CLIQUE(CLustering In QUEst)是一种经典的子空间聚类算法,由IBM Almaden研究中心在1998年提出。它专门用于从高维数据中发现密度相似的簇,且这些簇可能仅存在于某些子空间(特征的子集)中,而非全维空间。
CLIQUE简介
产生背景
高维数据的爆发与“维度灾难”
- 数据环境变化:随着信息技术、商业数据库(如超市交易记录)、科学实验(如基因微阵列)的普及,可收集的数据维度(特征/属性)急剧增长,从几十维跃升至成百上千维。
- 核心矛盾:传统聚类算法(如K-Means、DBSCAN)严重依赖全维度空间的距离度量(如欧氏距离)。在高维空间中,所有数据点之间的距离会变得极其相似(数据极度稀疏),这种现象被称为“维度灾难”。这使得基于距离的相似性计算失效,传统算法在全维度空间中难以找到有意义的簇。
簇存在于“子空间”而非全空间
- 现实观察:在实际高维数据中,有意义的簇通常只由一部分相关属性决定,而其他属性可能是无关的噪声。例如:
- 客户细分:一个簇可能由“年龄”和“收入”定义,而“邮编”在该簇内是随机分布。
- 基因表达:某些基因只在特定实验条件下(部分维度)协同表达。
- 关键洞察:在全维度空间中看似无结构的数据,在某些低维子空间投影中可能呈现出清晰的密集簇。因此,聚类任务不仅是要找簇,更要自动发现哪些子空间存在簇。
前人方法的局限
在CLIQUE之前,主流应对高维聚类问题的方法存在明显不足:
- 特征选择/降维(如PCA):为整个数据集选择一个全局的低维投影。弊端:可能会扭曲或掩盖仅存在于特定子空间中的簇,因为不同簇可能依赖于不同的特征子集。
- 传统全空间聚类算法:如上所述,在高维下效果很差。
- 需要手动指定相关维度:这要求领域专家预先知道哪些特征重要,不适用于探索性数据挖掘。
技术思潮的融合与创新
CLIQUE的设计巧妙地借鉴了当时两个火热领域的核心思想:
- 来自关联规则挖掘的“Apriori原理”:用于高效搜索频繁项集。CLIQUE将其创造性应用于子空间搜索,提出“单调性原理”:如果一个k维单元是密集的,那么它在所有(k-1)维投影中的父单元也必须是密集的。这允许算法自底向上、逐层生成并剪枝候选子空间,极大地避免了组合爆炸。
- 来自密度聚类(如DBSCAN)的“基于密度”思想:通过定义“密集单元”来发现任意形状的簇,并对噪声鲁棒。但CLIQUE将其与网格化结合,将连续空间离散化为单元,通过统计单元内点数来定义密度,大幅提升了计算效率。
核心思想
CLIQUE 的核心思想可以概括为:通过网格化和密度连接来发现高维数据中的簇,并利用子空间搜索的单调性原理,自动且高效地定位那些簇所存在的低维子空间。
这个思想基于一个深刻且现实的观察:在高维数据中,有意义的簇通常只在一部分属性(子空间)上密集分布,而在其他属性上是随机或稀疏的。因此,其核心围绕着以下三个相互关联的支柱展开:
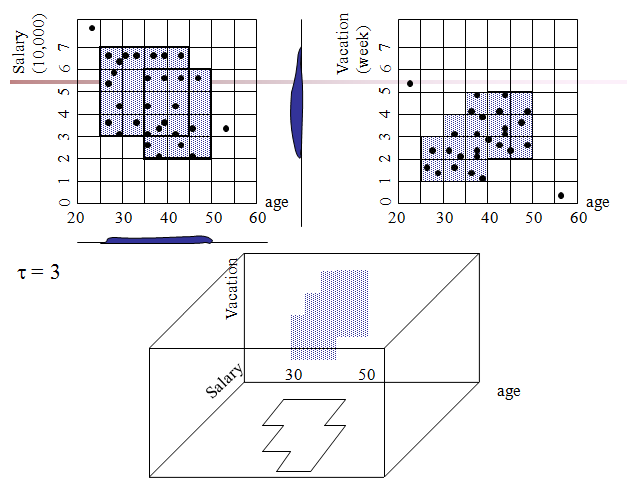
第一支柱:网格化与稠密单元
核心思想:将连续的、高维的数据空间离散化为网格单元,用单元的“数据点密度”来定义簇。
- 网格化:对每个维度进行等宽划分,将整个数据空间划分为一个个超矩形单元。这就像为数据世界绘制了一张带坐标网格的地图。
- 稠密单元:如果一个单元内包含的数据点数量超过了预设的密度阈值,它就被标记为“稠密单元”。稠密单元被认为是潜在簇的“砖块”。
为什么这样做?
- 降维计算:将复杂的连续空间密度计算,简化为对离散单元的计数,计算效率极高。
- 定义清晰:为“簇”提供了一个明确的、基于统计的定义。
第二支柱:向下闭包性与自底向上搜索
核心思想:利用“单调性”原理,像搭积木一样从低维到高维,系统地、高效地搜索所有可能存在簇的子空间。
这是CLIQUE最具创新性的部分,灵感来源于关联规则挖掘中的Apriori算法。
- 向下闭包性:如果一个 k维的单元是稠密的,那么它在所有 (k-1)维空间上的投影(父单元)也必须是稠密的。
- 直观理解:如果一个区域在“收入-年龄”二维平面上很密集,那么在单独看“收入”或“年龄”这两个一维分布时,该区域对应的区间也必然是密集的。反之则不成立(低维密集,高维不一定密集)。
- 自底向上搜索流程:
- 开始:先找出所有1维子空间(即单个属性)中的稠密单元。
- 迭代:基于已经找到的(k-1)维稠密单元,通过组合(类似连接操作)生成候选的k维单元。
- 剪枝:利用向下闭包性进行强力剪枝——如果一个候选k维单元的任何一个(k-1)维父单元不是稠密的,那么这个候选单元不可能是稠密的,可以直接丢弃,无需扫描数据验证。
- 终止:直到找不到更高维的候选稠密单元为止。
为什么这样做?
- 自动化:算法自动发现哪些属性组合(子空间)存在密集模式,无需人工指定。
- 高效性:剪枝策略避免了在所有可能的子空间组合(是指数级数量)上进行穷举搜索,是算法可行的关键。
第三支柱:连通性与最小化描述
核心思想:将邻近的“砖块”(稠密单元)连接起来形成完整的“建筑”(簇),并用最简洁的规则来描述它。
- 簇的生成:在找到的每个稠密集子空间中,将共享边界的稠密单元连接起来,形成一个连通的区域。这个区域就是一个簇。它可以是任意形状,不限于球形。
- 最小化描述:为每个生成的簇,找到一个最精简的规则集来覆盖其所有单元。例如:簇 = {年龄 ∈ [20,30] ∧ 收入 ∈ [50k,80k]}。这使聚类结果具有极强的可解释性,可以直接转化为业务知识。
为什么这样做?
- 捕获任意形状:基于连通性,能发现传统基于距离的方法难以发现的复杂形状簇。
- 结果可解释:最终的输出不仅是数据点的分组,更是清晰的、人类可读的“如果-那么”规则,这是其巨大优势。
核心思想总结
CLIQUE的智慧在于,它将一个极其复杂的高维聚类问题,分解为三个可计算、可管理的阶段:
- 量化(网格与密度):将“密集区域”这个模糊概念,量化为“超过阈值的网格单元”。
- 搜索(单调性剪枝):利用“局部密集则整体必密集”的逻辑,像侦探一样高效排除大量不可能存在簇的区域,锁定目标子空间。
- 构造与解释(连接与描述):将找到的“证据碎片”(稠密单元)拼合成完整的“画像”(簇),并用最简语言(规则)描述出来。
一个生动的比喻:
想象在一片广阔的多维星海中寻找文明(簇)。CLIQUE的做法是:
- 先绘制星图(网格化)。
- 然后从单个星座(1维)开始观察,记录恒星密集的星座。
- 接着根据一个关键法则:“如果一个双星系统(2维)密集,那么组成它的两颗单星(1维)所在区域也必然密集”。利用这个法则,只在那些单星密集的区域去寻找可能密集的双星系统,大大缩小了搜索范围。
- 最后,将邻近的密集双星、三星系统连接起来,标记为一个文明星团,并记录下它的精确坐标范围(规则描述)。
与同类方法对比
CLIQUE 作为子空间聚类领域的开创性算法,与同类方法的对比可以从几个维度展开:核心策略、目标、优势与局限。下表清晰地勾勒出它与几类代表性方法的区别:
| 方法类别 | 典型代表 | 核心策略 | 与 CLIQUE 的关键对比 |
| 传统全空间聚类 | K-Means, DBSCAN | 在所有维度上计算距离/密度进行聚类。 | 根本差异:CLIQUE 认为簇存在于子空间,能避免无关维度干扰;传统方法受“维度灾难”影响,在高维下失效。 |
| 基于距离/质心的子空间聚类 | PROCLUS, ORCLUS | 迭代选择子空间并为簇分配维度,基于距离度量。 | 搜索方式:CLIQUE 是自底向上、穷举剪枝式搜索;PROCLUS 是自顶向下、迭代采样式搜索。 簇形状:CLIQUE 基于密度,可发现任意形状簇;PROCLUS 基于距离,偏向球形或凸形簇。 输出:CLIQUE 提供可解释的规则;PROCLUS 给出簇的维度列表。 |
| 基于密度的子空间聚类 | SUBCLU | 将 DBSCAN 的核心思想(密度连接)直接扩展至子空间。 | 密度定义:CLIQUE 基于网格单元计数,边界生硬;SUBCLU 基于邻域和核心点,边界更自然。 精度与效率:SUBCLU 聚类质量更高,能识别更精细的密度变化,但计算成本远高于CLIQUE 的网格法。 结果:两者都能发现任意形状簇,但 SUBCLU 结果通常更准确。 |
| 降维后聚类 | PCA + K-Means | 先用线性变换(如PCA)将数据投影到全局低维空间,再聚类。 | 子空间性质:CLIQUE 发现的是轴平行(axis-parallel) 的子空间(原始特征子集);PCA 发现的是任意方向的线性子空间(特征组合)。 簇适用性:CLIQUE 适合不同簇依赖不同特征的数据;PCA 为全体数据寻找一个最优的全局低维视图,可能掩盖局部簇。 |
与 PROCLUS 对比:搜索范式的根本不同
CLIQUE 和 PROCLUS 代表了子空间聚类的两大经典范式。
- CLIQUE (自底向上,基于关联规则):
- 过程:像搭积木,从1维开始,利用“密集单元”的向下闭包性(单调性)逐层(2维、3维…)构建和验证候选子空间,最后将稠密单元连成簇。
- 优点:相对系统、全面,能保证发现所有满足密度阈值的轴平行子空间簇,结果可解释性强。
- 缺点:参数(网格粒度、密度阈值)敏感,网格边界可能导致簇的割裂。
- PROCLUS (自顶向下,基于K-Medoids):
- 过程:先初始化寻找可能的簇中心点(Medoids),然后为每个簇分配一组相关的维度(子空间),再迭代调整中心和维度,直到收敛。
- 优点:效率通常更高,对参数依赖相对较小,簇的描述简洁(每个簇一个维度集)。
- 缺点:需要预设簇数目K,对初始中心点敏感,偏向发现球形簇,可能错过低维的、基于密度的复杂形状簇。
简单来说:CLIQUE 是“发现密集区域并描述之”,PROCLUS 是“给簇分配一个特征子集”。
与 SUBCLU 对比:密度定义的精髓差异
两者都基于“密度”,但对密度的实现天差地别。
- CLIQUE (网格密度):
- 将空间划分为固定的网格,统计每个网格里的点数。密度是全局的、平均的。
- 缺点:网格大小固定,可能将一个自然连续的密集区域切割到多个单元中(边界问题),或者因阈值设置而丢失或合并簇。
- SUBCLU (基于点的密度):
- 直接沿用 DBSCAN 的定义:一个点是核心点,如果其ε-邻域内点的数量超过阈值。密度是局部的、基于点的。
- 优点:能更自然、更精确地刻画任意形状的簇和密度变化,对参数设置更鲁棒。
- 缺点:在高维子空间中进行基于点的邻域查询,计算复杂度远高于CLIQUE的网格计数,可扩展性是其挑战。
本质区别:CLIQUE 是“数格子”,SUBCLU 是“量半径”。前者快但粗糙,后者准但慢。
在算法家族内的演进
CLIQUE 启发了一系列改进算法,它们构成了一个家族:
- MAFIA: 主要改进网格划分,采用自适应(数据驱动的)网格,而非等宽网格,能更贴合数据分布,提升聚类质量。
- ENCLUS: 改进了子空间搜索标准。CLIQUE 用“密度”,ENCLUS 用“熵”来衡量子空间的兴趣度(聚类潜力),旨在找到更有趣、更不均匀分布的子空间。
- FIRES: 一种框架式方法,先在全维空间找到低维的“种子簇”,再将其合并或扩展到相关子空间,提供了另一种搜索思路。
优缺点与应用场景
优点
- 自动化子空间发现
- 核心优势:无需预先指定哪些维度与聚类相关。算法能自动识别出存在密集簇的特征子集,这是其最根本的贡献。
- 对输入顺序不敏感
- 由于基于全局网格划分和计数,结果的确定性和可重现性高,不受数据点输入顺序影响。
- 可扩展性高,效率突出
- 网格化计数:将复杂的邻域查询简化为对网格单元的整数累加,计算成本远低于基于距离的算法。
- 单调性剪枝:利用向下闭包性大幅减少需要检查的高维候选子空间数量,避免了组合爆炸。
- 非常适合处理大规模、高维度的数值型数据集。
- 对噪声数据鲁棒
- 低密度单元被自然过滤为噪声,不参与簇的形成,增强了模型的稳定性。
- 可发现任意形状的簇
- 基于密度单元的连接,而非基于距离的质心,因此能识别非球形、任意形状的簇结构。
- 结果可解释性强
- 输出不仅是簇的成员列表,更是清晰的“IF-THEN”形式规则(例如:IF 年龄 ∈ [20,30] AND 收入 ∈ [50k,80k] THEN 属于簇A),可直接转化为业务洞察。
缺点
- 参数敏感且难以设置
- 网格划分参数 (ξ):每个维度划分的区间数。太小会导致粒度太粗,可能合并多个簇;太大则粒度太细,可能将一个簇分解,并产生大量空单元。
- 密度阈值 (τ):区分稠密与稀疏单元的阈值。过高会遗漏真实但较稀疏的簇;过低会产生大量假阳性簇(将噪声区域误判为簇)。
- 参数设置高度依赖先验知识或反复试验。
- 网格边界问题
- 边界割裂:一个自然的密集区域可能被网格边界切割成多个相邻的稠密单元,虽然算法会连接它们,但切割仍可能影响簇的“自然”边界识别精度。
- 对数据分布和坐标轴对齐敏感:网格是轴平行的(Axis-aligned)。如果簇的边界是斜的或与坐标轴不平行,网格化会引入较大误差。
- 忽略属性间的相关性
- 网格划分完全独立于每个维度进行,忽略了特征之间的相关性(如:年龄和收入可能存在的非线性关系)。这限制了其发现非轴平行子空间簇的能力。
- 可能产生冗余簇描述
- 一个簇可能被多个重叠或相邻的规则集描述,需要后处理来生成最小覆盖集。
- 所有维度被平等对待
- 在子空间搜索的初始阶段(1维),算法平等地检查所有单个维度。如果大多数维度都是噪声,计算资源可能被浪费。
典型应用场景
CLIQUE特别适合于以下类型的任务和数据:
- 高维数据的探索性数据分析
- 场景:面对一个维度很高(数十维至数百维)、内在结构未知的数据集,需要快速了解“哪些特征组合可能隐藏着有意义的群体”。
- 示例:客户画像分析、基因表达数据的初步模式发现。
- 需要可解释性规则的商业智能
- 场景:聚类目标不仅是分组,更是要生成可直接用于决策的、人类可读的业务规则。
- 示例:
- 市场细分:发现规则如“年轻(20-30岁) & 高收入(>50K) & 高频网购”的客户群,以便进行精准营销。
- 风险控制:识别具有“交易频率异常高 & 单笔金额中等 & 登录地点分散”特征的潜在欺诈账户规则。
- 处理相对稀疏的高维数据
- 场景:数据在全维空间中非常稀疏(如文本的单词向量、用户-商品矩阵),但在某些低维子空间中可能存在密集块。
- 示例:文档聚类中,某些主题可能仅由一部分关键词(子空间)决定;推荐系统中,特定用户群可能只对某类商品(子空间)有共同偏好。
- 对聚类形状无球形假设,且计算资源有限
- 场景:需要发现任意形状的簇,同时数据量很大,计算效率是重要考量。
不适用或慎用场景
- 维度极低(如2D、3D)的数据
- 原因:有更高效、更精确的专用算法(如DBSCAN、OPTICS)。CLIQUE的网格化在此显得笨重且不必要。
- 要求簇边界极其精确
- 原因:网格边界效应会导致结果不够精确。
- 数据中存在大量复杂的相关性或非线性结构
- 原因:轴平行的网格无法有效捕获这些模式。应考虑基于流形学习或相关子空间的聚类方法。
- 无法接受参数调优
- 原因:CLIQUE的效果严重依赖参数调整,在缺乏调优经验或自动化工具时,效果可能不稳定。
CLIQUE算法实现
CLIQUE算法详细步骤
数据预处理
- 将所有特征归一化到[0,1]范围
- 确定每个维度的划分区间数ξ
网格划分
- 每个维度i等分为ξ个等宽区间
- 整个d维空间被划分为ξ^d个单元
- 单元表示:每个单元用其在每个维度的区间索引表示
识别稠密单元
# 伪代码逻辑
for 每个维度组合:
为每个单元计数数据点
如果计数 ≥ τ(总点数 * 阈值比例):
标记为稠密单元
自底向上搜索子空间
# 基于向下闭包性
D1 = 所有1维稠密单元的集合
k = 1
while Dk不为空:
# 生成候选(k+1)维单元
Ck+1 = 从Dk中生成候选(k+1)维单元
# 剪枝:移除任何(k+1)维候选,如果其任意k维投影不在Dk中
剪枝Ck+1
# 扫描数据,计算候选单元的密度
for 每个候选单元c in Ck+1:
计算c中的数据点计数
if 计数 ≥ τ:
将c加入Dk+1
k = k + 1
生成簇
- 在每个子空间中,连接相邻的稠密单元形成簇
- 相邻性:两个单元在每一维度上的索引最多相差1
生成最小化描述
- 为每个簇找到最小覆盖规则
- 规则形式:[维度i ∈ 范围] AND [维度j ∈ 范围] …
Python实现
import numpy as np
from collections import defaultdict, deque
from typing import List, Dict, Tuple, Set, Any
import itertools
class CLIQUE:
def __init__(self, xi: int = 10, tau: float = 0.2):
"""
初始化CLIQUE算法
参数:
xi: 每个维度的划分区间数
tau: 密度阈值比例 (单元内点数占总点数的比例)
"""
self.xi = xi
self.tau = tau
self.dense_units = defaultdict(list) # 存储各维度稠密单元
self.clusters = [] # 存储最终簇
self.rules = [] # 存储簇的描述规则
def fit(self, X: np.ndarray) -> 'CLIQUE':
"""
执行CLIQUE聚类
参数:
X: 输入数据 (n_samples, n_features)
返回:
self: 训练好的模型
"""
self.n_samples, self.n_features = X.shape
self.X = X.copy()
# 1. 数据归一化
self.X_normalized = self._normalize(X)
# 2. 网格划分
self.grid_cells = self._create_grid()
# 3. 自底向上搜索稠密单元
self._find_dense_units()
# 4. 从稠密单元生成簇
self._form_clusters()
# 5. 生成簇标签
self.labels_ = self._generate_labels()
return self
def _normalize(self, X: np.ndarray) -> np.ndarray:
"""将数据归一化到[0,1]范围"""
X_min = X.min(axis=0)
X_max = X.max(axis=0)
# 避免除零
X_range = X_max - X_min
X_range[X_range == 0] = 1.0
return (X - X_min) / X_range
def _create_grid(self) -> Dict[Tuple[int, ...], List[int]]:
"""创建网格并分配数据点到单元格"""
# 计算区间宽度
interval_width = 1.0 / self.xi
# 初始化网格字典:键是单元格坐标,值是点索引列表
grid = defaultdict(list)
# 分配每个数据点到单元格
for i, point in enumerate(self.X_normalized):
# 计算点在每个维度上的区间索引
cell_coords = tuple(int(coord // interval_width) for coord in point)
# 处理边界情况:当coord == 1.0时
cell_coords = tuple(min(c, self.xi - 1) for c in cell_coords)
grid[cell_coords].append(i)
return grid
def _find_dense_units(self):
"""自底向上搜索稠密单元"""
# 阈值:最小点数
min_points = self.tau * self.n_samples
# 步骤1: 找到所有1维稠密单元
D1 = [] # 存储1维稠密单元
for dim in range(self.n_features):
# 计算该维度每个区间的点数
interval_counts = np.zeros(self.xi, dtype=int)
for cell_coords, point_indices in self.grid_cells.items():
interval_idx = cell_coords[dim]
interval_counts[interval_idx] += len(point_indices)
# 标记稠密区间
for interval_idx, count in enumerate(interval_counts):
if count >= min_points:
dense_unit = (dim, interval_idx)
D1.append(dense_unit)
self.dense_units[1] = D1
# 步骤2: 自底向上搜索更高维稠密单元
k = 1
while k < self.n_features and len(self.dense_units[k]) > 0:
# 生成候选(k+1)维单元
candidates = self._generate_candidates(k)
if not candidates:
break
# 扫描数据,验证候选单元密度
Dk1 = [] # 存储(k+1)维稠密单元
for candidate in candidates:
# 计算候选单元中的数据点数
count = self._count_points_in_unit(candidate)
if count >= min_points:
Dk1.append(candidate)
if Dk1:
self.dense_units[k + 1] = Dk1
k += 1
else:
break
def _generate_candidates(self, k: int) -> List[Tuple]:
"""生成候选(k+1)维单元"""
candidates = []
if k not in self.dense_units or not self.dense_units[k]:
return candidates
Dk = self.dense_units[k]
# 如果k=1,生成2维候选
if k == 1:
# 组合不同的维度
for i in range(len(Dk)):
for j in range(i + 1, len(Dk)):
dim1, interval1 = Dk[i]
dim2, interval2 = Dk[j]
if dim1 != dim2:
# 检查所有(k-1)维投影是否稠密
# 对于2维,(1,2)的1维投影是(1)和(2),都在D1中
candidate = ((dim1, interval1), (dim2, interval2))
# 按维度排序
candidate = tuple(sorted(candidate))
candidates.append(candidate)
else:
# 对于k>1,通过合并相似的(k-1)维单元生成候选
# 这里简化处理:只检查维度组合
seen = set()
for i in range(len(Dk)):
for j in range(i + 1, len(Dk)):
unit1 = Dk[i] # k维单元
unit2 = Dk[j] # k维单元
# 检查是否共享(k-1)个维度
dims1 = {dim for dim, _ in unit1}
dims2 = {dim for dim, _ in unit2}
if len(dims1.intersection(dims2)) == k - 1:
# 可以合并
merged = sorted(set(unit1) | set(unit2))
# 检查所有k维投影是否稠密
if self._check_downward_closure(merged, Dk):
candidate = tuple(merged)
if candidate not in seen:
candidates.append(candidate)
seen.add(candidate)
return candidates
def _check_downward_closure(self, candidate: Tuple, Dk: List) -> bool:
"""检查向下闭包性:候选单元的所有k维投影是否都在Dk中"""
k_plus_1 = len(candidate)
# 生成所有k维子投影
for i in range(k_plus_1):
# 移除第i个元素得到k维投影
projection = candidate[:i] + candidate[i+1:]
# 检查投影是否在Dk中
if projection not in Dk:
return False
return True
def _count_points_in_unit(self, unit: Tuple) -> int:
"""计算单元中的数据点数"""
count = 0
# 单元表示:((dim1, interval1), (dim2, interval2), ...)
# 转换为网格坐标条件
conditions = {}
for dim, interval in unit:
conditions[dim] = interval
# 扫描所有点
for i, point in enumerate(self.X_normalized):
in_unit = True
interval_width = 1.0 / self.xi
for dim, interval in unit:
# 计算点在该维度的区间索引
point_interval = int(point[dim] // interval_width)
if point_interval == self.xi: # 处理边界
point_interval = self.xi - 1
if point_interval != interval:
in_unit = False
break
if in_unit:
count += 1
return count
def _form_clusters(self):
"""从稠密单元形成簇"""
# 在每个维度上,连接相邻的稠密单元
for dim_size, units in self.dense_units.items():
if not units:
continue
# 将稠密单元转换为图结构
graph = self._build_adjacency_graph(units, dim_size)
# 在图中寻找连通分量
visited = set()
for unit in units:
if tuple(unit) not in visited:
cluster = []
self._dfs(unit, graph, visited, cluster)
if cluster:
self.clusters.append((dim_size, cluster))
def _build_adjacency_graph(self, units: List, dim_size: int) -> Dict:
"""构建稠密单元的邻接图"""
graph = defaultdict(list)
# 转换为可哈希的元组
unit_tuples = [tuple(unit) for unit in units]
for i, unit1 in enumerate(unit_tuples):
for j, unit2 in enumerate(unit_tuples[i+1:], i+1):
if self._are_adjacent(unit1, unit2, dim_size):
graph[unit1].append(unit2)
graph[unit2].append(unit1)
return graph
def _are_adjacent(self, unit1: Tuple, unit2: Tuple, dim_size: int) -> bool:
"""检查两个单元是否相邻"""
# 两个单元在每个维度上的区间索引最多相差1
diff_count = 0
# 转换为字典形式方便比较
unit1_dict = dict(unit1)
unit2_dict = dict(unit2)
# 检查所有维度
all_dims = set(unit1_dict.keys()) | set(unit2_dict.keys())
for dim in all_dims:
idx1 = unit1_dict.get(dim, -1)
idx2 = unit2_dict.get(dim, -1)
if idx1 != -1 and idx2 != -1:
# 两个单元都包含这个维度
if abs(idx1 - idx2) > 1:
return False
elif abs(idx1 - idx2) == 1:
diff_count += 1
else:
# 只有一个单元包含这个维度
# 这种情况不应该发生,除非单元维度不同
return False
# 至少在一个维度上相邻
return diff_count >= 1
def _dfs(self, unit: Tuple, graph: Dict, visited: Set, cluster: List):
"""深度优先搜索,寻找连通分量"""
stack = [unit]
while stack:
current = stack.pop()
if current in visited:
continue
visited.add(current)
cluster.append(current)
for neighbor in graph.get(current, []):
if neighbor not in visited:
stack.append(neighbor)
def _generate_labels(self) -> np.ndarray:
"""为每个数据点生成簇标签"""
labels = -np.ones(self.n_samples, dtype=int) # -1表示噪声
# 为每个簇分配点
cluster_id = 0
for dim_size, cluster_units in self.clusters:
for unit in cluster_units:
# 找到在这个单元中的所有点
unit_points = self._get_points_in_unit(unit)
for point_idx in unit_points:
if labels[point_idx] == -1: # 还未分配
labels[point_idx] = cluster_id
# 注意:一个点可能属于多个簇,这里简单分配第一个遇到的簇
cluster_id += 1
return labels
def _get_points_in_unit(self, unit: Tuple) -> List[int]:
"""获取单元中的所有点索引"""
points = []
interval_width = 1.0 / self.xi
for i, point in enumerate(self.X_normalized):
in_unit = True
for dim, interval in unit:
point_interval = int(point[dim] // interval_width)
if point_interval == self.xi: # 处理边界
point_interval = self.xi - 1
if point_interval != interval:
in_unit = False
break
if in_unit:
points.append(i)
return points
def get_cluster_rules(self) -> List[Dict]:
"""获取每个簇的描述规则"""
rules = []
for cluster_id, (dim_size, cluster_units) in enumerate(zip(range(len(self.clusters)), self.clusters)):
if dim_size >= len(self.clusters):
continue
_, units = self.clusters[dim_size]
# 为每个簇找到最小覆盖区间
cluster_rule = {}
# 收集这个簇在所有维度上的区间
dim_intervals = defaultdict(list)
for unit in units:
for dim, interval in unit:
dim_intervals[dim].append(interval)
# 为每个维度找到最小和最大区间
for dim, intervals in dim_intervals.items():
if intervals:
min_interval = min(intervals)
max_interval = max(intervals)
# 转换为原始数据范围
min_val = min_interval * (1.0 / self.xi)
max_val = (max_interval + 1) * (1.0 / self.xi)
# 反归一化
if hasattr(self, 'X_min') and hasattr(self, 'X_range'):
min_val_orig = min_val * self.X_range[dim] + self.X_min[dim]
max_val_orig = max_val * self.X_range[dim] + self.X_min[dim]
cluster_rule[dim] = (min_val_orig, max_val_orig)
else:
cluster_rule[dim] = (min_val, max_val)
rules.append({
'cluster_id': cluster_id,
'dimensions': list(cluster_rule.keys()),
'rules': cluster_rule,
'num_points': np.sum(self.labels_ == cluster_id)
})
return rules
# 三、简化版CLIQUE实现(更高效)
class SimpleCLIQUE:
"""简化版CLIQUE实现,专注于核心逻辑"""
def __init__(self, xi=10, tau=0.1):
self.xi = xi
self.tau = tau
self.labels_ = None
def fit(self, X):
"""简化的CLIQUE实现"""
n_samples, n_features = X.shape
# 1. 归一化
X_min = X.min(axis=0)
X_max = X.max(axis=0)
X_range = X_max - X_min
X_range[X_range == 0] = 1.0
X_norm = (X - X_min) / X_range
# 2. 网格划分
interval_width = 1.0 / self.xi
grid = {}
for i in range(n_samples):
# 计算网格坐标
coords = tuple(min(int(val // interval_width), self.xi-1)
for val in X_norm[i])
if coords not in grid:
grid[coords] = []
grid[coords].append(i)
# 3. 识别稠密单元
min_points = self.tau * n_samples
dense_cells = []
for coords, points in grid.items():
if len(points) >= min_points:
dense_cells.append(coords)
# 4. 连接相邻稠密单元形成簇
clusters = []
visited = set()
for cell in dense_cells:
if cell in visited:
continue
# 新簇
cluster = []
queue = deque([cell])
while queue:
current = queue.popleft()
if current in visited:
continue
visited.add(current)
cluster.append(current)
# 找到相邻单元
for neighbor in self._get_neighbors(current):
if neighbor in grid and neighbor in dense_cells and neighbor not in visited:
queue.append(neighbor)
if cluster:
clusters.append(cluster)
# 5. 分配标签
labels = -np.ones(n_samples, dtype=int)
for i, cluster in enumerate(clusters):
for cell in cluster:
for point_idx in grid[cell]:
if labels[point_idx] == -1:
labels[point_idx] = i
self.labels_ = labels
self.clusters_ = clusters
self.grid_ = grid
self.dense_cells_ = dense_cells
return self
def _get_neighbors(self, cell):
"""获取相邻网格单元"""
neighbors = []
for i in range(len(cell)):
for delta in (-1, 1):
neighbor = list(cell)
neighbor[i] += delta
if 0 <= neighbor[i] < self.xi:
neighbors.append(tuple(neighbor))
return neighbors
# 四、使用示例
def example_usage():
"""CLIQUE算法使用示例"""
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# 生成示例数据
X, y_true = make_blobs(n_samples=1000, centers=3, n_features=2, random_state=42)
# 添加一些噪声
np.random.seed(42)
noise = np.random.randn(50, 2) * 3
X = np.vstack([X, noise])
y_true = np.concatenate([y_true, -np.ones(50)]) # 噪声点标签为-1
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 使用简化版CLIQUE
clique = SimpleCLIQUE(xi=15, tau=0.05)
clique.fit(X_scaled)
# 可视化结果
plt.figure(figsize=(12, 5))
# 真实标签
plt.subplot(1, 2, 1)
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=y_true, cmap='viridis', s=20, alpha=0.7)
plt.title("True Clusters")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
# CLIQUE聚类结果
plt.subplot(1, 2, 2)
unique_labels = set(clique.labels_)
colors = plt.cm.tab20(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
if k == -1:
col = 'gray' # 噪声点
class_member_mask = (clique.labels_ == k)
xy = X_scaled[class_member_mask]
plt.scatter(xy[:, 0], xy[:, 1], c=[col], s=20, alpha=0.7,
label=f'Cluster {k}' if k != -1 else 'Noise')
plt.title(f"CLIQUE Clustering (xi={clique.xi}, tau={clique.tau})")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.legend()
plt.tight_layout()
plt.show()
# 输出聚类统计
n_clusters = len(set(clique.labels_)) - (1 if -1 in clique.labels_ else 0)
n_noise = np.sum(clique.labels_ == -1)
print(f"Number of clusters found: {n_clusters}")
print(f"Number of noise points: {n_noise}")
print(f"Cluster sizes: {np.bincount(clique.labels_[clique.labels_ >= 0])}")
return clique
# 五、高级功能:CLIQUE用于高维数据
def high_dim_example():
"""高维数据上的CLIQUE示例"""
from sklearn.datasets import make_classification
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 生成高维数据(20维,但簇只存在于部分维度)
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=5, # 只有5个特征与聚类相关
n_redundant=5,
n_clusters_per_class=1,
n_classes=3,
random_state=42
)
# 使用CLIQUE
clique = SimpleCLIQUE(xi=10, tau=0.05)
clique.fit(X)
# 使用PCA降维可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 真实标签
axes[0].scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', s=20, alpha=0.7)
axes[0].set_title("True Classes (PCA Projection)")
axes[0].set_xlabel("PC1")
axes[0].set_ylabel("PC2")
# CLIQUE结果
unique_labels = set(clique.labels_)
colors = plt.cm.tab20(np.linspace(0, 1, len(unique_labels)))
for k, col in zip(unique_labels, colors):
if k == -1:
col = 'gray'
mask = (clique.labels_ == k)
axes[1].scatter(X_pca[mask, 0], X_pca[mask, 1],
c=[col], s=20, alpha=0.7,
label=f'Cluster {k}' if k != -1 else 'Noise')
axes[1].set_title(f"CLIQUE Clustering")
axes[1].set_xlabel("PC1")
axes[1].set_ylabel("PC2")
axes[1].legend()
plt.tight_layout()
plt.show()
# 统计信息
print("High-dimensional Clustering Results:")
print(f"Total samples: {X.shape[0]}")
print(f"Total features: {X.shape[1]}")
print(f"Clusters found: {len(set(clique.labels_)) - (1 if -1 in clique.labels_ else 0)}")
print(f"Noise points: {np.sum(clique.labels_ == -1)}")
return clique, X_pca
# 运行示例
if __name__ == "__main__":
print("=" * 60)
print("CLIQUE算法实现与示例")
print("=" * 60)
# 示例1:基本使用
print("\n1. 二维数据示例:")
clique_2d = example_usage()
# 示例2:高维数据
print("\n2. 高维数据示例:")
clique_hd, X_pca = high_dim_example()


