情感分析的定义与核心地位 情感分析(Sentiment Analysis),亦称为意见挖掘或倾向性分析,是人工智能领域中计算语言学的分支,属于自然语言处理(NLP)的核心内容。其核心定义为:通过自动化技术判定文本中观点持…

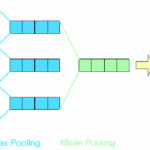
均值池化简介 均值池化(Mean Pooling) 是自然语言处理(NLP)中常用的一种技术,用于将一组词向量(如一个句子中所有词的向量)压缩成一个固定长度的句子向量。它的核心思想是通过简单的数学平均操作,将分散的…
项目简介:针对一标识的文本信息,抽取文本中的关键词,最后以词云的方式暂时关键词。数据集更有2列:text、flag。其中text是文本内容, flag样本标识(0或1)。 步骤一:对文本内容进行分词处理 这里采用的是结…

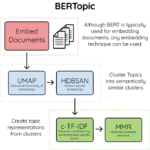
主题模型是用来在非结构数据中无监督的发现隐含主题信息的一类重要工具,比较成熟和常用的算法有基于矩阵分解(如:SVD分解)的LSA(Latent Semantic Analysis), 引入概率方法代替SVD的pLSA(Probabilistic Latent…
在HuggingFace 上,有多个模型适合用于对中文文本的迷信。这些模型通常被预训练在大规模的中文语料上,因此它们能够有效地理解和处理中文文本。以下是一些推荐的模型: bert-base-chinese bert-base-chinese 是一个…
背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是…
ChatGPT与GPT ChatGPT,全称聊天生成预训练转换器(英语:Chat Generative Pre-trainedTransformer),是OpenAI开发的人工智能聊天机器人程序,于2022年11月推出。该程序使用基于GPT-3.5、GPT-4架构的大型语言模型…
BERT简介 BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google的研究者在2018年提出。它在自然语言处理(NLP)领域取得了革命性的进展,尤其是在理解上下文含义…

Transformer简介 Transformer是一种深度学习架构,由Google的研究者在2017年的论文《Attention Is All You Need》中首次提出。它在自然语言处理(NLP)和其他领域取得了巨大的成功,特别是在处理长序列数据方面。Tr…
在听《字谈字畅》节目的时候了解到了一个新的概念:中文拼音正词法。 《中文拼音正词法基本规则》是中华人民共和国国家标准GB/T16159—1996,1996-01-22国家技术监督局发布,1996-07-01实施。以下为摘录内容: 总…






