网格系统(Grid System)对于分析海量空间数据集,将地球空间划分为可识别的网格单元(cell)至关重要。H3是由Uber开源的一个六边形分层索引网格系统,也是最近几年实现数据聚合的主要趋势,在H3出现之前大部分情况采用的是Geohash算法,墨卡托投影,还有一些其他投影技术,比如Google S2地理索引。
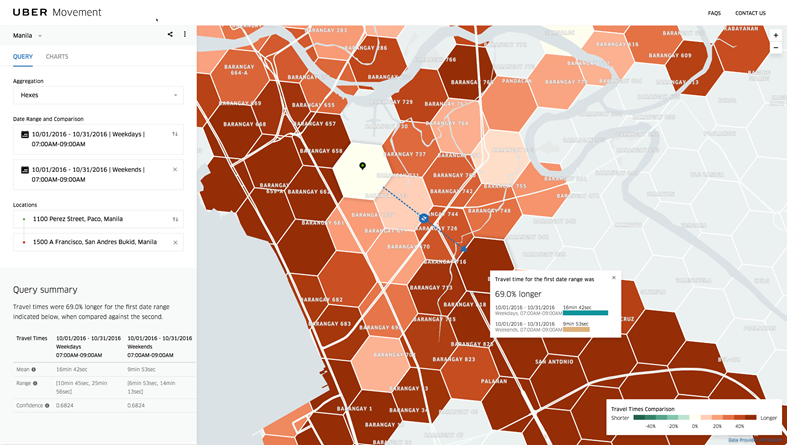
H3网格系统在Uber的主要应用为:
- 优化乘车价格和调度(动态定价)
- 地图空间数据的可视化和挖掘
- 用于整个市场的分析和优化
GEOHASH存在的问题
GeoHash的原理就是按照区域,把经纬度进行编码,按照不同的网格精度,变成不同位数的编码,在同一区域中的编码相同。
问题1:不同精度下网格的形状不一(长方形和矩形)且精度的变化幅度时小时大
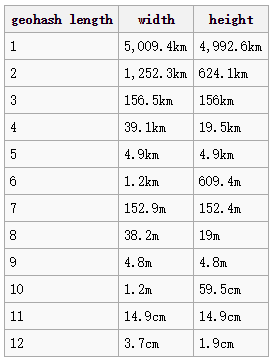
问题2:在不同纬度的地区会出现地理单元单位面积差异较大的情况
在国际化业务中会表现特别明显,比如北京和新加坡的geohash对应面积有将近30%的差异。这导致业务指标和模型输入的特征存在一定的分布倾斜和偏差。
问题3:存在8邻域到中心网格的距离不相等的问题
Uber H3的设计思路
六边形网格索引
H3是一种基于网格的空间索引,但跟普通的矩形网格索引不同的是,他的每一个网格都是正六边形。为啥要选正六边形呢,因为在基于网格的空间索引中,使用的多边形的边数越多,则一个网格越近似圆形,做缓冲区查询、kNN查询什么的也就越方便。而做网格索引又要求空间能够被网格铺满,不能有缝隙。根据初中数学知识,我们知道一个多边形的内角和公式为:
$$\theta=(x-2)*180^\circ$$
其中,x为多边形的边数,$\theta$为多边形的内角和。则一个正多边形的每个角的角度为$\frac{\theta}{x}=\frac{(x-2)*180^\circ}{x}$,而如果需要多边形能够铺满空间,则在多边形的顶点相交处,设每个顶点有y个多边形相交,需要满足以下等式:
$$\frac{360^\circ}{y}=\frac{(x-2)*180^\circ}{x}$$
以上等式的求解过程我不再赘述,这个等式只有三组整数解:x=3,y=6;x=4,y=4;x=6,y=3。
因此,能够做网格空间索引的形状只有三角形、矩形和六边形,而六边形因为边数最多,最接近圆,所以理论上来说在某些场景下是最优的选择。
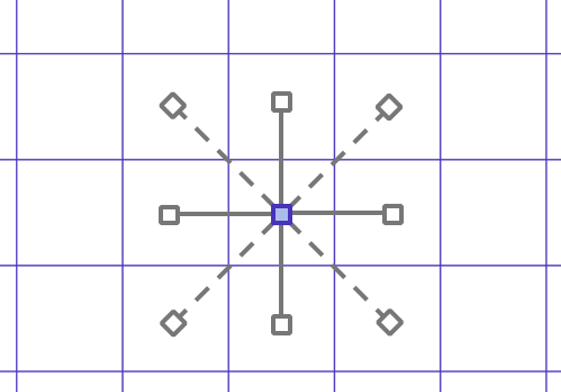
Uber的技术博客上也给出了使用六边形做空间索引的优越性:
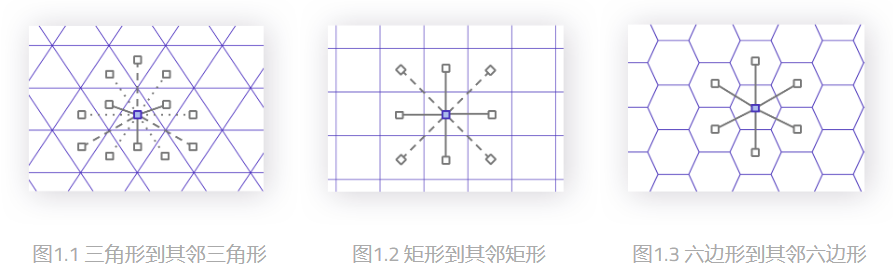
上图展示了三种网格到其相邻网格的距离,六边形网格与周围网格的距离有且仅有一个,而四边形存在两类距离,三角形有三类距离。所以,H3就使用六边形作为网格索引的基本单元,实现空间索引。
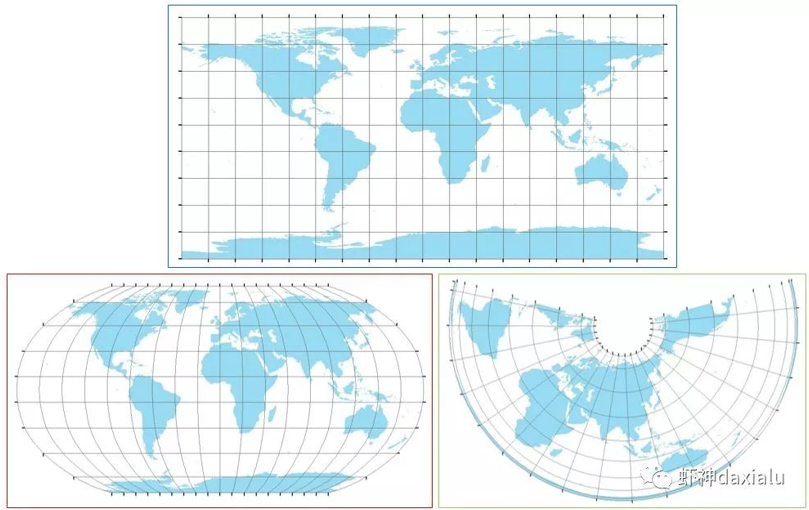
无变形的投影
全球网格系统通常至少需要两件事:地图投影和放置在地图上的网格。从地球上的三维位置到地图上的二维点需要地图投影然后将网格覆盖在地图上,形成一个全球网格系统。在GIS领域中,对空间填充曲线熟悉的同学应该知道,不论是GeoHash, Z2或者Hilbert,虽然看起来都是将空间按照经纬度分割成了一个个大小相等的网格,但实际上这些网格的实际面积并不相等。对于靠近极地的网格,虽然经纬度的间隔没变,但由于地球的曲率,这些网格的实际面积远小于靠近赤道的网格。
这种实际面积不相等的网格索引可能会造成一个问题,那就是由于网格大小不一致导致网格内数据量不一致,造成热网格和冷网格。于是,H3干脆摒弃传统的地图投影,直接在地球上铺满六边形。
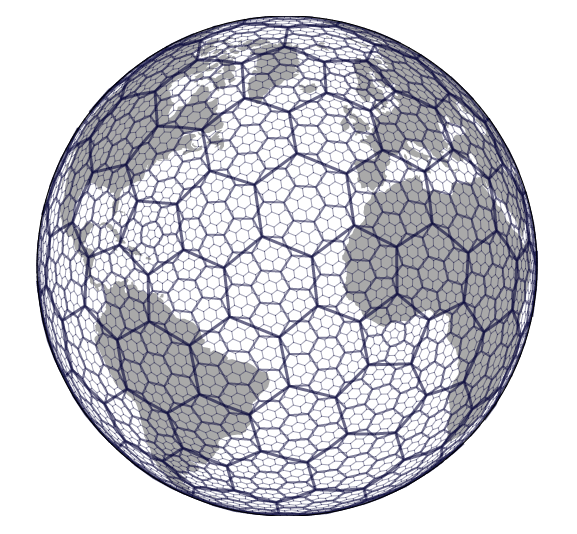
想要实现六边形的网格,最大的困难时如何变化。H3的前身其实是DDGS(Discrete global grid systems)中的ISEA3H,其原理是把无限的不规则但体积相等的六棱柱从二十面体中心延伸,这样任何半径的球体都会穿过棱镜形成相等的面积cell,基于该标准使得每一个地理单元的面积大小就可以保证几乎相同。然而原生的ISEA3H方案在任意级别中都存在12个五边形,H3的主要改进是通过坐标系的调整将其中的五边形都转移到水域上,这样就不影响大多数业务的开展。
H3实现的方法是:将地球当作一个二十面体,这个二十面体的每一个面都是球面三角形,有12个顶点,称为球形二十面体(spherical icosahedron),在这个球形十二面体的每个面上都有相同排列方式的六边形。由于这个球形二十面体的12个顶点每一个都在地球上的水里,可以保证对于每个面做处理时不会遇到边界的edge case,因为Uber还没有轮船快艇业务,只需要保证在陆地上H3好使就行。这个球形二十面体的示意图见图。
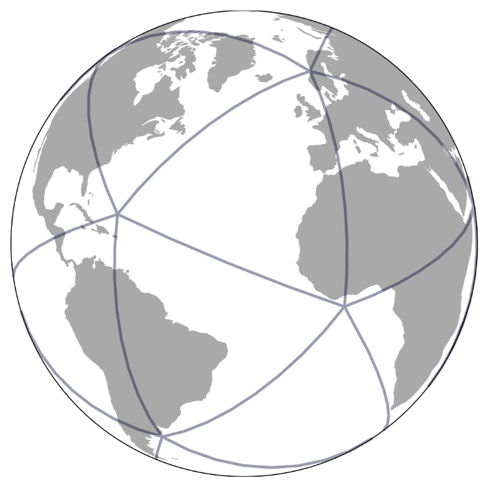
在第0层,这个球形二十面体的每一个面长这样:
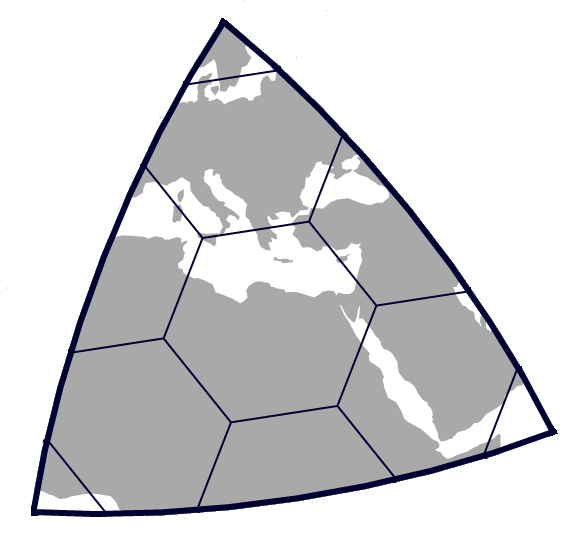
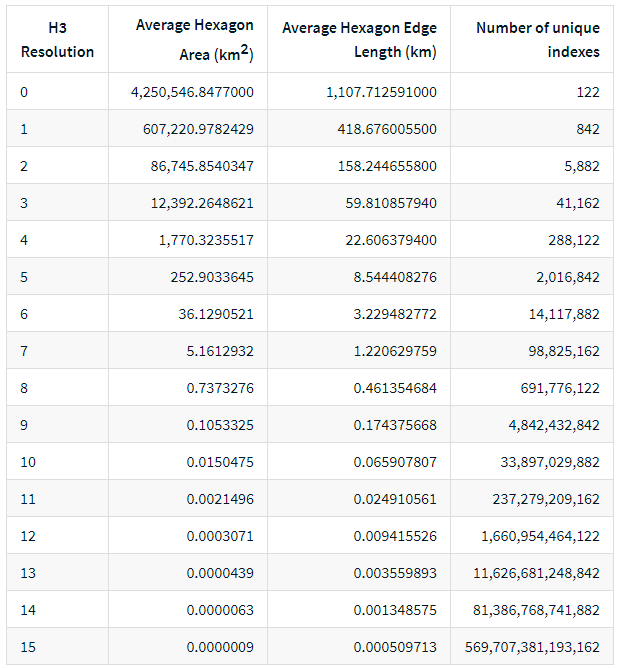
可以看到,在一个球面三角形的顶角处有个小三角形,这个小三角形就是 H3 的一种 edge case:在二十面体的顶点处,有五个面交于这个顶点,每个面在这个顶点处都有一个小三角形,所以这些小三角形会形成一个五边形。也就是说,H3 并不能保证每个空间单元都是六边形,在一些地方还是会存在五边形,但是这样做也不会造成很大影响,因为根据球形二十面体每个顶点都在水里的特性,这种五边形只会出现在水域周围,不会对 Uber 的打车和外卖业务造成很大的影响。根据这样的索引特性,H3 规定在索引的第 0 层,每个面和上图一样,每个面上有 5.5 个六边形和 3/5 个五边形,即第 0 层一共有 110 个六边形和 12 个五边形。H3 将这 110 个六边形称为基网格(base cells)。H3 最高可以到 15 层,也就是说 H3 有 16 个层级的空间索引粒度,在粒度最细的第 15 层中,平均每个网格的大小为 0.9 平方米,平均边长为 0.509713 米。在往下一层划分时,每个父网格对应 7 个子网格,父子网格之间的对应关系是这样的:
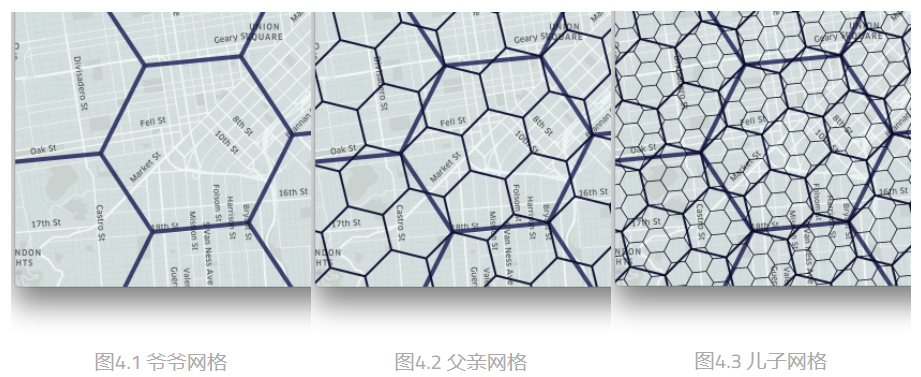
可以看到,父子网格之间并没有严密的对齐,父网格和其所对应的 7 个子网格之间会有一点差异,这种差异也导致了 H3 并不能表现出很好的层级关系。
详细的精度数据如下:
网格编码
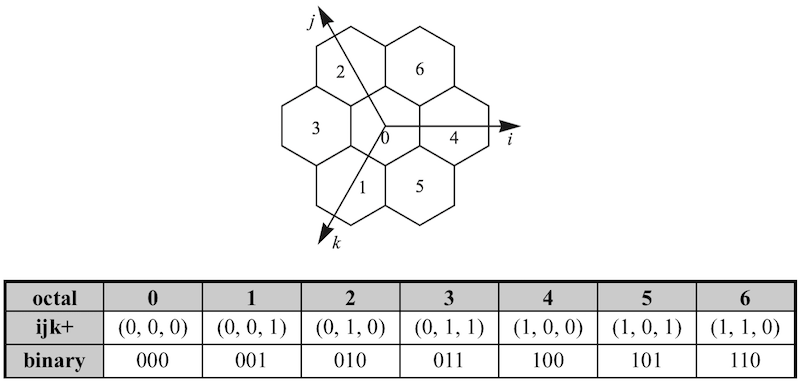
对六边形索引,H3 使用了一种 IJK 坐标系来确定六边形的位置。IJK 坐标系长这样:
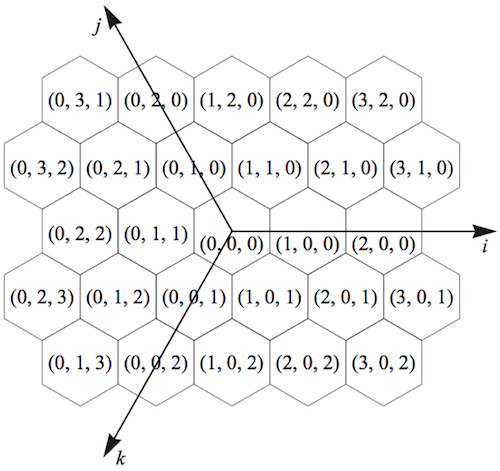
当然,H3 不会简单地使用这种坐标系来对所有六边形进行编码,因为在每一个层级六边形的排列方式都不太一样。总的来说,在所有层级中,六边形的排列方式只有两种类型,称为 Class II 和 Class III。在这两种类型的排列方式中,IJK 坐标系的三个轴的方向不太一样。对于这种在一个二十面体的面上,根据不同的六边形排列方式使用不同方向坐标轴的坐标系,H3 称之为 Face IJK 坐标系:
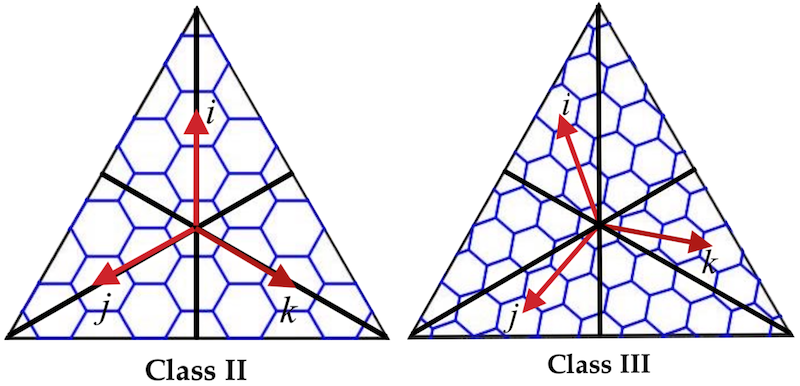
那么对于一个面上所有层级的所有六边形,都使用 Face IJK 坐标系编码,再加上面的唯一标识符可不可以?答案是可以,但没必要,因为如果这样做,H3 编码会更加表示不了层级之间的关系。H3 为了突出层级之间的关联性,使用了一种方法:每个六边形都包含其父六边形的坐标。这样只需要规定好每个网格的子网格坐标的计算方法,对于子网格,只需在父网格的坐标后面追加子网格的坐标即可。这样一来,只需关注一个网格的 7 个子网格如何计算坐标,所有层级的每个网格的坐标都可以递归得到,这 7 个网格坐标的计算方法见图,为了表述方便,称之为 IJK 七网格坐标系。那么还有 12 个五边形怎么办?那 12 个五边形随着层级划分仍然是 12 个,层级越高这些五边形越小,并且都在海里,影响不大,直接不管了。
同时,H3 还专门设置了一种叫做网格有向边(directed edges of grid cells)的东西(如图),其目的是为了网格能够快速地找到其某个邻网格。这种网格有向边分为单向网格有向边和双向网格有向边,比如说,对于两个相邻网格 A 和 B,其相交的边是 E,如果 E 是一条由 A->B 的单向边,那么只能通过 A 快速找到邻居 B,B 不能快速找到邻居 A;而如果 E 是一条双向边,那么 A 可以快速地找到 B,B 也可以快速地找到 A。
H3 的索引值最多占 63 个比特位,可以用一个长整型表示,其结构如下所示:
- 0-3 位:索引模式。0 表示无效,1 表示普通的网格,2 表示单向边,3 表示双向边
- 4-6 位:如果索引模式是 0 或 1,则没用;如果是 2 或 3,表示这条边是这个六边形的哪条边,取值范围 1-6
- 7-10 位:表示层级,取值范围 0-15
- 11-17 位:表示这个网格属于哪个基网格,取值范围 0-121
- 18-21 位:表示这个网格的第一代祖宗网格在 IJK 七网格坐标系下的坐标
- n-n+2(n<=61)位:同上,表示这个网格的第 i 代祖宗网格在 IJK 七网格坐标系下的坐标
可以看到,其实对于层级数比较小的网格,后面很多位是不需要的,如果全置为 0 则会浪费很多空间,所以 H3 索引值是可以压缩的。
Uber H3 使用示例
Uber 平台每天都会发生数以百万计数的事件,包括但不限于:打车、拼车,外卖。每个事件都发生在特定的位置,如,乘客在自己家中发起乘车订单,而驾驶员则在几英里外的汽车中接受该订单。这些事件使 Uber 能够更好地了解和优化我们的服务。例如,可以告诉我们在城市的某个地方需求大于供应,然后就可以做出相应的价格调整,或者通知平台的某个 Uber 驾驶员附近有两个乘车订单。
要从 Uber 业务数据中获取信息和知识,需要分析整个城市的数据。由于城市在地理位置上是多种多样的,因此需要以精细的粒度进行分析。以精细的粒度(事件发生的确切位置)进行分析是非常困难且费力的。对区域(例如城市中的社区)进行分析更加切实可行。
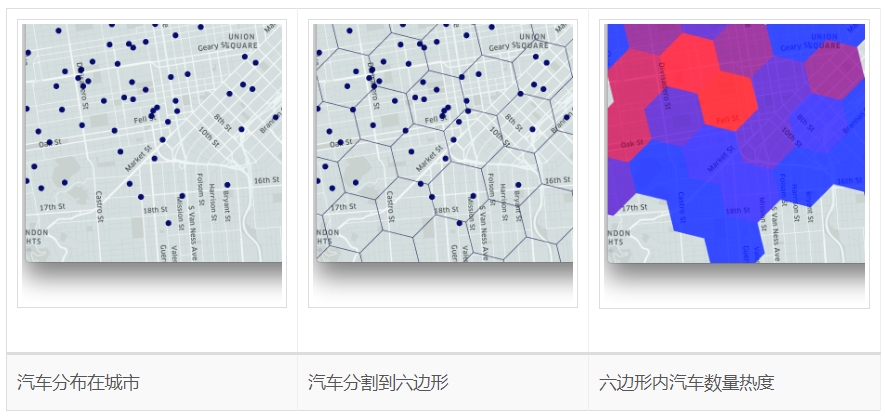
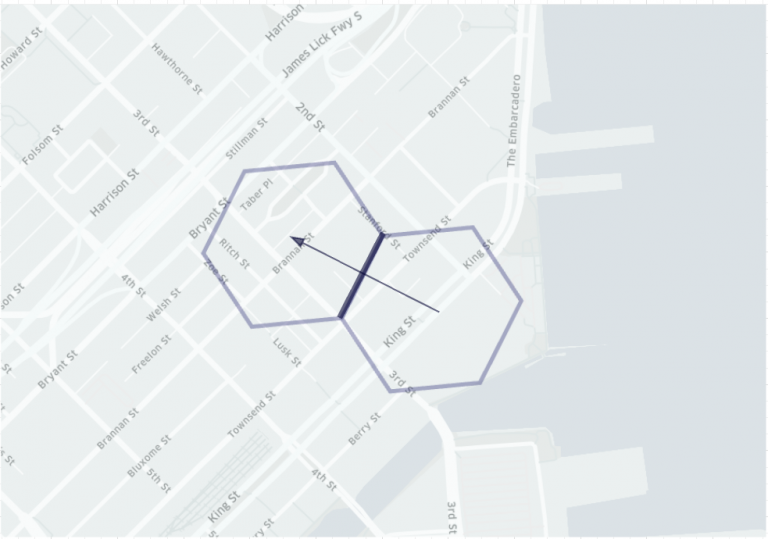
上面的地图描绘了使用 H3 进行分割的过程。我们使用网格系统将事件存储到六边形区域(即网格)中。我们通过测量所服务的每个城市中六边形的供求来计算高峰价格。这些六边形构成了我们分析 Uber 业务的基础。
六边形是一个重要的选择,六边形可以最大程度地减少用户穿越城市时引入的量化误差。还可以轻松地获取近似半径。下图为纽约市(曼哈顿)的按邮政编码划分的地图:
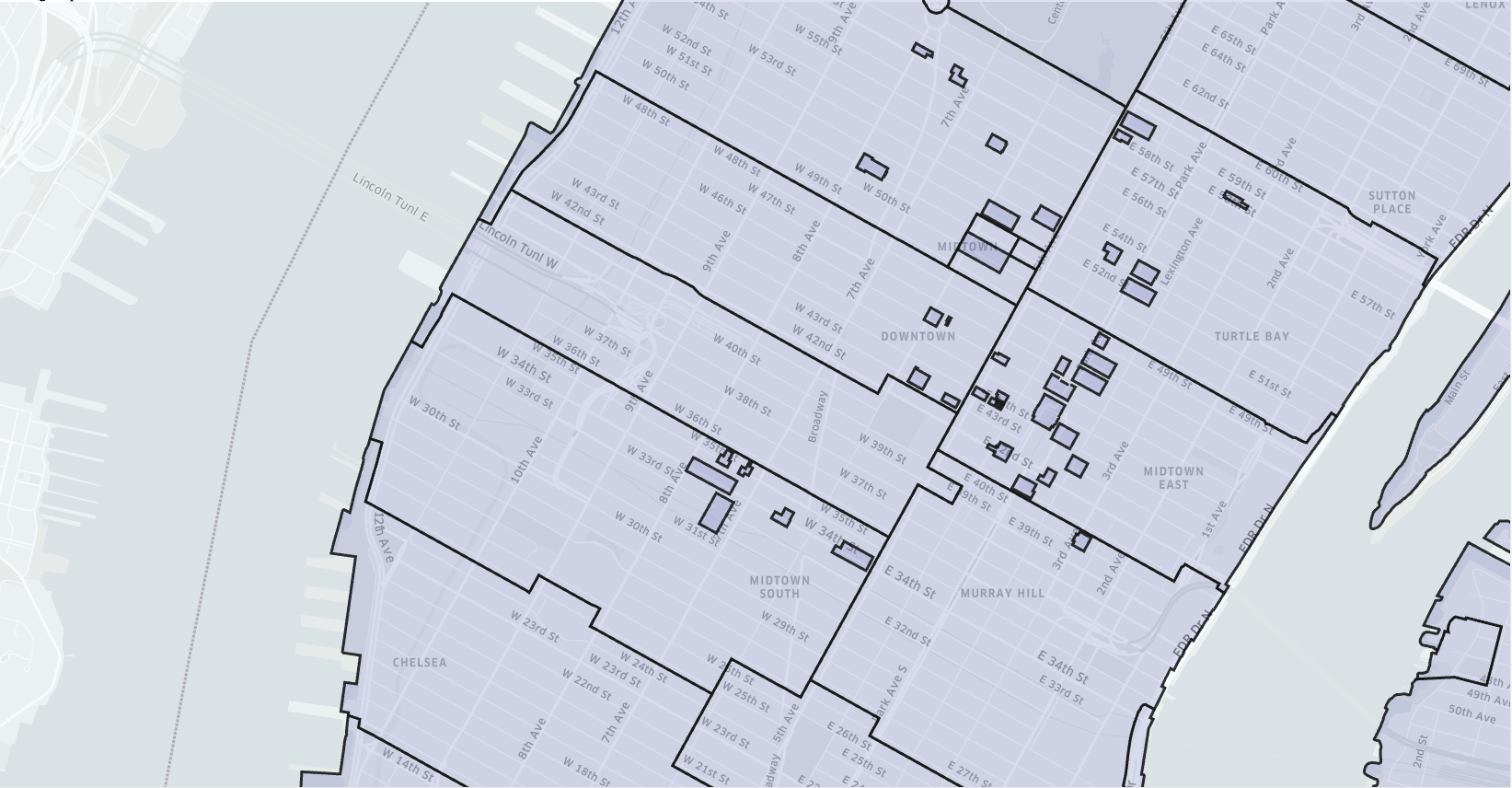
这些区域具有不规则的形状和大小,对分析没有帮助,并且区域划分随时发生改变,而这些改变与我们使用它们的目的完全无关的。Uber 运营团队还可以根据他们对城市的了解来划定区域,但是随着城市的变化,这些区域需要经常更新,并且经常随意定义区域的边缘。
网格系统在 Uber 运营所在的城市中应该具有可比的形状和大小,并且不受任意更改。尽管网格系统无法与城市中的街道和社区保持一致,但可以通过对网格单元进行聚合来将其有效地表示社区。可以使用目标函数完成聚合,从而生成对分析更有用的形状。确定聚类的成员与设置查找操作也应该是很高效的。随机生成的六边形簇覆盖旧金山市:
Uber H3 的安装与使用
H3 的安装
H3 在使用 pip install h3 时,容易发生如下错误:
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Collecting h3
Downloading http://mirrors.aliyun.com/pypi/packages/98/2a/704b2db80465ce3a412d6c94f1c1658cffbbb4e76c5c03bb133f588cc131/h3-3.4.3.tar.gz
Building wheels for collected packages: h3
Building wheel for h3 (setup.py) ... error
ERROR: Command errored out with exit status 1:
command: /opt/conda/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-h2kzp6ux/h3/setup.py'"'"'; __file__='"'"'/tmp/pip-install-h2kzp6ux/h3/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' bdist_wheel -d /tmp/pip-wheel-kqgcncvz --python-tag cp37
cwd: /tmp/pip-install-h2kzp6ux/h3/
Complete output (47 lines):
running bdist_wheel
running build
running build_py
creating build
creating build/lib.linux-x86_64-3.7
creating build/lib.linux-x86_64-3.7/h3
copying h3/__init__.py -> build/lib.linux-x86_64-3.7/h3
copying h3/h3.py -> build/lib.linux-x86_64-3.7/h3
running build_ext
+VERSION=v3.4.2
+IS_64BITS=True
+'[' '' == v3.4.2 ']'
+command -v cmake
+echo 'cmake required but not found.'
cmake required but not found.
+exit 1
Traceback (most recent call last):
File "", line 1, in
File "/tmp/pip-install-h2kzp6ux/h3/setup.py", line 65, in
distclass=BinaryDistribution)
File "/opt/conda/lib/python3.7/site-packages/setuptools/__init__.py", line 145, in setup
return distutils.core.setup(**attrs)
File "/opt/conda/lib/python3.7/distutils/core.py", line 148, in setup
dist.run_commands()
File "/opt/conda/lib/python3.7/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/opt/conda/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/opt/conda/lib/python3.7/site-packages/wheel/bdist_wheel.py", line 192, in run
self.run_command('build')
File "/opt/conda/lib/python3.7/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/opt/conda/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/opt/conda/lib/python3.7/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/opt/conda/lib/python3.7/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/opt/conda/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/tmp/pip-install-h2kzp6ux/h3/setup.py", line 25, in run
install_h3(h3_version)
File "/tmp/pip-install-h2kzp6ux/h3/setup.py", line 18, in install_h3
subprocess.check_call('bash ./.install.sh {} {}'.format(h3_version, is_64bits), shell=True)
File "/opt/conda/lib/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'bash ./.install.sh v3.4.2 True' returned non-zero exit status 1.
----------------------------------------
ERROR: Failed building wheel for h3
Running setup.py clean for h3
Failed to build h3
Installing collected packages: h3
Running setup.py install for h3 ... error
ERROR: Command errored out with exit status 1:
command: /opt/conda/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-h2kzp6ux/h3/setup.py'"'"'; __file__='"'"'/tmp/pip-install-h2kzp6ux/h3/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-ccmfladx/install-record.txt --single-version-externally-managed --compile
cwd: /tmp/pip-install-h2kzp6ux/h3/
Complete output (49 lines):
running install
running build
running build_py
creating build
creating build/lib.linux-x86_64-3.7
creating build/lib.linux-x86_64-3.7/h3
copying h3/__init__.py -> build/lib.linux-x86_64-3.7/h3
copying h3/h3.py -> build/lib.linux-x86_64-3.7/h3
running build_ext
+VERSION=v3.4.2
+IS_64BITS=True
+'[' '' == v3.4.2 ']'
+command -v cmake
+echo 'cmake required but not found.'
cmake required but not found.
+exit 1
Traceback (most recent call last):
File "", line 1, inFile "/tmp/pip-install-h2kzp6ux/h3/setup.py", line 65, in
distclass=BinaryDistribution)
File "/opt/conda/lib/python3.7/site-packages/setuptools/__init__.py", line 145, in setup
return distutils.core.setup(**attrs)
File "/opt/conda/lib/python3.7/distutils/core.py", line 148, in setup
dist.run_commands()
File "/opt/conda/lib/python3.7/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/opt/conda/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/opt/conda/lib/python3.7/site-packages/setuptools/command/install.py", line 61, in run
return orig.install.run(self)
File "/opt/conda/lib/python3.7/distutils/command/install.py", line 545, in run
self.run_command('build')
File "/opt/conda/lib/python3.7/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/opt/conda/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/opt/conda/lib/python3.7/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/opt/conda/lib/python3.7/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/opt/conda/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/tmp/pip-install-h2kzp6ux/h3/setup.py", line 25, in run
install_h3(h3_version)
File "/tmp/pip-install-h2kzp6ux/h3/setup.py", line 18, in install_h3
subprocess.check_call('bash ./.install.sh {} {}'.format(h3_version, is_64bits), shell=True)
File "/opt/conda/lib/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command 'bash ./.install.sh v3.4.2 True' returned non-zero exit status 1.
----------------------------------------
ERROR: Command errored out with exit status 1: /opt/conda/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-h2kzp6ux/h3/setup.py'"'"'; __file__='"'"'/tmp/pip-install-h2kzp6ux/h3/setup.py'"'"'; f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /tmp/pip-record-ccmfladx/install-record.txt --single-version-externally-managed --compile Check the logs for full command output.
通过分析,发现编译环境缺少 cmake 导致的。
- 解决方案 1:如果安装了 anaconda,则可以使用 conda install h3-py -c conda-forge 进行安装
- 解决方案 2:下载编译好的 .whl 文件进行安装h3-3.4.3-cp37-cp37m-win_amd64.whl.zip
- 解决方案 3:安装 cmake,以 Linux 系统为例:
sudo apt-get install libssl-dev wget https://github.com/Kitware/CMake/releases/download/v3.17.0/cmake-3.17.0.tar.gz tar -zxvf cmake-3.17.0.tar.gz cd cmake-3.17.0 ./bootstrap make sudo make install cmake --version
H3 的使用
使用示例:
from h3 import h3
for i in range(0, 16):
print(h3.geo_to_h3(lat=23.103804, lng=113.370424, res=i)) # 经纬度转化为 H3 索引
print(h3.h3_to_geo(h3_address="874118b24ffffff")) # H3 索引转化为经纬度(中心点)
print(h3.h3_to_geo_boundary(h3_address="874118b24ffffff")) # H3 索引转化为经纬度(六个顶点)
print(h3.k_ring(h3_address="874118b24ffffff", ring_size=1)) # 相邻网格(k 代表拓展的层数)
print(h3.k_ring_distances(h3_address="874118b24ffffff", ring_size=2)) # 讲相邻网格按距离拆分成列表
print(h3.hex_ring(h3_address="874118b24ffffff", ring_size=1)) # 给出相邻的环
print(h3.hex_range_distances(h3_address="874118b24ffffff", ring_size=1))
print(h3.hex_ranges(h3_address="874118b24ffffff", ring_size=1))
可视化工具:
Uber H3 实战:英国交通事故点聚类
主要流程:
- 将交通事故的经纬度信息转化为 Uber H3
- 方案一:对交通事故所在的经纬度进行聚类,获取非 -1 类别的数据,统计在聚集点的每个 Uber H3 的交通数据数量,并在地图上呈现
- 方案二:对交通事故所在的 H3 网格进行汇总统计,针对网格所在区域按照阈值筛选后在地图上进行呈现
具体代码:
import numpy as np
import pandas as pd
import folium
from h3 import h3
from sklearn.cluster import DBSCAN
def create_map(clusters):
# Create the map object
map = folium.Map(zoom_start=12)
# Convert the clusters dictionary items to polygons and add them to the map
for cluster in clusters.values():
points = cluster['geom']
# points = [p[::-1] for p in points]
tooltip = "{0} accidents".format(cluster['count'])
polygon = folium.vector_layers.Polygon(locations=points, tooltip=tooltip,
fill=True,
color='#ff0000',
fill_color='#ff0000',
fill_opacity=0.4, weight=3, opacity=0.4)
polygon.add_to(map)
# Determine the map bounding box
max_lat = df.Latitude.max()
min_lat = df.Latitude.min()
max_lon = df.Longitude.max()
min_lon = df.Longitude.min()
# Fit the map to the bounds
map.fit_bounds([[min_lat, min_lon], [max_lat, max_lon]])
return map
column_types = {'Accident_Index': np.string_, 'LSOA_of_Accident_Location': np.string_}
uk_acc = pd.read_csv("UK_Accidents_2015_2016.csv", dtype=column_types)
# 将经纬度转化成H3
h3_level = 11
def lat_lng_to_h3(row):
return h3.geo_to_h3(row['Latitude'], row['Longitude'], h3_level)
uk_acc['h3'] = uk_acc.apply(lat_lng_to_h3, axis=1)
# 使用DBSCAN进行聚类
uk_acc['rad_lng'] = np.radians(uk_acc['Longitude'].to_numpy())
uk_acc['rad_lat'] = np.radians(uk_acc['Latitude'].to_numpy())
eps_in_meters = 50.0
num_samples = 10
EARTH_R = 6370996.8 # 地球半径
uk_acc['cluster'] = DBSCAN(eps=eps_in_meters/EARTH_R, min_samples=num_samples, metric='haversine').fit_predict(uk_acc[['rad_lat', 'rad_lng']])
df = uk_acc[uk_acc.cluster != -1].copy()
clusters = dict()
for index, row in df.iterrows():
key = row['h3']
if key in clusters:
clusters[key]['count'] += 1
else:
clusters[key] = {"count": 1, "geom": h3.h3_to_geo_boundary(h3_address=key)}
create_map(clusters)
# 直接H3代码进行分组
h3_clusters = dict()
for index, row in uk_acc.iterrows():
key = row['h3']
if key in h3_clusters:
h3_clusters[key]["count"] += 1
else:
h3_clusters[key] = {"count": 1, "geom": h3.h3_to_geo_boundary(h3_address=key)}
relevant_clusters = {key: value for (key, value) in h3_clusters.items() if value['count'] >= 10}
create_map(relevant_clusters)
参考链接:



你好,我想请教个问题,我们在使用h3算法做地理网格索引的时候发现,落在中国上的六边形大部分都不是正六边形,而且部分六边形扭曲严重,想请教您有没有什么办法可以将六边形矫正,比如做偏移类似的方法。
没明白什么意思,地图上看起来不是正六边形?
哪个地图渲染的?
你好 请问一下那个UK_Accidents_2015_2016.csv 这个文件哪里有
搜索文件名自己找一下
H3中国华北大部分在五边形中,对中国很不友好,不推荐使用。