结巴分词
就是前面说的中文分词,这里需要介绍的是一个分词效果较好,使用起来像但方便的Python模块:结巴。
结巴中文分词采用的算法
- 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
结巴中文分词支持的分词模式
目前结巴分词支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
使用方法如下:
# -*- coding: utf-8 -*-
import jieba
text = '我来到北京清华大学'
default_mode = jieba.cut(text)
full_mode = jieba.cut(text, cut_all=True)
search_mode = jieba.cut_for_search(text)
print("精确模式: ", "/".join(default_mode))
print("全模式: ", "/".join(full_mode))
print("搜索引擎模式: ", "/".join(search_mode))
返回的数据如下:
精确模式: 我/来到/北京/清华大学 全模式: 我/来到/北京/清华/清华大学/华大/大学 搜索引擎模式: 我/来到/北京/清华/华大/大学/清华大学
上述代码解释:
- cut方法接受两个输入参数: 1) 第一个参数为需要分词的字符串 2)cut_all参数用来控制是否采用全模式,默认不采用。
- cut_for_search方法接受一个参数:需要分词的字符串, 该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
- 注意:待分词的字符串可以是gbk字符串、utf-8字符串或者unicode
- cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(…))转化为list
结巴中文分词的其他功能
1、添加或管理自定义词典
结巴的所有字典内容存放在dict.txt,你可以不断的完善dict.txt中的内容。
2、关键词抽取
通过计算分词后的关键词的TF/IDF权重,来抽取重点关键词。
具体示例:
# -*- coding: utf-8 -*-
import jieba.analyse
text = "结巴中文分词模块是一个非常好的Python分词组件"
tags = jieba.analyse.extract_tags(text, 2)
print("关键词抽取: ", "/".join(tags))
返回的结果为:关键词抽取: 分词/Python
更多信息请查看:https://github.com/fxsjy/jieba/
北大pkuseg
pkuseg简介
pkuseg是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。pkuseg具有如下几个特点:
- 多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。我们目前支持了新闻领域,网络领域,医药领域,旅游领域,以及混合领域的分词预训练模型。在使用中,如果用户明确待分词的领域,可加载对应的模型进行分词。如果用户无法确定具体领域,推荐使用在混合领域上训练的通用模型。各领域分词样例可参考txt。
- 更高的分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
- 支持用户自训练模型。支持用户使用全新的标注数据进行训练。
- 支持词性标注。
相关测试结果:
| MSRA | Precision | Recall | F-score |
| jieba | 87.01 | 89.88 | 88.42 |
| THULAC | 95.60 | 95.91 | 95.71 |
| pkuseg | 96.94 | 96.81 | 96.88 |
| Precision | Recall | F-score | |
| jieba | 87.79 | 87.54 | 87.66 |
| THULAC | 93.40 | 92.40 | 92.87 |
| pkuseg | 93.78 | 94.65 | 94.21 |
| Default | MSRA | CTB8 | PKU | All Average | |
| jieba | 81.45 | 79.58 | 81.83 | 83.56 | 81.61 |
| THULAC | 85.55 | 87.84 | 92.29 | 86.65 | 88.08 |
| pkuseg | 87.29 | 91.77 | 92.68 | 93.43 | 91.29 |
pkuseg的使用
1、使用默认配置进行配置
import pkuseg
seg = pkuseg.pkuseg() #以默认配置加载模型
text = seg.cut('我爱北京天安门') #进行分词
print(text)
2、使用细分领域分词(如果用户明确分词领域,推荐使用细领域模型分词)
import pkuseg
seg = pkuseg.pkuseg(model_name='medicine') #程序会自动下载所对应的细领域模型
text = seg.cut('我爱北京天安门') #进行分词
print(text)
3、分词同时进行词性标注,各词性标签的详细含义可参考tags.txt
import pkuseg
seg = pkuseg.pkuseg(postag=True) #开启词性标注功能
text = seg.cut('我爱北京天安门') #进行分词和词性标注
print(text)
4、对文件分词
import pkuseg
#对input.txt的文件分词输出到output.txt中
#开8个进程
pkuseg.test('input.txt', 'output.txt', nthread=8)
5、额外使用用户自定义词典
import pkuseg
seg = pkuseg.pkuseg(user_dict='my_dict.txt') #给定用户词典为当前目录下的"my_dict.txt"
text = seg.cut('我爱北京天安门')
print(text)
模型配置:
pkuseg.pkuseg(model_name="default", user_dict="default", postag=False) model_name 模型路径。 "default",默认参数,表示使用我们预训练好的混合领域模型(仅对pip下载的用户)。 "news", 使用新闻领域模型。 "web", 使用网络领域模型。 "medicine", 使用医药领域模型。 "tourism", 使用旅游领域模型。 model_path, 从用户指定路径加载模型。 user_dict 设置用户词典。 "default", 默认参数,使用我们提供的词典。 None, 不使用词典。 dict_path, 在使用默认词典的同时会额外使用用户自定义词典,可以填自己的用户词典的路径,词典格式为一行一个词。 postag 是否进行词性分析。 False, 默认参数,只进行分词,不进行词性标注。 True, 会在分词的同时进行词性标注。
对文件进行分词:
pkuseg.test(readFile, outputFile, model_name="default", user_dict="default", postag=False, nthread=10) readFile 输入文件路径。 outputFile 输出文件路径。 model_name 模型路径。同pkuseg.pkuseg user_dict 设置用户词典。同pkuseg.pkuseg postag 设置是否开启词性分析功能。同pkuseg.pkuseg nthread 测试时开的进程数。
模型训练:
pkuseg.train(trainFile, testFile, savedir, train_iter=20, init_model=None) trainFile 训练文件路径。 testFile 测试文件路径。 savedir 训练模型的保存路径。 train_iter 训练轮数。 init_model 初始化模型,默认为None表示使用默认初始化,用户可以填自己想要初始化的模型的路径如init_model='./models/'。
pkuseg实战
使用pkuseg分词+使用wordcloud显示词云:
import pkuseg
from collections import Counter
import pprint
from wordcloud import WordCloud
import matplotlib.pyplot as plt
with open("data/santisanbuqu_liucixin.txt", encoding="utf-8") as f:
content = f.read()
with open("data/CNENstopwords.txt", encoding="utf-8") as f:
stopwords = f.read()
lexicon = ['章北海', '汪淼', '叶文洁']
seg = pkuseg.pkuseg(user_dict=lexicon)
text = seg.cut(content)
new_text = []
for w in text:
if w not in stopwords:
new_text.append(w)
counter = Counter(new_text)
pprint.pprint(counter.most_common(50))
cut_text = "".join(new_text)
wordcloud = WordCloud(font_path="font/FZYingXueJW.TTF", background_color="white", width=800, height=600).generate(
cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()

参考链接:https://github.com/lancopku/pkuseg-python
哈工大LTP
LTP是哈工大出品的自然语言处理工具箱, LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。pyltp是python下对ltp(c++)的封装。
Pyltp在linux环境下安装非常的简单,仅需执行 pip install pyltp 即可,但由于需要编译ltp,在Windows环境下安装确存在各种问题。这里采用的是从网上找到的编译好的.whl文件。
pip install ./pyltp-0.2.1-cp36-cp36m-win_amd64.whl
安装完毕后,还需要下载模型文件,文件下载地址:http://ltp.ai/download.html
使用示例:
import os
from pyltp import SentenceSplitter
from pyltp import Segmentor
from pyltp import Postagger
from pyltp import NamedEntityRecognizer
from pyltp import Parser
from pyltp import SementicRoleLabeller
LTP_DATA_DIR = 'D:\CodeHub\CutSeg\ltp_data_v3.4.0' # ltp模型目录的路径
# 分句
sents = SentenceSplitter.split('元芳你怎么看?我就趴窗口上看呗!') # 分句
print('\n'.join(sents))
# 分词
cws_model_path = os.path.join(LTP_DATA_DIR, 'cws.model') # 分词模型路径,模型名称为`cws.model`
segmentor = Segmentor() # 初始化实例
segmentor.load(cws_model_path) # 加载模型
words = segmentor.segment('元芳你怎么看') # 分词
print('/'.join(words))
segmentor.release() # 释放模型
# 词性标注
pos_model_path = os.path.join(LTP_DATA_DIR, 'pos.model') # 词性标注模型路径,模型名称为`pos.model`
postagger = Postagger() # 初始化实例
postagger.load(pos_model_path) # 加载模型
postags = postagger.postag(words) # 词性标注
print('/'.join(postags))
postagger.release() # 释放模型
# 命名实体识别
ner_model_path = os.path.join(LTP_DATA_DIR, 'ner.model') # 命名实体识别模型路径,模型名称为`ner.model`
recognizer = NamedEntityRecognizer() # 初始化实例
recognizer.load(ner_model_path) # 加载模型
netags = recognizer.recognize(words, postags) # 命名实体识别
print('/'.join(netags))
recognizer.release() # 释放模型
# 依存句法分析
par_model_path = os.path.join(LTP_DATA_DIR, 'parser.model') # 依存句法分析模型路径,模型名称为`parser.model`
parser = Parser() # 初始化实例
parser.load(par_model_path) # 加载模型
arcs = parser.parse(words, postags) # 句法分析
print("/".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
parser.release() # 释放模型
# 语义角色标注
# srl_model_path = os.path.join(LTP_DATA_DIR, 'pisrl.model') # 语义角色标注模型目录路径,模型目录为`pisrl.model`
srl_model_path = os.path.join(LTP_DATA_DIR,
'pisrl_win.model') # windows系统要用不同的SRL模型文件,http://ospm9rsnd.bkt.clouddn.com/server/3.4.0/pisrl_win.model或http://model.scir.yunfutech.com/server/3.4.0/pisrl_win.model
labeller = SementicRoleLabeller() # 初始化实例
labeller.load(srl_model_path) # 加载模型
roles = labeller.label(words, postags, arcs) # 语义角色标注
for role in roles:
print(role.index, "".join(
["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))
labeller.release() # 释放模型
参考链接:
- https://github.com/HIT-SCIR/ltp
- https://github.com/HIT-SCIR/pyltp
- https://pyltp.readthedocs.io/zh_CN/latest/
清华THULAC
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
- 能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
- 准确率高。该工具包在标准数据集ChineseTreebank(CTB5)上分词的F1值可达3%,词性标注的F1值可达到9%,与该数据集上最好方法效果相当。
- 速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到3MB/s。
THULAC的安装
安装非常的简单,仅需执行pip install thulac即可。安装时会默认下载模型文件。官方说可以到thulac.thunlp.org下载更好的模型放入THULAC的根目录或用参数model_path指定模型的位置。
但经过测试发现从thulac.thunlp.org的模型与自动下载的模型(D:\CodeHub\NLP\venv\Lib\site-packages\thulac\models)完全一致。
THULAC的使用
命令行运行
# 从input.txt读入,并将分词和词性标注结果输出到ouptut.txt中 python -m thulac input.txt output.txt # 如果只需要分词功能,可在增加参数"seg_only" python -m thulac input.txt output.txt seg_only
Python接口使用
import thulac
# 示例1
thu1 = thulac.thulac() # 默认模式
text = thu1.cut("我爱北京天安门", text=True) # 进行一句话分词
print(text)
# 示例2
thu2 = thulac.thulac(seg_only=True) # 只进行分词,不进行词性标注
thu2.cut_f("input.txt", "output.txt") # 对input.txt文件内容进行分词,输出到output.txt
接口参数:
thulac(user_dict=None, model_path=None, T2S=False, seg_only=False, filt=False, max_length=50000, deli='_', rm_space=False)
- user_dict:设置用户词典,用户词典中的词会被打上uw标签。词典中每一个词一行,UTF8编码
- model_path:设置模型文件所在文件夹,默认为models/
- T2S:默认False,是否将句子从繁体转化为简体
- seg_only:默认False,时候只进行分词,不进行词性标注
- filt:默认False,是否使用过滤器去除一些没有意义的词语,例如”可以”。
- max_length:最大长度
- deli:默认为’_’,设置词与词性之间的分隔符
rm_space:默认为 False, 是否去掉原文本中的空格后再进行分词
cut(文本, text=False)
- text:默认为 False, 是否返回文本,不返回文本则返回一个二维数组([[word, tag]..]), seg_only 模式下 tag 为空字符。
cut_f(输入文件, 输出文件)
- 对文件进行分词
词性解释
n/名词 np/人名 ns/地名 ni/机构名 nz/其它专名
m/数词 q/量词 mq/数量词 t/时间词 f/方位词 s/处所词
v/动词 a/形容词 d/副词 h/前接成分 k/后接成分
i/习语 j/简称 r/代词 c/连词 p/介词 u/助词 y/语气助词
e/叹词 o/拟声词 g/语素 w/标点 x/其它
参考链接:https://github.com/thunlp/THULAC-Python
StanfordNLP
方案一:调用 StanfordCoreNLP
StanfordCoreNLP 的源代码是使用 Java 写的,提供了 Server 方式进行交互。stanfordcorenlp 是一个对 StanfordCoreNLP 进行了封装的 Python 工具包。
安装流程:
- 安装 Python 包:pip install stanfordcorenlp
- 下载安装 JDK(版本要求 JDK 1.8 以上)
- 下载安装StanfordCoreNLP 文件即语言包。解压 CoreNLP 文件,并将中文包放在解压文件的根目录。
在 Python 环境下直接调用
代码示例:
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP('D:\\stanford-corenlp-full-2018-02-27', lang='zh')
sentence = '斯坦福大学自然语言处理包 StanfordNLP'
print(nlp.word_tokenize(sentence)) # 分词
print(nlp.pos_tag(sentence)) # 词性标注
print(nlp.ner(sentence)) # 实体识别
print(nlp.parse(sentence)) # 语法树
print(nlp.dependency_parse(sentence)) # 依存句法
正常返回结果:
['斯坦福', '大学', '自然', '语言', '处理', '包', 'StanfordNLP']
[('斯坦福', 'NR'), ('大学', 'NN'), ('自然', 'AD'), ('语言', 'NN'), ('处理', 'VV'), ('包', 'NN'), ('StanfordNLP', 'NN')]
[('斯坦福', 'ORGANIZATION'), ('大学', 'ORGANIZATION'), ('自然', 'O'), ('语言', 'O'), ('处理', 'O'), ('包', 'O'), ('StanfordNLP', 'O')]
(ROOT
(IP
(NP(NR 斯坦福)(NN 大学))
(ADVP(AD 自然))
(NP(NN 语言))
(VP(VV 处理)
(NP(NN 包)(NN StanfordNLP)))))
[('ROOT', 0, 5), ('compound:nn', 2, 1), ('nsubj', 5, 2), ('advmod', 5, 3), ('nsubj', 5, 4), ('compound:nn', 7, 6), ('dobj', 5, 7)]
如果报如下错误,则为 JDK 没有安装或 JDK 环境变量没有正确配置。
Traceback (most recent call last):
File "D:/CodeHub/NLP/test_new.py", line 3, in <module>
nlp = StanfordCoreNLP('D:\\stanford-corenlp-full-2018-02-27', lang='zh')
File "D:\CodeHub\NLP\venv\lib\site-packages\stanfordcorenlp\corenlp.py", line 46, in __init__
if not subprocess.call(['java', '-version'], stdout=subprocess.PIPE, stderr=subprocess.STDOUT) == 0:
File "D:\ProgramFiles\Python37\lib\subprocess.py", line 339, in call
with Popen(*popenargs, **kwargs) as p:
File "D:\ProgramFiles\Python37\lib\subprocess.py", line 800, in __init__
restore_signals, start_new_session)
File "D:\ProgramFiles\Python37\lib\subprocess.py", line 1207, in _execute_child
startupinfo)
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
以服务方式调用
以命令方式创建一个 CoreNLP 服务:
PS D:\stanford-corenlp-full-2018-02-27> java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000 [main] INFO CoreNLP - --- StanfordCoreNLPServer#main() called --- [main] INFO CoreNLP - setting default constituency parser [main] INFO CoreNLP - warning: cannot find edu/stanford/nlp/models/srparser/englishSR.ser.gz [main] INFO CoreNLP - using: edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz instead [main] INFO CoreNLP - to use shift reduce parser download English models jar from: [main] INFO CoreNLP - http://stanfordnlp.github.io/CoreNLP/download.html [main] INFO CoreNLP - Threads: 4 [main] INFO CoreNLP - Starting server... [main] INFO CoreNLP - StanfordCoreNLPServer listening at /0:0:0:0:0:0:0:0:9000
代码示例:
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP('http://localhost', port=9000, lang='zh')
sentence = '斯坦福大学自然语言处理包StanfordNLP'
print(nlp.word_tokenize(sentence)) # 分词
print(nlp.pos_tag(sentence)) # 词性标注
print(nlp.ner(sentence)) # 实体识别
print(nlp.parse(sentence)) # 语法树
print(nlp.dependency_parse(sentence)) # 依存句法
方案二、使用官方发布的 stanfordnlp
安装方法:pip install stanfordnlp 。我执行的时候报如下错误:
Collecting torch>=1.0.0 (from stanfordnlp) Could not find a version that satisfies the requirement torch>=1.0.0 (from stanfordnlp) (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2) No matching distribution found for torch>=1.0.0 (from stanfordnlp)
无法找到适合版本的 pytorch?于是采用手动安装 PyTorch 的方式:https://pytorch.org/get-started/locally/后可顺利安装。
使用示例:
import stanfordnlp
# stanfordnlp.download('zh') # This downloads the English models for the neural pipeline
# 中间会遇到模型无法下载的情况,可通过以下地址 http://nlp.stanford.edu/software/stanfordnlp_models/latest/zh_gsd_models.zip
# 下载后解压,并放入:C:\\Users\\$username$\\stanfordnlp_resources\\文件夹下。
nlp = stanfordnlp.Pipeline(lang='zh') # This sets up a default neural pipeline in English
doc = nlp("位置很棒,地铁口附近,很舒适,唯一有缺点就是新装修,公共服务特别好,早餐比我想像的好很多,而且提供到号中午十二点。")
doc.sentences[0].print_dependencies()
# doc.sentences[0].print_tokens()
# doc.sentences[0].print_words()
执行后输出如下:
('位置', '5', 'nmod')
('很棒', '5', 'amod')
(',地', '5', 'nmod')
('铁口', '5', 'nmod')
('附近', '8', 'nsubj')
(',', '8', 'advmod')
('很', '8', 'advmod')
('舒适', '29', 'dep')
(',', '29', 'punct')
('唯一', '12', 'amod')
('有', '12', 'amod')
('缺点', '13', 'nsubj')
('就是', '29', 'dep')
('新装', '15', 'nsubj')
('修,', '19', 'advcl')
('公共', '17', 'amod')
('服务', '15', 'obj')
('特别', '19', 'advmod')
('好', '23', 'dep')
(',', '19', 'mark:relcl')
('早餐', '23', 'nsubj')
('比我', '23', 'advmod')
('想像', '26', 'acl:relcl')
('的', '23', 'mark:relcl')
('好', '26', 'amod')
('很多', '29', 'nsubj')
(',', '29', 'punct')
('而且', '29', 'mark')
('提供', '0', 'root')
('到', '29', 'mark')
('号', '34', 'nmod')
('中午', '34', 'nmod')
('十二', '34', 'nummod')
('点', '29', 'obj')
('。', '29', 'punct')
可以看到上面的分词效果较差,所以还是推荐使用第一种方案。
参考链接:https://stanfordnlp.github.io/stanfordnlp/
SnowNLP
SnowNLP 是一个 python 写的类库,可以方便的处理中文文本内容,是受到了 TextBlob 的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和 TextBlob 不同的是,这里没有用 NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。
主要特性:
- 中文分词(Character-Based Generative Model)
- 词性标注(TnT 3-gram 隐马)
- 情感分析(现在训练数据主要是买卖东西时的评价,所以对其他的一些可能效果不是很好,待解决)
- 文本分类(Naive Bayes)
- 转换成拼音(Trie 树实现的最大匹配)
- 繁体转简体(Trie 树实现的最大匹配)
- 提取文本关键词(TextRank 算法)
- 提取文本摘要(TextRank 算法)
- tf,idf
- Tokenization(分割成句子)
- 文本相似(BM25)
安装:pip install snownlp
示例代码:
from snownlp import SnowNLP
s1 = SnowNLP('这个东西真心很赞')
print(s1.words)
print(list(s1.tags))
print(s1.sentiments)
print(s1.pinyin)
s2 = SnowNLP('「繁體字」「繁體中文」的叫法在臺灣亦很常見。')
print(s2.han)
text = '''
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。
它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,
所以它与语言学的研究有着密切的联系,但又有重要的区别。
自然语言处理并不是一般地研究自然语言,
而在于研制能有效地实现自然语言通信的计算机系统,
特别是其中的软件系统。因而它是计算机科学的一部分。
'''
s3 = SnowNLP(text)
print(s3.keywords(3))
print(s3.summary(3))
print(s3.sentences)
s4 = SnowNLP([['这篇', '文章'], ['那篇', '论文'], ['这个']])
print(s4.tf)
print(s4.idf)
print(s4.sim([u'文章']))
['这个','东西','真心','很','赞']
[('这个','r'),('东西','n'),('真心','d'),('很','d'),('赞','Vg')]
0.9769551298267365
['zhe','ge','dong','xi','zhen','xin','hen','zan']
「繁体字」「繁体中文」的叫法在台湾亦很常见。
['语言','自然','计算机']
['因而它是计算机科学的一部分','自然语言处理是计算机科学领域与人工智能领域中的一个重要方向','自然语言处理是一门融语言学、计算机科学、数学于一体的科学']
['自然语言处理是计算机科学领域与人工智能领域中的一个重要方向','它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法','自然语言处理是一门融语言学、计算机科学、数学于一体的科学','因此','这一领域的研究将涉及自然语言','即人们日常使用的语言','所以它与语言学的研究有着密切的联系','但又有重要的区别','自然语言处理并不是一般地研究自然语言','而在于研制能有效地实现自然语言通信的计算机系统','特别是其中的软件系统','因而它是计算机科学的一部分']
[{'这篇':1,'文章':1},{'那篇':1,'论文':1},{'这个':1}]
{'这篇':0.5108256237659907,'文章':0.5108256237659907,'那篇':0.5108256237659907,'论文':0.5108256237659907,'这个':0.5108256237659907}
[0.4686473612532025,0,0]
参考链接:https://github.com/isnowfy/snownlp
DeepNLP
DeepNLP简介
DeepNLP项目是基于Tensorflow平台的一个python版本的NLP套装,目的在于将Tensorflow深度学习平台上的模块,结合最新的一些算法,提供NLP基础模块的支持,并支持其他更加复杂的任务的拓展,如生成式文摘等等。
- NLP套装模块
- 分词WordSegmentation/Tokenization
- 词性标注Part-of-speech(POS)
- 命名实体识别Named-entity-recognition(NER)
- 依存句法分析DependencyParsing(Parse)
- 自动生成式文摘Textsum(Seq2Seq-Attention)
- 关键句子抽取Textrank
- 文本分类Textcnn(WIP)
- 可调用WebRestfulAPI
- 计划中:句法分析Parsing
- 算法实现
- 分词:线性链条件随机场LinearChainCRF,基于CRF++包来实现
- 词性标注:单向LSTM/双向BI-LSTM,基于Tensorflow实现
- 命名实体识别:单向LSTM/双向BI-LSTM/LSTM-CRF结合网络,基于Tensorflow实现
- 依存句法分析:基于arc-standardsystem的神经网络的parser
- 预训练模型
- 中文:基于人民日报语料和微博混合语料:分词,词性标注,实体识别
DeepNLP的安装
安装说明
pip install deepnlp
下载模型:
import deepnlp
# Download all the modules
deepnlp.download()
# Download specific module
deepnlp.download('segment')
deepnlp.download('pos')
deepnlp.download('ner')
deepnlp.download('parse')
# Download module and domain-specific model
deepnlp.download(module='pos',name='en')
deepnlp.download(module='ner',name='zh_entertainment')
执行示例代码,报如下错误:
from deepnlp import segmenter tokenizer = segmenter.load_model(name='zh_entertainment') text = "我刚刚在浙江卫视看了电视剧老九门,觉得陈伟霆很帅" segList = tokenizer.seg(text) text_seg = "".join(segList) Traceback (most recent call last): File "D:/CodeHub/NLP/test_new.py", line 3, in <module> from deepnlp import segmenter File "D:\CodeHub\NLP\venv\lib\site-packages\deepnlp\segmenter.py", line 6, in <module> import CRFPP ModuleNotFoundError: No module named 'CRFPP'
解决方案,安装CRFPP。
DeepNLP的使用
使用示例:
from deepnlp import segmenter, pos_tagger, ner_tagger, nn_parser
from deepnlp import pipeline
# 分词模块
tokenizer = segmenter.load_model(name='zh')
text = "我爱吃北京烤鸭"
seg_list = tokenizer.seg(text)
text_seg = "".join(seg_list)
print(text_seg)
# 词性标注
p_tagger = pos_tagger.load_model(name='zh')
tagging = p_tagger.predict(seg_list)
for (w, t) in tagging:
pair = w + "/" + t
print(pair)
# 命名实体识别
n_tagger = ner_tagger.load_model(name='zh') # BaseLSTMBasedModel
tagset_entertainment = ['city', 'district', 'area']
tagging = n_tagger.predict(seg_list, tagset=tagset_entertainment)
for (w, t) in tagging:
pair = w + "/" + t
print(pair)
# 依存句法分析
parser = nn_parser.load_model(name='zh')
words = ['它', '熟悉', '一个', '民族', '的', '历史']
tags = ['r', 'v', 'm', 'n', 'u', 'n']
dep_tree = parser.predict(words, tags)
num_token = dep_tree.count()
print("id\tword\tpos\thead\tlabel")
for i in range(num_token):
cur_id = int(dep_tree.tree[i+1].id)
cur_form = str(dep_tree.tree[i+1].form)
cur_pos = str(dep_tree.tree[i+1].pos)
cur_head = str(dep_tree.tree[i+1].head)
cur_label = str(dep_tree.tree[i+1].deprel)
print("%d\t%s\t%s\t%s\t%s" % (cur_id, cur_form, cur_pos, cur_head, cur_label))
# Pipeline
p = pipeline.load_model('zh')
text = "我爱吃北京烤鸭"
res = p.analyze(text)
print(res[0])
print(res[1])
print(res[2])
words = p.segment(text)
pos_tagging = p.tag_pos(words)
ner_tagging = p.tag_ner(words)
print(list(pos_tagging))
print(ner_tagging)
自己训练模型流程:
参考链接:https://github.com/rockingdingo/deepnlp
小明NLP
小明NLP的主要功能:
- 中文分词&词性标注
- 支持繁體
- 支持自定义词典
- 中文拼写检查
- 文本摘要&关键词提取
- 情感分析
- 文本转拼音
- 获取汉字偏旁部首
其中最特别的是获取汉字的偏旁部首,类似英文的词干提取?由于汉字的特殊构造,导致具有相同部首的汉字可能存在某些关联,所以在机器学习中可能会有一定的价值。
直接上代码:
import xmnlp
print(xmnlp.radical('自然语言处理'))
print(xmnlp.radical('自然語言處理'))
输出内容为:
['自', '灬', '讠', '言', '夂', '王'] ['自', '灬', '讠', '言', '夂', '王']
从结果可以看到,其默认将繁体中文转化为简体中文后进行的偏旁部首提取。更好的方案可能是将简体中文转化为繁体后再进行提取(原因是汉字的简化导致一部分包含语义的偏旁被简化掉了)
看了下他的代码,其主要实现方式是通过字典来实现,来看一下其字典的数据:
import pickle
import bz2
fname = r"D:\CodeHub\NLP\venv\Lib\site-packages\xmnlp\radical\radical.pickle"
f = bz2.BZ2File(fname, 'rb')
d = pickle.loads(f.read())
for k, v in d['dictionary'].items():
print(k, v)
输出数据示例:
耀 羽 蘄 艹 涉 氵 谈 讠 伊 亻 預 页
另外也找到了两个中文偏旁部首的项目:
看了下字典基本上都一致(来自精简版的新华字典),其中一个针对本地没有的汉字额外请求了百度汉语,进行了抓取。
参考链接:https://github.com/SeanLee97/xmnlp
TextBlob
TextBlob简介
TextBlob是一个用Python编写的开源的文本处理库。是自然语言工具包NLTK的一个包装器,目的是抽象其复杂性。它可以用来执行很多自然语言处理的任务,比如,词性标注,名词性成分提取,情感分析,文本翻译,等等。
主要特性:
- 名词短语提取
- 词性标记
- 情绪分析
- 分类
- 由Google翻译提供的翻译和检测
- 标记(将文本分割成单词和句子)
- 词句、短语频率
- 解析
- n-gram
- 词变化(复数和单数化)和词形化
- 拼写校正
- 通过扩展添加新模型或语言
- WordNet集成
TextBlob的安装
直接执行pip install textblob即可进行安装。但是执行如下代码可能会报错:
from textblob import TextBlob text = 'I love natural language processing! I am not like fish!' blob = TextBlob(text)
D:\CodeHub\NLP\venv\Scripts\python.exe D:/CodeHub/NLP/test_new.py
Traceback (most recent call last):
File "D:\CodeHub\NLP\venv\lib\site-packages\textblob\decorators.py", line 35, in decorated
return func(*args, **kwargs)
File "D:\CodeHub\NLP\venv\lib\site-packages\textblob\tokenizers.py", line 57, in tokenize
return nltk.tokenize.sent_tokenize(text)
File "D:\CodeHub\NLP\venv\lib\site-packages\nltk\tokenize\__init__.py", line 105, in sent_tokenize
tokenizer = load('tokenizers/punkt/{0}.pickle'.format(language))
File "D:\CodeHub\NLP\venv\lib\site-packages\nltk\data.py", line 868, in load
opened_resource = _open(resource_url)
File "D:\CodeHub\NLP\venv\lib\site-packages\nltk\data.py", line 993, in _open
return find(path_, path + ['']).open()
File "D:\CodeHub\NLP\venv\lib\site-packages\nltk\data.py", line 701, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt')
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt/english.pickle
Searched in:
- 'C:\\Users\\qw.TCENT/nltk_data'
- 'D:\\CodeHub\\NLP\\venv\\nltk_data'
- 'D:\\CodeHub\\NLP\\venv\\share\\nltk_data'
- 'D:\\CodeHub\\NLP\\venv\\lib\\nltk_data'
- 'C:\\Users\\qw.TCENT\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- ''
**********************************************************************
解决方案是,安装好nltk,并下载好nltk_data。
TextBlob的使用
from textblob import TextBlob
from textblob import Word
text = 'I love natural language processing! I am not like fish!'
blob = TextBlob(text)
print(blob.words) # 分词
print(blob.tags) # 词性标注
print(blob.noun_phrases) # 短语抽取
# 分句+计算句子情感值
# 使用TextBlob情感分析的结果,以元组的方式进行返回,形式如(polarity, subjectivity).
# polarity是一个范围为[-1.0, 1.0]的浮点数,正数表示积极,负数表示消极。
# subjectivity是一个范围为[0.0, 1.0]的浮点数,其中0.0表示客观,1.0表示主观的。
for sentence in blob.sentences:
print(sentence + ' ------> ' + str(sentence.sentiment.polarity))
# 词语变形(Words Inflection)
w = Word("apple")
print(w.pluralize()) # 变复数
print(w.pluralize().singularize()) # 变单数
# 词干化(Words Lemmatization)
w = Word('went')
print(w.lemmatize('v'))
w = Word('octopi')
print(w.lemmatize())
# 拼写纠正(Spelling Correction)
sen = 'I lvoe naturll language processing!'
sen = TextBlob(sen)
print(sen.correct())
# 句法分析(Parsing)
text = TextBlob('I lvoe naturll language processing!')
print(text.parse())
# N-Grams
text = TextBlob('I lvoe naturll language processing!')
print(text.ngrams(n=2))
参考链接:
spaCy
spaCy是一个Python自然语言处理工具包,诞生于2014年年中,号称“Industrial-Strength Natural Language Processing in Python”,是具有工业级强度的Python NLP工具包。spaCy里大量使用了Cython来提高相关模块的性能,这个区别于学术性质更浓的NLTK,因此具有了业界应用的实际价值。
主要特性:
- 分词
- 命名实体识别
- 多语言支持(号称支持53种语言)
- 针对11种语言的23种统计模型
- 预训练词向量
- 高性能
- 轻松的整合深度学习
- 词性标注
- 依存句法分析
- 句法驱动的句子切分
- 用于语法和命名实体识别的内置可视化工具
- 方便的字符串到哈希映射
- 导出到numpy数据数组
- 高效的二进制序列化
- 易于模型打包和部署
- 稳健,精确评估
SpaCy的安装
先执行包的安装:pip install spacy,再执行数据集和模型的下载。
模型地址:
-
比如想安装英文的,执行如下命令即可:
python -m spacy download en_core_web_sm使用时加载相应的模型:
import spacy nlp = spacy.load("en_core_web_sm")由于官网没有中文的模型,针对中文模型安装稍微要麻烦些。
非官方中文模型地址:https://github.com/howl-anderson/Chinese_models_for_SpaCy
下载后执行:
pip install ./zh_core_web_sm-2.0.5.tar.gz安装后执行:
import spacy nlp = spacy.load("zh_core_web_sm")报如下错误:
Traceback (most recent call last): File "D:/CodeHub/NLP/test_new.py", line 7, in
nlp = spacy.load('zh_core_web_sm') File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\__init__.py", line 30, in load return util.load_model(name, **overrides) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\util.py", line 164, in load_model return load_model_from_package(name, **overrides) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\util.py", line 185, in load_model_from_package return cls.load(**overrides) File "D:\CodeHub\NLP\venv\lib\site-packages\zh_core_web_sm\__init__.py", line 12, in load return load_model_from_init_py(__file__, **overrides) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\util.py", line 228, in load_model_from_init_py return load_model_from_path(data_path, meta, **overrides) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\util.py", line 211, in load_model_from_path return nlp.from_disk(model_path) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\language.py", line 941, in from_disk util.from_disk(path, deserializers, exclude) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\util.py", line 654, in from_disk reader(path / key) File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\language.py", line 936, in p, exclude=["vocab"] File "pipes.pyx", line 661, in spacy.pipeline.pipes.Tagger.from_disk File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\util.py", line 654, in from_disk reader(path / key) File "pipes.pyx", line 641, in spacy.pipeline.pipes.Tagger.from_disk.load_model File "pipes.pyx", line 643, in spacy.pipeline.pipes.Tagger.from_disk.load_model File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\model.py", line 376, in from_bytes copy_array(dest, param[b"value"]) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\util.py", line 145, in copy_array dst[:] = src ValueError: could not broadcast input array from shape (128) into shape (96) 初步判定是版本问题,重新安装 spaCy:
pip install spacy==2.0.5重装完成后模型能正常加载,但是代码不能执行,报如下错误:
Building prefix dict from the default dictionary... Loading model from cache C:\Users\QWD312~1.TCE\AppData\Local\Temp\jieba.cache Loading model cost 0.785 seconds. Prefix dict has been built succesfully. Traceback (most recent call last): File "D:/CodeHub/NLP/test_new.py", line 6, in <module> doc = nlp("王小明在北京的清华大学读书") File "D:\CodeHub\NLP\venv\lib\site-packages\spacy\language.py", line 333, in __call__ doc = proc(doc) File "pipeline.pyx", line 390, in spacy.pipeline.Tagger.__call__ File "pipeline.pyx", line 402, in spacy.pipeline.Tagger.predict File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\model.py", line 161, in __call__ return self.predict(x) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\api.py", line 55, in predict X = layer(X) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\model.py", line 161, in __call__ return self.predict(x) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\api.py", line 293, in predict X = layer(layer.ops.flatten(seqs_in, pad=pad)) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\model.py", line 161, in __call__ return self.predict(x) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\api.py", line 55, in predict X = layer(X) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\model.py", line 161, in __call__ return self.predict(x) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\model.py", line 125, in predict y, _ = self.begin_update(X) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\api.py", line 374, in uniqued_fwd Y_uniq, bp_Y_uniq = layer.begin_update(X_uniq, drop=drop) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\api.py", line 61, in begin_update X, inc_layer_grad = layer.begin_update(X, drop=drop) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\layernorm.py", line 51, in begin_update X, backprop_child = self.child.begin_update(X, drop=0.) File "D:\CodeHub\NLP\venv\lib\site-packages\thinc\neural\_classes\maxout.py", line 69, in begin_update output__boc = self.ops.batch_dot(X__bi, W) File "ops.pyx", line 338, in thinc.neural.ops.NumpyOps.batch_dot File "<__array_function__ internals>", line 6, in dot ValueError: shapes (7, 512) and (640, 384) not aligned: 512 (dim 1) != 640 (dim 0)预估还是版本问题,重新一个个版本测试,终于将版本重装为 2.0.16 可顺利执行:
# -*- encoding: utf-8 -*- import spacy nlp = spacy.load("zh_core_web_sm") doc = nlp("王小明在北京的清华大学读书") for token in doc: print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_, token.shape_, token.is_alpha, token.is_stop, token.has_vector, token.ent_iob_, token.ent_type_, token.vector_norm, token.is_oov) spacy.displacy.serve(doc)Building prefix dict from the default dictionary... Loading model from cache C:\Users\QWD312~1.TCE\AppData\Local\Temp\jieba.cache Loading model cost 0.730 seconds. Prefix dict has been built succesfully. 王小明 王小明 X NNP nsubj xxx True False True B PERSON 14.44006 False 在 在 X VV acl x True True True O 9.84207 False 北京 北京 X NNP det xx True False True B GPE 18.310038 False 的 的 X DEC case:dec x True True True O 10.005628 False 清华大学 清华大学 X NNP obj xxxx True False True B ORG 21.960636 False 读书 读书 X VV ROOT xx True False True O 22.59519 False Serving on port 5000... Using the 'dep' visualizer
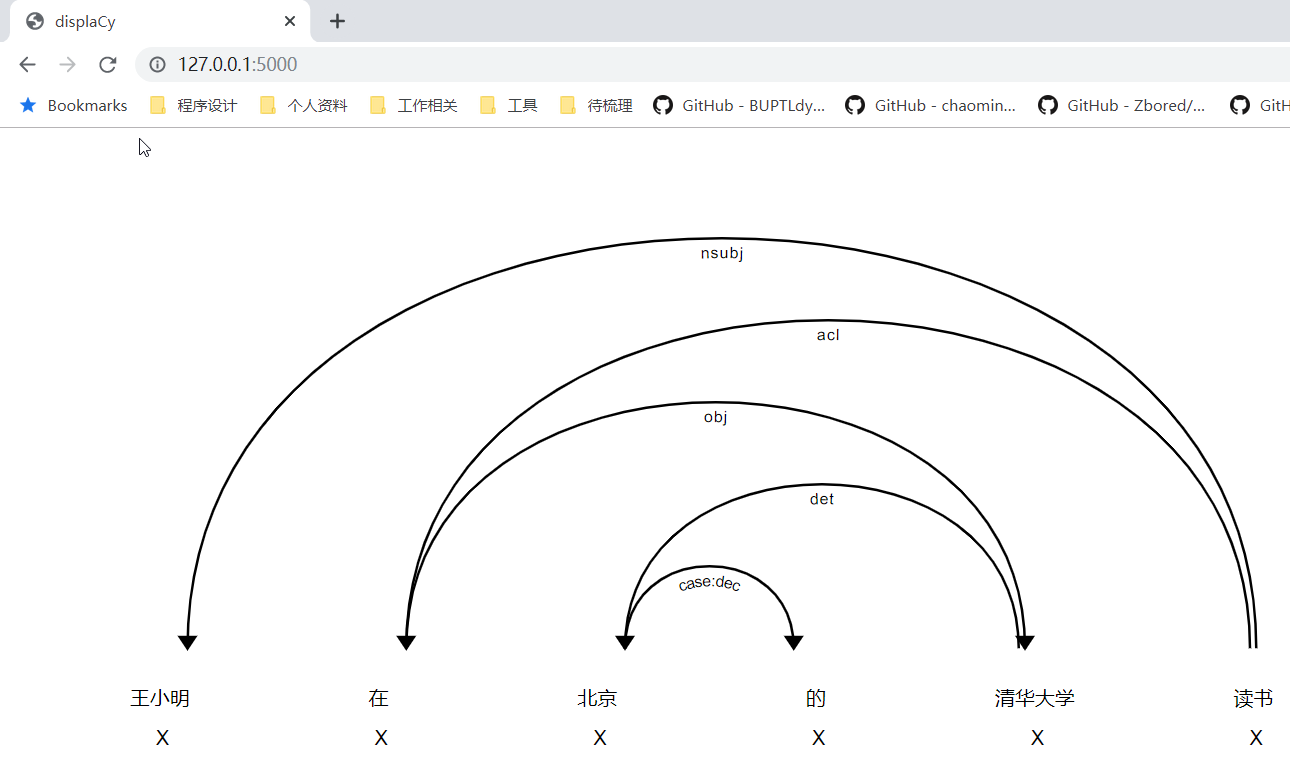
SpaCy 的使用
使用示例:
import spacy # Load English tokenizer, tagger, parser, NER and word vectors nlp = spacy.load("en_core_web_sm") text = "Rami Eidis studying at Stony Brook University in New York" doc = nlp(text) # 分词词性标注 for token in doc: print(token, token.pos_, token.pos) # 命名实体识别(NER) for ent in doc.ents: print(ent, ent.label_, ent.label) # 名词短语提取 for np in doc.noun_chunks: print(np)import spacy
nlp = spacy.load(“en_core_web_sm”)
text = “Rami Eidis studying at Stony Brook University in New York”
doc = nlp(text)# 分词词性标注
for token in doc:
print(token, token.pos_, token.pos)# 命名实体识别(NER)
for ent in doc.ents:
print(ent, ent.label_, ent.label)# 名词短语提取
for np in doc.noun_chunks:
print(np)# 依存关系
for token in doc:
print(token.text, token.dep_, token.head)# 文本相似度
doc1 = nlp(u”my fries were super gross”)
doc2 = nlp(u”such disgusting fries”)
similarity = doc1.similarity(doc2)
print(similarity)Spacy里面实体的标签及其表示的含义:
PERSON People, including fictional. 人物 NORP Nationalities or religious or political groups. 国家、宗教、政治团体 FAC Buildings, airports, highways, bridges, etc. 建筑、机场、高速公路、桥梁等 ORG Companies, agencies, institutions, etc. 组织公司、机构等 GPE Countries, cities, states. 国家、城市、州 LOC Non-GPE locations, mountain ranges, bodies of water. 山脉、水体等 PRODUCT Objects, vehicles, foods, etc. (Not services.) 车辆、食物等非服务性的产品 EVENT Named hurricanes, battles, wars, sports events, etc. 飓风、战争、体育赛事等 WORK_OF_ART Titles of books, songs, etc. 书名、歌名等 LAW Named documents made into laws. 法律文书 LANGUAGE Any named language. 语言 DATE Absolute or relative dates or periods. 日期 TIME Times smaller than a day. 小于1天的时间 PERCENT Percentage, including “%”. 百分比 MONEY Monetary values, including unit. 货币价值 QUANTITY Measurements, as of weight or distance. 度量单位 ORDINAL “first”, “second”, etc. 序数词 CARDINAL Numerals that do not fall under another type. 数量词 参考链接:
FoolNLTK
FoolNLTK简介
FoolNLTK是一个使用双向LSTM(BiLSTM模型)构建的便捷的中文处理工具包,该工具不仅可以实现分词、词性标注和命名实体识别,同时还能使用用户自定义字典加强分词的效果。根据该项目所述,这个中文工具包可能不是最快的开源中文分词,但很可能是最准的开源中文分词。
BiLSTM模型简介
如该项目所述,作者使用了双向LSTM来构建整个模型,这也许是作者对分词性能非常有信心的原因。在中文分词上,基于神经网络的方法,往往使用「字向量+双向LSTM+CRF」模型,利用神经网络来学习特征,将传统CRF中的人工特征工程量将到最低。
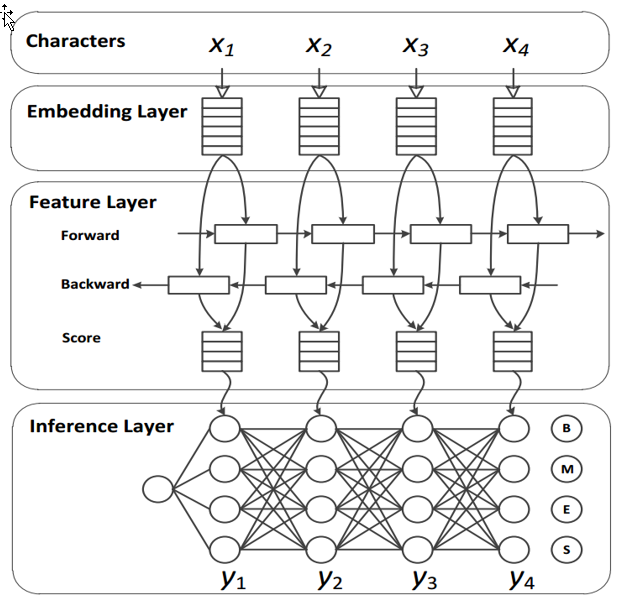
中文分词系统的一般神经网络架构,其中特征层就是使用的LSTM,来源Xinchi Chen et al.(2017)。除了该工具包所使用的深度方法,其实今年ACL的杰出论文就有一篇专门描述了分词方法。复旦大学的陈新驰、施展、邱锡鹏和黄萱菁在Adversarial Multi-Criteria Learning for Chinese Word Segmentation论文中提出了一个新框架,可以利用多标准的中文分词语料进行训练。因为该工具包主要使用的是双向LSTM,所以我们先简要解释一下这种网络再讨论我们测试的分词效果。首先顾名思义,双向LSTM结合了从序列起点开始移动的LSTM和另一个从序列末端开始移动的LSTM。其中正向和逆向的循环网络都由一个个LSTM单元组成。以下是LSTM单元的详细结构,其中Z为输入部分,$Z_i$、$Z_o$和$Z_f$分别为控制三个门的值,即它们会通过激活函数f对输入信息进行筛选。一般激活函数可以选择为Sigmoid函数,因为它的输出值为0到1,即表示这三个门被打开的程度。
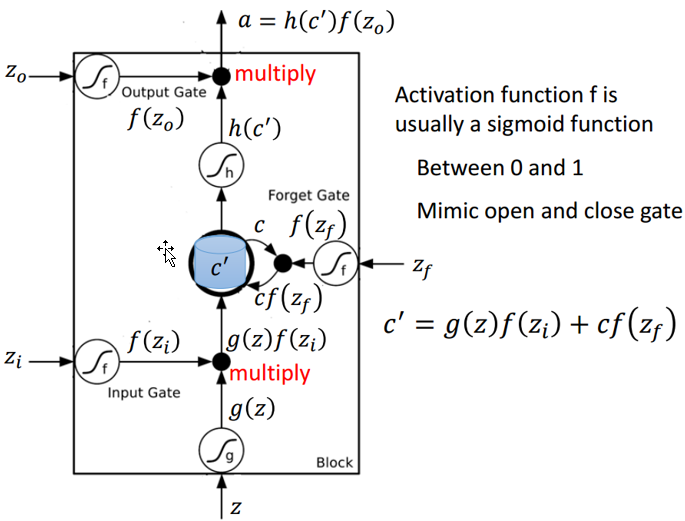
若我们输入Z,那么该输入向量通过激活函数得到的$g(Z)$和输入门$f(Z_i)$的乘积$g(Z)f(Z_i)$就表示输入数据经筛选后所保留的信息。$Z_f$控制的遗忘门将控制以前记忆的信息到底需要保留多少,保留的记忆可以用方程$c*f(z_f)$表示。以前保留的信息加上当前输入有意义的信息将会保留至下一个LSTM单元,即我们可以用$c’=g(Z)f(Z_i)+cf(z_f)$表示更新的记忆,更新的记忆$c’$也表示前面与当前所保留的全部有用信息。我们再取这一更新记忆的激活值$h(c’)$作为可能的输出,一般可以选择tanh激活函数。最后剩下的就是由$Z_o$所控制的输出门,它决定当前记忆所激活的输出到底哪些是有用的。因此最终LSTM的输出就可以表示为$$。若我们将这一系列LSTM单元组织为如下形式,那么它们就构成了一个BiLSTM网络:
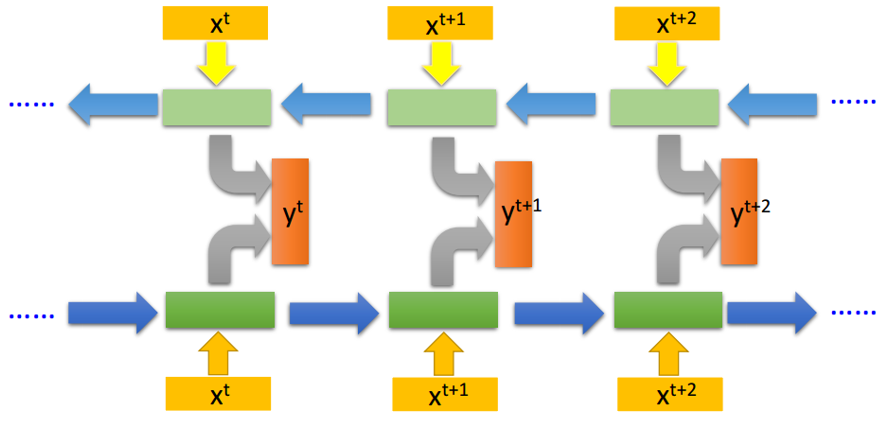 如上所示,我们将两个反向读取的LSTM网络连接就成了BiLSTM。如果我们同时训练正向LSTM与逆向LSTM,并把这两个循环网络的隐藏层拿出来都接入一个输出层,那么我们就能得到最后的输出结果y。使用这种BiLSTM的好处是模型的观察范围比较广,因为当我们只采用单向循环网络时,在时间步t+1只能观察到x_t以及之前的输入数据,而不能观察到x_t+2及之后的情况。而当我们使用双向循环网络,模型在每一个时间步都会观察全部的输入序列,从而决定最后的输出。
如上所示,我们将两个反向读取的LSTM网络连接就成了BiLSTM。如果我们同时训练正向LSTM与逆向LSTM,并把这两个循环网络的隐藏层拿出来都接入一个输出层,那么我们就能得到最后的输出结果y。使用这种BiLSTM的好处是模型的观察范围比较广,因为当我们只采用单向循环网络时,在时间步t+1只能观察到x_t以及之前的输入数据,而不能观察到x_t+2及之后的情况。而当我们使用双向循环网络,模型在每一个时间步都会观察全部的输入序列,从而决定最后的输出。FoolNLTK的安装
官方提供的安装方式是直接使用
pip install foolnltk进行安装,但我安装完后执行却报如下错误:Traceback (most recent call last): File "D:/CodeHub/NLP/test_new.py", line 1, in <module> import fool File "D:\CodeHub\NLP\venv\lib\site-packages\fool\__init__.py", line 10, in <module> from fool import lexical File "D:\CodeHub\NLP\venv\lib\site-packages\fool\lexical.py", line 8, in <module> from fool.predictor import Predictor File "D:\CodeHub\NLP\venv\lib\site-packages\fool\predictor.py", line 8, in <module> from tensorflow.contrib.crf import viterbi_decode ModuleNotFoundError: No module named 'tensorflow.contrib'导致此问题的原因是foolnltk的后端使用的是tensorflow,与已经安装的tersorflow2.0.2版本不兼容,解决方案:
pip uninstall tensorflow pip install tensorflow==1.15
FoolNLTK的使用
示例代码:
import fool sentence = "中文分词测试:我爱北京天安门" print(fool.cut(sentence)) # 分词 print(fool.pos_cut(sentence)) # 词性标注 print(fool.analysis(sentence)[1]) # 明名实体识别
输出:
[['中文', '分词', '测试', ':', '我', '爱', '北京', '天安', '门']] [[('中文', 'nz'), ('分词', 'n'), ('测试', 'n'), (':', 'wm'), ('我', 'r'), ('爱', 'v'), ('北京', 'ns'), ('天安', 'nz'), ('门', 'n')]] [[(9, 15, 'company', '北京天安门')]]参考链接:
HanLP
HanLP原先是一个JAVA版本的自然语言处理工具包,在目前的升级中已经支持了Python。当前已经支持基于TensorFlow2.x。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
- 中文分词
- HMM-Bigram(速度与精度最佳平衡;一百兆内存)
- 最短路分词、N-最短路分词
- 由字构词(侧重精度,全世界最大语料库,可识别新词;适合NLP任务)
- 感知机分词、CRF分词
- 词典分词(侧重速度,每秒数千万字符;省内存)
- 极速词典分词
- 所有分词器都支持:
- 索引全切分模式
- 用户自定义词典
- 兼容繁体中文
- 训练用户自己的领域模型
- HMM-Bigram(速度与精度最佳平衡;一百兆内存)
- 词性标注
- HMM词性标注(速度快)
- 感知机词性标注、CRF词性标注(精度高)
- 命名实体识别
- 基于HMM角色标注的命名实体识别(速度快)
- 中国人名识别、音译人名识别、日本人名识别、地名识别、实体机构名识别
- 基于线性模型的命名实体识别(精度高)
- 感知机命名实体识别、CRF命名实体识别
- 基于HMM角色标注的命名实体识别(速度快)
- 关键词提取
- TextRank关键词提取
- 自动摘要
- TextRank自动摘要
- 短语提取
- 基于互信息和左右信息熵的短语提取
- 拼音转换
- 多音字、声母、韵母、声调
- 简繁转换
- 简繁分歧词(简体、繁体、臺灣正體、香港繁體)
- 文本推荐
- 语义推荐、拼音推荐、字词推荐
- 依存句法分析
- 基于神经网络的高性能依存句法分析器
- 基于ArcEager转移系统的柱搜索依存句法分析器
- 文本分类
- 情感分析
- 文本聚类
- KMeans、RepeatedBisection、自动推断聚类数目k
- word2vec
- 词向量训练、加载、词语相似度计算、语义运算、查询、KMeans聚类
- 文档语义相似度计算
- 语料库工具
- 部分默认模型训练自小型语料库,鼓励用户自行训练。所有模块提供训练接口,语料可参考98年人民日报语料库。
参考链接:
其他参考:
- 中文分词


