背景与基础
目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。
通常情况下,Tokenizer 有三种粒度:word/char/subword
- word: 按照词进行分词,如: Today is sunday. 则根据空格或标点进行分割 [today, is, sunday, .]
- character:按照单字符进行分词,就是以 char 为最小粒度。如:Today is sunday. 则会分割成 [t,o,d,a,y,….,s,u,n,d,a,y,.]
- subword:按照词的 subword 进行分词。如:Today is sunday. 则会分割成 [to,day,is,s,un,day,.]
WordLevelTokenizer
word/词,是最自然的语言单元。对于英文等自然语言来说,存在着天然的分隔符,如空格或一些标点符号等,对词的切分相对容易。但是对于一些东亚文字包括中文来说,就需要某种分词算法才行。对于中文,词到底分成什么粒度,“苹果手机”到底是一个词还是二个词呢?“武汉市/长江/大桥/欢迎/你”与“武汉/市长/江大桥/欢迎/你”应该选择哪个方案呢?此外,对于“因吹斯汀”这些新词怎么识别呢?
除了如何切分成词外,还有一个最大的问题是结果集太大。比如 TransformerXL 中,使用标点和空格,切分后的词表大小有 267K,如此大的词表,不管是对存储还是计算都有压力。
基于词的切分,会造成:
- 词表规模过大
- 一定会存在 UNK(在自然语言处理中,UNK 通常表示“未知”或“未登录”等意思。当在训练数据中遇到一个未知的词时,就会用 UNK 来代替这个未知的词。在基于词的切分中,由于词表规模过大或一些生僻的词没有出现在词表中,或者一些单词形式变化(如单数变成复数)没有在词表中,因此会出现 UNK,造成信息丢失。),造成信息丢失
- 不能学习到词缀之间的关系,例如:dog 与 dogs,happy 与 unhappy
CharLevelTokenizer
既然分词这么麻烦,我不分好了,我就按“字”(char)来做最小单元做映射。这样词表就小多了:英文只需要 26 个字母即可,中文根据 2013 年中华人民共和国教育部《通用规范汉字表》定义“规范汉字”,国家规定的通用规范汉字一共为 8105 个,相比之下也不算大。
然而 char level 的主要问题是切分的太细:pneumonoultramicroscopicsilicovolcanoconiosis 这个单词是我找到的最长的英语单词,他有 45 个字母组成,而中文中也存在大量的成语/歇后语/专用名词等,如:只许州官放火不许百姓点灯。
目前我们 NLP 的主要思路是对句子进行,即:
$$P(S)=P(w_1,w_2,..w_n)=P(w_1)∗P(w_2|w_1)∗P(w_3|w_1,w_2)∗…∗P(w_n|w_1,w_2,..w_{n-1})$$
切分太细,则对应 S 的长度会变长,无疑大大增加建模难度(通过字来学习词的语义),也常常导致模型效果不理想。
对于 character 粒度分词:
- 优点:词表极小,比如:26 个英文字母几乎可以组合出所有词,5000 多个中文常用字基本也能组合出足够的词汇
- 缺点:
- 每个 token 的信息密度低,无法承载丰富的语义,英文中尤为明显,但中文却是较为合理,中文中用此种方式较多。
- 序列长度大幅增长,解码效率很低
SubwordLevelTokenizer
所以基于词和基于字的切分方式是两个极端,其优缺点也是互补的。而折中的 subword 就是一种相对平衡的方案。
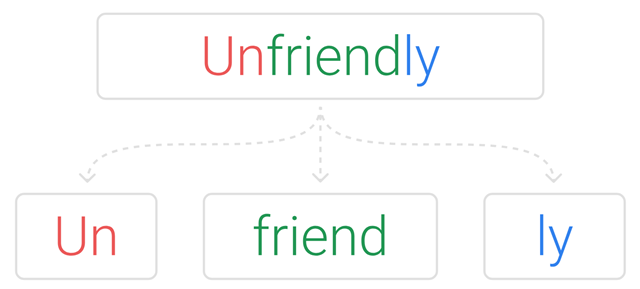
subword/子词级,它介于字符和单词之间。比如说 ‘Transformers’ 可能会被分成 ‘Transform’ 和 ‘ers’ 两个部分。这个方案平衡了词汇量和语义独立性,是相对较优的方案。
subword 的基本切分原则是:
- 高频词依旧切分成完整的整词
- 低频词被切分成有意义的子词,例如 dogs=>[dog,##s]
它的处理原则是,常用词应该保持原状,生僻词应该拆分成子词以共享 token 压缩空间。
基于 subword 的切分可以实现:
- 词表规模适中,解码效率较高
- 不存在 UNK,信息不丢失
- 能学习到词缀之间的关系
常见的子词算法有 Byte-Pair Encoding(BPE)/Byte-level BPE(BBPE)、Unigram LM、WordPiece、SentencePiece 等。
- BPE:即字节对编码。其核心思想是从字母开始,不断找词频最高、且连续的两个 token 合并,直到达到目标词数。
- BBPE:BBPE 核心思想将 BPE 的从字符级别扩展到子节(Byte)级别。BPE 的一个问题是如果遇到了 unicode 编码,基本字符集可能会很大。BBPE 就是以一个字节为一种“字符”,不管实际字符集用了几个字节来表示一个字符。这样的话,基础字符集的大小就锁定在了 256(2^8)。采用 BBPE 的好处是可以跨语言共用词表,显著压缩词表的大小。而坏处就是,对于类似中文这样的语言,一段文字的序列长度会显著增长。因此,BBPE based 模型可能比 BPE based 模型表现的更好。然而,BBPE sequence 比起 BPE 来说略长,这也导致了更长的训练/推理时间。BBPE 其实与 BPE 在实现上并无大的不同,只不过基础词表使用 256 的字节集。
- WordPiece:WordPiece 算法可以看作是 BPE 的变种。不同的是,WordPiece 基于概率生成新的 subword 而不是下一最高频字节对。WordPiece 算法也是每次从词表中选出两个子词合并成新的子词。BPE 选择频数最高的相邻子词合并,而 WordPiece 选择使得语言模型概率最大的相邻子词加入词表。
- Unigram:它和 BPE 以及 WordPiece 从表面上看一个大的不同是,前两者都是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram Language Model 却是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
- SentencePiece:SentencePiece 它是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用 BPE 或者 Unigram 算法来构造词汇表。SentencePiece 除了集成了 BPE、ULM 子词算法之外,SentencePiece 还能支持字符和词级别的分词。
下图是一些主流模型使用的分词算法,比如:GPT-1 使用的 BPE 实现分词,LLaMA/BLOOM/GPT2/ChatGLM 使用 BBPE 实现分词。BERT/DistilBERT/Electra 使用 WordPiece 进行分词,XLNet 则采用了 SentencePiece 进行分词。
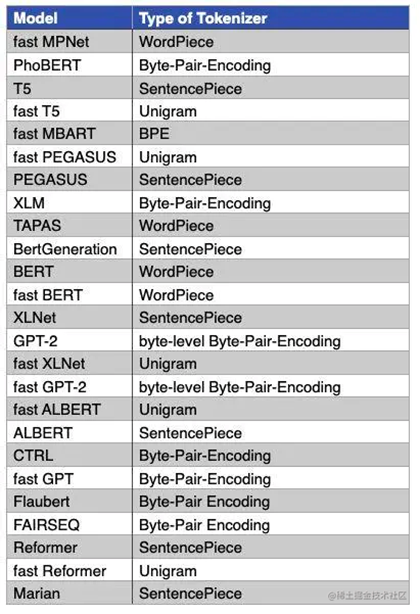
常见 Subword 子词算法
Byte-Pair Encoding(BPE)
Byte-Pair Encoding(BPE)是一种数据压缩技术,后来被引入到自然语言处理中作为一种子词级别的切分方法。它的核心思想是将常见的字节对(或字符对)替换为单个、未使用的字节(或字符),从而减少数据中的总字节数。在自然语言处理中,BPE 通过合并频繁出现的字符对来创建新的词汇,逐步建立起一个子词的词表。
BPE 算法的步骤通常如下:
- 准备一份足够大的文本数据集,并确定词表的大小。
- 统计所有相邻字符对的频率,并找出出现次数最多的字符对。
- 将最频繁的字符对合并,创建一个新的符号,并且将文本中的这些字符对替换为这个新符号。
- 重复步骤 3 和步骤 4,直到达到预定的词表大小或者没有可以合并的字符对为止。
将文本数据集中的词汇切分为基础字符(如字母、标点符号等),并为每个基础字符后加上终止符,以表示词的边界。
使用 BPE 有助于缓解词表大小膨胀的问题,并且能够更好地处理罕见词和外来词。通过分解为子词,BPE 可以将词汇的形态变化(如复数、时态变化等)和词缀(如前缀、后缀)进行有效的编码,从而使模型能够利用这些信息来更好地理解和生成文本。
在现代自然语言处理模型中,比如 GPT、BERT 等,BPE 及其变体(如 SentencePiece)被广泛使用作为词表构建和文本预处理的重要方法。
如 aaabdaaabac 这个序列,首先 a 频率是最高的,其次是 aa,这是用 Z 替换 aa,然后两个字符连在一起频率最高的是 ab,因而用 Y 替换 ab,得到 ZYdZYac,可以依次类推,这样将第一行的原始序列压缩为了最后一样的序列。在信号压缩领域中 BPE 过程可视化如下:

要使用 Byte-Pair Encoding (BPE) 算法,你可以使用 HuggingFace 的 tokenizers 库。以下是如何训练 BPE tokenizer 的示例:
你可以使用以下代码训练一个 BPE tokenizer:
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import Whitespace
# 创建一个基本的 BPE 模型
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
# 使用 Whitespace 作为预处理器
tokenizer.pre_tokenizer = Whitespace()
# 创建一个 BPE trainer,设置 vocab_size 为 5000
trainer = BpeTrainer(vocab_size=5000, special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
# 指定文件路径列表来训练 tokenizer
files = ["your_text_file_1.txt", "your_text_file_2.txt"]
tokenizer.train(files, trainer)
# 保存 tokenizer 到文件
tokenizer.save("bpe.tokenizer.json")
Byte-level BPE (BBPE)
Byte-level BPE (BBPE),即字节级别的 Byte-Pair Encoding,是一种特殊的词切分方法,主要用于自然语言处理任务中。它的出现主要是为了解决传统 BPE 或者 WordPiece 等方法中的一些问题,如未登录词和词表规模过大等。
BBPE 最初由 OpenAI 在 GPT-2 模型中提出并使用。不同于常规的基于字符的 BPE,BBPE 是直接在字节层面进行操作。它首先将文本转换为 UTF-8 编码,然后在这些编码上应用 BPE 算法。由于所有的字符都可以转换成字节序列,所以 BBPE 的词表中可以包含所有可能的单字节符号,这样就确保了模型不会出现任何未登录词,同时也可以有效地控制词表的规模。
BBPE 的主要优点在于,它可以实现真正的无 UNK 处理,同时也能较好地处理多语言文本。因为它基于字节,所以可以很好地处理任何 UTF-8 编码的文本,无论这些文本是哪种语言,都不需要做任何特殊处理。
BBPE 的核心思想是用 byte 来构建最基础的词表而不是字符。首先将文本按照 UTF-8 进行编码,每个字符在 UTF-8 的表示中占据 1-4 个 byte。在 byte 序列上再使用 BPE 算法,进行 byte level 的相邻合并。编码形式如下图所示:

通过这种方式可以更好的处理跨语言和不常见字符的特殊问题(例如,颜文字),相比传统的 BPE 更节省词表空间(同等词表大小效果更好),每个 token 也能获得更充分的训练。
但是在解码阶段,一个 byte 序列可能解码后不是一个合法的字符序列,这里需要采用动态规划的算法进行解码,使其能解码出尽可能多的合法字符。具体算法如下:
假定 $f(k)$ 表示字符序列 $B_{1,k}$ 最大能解码的合法字符数量,$f(k)$ 有最优的子结构:
$$f(k)=max_{t=1,2,3,4}{f(k-t)+g(k-t+1,k)}$$
这里如果 $B_{i,j}$ 为一个合法字符 $g(i,j)=1$,否则 $g(i,j)=0$。
要在 Python 中使用 BBPE,你可以使用 HuggingFace 的 tokenizers 库。以下是一个例子,展示如何使用这个库训练一个 BBPE tokenizer:
你可以使用以下代码训练一个 BBPE tokenizer:
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import ByteLevel
# 创建一个 Byte-level BPE 模型
tokenizer = Tokenizer(BPE())
# 使用 Byte-level pre-tokenizer
tokenizer.pre_tokenizer = ByteLevel()
# 创建一个 BPE trainer
trainer = BpeTrainer(vocab_size=30000, min_frequency=2)
# 训练 tokenizer
files = ["your_text_file_1.txt", "your_text_file_2.txt"]
tokenizer.train(files, trainer)
# 现在你可以使用这个 tokenizer 来做词条化和逆词条化
output = tokenizer.encode("Hello, world!")
print(output.tokens)
# 你也可以将这个 tokenizer 保存为一个文件,以便以后使用
tokenizer.save("byte-level-bpe.tokenizer.json")
请注意,你需要在上述代码中替换 files 变量的值,使其包含你的训练数据文件路径列表。同时,你也可以根据需要调整 BpeTrainer 中的 vocab_size 和 min_frequency 参数。
WordPiece
WordPiece 是一种子词切分的方法,它和 BPE (Byte-Pair Encoding) 很相似,都是一种处理未登录词和减小词表规模的方法。它被 Google 在他们的一些重要模型中使用,比如 Transformer 和 BERT。

WordPiece 的操作步骤通常是这样的:
- 初始化词表,一般包含所有的基础字符。
- 逐步添加新的词块到词表中。每次选择可以最大化数据集似然度的词块添加到词表。
- 重复第二步,直到词表达到设定的大小。
WordPiece 在对新词块进行选择的时候,不仅考虑了词块在数据集中出现的频次,还会考虑词块的长度以及它构成的词的频次。这样可以确保词表中既有高频的短词块,也有低频的长词块。
在实际应用中,为了解决某些语言(如德语和土耳其语)中的子词连接问题,WordPiece 还引入了一个特殊的前缀 “##” 来标记一个词块是否出现在单词的最开始。例如,单词 “unhappiness” 会被切分为 [“un”, “##happy”, “##ness”]。
总的来说,WordPiece 切分方法有效地解决了未登录词问题,减小了词表规模,且能够灵活地处理不同语言中的词形变化和复合词。
WordPiece 选取子词的方法如下,假设句子 $S=(t_1,t_2,\cdots,t_n)$ 由 n 个子词组成,$t_i$ 表示子词,且假设各个子词之间是独立存在的,则句子 S 的语言模型似然值等价于所有子词概率的乘积:
$$\log P(s)=\sum_{i=1}^N \log P(t_i)$$
设把相邻位置的 x 和 y 两个子词进行合并,合并后产生的子词记为 z,此时句子 S 似然值的变化可表示为:
$$\log P(t_z) – (\log P(t_x) + \log P(t_y)) = \log(\frac{P(t_z)}{P(t_x)P(t_y)})$$
似然值的变化就是两个子词之间的互信息。简而言之,WordPiece 每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
使用以下代码来训练一个 WordPiece tokenizer:
from tokenizers import BertWordPieceTokenizer
# 初始化 tokenizer
tokenizer = BertWordPieceTokenizer(
clean_text=True, # 清理文本,去除一些特殊字符
handle_chinese_chars=True, # 处理中文字符
strip_accents=True, # 去除重音符号(只对拉丁字母有效)
lowercase=True, # 文本小写化
)
# 指定数据集路径,训练 tokenizer
files = ["your_text_file_1.txt", "your_text_file_2.txt"]
tokenizer.train(
files,
vocab_size=5000,
min_frequency=2,
show_progress=True,
special_tokens=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"],
limit_alphabet=1000,
wordpieces_prefix="##",
)
# 现在你可以使用这个 tokenizer 来做词条化和逆词条化
output = tokenizer.encode("Hello, world!")
print(output.tokens)
# 你也可以将这个 tokenizer 保存到文件中,以便以后使用
tokenizer.save_model("wordpiece")
Unigram Language Model (ULM)
与 WordPiece 一样,Unigram Language Model (ULM) 同样使用语言模型来挑选子词。不同之处在于,BPE 和 WordPiece 算法的词表大小都是从小到大变化,属于增量法。而 Unigram Language Model 则是减量法, 即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM 算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于句子 S,$X=(x_1,x_2,\cdots,x_m)$ 为句子的一个分词结果,由 m 个子词组成。所以,当前分词下句子 S 的似然值可以表示为:
$$P(X)=\prod\limits_{i=1}^m P(x_i)$$
对于句子 S,挑选似然值最大的作为分词结果,则可以表示为:
$$x^*=\arg\max_{x\in U(x)} P(X)$$
这里 $U(x)$ 包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到 $x^*$ 来解决。
每个字词的概率 $P(x_i)$ 用最大期望的方法计算,假设当前词表 V,则 M 步最大化对象是如下似然函数:
$$L=\sum_{s=1}^{|D|} \log(P(X^{(s)}))=\sum_{s=1}^{|D|} \log(\sum_{x\in U(X^{(s)})} P(x))$$
其中,|D| 是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。
初始时,词表 V 并不存在,因而,ULM 算法采用不断迭代的方法来构造词表以及求解分词概率:
- 初始时,建立一个足够大的词表,一般,可用语料中的所有字符加上常见的字符串初始化词表,也可以通过 BPE 初始化;
- 针对当前词表,用 EM 算法求解买个 subword 在语料上的概率;
- 对于每个字词,计算当该字词从词表中移除时,总的 loss 降低了多少,记为该字词的 loss。
- 将字词按照 loss 大小进行排序,丢弃一定比例 loss 最小的字词(比如 20%),保留下来的字词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免 OOV 情况,
- 重复步骤 2 到 4,直到词表大小减少到设定范围。
SentencePiece
SentencePiece 是一种开源的无监督文本词条化和分词工具,由 Google 开发。SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。SentencePiece 实现了 subword 单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型 (subword model)。这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。
SentencePiece 包括下图蓝色的 Normaliser,Encoder,Decoder 以及 Trainer 四个部分。
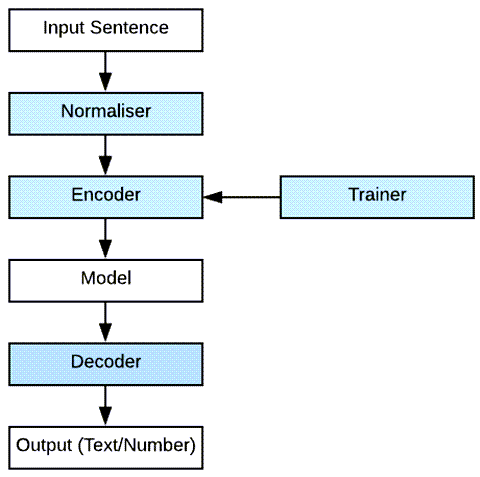
- Normaliser 并不是指对 tokenizer 之后的数字进行均值和方差归一化,在 NLP 中,归一化是指标准化文本中的单词,使它们遵循合适的格式。SentencePiece 采用的归一化方法是将单词/字母更改为等效的 NFKC Unicode(例如以 U+0026 开头)。当然也可以用不同 unicode 方法。对于那些感兴趣的人,可以在这里找到规范化器的 C++ [https://github.com/google/sentencepiece/blob/master/src/normalizer.cc] 实现。
- trainer 使用算法根据 subword 建立词汇表。SentencePiece 支持 BPE 和 unigram 两种语言模型。
- Encoder 和 Decoder 分别是前处理和后处理。
图中的过程可以用 SentencePiece 论文如下公式:
Decode(Encode(Normalized(text))) = Normalized(text)
这被称为无损 tokenization.
SentencePiece 的特性
- 唯一 Token 数量是预先确定的。神经网络机器翻译模型通常使用固定的词汇表进行操作。与大多数假设无限词汇量的无监督分词算法不同,SentencePiece 在训练分词模型时,使最终的词汇表大小固定,例如:8k、16k 或 32k。
- 从原始句子进行训练。以前的子词(sub-word)实现假设输入句子是预标记(pre-tokenized)的。这种约束是有效训练所必需的,但由于我们必须提前运行依赖于语言的分词器,因此使预处理变得复杂。SentencePiece 的实现速度足够快,可以从原始句子训练模型。这对于训练中文和日文的 tokenizer 和 detokenizer 很有用,因为在这些词之间不存在明确的空格。
- 子词正则化和 BPE-dropout。子词正则化和 BPE-dropout 是简单的正则化方法,它们实际上通过实时子词采样来增强训练数据,这有助于提高神经网络机器翻译(NMT)模型的准确性和鲁棒性。
空格被视为基本符号。自然语言处理的第一步是文本 tokenization。例如,标准的英语分词器(tokenizer)将对文本 Hello world 进行分段。分为 [Hello][World][.] 这三个 token。这种情况将导致原始输入和标记化(tokenized)序列不可逆转换。例如,“World”和“.”之间没有空格的信息。空格将从标记化序列中删除,例如: Tokenize(“ ”) == Tokenize(“World.”) 但是,SentencePiece 将输入文本视为一系列 Unicode 字符。空格也作为普通符号处理。为了明确地将空格作为基本标记处理,SentencePiece 首先使用元符号 “▁”(U+2581) 转义空格。由于空格保留在分段文本中,我们可以毫无歧义地对文本进行 detokenize。此特性可以在不依赖特定于语言的资源的情况下执行 detokenization。
SentencePiece 的技术优势
- 纯数据驱动:SentencePiece 从句子中训练 tokenization 和 detokenization 模型。并不总是需要 Pre-tokenization(Moses tokenizer/MeCab/KyTea)。
- 独立于语言:SentencePiece 将句子视为 Unicode 字符序列。没有依赖于语言的逻辑。
- 多子词算法:支持 BPE 和 unigram 语言模型。
- 子词正则化:SentencePiece 实现子词正则化和 BPE-dropout 的子词采样,有助于提高 NMT 模型的鲁棒性和准确性。
- 快速且轻量级:分割速度约为 50k 句子/秒,内存占用约为 6MB。
- Self-contained:只要使用相同的模型文件,就可以获得相同的 tokenization/detokenization。
- 直接词汇 ID 生成:SentencePiece 管理词汇到 ID 的映射,可以直接从原始句子生成词汇 ID 序列。
- 基于 NFKC 的 normalization:SentencePiece 执行基于 NFKC 的文本 normalization。
SentencePiece 的应用场景
随着 ChatGPT 迅速出圈,最近几个月开源的大模型也是遍地开花。目前,开源的大语言模型主要有三大类:
- ChatGLM 衍生的大模型(wenda、ChatSQL 等)
- LLaMA 衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera 等)
- Bloom 衍生的大模型(Bloomz、BELLE、Phoenix 等)
其中,ChatGLM-6B 主要以中英双语进行训练,LLaMA 主要以英语为主要语言的拉丁语系进行训练,而 Bloom 使用了 46 种自然语言、13 种编程语言进行训练。
| 模型 | 训练数据量 | 模型参数 | 训练数据范围 | 词表大小 | 分词算法 | 分词器(Tokenizer)后端 |
| LLaMA | 1T~1.4T tokens (其中,7B/13B 使用 1T,33B/65B 使用 1.4T) | 7B~65B | 以英语为主要语言的拉丁语系 | 32000 | BBPE | 基于 SentencePiece 工具实现 |
| ChatGLM-6B | 约 1T tokens | 6B | 中英双语 | 130528 | BBPE | 基于 SentencePiece 工具实现 |
| Bloom | 1.6TB 预处理文本,转换为 350B 唯一 tokens | 300M~176B | 46 种自然语言,13 种编程语言 | 250680 | BBPE | HuggingFace 的 tokenizers(类 SentencePiece) |
目前来看,在开源大模型中,LLaMA 无疑是其中最闪亮的星。但是,与 ChatGLM-6B 和 Bloom 原生支持中文不同。LLaMA 原生仅支持 Latin 或 Cyrillic 语系,对于中文支持不是特别理想。原版 LLaMA 模型的词表大小是 32K,而多语言模型(如:XLM-R、Bloom)的词表大小约为 250K。以中文为例,LLaMA 词表中的中文 token 比较少(只有几百个)。这将导致了两个问题:
- LLaMA 原生 tokenizer 词表中仅包含少量中文字符,在对中文字进行 tokenzation 时,一个中文汉字往往被切分成多个 tokens(2-3 个 Token 才能组合成一个汉字),显著降低编解码的效率。
- 预训练中没有出现过或者出现得很少的语言学习得不充分。
为了解决这些问题,我们可能就需要进行中文词表扩展。比如:在中文语料库上使用 SentencePiece 训练一个中文 tokenizer 模型,然后将中文 tokenizer 与 LLaMA 原生的 tokenizer 进行合并,通过组合它们的词汇表,最终获得一个合并后的 tokenizer 模型。
首先,让我们安装必要的库,包括 sentencepiece 和 transformers(HuggingFace 的库,用于加载 LLaMA 的 tokenizer)。
pip install sentencepiece transformers
接下来,我们在中文语料库上训练一个 SentencePiece tokenizer 模型:
import sentencepiece as spm
spm.SentencePieceTrainer.train('--input=chinese_corpus.txt --model_prefix=m --vocab_size=32000')
这将生成两个文件:m.model(模型文件)和 m.vocab(词汇表文件)。
然后我们需要加载 LLaMA tokenizer 和你刚刚创建的 SentencePiece tokenizer。加载 LLaMA 模型的 tokenizer 可以使用 HuggingFace 的 Transformers 库:
from transformers import AutoTokenizer
llama_tokenizer = AutoTokenizer.from_pretrained("meta-llama")
加载我们的 SentencePiece tokenizer:
sp = spm.SentencePieceProcessor()
sp.load('m.model')
然后,你需要将这两个 tokenizer 的词汇表进行合并。然而,这部分有些棘手,因为不同的 tokenizer 可能使用不同的标记(token)策略和词汇表大小,可能需要自定义函数进行合并。以下提供一个简单的示例,主要是将新词汇添加到 LLaMA tokenizer 的词汇表中,并重新分配词条 ID:
# 获取 LLaMA tokenizer 的词汇表 llama_vocab = llama_tokenizer.get_vocab() # 获取 SentencePiece tokenizer 的词汇表 sp_vocab = {sp.id_to_piece(id): id for id in range(sp.get_piece_size())} # 将 SentencePiece 的词汇表添加到 LLaMA 的词汇表中 merged_vocab = {**llama_vocab, **sp_vocab} # 将 LLaMA tokenizer 的词汇表更新为新词汇表 llama_tokenizer.vocab = merged_vocab llama_tokenizer.ids_to_tokens = {id: token for token, id in merged_vocab.items()}这里需要注意的是,这个简单的示例假设两个词汇表没有重叠。然而实际情况中,你可能需要处理词汇表重叠和词条ID冲突的问题。具体的处理方式可能依赖于你的应用需求和具体的合并策略。
此外,你需要知道,合并后的 tokenizer 在使用 LLaMA 模型进行预测时可能会出现问题,因为模型是在原始的词汇表上进行训练的。为了解决这个问题,你可能需要在合并的词汇表上对模型进行进一步的微调或预训练。



这篇不错