DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 是一种常用于聚类分析的算法,它可以很好地应用于经纬度数据的聚类。这种算法特别适合处理大规模的空间数据集,并且能够识别出噪声点。在先前的文章中介绍过DBSCAN 的原理与使用,但在实际使用过程中相关的代码还有很多可优化的点。这篇文章主要包含的内容:
- 如何使用 DBSACN 对经纬度进行聚类及相关性能调优的点
- 聚类后的效果呈现,使用 Folium 在地图上做可视化呈现(Folium 教程)
- 对聚类后的点进行统计如寻找中心点及就算中心点到各点的平均距离等
使用 DBSCAN 进行经纬度聚类
以下是使用 Python 的 Scikit-Learn 库中的 DBSCAN 算法对经纬度数据进行聚类:
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.metrics.pairwise import haversine_distances
from math import radians
import matplotlib.pyplot as plt
df = pd.read_csv("data/latlon.csv")
# 将经纬度转换为弧度,因为哈弗赛公式需要弧度作为输入
coordinates = df[['start_lng', 'start_lat']].apply(lambda x: x.map(radians)).values
# 定义一个函数来计算哈弗赛距离
def haversine_metric_km(x, y):
radian_distance = haversine_distances([x, y])[0][1]
# 将弧度距离转换为公里
return radian_distance * 6371
# 使用 DBSCAN 算法
# eps 需要根据数据的实际情况进行调整
dbscan = DBSCAN(eps=3, min_samples=300, metric=haversine_metric_km)
clusters = dbscan.fit_predict(coordinates)
df['clusters'] = clusters
print(df.head())
需要注意的是 haversine_distances 函数返回的单位是弧度。这个函数计算的是两点之间的大圆距离,也就是沿着地球表面的最短路径距离。由于输入的经纬度坐标是以弧度为单位的,因此返回的距离也是以弧度为单位。
如果想将这个距离转换为更常用公里可以通过乘以地球的半径来实现。地球的平均半径大约是 6,371 公里。这样修改后,你可以在 DBSCAN 算法中使用 haversine_metric_km 函数来获得基于公里单位的聚类结果。
以上代码常规的实现方案,但有一个问题,当需要调整 dbscan 的超参数 eps 和 min_samples 每次都要重复计算,等待的时间非常的长。好在 haversine_distances 的 metric 参数还有其他选项。
DBSCAN 算法中的 metric 参数用于指定计算点之间距离的方式。Scikit-Learn 的 DBSCAN 实现支持多种距离度量方式,包括:
- “euclidean”:欧几里得距离,即常规的直线距离。适用于大多数普通场景。
- “manhattan”:曼哈顿距离,即两点在标准坐标系上的绝对轴距总和。适用于格子状的道路系统等。
- “chebyshev”:切比雪夫距离,即两点之间的最大轴距。有时用于棋盘距离计算。
- “minkowski”:闵可夫斯基距离,是欧几里得距离和曼哈顿距离的一般化形式。
- “cosine”:余弦相似度,通常用于文本数据或角度距离的度量。
- “precomputed”:如果距离已经以某种方式预先计算好了,可以使用这个选项。
- 自定义函数:你可以定义自己的距离计算函数,比如前面提到的哈弗赛公式(Haversine formula)用于地理坐标的距离计算。
为了减少每次调整 DBSCAN 参数 eps 和 min_samples 时的计算时间,您可以先使用 haversine_metric_km 函数预计算所有点之间的距离,然后在 DBSCAN 算法中使用 metric=’precomputed’ 选项。这样,您只需一次计算所有点之间的距离矩阵,而不是每次调整参数时都重新计算。
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.metrics.pairwise import haversine_distances
from sklearn.metrics import pairwise_distances
df = pd.read_csv("data/latlon.csv")
# 定义一个函数来计算哈弗赛距离
def haversine_metric_km(x, y):
radian_distance = haversine_distances([x, y])[0][1]
# 将弧度距离转换为公里
return radian_distance * 6371
def haversine_distance_matrix(coordinates):
# 将经纬度转换为弧度
radians_coordinates = np.radians(coordinates)
# 计算所有点对之间的哈弗赛距离
return pairwise_distances(radians_coordinates, metric=haversine_metric_km)
# 计算距离矩阵
distance_matrix = haversine_distance_matrix(df[['start_lng', 'start_lat']].values)
# 应用 DBSCAN 算法
dbscan = DBSCAN(eps=2, min_samples=2, metric='precomputed')
clusters = dbscan.fit_predict(distance_matrix)
df['clusters'] = clusters
print(df.head())
在这段代码中,我们首先计算了所有点之间的距离矩阵,然后使用这个矩阵来运行 DBSCAN 算法。由于距离矩阵已经预先计算好,调整 eps 和 min_samples 参数时,不需要重新计算距离,从而节省了计算时间。请注意,这种方法在数据点非常多时可能会占用大量内存,因为需要存储一个大小为 N×N 的矩阵,其中 N 是数据点的数量。所以,它更适合于中小规模的数据集。
使用 Folium 进行可视化展示
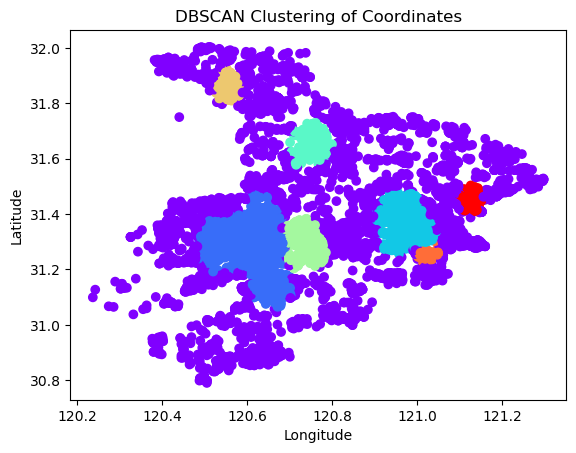
聚类后的展示,最简单的方法是使用 matplotlib 实现。代码示例:
import matplotlib.pyplot as plt
plt.scatter(df['start_lng'], df['start_lat'], c=df['clusters'], cmap='rainbow')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('DBSCAN Clustering of Coordinates')
plt.show()
在 Python 中,使用 Folium 库在地图上可视化聚类结果是一个常见的操作,尤其适用于处理地理数据和地图可视化。
import folium
# 创建颜色映射
unique_clusters = np.unique(clusters)
colors = ['red', 'green', 'blue', 'orange', 'purple', 'brown', 'pink', 'grey', 'black']
color_map = {cluster: colors[i % len(colors)] for i, cluster in enumerate(unique_clusters)}
# 创建地图对象
map_center = df[['start_lat', 'start_lng']].mean().values
map = folium.Map(location=map_center, zoom_start=10, tiles='http://map.geoq.cn/ArcGIS/rest/services/ChinaOnlineStreetGray/MapServer/tile/{z}/{y}/{x}', attr='GeoQ')
# 为每个聚类添加标记
for idx, row in df.iterrows():
cluster_color = color_map[row['clusters']]
folium.CircleMarker(
location=[row['start_lat'], row['start_lng']],
radius=5,
color=cluster_color,
fill=True,
fill_color=cluster_color,
fill_opacity=0.6
).add_to(map)
map
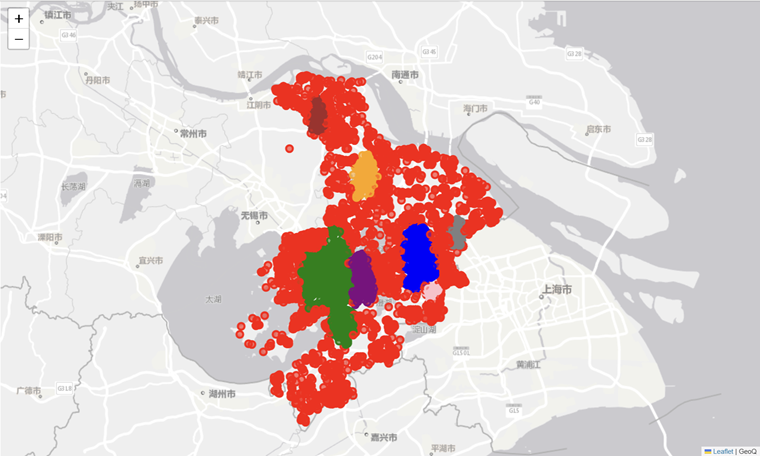
要在Jupyter Notebook环境中运行此代码,或者将地图保存为HTML文件后,在Web浏览器中打开。例如,使用map.save(“map.html”)可以将地图保存为HTML文件。
展示聚类后的相关信息
计算聚类的经纬度中心点及中心点到各个点的平均距离,可以通过以下步骤来实现:
- 计算每个簇的中心点(质心:这个中心点是簇中所有点的平均经纬度位置。我们可以通过对每个簇中的所有点的经度和纬度分别求平均值来得到。
- 计算中心点到簇内各点的距离:使用哈弗赛公式计算簇中心点到簇内每个点的距离。
- 计算平均距离:对簇内所有点到中心点的距离求平均值。
计算每个类别下的经纬度数量:
result = df.groupby('clusters').agg(
count=('clusters', 'size'),
avg_lat=('start_lat', 'mean'),
avg_lng=('start_lng', 'mean')
)
注意:聚类ID=-1的为无法聚类的点,可以忽略。
以下为计算每个聚类点的中心点和中心点到各个点的平均距离:
import numpy as np
from sklearn.metrics.pairwise import haversine_distances
from math import radians
# 定义一个函数来计算哈弗赛距离(以公里为单位)
def haversine_distance_km(point1, point2):
radian_distance = haversine_distances([point1, point2])[0][1]
return radian_distance * 6371
# 计算每个簇的中心点
def calculate_cluster_centers(df, clusters):
centers = {}
for cluster in set(clusters):
if cluster != -1: # 排除噪声点
members = df[clusters == cluster]
center_latitude = members['Latitude'].mean()
center_longitude = members['Longitude'].mean()
centers[cluster] = (center_longitude, center_latitude)
return centers
# 计算每个簇的中心点到各点的平均距离
def calculate_average_distances(df, clusters, centers):
average_distances = {}
for cluster, center in centers.items():
members = df[clusters == cluster]
distances = []
for _, row in members.iterrows():
distances.append(haversine_distance_km(
[radians(row['Latitude']), radians(row['Longitude'])],
[radians(center[1]), radians(center[0])]
))
average_distances[cluster] = np.mean(distances)
return average_distances
# 假设DataFrame df包含经纬度信息,clusters是DBSCAN的聚类结果
centers = calculate_cluster_centers(df, clusters)
average_distances = calculate_average_distances(df, clusters, centers)
print("Cluster Centers:", centers)
print("Average Distances:", average_distances)


