谱聚类简介 谱聚类(Spectral Clustering)是一种基于图论的聚类算法,它利用数据的相似性矩阵(拉普拉斯矩阵)的特征向量进行降维,然后在低维空间中使用传统聚类方法(如K-means)进行聚类。与K-means等基于距离…

CLIQUE(CLustering In QUEst)是一种经典的子空间聚类算法,由IBM Almaden研究中心在1998年提出。它专门用于从高维数据中发现密度相似的簇,且这些簇可能仅存在于某些子空间(特征的子集)中,而非全维空间。 …

BANG算法概述 BANG算法是21世纪初提出的一种用于空间数据聚类的算法,它结合了网格划分和层次聚类的思想,旨在高效地发现数据集中任意形状、不同密度的聚类,并且能够识别嵌套的聚类结构。 BANG算法是一种巧妙…

CLARANS简介 CLARANS(Clustering Large Applications based on RANdomized Search,基于随机搜索的大规模应用聚类)是一种经典的聚类算法,由Raymond T. Ng和Jiawei Han于1994年提出。它旨在解决当时主流聚类算法…
X-Means 和 G-Means 都是基于 K-Means 的改进算法,主要目标是自动确定最优的聚类数量k,无需人工预先指定。 X-Means X-Means 是一种能够自动确定最佳聚类数量的改进型K-Means算法,它通过统计指标来评估聚类…

PyClustering简介 PyClustering 是一个功能丰富的数据挖掘库,特别专注于聚类分析、振荡网络和神经网络。PyClustering 是一个算法覆盖面广、实现质量高的库,特别在以下方面表现突出: 聚类算法全面性:从经…

ROCK算法概述 ROCK产生背景 传统聚类算法的局限性 20世纪90年代末,随着电子商务、市场篮子分析和生物信息学等领域的快速发展,分类属性和布尔型数据的聚类需求日益凸显。传统聚类方法面临两大挑战: 距…
K-Medians简介 K-Medians 是 K-Means 聚类算法的一种变体,通过使用中位数而非均值来计算聚类中心,从而提升对异常值的鲁棒性。 核心思想 目标函数:最小化每个数据点到其所属聚类中心的曼哈顿距离之…

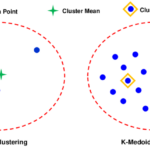
k-medoids算法概述 k-medoids 是一种基于中心的聚类算法,是 k-means 算法的改进版本。与 k-means 使用簇内数据点的均值作为中心点不同,k-medoids 使用实际数据点作为中心点(称为 medoid)。 与 k-means …
引言:聚类的美好承诺与普遍困境 当我们谈论聚类分析时,脑海中往往会浮现这样一个理想场景:将相似的数据对象自动分组,为业务决策提供清晰指导。这种无监督学习方法的吸引力在于其能够探索数据内在结构,而无需…