《Getting Real》是由知名软件公司37signals(现Basecamp)团队撰写的一部关于产品开发与创业的经典著作。它提出了一种颠覆传统软件开发流程的方法论,强调“更小规模、更快速、更高质量”的构建理念。这本书并非空洞…

在当今技术驱动的世界中,学习编程已成为一项极具价值的技能。然而,面对琳琅满目的编程语言,初学者甚至是有经验的开发者都常常感到困惑:我该从何学起?又该如何选择?本文旨在结合最新的行业趋势(如TIOBE指数和…

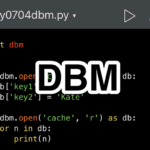
dbm简介 Python 的 dbm 模块是一个用于实现简单键值对数据库的模块。它是基于 Unix 系统上的数据库管理工具 dbm (Database Manager) 的概念引入的。以下是 dbm 及其在 Python 中实现的背景: dbm 的起源 …
在信息爆炸的时代,如何高效地整理、记录和思考,成为许多人面临的挑战。脑图型笔记应用应运而生,它们通过视觉化的方式,帮助用户将零散的信息组织成结构清晰的思维网络,提升学习和工作效率。本文将介绍几款主流…
在软件开发中,开源项目不仅是宝贵的技术灵感来源,更能有效避免“重复造轮子”,显著提升开发效率与项目质量。本文将系统性地梳理与优化各类发现优秀开源项目的渠道与方法,助您更快地锁定所需资源。 善用 GitH…

在快节奏的现代生活中,有效的时间与任务管理已成为提升个人效率与工作质量的关键。对于Windows用户而言,选择一款合适的工具能够事半功倍。本文将结合当前主流工具的特点,为您解析五款在Windows平台上表现卓越的…

在信息爆炸的时代,如何高效地组织和管理知识?开源Wiki系统提供了多样化的解决方案,从轻量级个人笔记到功能齐全的企业知识库,总有一款适合你的需求。 开源Wiki系统的多样性反映了知识管理需求的多元化。…

FastAPI 是一个现代化的 Python Web 框架,专为构建高性能 API 而设计。它支持异步请求处理,并自动生成交互式 API 文档。本指南以 LightGBM 模型为例,详细介绍如何开发、优化和部署机器学习模型接口。 基础…

在当今数据驱动的时代,将机器学习模型高效、可靠地部署为API服务已成为企业智能化转型的关键环节。FastAPI凭借其高性能、异步支持、自动API文档生成和强大的类型验证等特性,成为构建生产级机器学习API服务的理想…

曾几何时,代码补全只是敲下几个字符的提示。然而,自GitHub Copilot问世以来,AI在软件开发中的角色发生了根本性转变。今天,在2026年,讨论“是否使用AI编程”已无意义,核心议题已转变为 “如何选择最适合自己范式…






