number of simulated draws used to estimate uncertainty intervals. Setting this value to 0 or False will disable uncertainty estimation and speed up the calculation. stan_backend: str as defined in StanBackendEnum default: None - will try to iterate over all available backends and find the working one """ def __init__( self, growth='linear', changepoints=None, n_changepoints=25, changepoint_range=0.8, yearly_seasonality='auto', weekly_seasonality='auto', daily_seasonality='auto', holidays=None, seasonality_mode='additive', seasonality_prior_scale=10.0, holidays_prior_scale=10.0, changepoint_prior_scale=0.05, mcmc_samples=0, interval_width=0.80, uncertainty_samples=1000, stan_backend=None ):
Prophet()参数说明:
- growth: 字符串‘linear’或‘logistic’,表示线性或者逻辑增长趋势。在增量函数是逻辑回归函数的时候,需要设置的容量值Capacity参数。表示非线性增长趋势中限定的最大值,预测值将在该点达到饱和.
- changepoints: 日期型向量,指定潜在拐点,如果不指定,将会自动选择潜在拐点。例如:changepoints=[‘2014-01-01’]指定2014-01-01这一天是潜在的changepoints。
- n_changepoints: 表示changepoints的数量大小,如果changepoints指定,该传入参数将不会被使用。如果changepoints不指定,将会从输入的历史数据前80%中选取25个(个数由n_changepoints传入参数决定)潜在改变点。
- changepoint_range: 估计趋势变化点的历史比例。如果指定了`changepoints`,则不使用。
- yearly_seasonality: 指定是否分析数据的年季节性,如果为True,默认取傅里叶项为10,最后会输出,yearly_trend,yearly_upper,yearly_lower等数据。年周期性,True为启用,false为关闭,如果设置为自然数n,则n代表傅里叶级数的项数,项数越多,模型将拟合的越好,但是也越容易过拟合,因此论文中推荐年周期性的项数取10,而周的(weekly_seasonality)取3。一般来讲将历史数据大于1年时模型默认为True(项数默认为10),否则默认为False
- weekly_seasonality: 指定是否分析数据的周季节性,如果为True,默认取傅里叶项为3,最后会输出,weekly_trend,weekly_upper,weekly_lower等数据。周周期性,True为启用,false为关闭,如果设置为自然数n,则n代表傅里叶级数的项数,项数越多,模型将拟合的越好,但是也越容易过拟合,因此论文中推荐取3。一般来讲当历史数据大于1周时模型默认为True(项数默认为3),否则默认为False。
- daily_seasonality: 指定是否分析数据的天季节性,如果为 True,默认取傅里叶项为 10,最后会输出 daily_trend, daily_upper, daily_lower 等数据。当时间序列为小时级别序列时才会开启。
- holidays: 传入 dataframe 格式的数据。这个数据包含有 holiday 列(string)和 ds(date 类型)和可选列 lower_window 和 upper_window 来指定该日期的 lower_window 或者 upper_window 范围内都被列为假期。lower_window=-2 将包括前 2 天的日期作为假期。(默认 None)
- seasonality_mode: ‘additive’(default) or ‘multiplicative’。季节模型。
- seasonality_prior_scale: 调节季节性组件的强度。值越大,模型将适应更强的季节性波动,值越小,越抑制季节性波动。改变周期性影响因素的强度,值越大,周期性因素在预测值中占比越大。默认值为 10,调整的合理范围为 01~10,当设置为 0.01 时,季节性帮幅度被迫很小。实际上是 L2 惩罚。
- holidays_prior_scale: 调节节假日模型组件的强度。值越大,该节假日对模型的影响越大,值越小,节假日的影响越小。如果发现假期过拟合,可以通过 holidays_prior_scale 参数调节使其平滑,默认为 10,减小此参数可以减少假日的影响.
- changepoint_prior_scale: 增长趋势模型的灵活度。调节“changepoint”选择的灵活度,值越大选择的“changepoint”越多,使模型对历史数据的拟合程度变强,然而也增加了过拟合的风险。默认值为 05,一般建议转 0.01~0.5 之间是正确的。
- mcmc_samples: mcmc 采样,用于获得预测未来的不确定性。若大于 0,将做 mcmc 样本的全贝叶斯推理,如果为 0,将做最大后验估计。
- interval_width: 设置执行度,衡量未来时间内趋势改变的程度。表示预测未来时使用的趋势间隔出现的频率和幅度与历史数据的相似度,值越大越相似。当 mcmc_samples=0 时,该参数仅用于增长趋势模型的改变程度,当 mcmc_samples>0 时,该参数也包括了季节性趋势改变的程度。
- uncertainty_samples: 用来估计 uncertainty intervals 的采样次数,如果设置为 0 或者 False,就不会进行 uncertainty intervals 的估计,从而加快模型的训练速度。
- stan_backend: CMDSTANPY 或者 PYSTAN。一般 PYSTAN 在 linux 上使用,cmdstanpy 在微软操作系统上使用。提示下在微软操作系统上使用的同学,最好不要开启马尔科夫采样(就是不要把 mcmc_samples 设成大于 0),因为微软操作系统上马尔科夫采样非常慢。
以上内容非常的平常了,只是做了一些简单的罗列,以下会对一些难点进行详细介绍。
因子项使用加法还是乘法?
在时间序列分析领域,有一种常见的分析方法叫做时间序列的分解(Decomposition of Time Series),它把时间序列$y_t$分成几个部分,分别是季节项$S_t$,趋势项$T_t$,剩余项$R_t$。也就是说对所有的$t\geq0$,都有$y_t=S_t+T_t+R_t$。除了加法的形式,还有乘法的形式,也就是:$y_t=S_t\times T_t\times R_t$。
以上式子等价于$\ln y_t=\ln S_t\times \ln T_t\times \ln R_t$。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。
一般来说,在实际生活和生产环节中,除了季节项,趋势项,剩余项之外,通常还有节假日的效应。所以,在 prophet 算法里面,作者同时考虑了以上四项,也就是:
$$y(t)=g(t)+s(t)+h(t)+\epsilon_t$$
- g(t):表示趋势项,它表示时间序列在非周期上面的变化趋势。
- s(t):表示周期项,或者称为季节项,一般来说是以周或者年为单位。
- h(t):表示节假日项,表示在当天是否存在节假日。
- $\epsilon_t$:表示误差项或者称为剩余项。
Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
在 Facebook Prophet 模型中,因子项(即季节性和节假日效应)的组合方式可以使用加法模型或乘法模型。一般来说,加法模型适用于季节性因子,而乘法模型适用于节假日因子。
加法模型将季节性因子表示为一个固定的周期函数,如正弦函数或余弦函数。它假设季节性因子对时间序列的影响是固定的,并且在不同时间点的影响是相同的。在这种情况下,我们可以将季节性因子与时间序列直接相加。
乘法模型则采用了一种相对更加灵活的方式来建模节假日效应。它假设节假日效应对时间序列的影响是按比例变化的,即随着时间序列的增长而增长。在这种情况下,我们可以将节假日效应与时间序列相乘,使得节假日效应的影响随着时间序列的增长而逐渐放大。
具体来说,在 Prophet 模型中,如果使用乘法模型,则需要设置 seasonality_mode 参数为 ‘multiplicative’;如果使用加法模型,则无需进行特别设置,默认为加法模型。例如,我们可以通过以下代码来设置季节性和节假日效应的参数:
from prophet import Prophet model = Prophet(seasonality_mode='multiplicative') # 添加每周的季节性效应 model.add_seasonality(name='weekly', period=7, fourier_order=3) # 添加法定节假日作为节假日效应 model.add_country_holidays(country_name='CN')
上面的代码中,我们设置了 seasonality_mode 参数为 ‘multiplicative’,并使用 add_seasonality 方法添加了每周的季节性效应和 add_country_holidays 方法添加了中国大陆法定节假日作为节假日效应。Prophet 模型将根据历史数据来确定季节性和节假日效应的参数,并基于加法或乘法模型来预测未来时间序列的变化趋势。
Prophet 除了使用原始数据外,也可以结合Box-Cox 变换等进行预测。
变点的设置
在 Facebook Prophet 中,变点(changepoint)是指时间序列中的突变点或转折点。Prophet 模型使用了自适应的切分方法来检测这些变点,并将它们考虑在内以更准确地预测未来趋势。
要设置 Prophet 模型中的变点,可以使用 changepoint_prior_scale 参数。这个参数控制着模型对于变点的灵敏度,值越大则模型会更加关注变点,而值越小则模型会更倾向于平滑的预测结果。默认值为 0.05,在实际使用中可以根据具体情况进行调整。
另外,还可以通过设置 changepoints 参数手动指定变点的位置。这里需要传入一个时间戳列表,表示变点出现的时间点。如果设置了该参数,则模型将忽略 changepoint_prior_scale 参数。例如:
from prophet import Prophet
import pandas as pd
df = pd.read_csv('some_data.csv')
model = Prophet(changepoints=['2021-01-01', '2022-01-01'])
model.fit(df)
上面的代码中,我们手动设置了两个变点,分别在 2021 年和 2022 年的 1 月 1 日。模型将会根据这两个时间点来进行拟合和预测。
其他参数:
- changepoint_range:百分比,需要在前 changepoint_range 这一段的时间序列中设置变点,默认为 8,
- n_changepoints:变点的个数,默认为 25
在Prophet里面,变点默认的选择方法是前80%的点中等距选择25个点作为变点,也可以通过以下方法来自行设置变点,甚至可以人为设置某些点。变点的增长率是满足Laplace分布的。
Facebook Prophet中默认使用Laplace分布来建模变点的增长率。具体来说,Prophet假设变点的增长率是一个具有零均值和可调整尺度参数的Laplace分布,称为L1范数损失。这个假设源于Prophet开发者在实际业务中的经验,即时间序列数据中的突变点往往呈现出“大起大落”的趋势,而Laplace分布可以更好地刻画这种趋势。我们可以通过设置changepoint_prior_scale参数来控制这个分布的尺度参数。该值越小,表示对于突变点的惩罚力度越大,模型将更加平滑;该值越大,则相应地会使模型更关注可能的变点位置,并产生更多的变点。
需要注意的是,Laplace分布是一种长尾分布,即在尾部区域的概率密度远高于正态分布。因此,Prophet模型也可以较好地处理那些极端值(outliers)和异常情况,从而提高时间序列预测的鲁棒性。
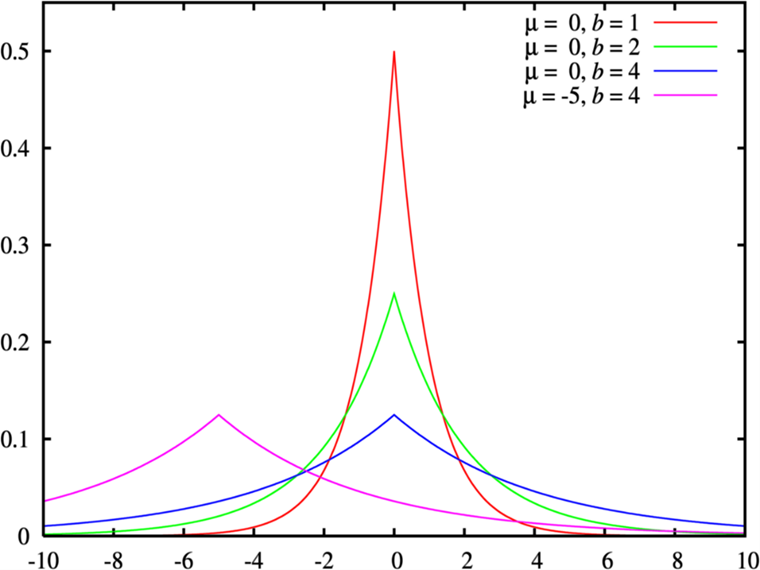
在概率论与统计学中,拉普拉斯分布(Laplace distribution)是以皮埃尔-西蒙·拉普拉斯的名字命名的一种连续概率分布。由于它可看作两平移指数分布背靠背拼接在一起,因此又称双指数分布(Double exponential distribution)。两个相互独立同概率分布指数随机变量之间的差别是按照指数分布的随机时间布朗运动,所以它遵循拉普拉斯分布。
变点的作图:
from prophet.plot import add_changepoints_to_plot m = Prophet(holidays=holidays) m.fit(df_new) future = m.make_future_dataframe(periods=21) fig = m.plot(forecast) a = add_changepoints_to_plot(fig.gca(), m, forecast)
Logistic饱和预测
在Facebook Prophet模型中,Logistic预测通常用于处理具有上限或下限的时间序列数据。例如,我们想要预测某种产品的销售量,但是由于市场饱和或其他因素,销售量可能会受到一个限制,即不能超过某个上限值。此时,我们可以使用Logistic预测来建模这个上限,并得出未来销售量的变化趋势。在Prophet中,Logistic预测采用了一个S形曲线来表示时间序列的增长趋势。具体来说,它假设时间序列的增长率遵循逻辑斯蒂增长函数(logistic growth function),其数学表达式为:
$$\frac{C}{1+e^{-k(t-m)}}$$
其中:
- C表示上限值;
- k是一个正数,表示增长率的速度;
- m是一个实数,表示增长率开始加速的时间点。
在使用Prophet进行Logistic预测时,需要将growth参数设置为’logistic’,并指定上限值(通过cap参数)和下限值(通过floor参数)。例如:
from prophet import Prophet
import pandas as pd
df = pd.read_csv('some_data.csv')
model = Prophet(growth='logistic', cap=1000, floor=0)
model.fit(df)
上面的代码中,我们使用growth参数指定了Logistic增长模型,并分别设置了上限值为1000和下限值为0。Prophet模型将根据历史数据来确定增长率的参数,并基于逻辑斯蒂增长函数来预测未来销售量的变化趋势。同时,通过cap和floor参数,我们还可以控制预测结果的上下限,使其更符合实际情况。
节假日参数设置
在Facebook Prophet模型中,节假日参数的设置可以帮助我们更好地预测时间序列中的特殊日期效应,例如国家或地区的法定节假日、重要纪念日等。Prophet模型提供了多种方式来设置节假日参数,包括:
1、使用add_country_holidays方法添加国家或地区的法定节假日作为节假日参数。该方法需要传入一个ISO3166-2编码,表示要添加的国家或地区。例如,对于中国大陆地区,可以使用’CN’来添加。
from prophet import Prophet model = Prophet() model.add_country_holidays(country_name='CN')
上面的代码中,我们创建了一个Prophet模型,并通过add_country_holidays方法设置了中国大陆的法定节假日作为节假日参数。
2、通过add_seasonality方法手动添加自定义的节假日参数。该方法需要指定一个名称和相应的参数列表,用于表示节假日的周期性变化。例如,我们可以通过以下代码来添加每年的母亲节和父亲节作为节假日参数。
from prophet import Prophet
import pandas as pd
df = pd.read_csv('some_data.csv')
model = Prophet()
model.add_seasonality(name='mother_day', period=365.25, fourier_order=10,
prior_scale=0.1, mode='additive')
model.add_seasonality(name='father_day', period=365.25, fourier_order=10,
prior_scale=0.1, mode='additive')
model.fit(df)
上面的代码中,我们通过add_seasonality方法手动添加了每年的母亲节和父亲节作为节假日参数。其中,name参数是一个字符串,表示节假日的名称;period参数则表示节假日的周期,以天为单位;fourier_order参数是调整傅里叶级数的次数,默认为10;prior_scale参数和mode参数则是模型调参时的超参数。
3、在数据集中添加一列自定义的节假日参数。如果我们已经在数据集中手动添加了某些特定的日期作为节假日参数,那么我们可以通过holiday参数设置这些参数的名称和影响范围。例如:
from prophet import Prophet
import pandas as pd
df = pd.read_csv('some_data.csv')
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
model = Prophet(holidays=holidays)
model.fit(df)
上面的代码中,我们首先创建了一个包含日期和影响范围的DataFrame,然后将其作为Prophet模型的holidays参数传递进去。这样,模型就会自动识别并使用my_custom_holiday作为节假日参数来进行预测。
需要注意的是,不同的节假日参数可能对预测结果产生不同的影响,因此在实际使用中需要根据具体情况来选择和设置相应的参数。
节假日实际使用的时候存在非常大的坑,我们一个个来详细的讲解。
1、自带的节假日
from __future__ import absolute_import, division, print_function
import pandas as pd
import prophet.hdays as hdays_part2
import holidays as hdays_part1
def make_holidays_df(year_list, country, province=None, state=None):
try:
holidays = getattr(hdays_part2, country)(years=year_list, expand=False)
except AttributeError:
try:
holidays = getattr(hdays_part1, country)(prov=province, state=state, years=year_list, expand=False)
except AttributeError as e:
raise AttributeError(f"Holidays in {country} are not currently supported!") from e
holidays_df = pd.DataFrame([(date, holidays.get_list(date)) for date in holidays], columns=['ds', 'holiday'])
holidays_df = holidays_df.explode('holiday')
holidays_df.reset_index(inplace=True, drop=True)
holidays_df['ds'] = pd.to_datetime(holidays_df['ds'])
return (holidays_df)
holidays_df = make_holidays_df([2023], 'CN')
print(holidays_df)
输出内容:
ds holiday 0 2023-01-01 New Year's Day 1 2023-05-01 Labour Day 2 2023-01-22 Chinese New Year (Spring Festival) 3 2023-01-23 Chinese New Year (Spring Festival) 4 2023-01-24 Chinese New Year (Spring Festival) 5 2023-10-01 National Day 6 2023-10-02 National Day 7 2023-10-03 National Day 8 2023-04-05 Tomb-Sweeping Day 9 2023-06-22 Dragon Boat Festival 10 2023-09-29 Mid-Autumn Festival
存在的问题:
- 节日较少,业务场景中包含一些西方节日如情人节、圣诞节等与业务量相关
- 节日的天数与放假也不尽相同,比如春节,这里只将”初一、初二、初三”这三天定义了节假日
- 未考虑节假日前后的影响,比如出行需求(类似机票、火车票)实际在节假日前后,比如春节,订单量的高峰期出现正在春节前,而到节中反而会需求下降。
- 自定义节假日
Holidays参数实际是一个pd.DataFrame:
| holiday | ds | lower_window | upper_window |
| 元旦 | 2019/1/1 | -1 | 1 |
| 元旦 | 2018/1/1 | -1 | 1 |
holiday是特殊日期的时间,ds是时间(pd.Timestamp类型),upper_window和lower_window分别指特殊日期的影响上下限。
需要在Prophet中,认为holiday服从正态分布,正态分布的轴为ds。因此,prophet在预测节假日时会以正态分布作为来估计预测值,但这个过程只是一个先验估计的过程,如果模型后面发现这个holiday期间内不服从正态分布,那么模型将生硬的拟合该节假日。
holidays这个参数非常重要,对整个模型的影响极大,因此大家在构建这个参数时一定要给予相当的重视。holidays在模型中是一个广义的概念,不仅指节假日,也指活动日期,特殊事件日期等,因此大家在设置holidays时一定要确保完整,同时对于upper_window和lower_window的设置也应符合实际情况。值得注意的是holidays的数量应尽量少,过多的holidays会对模型的过拟合现象加重,如果holidays的数量超过了整体数据的30%,工程师就应该考虑是否去掉一些影响较小的节假日。
以下为节假日参数在设置时的一些经验,不一定正确。
官方示例的节假日是一天,而国内的节假日会存在联系N天的场景,遇到类似的场景,应该如何设置?
| ds | holiday | lower_window | upper_window |
| 2021-05-01 | LabourDayHolidayD1 | -1 | 0 |
| 2021-05-02 | LabourDayHolidayD2 | 0 | 0 |
| 2021-05-03 | LabourDayHolidayD3 | 0 | 0 |
| 2021-05-04 | LabourDayHolidayD4 | 0 | 0 |
| 2021-05-05 | LabourDayHolidayDE | 0 | 1 |
目前的设置方案如上:
- holiday采用不同的名称,原因是默认服从正态分布,但在业务层面缺存在较大的差异。所以将每一天单独看待,LabourDayHolidayDE表示为假日的最后一天的,便于对齐一些放假不满5天的情况。
- 第一天的lower_window=-1和最后一天的upper_window=1,代表会影响到节假日的前一天和后一天。
针对上述的内容,我也可以的调整为:
| ds | holiday | lower_window | upper_window |
| 2021-04-30 | LabourDayHolidayP1 | 0 | 0 | 2021-05-01 | Labour Day Holiday D1 | 0 | 0 |
| 2021-05-02 | Labour Day Holiday D2 | 0 | 0 |
| 2021-05-03 | Labour Day Holiday D3 | 0 | 0 |
| 2021-05-04 | Labour Day Holiday D4 | 0 | 0 |
| 2021-05-05 | Labour Day Holiday DE | 0 | 0 |
| 2021-05-06 | Labour Day Holiday N1 | 0 | 0 |
节假日的设置可以观察往年的波动数据结合万年历工具人工整理,也可从以下包中获取部分信息:GitHub – workalendar/workalendar: Worldwide holidays and workdays computational toolkit.
额外回归量
在Facebook Prophet模型中,额外回归量可以用于增强模型的预测能力,例如将天气、广告费用等因素作为额外变量加入到模型中。Prophet模型支持多种类型的额外回归量,包括线性和非线性回归量。
要使用额外回归量,需要在数据集中添加一列或多列表示额外变量,并通过add_regressor方法来告诉Prophet模型如何处理这些变量。例如,我们可以通过以下代码来设置一个额外回归量:
m = Prophet()
m.add_regressor('temp', prior_scale=0.5, mode='multiplicative')
m.add_regressor('rain', prior_scale=0.5, mode='multiplicative')
m.add_regressor('sun', prior_scale=0.5, mode='multiplicative')
m.add_regressor('wind', prior_scale=0.5, mode='multiplicative')
m.fit(data_train)
比如要添加一个疫情影响,是不是可以增加一个每日确诊人数的数值,这样可以在作为一个参数使用。
需要注意的是,额外回归量的处理方式可能因其类型而异。对于线性回归量,Prophet模型假设它们与时间序列之间存在线性关系,并使用线性回归的方法来建模。而对于非线性回归量,则需要使用更加复杂的建模技术(例如核回归)来处理。在实际使用中,我们需要根据具体情况来选择并合理设置额外回归量的类型和参数,以获得更好的预测效果。
交叉验证
在Prophet模型中,交叉验证(Cross Validation)是一种常用的模型评估方法,用于测试模型在新数据上的泛化能力。通过交叉验证,我们可以更加准确地评估模型的预测效果,并选择最佳的超参数设置。
Prophet模型提供了cross_validation方法来进行交叉验证。该方法将原始数据集分成多个子序列,每个子序列用于训练模型,并使用训练出的模型对剩余部分进行预测。最后,计算各个预测结果与实际值之间的误差,并得出模型的平均误差和标准误差。
Prophet自带的交叉验证(cross_validation)函数
def cross_validation(model, horizon, period=None, initial=None, parallel=None, cutoffs=None, disable_tqdm=False):
- model: model是已经训练的Prophet模型
- horizon: 这是预测的未来时间段的长度。
- period:period是触发预测动作的时间周期。如果设置为‘7d’或‘7days’等等,而这些预测的数据为前面定义的horizon。
- initial:用于训练初始模型的时间段长度;整个交叉验证的数据范围,结束点是昨天的点,开始点是(昨天-initial)。
- parallel:是否启用并行计算。parallel可选dask、processes、threads,默认为None,建议设置为processes通过设定该参数的值,转Python中以并行模式运行
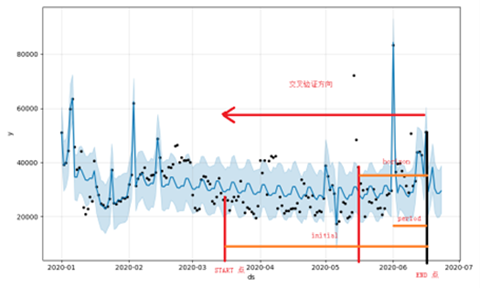
例如,我们可以通过以下代码来进行5折交叉验证:
from prophet import Prophet
import pandas as pd
df = pd.read_csv('some_data.csv')
model = Prophet()
model.fit(df)
df_cv = model.cross_validation(initial='730 days', period='180 days',
horizon='365 days', parallel='processes')
上面的代码中,我们首先创建了一个Prophet模型,并在整个数据集上进行了拟合。然后,我们使用cross_validation方法将数据集按照一定的时间跨度和预测跨度进行划分,并测试模型在新数据上的表现。其中,initial参数表示训练初始模型的时间段长度;period参数表示训练模型的时间段长度;horizon参数表示预测的时间跨度长度;parallel参数指定是否启用并行计算。
需要注意的是,交叉验证可能会消耗大量的计算资源和时间,因此在实际使用中需要根据具体情况进行选择和调整。同时,我们还可以使用performance_metrics方法来计算模型在交叉验证中的性能指标,并生成相应的可视化图表。
cross_validation方法自动产生cutoff(分割时间),然后根据分割点划分数据集,并进行预测验证。当然也可以制定分割点,示例:
cutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15']) df_cv = cross_validation(model, cutoffs=cutoffs, horizon='365 days')
查看指标
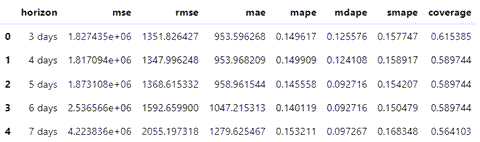
performance_metrics 作为离截止点(预测的未来距离)的函数,可用于计算关于预测性能的一些有用统计数据(如与 y 相比时 yhat、yhat_lower 和 yhat_upper)。计算得到的统计信息包括均方误差(mean squared error, MSE)、均方根误差(root mean squared error, RMSE)、平均绝对误差(mean absolute error, MAE)、平均绝对误差(mean absolute percent error, MAPE) 以及 yhat_lower 和 yhat_upper 估计的覆盖率。这些都是在 df_cv 中通过 horizon (ds – cutoff) 排序后预测的滚动窗口中计算出来的。默认情况下,每个窗口都会包含 10% 的预测,但是可以通过 rolling_window 参数来更改。
from prophet.diagnostics import performance_metrics df_p = performance_metrics(df_cv) df_p.head()
交叉验证性能指标可以用 plot_cross_validation_metric 可视化,这里显示的是 MAPE。点表示 df_cv 中每个预测的绝对误差百分比。蓝线显示的是 MAPE,均值被取到滚动窗口的圆点。我们可以看到,对于一个月后的预测,误差在 20% 左右。
from prophet.plot import plot_cross_validation_metric fig = plot_cross_validation_metric(df_cv, metric='mape')
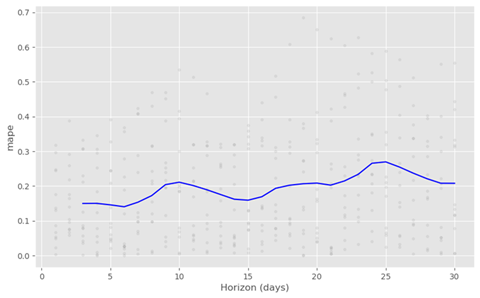
黑点是每天的实际偏差值,蓝色的线是时间窗口内平滑后的指标。
图中滚动窗口的大小可以通过可选参数 rolling_window 更改,该参数指定在每个滚动窗口中使用的预测比例。默认值为 0.1,即每个窗口中包含的 df_cv 的 10% 行;增大值得话将导致图中平均曲线更平滑。
初始周期应该足够长,以捕获模型的所有特性,特别是季节性和额外的回归变量:对年的季节性至少保证一年,对周的季节性至少保证一周,等等。
超参数优化
import itertools
import numpy as np
import pandas as pd
from prophet import Prophet
from prophet.diagnostics import cross_validation
from prophet.diagnostics import performance_metrics
df = pd.read_excel("data.xlsx")
holidays = pd.read_excel("data/holidays.xlsx")
param_grid = {
"changepoint_prior_scale": [0.01, 0.05, 0.1],
"seasonality_prior_scale": [5, 10, 15],
"yearly_seasonality": [1, 5, 10],
"weekly_seasonality": [1, 3, 5],
"holidays_prior_scale": [5, 10, 15],
"holidays": [holidays]
}
# Generate all combinations of parameters
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]
rmses = [] # Store the RMSEs for each params here
# Use cross validation to evaluate all parameters
for params in all_params:
m = Prophet(**params).fit(df) # Fit model with given params
df_cv = cross_validation(m, initial='730 days', horizon='30 days', parallel="processes")
df_p = performance_metrics(df_cv, rolling_window=1)
rmses.append(df_p['rmse'].values[0])
# Find the best parameters
tuning_results = pd.DataFrame(all_params)
tuning_results['rmse'] = rmses
print(tuning_results)
# Python
best_params = all_params[np.argmin(rmses)]
print(best_params)
其他内容
Prophet 的图表呈现
引入 plotly 库可以在 jupyter 上绘制可交互的序列图。
from prophet.plot import plot_plotly import plotly.offline as py py.init_notebook_mode() fig = plot_plotly(m, forecast) # This returns a plotly Figure py.iplot(fig)
保存/加载模型
import json
from prophet.serialize import model_to_json, model_from_json
with open('serialized_model.json', 'w') as fout:
json.dump(model_to_json(m), fout) # Save model
with open('serialized_model.json', 'r') as fin:
m = model_from_json(json.load(fin)) # Load model
参考链接:



5 折交叉验证的代码是不是写错了,’Prophet’ object has no attribute ‘cross_validation’。
检查下你安装的版本