推荐系统的优劣需要一套科学、多维度的指标体系来衡量。一套好的评价指标不仅能客观反映系统性能,更能指引产品优化和算法迭代的方向。本文旨在系统性地梳理推荐系统领域常见且重要的评测指标,结合其定义、计算方…
核心摘要 本报告对迅销集团旗下核心品牌优衣库(UNIQLO)进行了系统性解构。其成功本质在于将服装“产品化”,在基础款赛道上构建了难以复制的“科技+供应链+体验”复合型护城河。报告从历史沿革、核心理念、商业模式…

在数字化运营成为企业标配的今天,稳定、高效、安全的通信服务是企业顺畅运转的基石。无论是内部协同办公的电子邮件,还是面向客户的验证码、通知与营销短信,选择合适的服务商都至关重要。本文将在现有资料基础上…
摘要:本报告基于2024年市场环境,聚焦滴滴出行快车与顺风车两大核心业务,通过用户旅程地图、任务流分析等方法,深入剖析了乘客与司机在完整服务流程中的核心痛点,并针对“等待焦虑”、“司乘沟通效率”、“司机端操作…
机器学习中的损失函数用于衡量模型预测值与真实值之间的差异,是模型优化的关键。以下按任务类型分类介绍常见损失函数: 回归任务损失函数 均方误差 (Mean Squared Error, MSE / L2 Loss) 公式 $$\text{M…
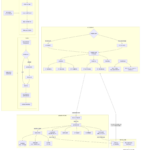
QQ作为中国用户基数最大的即时通讯软件,其背后的通讯协议体系是一个融合了网络编程、数据加密、分布式系统等多种技术的复杂工程。本文将基于公开的技术资料与分析,系统性地剖析QQ协议的核心设计、通信机制、安全…
随着人工智能技术的爆发式发展,个人知识管理的范式正在被深刻重塑。传统的笔记软件依赖人工整理与记忆关联,效率存在瓶颈。如今,基于 AI 的工具能够理解内容、自动建立连接、智能问答,将静态的知识库转化为动态…

谱聚类简介 谱聚类(Spectral Clustering)是一种基于图论的聚类算法,它利用数据的相似性矩阵(拉普拉斯矩阵)的特征向量进行降维,然后在低维空间中使用传统聚类方法(如K-means)进行聚类。与K-means等基于距离…

CLIQUE(CLustering In QUEst)是一种经典的子空间聚类算法,由IBM Almaden研究中心在1998年提出。它专门用于从高维数据中发现密度相似的簇,且这些簇可能仅存在于某些子空间(特征的子集)中,而非全维空间。 …

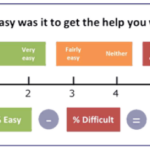
客户费力度(CES)是一个直接衡量客户在与企业互动过程中所付出努力程度的指标,其核心理念在于:客户体验越轻松,他们的满意度和忠诚度往往越高 。 CES 的核心概念与价值 CES 的核心是“减少客户的努力”,强调让…