Transformer简介
Transformer是一种深度学习架构,由Google的研究者在2017年的论文《Attention Is All You Need》中首次提出。它在自然语言处理(NLP)和其他领域取得了巨大的成功,特别是在处理长序列数据方面。Transformer模型的核心特点是使用了”注意力机制”(Attention Mechanism),它能够有效地捕获输入数据之间的关系,无论这些数据之间的距离有多远。
![]()
Transformer模型的产生背景是对自然语言处理(NLP)中的传统模型的局限性的回应和改进。在Transformer出现之前,NLP领域主要由两种模型主导:循环神经网络(RNN)和卷积神经网络(CNN)。
- 循环神经网络(RNN)的局限性:RNN是处理序列数据的一种流行方法。然而,RNN在处理长序列时会遇到两个主要问题:
- 梯度消失/爆炸:这是由于序列长度增加导致的,难以训练长序列。
- 并行处理困难:由于RNN的顺序处理特性,它无法充分利用现代计算硬件(如GPU)的并行处理能力。
- 卷积神经网络(CNN):尽管CNN在处理短序列和固定大小输入方面效果不错,但它们在捕捉长距离依赖关系方面存在局限性。
- 长短期记忆网络(LSTM)和门控循环单元(GRU):这些是RNN的改进版本,旨在解决梯度消失的问题,但它们仍然无法高效处理长序列和复杂的依赖关系。
Transformer的设计目标是解决这些问题,尤其是提高对长距离依赖关系的处理能力,并提高模型训练的效率。Transformer的核心创新是自注意力机制(Self-Attention Mechanism),这使得模型能够同时考虑序列中所有元素的依赖关系,而不是像RNN那样顺序处理。这不仅改善了对长距离依赖关系的处理,还使得模型能够在现代计算硬件上实现高效的并行处理。
因此,Transformer模型的产生是NLP领域对更高效、更强大的语言处理模型需求的响应,它在处理语言相关任务时表现出了显著的优势。
Transformer 于2017年6月推出。原本研究的重点是翻译任务。随后推出了几个有影响力的模型,包括:
- 2018年6月:GPT, 第一个预训练的Transformer模型,用于各种NLP任务并获得极好的结果
- 2018年10月:BERT, 另一个大型预训练模型,该模型旨在生成更好的句子摘要
- 2019年2月:GPT-2, GPT的改进(并且更大)版本,由于道德问题没有立即公开发布
- 2019年10月:DistilBERT, BERT的提炼版本,速度提高60%,内存减轻40%,但仍保留BERT 97%的性能
- 2019年10月:BART 和T5, 两个使用与原始Transformer模型相同架构的大型预训练模型
- 2020年5月, GPT-3, GPT-2的更大版本,无需微调即可在各种任务上表现良好(称为零样本学习)
![]()
由于Transformer优异的模型结构,使得其参数量可以非常庞大从而容纳更多的信息,因此Transformer模型的能力随着预训练不断提升,随着近几年计算能力的提升,越来越大的预训练模型以及效果越来越好的Transformers不断涌现,简单的统计可以从下图看出:
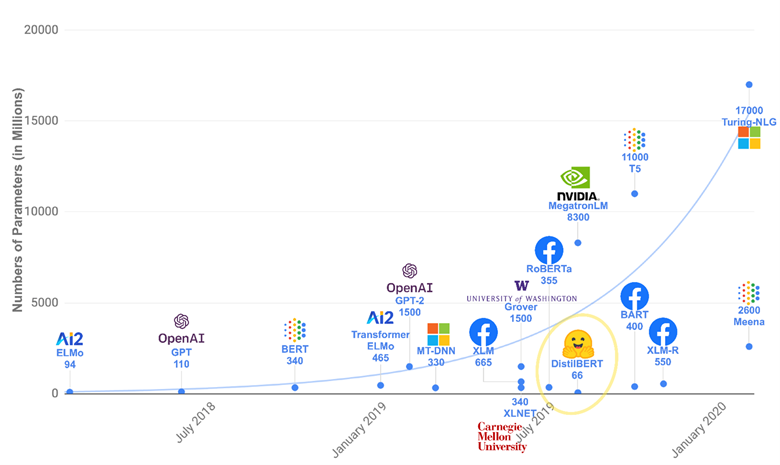
这个列表并不全面,只是为了突出一些不同类型的Transformer模型。大体上,它们可以分为三类:
- GPT-like (也被称作自回归Transformer模型)
- BERT-like (也被称作自动编码Transformer模型)
- BART/T5-like (也被称作序列到序列的Transformer模型)
稍后我们将更深入地探讨这些分类。
核心特点
- 注意力机制(Attention Mechanism):Transformer的核心是自注意力(Self-Attention)机制。这种机制允许模型在处理序列的每个元素时,同时考虑序列中的所有其他元素。这种直接的依赖关系捕获了序列内部的上下文信息,并且能够处理长距离依赖。
- 编码器-解码器架构:Transformer通常包含两部分:编码器和解码器。编码器读取输入数据并将其转换为一系列内部表示,解码器则根据这些表示生成输出数据。在文本翻译等任务中,编码器处理输入文本,而解码器生成翻译后的文本。
- 多层结构:Transformer模型包含多个编码器和解码器层。每个层都包含一个自注意力模块和一个前馈神经网络。这些层的堆叠增加了模型的容量和复杂性。
- 位置编码(Positional Encoding):由于Transformer不使用循环神经网络(RNN),因此需要一种方法来处理序列数据中的位置信息。Transformer通过在输入嵌入中添加位置编码来实现这一点,确保了模型能够理解单词在序列中的位置。
注意力机制的工作原理
- 计算注意力分数:Transformer计算每个序列元素对其他所有元素的注意力分数。这些分数决定了在处理每个元素时,其他元素的重要性。
- 加权求和:然后将这些分数用于加权求和,生成每个元素的输出表示,该表示包含了整个序列的信息。
应用和影响
- 广泛应用:Transformer架构在NLP领域尤其成功,被用于多种任务,如机器翻译、文本生成、情感分析等。
- 机器翻译:Transformer模型最初就是为了改善机器翻译的性能而设计的。它通过自注意力机制有效地捕捉句子中的长距离依赖,从而在不同语言之间进行精确的转换。
- 文本摘要:在自动文本摘要任务中,Transformer能够理解原文的主要内容,并生成包含关键信息的简短文本。这在新闻摘要、报告生成等领域非常有用。
- 情感分析:Transformer模型能够理解文本中的情绪倾向,如正面、负面或中性,广泛应用于市场分析、社交媒体监控等领域。
- 问答系统:利用Transformer模型,可以构建能够理解自然语言问题并从给定的文本中提取答案的系统。这在在线客服、虚拟助手等领域有广泛应用。
- 自然语言推理(NLI):在这个任务中,模型需要判断一段文本是否蕴含、矛盾或与另一段文本无关。这对于理解语言的细微差别非常关键。
- 语言模型和文本生成:Transformer模型也被用于生成连贯的文本,包括故事创作、自动生成文章内容、编写代码等。
- 命名实体识别(NER):在这个应用中,Transformer 模型识别文本中的特定实体,如人名、地点、组织等,这对于信息提取和组织非常重要。
- 语言理解和生成:更高级的 Transformer 模型,如 GPT 系列,不仅能够理解文本,还能够生成新的、相关的内容,这在创造性写作、对话系统和更多领域开辟了新的可能性。
- 跨语言理解:Transformer 模型的一个重要应用是跨语言的信息检索、分类和问答,这对于构建多语言支持的 NLP 系统至关重要。
- 语音识别:虽然 Transformer 起源于 NLP 领域,但它的变体也被用于语音识别等其他领域,将语音信号转换为文本。
- 预训练模型:Transformer 是许多流行的预训练模型(如 BERT、GPT 系列)的基础,这些模型在多项 NLP 任务中取得了前所未有的成绩。
性能和效率
- 并行处理能力:与传统的 RNN 和 LSTM 相比,Transformer 能够并行处理序列中的所有元素,大大提高了处理效率。
- 长距离依赖:自注意力机制使得 Transformer 特别擅长处理长距离依赖问题。
总的来说,Transformer 架构通过其创新的注意力机制,彻底改变了序列建模任务的处理方式,尤其在自然语言处理领域引发了一场革命。
Transformers 的理论基础
注意力机制
注意力机制(Attention Mechanism)是一种在深度学习中广泛使用的技术,尤其在自然语言处理(NLP)和计算机视觉(CV)领域中非常重要。注意力机制的核心思想是模拟人类的注意力特性,即在处理大量信息时能够专注于某些关键部分,而忽略其他不太重要的信息。这种机制在改善模型的性能和解释性方面发挥了关键作用。
注意力机制的基本原理是对输入数据的不同部分赋予不同的重要性。在 NLP 任务中,这通常意味着对不同的单词或短语赋予不同的权重;在 CV 任务中,这可能意味着对图像的不同区域赋予不同的权重。
- 软注意力(Soft Attention):
- 在软注意力机制中,权重是通过模型学习得到的,通常使用 softmax 函数来分配。
- 这种类型的注意力是可微的,允许使用标准的反向传播算法进行训练。
- 例子:在机器翻译中,模型可能会在翻译特定单词时更多地关注源句子中的相关单词。
- 硬注意力(Hard Attention):
- 在硬注意力机制中,模型选择关注数据的特定部分,而完全忽略其他部分。
- 这种类型的注意力通常是非可微的,需要使用强化学习或其他特殊技术来训练。
- 例子:在图像处理中,模型可能只关注图像的某一部分来识别对象。
注意力机制的优势:
- 提高模型的性能:通过集中于关键信息,注意力机制可以帮助模型更有效地学习。
- 提高模型的解释性:注意力权重可以用来解释模型的决策过程,例如,展示模型在做出预测时关注了哪些信息。
- 适应性强:注意力机制可以应用于各种不同类型的模型和任务中。
Attention 机制的本质思想
我们可以这样来看待 Attention 机制:将 Source 中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定 Target 中的某个元素 Query,通过计算 Query 和各个 Key 的相似性或者相关性,得到每个 Key 对应 Value 的权重系数,然后对 Value 进行加权求和,即得到了最终的 Attention 数值。
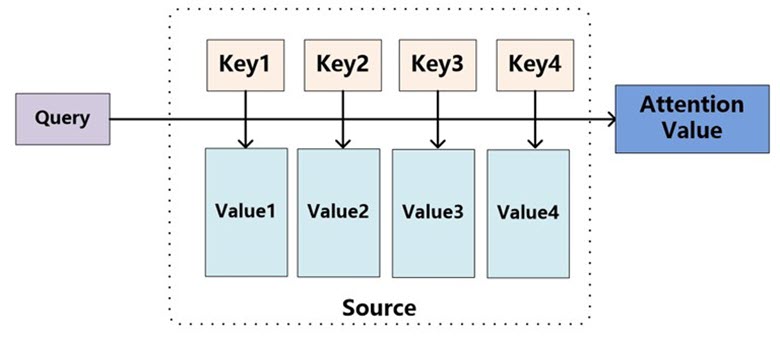
所以本质上 Attention 机制是对 Source 中元素的 Value 值进行加权求和,而 Query 和 Key 用来计算对应 Value 的权重系数。即可以将其本质思想改写为如下公式:
$$Attention(Query,Source)=\sum_{i=1}^{L_x}Similarity(Query,key_i)*Value_i$$
其中,$L_x=||Source||$ 代表 Source 的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算 Attention 的过程中,Source 中的 Key 和 Value 合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把 Attention 仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的 Value 值上,即权重代表了信息的重要性,而 Value 是其对应的信息。
至于 Attention 机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据 Query 和 Key 计算权重系数,第二个过程根据权重系数对 Value 进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据 Query 和 Key 计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将 Attention 的计算过程抽象为如图展示的三个阶段。
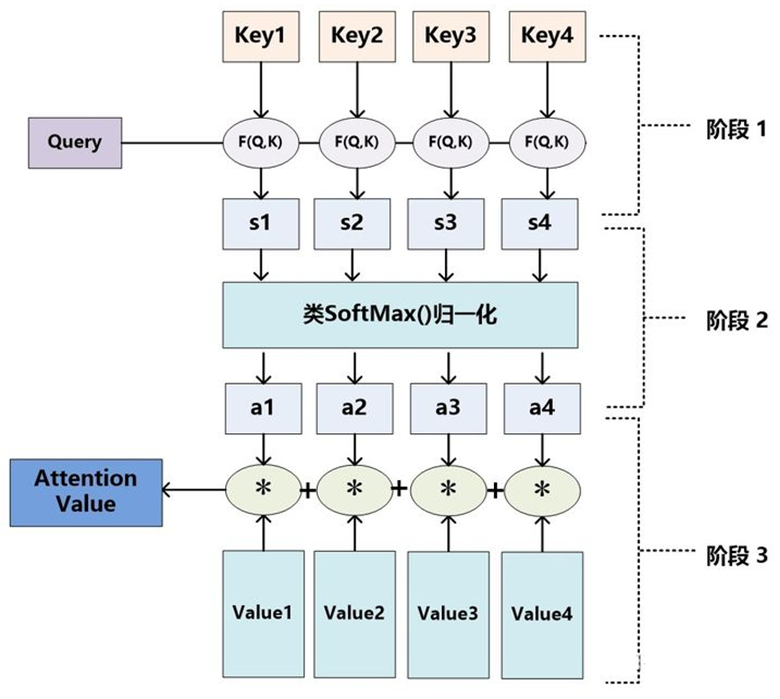
在第一个阶段,可以引入不同的函数和计算机制,根据 Query 和某个 Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量 Cosine 相似性或者通过再引入额外的神经网络来求值,即如下方式:
- 点积:$Similarity(Query,Key_i)=Query \cdot Key_i$
- cosine 相似性:$Similarity(Query,Key_i)=\frac{Query \cdot Key_i}{\left\|Query\right\| \cdot \left\|Key_i\right\|}$
- MLP 网络:$Similarity(Query,Key_i)=MLP(Query,Key_i)$
第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似 SoftMax 的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为 1 的概率分布;另一方面也可以通过 SoftMax 的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
$$a_i=Softmax(Sim_i)=\frac{e^{Sim_j}}{{\textstyle\sum_{j=1}^{L_x}e^{Sim_j}}}$$
第二阶段的计算结果 $a_i$ 即为 $Value_i$ 对应的权重系数,然后进行加权求和即可得到 Attention 数值:
$$Attention(Query,Source)=\sum_{i=1}^{L_x}a_i \cdot Value_i$$
通过如上三个阶段的计算,即可求出针对 Query 的 Attention 数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
序列到序列模型(Seq2Seq)
序列到序列模型(Seq2Seq)是一种深度学习模型,广泛用于处理需要将一个序列转换成另一个序列的任务,例如机器翻译、文本摘要、语音识别等。Seq2Seq 模型的关键特点是它能够处理可变长度的输入和输出序列。
Seq2Seq 模型通常包括两部分:编码器(Encoder)和解码器(Decoder)。
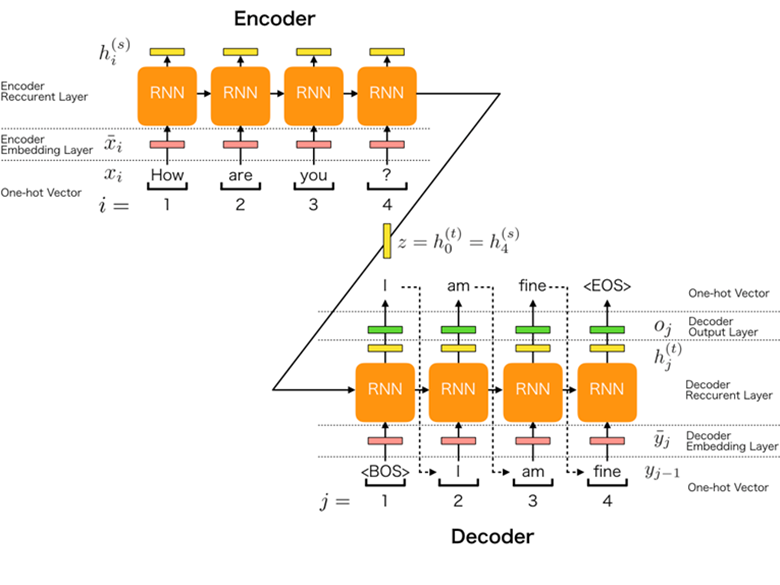
- 编码器:
- 编码器的作用是处理输入序列并提取相关信息。
- 在处理输入时,它将序列中的每个元素(如单词或字符)转换成一个向量。
- 它通常使用循环神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)来处理序列数据,并捕捉其中的时间依赖性。
在处理完整个输入序列后,编码器生成一个上下文向量(Context Vector),这个向量是输入序列的压缩表示,捕捉了序列中的关键信息。
- 解码器的任务是将编码器产生的上下文向量转换成输出序列。
- 解码器也通常使用 RNN、LSTM 或 GRU。
- 在生成输出时,它一般是逐步进行的,每次生成序列的一个元素(如一个单词),然后将其作为下一步的输入。
与注意力机制的结合
在初期的 Seq2Seq 模型中,编码器只生成一个固定的上下文向量来表示整个输入序列。这种设计在处理长序列时效果不佳,因为固定长度的向量难以捕捉长序列中的所有信息。为了解决这个问题,注意力机制被引入到 Seq2Seq 模型中。
- 注意力机制允许解码器在生成每个输出元素时”关注”输入序列中的不同部分。
- 例如,在机器翻译中,当解码器生成目标语言的一个单词时,它可以关注与这个单词最相关的源语言中的几个单词。
- 这种方法显著提高了模型处理长序列和复杂序列的能力。
seq2seq 的细节
seq2seq 模型由编码器(Encoder)和解码器(Decoder)组成。绿色的编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个黄色的向量(称为 context 向量)。当我们处理完整个输入序列后,编码器把 context 向量发送给紫色的解码器,解码器通过 context 向量中的信息,逐个元素输出新的序列。
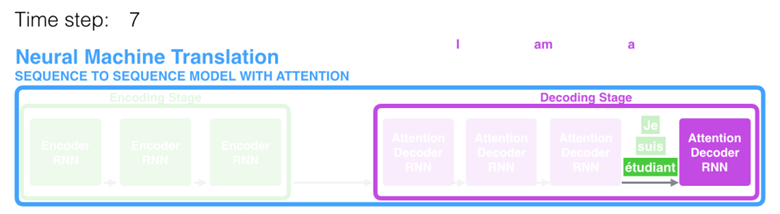
在第 7 个时间步,注意力机制使得解码器在产生英语翻译 student 英文翻译之前,可以将注意力集中在法语输入序列的:étudiant。这种有区分度得 attention 到输入序列的重要信息,使得模型有更好的效果。
让我们继续来理解带有注意力的 seq2seq 模型:一个注意力模型与经典的 seq2seq 模型主要有 2 点不同:
A)首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态),如下面的动态图所示:
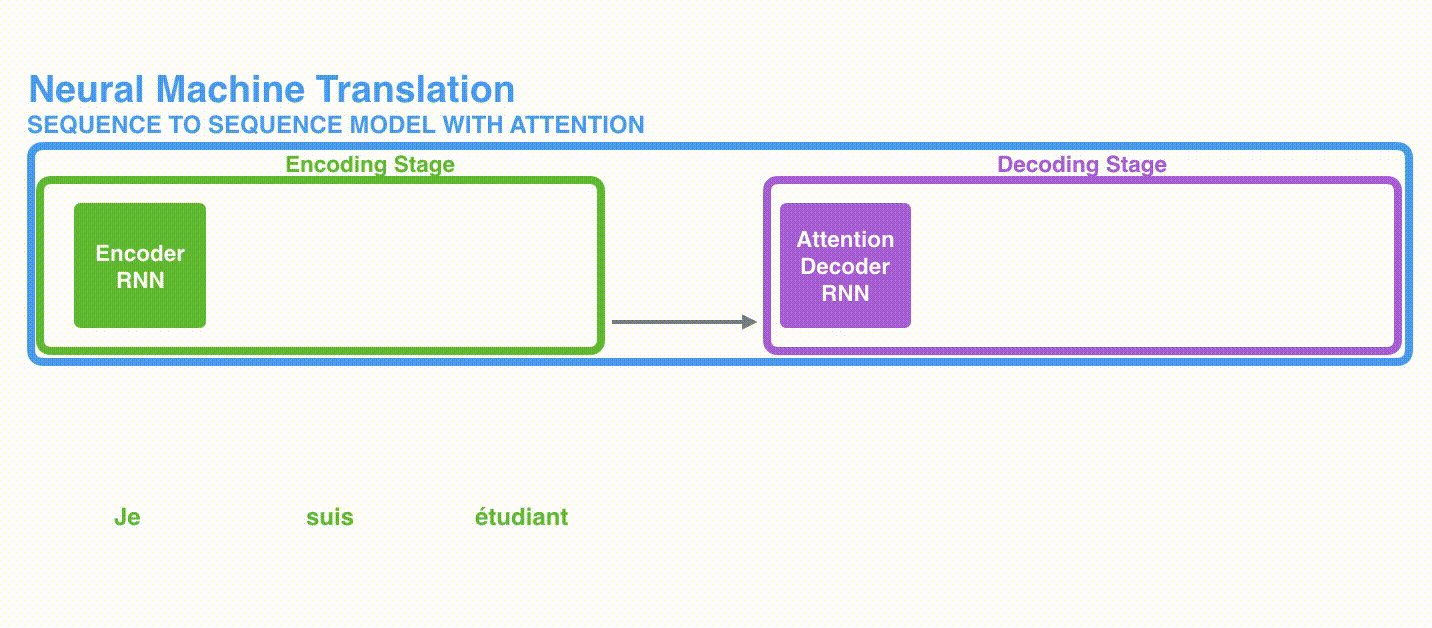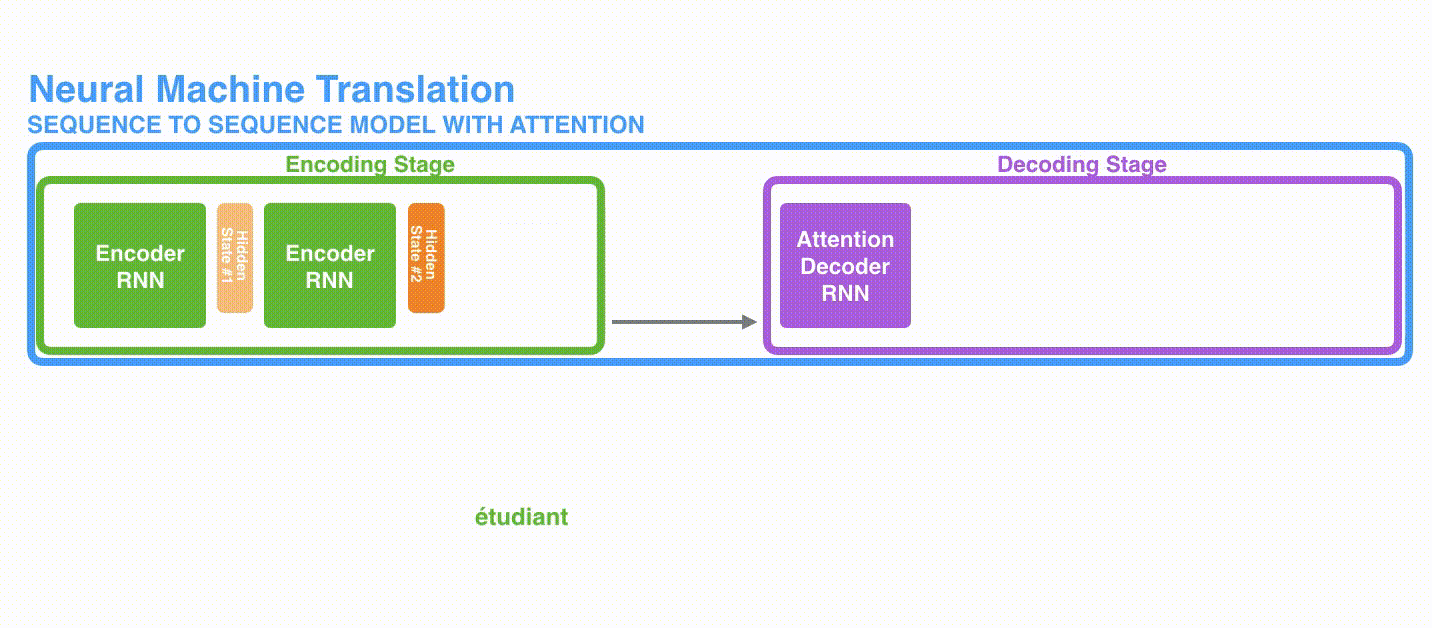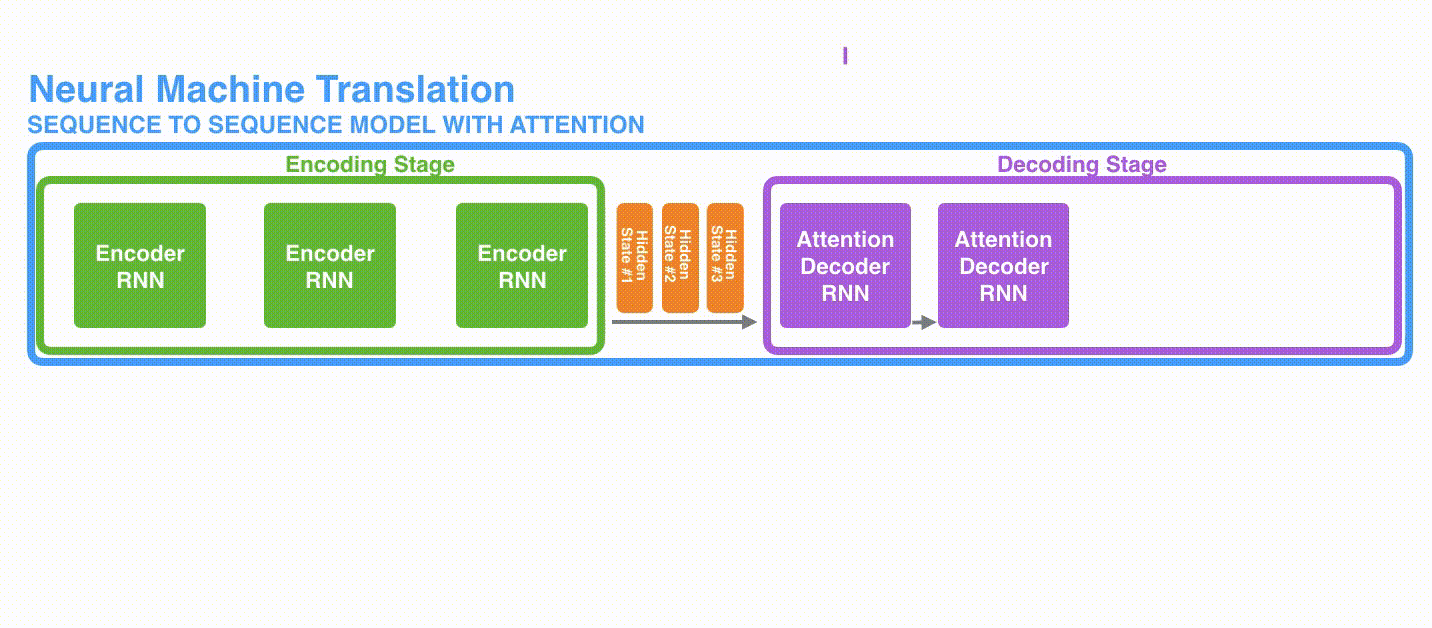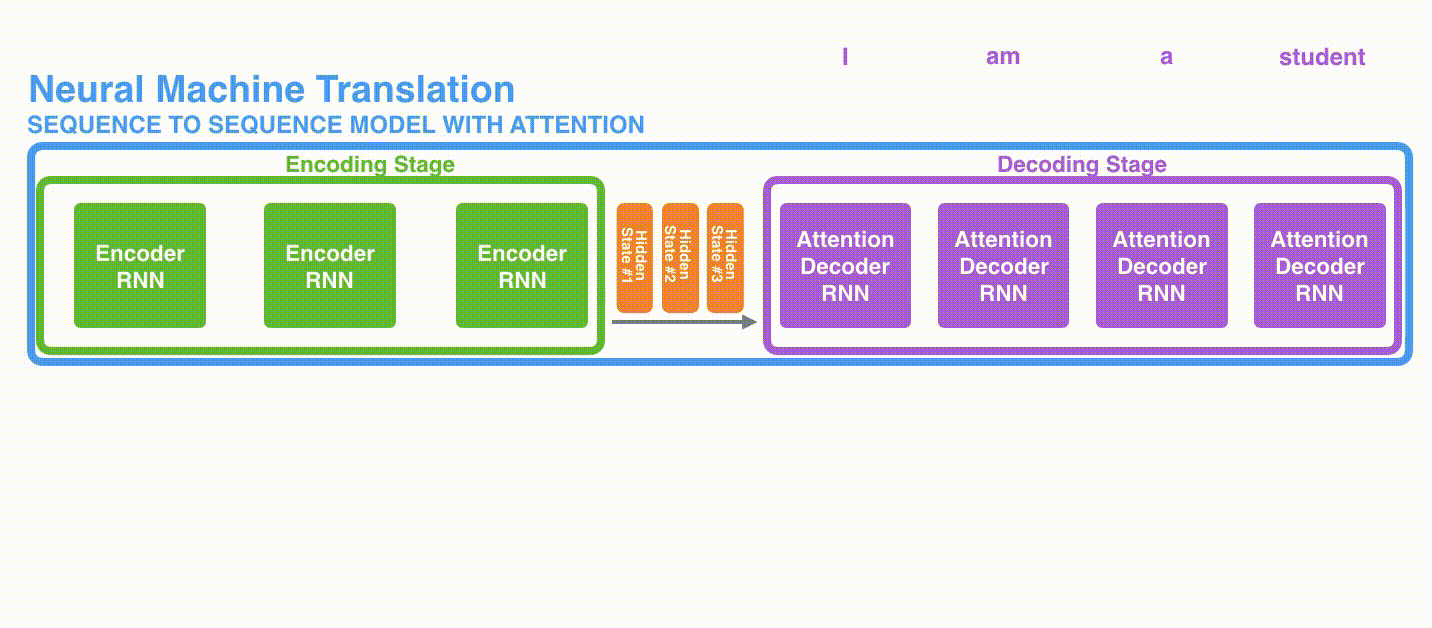
B)注意力模型的解码器在产生输出之前,做了一个额外的 attention 处理。如下图所示,具体为:
- 由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden state(隐藏层状态)。
- 给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
- 所有 hidden state(隐藏层状态)的分数经过 softmax 进行归一化。
- 将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
- 将所有 hidden state 根据对应分数进行加权求和,得到对应时间步的 context 向量。

所以,attention 可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
现在,让我们把所有内容都融合到下面的图中,来看看结合注意力的 seq2seq 模型解码器全流程,动态图展示的是第 4 个时间步:
- 注意力模型的解码器 RNN 的输入包括:一个 word embedding 向量,和一个初始化好的解码器 hidden state,图中是 $h_{init}$。
- RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state,图中为 h4。
- 注意力的步骤:我们使用编码器的所有 hidden state 向量和 h4 向量来计算这个时间步的 context 向量(C4)。
- 我们把 h4 和 C4 拼接起来,得到一个橙色向量。
- 我们把这个橙色向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。
- 根据前馈神经网络的输出向量得到输出单词:假设输出序列可能的单词有 N 个,那么这个前馈神经网络的输出向量通常是 N 维的,每个维度的下标对应一个输出单词,每个维度的数值对应的是该单词的输出概率。
- 在下一个时间步重复 1-6 步骤。
到目前为止,希望你已经知道本文开头提出的 3、4 问题的答案啦:3、seq2seq 处理长文本序列的挑战是什么?4、seq2seq 是如何结合 attention 来解决问题 3 中的挑战的?
最后,我们可视化一下注意力机制,看看在解码器在每个时间步关注了输入序列的哪些部分:
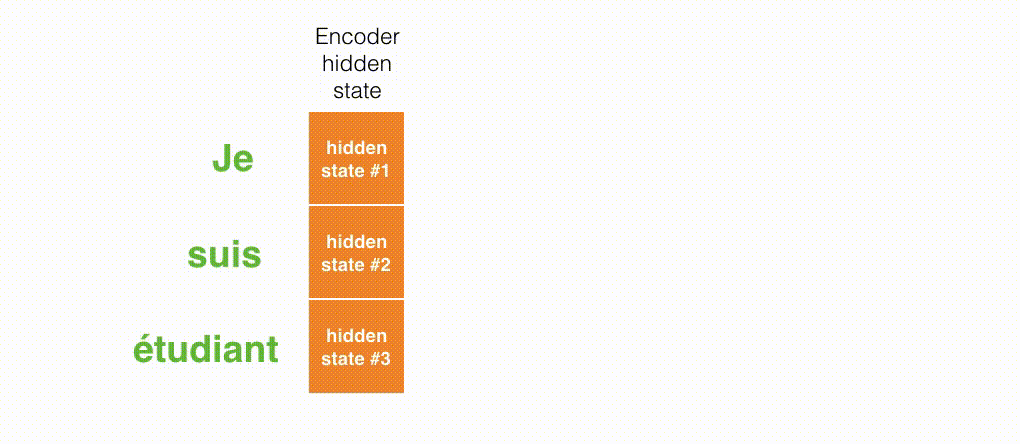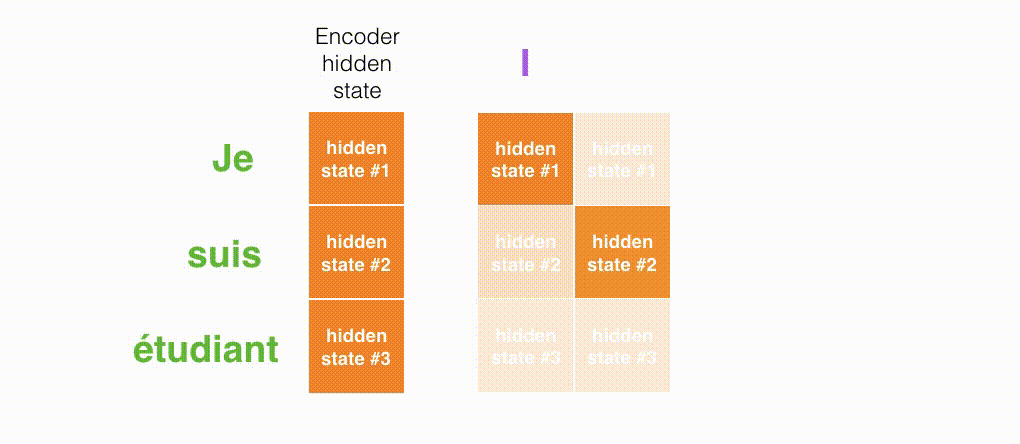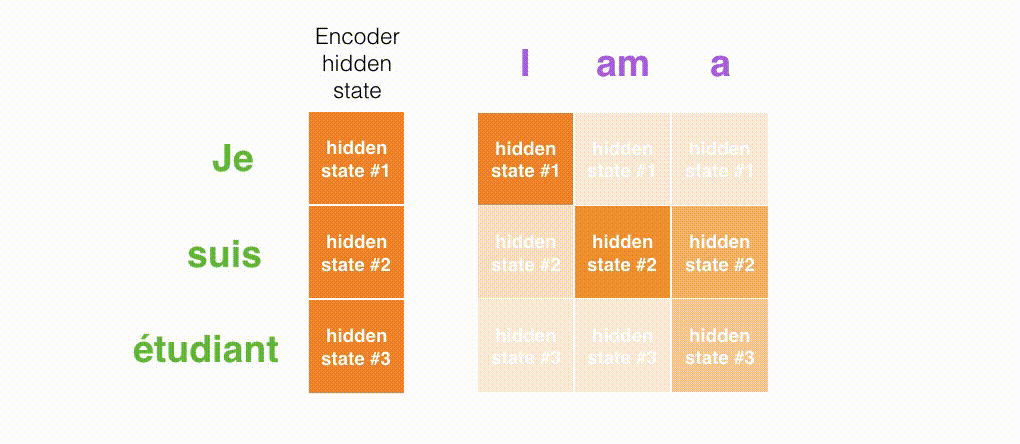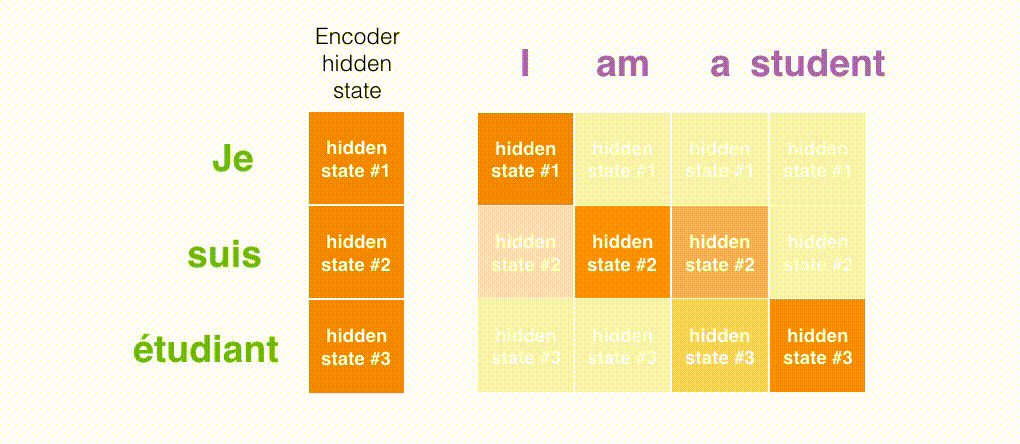
需要注意的是:注意力模型不是无意识地把输出的第一个单词对应到输入的第一个单词,它是在训练阶段学习到如何对两种语言的单词进行对应(在我们的例子中,是法语和英语)。
语言模型与迁移学习
语言模型
Transformer 模型本质上都是预训练语言模型,大都采用自监督学习 (Self-supervised learning) 的方式在大量生语料上进行训练,也就是说,训练这些 Transformer 模型完全不需要人工标注数据。
自监督学习是一种训练目标可以根据模型的输入自动计算的训练方法。
例如下面两个常用的预训练任务:
1)基于句子的前 n 个词来预测下一个词,因为输出依赖于过去和当前的输入,因此该任务被称为因果语言建模 (causal language modeling);

2)基于上下文(周围的词语)来预测句子中被遮盖掉的词语 (masked word),因此该任务被称为遮盖语言建模 (masked language modeling)。

这些语言模型虽然可以对训练过的语言产生统计意义上的理解,例如可以根据上下文预测被遮盖掉的词语,但是如果直接拿来完成特定任务,效果往往并不好。
回忆一下,”因果语言建模”就是上一章中说的统计语言模型,只使用前面的词来预测当前词,由 NNLM 首次运用;而”遮盖语言建模”实际上就是 Word2Vec 模型提出的 CBOW。
因此,我们通常还会采用迁移学习 (transfer learning) 方法,使用特定任务的标注语料,以有监督学习的方式对预训练模型参数进行微调 (fine-tune),以取得更好的性能。
迁移学习
前面已经讲过,预训练是一种从头开始训练模型的方式:所有的模型权重都被随机初始化,然后在没有任何先验知识的情况下开始训练:
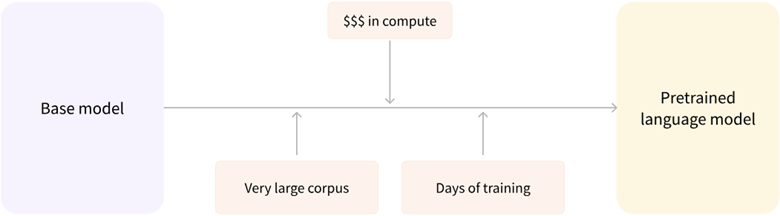
这个过程不仅需要海量的训练数据,而且时间和经济成本都非常高。
因此,大部分情况下,我们都不会从头训练模型,而是将别人预训练好的模型权重通过迁移学习应用到自己的模型中,即使用自己的任务语料对模型进行”二次训练”,通过微调参数使模型适用于新任务。
这种迁移学习的好处是:
- 预训练时模型很可能已经见过与我们任务类似的数据集,通过微调可以激发出模型在预训练过程中获得的知识,将基于海量数据获得的统计理解能力应用于我们的任务;
- 由于模型已经在大量数据上进行过预训练,微调时只需要很少的数据量就可以达到不错的性能;
- 换句话说,在自己任务上获得优秀性能所需的时间和计算成本都可以很小。
例如,我们可以选择一个在大规模英文语料上预训练好的模型,使用arXiv语料进行微调,以生成一个面向学术/研究领域的模型。这个微调的过程只需要很少的数据:我们相当于将预训练模型已经获得的知识”迁移”到了新的领域,因此被称为迁移学习。
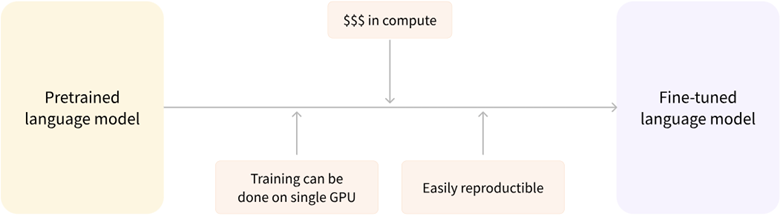
与从头训练相比,微调模型所需的时间、数据、经济和环境成本都要低得多,并且与完整的预训练相比,微调训练的约束更少,因此迭代尝试不同的微调方案也更快、更容易。实践证明,即使是对于自定义任务,除非你有大量的语料,否则相比训练一个专门的模型,基于预训练模型进行微调会是一个更好的选择。
在绝大部分情况下,我们都应该尝试找到一个尽可能接近我们任务的预训练模型,然后微调它,也就是所谓的”站在巨人的肩膀上”。
Transformer的整体架构
Transformer框架简介
Transformer最开始提出来解决机器翻译任务,因此可以看作是seq2seq模型的一种。本小节先抛开Transformer模型中结构具体细节,先从seq2seq的角度对Transformer进行宏观结构的学习。以机器翻译任务为例,先将Transformer这种特殊的seq2seq模型看作一个黑盒,黑盒的输入是法语文本序列,输出是英语文本序列(对比seq2seq框架知识我们可以发现,Transformer宏观结构属于seq2seq范畴,只是将之前seq2seq中的编码器和解码器,从RNN模型替换成了Transformer模型)。
![]()
Transformer的内部,在本质上是一个Encoder-Decoder的结构,即编码器-解码器。
将上图中的中间部分”THE TRANSFORMER”拆开成seq2seq标准结构,得到下图:左边是编码部分encoders,右边是解码器部分decoders。
![]()
下面,再将上图中的编码器和解码器细节绘出,得到下图。Transformer中抛弃了传统的CNN和RNN,整个网络结构完全由Attention机制组成,并且采用了6层Encoder-Decoder结构。我们可以看到,编码部分(encoders)由多层编码器(Encoder)组成(Transformer论文中使用的是6层编码器,这里的层数6并不是固定的,你也可以根据实验效果来修改层数)。同理,解码部分(decoders)也是由多层的解码器(Decoder)组成(论文里也使用了6层解码器)。每层编码器网络结构是一样的,每层解码器网络结构也是一样的。不同层编码器和解码器网络结构不共享参数。
![]()
Transformer和LSTM的最大区别,就是LSTM的训练是迭代的、串行的,必须要等当前字处理完,才可以处理下一个字。而Transformer的训练时并行的,即所有字是同时训练的,这样就大大增加了计算效率。
接下来,我们看一下单层encoder,单层encoder主要由以下两部分组成,如下图所示
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,缩写为FFNN)
编码器的输入文本序列$w_1,w_2,…,w_n$最开始需要经过embedding转换,得到每个单词的向量表示$x_1,x_2,…,x_n$,其中$x_i\in\mathbb{R}^{d}$是维度为$d$的向量,然后所有向量经过一个Self-Attention神经网络层进行变换和信息交互得到$h_1,h_2,…h_n$,其中$h_i\in\mathbb{R}^{d}$是维度为$d$的向量。self-attention层处理一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(你可以类比为:当我们翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)。Self-Attention层的输出会经过前馈神经网络得到新的$x_1,x_2,..,x_n$,依旧是$n$个维度为$d$的向量。这些向量将被送入下一层encoder,继续相同的操作。
![]()
与编码器对应,如下图,解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分(类似于seq2seq模型中的Attention)。
![]()
总结一下,我们基本了解了Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由self-attention和FFNN组成,每个解码层由self-attention、FFN和encoder-decoder attention组成。以上便是Transformer的宏观结构,下面我们开始看宏观结构中的模型细节。
Transformer结构图
下图便是Transformer整体结构图,与seq2seq模型类似,Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder)。
![]()
![]() Transformer使用了位置嵌入 (Positional Encoding) 来理解语言的顺序,使用自注意力机制(Self Attention Mechanism)和全连接层进行计算。
Transformer使用了位置嵌入 (Positional Encoding) 来理解语言的顺序,使用自注意力机制(Self Attention Mechanism)和全连接层进行计算。
Transformer模型主要分为两大部分,分别是 Encoder 和 Decoder。Encoder 负责把输入(语言序列)隐射成隐藏层(下图中第2步用九宫格代表的部分),然后解码器再把隐藏层映射为自然语言序列。例如下图机器翻译的例子(Decoder 输出的时候,是通过 N 层 Decoder Layer 才输出一个 token,并不是通过一层 Decoder Layer 就输出一个 token)
![]()
左侧红框是编码器,右侧红框是解码器,编码器负责把自然语言序列映射成为隐藏层(上图第2步),即含有自然语言序列的数学表达。解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,如情感分析、机器翻译、摘要生成、语义关系抽取等。简单说下,上图每一步都做了什么:
- 输入自然语言序列到编码器: Why do we work?
- 编码器输出的隐藏层,再输入到解码器
- 输入<𝑠𝑡𝑎𝑟𝑡>符号到解码器
- 解码器得到第一个字“为”
- 将得到的第一个字“为”落下来再输入到解码器
- 解码器得到第二个字“什”
- 将得到的第二字再落下来,直到解码器输出<𝑒𝑛𝑑>,即序列生成完成。
Encoder 编码器
编码器即是把自然语言序列映射为隐藏层的数学表达的过程。为了方便学习,编码器可以分为4个部分:
![]()
位置嵌入(Positional Encoding)
我们输入数据 X 维度为 [batch size, sequence length] 的数据,比如“Why do we work?”。batch size 就是 batch 的大小,这里只有一句话,所以 batch size 为1,sequence length 是句子的长度,一共7个字,所以输入的数据维度是 [1, 7]。
我们不能直接将这句话输入到编码器中,因为 Transformer 不认识,我们需要先进行字嵌入,即得到图中的 $X_{embedding}$。简单点说,就是文字到字向量的转换,这种转换是将文字转换为计算机认识的数学表示,用到的方法就是Word2Vec。
得到的 $X_{embedding}$ 的维度是 [batch size, sequence length, embedding dimension],embedding dimension 的大小由 Word2Vec 算法决定,Transformer 采用512长度的字向量。所以 $X_{embedding}$ 的维度是 [1, 7, 512]。
![]()
![]()
我们知道,文字的先后顺序,很重要。比如吃饭没、没吃饭、没饭吃、饭吃没、饭没吃,同样三个字,顺序颠倒,所表达的含义就不同了。
文字的位置信息很重要,Transformer 没有类似 RNN 的循环结构,没有捕捉顺序序列的能力。为了保留这种位置信息交给 Transformer 学习,我们需要用到位置嵌入。
![]()
加入位置信息的方式非常多,最简单的可以是直接将绝对坐标0,1,2编码。Transformer 采用的是 sin-cos 规则,使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:
$$\begin{aligned}PE_{(pos,2i)}&=\sin(pos/10000^{2i/d_{model}})\\PE_{(pos,2i+1)}&=\cos(pos/10000^{2i/d_{model}})\end{aligned}$$
上式中 pos 指的是句中字的位置,取值范围是 [0, max_sequence_length),i 指的是字嵌入的维度,取值范围是 [0, embedding_dimension)。
上面有 sin 和 cos 一组公式,也就是对应着 embedding_dimension 维度的一组奇数和偶数的序号的维度,从而产生不同的周期性变化。
可以用代码,简单看下效果。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个 positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
# 归一化, 用位置嵌入的每一行除以它的模长
# denominator = np.sqrt(np.sum(position_enc**2, axis=1, keepdims=True))
# position_enc = position_enc / (denominator + 1e-8)
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
plt.show()
![]()
plt.figure(figsize=(8, 5))
plt.plot(positional_encoding[1:, 1], label="dimension 1")
plt.plot(positional_encoding[1:, 2], label="dimension 2")
plt.plot(positional_encoding[1:, 3], label="dimension 3")
plt.legend()
plt.xlabel("Sequence length")
plt.ylabel("Period of Positional Encoding")
plt.show()
![]()
就这样,产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。
最后,将$X_{embedding}$和位置嵌入相加(维度相同,可以直接相加),得到该字真正的向量表示,然后送给下一层。
自注意力层(Self-Attention Mechanism)
Transformer模型的标志就是采用了注意力层 (Attention Layers)的结构,前面也说过,提出Transformer结构的论文名字就叫《Attention Is All You Need》。顾名思义,注意力层的作用就是让模型在处理文本时,将注意力只放在某些词语上。
例如要将英文“You like this course”翻译为法语,由于法语中“like”的变位方式因主语而异,因此需要同时关注相邻的词语“You”。同样地,在翻译“this”时还需要注意“course”,因为“this”的法语翻译会根据相关名词的极性而变化。对于复杂的句子,要正确翻译某个词语,甚至需要关注离这个词很远的词。
同样的概念也适用于其他NLP任务:虽然词语本身就有语义,但是其深受上下文的影响,同一个词语出现在不同上下文中可能会有完全不同的语义(例如“我买了一个苹果”和“我买了一个苹果手机”中的“苹果”)。
我们在上一章中已经讨论过多义词的问题,这也是Word2Vec这些静态模型所解决不了的。
Self-Attention综述
self-attention,其思想和attention类似,但是self-attention是Transformer用来将其他相关单词的“理解”转换成我们正在处理的单词的一种思路。
自注意力机制与传统注意力的主要区别在于:
- 自我参照:自注意力机制是序列自身对自身的注意,而不是对外部序列。
- 全局依赖捕获:不受局部窗口限制,能捕获序列中任意距离的依赖关系。
自注意力机制能够并行处理整个序列,不受序列长度的限制,从而实现了显著的计算效率。
- 并行化优势:自注意力计算可同时进行,提高了训练和推理速度。
在Transformer中,自注意力机制是关键组成部分:
- 多头注意力:通过多头注意力,模型能同时学习不同的依赖关系,增强了模型的表现力。
- 权重可视化:自注意力权重可被用来解释模型的工作方式,增加了可解释性。
假设我们想要翻译的句子是:The animal didn’t cross the street because it was too tired
这个句子中的 it 是一个指代词,那么 it 指的是什么呢?它是指 animal 还是 street?这个问题对人来说,是很简单的,但是对模型来说并不是那么容易。但是,如果模型引入了Self Attention机制之后,便能够让模型把it和animal关联起来了。同样的,当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
与RNN对比:RNN在处理序列中的一个词时,会考虑句子前面的词传过来的hidden state,而hidden state就包含了前面的词的信息;而Self Attention机制指的是,当前词会直接关注到自己句子中前后相关的所有词语,如下图 it的例子:
![]()
上图所示的it是一个真实的例子,是当Transformer在第5层编码器编码“it”时的状态,可视化之后显示it有一部分注意力集中在了“The animal”上,并且把这两个词的信息融合到了”it”中。
Self-Attention细节
先通过一个简单的例子来理解一下什么是“self-attention自注意力机制”?假设一句话包含两个单词:Thinking Machines。自注意力的一种理解是:Thinking-Thinking,Thinking-Machines,Machines-Thinking,Machines-Machines,共$2^2$种两两attention。那么具体如何计算呢?假设Thinking、Machines这两个单词经过词向量算法得到向量是$X_1, X_2$:
$$1: q_1 = X_1 W^Q, q_2 = X_2 W^Q; k_1 = X_1 W^K, k_2 = X_2 W^K; v_1 = X_1 W^V, v_2 = X_2 W^V, W^Q, W^K, W^K \in \mathbb{R}^{d_x \times d_k}$$
$$2-3: score_{11} = \frac{q_1 \cdot q_1}{\sqrt{d_k}}, score_{12} = \frac{q_1 \cdot q_2}{\sqrt{d_k}}; score_{21} = \frac{q_2 \cdot q_1}{\sqrt{d_k}}, score_{22} = \frac{q_2 \cdot q_2}{\sqrt{d_k}};$$
$$4: score_{11} = \frac{e^{score_{11}}}{e^{score_{11}} + e^{score_{12}}}, score_{12} = \frac{e^{score_{12}}}{e^{score_{11}} + e^{score_{12}}}; score_{21} = \frac{e^{score_{21}}}{e^{score_{21}} + e^{score_{22}}}, score_{22} = \frac{e^{score_{22}}}{e^{score_{21}} + e^{score_{22}}}$$
$$5-6: z_1 = v_1 \times score_{11} + v_2 \times score_{12}; z_2 = v_1 \times score_{21} + v_2 \times score_{22}$$
下面,我们将上诉self-attention计算的6个步骤进行可视化。
第1步:对输入编码器的词向量进行线性变换得到:Query向量: $q_1, q_2$,Key向量: $k_1, k_2$,Value向量: $v_1, v_2$。这3个向量是词向量分别和3个参数矩阵相乘得到的,而这个矩阵也是是模型要学习的参数。
![]() Query 向量,Key 向量,Value 向量是什么含义呢?
Query 向量,Key 向量,Value 向量是什么含义呢?
其实它们就是 3 个向量,给它们加上一个名称,可以让我们更好地理解 Self-Attention 的计算过程和逻辑。attention 计算的逻辑常常可以描述为:query 和 key 计算相关或者叫 attention 得分,然后根据 attention 得分对 value 进行加权求和。
第 2 步:计算 Attention Score(注意力分数)。假设我们现在计算第一个词 Thinking 的 Attention Score(注意力分数),需要根据 Thinking 对应的词向量,对句子中的其他词向量都计算一个分数。这些分数决定了我们在编码 Thinking 这个词时,需要对句子中其他位置的词向量的权重。
Attention score 是根据 “Thinking” 对应的 Query 向量和其他位置的每个词的 Key 向量进行点积得到的。Thinking 的第一个 Attention Score 就是 $q_1$ 和 $k_1$ 的内积,第二个分数就是 $q_1$ 和 $k_2$ 的点积。这个计算过程在下图中进行了展示,下图里的具体得分数据是为了表达方便而自定义的。
![]()
第 3 步:把每个分数除以 $\sqrt{d_k}$,$d_{k}$ 是 Key 向量的维度。你也可以除以其他数,除以一个数是为了在反向传播时,求梯度时更加稳定。
第 4 步:接着把这些分数经过一个 Softmax 函数,Softmax 可以将分数归一化,这样使得分数都是正数并且加起来等于 1,如下图所示。这些分数决定了 Thinking 词向量,对其他所有位置的词向量分别有多少的注意力。
![]()
第 5 步:得到每个词向量的分数后,将分数分别与对应的 Value 向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
第 6 步:把第 5 步得到的 Value 向量相加,就得到了 SelfAttention 在当前位置(这里的例子是第 1 个位置)对应的输出。
最后,在下图展示了对第一个位置词向量计算 SelfAttention 的全过程。最终得到的当前位置(这里的例子是第一个位置)词向量会继续输入到前馈神经网络。注意:上面的 6 个步骤每次只能计算一个位置的输出向量,在实际的代码实现中,SelfAttention 的计算过程是使用矩阵快速计算的,一次就得到所有位置的输出向量。
![]()
Self-Attention 矩阵计算
将 self-attention 计算 6 个步骤中的向量放一起,比如 $X=[x_1;x_2]$,便可以进行矩阵计算啦。下面,依旧按步骤展示 self-attention 的矩阵计算方法。
$$X=[X_1;X_2]\Q=XW^Q,K=XW^K,V=XW^V\Z=softmax(\frac{QK^T}{\sqrt{d_k}})V$$
第 1 步:计算 Query,Key,Value 的矩阵。首先,我们把所有词向量放到一个矩阵 X 中,然后分别和 3 个权重矩阵 $W^Q,W^KW^V$ 相乘,得到 Q,K,V 矩阵。矩阵 X 中的每一行,表示句子中的每一个词的词向量。Q,K,V 矩阵中的每一行表示 Query 向量,Key 向量,Value 向量,向量维度是 $d_k$。
![]()
![]()
第 2 步:由于我们使用了矩阵来计算,我们可以把上面的第 2 步到第 6 步压缩为一步,直接得到 SelfAttention 的输出。
![]()
多头注意力机制
Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了 Self-Attention。这种机制从如下两个方面增强了 attention 层的能力:
- 它扩展了模型关注不同位置的能力。在上面的例子中,第一个位置的输出 $z_1$ 包含了句子中其他每个位置的很小一部分信息,但 $z_1$ 仅仅是单个向量,所以可能仅由第 1 个位置的信息主导了。而当我们翻译句子:The animal didn’t cross the street because it was too tired 时,我们不仅希望模型关注到 “it” 本身,还希望模型关注到 “The” 和 “animal”,甚至关注到 “tired”。这时,多头注意力机制会有帮助。
- 多头注意力机制赋予 attention 层多个“子表示空间”。下面我们会看到,多头注意力机制会有多组 $W^Q,W^KW^V$ 的权重矩阵(在 Transformer 的论文中,使用了 8 组注意力),,因此可以将 $X$ 变换到更多种子空间进行表示。接下来我们也使用 8 组注意力头(attention heads))。每一组注意力的权重矩阵都是随机初始化的,但经过训练之后,每一组注意力的权重 $W^Q,W^KW^V$ 可以把输入的向量映射到一个对应的”子表示空间“。
![]()
在多头注意力机制中,我们为每组注意力设定单独的 $W_Q,W_K,W_V$ 参数矩阵。将输入 X 和每组注意力的 $W_Q,W_K,W_V$ 相乘,得到 8 组 Q,K,V 矩阵。
接着,我们把每组 K,Q,V 计算得到每组的 Z 矩阵,就得到 8 个 Z 矩阵。
![]()
由于前馈神经网络层接收的是 1 个矩阵(其中每行的向量表示一个词),而不是 8 个矩阵,所以我们直接把 8 个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵 $W^O$ 相乘做一次变换,映射到前馈神经网络层所需要的维度。
![]()
总结一下就是:
- 把 8 个矩阵 {Z0,Z1…,Z7} 拼接起来
- 把拼接后的矩阵和 WO 权重矩阵相乘
- 得到最终的矩阵 Z,这个矩阵包含了所有 attention heads(注意力头)的信息。这个矩阵会输入到 FFNN(Feed Forward Neural Network) 层。
以上就是多头注意力的全部内容。最后将所有内容放到一张图中:
![]()
学习了多头注意力机制,让我们再来看下当我们前面提到的it例子,不同的attention heads(注意力头)对应的“it”attention了哪些内容。下图中的绿色和橙色线条分别表示2组不同的attention heads:
![]()
当我们编码单词”it”时,其中一个attention head(橙色注意力头)最关注的是”the animal”,另外一个绿色attention head关注的是”tired”。因此在某种意义上,”it”在模型中的表示,融合了”animal”和”tire”的部分表达。
残差连接与层归一化
加入了残差设计和层归一化操作,目的是为了防止梯度消失,加快收敛。
残差设计
我们在上一步得到了经过注意力矩阵加权之后的V,也就是Attention(Q,K,V),我们对它进行一下转置,使其和$X_{embedding}$的维度一致,也就是[batch size, sequence length, embedding dimension],然后把他们加起来做残差连接,直接进行元素相加,因为他们的维度一致:
$$X_{embedding}+Attention(Q,\ K,\ V)$$
在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层:
$$X+SubLayer(X)$$
层归一化
Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
说到normalization,那就肯定得提到BatchNormalization。BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
BN的具体做法就是对每一小批数据,在批这个方向上做归一化。如下图所示:
![]()
可以看到,左半边求均值是沿着数据batch_size的方向进行的,其计算公式如下:
$$BN(x_i)=\alpha×\frac{x_i-\mu_b}{\sqrt{\sigma^2_B+\epsilon}}+\beta$$
那么什么是Layer normalization呢?它也是归一化数据的一种方式,不过LN是在每一个样本上计算均值和方差,而不是BN那种在批方向计算均值和方差!
LayerNormalization的作用是把神经网络中隐藏层归一为标准正态分布,也就是$i.i.d$独立同分布,以起到加快训练速度,加速收敛的作用。
LN的公式为:
$$LN(x_i)=\alpha×\frac{x_i-\mu_L}{\sqrt{\sigma^2_L+\epsilon}}+\beta$$
残差连接
到目前为止,我们计算得到了self-attention的输出向量。而单层encoder里后续还有两个重要的操作:残差连接、标准化。
编码器的每个子层(Self Attention层和FFNN)都有一个残差连接和层标准化(layer-normalization),如下图所示。
![]()
将Self-Attention层的层标准化(layer-normalization)和涉及的向量计算细节都进行可视化,如下所示:
![]()
编码器和和解码器的子层里面都有层标准化(layer-normalization)。假设一个Transformer是由2层编码器和两层解码器组成的,将全部内部细节展示起来如下图所示。
![]()
前馈网络
前馈网络Feed Forward,其实就是两层线性映射并用激活函数激活。然后经过这个网络激活后,再经过一个残差连接和层归一化,即可输出。
Transformer中的Feed Forward就是普通的全连接网络,激活函数使用的是ReLU:
$$FFN(x)=max(0,xW_1+b_1)W_2+b_2$$
Encoder整体结构
经过上面3个步骤,我们已经基本了解了Encoder的主要构成部分。
用一个更直观的图表示如下:
![]() 文字描述为:
文字描述为:
输入$x_1,x_2$经 self-attention 层之后变成$z_1,x_2$,然后和输入$x_1,x_2$进行残差连接,经过 LayerNorm 后输出给全连接层。全连接层也有一个残差连接和一个 LayerNorm,最后再输出给下一个 Encoder(每个 EncoderBlock 中的 FeedForward 层权重都是共享的)公式描述为:
1)字向量与位置编码
$$X=\text{Embedding-Lookup}(X)+\text{Positional-Encoding}$$
2)自注意力机制
$$\begin{align}Q&=\text{Linear}_q(X)=XW_{Q}\\K&=\text{Linear}_k(X)=XW_{K}\\V&=\text{Linear}_v(X)=XW_{V}\\X_{attention}&=\text{Self-Attention}(Q,K,V)\end{align}$$
3)self-attention 残差连接与 LayerNormalization
$$\begin{align}X_{attention}&=X+X_{attention}\\X_{attention}&=\text{LayerNorm}(X_{attention})\end{align}$$
4)前馈网络 FeedForward
$$X_{hidden}=\text{Linear}(\text{ReLU}(\text{Linear}(X_{attention})))$$
5)FeedForward 残差连接与 LayerNormalization
$$\begin{align}X_{hidden}&=X_{attention}+X_{hidden}\\X_{hidden}&=\text{LayerNorm}(X_{hidden})\end{align}
其中:
$$X_{hidden}\in\mathbb{R}^{batch\_size \*\ seq\_len. \*\ embed\_dim}$$
Decoder 解码器
现在我们已经介绍了编码器中的大部分概念,我们也基本知道了编码器的原理。现在让我们来看下,编码器和解码器是如何协同工作的。
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的 K、V 输入,其中 K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的 Encoder-Decoder Attention 层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。
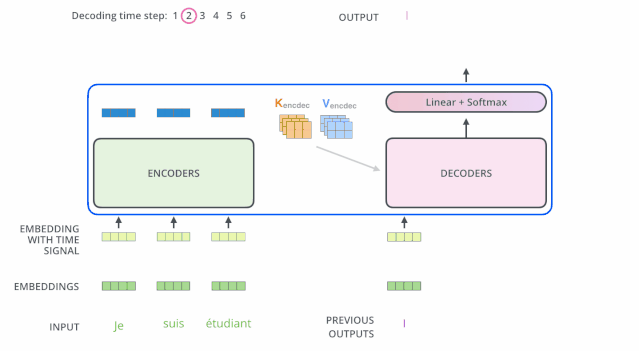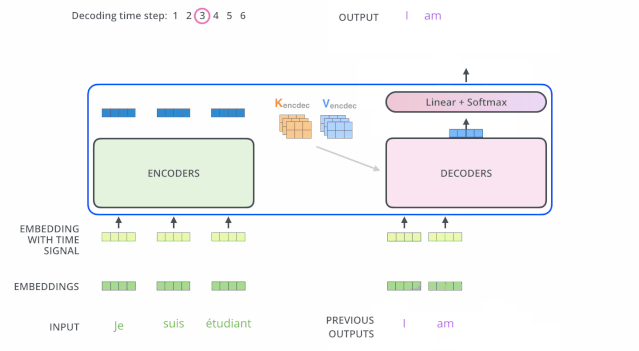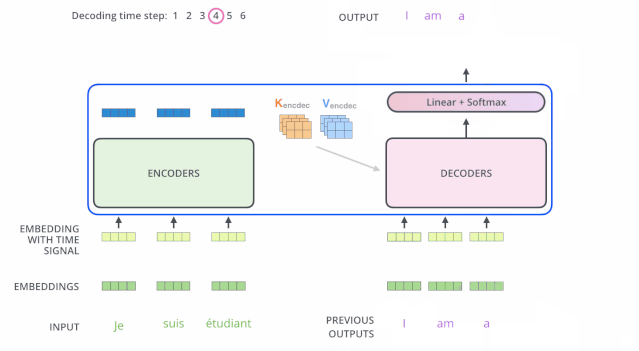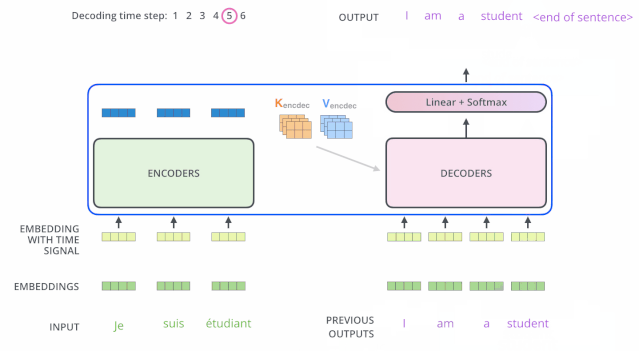
解码(decoding)阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为输入 Q 和编码器的输出 K、V 共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。如下图所示:
![]()
解码器中的 Self Attention 层,和编码器中的 Self Attention 层的区别:
- 在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将 attention score 设置成-inf)。
- 解码器 Attention 层是使用前一层的输出来构造 Query 矩阵,而 Key 矩阵和 Value 矩阵来自于编码器最终的输出。
Decoder 的整体框架
![]()
我们先从 High Level 的角度观察一下 Decoder 结构,从下到上依次是:
- Masked Multi-Head Self-Attention
- Multi-Head Encoder-Decoder Attention
- Feed Forward Network
和 Encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。Decoder 的中间部件并不复杂,大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些细节。
Masked Self-Attention
具体来说,传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。
而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
举个例子,Decoder 的 ground truth 为“start 起始符号 I am fine”,我们将这个句子输入到 Decoder 中,经过 Word Embedding 和 Positional Encoding 之后,将得到的矩阵做三次线性变换$W_Q,W_K,W_V$。然后进行 self-attention 操作,首先通过$\frac{Q\times K^T}{\sqrt{d_k}}$得到 Scaled Scores,接下来非常关键,我们要对 Scaled Scores 进行 Mask,举个例子,当我们输入“I”时,模型目前仅知道包括“I”在内之前所有字的信息,即“start 起始符号”和“I”的信息,不应该让其知道“I”之后词的信息。
道理很简单,我们做预测的时候是按照顺序一个字一个字的预测,怎么能这个字都没预测完,就已经知道后面字的信息了呢?Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可:
![]()
之后再做 softmax,就能将-inf 变为 0,得到的这个矩阵即为每个字之间的权重:
![]()
Multi-Head Self-Attention 无非就是并行的对上述步骤多做几次,前面 Encoder 也介绍了,这里就不多赘述了。
Masked Encoder-Decoder Attention
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的 K,V 为 Encoder 的输出(不然 Encoder 辛辛苦苦做的输出就没用了),Q 为 Decoder 中 Masked Self-Attention 的输出。
![]()
线性层和 softmax
Decoder最终的输出是一个向量,其中每个元素是浮点数。我们怎么把这个向量转换为单词呢?这是线性层和softmax完成的。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为logits向量:假设我们的模型有10000个英语单词(模型的输出词汇表),此logits向量便会有10000个数字,每个数表示一个单词的分数。然后,Softmax层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
![]()
损失函数
Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播。这一小节,我们用一个简单的例子来说明训练过程的loss计算:把“merci”翻译为“thanks”。
我们希望模型解码器最终输出的概率分布,会指向单词”thanks“(在“thanks”这个词的概率最高)。但是,一开始模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远,如下图所示,正确的概率分布应该是“thanks”单词的概率最大。但是,由于模型的参数都是随机初始化的,所示一开始模型预测所有词的概率几乎都是随机的。
![]()
只要Transformer解码器预测了组概率,我们就可以把这组概率和正确的输出概率做对比,然后使用反向传播来调整模型的权重,使得输出的概率分布更加接近整数输出。
那我们要怎么比较两个概率分布呢?我们可以简单的用两组概率向量的的空间距离作为loss(向量相减,然后求平方和,再开方),当然也可以使用交叉熵(cross-entropy)和KL散度(Kullback–Leibler divergence)。
由于上面仅有一个单词的例子太简单了,我们可以再看一个复杂一点的句子。句子输入是:“jesuisétudiant”,输出是:“iamastudent”。这意味着,我们的transformer模型解码器要多次输出概率分布向量:
- 每次输出的概率分布都是一个向量,长度是vocab_size(前面约定最大vocab size,也就是向量长度是6,但实际中的vocab size更可能是30000或者50000)
- 第1次输出的概率分布中,最高概率对应的单词是“i”
- 第2次输出的概率分布中,最高概率对应的单词是“am”
- 以此类推,直到第5个概率分布中,最高概率对应的单词是“<eos>”,表示没有下一个单词了
于是我们目标的概率分布长下面这个样子:
![]()
我们用例子中的句子训练模型,希望产生图中所示的概率分布我们的模型在一个足够大的数据集上,经过足够长时间的训练后,希望输出的概率分布如下图所示:
![]()
我们希望模型经过训练之后可以输出的概率分布也就对应了正确的翻译。当然,如果你要翻译的句子是训练集中的一部分,那输出的结果并不能说明什么。我们希望模型在没见过的句子上也能够准确翻译。
额外提一下greedy decoding和beam search的概念:
- Greedy decoding:由于模型每个时间步只产生一个输出,我们这样看待:模型是从概率分布中选择概率最大的词,并且丢弃其他词。这种方法叫做贪婪解码(greedy decoding)。
- Beam search:每个时间步保留k个最高概率的输出词,然后在下一个时间步,根据上一个时间步保留的k个词来确定当前应该保留哪k个词。假设k=2,第一个位置概率最高的两个输出的词是”I“和”a“,这两个词都保留,然后根据第一个词计算第2个位置的词的概率分布,再取出第2个位置上2个概率最高的词。对于第3个位置和第4个位置,我们也重复这个过程。这种方法称为集束搜索(beam search)。
Transformer训练和推理过程
训练过程:
对于训练过程,我们是将原始输入和正确答案一同输入的,训练过程采用Teacher Forcing,而对于正确答案输入是采用了Mask操作,就是为了不让模型看到当前词之后的信息,这是可以并行进行的。
推理过程:
但是对于推理过程,是不会输入正确答案的,而且和RNN运行差不多是一个一个的,首先会给Decoder输入开始标志,然后经过Decoder会预测出“I”单词,然后拿着这个“I”单词继续喂入Decoder去预测“love”,但后拿着“love”去预测“you”,最后拿着“you”去预测结束标志。
对于翻译任务来说,这是序列到序列的问题,显然每次的输出序列的长度是不一致的,所以需要一个结束标志来表明这句话已经翻译完成,所以需要按顺序一个一个翻译,不断拿着已经翻译出的词送入模型,知道预测出结束标志为止。
Transformer家族
标准的Transformer模型主要由两个模块构成:
- Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
- Decoder(右边):负责生成输出,使用Encoder输出的语义表示结合其他输入来生成目标序列。
![]()
这两个模块可以根据任务的需求而单独使用。虽然新的Transformer模型层出不穷,它们采用不同的预训练目标在不同的数据集上进行训练,但是依然可以按模型结构将它们大致分为三类:
- 纯Encoder模型(例如BERT),又称自编码(auto-encoding)Transformer模型;
- 纯Decoder模型(例如GPT),又称自回归(auto-regressive)Transformer模型;
- Encoder-Decoder模型(例如BART、T5),又称Seq2Seq(sequence-to-sequence)Transformer模型。
![]()
Encoder分支
纯Encoder模型只使用Transformer模型中的Encoder模块,也被称为自编码(auto-encoding)模型。在每个阶段,注意力层都可以访问到原始输入句子中的所有词语,即具有“双向(Bi-directional)”注意力。
纯Encoder模型通常通过破坏给定的句子(例如随机遮盖其中的词语),然后让模型进行重构来进行预训练,最适合处理那些需要理解整个句子语义的任务,例如句子分类、命名实体识别(词语分类)、抽取式问答。
BERT是第一个基于Transformer结构的纯Encoder模型,它在提出时横扫了整个NLP界,在流行的GLUE基准上超过了当时所有的最强模型。随后的一系列工作对BERT的预训练目标和架构进行调整以进一步提高性能。目前,纯Encoder模型依然在NLP行业中占据主导地位。
下面简略介绍一下BERT模型及它的常见变体:
- BERT:通过预测文本中被遮盖的词语和判断一个文本是否跟随另一个来进行预训练,前一个任务被称为遮盖语言建模 (Masked Language Modeling, MLM),后一个任务被称为下句预测 (Next Sentence Prediction, NSP);
- DistilBERT:尽管BERT性能优异,但它的模型大小使其难以部署在低延迟需求的环境中。通过在预训练期间使用知识蒸馏 (knowledge distillation) 技术,DistilBERT在内存占用减少40%、计算速度提高60%的情况下,依然可以保持97%的性能;
- RoBERTa:BERT之后的一项研究表明,通过修改预训练方案可以进一步提高性能。RoBERTa在更多的训练数据上,以更大的批次训练了更长的时间,并且放弃了NSP任务。与BERT模型相比,这些改变显著地提高了模型的性能;
- XLM:跨语言语言模型 (XLM) 探索了构建多语言模型的多个预训练目标,包括来自GPT的自回归语言建模和来自BERT的MLM,还将MLM拓展到多语言输入,提出了翻译语言建模 (Translation Language Modeling, TLM)。XLM在多个多语言NLU基准和翻译任务上都取得了最好的性能;
- XLM-RoBERTa:跟随XLM和RoBERTa,XLM-RoBERTa (XLM-R) 通过升级训练数据来改进多语言预训练。其基于CommonCrawl创建了一个5TB的语料,然后运用MLM训练编码器,由于没有平行对照文本,因此移除了XLM的TLM目标。最终,该模型大幅超越了XLM和多语言BERT变体;
- ALBERT:ALBERT通过三处变化使得Encoder架构更高效:首先将词嵌入维度与隐藏维度解耦以减少模型参数;其次所有模型层共享参数;最后将NSP任务替换为句子排序预测(判断句子顺序是否被交换)。这些变化使得可以用更少的参数训练更大的模型,并在NLU任务上取得了优异的性能;
- ELECTRA:MLM在每个训练步骤中只有被遮盖掉词语的表示会得到更新。ELECTRA使用了一种双模型方法来解决这个问题:第一个模型继续按标准MLM工作;第二个模型(鉴别器)则预测第一个模型的输出中哪些词语是被遮盖的,这使得训练效率提高了30倍。下游任务使用时,鉴别器也参与微调;
- DeBERTa:DeBERTa模型引入了两处架构变化。首先将词语的内容与相对位置分离,使得自注意力层 (Self-Attention) 层可以更好地建模邻近词语对的依赖关系;此外在解码头的softmax层之前添加了绝对位置嵌入。DeBERTa是第一个在SuperGLUE 基准上击败人类的模型。
Decoder分支
纯Decoder模型只使用Transformer模型中的Decoder模块。在每个阶段,对于给定的词语,注意力层只能访问句子中位于它之前的词语,即只能迭代地基于已经生成的词语来逐个预测后面的词语,因此也被称为自回归 (auto-regressive) 模型。
纯Decoder模型的预训练通常围绕着预测句子中下一个单词展开。纯Decoder模型适合处理那些只涉及文本生成的任务。
对Transformer Decoder模型的探索在在很大程度上是由OpenAI 带头进行的,通过使用更大的数据集进行预训练,以及将模型的规模扩大,纯Decoder模型的性能也在不断提高。
下面就简要介绍一些常见的生成模型:
- GPT:结合了Transformer Decoder架构和迁移学习,通过根据上文预测下一个单词的预训练任务,在BookCorpus数据集上进行了预训练。GPT模型在分类等下游任务上取得了很好的效果;
- GPT-2:受简单且可扩展的预训练方法的启发,OpenAI通过扩大原始模型和训练集创造了GPT-2,它能够生成篇幅较长且语义连贯的文本;
- CTRL:GPT-2虽然可以根据模板 (prompt) 续写文本,但是几乎无法控制生成序列的风格。条件Transformer语言模型 (Conditional Transformer Language, CTRL) 通过在序列开头添加特殊的”控制符”以控制生成文本的风格,这样只需要调整控制符就可以生成多样化的文本;
- GPT-3:将GPT-2进一步放大100倍,GPT-3具有1750亿个参数。除了能生成令人印象深刻的真实篇章之外,还展示了小样本学习 (few-shot learning) 的能力。这个模型目前没有开源;
- GPT-Neo/ GPT-J-6B:由于GPT-3没有开源,因此一些旨在重新创建和发布GPT-3规模模型的研究人员组成了EleutherAI,训练出了类似GPT的GPT-Neo和GPT-J-6B。当前公布的模型具有3、2.7、60亿个参数,在性能上可以媲美较小版本的GPT-3模型。
Encoder-Decoder分支
Encoder-Decoder模型(又称Seq2Seq模型)同时使用Transformer架构的两个模块。在每个阶段,Encoder的注意力层都可以访问初始输入句子中的所有单词,而Decoder的注意力层则只能访问输入中给定词语之前的词语(即已经解码生成的词语)。
Encoder-Decoder模型可以使用Encoder或Decoder模型的目标来完成预训练,但通常会包含一些更复杂的任务。例如,T5通过随机遮盖掉输入中的文本片段进行预训练,训练目标则是预测出被遮盖掉的文本。Encoder-Decoder模型适合处理那些需要根据给定输入来生成新文本的任务,例如自动摘要、翻译、生成式问答。
下面简单介绍一些在自然语言理解 (NLU) 和自然语言生成 (NLG) 领域的Encoder-Decoder模型:
- T5:将所有NLU和NLG任务都转换为Seq2Seq形式统一解决(例如,文本分类就是将文本送入Encoder,然后Decoder生成文本形式的标签)。T5通过MLM及将所有SuperGLUE任务转换为Seq2Seq任务来进行预训练。最终,具有110亿参数的大版本T5在多个基准上取得了最优性能。
- BART:同时结合了BERT和GPT的预训练过程。将输入句子通过遮盖词语、打乱句子顺序、删除词语、文档旋转等方式破坏后传给Encoder编码,然后要求Decoder能够重构出原始的文本。这使得模型可以灵活地用于NLU或NLG任务,并且在两者上都实现了最优性能。
- M2M-100:语言对之间可能存在共享知识可以用来处理小众语言之间的翻译。M2M-100是第一个可以在100种语言之间进行翻译的模型,并且对小众的语言也能生成高质量的翻译。该模型使用特殊的前缀标记来指示源语言和目标语言。
BigBird:由于注意力机制的内存要求,Transformer 模型只能处理一定长度内的文本。BigBird 通过使用线性扩展的稀疏注意力形式,将可处理的文本长度从大多数模型的 512 扩展到 4096,这对于处理文本摘要等需要捕获长距离依赖的任务特别有用。
模型分支的选择
使用编码器或解码器,具体取决于您要解决的任务类型。下表总结了这一点:
| 模型 | 示例 | 任务 |
| 编码器 | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | 句子分类、命名实体识别、从文本中提取答案 |
| 解码器 | CTRL, GPT, GPT-2, TransformerXL | 文本生成 |
| 编码器-解码器 | BART, T5, Marian, mBART | 文本摘要、翻译、生成问题的回答 |
参考链接:



这么好的文章怎么能没有评论!